深度学习之循环神经网络RNN
一、RNN基础介绍
1.1 什么是RNN?
循环神经网络(Recurrent Neural Network)是一种专门处理序列数据的神经网络计算模型。
1.2 序列数据的特点
-
数据根据时间步生成
-
前后数据存在关联关系
-
典型代表:文本数据、时间序列数据
1.3 RNN的主要应用场景
-
✨ 生成式AI大模型(AIGC)
-
🌐 机器翻译
-
🎤 语音识别
-
📝 自然语言处理(NLP)
-
文本生成、情感分析等
二、词嵌入层(Embedding Layer)
2.1 核心作用
-
向量表示:将离散的词转换为连续的低维稠密向量
-
语义保持:在向量空间中保持词语的上下文语义关系
-
维度约减:避免one-hot编码的高维稀疏问题
2.2 使用方法
文本 → jieba分词 → 词下标索引 → Embedding层 → 词向量
2.3 PyTorch API
"""
演示词嵌入层的API应用.
RNN介绍:
全称叫Recurrent neural network, 循环神经网络, 主要处理 序列数据的.
序列数据: 后边数据对前边的数据有依赖, 例如: 天气预测, 股市分析, 文本生成...
组成:
词嵌入层 Embedding
循环网络层 RNN
输出层 Linear + Softmax (全连接层)
self.ebd = nn.Embedding(unique_word_count, 128) # 词嵌入层
self.rnn = nn.RNN(128, 256, 1) # 循环网络层
self.out = nn.Linear(256, unique_word_count) # 输出层(Linear + Softmax)
第1层:词嵌入层 (Embedding) # 词 → 向量
第2层:循环网络层 (RNN) # 处理序列依赖
第3层:输出层 (Linear+Softmax) # 向量 → 概率
词嵌入层介绍(作用):
把词 (或者 词对应的索引) 转成 词向量.
"""
import torch.nn as nn
# 创建词嵌入层
embed = nn.Embedding(
num_embeddings=len(vocab), # 词汇表大小
embedding_dim=8 # 词向量维度
)参数说明:
-
num_embeddings:词汇表中词的总数量 -
embedding_dim:每个词映射成的向量维度
三、RNN循环层
3.1 核心作用
-
具有记忆功能的网络结构
-
专门处理序列数据,捕捉时间步之间的依赖关系
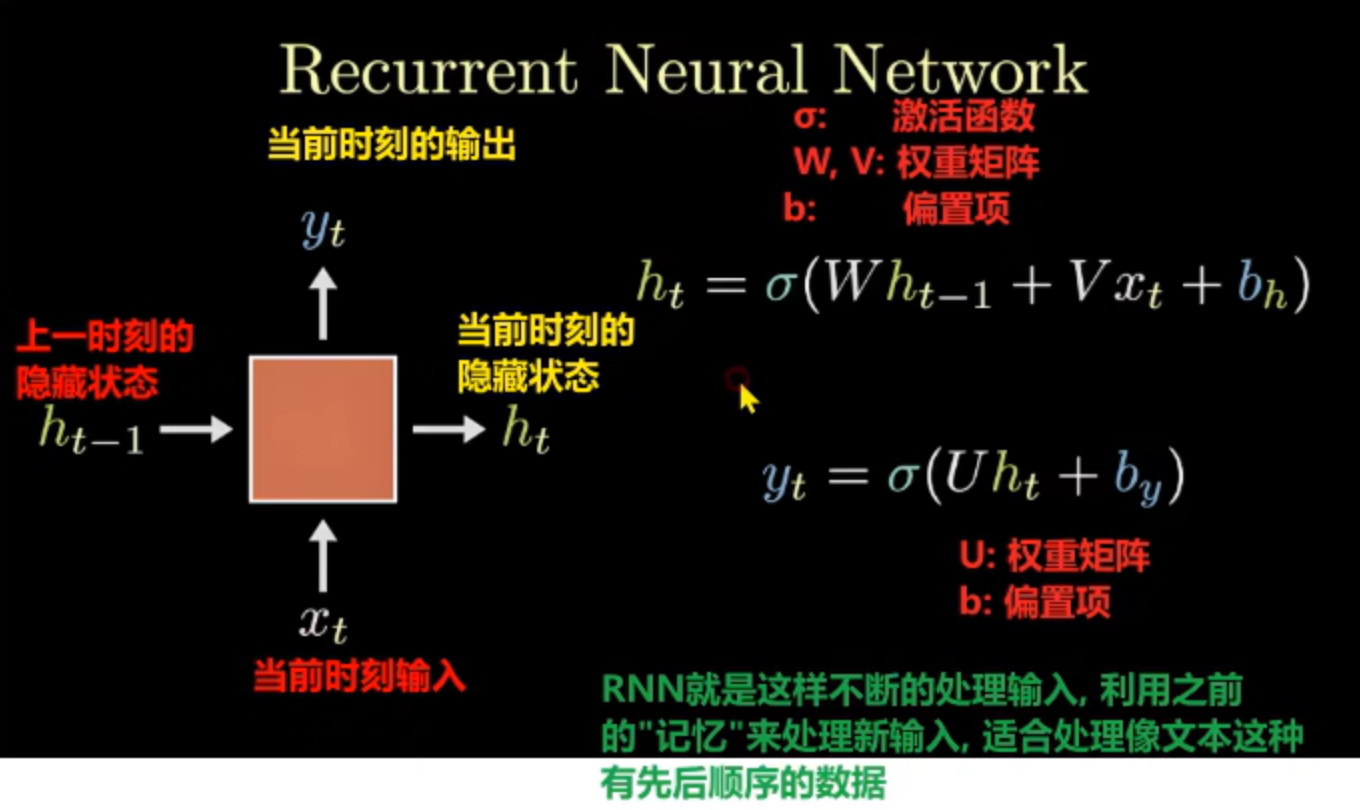
