超越GRPO!解密最新大模型强化学习领域的SOTA算法:STAPO
超越GRPO!解密最新大模型强化学习领域的SOTA算法:STAPO
本文介绍了清华大学智能驾驶课题组(iDLab)与滴滴深穹远航实验室(DiDi Voyager Labs) 联合提出的用于大模型微调训练的 STAPO(Spurious-Token-Aware Policy Optimization)算法,旨在解决强化学习(RL)训练过程中常见的策略熵失稳和性能震荡衰退难题。以六个基准测试(AIME24、AIME25、AMC23、MATH500、Minerva 和 OlympiadBench)和三个大模型(Qwen3 1.7B、8B 和 14B)的实验表明,STAPO 超越了GRPO、20-Entropy 和 JustRL等算法,达到领域内的SOTA性能。这为以词元(token)为基本要素的大模型训练技术提供了全新设计方案。
研究链接:https://arxiv.org/abs/2602.15620
一、背景
近年来,大语言模型(LLMs)在数学与编程等复杂推理任务上持续进展。包括 OpenAI-o1、DeepSeek-R1 和 Qwen3 在内的模型,展现出较强的长链条推理能力。其中,强化学习(RL)在优化结果级正确性方面发挥了重要作用,并被认为与复杂推理能力的提升有关。然而,训练稳定性仍然是 RL 面临的主要瓶颈之一。在实际训练过程中,模型有时会出现明显退化现象:原本连贯的推理链条退化为浅层、重复甚至无意义的输出模式。这种不稳定性在一定程度上制约了 RL 在大模型推理中的应用。现有研究主要从两个方向缓解这一问题:
- 熵调控(Entropy Regulation):通过选择性正则化、样本增强或裁剪策略等方式抑制熵塌陷,但也可能引发相反问题(如熵过度波动或振荡),影响推理连贯性。
- 梯度调制(Gradient Modulation):针对低概率词元对参数更新影响过大的现象,采用优势重加权、概率重塑或正则约束等方法抑制不稳定梯度。但这些方法缺乏对词元层面不稳定性的精细刻画,未能区分低概率区域中的有效探索与有害噪声。
不同于以往的工作,本工作从词元级别出发,对强化学习中的优化动态进行系统分析,创新在于:
-
通过碰撞概率与香农熵的上下界分析,从数学层面揭示了词元级策略梯度的范数不仅取决于词元生成概率,而且还和词元生成熵(token-level generation entropy)呈现负相关联系,这为大模型强化学习算法的设计提供了全新的理论支撑。
-
首次定义了“虚假词元 (spurious token)”的概念,即虽然出现在正确回答中,但对推理过程几乎无贡献甚至为负的词元。通过构建涵盖策略梯度范数、生成熵变化方向和学习潜力的三维度分析框架,建立了以“低”生成概率、“低”生成熵、“正”优势函数为准则的虚假词元判别条件。
-
为进一步提升以词元为基本要素的大模型推理性能,提出了虚假词元剔除机制(Silencing Spurious Tokens, S2T),将该机制与组优势目标函数相结合进行策略梯度计算,所衍生的STAPO算法实现了策略熵稳定性和收敛性能的综合提升,典型测试场景超越了主流的Baseline算法。
二、策略梯度范数边界定理
为解释 RL 微调出现训练震荡的原因,本工作从词元级别建立理论分析框架,刻画了单个词元的一次更新如何影响整体优化。
