即插即用系列 | CVPR 2024 MobileNetV4王者归来!倒残差模块(UIB)+移动注意力(Mobile) MQA打造全平台
论文名称:MobileNetV4: Universal Models for the Mobile Ecosystem
论文原文 (Paper):https://arxiv.org/abs/2404.10518
代码 (code):https://github.com/tensorflow/models/blob/master/official/vision/modeling/backbones/mobilenet.py
哔哩哔哩视频讲解:https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
本论文的完整复现代码(即插即用版)已更新至专栏
即插即用系列(代码实践) | CVPR 2024 MobileNetV4王者归来!倒残差模块(UIB)+移动注意力(Mobile) MQA打造全平台
目录
1. 核心思想
本文推出了 MobileNet 系列的最新一代——MobileNetV4 (MNv4),旨在解决移动端模型在不同硬件(CPU、DSP、GPU、NPU)上性能不一致的难题。论文提出了一种通用倒残差模块(UIB)和针对移动端加速器优化的Mobile MQA注意力机制,并结合改进的**两阶段 NAS(神经架构搜索)策略,设计出了一系列在各种硬件平台上均能达到帕累托最优(Pareto Optimal)的模型。此外,作者还利用Roofline Model(屋顶线模型)**从理论层面分析了不同硬件的计算与访存瓶颈,指导了网络架构的设计方向。
2. 背景与动机
文本背景分析
在移动端模型设计领域,长期存在一个痛点:硬件碎片化导致的效率割裂。
- MobileNetV3 在 CPU 上表现优异,但在 DSP 和 EdgeTPU 等加速器上却因为缺乏并行性而性能不佳。
- MobileOne/FastViT 等针对特定硬件(如 GPU 或 Apple Neural Engine)优化的模型,一旦部署到通用 CPU 上,延迟往往很高。
现有的高效网络往往只能在某一类特定的硬件上实现“高效”,缺乏一种**通用(Universal)**的架构能够同时适应 CPU、GPU、DSP 和专用加速器。本文的动机就是打破这种“顾此失彼”的局面,设计一种在整个移动生态系统中都能实现高效推理的通用模型。
动机图解分析
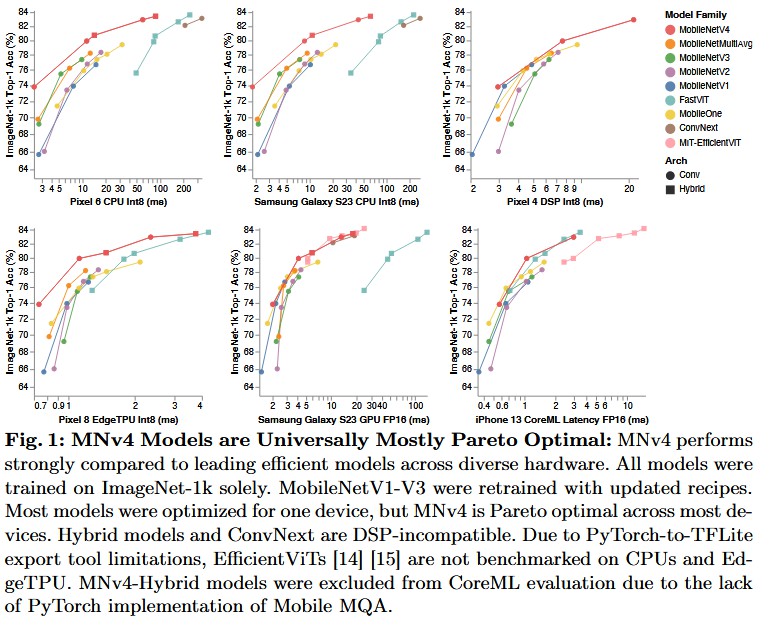
图解分析:
- 图表含义:图 1 展示了不同模型家族(不同颜色曲线)在不同硬件平台(六个子图:Pixel 6 CPU, S23 CPU, Pixel 4 DSP, EdgeTPU, S23 GPU, iPhone CoreML)上的 ImageNet 准确率与延迟的折线图。越靠近左上角的曲线意味着性价比(准确率/延迟)越高。
- 现有方法的局限性:
- 观察绿色曲线(MobileNetV3):在 CPU 子图(上排前两张)中表现尚可,但在 DSP 和 EdgeTPU(下排第一张)中明显落后,曲线偏右下。
- 观察黄色曲线(MobileOne)和青色曲线(FastViT):它们在特定的 GPU 或 CoreML 环境下表现不错,但在 CPU 上延迟极高。