3.2 工作原理
h₁ = 激活函数(W·h₀ + U·x + b)
输出 =激活函数(V·h₁ + b)
计算流程:
-
接收上一步的隐藏状态h₀
-
接收当前输入的词向量x
-
计算当前步的隐藏状态h₁
-
输出预测结果
-
预测结果经过全连接层,输出词汇表中每个词的概率
3.3 PyTorch API
"""
创建RNN层
rnn = nn.RNN(
input_size, 输入维度(词向量维度)
hidden_size, 隐藏层维度(神经元输出维度)
num_layers=1 隐藏层层数
)
rnn = nn.RNN(input_size=128, hidden_size=256, num_layers=1)
单批次数据说明:
- 样本数: 5句话 (batch_size=5)
- 特征数: 每句话32个词 (seq_len=32) → 每个词是一个特征
- 特征维度: 256维 (hidden_size) → 每个特征(词)用256维向量表示
调用RNN
output, hn = rnn(x, h0)
输入输出说明:
x: [5, 32] 单批次5句话,每句32个词(词索引)
经过词嵌入层后 nn.Embedding(5703, 128) - embd = self.ebd(x) - embd.shape: [5, 32, 128]
输入RNN时需要转置 rnn_input = embd.transpose(0, 1) # [32, 5, 128]
现在才是真正的RNN输入:[时间步, 样本数, 输入维度]
output, hn = rnn(rnn_input, h0) # output: [32, 5, 256]
h0: [1, 5, 256] 单批次5句话的初始隐藏状态(全0)
output: [32, 5, 256] 单批次5句话的完整特征表示:
- 32: 每句话的32个特征(词)位置
- 5: 5个样本(5句话)
- 256: 每个特征的隐藏状态维度
hn: [1, 5, 256] 单批次5句话的最终特征表示:
- 1: RNN层数
- 5: 5个样本
- 256: 最后一词(第32个特征)的隐藏状态
循环网络层:
基于 上一次的隐藏状态 + 本次的输入 -> 本次的隐藏状态.
全连接层:
基于 本次的隐藏状态 -> 本次的输出.
公式:
本次的隐藏状态 = tanh(上次的隐藏状态加权求和 + 本次的输入 加权求和)
本次的输出 = softmax(本次的隐藏状态加权求和), 有词汇表中所有词的概率, 选概率最大的哪个词作为 最终预测结果.
简单总结下RNN:
词嵌入层:
将词(词的索引) 转换为 词向量表示.