本工作提出了策略梯度范数边界定理(Policy Gradient Norm Bounds),首次揭示了单个词元的梯度范数与其生成概率、生成熵之间的关系:
该定理给出一个关键结论:词元的梯度范数与其生成概率和生成熵均呈负相关关系。换言之,“低”概率且“低”熵(过度自信)的词元往往会产生更大的梯度,从而成为训练不稳定的来源之一。
三、“虚假词元”定义
结合已有工作的分析,本工作进一步将词元的优化行为归纳为三个指标:
- 策略梯度范数(Gradient Norm):决定更新幅度;过大时更容易引发不稳定。
- 生成熵变化方向(Entropy Change):衡量更新对生成熵的推动方向;需要关注熵过度波动的风险。
- 学习潜力(Learning Potential):反映该词元是否仍值得继续优化;对已充分学习的词元持续施压可能带来收益递减或副作用。
基于以上三个指标,本工作将采样的词元,并联合评估其对策略更新的“正/负效应”,结果如下表所示: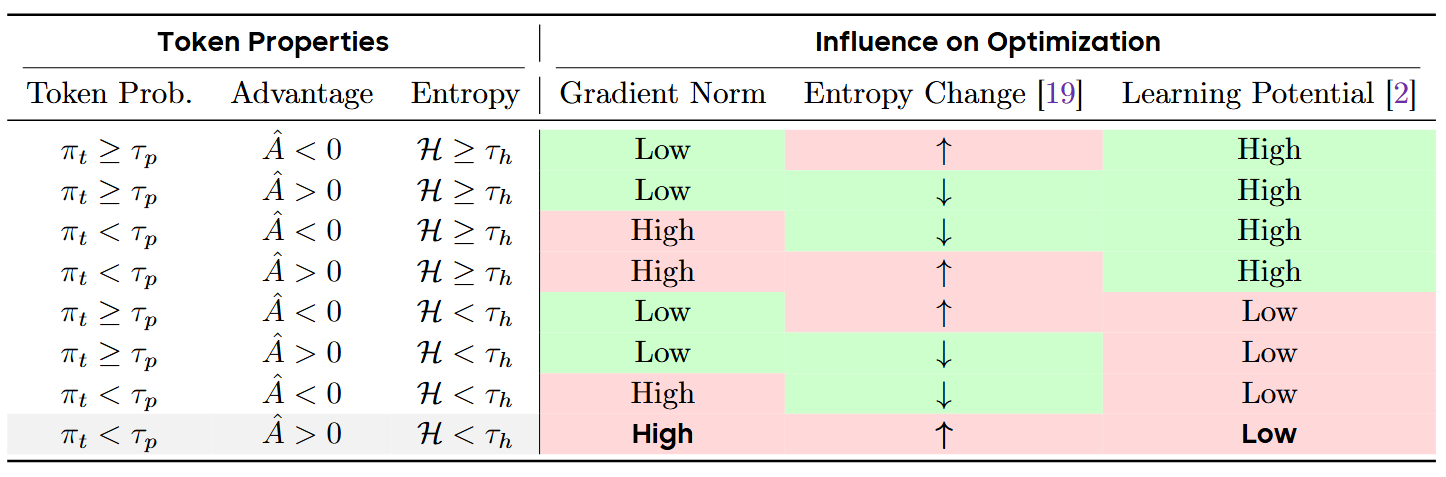
通过构建涵盖策略梯度范数、生成熵变化方向和学习潜力的三维度分析框架,本研究提出当词元同时满足“低”生成概率、“低”生成熵、“正”优势函数时,更容易把策略更新推向不稳定方向。
为验证这一结论并刻画其在真实训练中的行为,本工作在训练过程中记录词元的生成概率、生成熵与梯度统计。结果显示:记录到的词元会在“概率–熵”平面上自然形成若干簇,与上表中的不同区域相对应;进一步的统计分析表明,低”生成概率、“低”生成熵、“正”优势函数区域的词元平均梯度范数在所有类别中最高(下图)。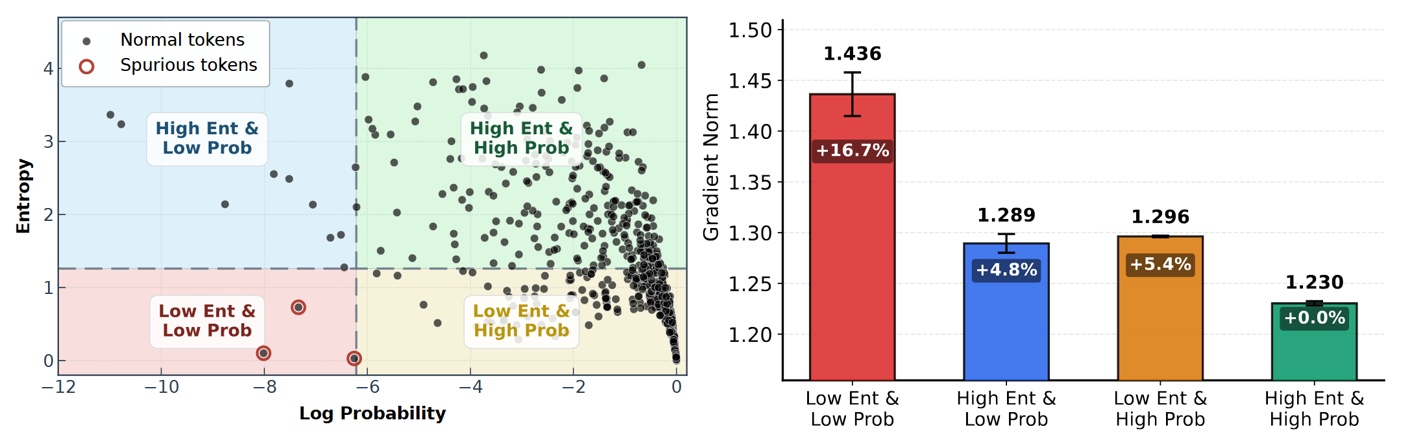
