关于数据湖 Paimon,万字长文带你快速入门(上)
点击上方 "云祁的数据江湖"关注, 星标一起成长

大家好,我是云祁!某大厂资深数据老兵。
1. 概述
我们用一句话来概括数据湖 Paimon 的话,Paimon 是一种湖格式,它支持使用 Flink 和 Spark 为流处理和批处理操作构建实时湖仓架构。它创新性地将 LSM Tree 与湖格式相结合,将实时流更新引入湖架构。
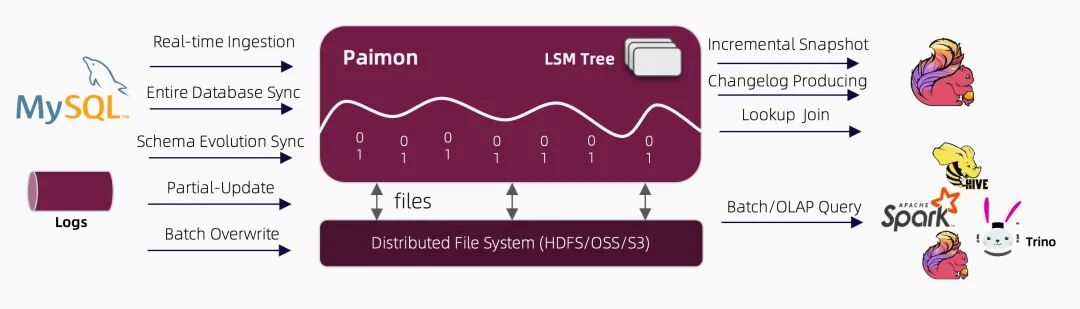
Apache Paimon (后简称 Paimon)起源于 Apache Flink (后简称 Flink)的一个子项目,起初它只是 Flink 内置的 Table Store 的一个格式,经过了几年的发展后,在 2024 年成功从 Apache 软件基金会(ASF)孵化器毕业,成为正式的顶级项目。
Paimon 的优势主要在以下四大方面:
- 实时更新能力:
-
- 高效更新:主键表支持大规模更新写入,具有非常高的更新性能,通常通过 Flink 流处理实现。
- 灵活更新:支持定义合并引擎,可以按照您喜欢的方式来更新记录。可以去重以保留最后一行,或保留首行,或部分字段更新,或聚合记录。
- 变更日志:支持定义变更日志生成器,在更新中为合并引擎产生正确且完整的变更日志,简化您的流式分析。
- 及时可见:数据分钟级(1-10min)可见
- 海量“追加数据”处理能力:
-
- 追加表(无主键)提供大规模的批处理和流处理能力。
- 自动合并小文件。
- 高效查询能力:
-
- 支持使用 z-order 排序的数据压缩优化文件布局,并基于诸如最小最大值的索引进行数据跳过,以提供快速查询能力。
- 数据湖能力:
-
- 可扩展的元数据:支持存储PB级大规模数据集和存储大量分区。
- 支持 ACID 事务、数据版本回溯和模式演变。
1.1 概览
如上架构图所示:
读/写:Paimon 支持多种方式来读取/写入数据和执行 OLAP 查询。
- 对于读取,它支持消费数据
-
- 从历史快照(批处理模式)
- 从最新偏移量(在流模式下),或以混合方式读取增量快照。
- 对于写入,它支持
-
- 来自数据库变更日志的流式同步(CDC)
- 从离线数据批量插入/覆盖。
生态系统:除了 Apache Flink,Paimon 还支持其他计算引擎的读取,例如 Apache Hive、Apache Spark 和 Trino。
内部的:
- 在底层,Paimon 将列式文件存储在 文件系统/对象存储 中。
- 元数据存储在 manifest 文件中,提供了大规模存储和数据跳过功能。
- 对于主键表,使用 LSM 树结构来支持大量数据更新和高性能查询。
1.2 基础概念
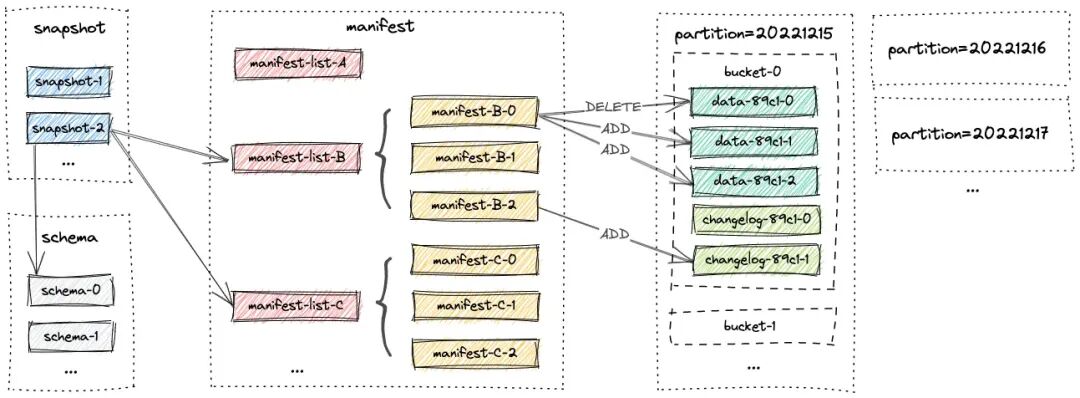
Snapshot 包含 schema 和 manifest 列表,manifest 包含 LSM 数据文件和 changelog 文件。LSM 数据文件和 changelog 文件又被组织在不同的分区和桶中。
1.2.1 Snapshot 快照
快照都存储在 Snapshot 文件夹中。快照文件本质是一个 JSON 文件,包含
● the schema file in use
● the manifest list containing all changes of this snapshot
快照可以捕获表在某个时间点的状态。用户可以通过最新的快照访问表的最新数据。通过时间旅行,用户还可以通过较早的快照访问表的先前状态。
系统默认最少会保留 10 个快照,默认最大会保留 2147483647 个快照,快照文件的默认过期时间是 1 小时。
简单总结就是说,当快照文件大于 10 个的大前提下,只要快照文件大于 2147483647 个 || 最早的快照文件产出时间距离现在已经超过 1 小时,就会触发快照文件的过期删除动作。
1.2.2 Manifest Files 清单文件
Manifest 清单列表和 Manifest 清单文件都存储在 Manifest 文件夹中。
一份 Manifest 文件包含了「LSM 数据文件和 changelog 文件」的所有变化情况。
1.2.3 Data Files 数据文件
数据文件被组织在不同的分区中,Paimon 支持列式和行式存储。
1.2.4 Partition 分区
分区是一种 可选 的方式,用于根据特定列(如日期、城市和部门)的值将表划分为相关部分。
1.2.5 时效性问题
写入的时候:Paimon 的 Write 算子会首先将数据缓存在内存以及临时文件中,在 Flink 任务创建检查点(Checkpoint)之后,才会将临时文件进行提交(commit),并产生快照(snapshot)文件。
快照文件是读取 Paimon 表数据的入口。
流式读取的时候:下游的流式消费将会监听 Paimon 的快照(snapshot)文件列表。发现新的快照文件以后,才会读取该快照文件对应的数据变更。
批式读取的时候:下游的批消费默认情况下,批作业将读取最新的快照文件,产出 Paimon 表的最新状态。
因此,Paimon 的时效性受到快照文件(snapshot)产生频率的影响。在没有外界异常因素干扰的情况下,快照文件产生的频率等同于创建检查点的时间间隔(Checkpoint interval)。等于说,Paimon 表的时效性,等于创建 Checkpoint 的时间间隔。
一般建议将创建检查点的 时间间隔设置为 1 分钟至 10 分钟。且根据业务的接受程度,应尽可能提高这一时间间隔,以进一步提高 Paimon 表的读写效率。
- 该时间间隔既 不宜设置过小,否则对任务运行效率有负面影响。
- 该时间间隔也 不宜设置过大,否则业务就要被迫接受更长的延迟。
设置检查点的参数如下:
execution.checkpointing.interval=xxx分钟。将检查点的创建间隔设置为xxx分钟。
execution.checkpointing.max-concurrent-checkpoints=3。这一参数将允许至多 3 个检查点同时进行,主要用于减小部分并发检查点长尾的影响
1.2.6 Consistency Guarantees 一致性问题
Paimon writers use two-phase commit protocol(两阶段提交协议) to atomically commit(原子化提交) a batch of records to the table. Each commit produces at most two snapshotsat commit time.
