高通技术公司携手Nexa AI与Docker,以面向Linux的NexaSDK将AI带入物联网与机器人领域

直接在边缘和物联网设备上运行多模态AI模型正迅速成为主流方案,因为这种方式可以提供低延迟响应,将敏感数据保存在本地,并且即使在连接受限或离线时也保持可靠性。
而真正的核心驱动力是NPU:专门为AI推理而设计的NPU提供的效能功耗比要明显优于仅使用CPU/GPU的设置,这意味着更快的推理速度、更低的热量、更长的电池寿命,以及在边缘功率和热限制范围内可以匹配的真正“永远在线”AI体验。
高通技术公司与Nexa AI和Docker进行合作,借助面向Linux操作系统的NexaSDK,使NPU 优先的部署方式变得落地实用。
这是一种单一、统一的推理引擎,在NPU、GPU和CPU范围内运行开发者所需要的最新模型 – 大模型、视觉语言模型、语音、嵌入/重排序、和视觉模型。
通过一个简单的Docker工作流,可以实现干净的设置和重复性能表现。开发者无需将驱动程序、运行时、和每个模型粘合在一起,只需拉取一个镜像,就可以在最新的物联网设备上运行针对高通Hexagon NPU进行了本地优化的现代多模态模型。
对于Linux操作系统,NexaSDK重点支持高通的两种旗舰型物联网平台,即:高通跃龙IQ9平台和高通跃龙第2代RB3开发套件。
高通跃龙IQ9系列平台专为高性能工业和边缘人工智能工作负载而设计。该平台采用运行速频率高达2.36 GHz的八核高通Kryo第6代CPU,运行频率高达800 MHz的高通Adreno 663 GPU,以及算力在50到100稠密TOPS之间的高通Hexagon NPU。

IQ9平台细节图
高通跃龙第2代RB3开发套件面向机器人、视觉AI和智慧安保等应用场景,为边缘计算开发者提供了一个易于使用且灵活可扩展的开发平台。高通跃龙第2代RB3开发套件集成了多核CPU,用于图形和辅助计算的Adreno GPU,以及算力高达12稠密TOPS的Hexagon NPU。