除此之外,本工作展示了训练回答中的例子。如下图所示,低”生成概率、“低”生成熵、“正”优势函数区域的词元往往表现为语义不当、计算错误、格式混乱;而高概率的候选词元更有助于保持语义一致性与推理链条的连贯性。由于样本级奖励按序列级分配(最终答案可能仍然高分),较大梯度会把这些模式一并强化,进而影响思维链连贯性并降低训练稳定性。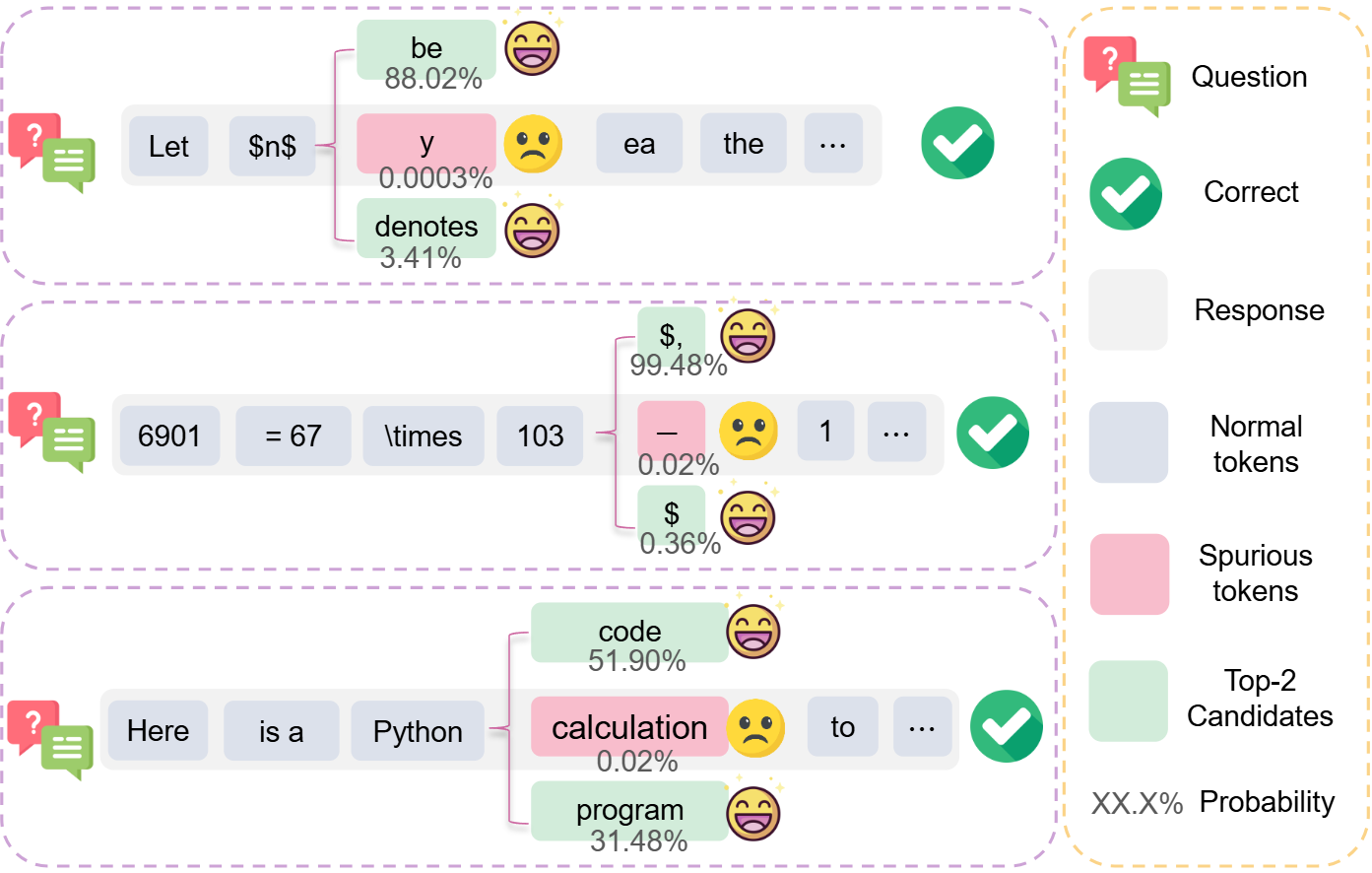
结合三维度分析框架及训练实例分析,本工作将“虚假词元 ”定义为:出现在正确回答中,但对推理过程几乎无贡献甚至为负的词元。工程实践上,“低”生成概率、“低”生成熵、“正”优势函数可作为识别虚假词元的判别准则。
三、STAPO 算法原理解析
STAPO算法的核心原理是降低虚假词元对优化的影响,同时尽量保留策略对真实错误的纠错能力,所采用的方案是剔除虚假词元的S2T机制。S2T机制本质是一个二值掩码函数,用于在神经网络反向传播时选择性屏蔽落入破坏性区域的词元梯度。
当某个词元同时满足优势函数为正(A^i>0\hat{A}_i>0A^i>0)、生成概率较低(π(yi,t)<τp\pi(y_{i,t})<\tau_pπ(yi,t)<τp)和生成熵较低(Ht<τh\mathcal{H}_t<\tau_hHt<τh)的条件时,将其判定为虚假词元并剔除;其余情况则保留正常梯度计算。
Ii,tS2T={0,if A^i>0∧πθ(yi,t)<τp∧Ht<τh1,otherwise. \mathbb{I}^{\text{S2T}}_{i,t} = \begin{cases} 0, & \text{if } \hat{A}_i > 0 \land \pi_\theta(y_{i,t}) < \tau_p \land \mathcal{H}_t < \tau_h \\1, & \text{otherwise}\end{cases}. Ii,tS2T={0,1,if A^i>0∧πθ(yi,t)<τp∧Ht<τhotherwise.
结合组优势目标函数,STAPO算法的总体更新目标定义为:
JSTAPO(θ)=E[∑i,tIi,tS2T⋅min(ρi,tA^i,clip(ρi,t,1−ϵlow,1+ϵhigh)A^i)∑i,tIi,tS2T]ρi,t(θ)=πθ(yi,t∣x,yi,<t)πθold(yi,t∣x,yi,<t),A^i=R(x,yi)−mean({Rj})std({Rj}), \begin{aligned} \mathcal{J}_{\text{STAPO}}(\theta) &= \mathbb{E} \left[ \frac{\sum_{i,t} \mathbb{I}^{\text{S2T}}_{i,t} \cdot \min \left( \rho_{i,t} \hat{A}_{i}, \text{clip}(\rho_{i,t}, 1-\epsilon_{\text{low}}, 1+\epsilon_{\text{high}}) \hat{A}_{i} \right)}{\sum_{i,t}\mathbb{I}^{\text{S2T}}_{i,t}} \right] \\ \rho_{i,t}(\theta) &= \frac{\pi_\theta(y_{i,t} \mid \boldsymbol{x}, \boldsymbol{y}_{i,<t})}{\pi_{\theta_{\text{old}}}(y_{i,t} \mid \boldsymbol{x}, \boldsymbol{y}_{i,<t})}, \quad \hat{A}_i = \frac{R(\boldsymbol{x}, \boldsymbol{y}_i) - \text{mean}(\{R_j\})}{\text{std}(\{R_j\})}, \end{aligned} JSTAPO(θ)ρi,t(θ)=E
∑i,tIi,tS2T∑i,tIi,tS2T⋅min(ρi,tA^i,clip(ρi,t,1−ϵlow,1+ϵhigh)A^i)
=πθold(yi,t∣x,yi,<t)πθ(yi,t∣x,yi,<t),A^i=std({Rj})R(x,yi)−mean({Rj}),
其中,π(yi,t)\pi(y_{i,t})π(yi,t) 为当前策略对第 ttt 个词元的生成概率,Ht\mathcal{H}_tHt 为该位置的词元生成熵。整体算法流程如下所示:
四、实验结果
研究团队在Qwen3 1.7B、8B 和 14B Base模型上开展系统评测,并在六个数学推理基准上(AIME24、AIME25、AMC23、MATH500、Minerva、Olympiad Bench)与GRPO、20-Entropy、JustRL等大模型强化学习算法进行对比。
1. 数学推理能力评估
针对数学推理任务,STAPO不同评测参数设置下均取得SOTA性能:(1)ρT=1.0\rho_{\mathrm{T}}=1.0ρT=1.0、top-p=1.0参数(黑色字体),平均提升7.13%;(2)ρT=0.7\rho_{\mathrm{T}}=0.7ρT=0.7、top-p=0.9 参数(灰色字体),平均提升3.69%。总体而言,STAPO 在两套配置下均表现稳定,体现出更好的鲁棒性。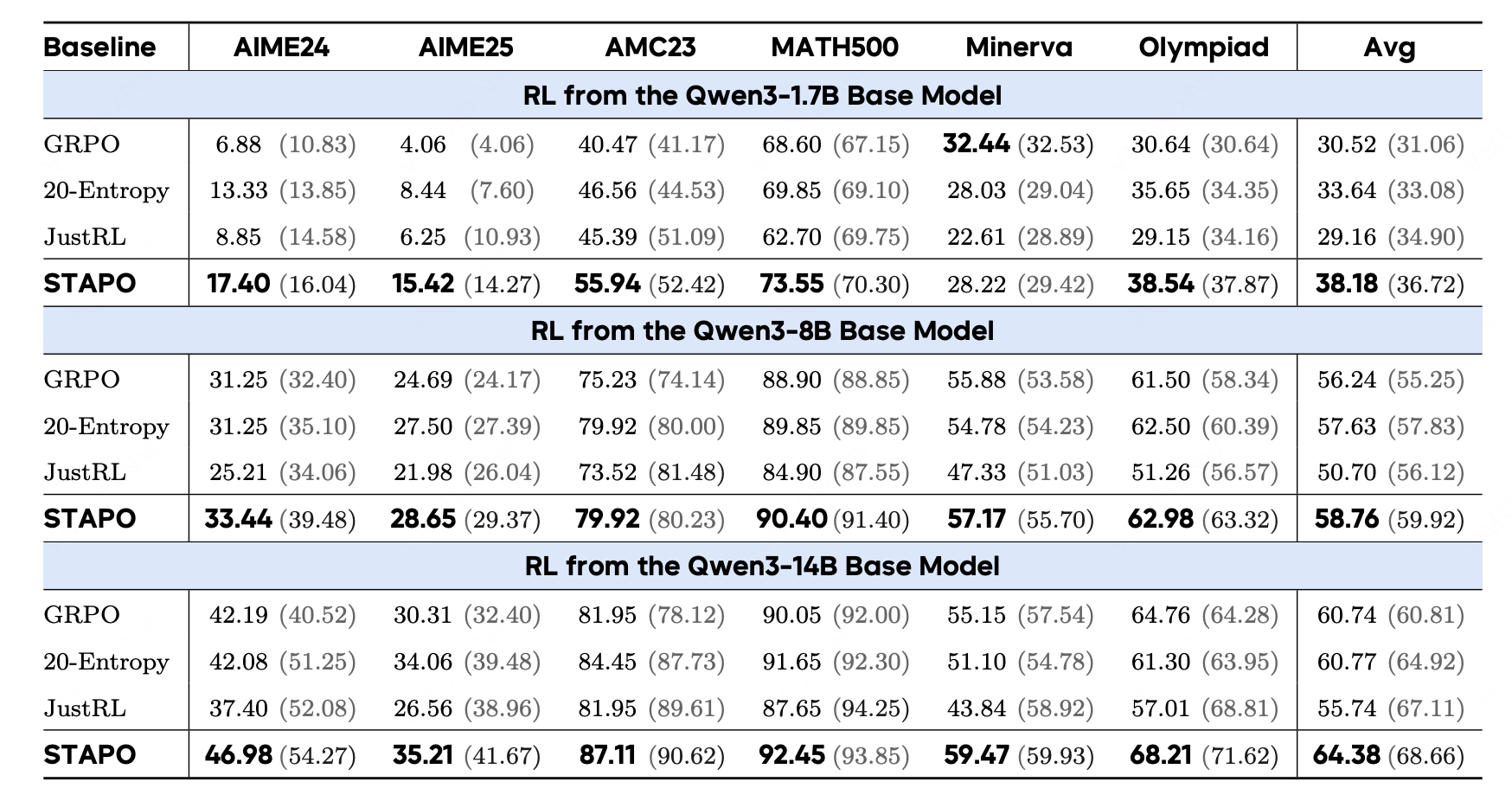