Paimon 结果表使用两阶段提交协议,在每次 Flink 作业的 checkpoint 期间提交写入的数据,因此 数据新鲜度 即为 Flink 作业的 checkpoint 间隔。每次提交将会产生至多两个 snapshot。
当两个 Flink 作业同时写入一张 Paimon 表时,如果两个作业的数据没有写入同一个分桶,则能保证 serializable 级别的一致性。如果两个作业的数据写入了同一个分桶,则只能保证 snapshot isolation 级别的一致性。也就是说,表中的数据可能混合了两个作业的结果,但不会有数据丢失。
Paimon 将通过作业失败重启(failover)的方式解决数据冲突。
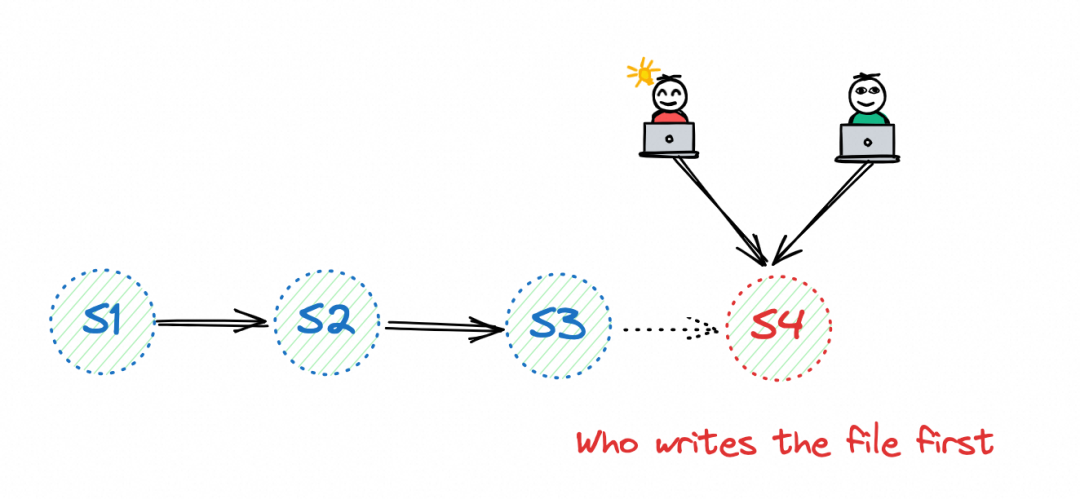
1.3 Concurrency Control 并发控制
快照冲突:快照ID已被抢占,表已经由另一个作业生成了一个新的快照。好的,让我们再次尝试提交。
- Paimon 的快照ID是唯一的,因此只要作业将其快照文件写入文件系统,就被认为是成功的。
- Paimon 利用 HDFS 的重命名机制来提交快照,这对于 HDFS 来说是安全的,因为它确保了事务性和原子性的重命名。
- 但是对 OSS 和 S3 则不行,需要额外配置 Hive 或者 jdbc 元存储。
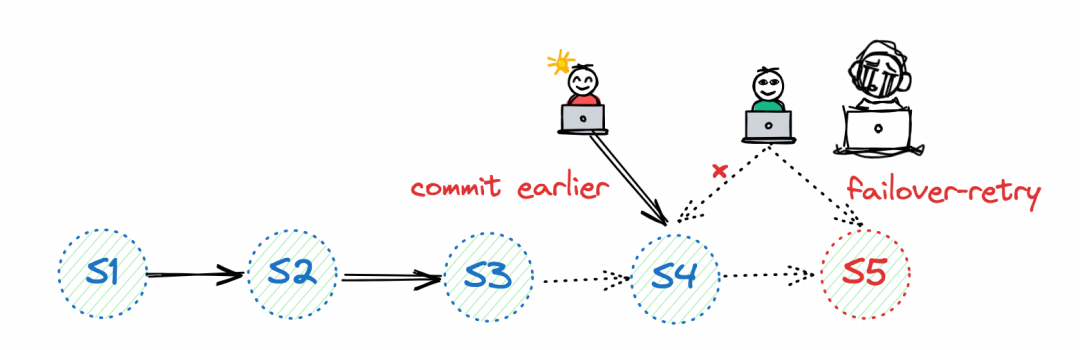
文件冲突:要删除的文件已经被删除了,此时job只能失败(对流任务来说,它会失败并重启,FO一次)
- 因此,它只能故意触发故障转移以重新启动,作业将从文件系统检索最新状态,希望能够解决这一冲突。
- 你会发现它们在不断地重启,这并不是一件好事。
- 冲突的本质在于删除文件(逻辑上),而删除文件源自于压缩,因此只要我们关闭写入作业的压缩功能(将‘write-only’设置为true)并启动一个单独的作业来执行压缩工作,一切都会变得非常好。
2. Table with PK 主键表
2.1. Overview
- Paimoin 强制每个 Bucket 内数据基于主键排序。用户可通过对主键应用过滤条件可以实现高性能查询。
2.1.1. Bucket 桶
- 数据分桶并用额外的结构,目的是为了高效查询。
- 每一个 Bucket 文件夹下存储一颗 LSM 树和其变更日志文件。
- 分桶的逻辑可以指定字段,如果没指定,那就用主键字段,如果主键也没指定,那就用全字段。
CREATETABLE T (
dt STRING,
shop_id BIGINT,
user_id BIGINT,
num_orders INT,
total_amount INT,
PRIMARYKEY (dt, shop_id, user_id) NOT ENFORCED
) PARTITIONED BY (dt) WITH (
'bucket' = '4',
'bucket-key' = 'dt,shop_id,user_id' //不指定就用主键字段,主键也没有就用全字段
)主键必须完整包含 bucket-key
- 一个 Bucke t是数据读写的最小单元,Bucket 数量决定了处理的最大并发。这个值不能太大,否则会有很多小文件引发较低的读取性能。也不能太小,太小会影响写入性能(这里又是一个权衡取舍,关于桶数量带来的读写平衡的取舍)。一般建议一个 Bucket 内的数据量在200M-1G之间(也有说在2G-5G之间,建议目前以官网的200M-1G为准)。
分桶(Bucket)是 Paimon 表读写操作的最小单元(因此 Bucket 的数量限制了最大的处理并行度)。非分区表的所有数据,以及分区表每个分区的数据,都会被进一步划分到不同的分桶中,以便同一作业使用多个并发同时读写 Paimon 表,加快读写效率。
每一个 Bucket 目录内会包含一个 LSM 树。
2.1.2. LSM 树
2.1.2.1. Sorted Runs
- LRM 树把文件组织称几个 Sorted Run。一个 Sorted Run 由一个或多个数据文件组成,每个数据文件恰好属于一个 Sorted Run。
- 有几个原则如下图所示:Sorted Run 由一个或多个数据文件组成,数据文件中的记录按其主键进行排序。在 Sorted Run 中,数据文件的主键范围从不重叠。在不同的 Sorted Run 之间,主键会交叉甚至一样。
- 查询 LSM 时,所有 Sorted Run 里相同主键的记录要根据用户指定的合并引擎进行合并。
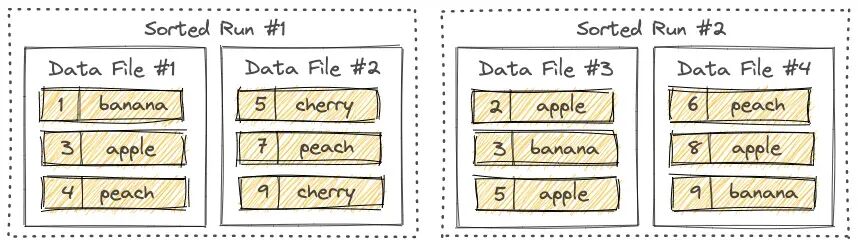
新数据写入LSM时候,数据会被缓存在内存再。但缓存满了,所有数据都会排序并刷进磁盘,此刻,一个新的sorted run就诞生了。(这里就可以理解,为啥 Sorted Run 内部所有 Data File 的主键不会重复,因为在内存里可以天然处理掉重复的记录)
可以将 Sorted Runs 理解为多个有序的 Data File 组成的一个有序文件。
2.1.2.2. Compaction 压缩
随着越来越多记录写入 LSM,Sorted Run 数量会增加。太多的 Sorted Run 会导致查询很慢甚至OOM,因为查询时要对 sorted run 进行合并,这是必须进行的。
为了避免上述的查询慢甚至 OOM,我们就要压限制 sorted run 的个数。因此需要定期对 Sorted Run 进行合并。这个过程叫做 compaction。(压缩的目的是为了保证读时性能,所以最好时刻都在压缩(但不现实也不可能),这样子读的时候就很快了)
但是压缩是一种资源密集型过程,它消耗一定量的CPU时间和磁盘IO。压缩太频繁又会导致写入慢。(压缩是为了读时快,但频繁压缩又影响写入,这里其实是一个权衡取舍),本质是在读写之间做了一个取舍。Paimon 当前采用的压缩策略类似 RocksDB 的全局压缩。
不仅仅是压缩频繁会阻塞写入,数据量一大导致小文件太多时压缩也会阻塞写入。
默认情况下,当 Paimon 向 LSM 树追加记录时,它也会 根据需要 执行压缩。用户还可以选择在一个专门的压缩作业中执行所有压缩操作。
主键表的 Compaction 默认在 Flink Sink 中自动完成,你不用关心它的具体过程,它会在 LSM 中生成一个 写放大 与 读放大 的基本平衡(控制平衡的参数参见6.2.2)。
这里换个说法,考虑两个极端:
- 如果压缩合并非常频繁,那么读不会放大(读的都是合并完成的数据),写会放大(每次写都要跟所有文件合并)。
- 如果压缩合并很不频繁,那么写不会放大(每次直接写文件落盘),读会放大(要做大量重复数据的meger)。
2.1.2.3. Record-Level expire 记录级别过期
压缩过程中,可以配置记录级别的过期时间
- 'record-level.expire-time': time retain for records.
- 'record-level.time-field': time field for record level expire, it should be a seconds INT.
过期操作发生在压缩过程中,但是没有强保证记录过期是及时的。
2.2 Data Distribution 数据分布
By default, Paimon table only has one bucket, which means it only provides single parallelism read and write. Please configure the bucket strategy to your table.
A bucket is the smallest storage unit for reads and writes, each bucket directory contains an LSM tree.
2.2.1 Fixed Bucket 固定数量的桶
计算逻辑是取余求桶的序号。
using Fixed Bucket mode, according to Math.abs(key_hashcode % numBuckets) to compute the bucket of record.
重新调整桶的大小只能通过离线过程来完成。桶数量太大导致太多小文件影响读性能,桶数量太小又会导致写入性能太差。
这里又是一个权衡取舍,关于桶数量带来的读写平衡的取舍。
Bucket 数量很关键,往往我们很难一开始就精准定义清楚 Bucket 个数,后期可能会有调整的需求。官方的建议是直接重建表,但是这个是用户不友好行为,且会漏数据。大概率需要靠 Rescale Bucket 能力。

如图所示,Write 之前会有根据 Bucket 的 Shuffle。
2.2.2 Dynamic Bucket 动态数量的桶
