AI 基础知识十 Transformer模型架构和位置编码
论文
Transformer模型架构是由谷歌大脑团队在2017年提出,论文Attention is All You Need 其核心思想是提出了一种完全靠 “注意力机制” 工作的神经网络,替代循环神经网络和卷积神经网络。
简单总结论文内容:
在做翻译、文本处理时,大多靠循环网络一步步处理数据,慢还难并行,Transformer 靠注意力机制,能同时处理整个序列,训练速度快很多,还能捕捉长距离的语义关联。
Transformer没有循环结构,模型不知道单词的顺序,所以加了 “位置编码”,用正弦余弦函数给每个位置的单词加个 “位置标签”,让模型知道谁在前谁在后。
注意力机制 就像人看书时会同时关注不同重点,模型会分成多个 “注意力头”,各自关注序列里不同位置的信息,再把结果整合,能更全面地理解数据。
实验效果: 在英德、英法翻译任务上,比当时最好的模型效果还好,训练时间却短很多(比如英法翻译用 8 块 GPU 训 3.5 天就达到新纪录),还能用到其他任务,比如英语语法分析,就算训练数据不多也能有好效果。
用注意力机制替代传统循环 / 卷积,让模型又快又强,不仅能做好翻译,还能适配多种文本处理任务,后来成了大语言模型的核心基础。
总结一下"注意力机制" 就像作阅读理解,先看问题,带着问题去阅读,重点关注与问题相关的上下文内容,并找出答案。
Transformer模型架构
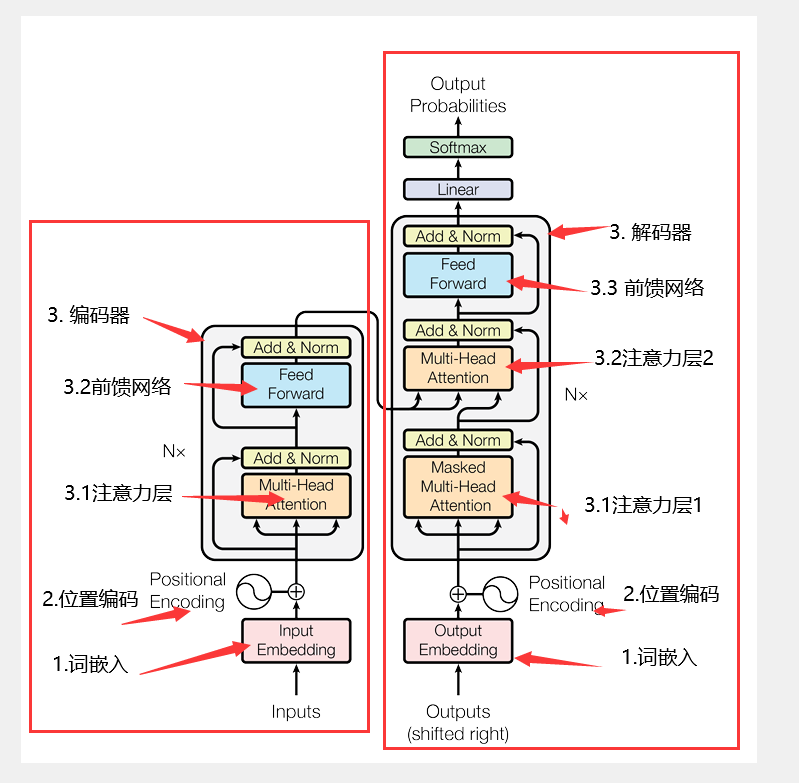
上图Transformer结构先把重复的部份删除,列举一下主要结构组件:
1. input/output Embedding 词嵌入
2. Positional Encoding 位置编码
3. Multi-Head/Masked-Multi-Head Attention 注意力层
4. Add & norm 残差结构,归一化层
5. Feed Forward 前馈网络
6. linear 全连接层
7. Softmax 逻辑回归函数
按流程先后顺序 左边是编码器,输入文本经过
1. “词嵌入”
2. “位置编码”,送入“编码器”中
3. 编码器内部
3.1 注意力机制
3.2 “残差网络和归一化(Add & Norm)
3.3 前馈网络
3.4 残差网络和归一化(Add & Norm)
4. 将结果送到解码器
右边是解码器,输入文本经过
1. “词嵌入”
2. “位置编码”,送入“解码器”中
3. 解码器内部
3.1 掩码注意力机制
3.2 残差网络和归一化(Add & Norm)
3.3 同编码器输出结果 引用 注意力机制
3.4 残差网络和归一化(Add & Norm)
3.5 前馈网络 和 残差网络和归一化(Add & Norm)
4. 全连接层 和 Softmax 输出结果
Transformer 可以同时有多个编码器 和 解码器,默认有6个编码器和6个解码器,
libtorch库提供强大功能让人工智能研究工作变得容易很多,libtorch-Transformer 模型 本身内置没有词嵌入(已经讲过) 和 位置编码这两个模块,必须手动实现。
位置编码
位置编码公式

重点看计算公式 假设PE是个4X4的张量
int main()
{
int d_model = 4;
auto PE = torch::zeros({ d_model,d_model}, torch::kFloat32);
/* 运行结果
0 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0
[ CPULongType{4,4} ]
*/
}用公式对位置进行编码
编码运算结果
sin(0): 0
cos(0): 1
0.0000 1.0000 0.0000 1.0000
0.8415 0.5403 0.0100 0.9999
0.9093 -0.4161 0.0200 0.9998
0.1411 -0.9900 0.0300 0.9996
[ CPUFloatType{4,4} ]
公式简单记忆:
pos是行下标
i是列下标
偶数维度 用 sin()
奇数维度 用 cos()
数恒等式推导过程
对应 pow(10000,
),官方推荐用exp
1. pow 在负数/小数指数时不稳定,在浮点数计算中容易数值爆炸/下溢
2. exp 是硬件原生指令,速度快很多
指数转对数恒等式:对任意正数 x,有 (e 是自然常数,ln 是自然对数)
例: 2=,
对数的幂法则:
例:
等式推导过程:
拆分分母的幂运算
exp替换pow运算
libtorch实现代码
用"torch::indexing::Slice()"对两维张量进行切片
int d_model = 4;
auto PE = torch::zeros({ d_model,d_model}, torch::kFloat32);
auto pos = torch::arange(0, d_model, torch::kFloat32).reshape({ d_model, 1 });
std::cout<<"pos: "<< std::endl << pos << std::endl << std::endl;
auto i = torch::arange(0, d_model, 2, torch::kFloat32);
std::cout <<"2*i: "<<std::endl << i << std::endl << std::endl;
auto den = torch::exp(-i * std::log(10000.0f) / d_model);
PE.index_put_({ torch::indexing::Slice(), torch::indexing::Slice(0, d_model, 2) }, torch::sin(pos * den));
PE.index_put_({ torch::indexing::Slice(), torch::indexing::Slice(1, d_model, 2) }, torch::cos(pos * den));
std::cout << "sin(0): " << sin(0) << std::endl;
std::cout << "cos(0): " << cos(0) << std::endl << std::endl;
std::cout << PE << std::endl;
/* 运行结果
pos:
0
1
2
3
[ CPUFloatType{4,1} ]
2*i:
0
2
[ CPUFloatType{2} ]
sin(0): 0
cos(0): 1
0.0000 1.0000 0.0000 1.0000
0.8415 0.5403 0.0100 0.9999
0.9093 -0.4161 0.0200 0.9998
0.1411 -0.9900 0.0300 0.9996
[ CPUFloatType{4,4} ]
*/感谢大家的支持,如要问题欢迎提问指正。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)