【Luck-Report】表达式

导航:LuckReport专栏
本文转载自 W3Cschool,原文链接:ureport2表达式,版权归原平台所有,仅用于技术交流学习,禁止商用。
一、快速了解
项目简介
Luck-Report 是一款基于开源项目 UReport2 重构的 Java 高性能报表引擎,通过迭代单元格可以实现任意复杂的中国式报表。相较于 UReport2,Luck-Report 在技术架构上进行了全新升级,后端基于 SpringBoot 框架开发、前端采用 Vue 框架构建,技术选型贴合当下主流项目开发标准,可精准适配各类实际开发需求。
Luck-Report 提供了全新的基于网页的报表设计器,可以在 Chrome、Firefox、Edge 等各种主流浏览器运行(IE 浏览器除外)。使用 Luck-Report,打开浏览器即可完成各种复杂报表的设计制作。
Luck-Report 基于 Apache-2.0 开源协议开源
在线体验
- 体验地址:https://www.quzhe.top/luck-report/report/designer
- 源码地址:https://gitee.com/LuckyPools/luck-report
- 文档地址:https://www.quzhe.top/luck-report-blog/report
二、表达式
在报表使用过程当中,不可避免的要使用函数及表达式实现一些数据的计算,在 Luck-Report 当中,很多地方都支持编写表达式,比如最典型的我们可以将单元格类型改为 “表达式”,这样就可以在下面的表达式编辑器里输入相应的表达式与函数,除此之外,Luck-Report 还允许我们在条件、图片来源、二维码数据来源等地方使用表达式,所以学习并掌握 Luck-Report 中提供的表达式,是制作复杂报表的前提。
# 基本语法
与一般的编程语言类似,Luck-Report 中的表达式也有一些基本的数据类型,比如数字、字符串等,如下表所示:
| 表达式类型 | 描述 | 示例 |
|---|---|---|
| 数字 | 可以是一个整数,也可以是一个小数 | 1、123、0.121331,这些都是合法的数字 |
| 字符串 | 字符串需要用单引号或双引号包裹 | “Luck-Report”、‘Luck-Report 教程’,这些都是合法的字符串 |
| 布尔值 | 布尔值表示是或否 | 布尔就两个:true 和 false |
上述的有三种基本的数据类型,可以单独使用,也可以用 “+”、“-”、“*”、“/”、“%” 连接,进行组合运算,如下表所示:
| 操作符 | 描述 | 示例 |
|---|---|---|
| + | 求两个数的和,或者是连接两个值 | 21+31,这就表示求这两个数的和,结果就是 52,“值:”+331 则表示连接两个值,其结果就是 “值:331” |
| - | 求两个数差 | 21 - 31,这就表示求这两个数的差,结果就是 - 10 |
| * | 求两个数的乘积 | 3*6,结果就是 18 |
| / | 求两个数除的结果 | 6/3,结果就是 2,如果除不尽,则会保留 8 位小数 |
| % | 求两个数除的余值 | 5%3,结果是 2;6%2 结果是 0 |
Luck-Report 中还提供了几种类型的条件判断运算符,我们首先来看一下三元表达式。
# 三元表达式
基本所有的语言都支持三元表达式判断,它的特点是简洁明晰,可以用最少的代码进行条件判断,Luck-Report 中的三元表达式语法结构如下图所示:

可以看到,和普通的三元表达式一样,它的第一部分是条件部分,条件部分可以有多个条件(用 and 或 or 连接),“?” 后面是条件满足后执行并返回的表达式部分,“:” 后面则是条件不满足时执行返回的表达式部分。
| 三元表达式示例 | 说明 |
|---|---|
| A1>1000 ? “正常值” : “低值” | 表达式计算时,先取到 A1 单元格的值,判断值是否大于 1000,如果是返回 “正常值” 字符串,否则返回 “低值” 字符串 |
| A1>1000 and A1<20000 ? “正常值” : “修正值:”+(A1+100) | 条件部分,判断 A1 值是否大于 1000 且小于 20000,如果是返回 “正常值”,否则返回字符串”修正值 “与 A1 值加 100 后结果连接的值,如果 A1 是 2000,那么就返回” 修正值:2100“ |
# if 判断
Luck-Report 中 if 判断表达式语法结构如下图所示:
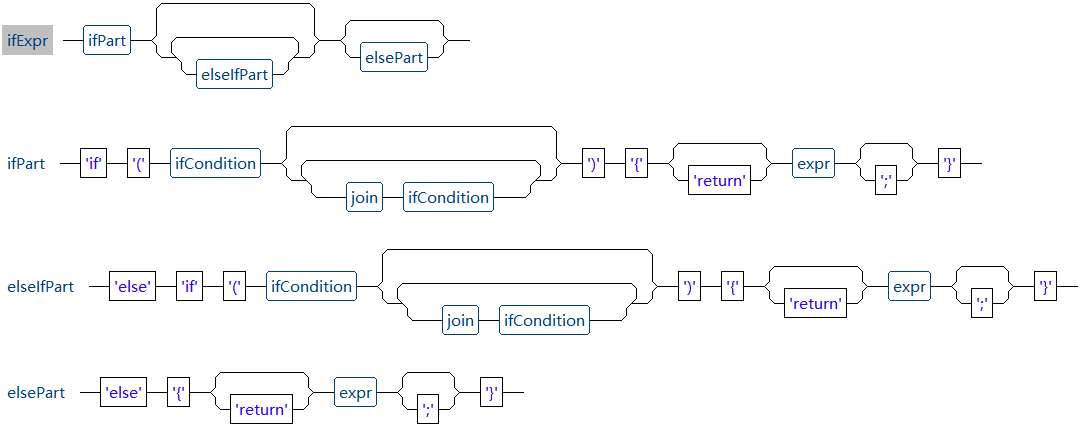
从图中可以看到,if 判断表达式则一个 if 条件判断部分加若干个可选的 elseif 条件判断部分,最后再加一个可选的 else 部分构成,语法结构类似 java 或 javascript。
| if 判断表达式示例 | 说明 |
|---|---|
| if(A1>1000){return “正常值”} | 判断 A1 单元格的值是不是大于 1000,如果是返回” 正常值 “字符串,否则什么都不做 |
| if(A1>1000){return “正常值”}else{“低值”;} | 判断 A1 单元格的值是不是大于 1000,如果是返回”正常值 “字符串,否则返回” 低值“字符串。这里需要注意的是,在 if 表达式中,return 关键字是可选的,同是行尾添加’;'也是可选的,这主要是为了照顾一些 java 及 javascript 程序的习惯 |
| if(A1>1000 and A1<20000){return “正常值:”+A1}else if(A>20000 and A1<40000){return “超高值”}else{“低值”} | 在这个例子当中,条件部分添加了多个组合条件,同时 else if 多重判断 |
# case 判断
case 判断是 Luck-Report 中提供的另一种条件判断形式,与 if 判断有些类似,但 case 判断看起来更为简洁,其语法结构图如下所示:
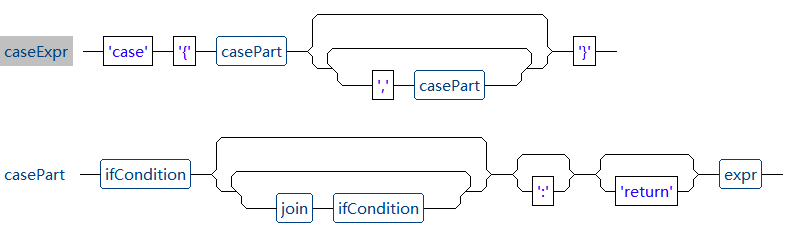
可以看到,case 判断要由 case{…} 包裹,然后是若干条件加返回值。
| case 表达式示例 | 说明 |
|---|---|
| case{A1==100 return “正常值”,A1>100 and A1<1000return ‘偏高’} | 有两个条件,分别返回不同的值 |
| case{A1==100 return “正常值”,A1>100 and A1<1000’偏高’} | 在 case 表达式中,return 关键字同样是可选的 |
# 单元格引用
在报表当中,大多数的计算都是针对单元格或与单元格有关,因为报表中单元格多数都与数据绑定,而数据往往又是多条,所以计算后的报表一个单元格会产生多个,这样对于单元格的引用就变的比较复杂。在 Luck-Report 中,引用的目标单元格是相对当前单元格来进行计算的,引用方法就是直接在表达式里书写单元格名称,比如引用 A1 单元格,就直接写 A1 即可,如下面的例子:

在上图当中,我们在 D1 单元格中输入表达式 A1,这就表示,在 D1 单元格里填入相对当前 D1 单元格的 A1 单元格的值,运行后的效果如下:
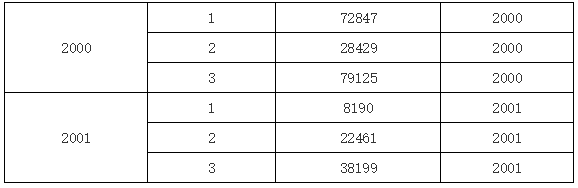
可以看到,因为 D1 是 A1 的子格,A1 单元格绑定的数据就是分组结构,根据当前 D1 单元格的位置,就产生的上图所示的结果。如果在 D1 单元格中输入 B1,那么运行后的效果又是下图的样子:
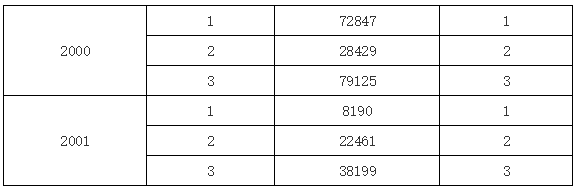
同样,如果在 D1 中输入表达式 C1,那么运行后将会在每个 D1 单元格中填入与 D1 单元格位于同一行的 C1 单元格的值,运行结果这里就不再贴出来了。
通过上面的例子我们可以看到,Luck-Report 中某个单元格的表达式引用目标单元格,首先判断的是目标单元格与其所在单元格是否位于同一行或列,如果是则直接取对应行或列上目标单元格的值。如果当前单元格与目标单元格不在同一行或列,那情况又不一样了,我们来看下一个例子。

在上面的例子中,我们在 C2 单元格的表达式中输入 B1,表示取 B1 单元格的值,但 B1 单元格又和 C2 不在同一行或列上,同时 B1 单元格展开后会有多个值,但 B1 单元格和 C2 单元格都拥有一个共同的父格或间接父格 A1(C2 单元格的左父格是 B2,而 B2 单元格的左父格又是 A1,所以 A1 是 C2 单元格的间接左父格),所以它会取他们共同父格 A1 下所有 B1 的值,运行结果如下图所示:
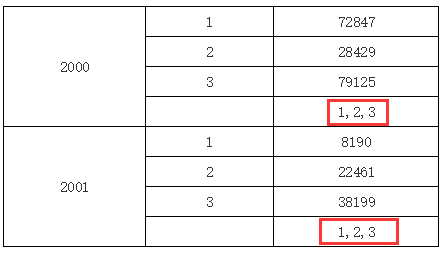
多个值的输出在 Luck-Report 中,如果取到值超过一个,输出时多个值间以 “,” 分隔,如上图所示
目标格获取原则由上面的例子可以看出,Luck-Report 中单元格表达式在取目标格值时,优先考虑的是目标格是否与其位于同一行或列,如果是则取与其位于同一行或列的目标单元格,如果不是,则取与当前单元格有共同父格的所有目标单元格,如果他们有共同的上父格或共同的左父格,那么就取共同上父格与共同左格交集部分的目标单元格;如果他们没有共同的父格,那么就取迭代后所有的目标单元格。
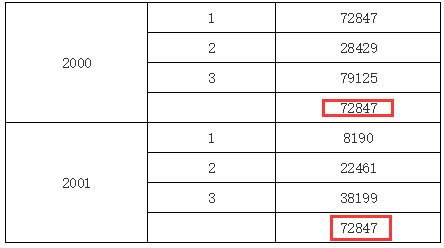
针对上面的例子,如果我们在上面的单元格中输入 C1,那结果又不一样;因为 C1 是 C2 的上父格,所以将直接取与其位于同一列的上父格单元格的值,运行效果如下图所示:
再看下面的报表示例:
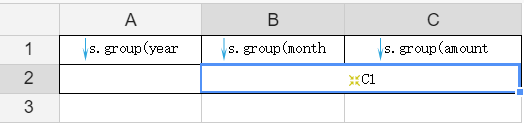
在上面的例子中,B2 单元格表达里输入 C1,因为 B2 和 C2 既不在同一行或列,也没有共同的父格,所以 B2 中将取到所有的 C1 单元格的值,如下图所示:
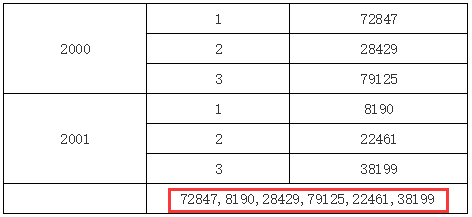
更改父格实现单元格取值在之前的视频教程中,在介绍报表计算模型时,我们多次利用更改当前单元格的上父格或左父格使得当前单元格与目标格处于某个特定的父格下,其原理就来自于此。
# 单元格坐标
为了实现更为复杂的单元格引用,Luck-Report 引用了单元格坐标的概念。单元格坐标,也是相对于当前单元格来进行计算的,同样遵循上面的介绍的优先取同行、同列或共同父格的原则,一个标准的单元格坐标格式如下:
单元格坐标格式单元格名称 [Li:li,Li-1:li-1,…;Ti:ti,Ti-1:ti-1…]{条件…}
L 表示左父格,l 表示左父格展示后的序号,序号为负值,表示向上位移;T 表示上父格,t 表示上父格展开后的序号,序号为负值,表示相对于当前单元格向上位移,正值则表示向下位移,如果只有左父格,那么直接写 L 部分即可;如果只是上父格,那么前面需要加上 “;” 号,然后写 T 部分,后面的大括号中是条件部分,多个条件之间用 and/or 连接,表示对通过坐标取到的单元格进行条件过滤(如果取到多个单元格的话),条件部分是可选的,相关示例如下:
| 单元格坐标示例 | 说明 |
|---|---|
| C1[A1:2,B1:1] | 在找 C1 时先找单元格 A1 展开后的第 2 格;再找第二个 A1 下的 B1 单元格展开后的第一个单元格,然后再找这个 B1 单元格对应的 C1 单元格 |
| C2[A1:2,B1:2;C1:3] | 在找 C2 时,先找 A1 单元格展开后的第二格,再找第二个 A1 单元格下 B2 单元格展开后的第二格,再根据第二个展开的 B2 单元格找其下名为 C2 单元格的左子格;然后再找到 C1 单元格展开后的第三格,再看其下的 C2 单元格,取 C2 单元格的交集 |
| C2[A1:2,B2:2]{C2>1000} | 表示取 A2 单元格展开后的第二格,再取其下 B2 单元格展开后第二格,再取 B2 下所有的 C2 单元格,最后再对取到的 C2 单元格进行条件过滤,只取出 C2 单元格值大于 1000 的所有 C2 单元格。 |
| C2[A1:2,B2:2]{C2>1000 and C2<10000} | 表示取 A2 单元格展开后的第二格,再取其下 B2 单元格展开后第二格,再取 B2 下所有的 C2 单元格,最后再对取到的 C2 单元格进行条件过滤,只取出 C2 单元格值大于 1000 且小于 10000 的所有 C2 单元格的值。 |
我们来看一个具体的示例,报表模版如下:

在上面的报表模版中,在 B2 单元格表达式里,我们输入了 C1[A1:2,B1:1],这就表示取 A1 单元格展开后第二格下 B1 单元格展开后第一格下对应的 C1 单元格的值,所以运行后我们可以看到如下图所示效果:
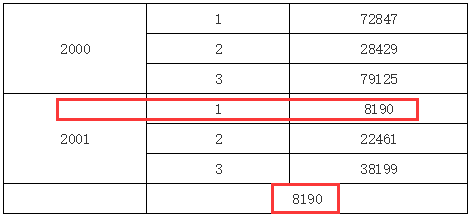
当然,我们可以做一个交叉表,然后通过添加左父格和上父格约束坐标来定位某个特定单元格,这里就不再演示了。在实际应用当中,单元格坐标可以用在诸如同比,环比之类的统计报表当中,这时单元格坐标序号会用一些负值相对当前单元格进行位移,从而实现各种比值的计算。
引用所有单元格如果我们需要引用所有单元格时,那么只需要在单元格名称后跟”[]“即可,如 A1[],表达引用所有 A1 单元格,而不管当前引用格所在位置,同时在引用所有单元格时,还可以后跟条件,以对引用格做进一步条件限制,如 A1[]{@>1000 and @<10000},表示要引用所有的 A1 单元格,但要求引用的 A1 单元格值要大于 1000 同时小于 10000,这里的 @符号是 2.2.3 及以后版本新增加的一个表达式符号,专门用于取条件循环中当前循环对象。
我们首先来看一个环比的例子。
# 环比
报表模版如下图所示:

在上面的报表模版中,D2 单元格中的表达式为 C2 - C2[A2:-1] ,这就表示在 D2 单元格中首先取到 C2 单元格的值, 因为 C2 单元格与 D2 位于同一行,所以可以直接取到,且只有一个;下一个 C2 采用了坐标 A2:-1,那就表示取相对于当前单元格的 A2 单元格上一格 (负值表示向上位移) 的 A2 单元格所对应的 C2 单元格,运行后的效果如下图所示:
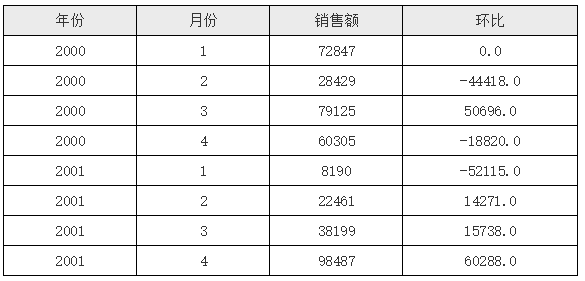
从运行结果中可以看到,第一行环比的值为 0,这是因为对于第一行的 D2 单元格来说,其上一行其实是不存在的,所以 Luck-Report 默认就取了第一个 C2 单元格的值,所以两个值减下来就是 0。
下一个例子我们来看看同比。
# 同比
报表模版如下图所示:

在上面的模版当中,D2 单元格中首先取到与其同行的 C2 单元格的值,然后利用单元格坐格,先取到当前 D2 单元格所在行的 A2 单元格的上一条 A2 单元格记录(-1 表示坐标上移),然后再取这个 A2 下对应的 C2 单元格,但由于其下 C2 单元格还是有多个,所以这里加了个条件 B2== B 2 ,这里的第一个 B 2 表示当前单元格所在行对应的 B 2 的值, B2,这里的第一个 B2 表示当前单元格所在行对应的 B2 的值, B2,这里的第一个B2表示当前单元格所在行对应的B2的值,B2 表示坐标定位后 C2 单元格对应的 B2 单元格的值,条件就是他们俩要相等,实际上就是月份相等,这样就达到了我们要实现的同比的目的,运行后的效果如下:
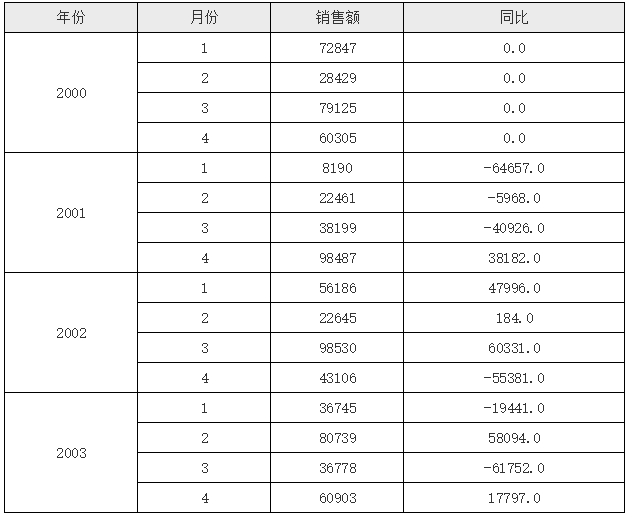
关于 $B2 在 Luck-Report 当中,在单元格名称前加 $ 符号,表示取相对于目标单元格的单元格的值,多用在条件比较当中,比如上面的 C2[A2:-1]{B2==$B2},这里的 $B2 就是指取到的 C2 单元格对应的 B2 单元格的值。
在上面的例子中,第一个分组 2000 下,所有的同比值都为 0,这是因为这个分组下不存在 A2:-1 这个坐标,没法上移,所以系统默认取了当前记录自身,所以计算后的值都是 0。如果我们不希望显示 0,那么可以加个 if 条件判断表达式,如果当前位于第一个分组,就输出空字符串,否则输出实际计算后的值,修改后的报表模版如下图所示:

D2 单元格对应的表达内容如下图所示:

运行后的效果如下图所示:
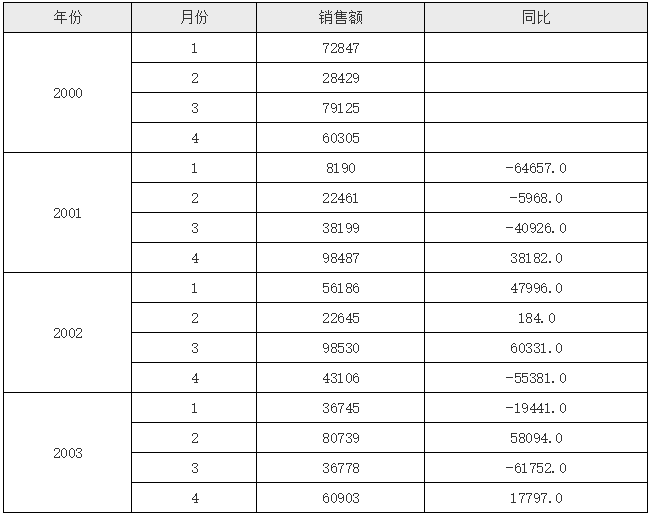
在上面的例子中,我们使用了 if 判断表达式,当然你也可以换成三元表达式判断或 case 判断,在这个 if 判断中,首先我们判断的是 &A2==1 是否成立,这里的 &A2 指的是相对于当前单元格 A2 单元格展开后的序号,在 Luck-Report 中,可以采用 “& 单元格名称” 的方式标记某个单元格展开后的序号,需要注意的是,使用 “& 单元格名称” 来标记目标单元格展开后的序号时,当前单元格必须是目标单元格的子格或间接子格;比如,在上面的例子中,使用 &A2 的单元格是 D2,D2 是 A2 单元格的间接子格,这样就可以正确取到 A2 展开后的序号值。
关于 & 标记的使用
在使用 “& 单元格名称” 来标记目标单元格展开后的序号时,除上需要注意上面描述的内容外,还需要注意,取序号将以他们共同的父格为基准,如果他们有共同的父格,那么将以这个父格里目标单元格的数量来进行序号编排,这在之前视频教程介绍报表计算模型中,实现明细型主从报表,对从表数据进行编号时就有体现。
# 逐层累加
报表模版如下图所示:

D2 单元格对应的表达式如下:

在上面的表达式中,我们采用了 if 判断(同样你可以换成三元判断或 case 判断),当相对当前单元格 A2 展开后的序号为 1 时,那么直接取当前行的 C2 单元格值,否则就拿当前行的 C2 单元格值加上,上一行 D2 单元格值,这样就实现了逐层累加的需求,运行后的效果如下:
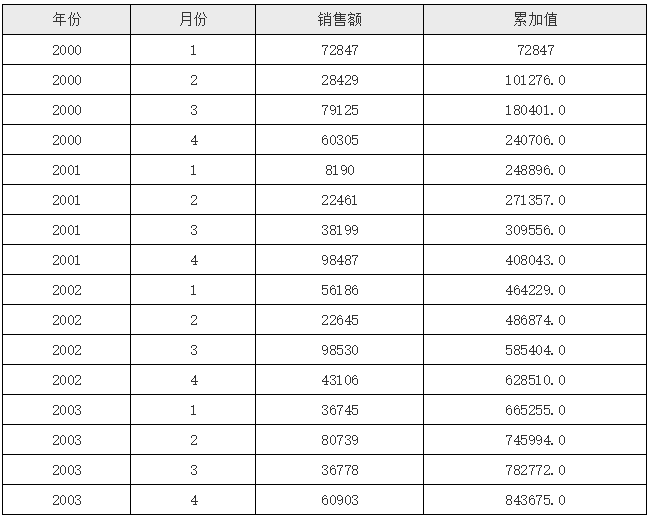
### 数据集表达式
数据集是报表展示数据的来源,一般情况,定义好数据集后,在数据集对应的字段上双击即可在目标单元格上添加对应的数据绑定信息,然后在其属性面板设置聚合方式、迭代方向等。实际上,在 Luck-Report 中,还允许我们在单元格表达式里通过书写表达式来实现单元格与数据集字段的绑定,其语法结构如下:
数据集名称. 聚合方式 (字段名 [条件, 排序方式])
聚合方式与我们双击添加字段绑定后在属性面板上看到的聚合方式基本一致,具体有以下几种类型。
# select(罗列数据)
语法格式如下:
datasetName.select(propertyName,filter,order)
filter 为条件部分,条件可以有多个,多个条件之间用 and 或 or 连接,order 为是否对当前的 propertyName 进行排序,可选值有两个 desc 和 asc,既正序和倒序。
| 示例 | 说明 |
|---|---|
| ds1.select(username) | 取数据集 ds1 中所有的 username 字段信息 |
| ds1.select(username,age>18) | 取数据集 ds1 中所有的 age 属性大于 18 的 username 字段信息 |
| ds1.select(username,age>18, desc) | 取数据集 ds1 中所有的 age 属性大于 18 的 username 字段信息,同时对 username 字段做倒排序 |
| ds1.select(username,age>18 and age<60, asc) | 取数据集 ds1 中所有的 age 属性大于 18 且小于 60 的 username 字段信息,同时对 username 字段做正排序 |
# group(分组罗列数据)
语法格式如下:
datasetName.group(propertyName,filter,order)
filter 为条件部分,条件可以有多个,多个条件之间用 and 或 or 连接,order 为是否对当前的 propertyName 进行排序,可选值有两个 desc 和 asc,既正序和倒序。
| 示例 | 说明 |
|---|---|
| ds1.group(degree) | 对数据集 ds1 中 degree 字段进行分组 |
| ds1.group(degree,age>18) | 对数据集 ds1 中 age 属性大于 18 的所有的 degree 字段进行分组 |
| ds1.group(degree,age>18, asc) | 对数据集 ds1 中 age 属性大于 18 的所有的 degree 字段进行分组,同时对分组后的 degree 字段进行正排序 |
# sum(累加数据)
sum 是对数据集目标字段进行累加,所以目标字段一定要是一个数字类型,否则就会产生错误,其语法格式如下:
datasetName.sum(propertyName,filter)