Configure 'bucket' = '-1'. The keys that arrive first will fall into the old buckets, and the new keys will fall into the new buckets, the distribution of buckets and keys depends on the order in which the data arrives. Paimon maintains an index to determine which key corresponds to which bucket. 配置 bucket-1 即可实现动态分桶。不同顺序进来的数据会被分到不同的桶里。不再是简单的 key 的哈希值取余,而是 依赖 key 进来的顺序。Paimon 会维护一个 key-bucket 的关系。
- Option1: 'dynamic-bucket.target-row-num': controls the target row number for one bucket.
- 该参数控制一个 bucket 中的数据量上限
- Option2: 'dynamic-bucket.initial-buckets': controls the number of initialized bucket.
- 该参数控制 bucket 的初始化个数
Dynamic Bucket only support single write job. Please do not start multiple jobs to write to the same partition (this can lead to duplicate data). Even if you enable 'write-only' and start a dedicated compaction job, it won’t work. 动态分桶不是普适的,只支持单个 write 作业。
Normal Dynamic Bucket Mode 普通的动态桶模式
When your updates do not cross partitions (no partitions, or primary keys contain all partition fields), Dynamic Bucket mode uses HASH index to maintain mapping from key to bucket, it requires more memory than fixed bucket mode. 适用场景,无分区表、分区表且主键完全包含了分区字段(Paimon 可以确定该主键属于哪个分区,但无法确定属于哪个分桶,因此需要使用额外的堆内存创建索引,以维护主键与分桶编号的映射关系。) 使用了简单的 Hash 来维护 key-bucket 的关系,动态分桶要比固定分桶多消耗一部分内存。
Performance:
- 无性能损失,仅仅是多消耗一些内存。1亿条数据大约消耗1G内存。
- 对于更新频率较低的表,建议采用此模式以 显著提高性能。
Normal Dynamic Bucket Mode supports sort-compact to speed up queries. See Sort Compact.
Cross Partitions Upsert Dynamic Bucket Mode 交叉分区更新的动态桶模式
When you need cross partition upsert (primary keys not contain all partition fields), Dynamic Bucket mode directly maintains the mapping of keys to partition and bucket, uses local disks, and initializes indexes by reading all existing keys in the table when starting stream write job 适用场景,主键不完全包含了所有分区字段(注意:Paimon 无法根据主键确定该数据属于哪个分区的哪个分桶,因此需要使用 rocksdb 维护主键与分区以及分桶编号的映射关系)。这时候,就需要维护主键key到分区+分桶的映射关系,使用本地磁盘,并在启动流写作业时通过读取表中所有现有的键来初始化索引
Different merge engines have different behaviors: 此类表在不同的合并引擎会有不同的表现(注意:其实没有一定的实战经验,很难对以下三种表现有深刻体会,先写在这里,未来再看)
- 数据将会从老分区删除,并插入新分区。
- 数据将会直接在老分区中更新,无视新数据的分区键。
- 如果相同主键的数据已经存在,则新数据将被直接丢弃。
- 大数据量下性能有损,而且初始化映射关系耗时很久(因为作业启动时需要将映射关系全量加载至 rocksdb 中,作业的启动速度也会变慢)
注意:不是很推荐这种模式,限制和问题都较多。
2.2.3 Pick Partition Fields 分区字段选择
- 创建时间(推荐):创建时间通常是不可变的,因此你可以放心地将其作为一个分区字段,并将其添加到主键中。
- 事件事件:事件时间是原始表中的一个字段。对于CDC数据,例如从MySQL CDC同步过来的表或Paimon生成的变更日志,它们都是完整的CDC数据,包括 UPDATE_BEFORE 记录,即使你声明了包含分区字段的主键,也可以实现唯一性效果(需要设置 'changelog-producer'='input')。
- CDC操作时间戳(CDC op_ts):它不能被定义为一个分区字段,无法得知之前记录的时间戳。因此,你需要使用跨分区的upsert操作,这将会消耗更多的资源。
2.2.4 所有建表可用参数
|
with参数 |
数据类型 |
默认值 |
备注 |
|
bucket |
Integer |
无 |
如果等于-1,就是动态分桶 |
|
bucket-key |
String |
主键 |
没有主键就用全字段 |
|
dynamic-bucket.target-row-num |
Long |
2000000 |
前提:bucket=-1 每个分桶最多存储几条数据。 |
|
dynamic-bucket.initial-buckets |
Integer |
无 |
前提:bucket=-1 初始的分桶数。如果不设置,初始将创建等同于 writer 算子并发数的分桶。 |
2.3 Merge Engine 合并引擎
two or more records with the same primary keys, it will merge them into one record to keep primary keys unique. 多条相同主键的记录同时到来时,paimon会合并他们成为一条记录。
Always set table.exec.sink.upsert-materialize to NONE in Flink SQL TableConfig, sink upsert-materialize may result in strange behavior. When the input is out of order, we recommend that you use Sequence Fieldto correct disorder. 注意用合并引擎时,flink的一个配置项要置为NONE。
2.3.1 Deduplicate 数据去重(保留最后一条)
这是默认值,它会保留相同主键下的最新一条记录值
Specifically, if the latest record is a DELETE record, all records with the same primary keys will be deleted. You can config ignore-delete to ignore it. 注意最后一次为delete时候的情况,会查出来为空
2.3.2 First Row 保留第一条
和上面相反,保留相同主键下的第一条记录。
in the first-row merge engine, it will generate insert only changelog. 和 deduplicate 不同的就是,first-row 引擎只会生成 insert 的 changelog。
- first-row merge engine must be used together with lookup changelog producer. 特别注意,保留第一条能力必须和lookup changelog producer一起用
- You can not specify sequence.field.