2. 训练行为分析
研究团队进一步对准确率(AIME24 Acc@32)、策略熵(Entropy)和训练奖励(Training Reward)等关键指标进行了可视化分析。如下图所示,在Qwen3-1.7-Base模型的表现上,相较于20-Entropy、JustRL算法,STAPO的策略熵更加平滑、波动更小,体现出更加稳定的探索能力;相较于GRPO算法,STAPO的策略熵不会退化为零,保持了良好的探索能力;与此同时,STAPO的准确率与训练奖励也获得了更加优异的表现。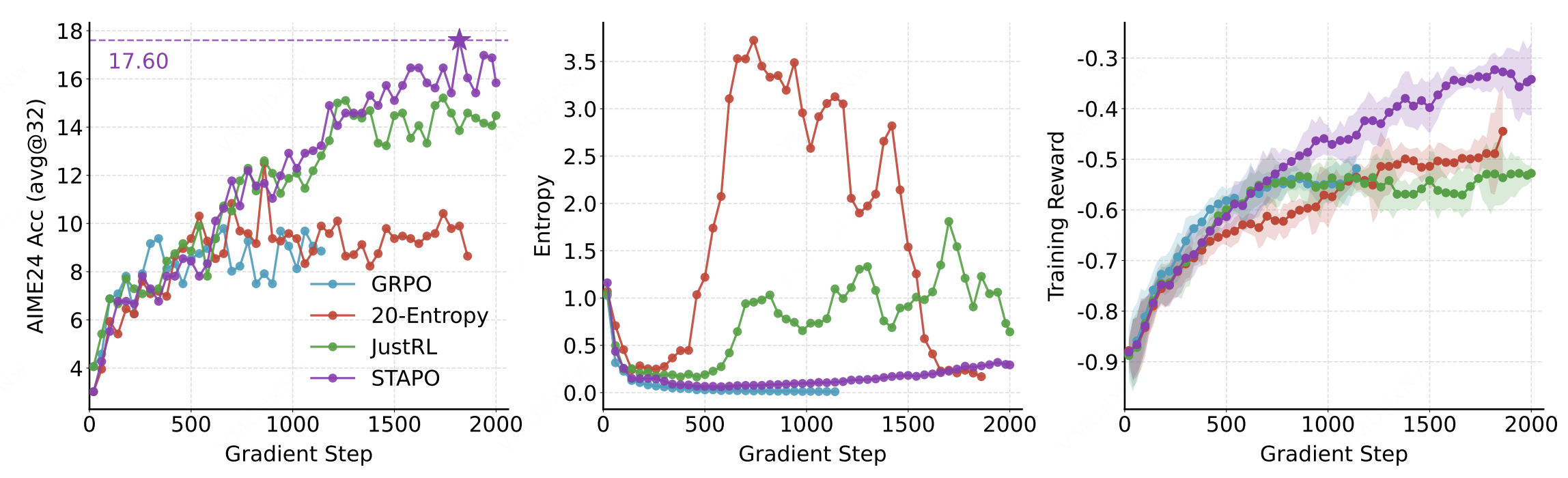
3. 超参数敏感性分析
该研究对 STAPO 的超参数(概率阈值 τp\tau_pτp 与熵阈值 τh\tau_hτh)进行了敏感性分析。研究指出,τp\tau_pτp 需要保持足够的选择性,以尽量只过滤真正的虚假词元,同时保留稀有但具有语义意义的词元;而较低的 τh\tau_hτh 往往会过滤更多词元,从而有助于降低训练偏移风险并提升稳定性。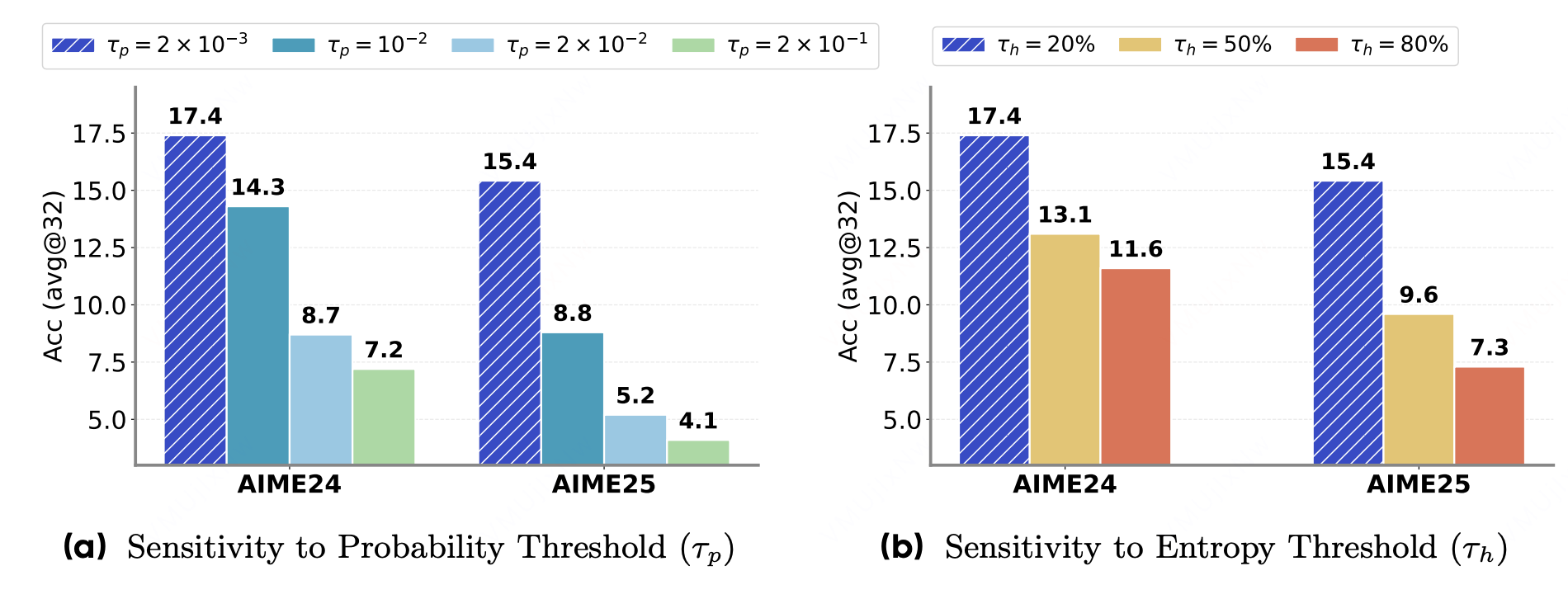
4. 虚假词元性质分析
为进一步分析性能变化的可能原因,研究补充了对虚假词元占比与词云可视化的统计分析。