- 本文的突破:
- 红色曲线(MobileNetV4):请注意红色曲线在所有六个子图中,始终处于最左上角或紧贴帕累托前沿。这直观地证明了 MNv4 并非针对单一硬件过拟合,而是真正实现了“通用性”。
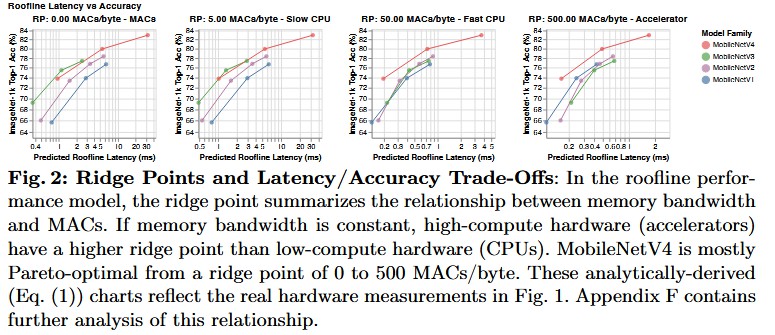
图解分析:
- 图表含义:为了解释图 1 的现象,作者引入了 Roofline Model 的理论分析。图 2 展示了不同Ridge Point (RP) 下的性能表现。RP 代表硬件的计算密度(MACs/Byte),即峰值算力与峰值带宽之比。
- 低 RP(左侧子图):代表 CPU 等带宽受限较小的通用硬件,此时计算量(MACs)是主要瓶颈。
- 高 RP(右侧子图):代表 DSP/加速器等高算力硬件,此时内存带宽(Data Movement)是主要瓶颈。
- 核心问题引出:现有模型往往只针对某一特定的 RP 范围进行优化。MNv4 通过平衡计算密集型算子(Conv2D)和访存密集型算子(DW-Conv/FC),使其在从 0 到 500 MACs/Byte 的宽广 RP 范围内都能保持最优。
3. 主要创新点
- 通用倒残差模块 (Universal Inverted Bottleneck, UIB):提出了一种高度灵活的搜索模块,统一了 IB、ConvNeXt、FFN 等多种经典结构,并引入了 ExtraDW 变体。
- Mobile MQA (Mobile Multi-Query Attention):针对移动端加速器优化的注意力机制,通过共享 Key-Value 头和 Einsum 优化,在几乎不损失精度的情况下实现了 39% 的推理加速。
- 基于 Roofline 的性能建模:利用理论模型指导设计,避免了仅依赖 FLOPs 或特定设备延迟造成的偏差,确保了跨平台的通用性。
- 改进的 NAS 策略:引入两阶段搜索(先粗粒度搜宏观结构,再细粒度搜 UIB 内部配置)和 JFT 数据集蒸馏,大幅提升了搜索效率和模型质量。
4. 方法细节
整体网络架构
MNv4 的整体架构是通过 NAS 搜索得到的,遵循了经典的层级式设计。
- 输入 (Input):标准 RGB 图像。
- 早期阶段 (Early Stages):
- 设计理念:在分辨率较高的初期,使用计算密度高的标准卷积(Conv2D)或 UIB 中的 ExtraDW 模式。这是因为在低 RP 硬件(CPU)上,大计算量的初始层能显著提升容量;而在高 RP 硬件(加速器)上,这些层通常受限于计算而非访存,因此不会成为瓶颈。
- 数据流:Stem 层 -> 下采样 -> 特征提取。
- 中期阶段 (Middle Stages):
- 核心组件:由 NAS 搜索出的各种 UIB Block 堆叠而成。
- 连接方式:采用残差连接(Residual Connection)贯穿各个 Block,确保梯度流通。
- 后期阶段 (Late Stages):
- 特征融合:对于 Hybrid 版本(MNv4-Hybrid),在特征图较小的最后阶段引入 Mobile MQA 模块。此时 Token 数量较少,使用 Attention 性价比最高。
- 输出头:全局平均池化 -> 全连接层(FC)-> Softmax 输出。NAS 发现全连接层在 DSP 等加速器上是访存瓶颈,但在 CPU 上很快,因此 MNv4 统一了头部设计以平衡各端性能。