- Not accept DELETE and UPDATE_BEFORE message. You can config ignore-delete to ignore these two kinds records.
2.3.3 Partial Update 局部更新数据字段
对于需要构建宽表的业务场景,使用 partial-update 非常合适,并且操作也非常简单。
但是 partial-update 表默认不支持流读,需要结合 lookup 或者 full-compaction 一起使用才可以支持下游流读。
同时由于 partial-update 不能接收和处理 DELETE 消息,为了避免接收到 DELETE 消息而造成系统报错,需要在建表中配置忽略 delete 消息。简单总结,即必须加上以下两个参数配置一起使用:
'changelog-producer' = 'lookup' | 'full-compaction'
'merge-engine' = 'partial-update'
'partial-update.ignore-delete' = 'true'
By specifying 'merge-engine' = 'partial-update', Users have the ability to update columns of a record through multiple updates until the record is complete. This is achieved by updating the value fields one by one, using the latest data under the same primary key. However, null values are not overwritten in the process.
相同主键的记录中,使用最新一条记录的值去更新字段。如果最新记录的字段值是 null,null 是不会去覆盖其他字段值的。
假设进来三条记录:
- <1, 23.0, 10, NULL>
- <1, NULL, NULL, 'This is a book'>
- <1, 25.2, NULL, NULL>
Assuming that the first column is the primary key, the final result would be <1, 25.2, 10, 'This is a book'>. 并假设第一列就是主键,那么结果就是 <1, 25.2, 10, 'This is a book'>。
Sequence Group 序列组
A sequence-field may not solve the disorder problem of partial-update tables with multiple stream updates, because the sequence-field may be overwritten by the latest data of another stream during multi-stream update.虽然已经有了 sequence-field 来解决一些合并的无序问题,但是在多流更新的场景下,sequence-field 有可能被另外一个无关的流写入数据进而导致合并顺序或合并结果的不对。
So we introduce sequence group mechanism for partial-update tables. It can solve: 所以引入的sequence-group来解决局部更新表的2个重要问题:
- Disorder during multi-stream update. Each stream defines its own sequence-groups. 多流更新,每个流只能控制它自己的序列组。
- A true partial-update, not just a non-null update. 一个真正意义上局部更新,而不是简单的非空更新。
举例:
CREATE TABLE t (
k INT,
a INT,
b INT,
g_1 INT,
c INT,
d INT,
g_2 INT,
PRIMARY KEY (k) NOT ENFORCED
) WITH (
'merge-engine'='partial-update',
'fields.g_1.sequence-group'='a,b', // 你们三个一组
'fields.g_2.sequence-group'='c,d' // 你们三个一组
);// 等于说:a、b 两列将根据 g_1 列的值从小到大进行合并,而 c、d 两列将根据 g_2 列的值从小到大进行合并。
INSERT INTO t VALUES (1, 1, 1, 1, 1, 1, 1);
-- g_2 is null, c, d should not be updated
INSERT INTO t VALUES (1, 2, 2, 2, 2, 2, CAST(NULL AS INT));
SELECT * FROM t; -- output 1, 2, 2, 2, 1, 1, 1
-- g_1 is smaller, a, b should not be updated
INSERT INTO t VALUES (1, 3, 3, 1, 3, 3, 3);
SELECT * FROM t; -- output 1, 2, 2, 2, 3, 3, 3For fields.<field-name>.sequence-group, valid comparative data types include: DECIMAL, TINYINT, SMALLINT, INTEGER, BIGINT, FLOAT, DOUBLE, DATE, TIME, TIMESTAMP, and TIMESTAMP_LTZ. sequence-group支持以上这些类型
Aggregation For Partial Update 局部更新时进行数据预聚合,打宽且聚合
aggregation章节中预聚合的所有函数都可以使用。
CREATE TABLE t (
k INT,
a INT,
b INT,
c INT,
d INT,
PRIMARY KEY (k) NOT ENFORCED
) WITH (
'merge-engine'='partial-update',
'fields.a.sequence-group' = 'b',
'fields.b.aggregate-function' = 'first_value', // 这里不全,first_value不支持回撤,要加参数,学到后面会知道
'fields.c.sequence-group' = 'd',
'fields.d.aggregate-function' = 'sum'
);
INSERT INTO t VALUES (1, 1, 1, CAST(NULL AS INT), CAST(NULL AS INT)); -- output 1, 1, 1, null, null
INSERT INTO t VALUES (1, CAST(NULL AS INT), CAST(NULL AS INT), 1, 1); -- output 1, 1, 1, 1, 1
INSERT INTO t VALUES (1, 2, 2, CAST(NULL AS INT), CAST(NULL AS INT)); -- output 1, 2, 1, 1, 1
INSERT INTO t VALUES (1, CAST(NULL AS INT), CAST(NULL AS INT), 2, 2); -- output 1, 2, 1, 2, 3
SELECT * FROM t; -- output 1, 2, 1, 2, 32.3.4 Aggregation 数据预聚合
NOTE: Always set table.exec.sink.upsert-materialize to NONE in Flink SQL TableConfig.
Sometimes users only care about aggregated results. The aggregation merge engine aggregates each value field with the latest data one by one under the same primary key according to the aggregate function.
同主键下的最新记录中的每一个列,会一条条的使用所配置的聚合函数。
Each field not part of the primary keys can be given an aggregate function, specified by the fields.<field-name>.aggregate-function table property, otherwise it will use last_non_null_value aggregation as default.
除了主键以外的每一个列 都可以指定一个聚合函数。不使用聚合函数的列,默认会使用last-non-null-value函数,即保存最新非空值且空值不会进行覆盖。
注意:aggregation引擎也需要结合lookup或者full-compaction一起使用以后,下游才可以流式消费(也就是流读)该Paimon表。
用法举例:
CREATE TABLE my_table (
product_id BIGINT,
price DOUBLE,
sales BIGINT,
PRIMARY KEY (product_id) NOT ENFORCED
) WITH (
'changelog-producer' = 'lookup' | 'full-compaction'
'merge-engine' = 'aggregation',
'fields.price.aggregate-function' = 'max',
'fields.sales.aggregate-function' = 'sum'
'fields.price.ignore-retract'='true' //如果字段用的聚合函数不支持回撤的话,需要加这个参数
);Field price will be aggregated by the max function, and field sales will be aggregated by the sum function. Given two input records <1, 23.0, 15> and <1, 30.2, 20>, the final result will be <1, 30.2, 35>.