RNN层(循环网络层):
逐步处理词向量, 生成 每个时间步的 隐藏状态.
全连接层(输出映射):
通过线性变换将隐藏状态映射到输出, 通常是1个词汇表中词的概率分布.
"""
# 导包
import torch
import torch.nn as nn
rnn = nn.RNN(input_size=128, hidden_size=256, num_layers=1)
x = torch.randn(size=(5, 32)) # 修正:原始输入是词索引
# 1. 原始输入
x: [5, 32] # 5句话,每句32个词(词索引)
# 2. 经过词嵌入层后
embd = nn.Embedding(5703, 128) # 词嵌入层
x_embd = embd(x) # [5, 32, 128] 每个词变成128维向量
# 3. 输入RNN时需要转置
rnn_input = x_embd.transpose(0, 1) # [32, 5, 128]
# 现在才是真正的RNN输入:[时间步, 样本数, 输入维度]
# 4. 初始化隐藏状态 h0
h0 = torch.randn(size=(1, 5, 256)) # 修正:[层数, batch_size, hidden_size]
"""
h0: [1, 5, 256] 初始隐藏状态含义:
- 维度1 (1): RNN层数 = 1
- 维度2 (5): 批次大小 = 5句话
- 维度3 (256): 隐藏状态维度 = 256个神经元
说明: h0是5句话各自的初始记忆,初始值通常设为0或随机初始化
"""
# 5. RNN处理
output, hn = rnn(rnn_input, h0) # output: [32, 5, 256]
"""
output: [32, 5, 256] 输出含义:
- 32: 时间步长度(每句话32个词的位置)
- 5: 批次大小(5句话)
- 256: 隐藏状态维度(每个词位置的记忆)
hn: [1, 5, 256] 最终隐藏状态含义:
- 1: RNN层数
- 5: 5句话
- 256: 最后一词(第32个词)的隐藏状态
说明: hn是5句话各自最后时刻的记忆,包含了整句话的完整信息
"""张量维度说明:
-
x/output:(sequence_length, batch_size, input_size) -
h0/hn:(num_layers, batch_size, hidden_size)
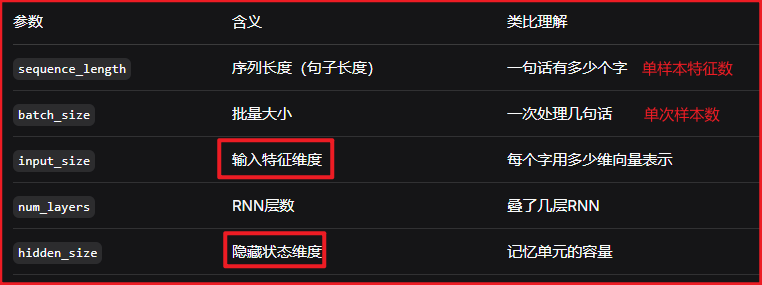
注意:RNN层的预测结果维度 = 隐藏层维度
阿珍爱上了阿强 文本分析
1.阿珍爱上了阿强 切词并压缩降维
text = '阿珍爱上了阿强'
words = jieba.lcut(text)
print(words)
# 参1: 词表大小(词的个数), 参2: 词向量的维度
embed = nn.Embedding(len(words), 2)
for i, word in enumerate(words):
# print(i, word)
# 5. 把词索引(张量形式) 转成 词向量.
word_vector = embed(torch.tensor(i))
print(f'词: {word}, \t\t词向量: {word_vector}')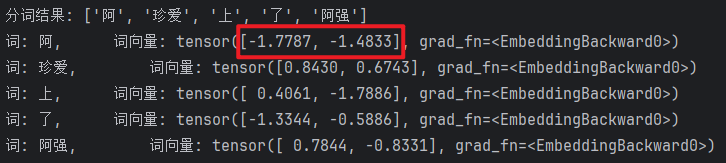
我们如果按照正常的one-hot来记录每个词的词向量,那太耗费算力了,于是我们利用Embedding将词向量压缩到2个维度,然后将每个压缩后的词向量与词表的索引做关联
词表库由5*5(one-hot)压缩成了5*2,将后序需要计算的词向量由5维降低到了2维
2.开始预测下次输出
RNN的作用:
基于上一次的隐藏状态(假设3维) + 本次的输入(2维) 👉本次隐藏状态(3维) 👉 本次输出(5维)
下次输入继续查表找到压缩后的2维 重复计算
本次的隐藏状态 = tanh(上次的隐藏状态加权求和 + 本次的输入 加权求和)
备注:这里2维和3维计算 结果是3维(低维与高维一起计算,结果是高维)
本次的输出 = softmax(本次的隐藏状态加权求和)
备注:这里经过 全连接层中线性层映射升维 加权求和重新回到5维,经过softmax得到概率集合
输出中有词汇表中所有词的概率, 概率求和为1,选概率最大的词作为 最终预测结果.