核心创新模块详解
1. 通用倒残差模块 (Universal Inverted Bottleneck, UIB)
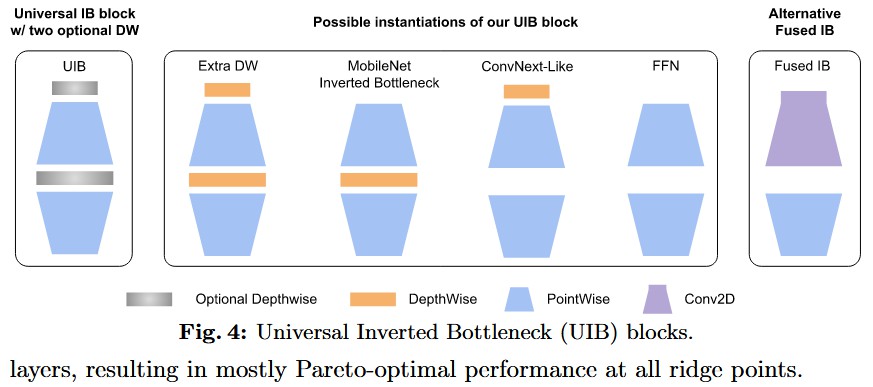
-
结构拆解:
UIB 是对 MobileNetV2 中经典的 Inverted Bottleneck (IB) 的扩展。它的核心在于引入了两个可选的深度卷积(Optional Depthwise Conv)。- DW1 (Start):位于扩张(Expansion)之前。
- Expansion:1x1 卷积,提升通道数。
- DW2 (Middle):位于扩张之后(经典 IB 的位置)。
- Projection:1x1 卷积,降低通道数。
-
变体与工作机制:通过 NAS 选择是否启用 DW1 和 DW2,UIB 可以实例化为四种形态:
- Inverted Bottleneck (IB):仅启用 DW2。这是经典的 MobileNetV2 结构,在扩张后的高维特征上做空间混合。
- ConvNeXt-Like:仅启用 DW1。类似于 ConvNeXt 的设计,在扩张前用大核做空间混合,成本更低。
- ExtraDW:启用 DW1 和 DW2。这是一种新颖的设计,允许在增加网络深度和感受野的同时,保持较低的参数量。
- FFN:DW1 和 DW2 都不启用。此时退化为两个 1x1 卷积的堆叠(Feed Forward Network),常见于 Transformer 或作为纯通道混合层。
2. Mobile MQA (Mobile Multi-Query Attention)
- 设计背景:标准的 MHSA(多头自注意力)在移动端主要受限于访存带宽而非计算量。
- 模块拆解:
- Multi-Query Attention (MQA):不同于 MHSA 每个头都有独立的 Query, Key, Value,MQA 让所有 Query 头共享同一组 Key 和 Value。这极大地减少了 KV Cache 的读取量,大幅提升了计算密度(Operational Intensity)。
- Einsum 优化:论文指出现有的 MQA 实现中包含大量的
Transpose和Reshape操作,这些无计算的操作在移动端加速器上非常耗时。Mobile MQA 通过重写 Einsum 公式,将内存布局调整与矩阵乘法融合,移除了显式的 Transpose 操作。
- 数据流:输入 X -> 投影得到 Q, K, V (K, V 共享头) -> Einsum 计算 Attention Score -> Softmax -> 加权求和 -> 输出投影。
理念与机制总结
MNv4 的核心理念是**“基于屋顶线模型的成本平衡”**。
作者观察到,不同硬件的瓶颈不同:CPU 怕计算量大(MACs),加速器怕数据搬运多(Memory Access)。
- UIB 的作用:通过搜索,网络可以在需要大感受野的地方使用 ExtraDW(增加 MACs 但减少层数),在需要通道融合的地方使用 FFN(增加访存但计算简单),从而在不同层级动态调整计算与访存的比例。
