MySQL:(0) 存储引擎基础与主从复制/分库分表
1. InnoDB
地位:MySQL 5.5 版本后的默认引擎。
- 核心特性:
- 支持事务 (ACID),外键与行锁。
- 支持崩溃恢复 (Crash Recovery)。
- 每张表都对应一个表文件 .ibd(可共用或一一对应),存储表结构、数据和索引。
- 适用场景:绝大多数需要事务安全、高并发读写的应用场景(如电商订单、用户系统)。
- 缺点:相比 MyISAM,占用更多磁盘空间,全表扫描速度略慢。
1.1 4种事务隔离级别
- Read Uncommitted(读未提交) 这是最低的隔离级别,允许一个事务读取另一个事务尚未提交的修改数据;这会导致“脏读”问题,即读到了别人回滚前的临时无效数据,实际生产中极少使用。
- Read Committed(读已提交) 保证一个事务只能读取到已经提交的数据,解决了脏读问题;但在同一事务内,两次读取同一数据可能因其他事务的提交修改而得到不同结果,因此仍存在“不可重复读”问题,是 Oracle 和 SQL Server 的默认级别。
- Repeatable Read(可重复读) 保证在同一事务内,多次读取同一数据的结果始终一致,即使其他事务已提交修改也不会影响当前视图,从而解决了不可重复读问题;这是 MySQL InnoDB 的默认隔离级别,并通过 MVCC 和间隙锁在很大程度上避免了“幻读”。
- Serializable(串行化) 这是最高的隔离级别,强制事务串行执行(相当于给所有读取的数据加上共享锁,写入加排他锁),彻底解决了脏读、不可重复读和幻读所有并发问题;但代价是极大的性能损耗和并发能力下降,通常仅在对数据一致性要求极高且并发量低的场景使用。
|
特性 |
不可重复读 (Non-Repeatable Read) |
幻读 (Phantom Read) |
|---|---|---|
|
关注点 |
修改 (Update) / 删除 (Delete) |
插入 (Insert) (偶尔也包含删除) |
|
现象描述 |
同一个事务内,两次读取同一行记录,发现内容变了。 |
同一个事务内,两次执行相同的范围查询,发现行数变多了(或少了)。 |
|
本质原因 |
其他事务修改并提交了已存在的记录。 |
其他事务新增(或删除)了符合查询条件的记录。 |
|
锁的解决方式 |
Record Lock (记录锁) 即可解决。 |
需要 Gap Lock (间隙锁) 或 Next-Key Lock (临键锁) 才能解决。 |
|
隔离级别要求 |
读已提交 (RC) 可避免。 |
读已提交 (RC) 无法避免。 |
1.2 4大特性
- 插入缓冲 针对非唯一二级索引的插入操作进行优化,当新记录需要插入到非连续的索引页时,InnoDB 不直接写入磁盘,而是先将其暂存于内存中的“插入缓冲”链表里;随后在后台线程空闲或页面被读取时,再将这些分散的插入操作合并为一次顺序 I/O 写入磁盘,从而将大量的随机写转化为顺序写,显著提升写性能。
- 二次写 为解决数据库发生崩溃(如断电)时,因页写入磁盘过程不完整(仅写了一半,即“页断裂”)而导致的数据损坏问题而设计;InnoDB 在将脏页刷新到正式表空间前,会先将其顺序写入一个名为"doublewrite buffer"的共享区域,若恢复时发现数据页损坏,可从该缓冲区中找回完整的副本进行修复,确保数据的可靠性。