四、RNN案例_AI歌词生成器
"""
案例:
RNN案例, 基于杰伦歌词来训练模型, 用给定的起始词, 结合长度, 来进行 AI歌词生成.
实现步骤:
1. 获取数据, 进行分词, 获取词表.
2. 数据预处理, 构建数据集.
3. 搭建RNN神经网络.
4. 训练模型.
5. 模型预测.
"""
# 导包
import torch
import jieba
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
import time
# 1. 获取数据, 进行分词, 获取词表.
def build_vocab():
# 1. 定义变量, 记录: 去重后所有的词, 每行文本分词结果.
unique_words, all_words = [], []
# 2. 遍历数据集, 获取到每行文本.
for line in open('./data/jaychou_lyrics.txt', 'r', encoding='utf-8'):
# 2.1 获取到每行歌词, 进行分词.
words = jieba.lcut(line) # ['想要', '有', '直升机', '\n']
# 2.2 所有分词结果记录到 all_words 中.
all_words.append(words) # [['想要', '有', '直升机', '\n'], [第2句歌词切词], ......]
# 2.3 遍历分词结果, 去重后, 添加到unique_words中.
for word in words:
if word not in unique_words:
unique_words.append(word)
# 3. 统计语料中(去重后)词的数量.
word_count = len(unique_words) # 5703个词
# 4. 构建词表, 字典形式, key是词, value是词的索引.
# 例如: {'想要': 0, '有': 1, '直升机': 2, '\n': 3, ...'冠军': 5701, '要大卖': 5702}
word_to_index = {word: i for i, word in enumerate(unique_words)}
# 5. 歌词文本用词表索引表示.
corpus_idx = []
# 6. 遍历每一行的分词结果.
for words in all_words:
# 6.1 定义变量, 记录: 词索引列表.
tmp = []
# 6.2 获取每一行的词, 并获取相应的索引.
for word in words:
tmp.append(word_to_index[word])
# 6.3 在每行词之间, 添加空格隔开.
tmp.append(word_to_index[' '])
# 6.4 获取文档中每个词的索引, 添加到corpus_idx中.
corpus_idx.extend(tmp)
# 7. 返回结果: 唯一词列表(5703个词), 词表 {'想要': 0, '有': 1, ... '要大卖': 5702}, (去重后)词的数量, 歌词文本用词表索引表示.
return unique_words, word_to_index, word_count, corpus_idx
# 2. 数据预处理, 构建数据集.
# 定义数据集类, 继承 torch.utils.data.Dataset
class LyricsDataset(torch.utils.data.Dataset):
# 1. 初始化词索引, 词个数等...
def __init__(self, corpus_idx, num_chars):
# 1.1 文档数据中词的索引
self.corpus_idx = corpus_idx
# 1.2 每个句子中词的个数.
self.num_chars = num_chars
# 1.3 文档数据中词的数量, 不去重.
self.word_count = len(self.corpus_idx)
# 1.4 句子数量
self.number = self.word_count // self.num_chars
# 2. 当使用 len(obj)时, 自动调用此方法.
def __len__(self):
# 返回句子数量
return self.number
# 3. 当使用 obj[index]时, 自动调用此方法.
def __getitem__(self, idx):