Current supported aggregate functions and data types are:
- sum(累加,支持回撤): The sum function aggregates the values across multiple rows. It supports DECIMAL, TINYINT, SMALLINT, INTEGER, BIGINT, FLOAT, and DOUBLE data types.
- product(累乘,支持回撤): The product function can compute product values across multiple lines. It supports DECIMAL, TINYINT, SMALLINT, INTEGER, BIGINT, FLOAT, and DOUBLE data types.
- count(计数,支持回撤): The count function counts the values across multiple rows. It supports INTEGER, BIGINT data types.
- max: The max function identifies and retains the maximum value. It supports CHAR, VARCHAR, DECIMAL, TINYINT, SMALLINT, INTEGER, BIGINT, FLOAT, DOUBLE, DATE, TIME, TIMESTAMP, and TIMESTAMP_LTZ data types.
- min: The min function identifies and retains the minimum value. It supports CHAR, VARCHAR, DECIMAL, TINYINT, SMALLINT, INTEGER, BIGINT, FLOAT, DOUBLE, DATE, TIME, TIMESTAMP, and TIMESTAMP_LTZ data types.
- last_value(支持回撤): The last_value function replaces the previous value with the most recently imported value. It supports all data types.
- last_non_null_value(支持回撤)(不配置的默认选项):The last_non_null_value function replaces the previous value with the latest non-null value. It supports all data types.
- listagg: The listagg function concatenates multiple string values into a single string. It supports STRING data type.
- bool_and: The bool_and function evaluates whether all values in a boolean set are true. It supports BOOLEAN data type.
- bool_or: The bool_or function checks if at least one value in a boolean set is true. It supports BOOLEAN data type.
- first_value: The first_value function retrieves the first null value from a data set. It supports all data types.
- first_non_null_value: The first_non_null_value function selects the first non-null value in a data set. It supports all data types.
- nested_update(支持回撤): The nested_update function collects multiple rows into one array (so-called ‘nested table’). It supports ARRAY data types.Use fields.<field-name>.nested-key=pk0,pk1,... to specify the primary keys of the nested table. If no keys, row will be appended to array.
- collect(支持回撤): The collect function collects elements into an Array. You can set fields.<field-name>.distinct=true to deduplicate elements. It only supports ARRAY type.
- merge_map(支持回撤): The merge_map function merge input maps. It only supports MAP type.
Retract 回撤
Only sum, product, count, collect, merge_map, nested_update, last_value and last_non_null_value supports retraction (UPDATE_BEFORE and DELETE), others aggregate functions do not support retraction. If you allow some functions to ignore retraction messages, you can configure: 'fields.${field_name}.ignore-retract'='true'. 因为不是所有函数都支持回撤的,所以如果要允许一些函数忽略回撤消息,避开报错,可以配置 'fields.字段名.ignore-retract'='true'
The last_value and last_non_null_value just set field to null when accept retract messages. 函数last_value和last_non_null_value应对回撤消息的行动就是将字段值设置为null。
The collect and merge_map make a best-effort attempt to handle retraction messages, but the results are not guaranteed to be accurate. 函数collect和merge_map虽然已经支持回撤消息,但是可能对结果准确性有影响。
2.3.5 所有建表可用参数
|
with参数 |
数据类型 |
默认值 |
备注 |
|
merge-engine |
String |
deduplicate |
deduplicate、first-row、partial-update、aggregation |
|
first-row.ignore-delete |
String |
false |
前提:merge-engine='first-row' first-row 无法处理 delete 与 update_before 消息。您可以设置 |
|
fields.<field-name>.aggregate-function |
String |
last-non-null-value |
前提:merge-engine='aggregation' | 'partial-update' 不属于主键的每一列,都需要指定聚合函数 或者 在局部更新时候,可以打宽的同时进行聚合,但是<field-name> 这一列需要属于某个 sequence group |
|
fields.<field-name>.ignore-retract |
String |
false |
前提:merge-engine='aggregation' 因为不是所有函数都支持回撤的,可以给列配置参数使对应列忽略回撤消息,避开报错 |
|
partial-update.ignore-delete |
String |
false |
前提:merge-engine='partial-update' partial-update 无法处理 delete消息,碰到delete消息,Flink系统会报错。 说明:并非所有场景下忽略delete消息都是正确的,您需要结合自己的实际场景配置该参数。 |
|
fields.<field-name>.sequence-group |
String |
无 |
前提:merge-engine='partial-update' 为不同列分别指定合并顺序,或者叫列分组,每一组可能来源一个流maybe |
2.4 Changelog Producer 变更日志生成器 重要!
Paimon 表中存储数据的时候,除了存储数据本身,还可以选择存储数据的变更日志,也就是 changelog
changelog 的主要应用场景是流读场景。在构建实时数仓的过程中,我们需要通过流式读取上游的数据写入到下游,完成数仓各个层次时间的数据传递,让整个数仓的数据实时流动起来。
如果上游数据来源于 mysql 的 binlog 日志,这样是可以直接提供完整的 changelog 以供流来读取的。
但是针对湖仓一体架构,Paimon 也可以用来构建中间层,如果下游的 flink 任务要流式读取 Paimon 中间层表中的数据,则需要 Paimon 的存储系统帮助生成 changelog,以便下游流读。
那就有一个疑问,为什么一定需要 changelog 呢?我就直接读取 Paimon 里的记录不行么?
因为通过 changelog 可以记录数据的中间变化。针对某些逻辑,我们需要知道之前的历史数据值是什么,这样子才能得到正确的计算结果。比如说:我们接收到 10 条相同主键的 Insert 数据,如果没有changelog,会导致下游的流聚合任务计算出问题,因为相同主键的多条数据应该被认为是更新,而不是重复累加计算。
此时,就需要我们在建表的时候指定 Paimon 的存储系统在何时、以何种方式生成 changelog。Paimon 支持的 Changelog Producers有四类,分别是 None、Input、Lookup、Full-Compaction.