- 自适应哈希索引 InnoDB 会监控索引页的访问频率,对于某些被频繁热点访问的页,自动在内存中为其建立哈希索引;这使得原本需要通过 B+ 树多层遍历的查询,可以直接通过哈希表实现 O(1) 复杂度的等值查找,无需人工干预即可动态加速热点数据的检索速度。
- 预读 基于局部性原理设计的 I/O 优化策略,当检测到系统正在顺序访问某个区(Extent)中的部分数据页时,InnoDB 会预测后续即将需要的数据,并主动在后台异步地将该区剩余的页提前加载到缓冲池(Buffer Pool)中;这样当用户真正请求这些数据时,可直接从内存命中,避免了等待磁盘 I/O 的延迟。
1.3 表空间(.ibd)存储结构
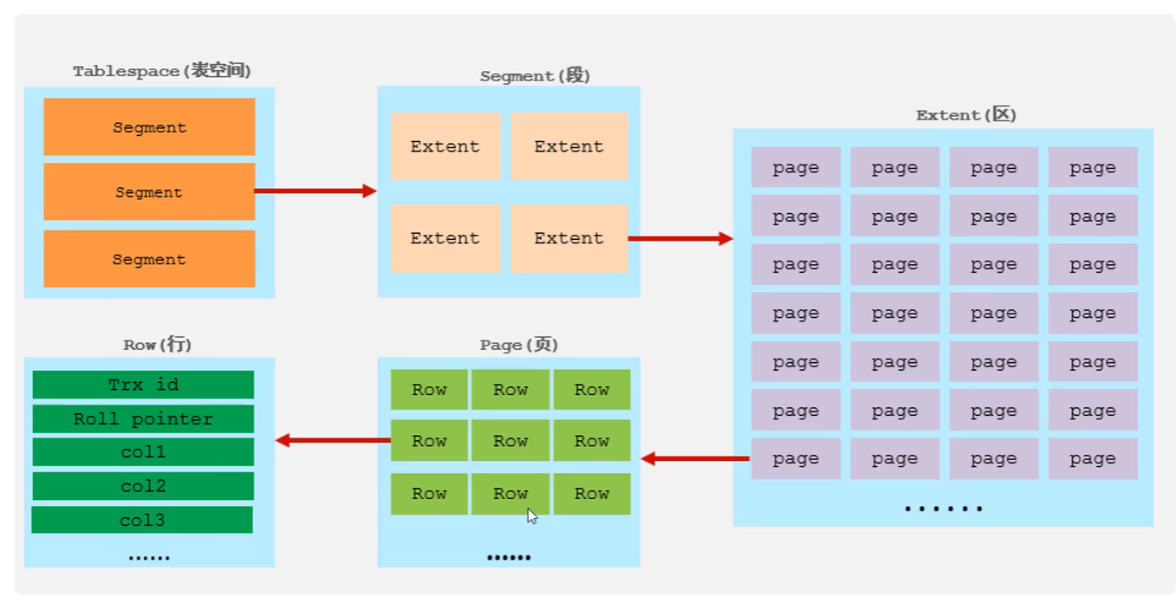
表空间(ibd文件),一个mysql实例可以对应多个表空间,用于存储记录、索引等数据。
段,分为数据段(Leaf node segment)、索引段(Non-leaf node segment)、回滚段(Rollback segment),InnoDB是索引组织表,数据段就是B+树的叶子节点,索引段即为B+树的非叶子节点。段用来管理多个Extent(区)。
区,表空间的单元结构,每个区的大小为1M。默认情况下,InnoDB存储引擎页大小为16K,即一个区中一共有64个连续的页。
页,是InnoDB存储引擎磁盘管理的最小单元,每个页的大小默认为16KB。为了保证页的连续性,InnoDB存储引擎每次从磁盘申请4-5个区。
行,InnoDB存储引擎数据是按行进行存放的。
- Trx_id: 每次对某条记录进行改动时,都会把对应的事务id赋值给trx_id隐藏列。
- Roll_pointer: 每次对某条引记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
1.4 整体架构
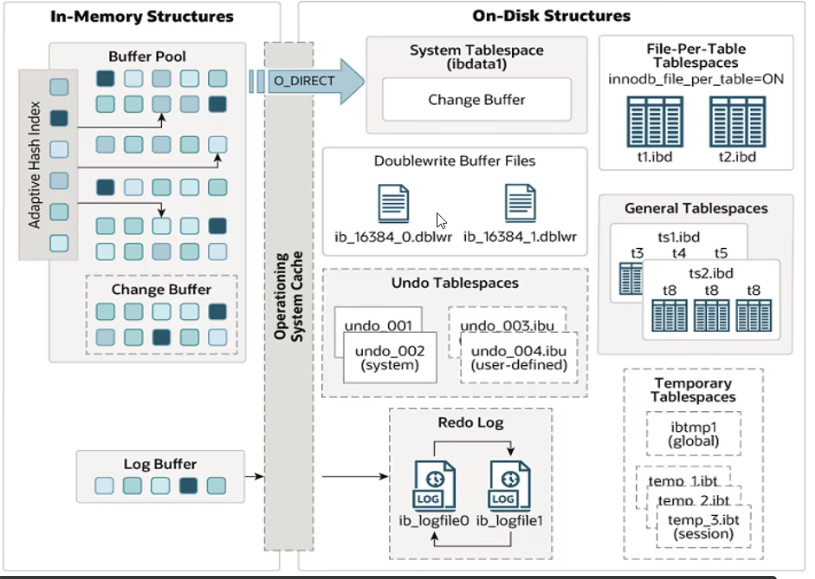
1.4.1 内存结构
① Buffer Pool: 缓冲池是主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改查操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),然后再以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度。
缓冲池以Page页为单位,底层采用链表数据结构管理Page。根据状态,将Page分为三种类型:
- free page: 空闲page,未被使用。
- clean page: 被使用page,数据没有被修改过。
- dirty page: 脏页,被修改过但还没写到磁盘的数据页。
② Change Buffer: 更改缓冲区(针对于非唯一二级索引页),在执行DML语句时,如果这些数据Page没有在Buffer Pool中,不会直接操作磁盘,而会将数据变更存在更改缓冲区 Change Buffer 中,在未来数据被读取时,再将数据合并恢复到Buffer Pool中,再将合并后的数据刷新到磁盘中。