# idx: 指的是词的索引, 并将其修正索引值 到 文档的范围里边.
# 3.1 确保索引start在合法范围内, 避免越界, start: 当前样本的起始索引.
start = min(max(idx, 0), self.word_count - self.num_chars - 1)
# 3.2 计算当前样本的结束索引.
end = start + self.num_chars
# 3.3 输入值, 从文档中取出 start ~ end 的索引的词 -> 作为 x
x = self.corpus_idx[start:end]
# 3.4 输出值, 网络预测结果.
y = self.corpus_idx[start + 1:end + 1]
# 3.5 返回输入值和输出值 -> 张量形式.
return torch.tensor(x), torch.tensor(y)
# 3. 搭建RNN神经网络.
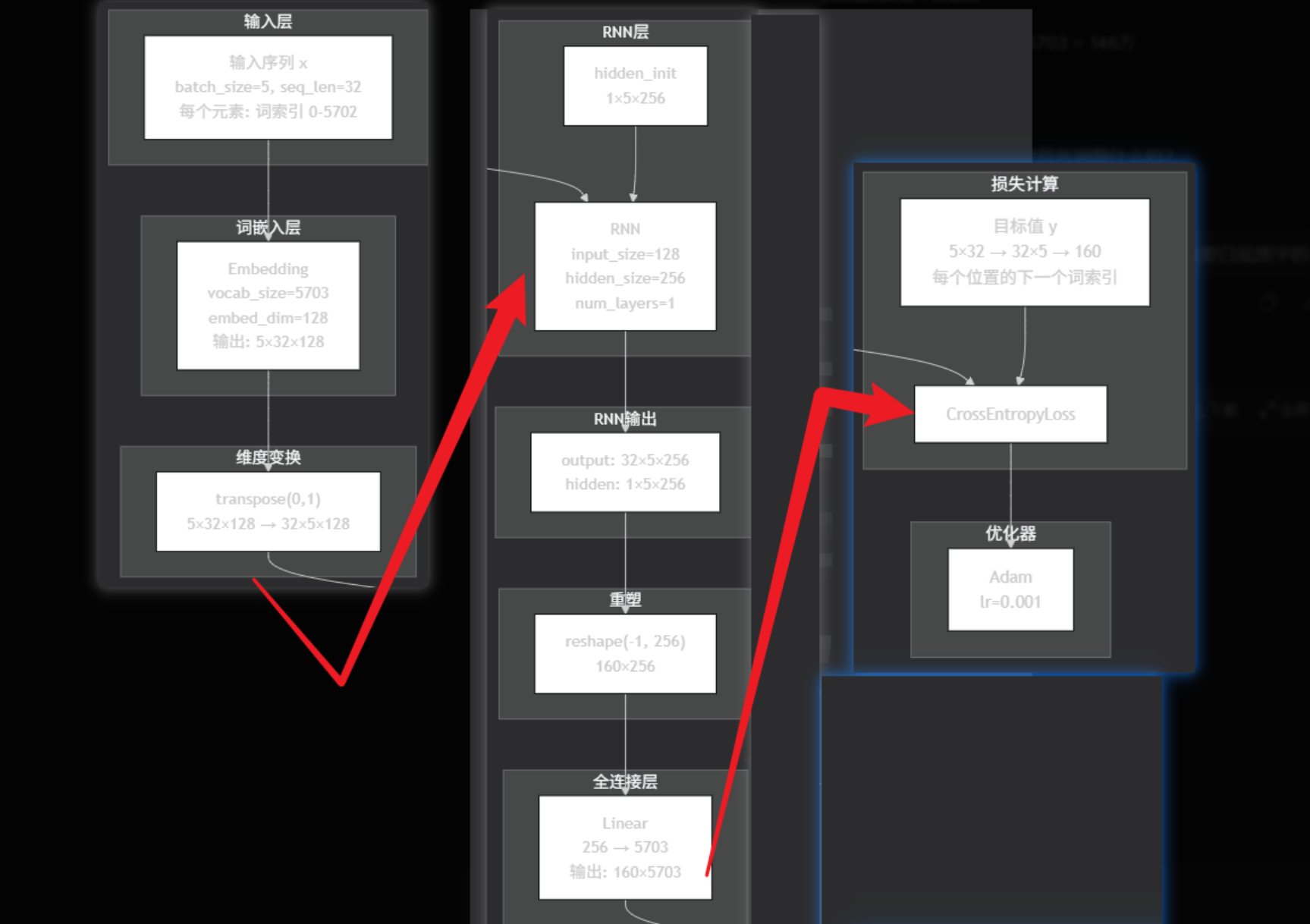
class TextGenerator(nn.Module):
# 1. 初始化方法
def __init__(self, unique_word_count): # unique_word_count: 去重的词的数量(5703)