- Mobile MQA 的作用:在低分辨率层,计算不再是主要矛盾,利用 MQA 获取全局视野,同时通过共享 KV 减少访存压力,完美契合加速器的高算力低带宽特性。
图解总结
整个设计就像一个精密的拼图:NAS 算法作为“拼图者”,依据 Roofline Model 这一“指导图纸”,从 UIB 和 Mobile MQA 这两个“积木盒”中挑选最合适的组件,拼出了在 CPU(低 MACs 优先)和 NPU(低访存优先)上都能跑得快的 MobileNetV4。
5. 即插即用模块的作用
本论文提出的模块具有极高的通用性,可应用于以下场景:
- UIB Block (通用倒残差块):
- 场景:任何轻量级 CNN 的设计或改进。
- 应用:可以替换现有的 MobileNetV2/V3 或 ResNet 中的基础 Block。如果在 NAS 搜索空间中使用 UIB,可以自动发现比人工设计更优的结构组合。
- Mobile MQA (移动端 MQA):
- 场景:移动端 Vision Transformer (ViT) 或混合架构。
- 应用:可直接替换标准 ViT 或 EdgeNeXt 中的 MHSA 模块。特别是在部署到 EdgeTPU、DSP 或高通 NPU 时,能显著降低推理延迟(论文数据:加速 39%)。
- 蒸馏方案 (Distillation Recipe):
- 场景:小模型的训练。
- 应用:论文提出的“动态数据集混合”和“JFT 数据增强”策略,可以作为通用的 Training Trick,用于提升任何轻量级模型的最终精度。
6. 论文实验部分对比分析
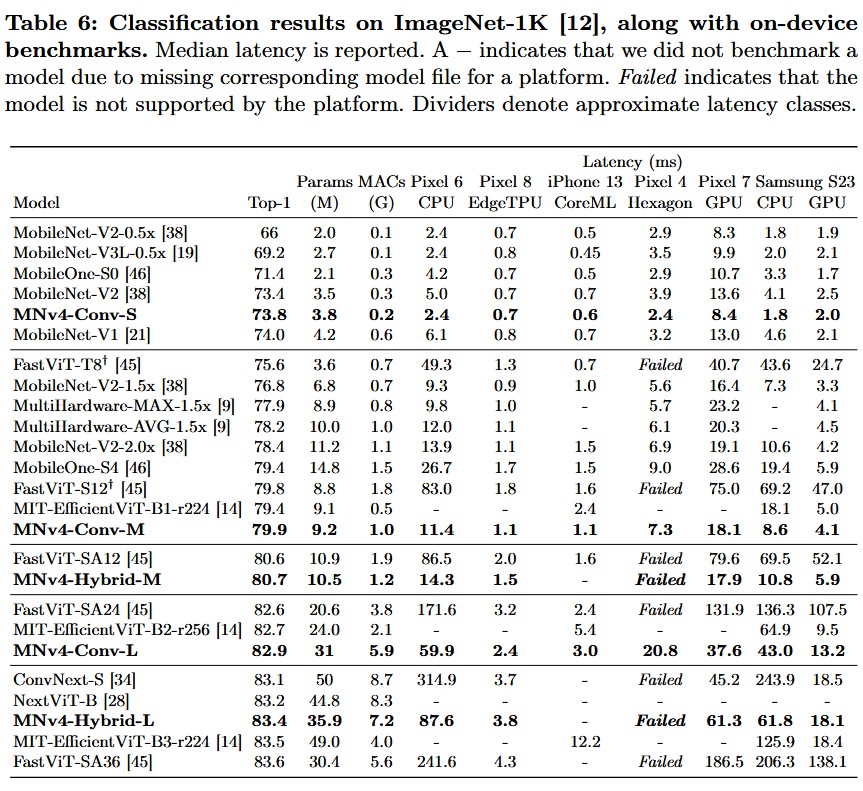
-
与 MobileNetV3 对比:
- 在 CPU 上,MNv4 相比 MNv3 并没有巨大的延迟优势(因为 MNv3 已经对 CPU 极致优化),但在精度上显著提升。
- 关键点:在 EdgeTPU 和 DSP 上,MNv4 的速度是 MNv3 的 2倍 以上。这直接解决了 MNv3 跨平台性能差的问题。
-
与 EfficientViT / FastViT 对比:
- FastViT 在 Apple Neural Engine 上很快,但在 Android CPU/GPU 上较慢。
- MNv4 在保持与它们相当甚至更高精度的同时,在所有测试设备上都保持了第一梯队的推理速度,没有短板。
-
ImageNet 结果:
- MNv4-Conv-S:3.8M 参数,73.8% Top-1,在 Pixel 6 CPU 上仅需 2.4ms。
- MNv4-Hybrid-L:利用蒸馏技术达到了 87.0% 的 Top-1 准确率,且在 Pixel 8 EdgeTPU 上延迟仅为 3.8ms。这是一个非常惊人的 SOTA 结果,打破了轻量级模型精度的天花板。
-
目标检测 (COCO):
- MNv4 作为 Backbone 在 RetinaNet 上,相比 MobileNetV2 和 MobileNetMultiAvg,在保持更低延迟的同时实现了更高的 mAP (+1.6%)。
到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。
6. 获取即插即用代码关注 【AI即插即用】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)