与之前函数不同之处在于,sum 函数没有 order,也就是说不需要排序,原因很简单,因为累加后的值只有一个,所以无需排序。
| 示例 | 说明 |
|---|---|
| ds1.sum(salary) | 对于数据集 ds1 中的 salary 字段进行累加 |
| ds1.sum(salary, age>30) | 对数据集 ds1 中 age 属性大于 30 的所有对象的 salary 字段进行累加 |
# count(统计数量)
count 是对数据集对象数量进行统计,其语法格式如下:
datasetName.count(filter)
统计数量不需要指定 propertyName 及 order。
| 示例 | 说明 |
|---|---|
| ds1.count() | 对 ds1 数据集中对象数量进行统计 |
| ds1.count(age>30) | 统计数据集 ds1 中对象属性 age 值大 30 的所有对象的数量 |
# max(取最大值)
max 语法格式如下:
datasetName.max(propertyName,filter)
取最大值没有 order。
| 示例 | 说明 |
|---|---|
| ds1.max(salary) | 对于数据集 ds1 中的 salary 字段进行比较,取最大值 |
| ds1.max(salary, age>30) | 对数据集 ds1 中 age 属性大于 30 的所有对象的 salary 字段进行比较,取最大值 |
# min(取最小值)
min 的语法格式如下:
datasetName.min(propertyName,filter)
取最小值没有 order。
| 示例 | 说明 |
|---|---|
| ds1.min(salary) | 对于数据集 ds1 中的 salary 字段进行比较,取最小值 |
| ds1.min(salary, age>30) | 对数据集 ds1 中 age 属性大于 30 的所有对象的 salary 字段进行比较,取最小值 |
# avg(取平均值)
avg 在取平均值时,如除不尽,则保留 8 位小数,avg 的语法格式如下:
datasetName.avg(propertyName,filter)
取平均值没有 order。
| 示例 | 说明 |
|---|---|
| ds1.avg(salary) | 对于数据集 ds1 中的 salary 字段取平均值时,如除不尽,则保留 8 位小数 |
| ds1.avg(salary, age>30) | 对数据集 ds1 中 age 属性大于 30 的所有对象的 salary 字段取平均值时,如除不尽,则保留 8 位小数 |
# 取当前单元格值
在 Luck-Report 中提供了一种特殊的表达式,用来取当前单元格值,它就是 “#”,比如在给某个单元格配置链接时,我们可能需要将当前单元格值作为参数传递给这个链接,那么就可以在链接表达式里输入 #,这就将会将当前单元格值取出来,传递过去,如下图所示:
除此之外,如果在 #后面加上. 后接具体的属性名,那么还可以取到与当前单元格绑定的数据对象的具体属性值,如:#.id,表示取与当前单元格绑定的对象的 id 属性值,当然如果当前单元格内容不是一个数据集类型的,那么就会返回 null,同样如果当前单元格绑定的数据集属性运行时值有多个,那么它只会取第一个对象的对应的属性值。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)