# 1.1 初始化父类的成员.
super().__init__()
# 1.2 初始化词嵌入层: 语料中词的数量, 词向量的维度.
self.ebd = nn.Embedding(unique_word_count, 128)
# 1.3 循环网络层: 词向量维度, 隐藏层维度: 256, 网络层数: 1
self.rnn = nn.RNN(128, 256, 1)
# 1.4 输出层(全连接层): 特征向量维度(和隐藏向量维度一致), 词表中词的个数.
self.out = nn.Linear(256, unique_word_count) # 词表中每个词的概率 -> 选概率最大的哪个词作为 预测结果.
# 2. 前向传播方法
def forward(self, inputs, hidden):
# 2.1 初始化 词嵌入层处理.
# embd格式: (batch句子的数量, 句子的长度, 词向量维度)
embd = self.ebd(inputs)
# print(f'embd.shape: {embd.shape}')
# 2.2 rnn处理
# rnn格式: (句子的长度, batch句子的数量, 隐藏层维度)
output, hidden = self.rnn(embd.transpose(0, 1), hidden)
# 2.3 全连接, 输入内容必须是二维数据, 即: 词的数量 * 词的维度
# 输入维度: (seq_len句子数量 * batch, 词向量维度256)
# 输出维度: (seq_len句子数量 * batch, 词表中词的个数)
output = self.out(output.reshape(shape=(-1, output.shape[-1])))
# 2.4 返回结果, 预测结果, 隐藏层.
return output, hidden
# 3. 隐藏层的初始化方法.
def init_hidden(self, bs): # batch_size
# 隐藏层初始化: [网络层数, batch, 隐藏层向量维度]
return torch.zeros(1, bs, 256)
# 4. 训练模型.
def train():
# 1. 构建词典.
unique_words, word_to_index, unique_word_count, corpus_idx = build_vocab()
# 2. 获取数据集.
lyrics = LyricsDataset(corpus_idx, 32)
# 3. 初始化(神经网络)模型
model = TextGenerator(unique_word_count) # 预测5703个词, 每个词的概率.
# 4. 创建数据加载器对象.
# 参1: 数据集对象. 参2: 样本数 每批5个句子(样本), 每个句子(样本)32个词 参3: 是否打乱数据.
lyrics_dataloader = DataLoader(lyrics, batch_size=5, shuffle=True)
# 5. 定义损失函数
criterion = nn.CrossEntropyLoss()
# 6. 定义优化器.
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 7. 模型训练.
# 7.1 定义变量, 记录训练的轮数.
epochs = 50
# 7.2 具体的每轮训练动作.
for epoch in range(epochs): # epoch: 0, 1, 2, 3...9, 分别表示: 第1轮, 第2轮, ... 第10轮.
# 7.3 定义变量记录: 本轮开始训练时间, 迭代(批次)次数, 训练总损失.
start, iter_num, total_loss = time.time(), 0, 0.0
# 7.4 具体的 本轮 各批次 训练动作.
# 遍历数据集, 后台会调用 LyricsDataset#__getitem__()方法, 获取到每个样本的数据和标签,
for x, y in lyrics_dataloader:
# 7.5 获取隐藏层初始值.
hidden = model.init_hidden(5)
# 7.6 模型计算.
output, hidden = model(x, hidden)
# 7.7 计算损失.
# y的形状: (batch 批次数, seq_len 句子长度, 词向量维度) -> 转成一维向量 -> 每个词的下标索引.
# output形状为: (seq_len, batch, 词向量维度)
y = torch.transpose(y, 0, 1).reshape(shape=(-1, ))
loss = criterion(output, y)
# 7.8 梯度清零 + 反向传播 + 更新参数.
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 7.9 累计损失 和 迭代次数.