Change Buffer的意义:与聚集索引不同,二级索引通常是非唯一的,并且以相对随机的顺序插入二级索引。同样,删除和更新可能会影响索引树中不相邻的二级索引页,如果每一次都操作磁盘,会造成大量的磁盘IO。有了ChangeBuffer之后,我们可以在缓冲池中进行合并处理,减少磁盘IO。
③ Adaptive Hash Index: 自适应hash索引,用于优化对Buffer Pool数据的查询。InnoDB存储引擎会监控对表上各索引页的查询,如果观察到hash索引可以提升速度,则建立hash索引,称之为自适应hash索引。无需人工干预,系统根据情况自动完成。
④ Log Buffer: 日志缓冲区,用来保存要写入到磁盘中的log日志数据(redolog),默认大小为 16MB,日志缓冲区的日志会定期刷新到磁盘中。如果需要更新、插入或删除许多行的事务,增加日志缓冲区的大小可以节省磁盘 I/O。
- innodb_log_buffer_size:缓冲区大小
- innodb_flush_log_at_trx_commit:日志刷新到磁盘时机
- 1 日志在每次事务提交时写入并刷新到磁盘
- 0 每秒将日志写入并刷新到磁盘一次。
- 2 日志在每次事务提交后写入,并每秒刷新到磁盘一次。
1.4.2 磁盘结构
① System Tablespace: 默认情况下,所有 InnoDB 表的数据和索引都存到这里,已废弃,仅用于系统数据,系统表空间是更改缓冲区的存储区域。如果表是在系统表空间而不是每个表文件或通用表空间中创建的,它也可能包含表和索引数据。(在MySQL5.x版本中还包含InnoDB数据字典、undolog等) 参数:innodb_data_file_path
② File-Per-Table Tablespaces: 开启后,每个表有自己的 .ibd 文件,每个表的文件表空间包含单个InnoDB表的数据和索引,并存储在文件系统上的单个数据文件中。 参数:innodb_file_per_table
③ General Tablespaces: 通用表空间,需要通过 CREATE TABLESPACE 语法创建通用表空间,在创建表时,可以指定该表空间。
④ Undo Tablespaces: 撤销表空间,MySQL实例在初始化时会自动创建两个默认的undo表空间(初始大小16M),用于存储undo log日志。
⑤ Temporary Tablespaces: InnoDB 使用会话临时表空间和全局临时表空间。存储用户创建的临时表等数据。存放 临时表 和 排序/分组中间结果 的空间。
⑥ Doublewrite Buffer Files: 双写缓冲区,InnoDB引擎将数据页从Buffer Pool刷新到磁盘前,先将数据页写入双写缓冲区文件中,便于系统异常时恢复数据。为了防止“部分页写入”导致的数据损坏而设计的一种安全机制。写磁盘前先备份一份完整页到双写区,万一写入过程中断电/崩溃,可以用备份恢复。
⑦ Redo Log: 重做日志,是用来实现事务的持久性。该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log),前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都会存到该日志中,用于在刷新脏页到磁盘时,发生错误时,进行数据恢复使用。