(1)占比比例:研究报告 STAPO 识别出的虚假词元比例在强化学习训练过程中保持在较低水平。尽管这类词元很少见,屏蔽它们仍带来推理性能的提升。研究据此得出结论,强化学习的不稳定性并非主要来自频繁错误,而与极少数具有正优势但语义信息较弱的词元有关。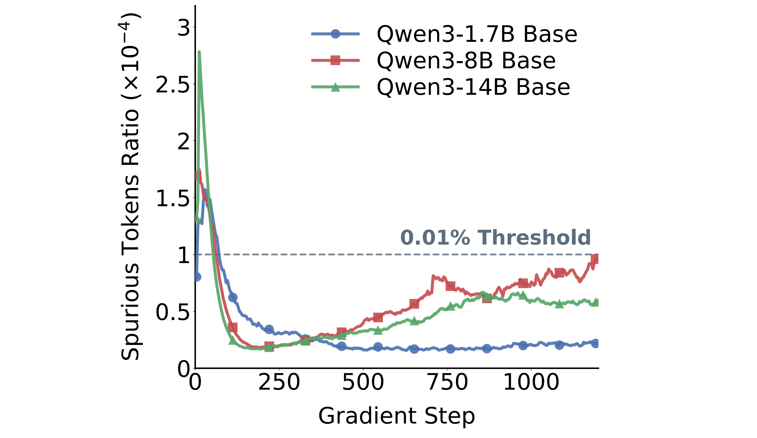
(2)词云可视化:虚假词元常以数字(1、2、3、4)、符号($)、转折词(Wait、But)等形式出现,对应到公式计算中的不一致表达或局部噪声;对这些词元的正向强化压低更“正常”词元的概率,并在梯度放大时放大不稳定性。相对地,其他词元更常见于逻辑引导词(Let、find、we、can)等,有助于维持推理连贯性。整体结果支持本研究的观点:剔除信息量低且梯度范数大的词元,有助于稳定训练。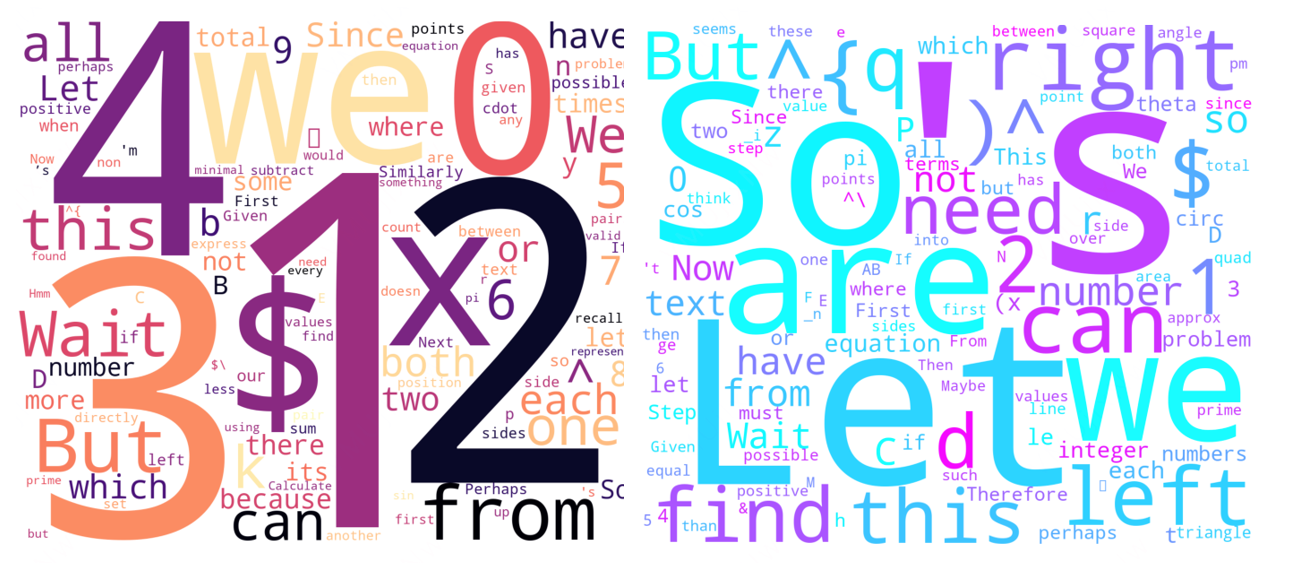
五、总结
本研究从词元角度出发,分析了大模型强化学习训练不稳定的机制。研究指出,策略优化过程中词元生成概率、生成熵与优势符号之间的相互作用,可能会放大极少数虚假词元的更新影响。这类词元虽然出现在回答正确的样本中,但对推理过程贡献有限;在“低”生成概率、“低”生成熵和正优势的组合下,其梯度可能被放大,干扰整体优化方向并引发训练波动。
基于上述分析,研究提出 STAPO 算法:通过识别并剔除约 0.01% 的虚假词元更新,并对其余词元重新归一化损失,从而在不显著改变训练框架的情况下提升训练稳定性。研究在六个数学推理基准上的实验结果显示,STAPO 在不同模型规模与评测设置下均能保持较稳定的策略熵变化,并取得相对更好的推理性能。作者希望该方法能为大模型推理强化学习的稳定性问题提供全新的视角和设计方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)