2.4.1 None
None的时候,往 Paimon 写数据,Paimon 表只存储数据本身,不存储数据的 Changelog。换个角度说,此 Paimon 主键表将不会产出完整的变更数据,此 Paimon 表仅能被批作业进行消费,不能被流作业进行消费。
但实际情况是,此时再启动一个流读的任务消费该 Paimon 表,这个流读的任务是可以读取到完整类型的数据的(如下图所示,即-U1和+U1都有了),这是为什么呢? 因为这个流读的任务会自己产生一个Changelog Normalize物化节点来自己生成数据的 Changelog,但这个操作非常昂贵,因为它需要在状态中维护数据的所有历史变化情况,才能生成数据的 Changelog。
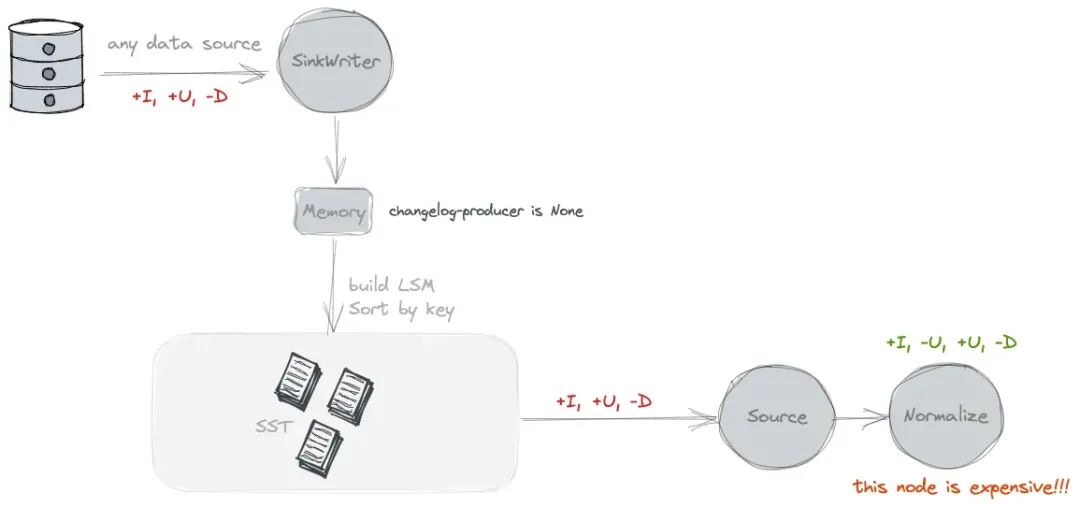
Changelog Normalize 物化节点可以在 Flink 任务的 Web UI 界面查看到。
(这个物化节点干了啥呢,更加细节一些的解释就是,在状态中维护接受到的每一条历史数据,如果接受到相同组件的多条数据,那么它就知道是发生了数据变更这种行为,就可以进行对应的数据行为补全)
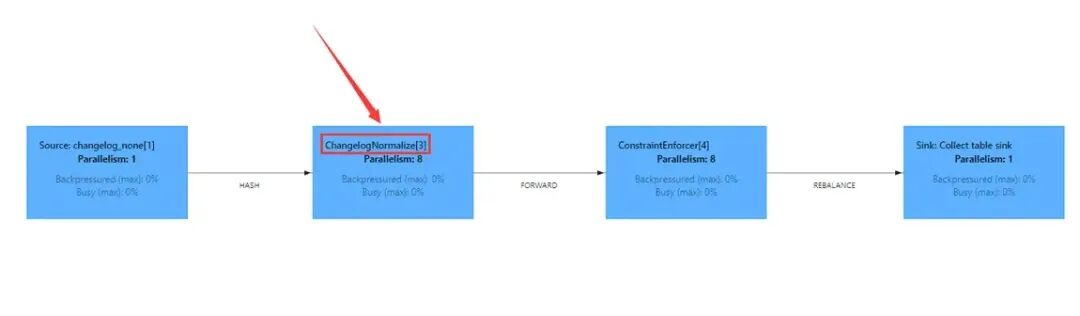
Paimon source 只能看到多个快照合并后的结果
假设你正在做sum(xx) group by yy 操作,如果你只能看到某条记录的最新值是5而看不到变化部分,你其实做不鸟任何事。因为你也不知道应该应该对这个sum的结果做啥操作。
Flink 内置了物化节点来持久化明细数据。
2.4.2 Input
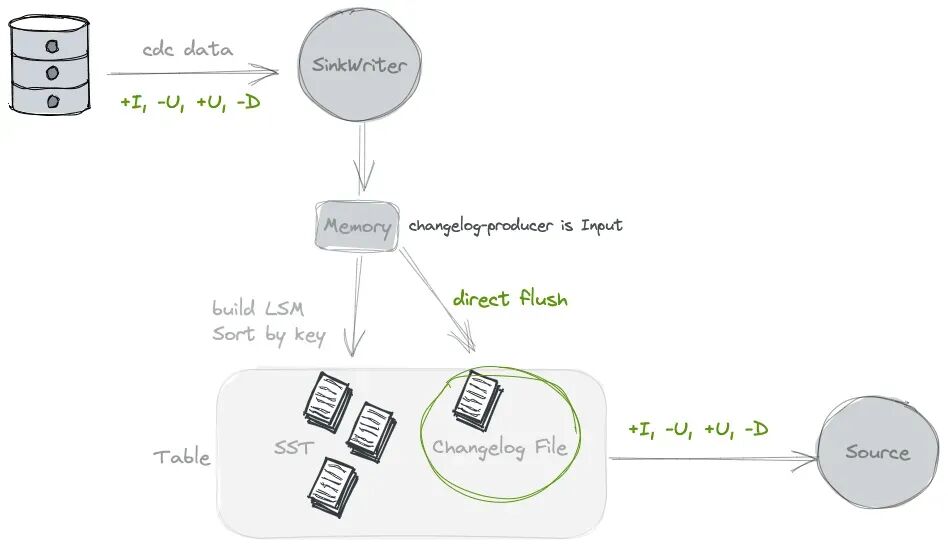
如果我们数据源中天然可以提供完整的 Changelog 数据,那么建议给存储数据的 Paimon 表设置changelog-producer=input。这样子在向 Paimon 表写入数据的时候,会同时将数据源中的 Changelog 也存储到 Paimon 表的 Changelog 文件夹中。这样子当下游任务读取这个 Paimon 表的时候就可以直接从表的 Changelog 文件中获取变更数据了,不再需要这个读取的流任务自己去维护数据明细和推导数据变更行为,因此资源消耗更少、效率也更高。
所下图中所示,这里 Changelog File 的生成方式是 direct flush,即没有做任何加工,直接从内存中刷进磁盘的。
2.4.3 Lookup
lookup 这种方式属于一种折中方案,如果数据源里无法提供完整的 Changelog 变更日志,那么就无法使用 input 模式,但我们又想摆脱昂贵的 Changelog Normalize 物化节点,这个时候就可以考虑上 lookup了。
更加详细一些来说,在向 Paimon 表写入数据的时候,通过一种类似于维表的点查机制,在每次提交 snapshot之前都会查找新增key的旧值,如果旧值不存在,则changelog为+I消息,如果旧值存在,则changelog为-U和+U消息。因此,无论上游是否为CDC数据源,lookup都会生成完整的changelog。(这里的关键点是,changelog数据是在我们向paimon表中写入数据的时候,作业每次创建检查点(checkpoint)时会触发小文件合并(compaction),并利用小文件合并的结果产生完整的变更数据,动作发生在产生snapshot之前)
但要注意的是,虽然lookup这种方式不产生 Changelog Normalize 物化节点,但是它在生成 Changelog File 的时候依然会消耗一部分资源,因为它需要触发数据的查找过程并进行判断才能补全一些-U行为,只不过资源消耗上要比 Changelog Normalize 物化节点这种方式低很多。
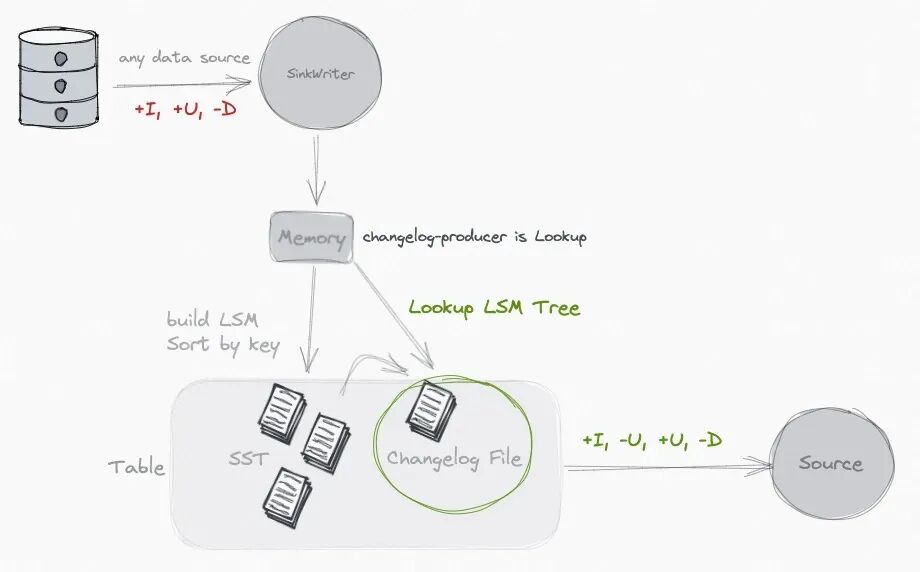
By specifying 'changelog-producer' = 'lookup', Paimon will generate changelog through 'lookup' before committing the data writing.