1.4.3 后台线程
① Master Thread
核心后台线程,负责调度其他线程,还负责将缓冲池中的数据异步刷新到磁盘中,保持数据的一致性,还包括脏页的刷新、合并插入缓存、undo页的回收。
② IO Thread
在InnoDB存储引擎中大量使用了AIO来处理IO请求,这样可以极大地提高数据库的性能,而IO Thread主要负责这些IO请求的回调。
|
线程类型 |
默认个数 |
职责 |
|---|---|---|
|
Read thread |
4 |
负责读操作 |
|
Write thread |
4 |
负责写操作 |
|
Log thread |
1 |
负责将日志缓冲区刷新到磁盘 |
|
Insert buffer thread |
1 |
负责将写缓冲区内容刷新到磁盘 |
③ Purge Thread
主要用于回收事务已经提交了的undo log,在事务提交之后,undo log可能不用了,就用它来回收。
④ Page Cleaner Thread
协助 Master Thread 刷新脏页到磁盘的线程,它可以减轻 Master Thread 的工作压力,减少阻塞。
1.5 事务与ACID
事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
● 特性 ACID
- 原子性:事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性:事务完成时,必须使所有的数据都保持一致状态。
- 隔离性:数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性:事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
隔离性由锁和MVCC实现;原子性、一致性和持久性由 redo log 和 undo log 实现。
① 原子性 → 靠 Undo Log
- 事务执行过程中每一步都记录 Undo,记录数据被修改前的信息。
- 如果中途出错或主动 ROLLBACK → 按 Undo 逆向操作 → 数据回到事务开始前状态。
- 崩溃恢复时,对未提交事务也做同样回滚 → 保证原子性。
② 一致性 → 两者协同
- Undo Log:保障事务内部逻辑一致(如转账总额不变),失败可回滚。
- Redo Log:保障外部环境一致(如宕机后数据仍符合约束),提交必生效。
- 二者共同确保:无论成功还是失败,数据库始终处于合法状态。
③ 持久性 → 靠 Redo Log
- WAL(Write-Ahead Logging)机制:
- 修改 Buffer Pool 中的数据页(dirty page)。
- 同时记录 Redo Log Buffer。
- 事务提交 → 强制刷 Redo Log 到磁盘(根据innodb_flush_log_at_trx_commit)。
- 后台异步刷 dirty page 到数据文件。
- 即使第 4 步没完成就宕机 → 重启后从 Redo Log 重放 → 数据不丢失。
