探索沙丘猫群优化算法 - GRNN(SCSO - GRNN)的奇妙世界
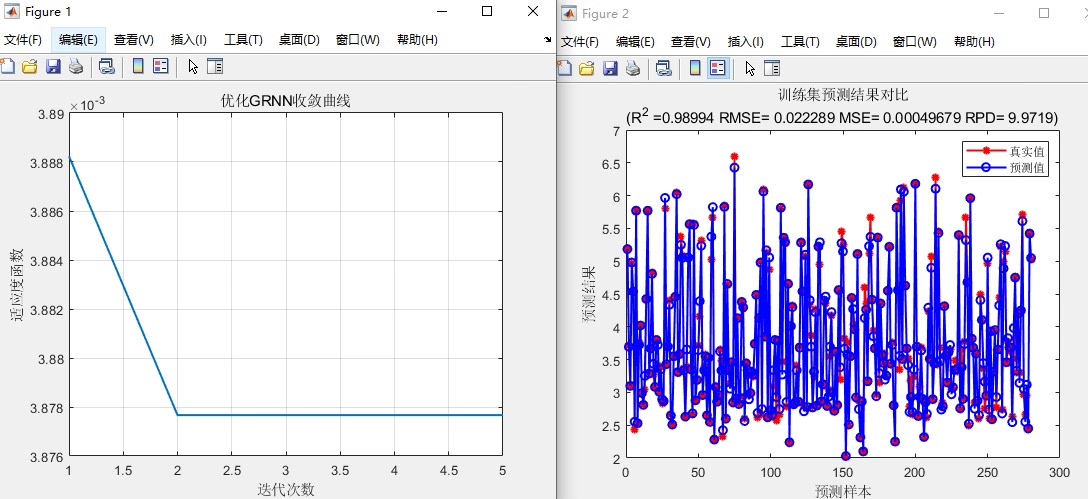
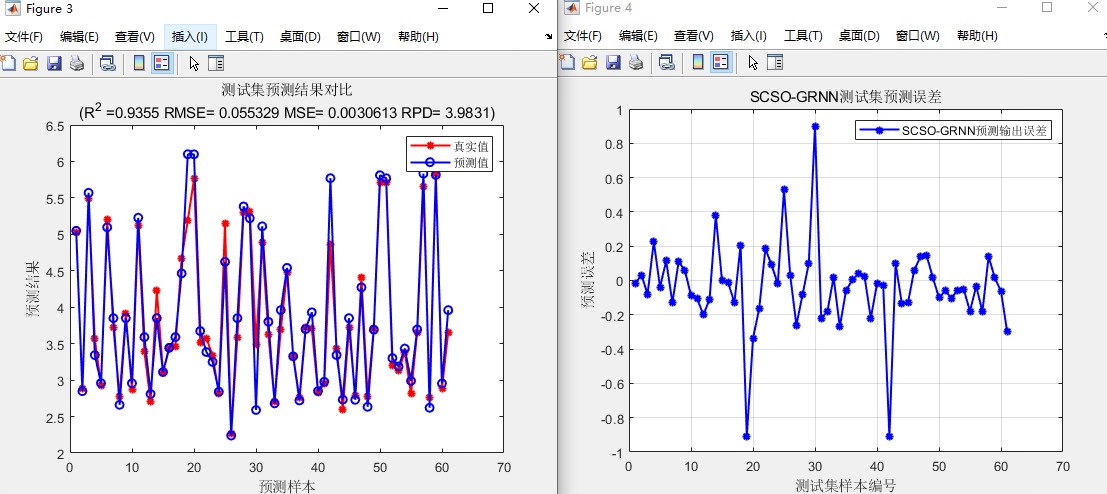
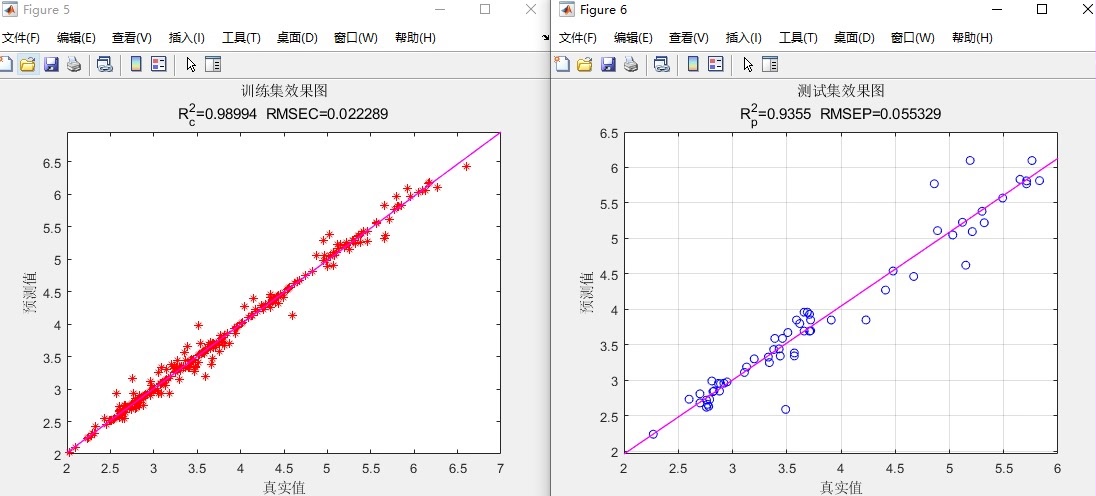
基于沙丘猫群优化算法-GRNN。 (SCSO-GRNN) 效果如下,代码注释详细,可移植性强,可自行更换excel数据,跑自己模型。
在数据建模与预测的领域中,不断涌现的新算法为我们提供了更高效、准确的解决方案。今天,咱们就来唠唠基于沙丘猫群优化算法 - GRNN(SCSO - GRNN),这组合可谓是独具特色,效果那也是杠杠滴,而且代码注释详细,可移植性强,还能轻松换上自己的 excel 数据,跑起属于自己的模型。
一、沙丘猫群优化算法(SCSO)
沙丘猫,生活在沙漠中的神秘猎手,它们独特的狩猎行为给了科学家们灵感,从而诞生了沙丘猫群优化算法。该算法模拟了沙丘猫在沙漠环境中的觅食、栖息等行为。
简单来说,沙丘猫们在沙漠中寻找食物(也就是最优解),每只沙丘猫都有自己的位置(对应解空间中的一个点)和速度(移动方向和步长)。它们会根据自己的经验(自身历史最优位置)和群体的经验(全局最优位置)来调整自己的移动方向和步长。
基于沙丘猫群优化算法-GRNN。 (SCSO-GRNN) 效果如下,代码注释详细,可移植性强,可自行更换excel数据,跑自己模型。
以下是一段简化的 SCSO 算法核心代码示例(以 Python 为例):
import numpy as np
# 初始化沙丘猫位置和速度
def initialize_positions(n_cats, dim, bounds):
positions = np.zeros((n_cats, dim))
for i in range(n_cats):
for j in range(dim):
positions[i, j] = np.random.uniform(bounds[0][j], bounds[1][j])
velocities = np.zeros((n_cats, dim))
return positions, velocities
# 更新沙丘猫位置和速度
def update_positions_velocities(positions, velocities, pbest_positions, gbest_position, w, c1, c2, bounds):
r1 = np.random.rand(*positions.shape)
r2 = np.random.rand(*positions.shape)
velocities = w * velocities + c1 * r1 * (pbest_positions - positions) + c2 * r2 * (gbest_position - positions)
positions = positions + velocities
for i in range(positions.shape[0]):
for j in range(positions.shape[1]):
if positions[i, j] < bounds[0][j]:
positions[i, j] = bounds[0][j]
elif positions[i, j] > bounds[1][j]:
positions[i, j] = bounds[1][j]
return positions, velocities代码分析
initialize_positions函数:
- 它负责初始化沙丘猫的位置和速度。这里通过np.random.uniform在给定的边界范围内随机生成每只沙丘猫的初始位置。每只沙丘猫的位置是一个在解空间维度dim上的向量。速度则初始化为全零向量,因为刚开始沙丘猫还没有移动方向和步长。updatepositionsvelocities函数:
- 此函数用于更新沙丘猫的位置和速度。w是惯性权重,它控制着沙丘猫保留先前速度的程度,类似于一种 “惯性”。c1和c2是学习因子,分别表示沙丘猫向自身历史最优位置(pbestpositions)和全局最优位置(gbestposition)学习的程度。r1和r2是在 0 到 1 之间的随机数,增加了算法的随机性和搜索能力。
- 先计算出新的速度,然后根据新速度更新位置。最后,通过边界检查,确保沙丘猫的位置始终在合法的解空间范围内。
二、广义回归神经网络(GRNN)
GRNN 是一种基于径向基函数的神经网络,它在函数逼近、时间序列预测等方面表现出色。GRNN 的结构相对简单,由输入层、模式层、求和层和输出层组成。
以下是一个简单的 GRNN 代码示例(使用 Python 的 scikit - learn 库中的 neighbors.KernelDensity 来近似实现):
from sklearn.neighbors import KernelDensity
import numpy as np
# 训练 GRNN
def train_grnn(X, y):
kde = KernelDensity(kernel='gaussian', bandwidth=0.2).fit(X)
return kde
# 预测
def predict_grnn(kde, X_test):
log_dens = kde.score_samples(X_test)
y_pred = np.exp(log_dens)
return y_pred代码分析
train_grnn函数:
- 这里使用KernelDensity来训练 GRNN。选择'gaussian'核函数,带宽bandwidth设置为 0.2。带宽的选择很关键,它决定了核函数的平滑程度,对预测结果有较大影响。训练时将输入数据X传入fit方法进行模型训练。predictgrnn函数:
- 利用训练好的kde模型对测试数据Xtest进行预测。scoresamples方法返回样本的对数似然估计,通过np.exp转换为概率密度估计值,即得到预测结果ypred。
三、SCSO - GRNN 的结合
将 SCSO 和 GRNN 结合起来,就是利用 SCSO 的寻优能力来优化 GRNN 的参数(比如带宽等),从而提升 GRNN 的性能。
# SCSO - GRNN 结合
def scso_grnn(X_train, y_train, X_test, n_cats, dim, bounds, max_iter, w, c1, c2):
best_bandwidth = None
best_score = float('inf')
positions, velocities = initialize_positions(n_cats, dim, bounds)
pbest_positions = positions.copy()
pbest_scores = np.array([float('inf')] * n_cats)
gbest_position = None
gbest_score = float('inf')
for t in range(max_iter):
for i in range(n_cats):
bandwidth = positions[i, 0]
kde = KernelDensity(kernel='gaussian', bandwidth=bandwidth).fit(X_train)