Lookup will cache data on the memory and local disk, you can use the following options to tune performance: 性能调优的几个手段:
|
Option |
Default |
Type |
Description |
|
lookup.cache-file-retention |
1 h |
Duration |
The cached files retention time for lookup. After the file expires, if there is a need for access, it will be re-read from the DFS to build an index on the local disk. |
|
lookup.cache-max-disk-size |
unlimited |
MemorySize |
Max disk size for lookup cache, you can use this option to limit the use of local disks. |
|
lookup.cache-max-memory-size |
256 mb |
MemorySize |
Max memory size for lookup cache. Paimon 维表的内存缓存大小。 该参数值会同时影响 Paimon 维表缓存大小和lookup changelog-producer 的缓存大小,两个机制的缓存大小都由该参数配置。 |
Full-compaction changelog-producer supports changelog-producer.row-deduplicate to avoid generating -U, +U changelog for the same record.
(Note: Please increase 'execution.checkpointing.max-concurrent-checkpoints' Flink configuration, this is very important for performance).
2.4.4 Full-Compaction
full-compaction 的使用背景和 lookup 一样,都是在数据源无法提供完整的 changelog 变更日志时,使用 full-compaction 可以为任何类型的数据源生成完整的 changelog 日志。但是 full-compaction 和lookup 不一样的地方在于,full-compaction 消耗的资源更少,不过对应的它也带来一些延迟的副作用。
更加详细一些来说,full-compaction 将写入数据和生成 changelog 这两个步骤解耦了,不再是写入数据创建检查点时候进行小文件合并。而是会先尽可能将数据写入 Paimon 表,当发生小文件全量合并时,paimon会比较两次完全压缩之间的结果并生成差异作为 changelog。那么,生成 changelog 的延迟就受到压缩频率的影响。
默认情况下,每1次的 checkpoint 都会有一次完全压缩然后产生一个 changelog。我们可以通过设置 full-compaction.delta-commits 参数值等于n(n默认值就是1),也就是,提交n次 checkpoint 才会触发一次full-compaction 并生成 changelog。当 n=1 的时候,对生成 changelog 的延迟没有特别大的影响。
值得注意的是,完全压缩是一个资源密集型的过程,会消耗一定的 CPU 和磁盘 IO。因此过于频繁的完全压缩可能会导致写入速度变慢。
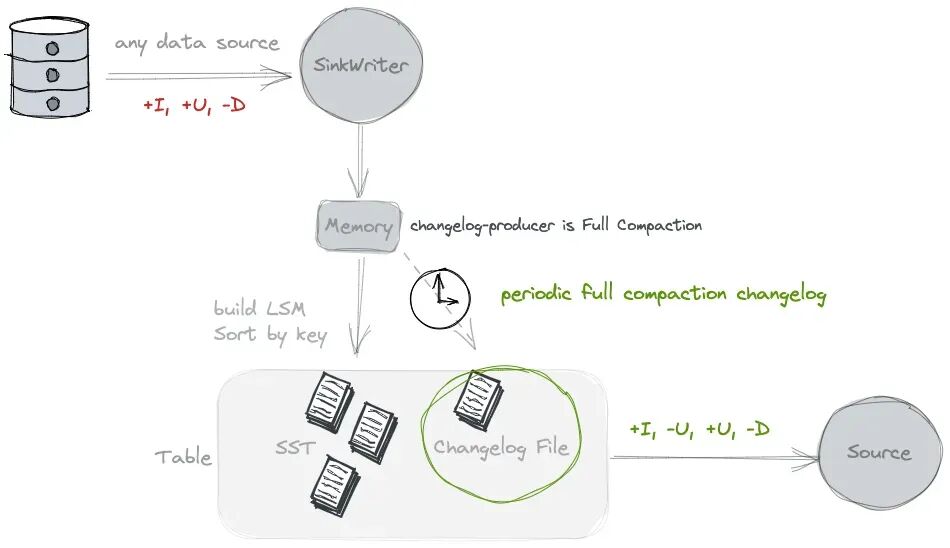
If you think the resource consumption of ‘lookup’ is too large, you can consider using ‘full-compaction’ changelog producer, which can decouple data writing and changelog generation, and is more suitable for scenarios with high latency (For example, 10 minutes). 更适合高延迟场景,比如10min延迟。
Full compaction changelog producer can produce complete changelog for any type of source. However it is not as efficient as the input changelog producer and the latency to produce changelog might be high.
Full-compaction changelog-producer supports changelog-producer.row-deduplicate to avoid generating -U, +U changelog for the same record.
(Note: Please increase 'execution.checkpointing.max-concurrent-checkpoints' Flink configuration, this is very important for performance).
full-compaction 会判断是否有低层数据写入,是否需要 compaction,如果有些分区没有低层数据写入,那边 Full-compaction 就不会涉及该分区。
2.4.5 总结
- 一句话:如果下游要通过流作业消费Paimon主键表,则此Paimon主键表需要设置「变更日志生成器」。
- 实际工作中,使用 'changelog-producer' = 'none' 的情况很少,因为成本太高。
- 如果数据源是完整的CDC数据,直接用input方式,成本最低,效率最高。
- 如果数据源无法提供完整的changelog,可以考虑使用lookup和full-compaction
- lookup机制的时效性更好,但总体来看耗费的资源更多。对数据新鲜度有较高要求(分钟级)的情况下使用。
- full-compaction机制的时效性较差,但它利用了文件全量合并过程,不产生额外计算,因此总体来看耗费的资源更少。推荐在对数据新鲜度要求不高(小时级)的情况下使用。延迟大小取决于delta-commits参数设置。
|
with参数 |
数据类型 |
默认值 |
备注 |
|
changelog-producer |
String |
none |
none、input、lookup、full-compaction |
|
scan.remove-normalize |
String |
主键 |
前提:changelog-producer='none' 消除none模式下的物化节点 |
|
lookup.cache-file-retention |
Duration |
1 h |
前提:changelog-producer='lookup' |
|
lookup.cache-max-disk-size |
MemorySize |
unlimited |
前提:changelog-producer='lookup' |
|
lookup.cache-max-memory-size |
MemorySize |
256 mb |
前提:changelog-producer='lookup' 该参数值会同时影响Paimon维表缓存大小和lookup changelog-producer的缓存大小,两个机制的缓存大小都由该参数配置。 |
|
full-compaction.delta-commits |
Integer |
1 |
前提:changelog-producer='full-compaction' Paimon在每N次作业的检查点执行小文件全量合并 |
|
changelog-producer.row-deduplicate |
Boolean |
False |
前提:changelog-producer='lookup'|'full-compaction' 推荐仅在无效变更数据较多的情况下使用该参数 |
|
execution.checkpointing.max-concurrent-checkpoints |
Integer |
?? |
前提:changelog-producer='lookup'|'full-compaction' |
2.5 Sequence and Rowkind 序列和行变更类型
When creating a table, you can specify the 'sequence.field' by specifying fields to determine the order of updates, or you can specify the 'rowkind.field' to determine the changelog kind of record. 人工指定记录的合并书序和人工指定记录的行变更类型两个能力。
2.5.1 Sequence Field 序列字段
By default, the primary key table determines the merge order according to the input order (the last input record will be the last to merge). 默认情况下,合并的顺序就是输入的顺序,最后一条记录会被最后合并。However, in distributed computing, there will be some cases that lead to data disorder. At this time, you can use a time field as sequence.field。 然后在分布式系统中,数据进来的顺序有可能是无序的。这时候,可以通过指定某个字段(大部分时候是时间字段)来让合并按照自己的意愿进行。
举例说明:
CREATE TABLE my_table (
pk BIGINT PRIMARY KEY NOT ENFORCED,
v1 DOUBLE,
v2 BIGINT,
update_time TIMESTAMP
) WITH (
'sequence.field' = 'update_time'