total_loss += loss.item()
iter_num += 1
# 7.10 走到这里, 说明 本轮训练结束, 打印本轮的训练信息.
print(f'epoch: {epoch + 1}, time: {time.time() - start:.2f}s, loss: {total_loss / iter_num:.4f}')
# 8. 走到这里, 说明多轮训练结束(模型训练结束), 保存即可.
torch.save(model.state_dict(), './model/text_generator.pth')
# 5. 模型预测.
def evaluate(start_word, sentence_length):
# 1. 构建词典.
unique_words, word_to_index, unique_word_count, corpus_idx = build_vocab()
# 2. 获取模型.
model = TextGenerator(unique_word_count)
# 3. 加载模型参数.
model.load_state_dict(torch.load('./model/text_generator.pth'))
# 4. 获取隐藏层初始值.
hidden = model.init_hidden(1)
# 5. 将输入的 开始词 转换成 索引.
word_idx = word_to_index[start_word]
# 6. 定义列表, 存放: 产生的词的索引.
generate_sentence = [word_idx] # 开始词的索引, 是列表的: 第1个值.
# 7. 遍历句子长度, 获取到每一个词.
for i in range(sentence_length):
# 7.1 模型预测.
output, hidden = model(torch.tensor([[word_idx]]), hidden)
# 7.2 获取预测结果. argmax() 从所有结果(5703个词的概率)中, 找最大值对应的索引.
word_idx = torch.argmax(output)
# 7.3 把预测结果添加到列表中.
generate_sentence.append(word_idx)
# 8. 将索引转成词, 并打印.
for idx in generate_sentence:
print(unique_words[idx], end='')
# 6. 测试
if __name__ == '__main__':
# 1. 获取数据, 进行分词, 获取词表.
# unique_words, word_to_index, word_count, corpus_idx = build_vocab()
# print(f'词的数量: {word_count}') # 去重后, 5703个词
# print(f'去重后的词: {unique_words}') # ['想要', '有', '直升机', '\n', '和', '你'...'冠军', '要大卖']
# print(f'每个词的索引: {word_to_index}') # 词表: {'想要': 0, '有': 1, '直升机': 2, '\n': 3, '和': 4, '你': 5, ... '冠军': 5701, '要大卖': 5702}
# print(f'文档中每个词对应的索引: {corpus_idx}') # [0, 1, 2, 1 3, 40, 0, 4, 5, 6, 7, 8, 3, 40, 0, 4, 5, 9, 10, 11, 3, 40,......]
# 2. 构建数据集
# dataset = LyricsDataset(corpus_idx, 5)
# print(f'句子数量: {len(dataset)}')
# # 查看下 输入值 和 目标值.
# x, y = dataset[1]
# print(f'输入值: {x}') # [0, 1, 2, 3, 40] [1, 2, 3, 40, 0]
# print(f'目标值: {y}') # [1, 2, 3, 40, 0] [2, 3, 40, 0, 4]
# 3. 创建模型对象.
# model = TextGenerator(word_count)
# # 查看参数.
# for name, parameter in model.named_parameters():
# print(f'参数名称: {name}, 参数维度: {parameter.shape}')
# 4. 训练(并保存)模型.
# train()
# 5. 测试模型.
evaluate('星星', 50)架构图
五、关键知识点总结 📝
| 组件 | 作用 | 维度变化 |
|---|---|---|
| 词嵌入层 | 词 → 向量 | (词数) → (词数, 向量维度) |
| RNN层 | 捕捉时序依赖 | (seq_len, batch, embed_dim) → (seq_len, batch, hidden_size) |
| 全连接层 | 分类输出 | (hidden_size) → (vocab_size) |
注意事项
-
隐藏状态初始化:第一个时间步的隐藏状态通常初始化为0
-
损失函数:文本生成是多分类问题,使用交叉熵损失
-
维度匹配:各层之间的维度传递要确保正确
-
预测策略:除了贪心搜索,还可以考虑beam search等更优策略
六、扩展思考 💭
-
RNN的局限性:长序列时存在梯度消失/爆炸问题
-
改进方案:LSTM、GRU等变体
-
应用升级:注意力机制、Transformer架构
-
实际优化:增加dropout、使用预训练词向量等
以上就是RNN的核心知识笔记,从基础概念到代码实现,希望能帮助大家快速上手循环神经网络!如有问题,欢迎交流讨论~ 🚀

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 22
22 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)