从 0 到 1!Qwen3.5 系列开源大模型本地部署全流程(ModelScope)
【本文作者:Troy】
1.Qwen
Qwen3.5是阿里云通义千问团队发布的新一代开源大模型系列,是提供基础智能能力的“大脑”。主要是作为基础模型,本身具备强大的文本生成、复杂推理、多模态理解(如图像、视频)和工具调用等能力。适用于希望直接使用高性能大模型,或将其作为基座进行二次开发的个人、研究者和企业。
可访问魔搭社区:https://www.modelscope.cn/models?name=qwen3.5&page=1&tabKey=task
Qwen3.5 具备以下增强特性:
- 统一的视觉-语言基础:在多模态 token 上进行早期融合训练,在推理、编码、智能体和视觉理解等基准测试中,跨代际表现与 Qwen3 持平,并优于 Qwen3-VL 模型。
- 高效混合架构:门控 Delta 网络与稀疏混合专家(Mixture-of-Experts)相结合,实现高吞吐推理,同时保持极低延迟和成本开销。
- 可扩展的强化学习泛化能力:在百万级智能体环境中进行强化学习训练,任务分布逐步复杂化,从而获得强大的现实世界适应能力。
- 全球语言覆盖:支持扩展至 201 种语言和方言,实现包容性的全球部署,并具备细致入微的文化与区域理解能力。
- 下一代训练基础设施:相比纯文本训练,多模态训练效率接近 100%,并采用异步强化学习框架,支持大规模智能体脚手架和环境编排。
文件名其中B代表billion,即十亿,指的是模型的参数量,例如:2B=参数量为20亿;一般来说,参数量越大的模型,其“记忆体”和“计算单元”越多,能够学习到的知识更丰富,处理复杂逻辑推理的能力也越强。参数量也直接决定了运行这个模型所需要的内存(显存)和存储空间。
考虑到本地个人电脑(无独显)硬件配置,此处选择【Qwen3.5-0.8B-GGUF】举例子,详情见:https://www.modelscope.cn/models/unsloth/Qwen3.5-0.8B-GGUF/summary
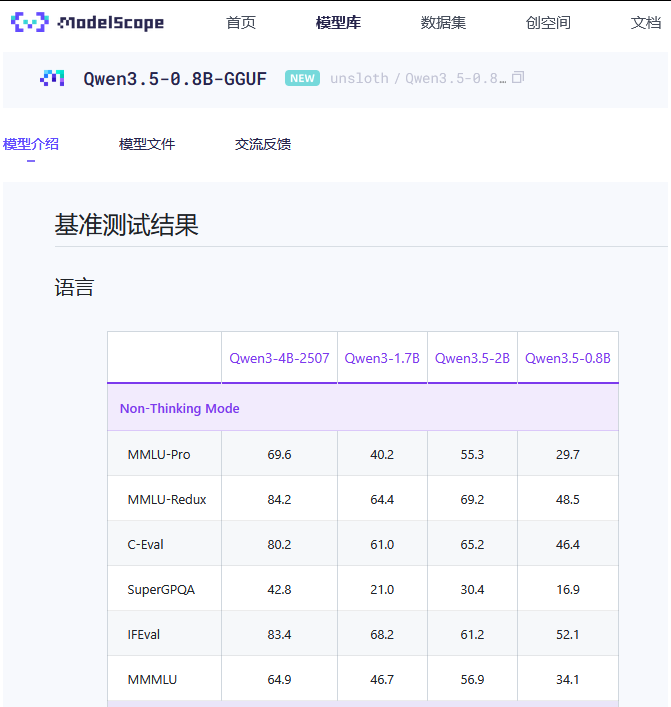