高通跃龙第2代RB3套件
基于Docker、可用于物联网设备的NexaSDK
Linux物联网环境经常受到操作系统和驱动碎片化问题,特别是在部署NPU加速AI推理工作负载时。Linux发行版、内核版本和供应商特定驱动程序之间的差异,加上复杂的AI运行时依赖关系,使得大规模部署、优化、可再现性变得困难。
NexaSDK Docker镜像提供了针对搭载Hexagon NPU的Linux ARM64兼容系统进行优化的容器化AI运行时,从而可以通过统一的推理接口直接调用Hexagon NPU、CPU和GPU的算力。
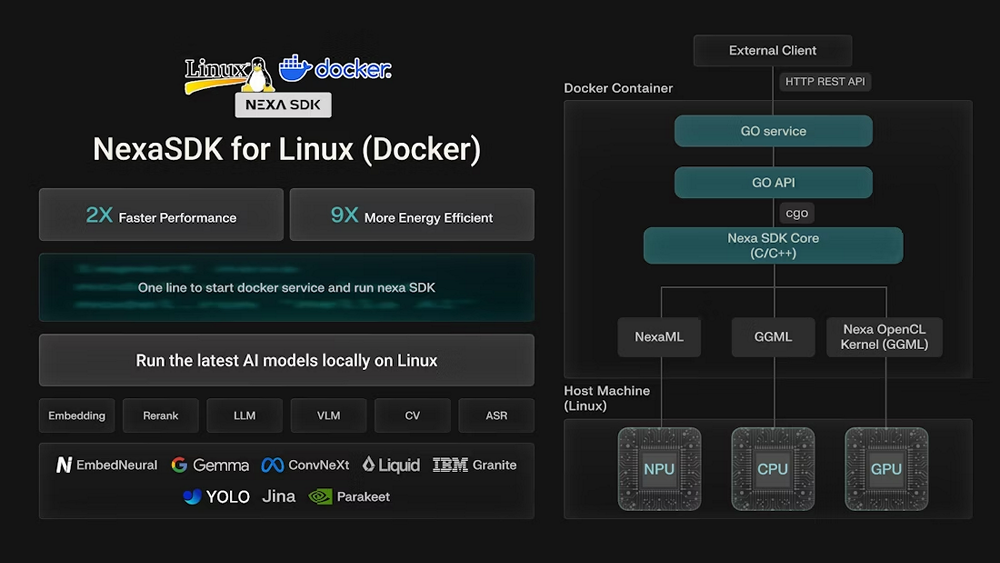
面向Linux的NexaSDK(Docker)架构图
NexaSDK提供了适用于各种Linux发行版的一致运行时,将应用程序与操作系统依赖项隔离,并无需手动配置 NPU 软件栈。
具体来说,面向Linux操作系统的NexaSDK具有以下优势:
- 适用于各种设备和Linux发行版的一致运行时。
- 与操作系统依赖项隔离,无需手动设置NPU堆栈,只需一个docker运行命令即可快速上手。
- 支持多种模型类型:大模型、视觉语言模型、嵌入、重排序、计算机视觉和自动语音识别模型。
- 通过从Docker Hub提取新的Docker镜像,轻松更新SDK。
利用面向Linux操作系统的NexaSDK运行模型
通过高通技术公司与Docker公司及Nexa AI的合作,NexaSDK使用基于Docker的虚拟化技术来避免Linux操作系统设置的复杂性,同时在高通技术公司平台上实现一致的性能。
NexaSDK支持交互模式和服务器模式。以IBM Granite-4-350M模型为例,开发者可以直接在交互式命令行界面(CLI)中运行模型,或者将其部署为持久的REST服务。您可以参考SDK文档,以了解详细信息。
开始使用
1. 交互式命令行界面(CLI)模式
Bash
export NEXA_TOKEN="YOUR_LONG_TOKEN_HERE"
docker run --rm -it --privileged \
-v /etc/machine-id:/etc/machine-id:ro \
-e NEXA_TOKEN \
nexa4ai/nexasdk:latest infer NexaAI/Granite-4.0-h-350M-NPU
2. 服务器(REST API)模式:
export NEXA_TOKEN="YOUR_LONG_TOKEN_HERE"
docker run --rm -it --privileged \
-v /etc/machine-id:/etc/machine-id:ro \
-e NEXA_TOKEN \
nexa4ai/nexasdk:latest pull NexaAI/Granite-4.0-h-350M-NPU
docker run --rm -d -p 18181:18181 --privileged \
-v /etc/machine-id:/etc/machine-id:ro \
-e NEXA_TOKEN \
nexa4ai/nexasdk:latest serve
该视频演示演示了适用于大型语言模型、视觉语言模型、自动语言识别、和嵌入模型的CLI和服务器模式。
了解高通跃龙IQ9平台的视频
视频说明了企业应用程序中最丰富但最未充分利用的实时智能来源之一,它捕获了各个领域内(例如:安全操作、工业监控、零售分析、和智慧工作场所)有价值的视觉上下文和时间模式。
为了演示理解各项功能的实用视频,NexaSDK提供了一个在高通跃龙IQ9平台上运行的完整端到端演示,并由AutoNeural(Nexa AI的NPU原生1.5B-参数视觉语-言模型)提供支持。
该项演示获取上传的视频,以固定的间隔自动提取关键帧,并执行连续的视觉语言推理,从每个场景中生成有意义的人类可读见解。
结果通过基于Gradio的交互式用户界面实时传输。
通过结合高效的本地推理、低延迟响应、和多模态式理解,高通跃龙IQ9平台上的NexaSDK演示了如何将视频转换为一流的智能数据源,而不是静态记录。
Linux操作系统开发者快速入门
NexaSDK包含一个初学者指南,可确保大多数开发者快速运行测试构建。
所有NexaSDK Docker镜像版本均在Docker Hub上发布。
截至2025年12月,NexaSDK在物联网设备上支持以下模型。这些模型均在Huggingface上托管。
在高通跃龙IQ9平台上支持的模型
视觉语言模型(VLM)
- AutoNeural: NexaAI/AutoNeural
大模型(LLM)
- FM2.5-1.2B: NexaAI/LFM2.5-1.2B-npu
- FM2-1.2B: NexaAI/LFM2-1.2B-npu
- Granite-4.0-h-350M: NexaAI/Granite-4.0-h-350M-NPU
嵌入模型(嵌入)
- EmbeddingGemma-300M: NexaAI/embeddinggemma-300m-npu
- EmbedNeural: NexaAI/EmbedNeural
重排序模型(重排序)
· Jina-v2 Reranker: NexaAI/jina-v2-rerank-npu
自动语音识别
· Parakeet-TDT-0.6B-v3: NexaAI/parakeet-tdt-0.6b-v3-npu
计算机视觉模型(CV)
· YOLOv12: NexaAI/yolov12-npu
· RF-DETR Segmentation: NexaAI/rf-detr-seg-preview-npu
· ConvNeXt-Tiny: NexaAI/convnext-tiny-npu-IoT
在第2代RB3开发套件上支持的模型
计算机视觉模型(CV)
· ConvNeXt-Tiny NexaAI/convnext-tiny-npu-IoT-rb3
今天就开始尝试
准备好为您的物联网和机器人应用引入最先进的AI了吗?
浏览NexaSDK文档,加入开发者社区,了解将我们先进的NPU与容器化AI部署的灵活性相结合的可能性。
在所发布内容中表达的观点仅为原作者的个人观点,并不代表高通技术公司或其子公司(以下简称为“高通技术公司”)的观点。所提供的内容仅供参考之用,而并不意味着高通技术公司或任何其他方的赞同或表述。本网站同样可以提供非高通技术公司网站和资源的链接或参考。高通技术公司对于可能通过本网站引用、访问、或链接的任何非高通技术公司网站或第三方资源并没有做出任何类型的任何声明、保证、或其他承诺。
高通品牌产品均为高通技术公司和/或其子公司的产品。
关于作者
卢比·哈金,高级营销沟通专员
阿历克斯·陈,Nexa AI首席执行官及创办人
扎克·李,Nexa AI首席技术官及创办人
阿兰·朱,Nexa AI产品主管

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)