);The record with the largest sequence.field value will be the last to merge, if the values are the same, the input order will be used to determine which one is the last one. 被指定的字段,其值最大的记录就会成为最后被合并的字段。如果字段值相同,那么回到按照输入的顺序。
You can define multiple fields for sequence.field, for example 'update_time,flag', multiple fields will be compared in order. 也可以指定多个字段来一起控制合并的顺序。
简单来说就是一句话,具有相同主键的数据将按 <column-name> 这一列的值从小到大进行合并。具有最大 sequence.field 值的记录将是最后合并的记录。
2.5.2 Row Kind Field
By default, the primary key table determines the row kind according to the input row. You can also define the 'rowkind.field' to use a field to extract row kind. 默认情况下,主键表根据输入行来确定行类型。您也可以定义“rowkind.field”来使用一个字段提取行类型。
The valid row kind string should be '+I', '-U', '+U' or '-D'. 一共就四种类型:'+I', '-U', '+U', '-D'
上述描述中,所谓的 extract 可理解为提取,也就是说,我们可以直接定义某个记录里的某一个列的内容就是这一行数据的变更类型,拿出来即可用。我们不再让 Paimon 系统自己去判断(假设你用了lookup 或 full-compaction)。
2.5.3 总结:所有建表可用参数
|
with参数 |
数据类型 |
默认值 |
备注 |
|
sequence.field |
String |
无 |
默认按照数据流入进来的顺序。人工指定后,具有相同主键的数据将按 <column-name> 这一列的值从小到大进行合并。 |
|
rowkind.field |
String |
无 |
默认Paimon会自己推导。人工指定后,Paimon可以根据输入数据行中的一个字段来判断数据的行类型。 |
2.6 Deletion Vectors 删除向量
The Deletion Vectors mode is designed to takes into account both data reading and writing efficiency. 该设计是为了同时兼顾读写效率。
In this mode, additional overhead (looking up LSM Tree and generating the corresponding Deletion File) will be introduced during writing, but during reading, data can be directly retrieved by employing data with deletion vectors, avoiding additional merge costs between different files. 在这种模式下,在写入过程中将引入 额外的开销(查找LSM树并生成相应的删除文件),但在读取时,可以通过使用带有删除向量的数据直接检索数据,避免了不同文件之间的额外合并成本。(备注:这里又是一个平衡,通过在写入的时候附带一些额外开销,提升读取时RT)
Furthermore, data reading concurrency is no longer limited, and non-primary key columns can also be used for filter push down. Generally speaking, in this mode, we can get a huge improvement in read performance without losing too much write performance. 此外,数据读取并发不再受限制,非主键列也可以用于过滤器下推。一般来说,在这种模式下,我们可以在不过多牺牲写性能的情况下,获得巨大的读性能提升。
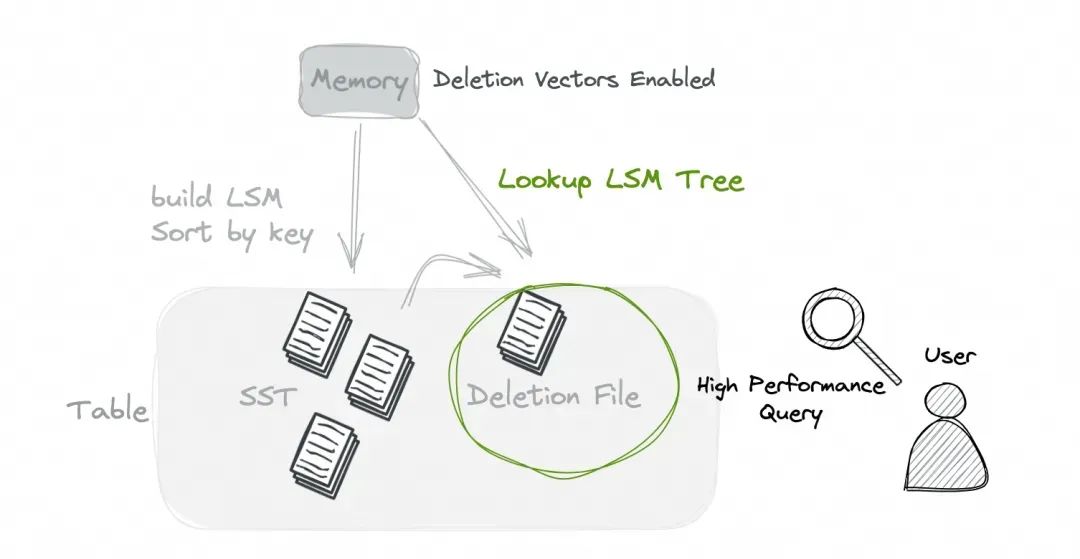
By specifying 'deletion-vectors.enabled' = 'true', the Deletion Vectors mode can be enabled. 配置deletion-vectors这个参数即可开启该能力。
但是该能力开启有四大限制:
- changelog-producer needs to be none or lookup. 变更日志生成器必须是none或lookup
- changelog-producer.lookup-wait can’t be false. 这个参数不能是false
- merge-engine can’t be first-row, because the read of first-row is already no merging, deletion vectors are not needed. 合并引擎不能是first-row
- This mode will filter the data in level-0, so when using time travel to read APPEND snapshot, there will be data delay. 该模式下时间旅行读取快照,会有延迟。
所有建表可用参数
|
with参数 |
数据类型 |
默认值 |
备注 |
|
deletion-vectors.enabled |
Boolean |
false |
默认不开启删除向量能力。打开以后,可以提升读性能同时不过分牺牲写性能。 |
2.7 Read Optimized 读优化
对于paimon主键表,本质是一个 MergeOnRead 技术。在读取数据时,很多层的 LSM 数据会合并,合并的并行度受到 buckets 数量限制。尽管 Paimon 的合并性能很高效,但仍然赶不上普通的仅追加(AppendOnly)表。
We recommend that you use Deletion Vectorsmode. 推荐使用'deletion-vectors.enabled' = 'true'。
If you don’t want to use Deletion Vectors mode, you want to query fast enough in certain scenarios, but can only find older data, you can also: 如果你不想使用'deletion-vectors,但你又想在部分场景下查询够快,且还接受只能查旧数据的话,你可以操作如下:
- Configure ‘compaction.optimization-interval’ when writing data. For streaming jobs, optimized compaction will then be performed periodically; For batch jobs, optimized compaction will be carried out when the job ends. (Or configure 'full-compaction.delta-commits', its disadvantage is that it can only perform compaction synchronously, which will affect writing efficiency)
在写入数据时配置 ‘compaction.optimization-interval’。对于流处理作业,全量压缩将定期进行;对于批处理作业,全量压缩将在作业结束时执行。(或者配置'full-compaction.delta-commits',其缺点是它是同步的不是异步的,这将影响写入效率)
- Query from read-optimized system table. Reading from results of optimized files avoids merging records with the same key, thus improving reading performance. 从read_optimized表来读取,读该表可以避免合并。
You can flexibly balance query performance and data latency when reading. 在读取时,你可以灵活地平衡查询性能和数据延迟。
1:读优化最基础的方法,是调整 Paimon source 的并发数。参数'scan.parallelism' = 'xx' 即可。
2:Paimon 默认处理小文件并提供良好的读取性能。请不要在没有任何要求的情况下配置此Full Compaction选项,因为它会对性能产生重大影响。
3:所谓的读优化,其本质就是和写入效率进行权衡取舍。
总结:所有建表可用参数
|
with参数 |
数据类型 |
默认值 |
备注 |
|
compaction.optimization-interval |
Duration |
(none) |
Implying how often to perform an optimization compaction, this configuration is used to ensure the query timeliness of the read-optimized system table. 这个配置用于指明多久执行一次优化压缩,用以确保读优化系统表的查询时效性。(注意:这是异步进行的全量压缩,建议配置间隔30min以上,因为全量合并真的很吃资源) |
|
full-compaction.delta-commits |
Integer |
(none) |
Full compaction will be constantly triggered after delta commits. (注意:这是同步进行的全量压缩) |

数据体系构建 👇
--END--

非常欢迎大家加我个人微信,有问题欢迎找我交流

更多精彩👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)