其中【模型介绍】描述基准测试结果关于不同模型间的比较,可自行阅读;
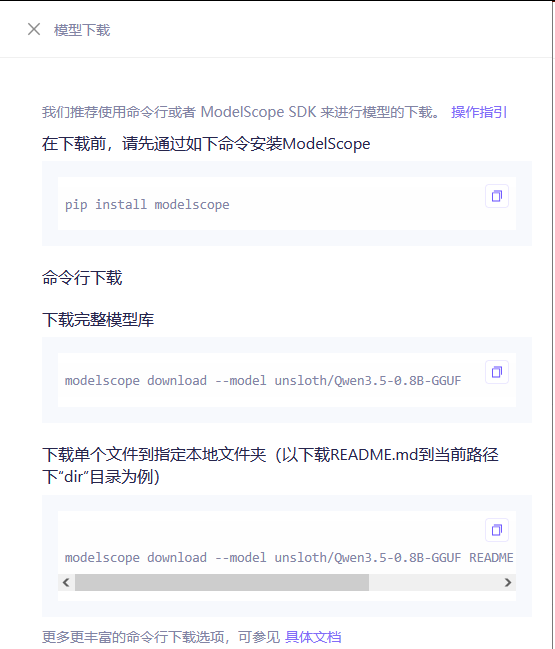
点击【下载模型】,个人觉得【命令行下载】较方便,遂执行命令行,文件默认下载至【C:\Users\Administrator\.cache\modelscope\hub\models\unsloth\Qwen3___5-0___8B-GGUF】

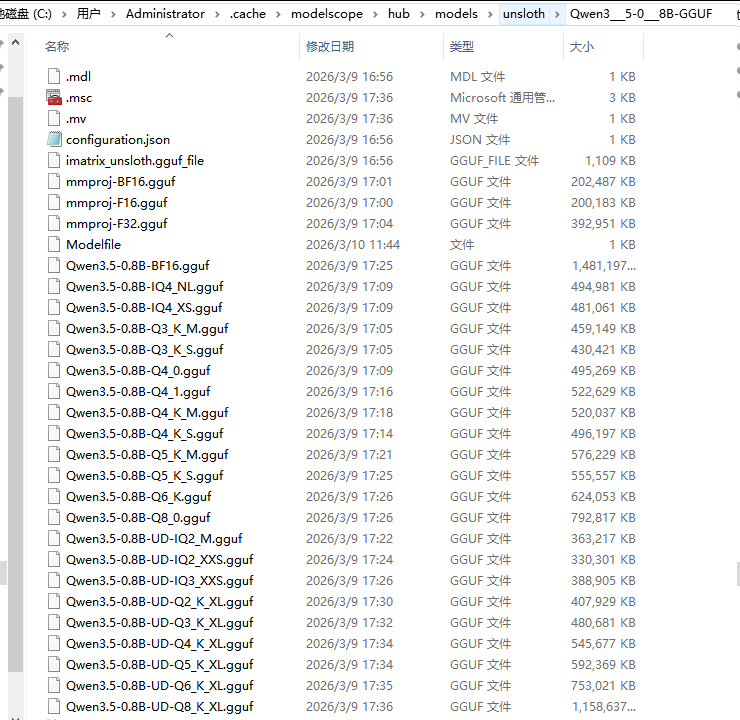
GGUF是一种专为大型语言模型(LLM)设计的二进制文件格式,全称是GPT-Generated Unified Format(GPT生成统一格式)。可以理解为一个经过高度优化和打包的模型“压缩包”,其核心目标就是让庞大的AI模型能在普通电脑上更快地加载和运行。
Qwen3.5-0.8B-Q4_K_M.gguf (推荐):平衡性最好,质量与大小的黄金比例;适用于日常对话、文本生成,兼顾速度和效果;
Qwen3.5-0.8B-Q3_K_S.gguf (高速):文件最小,运行最快,但质量略有下降;
Qwen3.5-0.8B-Q5_K_M.gguf (高质量):质量更好,接近原始模型,但文件稍大,占用内存更多;
不建议使用的文件:
mmproj-*.gguf:这些是多模态投影文件,纯文本模型不需要;
Qwen3.5-0.8B-BF16.gguf:这是未量化的完整模型,约1.4GB,内存占用太大;
Qwen3.5-0.8B-Q8_0.gguf:质量提升有限但体积大很多;
文件名含义:
Q4/Q5/Q8:量化位数,越高质量越好但文件越大;
K_M/K_S:K表示K-quants量化方法,M是中等质量,S是小体积;
IQ:改进型量化,压缩率更高;
2.Ollama
Ollama是一个开源、轻量级的工具,可以让你在个人电脑上轻松运行大型语言模型(如Llama 3、Qwen等)。可以理解为一个本地版的AI模型“应用商店”和“运行平台”,无需联网和复杂的配置,就能拥有一个私人的AI助手。
Ollama的设计初衷是简化AI模型的使用,让技术不再有高门槛。它的核心价值体现在以下几个方面:
极致简化部署:告别繁琐的环境配置和依赖安装。通过一行命令 ollama run <模型名>,Ollama会自动帮你完成模型的下载、加载和启动,真正做到开箱即用。
数据隐私安全:所有模型和数据都在你自己的电脑上运行,无需将任何信息上传到云端。这对于处理敏感信息的企业或个人来说,是一个至关重要的优势。
硬件资源友好:Ollama采用了模型量化等技术,能显著降低模型对内存的需求。这使得很多原本需要昂贵服务器的模型,也能在普通的个人电脑甚至笔记本上流畅运行。
通过官方下载PC端,详情见:https://ollama.com/download
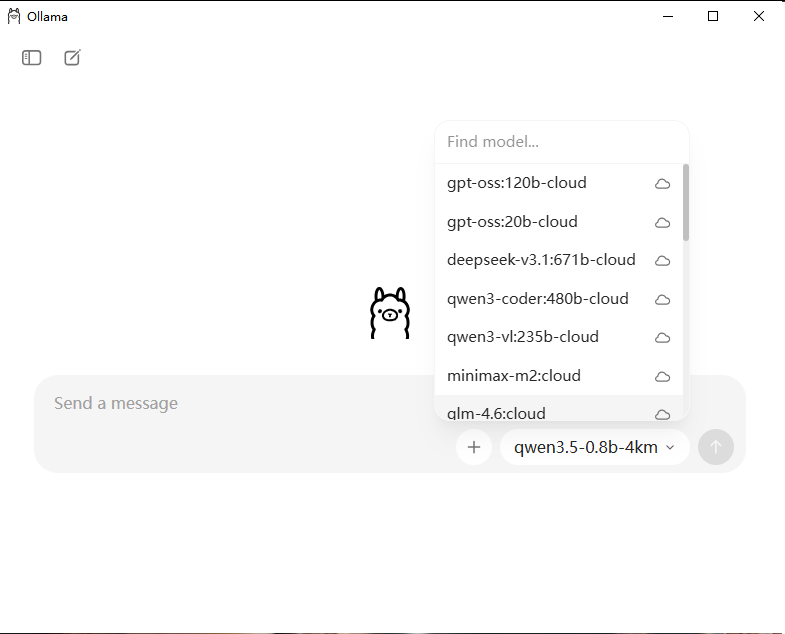
可以选择对应的模型,若要引入本地离线模型,此处使用上文中的Qwen3.5举例:
1.首先进入模型目录:cd "C:\Users\Administrator\.cache\modelscope\hub\models\unsloth\Qwen3___5-0___8B-GGUF"
2.创建【Modelfile】此文件无后缀:echo FROM Qwen3.5-0.8B-Q4_K_M.gguf > Modelfile
3.创建模型-文件中写的是相对路径所以需要在当前目录下:ollama create qwen3.5-0.8b-4km -f ./Modelfile
4.重启ollama即可选择该模型,或者执行命令:ollama run qwen3.5-0.8b-4km
3.LLaMaFactory
LLaMaFactory安装详情见:https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/installation.html
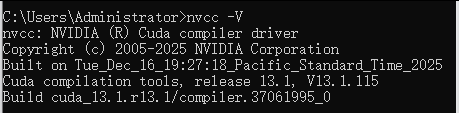
安装完成后命令行:nvcc -V 出现如下,表示安装成功;
使用git下载项目:git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .
pip install -r requirements/metrics.txt
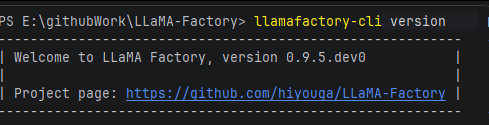
通过使用 llamafactory-cli version 校验安装成功;
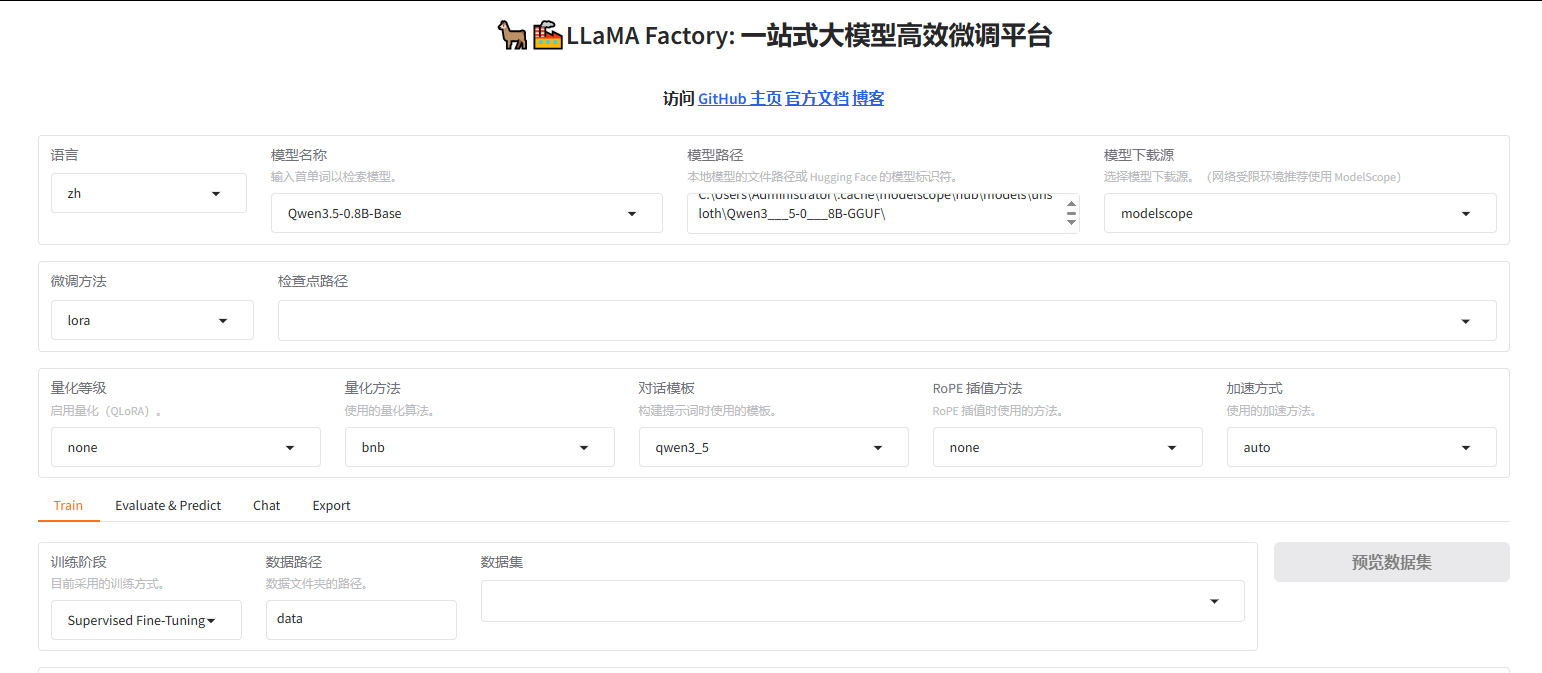
LLaMa Factory 支持通过WebUI微调大语言模型,使用指令:llamafactory-cli webui
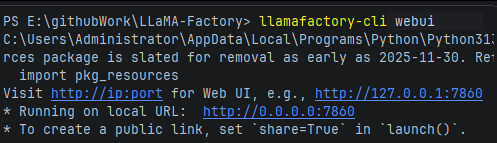
访问:http://localhost:7860/ 可以进入页面;
4.llama.cpp
由于个人电脑缺少独显GPU,无法运行LLaMa Factory,故后续改用llama.cpp;
llama.cpp是免费的开源工具,对CPU运行做了优化,同时可直接使用GGUF格式。
访问官方发布页:https://github.com/ggml-org/llama.cpp/releases 下载对应Windows版本压缩包文件;
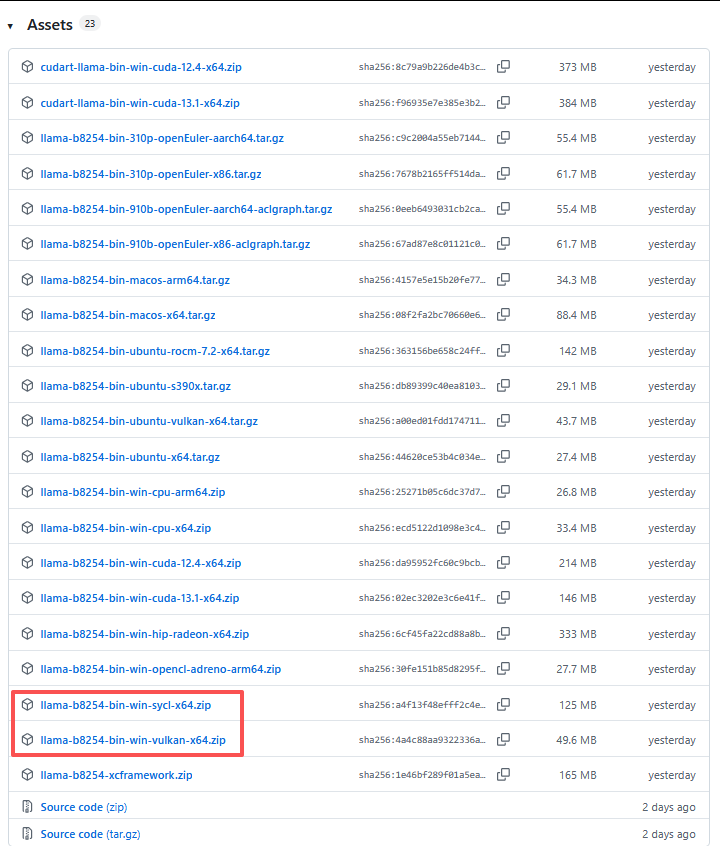
在Assets中找到 bin-win 的zip包;Vulkan表示通用版,覆盖面广;SYCL表示专业版,主要是配合独显设计的;
解压后进入目录,例如:D:\Program Files\llama-b8254-bin-win-vulkan-x64
使用命令行:llama-server.exe -m "C:\Users\Administrator\.cache\modelscope\hub\models\unsloth\Qwen3___5-0___8B-GGUF\Qwen3.5-0.8B-Q4_K_M.gguf"
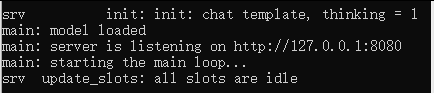
这次基于 ModelScope 平台的 Qwen3.5 系列开源大模型本地部署实践,尽管最后通过引入 llama.cpp 成功在 CPU 环境下启动了模型服务,验证了其在资源受限环境下本地化部署的可行性。
但是 LLaMaFactory 的 WebUI 微调功能及其具体参数配置,由于涉及更复杂的依赖环境和硬件要求,本次暂未展开实践,相关内容将在后续的技术分享中进行实践和讲解。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)