log_dens = kde.score_samples(X_train)
loss = -np.mean(log_dens)
if loss < pbest_scores[i]:
pbest_scores[i] = loss
pbest_positions[i] = positions[i]
if loss < gbest_score:
gbest_score = loss
gbest_position = positions[i]
best_bandwidth = bandwidth
positions, velocities = update_positions_velocities(positions, velocities, pbest_positions, gbest_position, w, c1, c2, bounds)
final_kde = KernelDensity(kernel='gaussian', bandwidth=best_bandwidth).fit(X_train)
y_pred = predict_grnn(final_kde, X_test)
return y_pred代码分析
- 首先初始化一些变量,包括最优带宽
bestbandwidth、最优得分bestscore等。同时初始化沙丘猫的位置、速度、个体最优位置和得分,以及全局最优位置和得分。 - 在迭代过程中,每只沙丘猫对应的位置中的第一个维度值作为 GRNN 的带宽参数。根据这个带宽训练 GRNN 并计算在训练集上的损失。如果损失小于个体最优得分,则更新个体最优位置和得分;如果损失小于全局最优得分,则更新全局最优位置、得分和最优带宽。
- 每次迭代结束后,根据 SCSO 算法更新沙丘猫的位置和速度。
- 最后,利用找到的最优带宽训练最终的 GRNN 模型,并对测试数据进行预测,返回预测结果。
四、数据替换与模型运行
要使用自己的 excel 数据跑模型也很简单。假设数据格式为:第一列为自变量 1,第二列为自变量 2,最后一列为因变量。
import pandas as pd
# 读取数据
data = pd.read_excel('your_data.xlsx')
X = data.iloc[:, :-1].values
y = data.iloc[:, -1].values
# 划分训练集和测试集(简单示例,实际应用中可采用更复杂的划分方式)
split = int(len(X) * 0.8)
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
# 运行 SCSO - GRNN 模型
y_pred = scso_grnn(X_train, y_train, X_test, n_cats=10, dim=1, bounds=[[0.1], [1.0]], max_iter=50, w=0.7, c1=1.5, c2=1.5)代码分析
- 使用
pandas的read_excel函数读取 excel 数据。 - 将数据划分为自变量
X和因变量y,并简单地按照 80% 和 20% 的比例划分训练集和测试集。实际应用中,可以使用更科学的交叉验证等方式进行划分。 - 调用
scsogrnn函数,传入训练集、测试集数据以及 SCSO 算法的相关参数,运行模型并得到预测结果ypred。
基于沙丘猫群优化算法 - GRNN(SCSO - GRNN)为我们在数据建模和预测任务中提供了一种强大的工具。通过灵活运用它,相信能在不少实际项目中取得优异的成果。希望大家都能尝试跑一跑自己的数据,挖掘出数据背后更多的价值!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)