1.6 MVCC
每当事务修改数据时,数据库不会直接覆盖原值,而是生成一个新版本并保留旧版本(通过 Undo Log 链接),同时给每个事务分配一个唯一的交易 ID;当事务进行读取时,系统会根据该事务的启动时间(或快照点)和可见性规则,动态判断并返回对其可见的那个特定版本的数据——这意味着读操作不需要加锁(非阻塞读),可以瞬间拿到一致性视图,而写操作也只锁定当前最新行,从而完美解决了“读写冲突”,实现了高效的读写并行。
|
类型 |
SQL 示例 |
读什么版本 |
是否加锁 |
|---|---|---|---|
|
快照读 |
SELECT * FROM t WHERE id=1; |
历史版本 |
❌ 不加锁 |
|
当前读 |
SELECT ... FOR UPDATE; UPDATE; |
最新版本 |
✅ 加锁 |
● MVCC:多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突,快照读为MySQL实现MVCC提供了一个非阻塞读功能。MVCC的具体实现,还需要依赖于数据库记录中的三个隐式字段、undo log日志、readView。
1.6.1 隐藏字段
表中会自动生成三个隐藏的字段。
|
隐藏字段 |
含义 |
|---|---|
|
DB_TRX_ID |
最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID。 |
|
DB_ROLL_PTR |
回滚指针,指向这条记录的上一个版本,用于配合undo log,指向上一个版本。 |
|
DB_ROW_ID |
隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段。 |
1.6.2 undo log 版本链
回滚日志,在 insert、update、delete 的时候产生的便于数据回滚的日志。
每次 UPDATE 都会:
- 把旧版本写入 Undo Log
- 新版本指向旧版本(DB_ROLL_PTR)
- 形成一条版本链
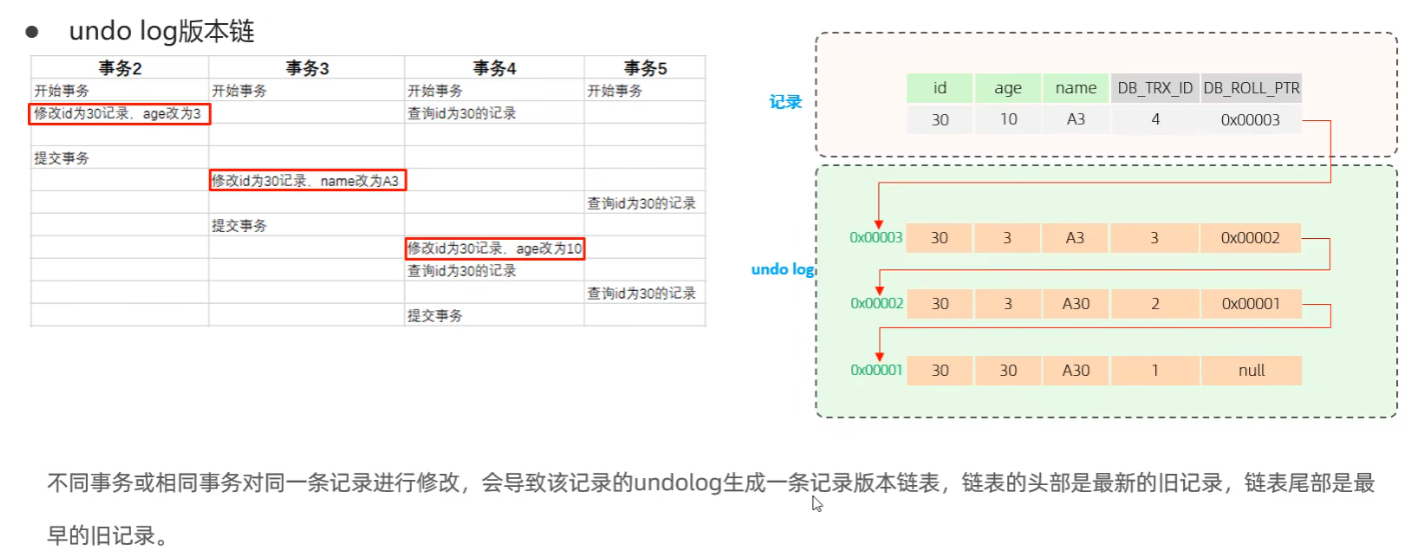
1.6.3 read view
ReadView(读视图)是快照读 SQL 执行时 MVCC 提取数据的依据,记录并维护系统当前活跃的事务(未提交的)id,决定"我能看到哪个版本"的可见性规则。
ReadView 结构中包含了四个核心字段:
|
字段名 |
含义说明 |
|---|---|
|
m_ids |
当前所有未提交事务的 ID 列表(数组),用于判断哪些版本不可见。 |
|
min_trx_id |
m_ids 中最小的事务 ID → 表示最早开始且尚未提交的事务。 |
|
max_trx_id |
下一个将要分配的事务 ID = 当前已分配的最大事务 ID + 1(全局自增计数器)。 |
|
creator_trx_id |
创建这个 ReadView 的那个事务自身的 ID(即执行 SELECT 语句的那个事务)。 |

当事务执行一个不加锁的 SELECT(快照读)时,InnoDB 会生成一个 ReadView,用来决定:能看到哪些版本的数据?
|
隔离级别 |
ReadView 创建时机 |
效果 |
|---|---|---|
|
RC |
每次 SELECT 都创建新的 |
能看到最新提交的版本 |
|
RR |
第一次 SELECT 时创建一次 |
整个事务看到相同版本 |
┌─────────────────────────────────────────────────────────────────┐
│ 事务执行快照读 SELECT │
└─────────────────────────────┬───────────────────────────────────┘
│
▼
┌─────────────────────┐
│ 需要 ReadView 吗? │
└─────────┬───────────┘
│
┌───────────────┴───────────────┐
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ RC 隔离级别 │ │ RR 隔离级别 │
│ │ │ │
│ 每次SELECT都 │ │ 只在第一次SELECT │
│ 创建新ReadView │ │ 时创建ReadView │
└────────┬────────┘ └────────┬────────┘
│ │
└───────────┬───────────────────┘
▼
┌─────────────────────┐
│ 生成/复用ReadView │
│ │
│ m_ids = [101,102] │
│ min_trx_id = 101 │
│ max_trx_id = 105 │
│ creator_trx_id=100 │
└─────────┬───────────┘
│
▼
┌─────────────────────┐
│ 从数据表中读取 │
│ 当前最新版本记录 │
│ │
│ DB_TRX_ID = 103 │
│ DB_ROLL_PTR │
│ age = 25 │
└────────┬────────────
│
▼
┌─────────────────────┐
│ 用ReadView判断 │
│ 当前版本是否可见? │
│ │
│ 103 ∈ m_ids? │
│ 103 < min_trx_id? │
│ 103 == creator? │
└─────────┬───────────┘
│
┌───────────┴───────────┐
│ │
▼ ▼
✅ 可见 ❌ 不可见
│ │
│ ▼
│ ┌─────────────────┐
│ │ 沿着DB_ROLL_PTR │
│ │ 找到上一个版本 │
│ │ │
│ │ DB_TRX_ID = 101 │
│ │ age = 20 │
│ └────────┬────────┘
│ │
│ ▼
│ ┌─────────────────┐
│ │ 继续用ReadView │
│ │ 判断是否可见? │
│ └────────┬────────┘
│ │
│ ┌───────────┴───────────┐
│ │ │
│ ▼ ▼
│ ✅ 可见 ❌ 不可见
│ │ │
│ │ ▼
│ │ (继续沿着版本链
│ │ 往下找...)
│ │
└───────────┴───────────────────────┘
│
▼
┌─────────────────────┐
│ 返回第一个可见的 │
│ 版本数据给用户 │
│ │
│ SELECT age = 20 │
└─────────────────────┘2. 其他存储引擎
2.1 MyISAM
- 地位:MySQL 5.5 之前的默认引擎,目前主要用于遗留系统或特定只读场景。
- 核心特性:
- 不支持事务、外键和行锁。
- 支持表级锁,写入时会锁住整张表,并发性能差。
- 读取速度快,尤其是 COUNT(*) 操作(因为内部维护了行数计数)。
- 3个文件:.sdi (表结构)、.MYD (数据)、.MYI (索引)
- 适用场景:只读或读多写少、不需要事务安全的日志记录、数据仓库报表。
- 缺点:表损坏后修复困难,不支持事务,高并发写入瓶颈明显。
|
特性 |
MyISAM |
InnoDB |
|---|---|---|
|
文件组成 |
3个文件:• .sdi (表结构) |
1个文件:• .ibd (数据+索引,共享表空间或独立表空间) |
|
存储结构 |
索引与数据分离。索引有压缩,节省空间。 |
索引与数据捆绑(聚簇/二级索引)。数据即索引,索引即数据,无压缩,体积通常较大。 |
|
事务、外键与行锁 |
❌ 不支持。 |
✅ 支持。 |
|
锁机制 |
表级锁 |
行级锁(默认) |
|
读操作 |
极快。适合以读为主的业务。 |
较慢(需维护事务日志和锁)。 |
|
写操作 |
较慢(表锁阻塞)。 |
较快。行锁允许高并发写入。 |
|
清空表 |
重建表。速度极快,但碎片整理耗时。 |
逐行删除。速度慢,消耗大。 |
|
统计行数 |
O(1)。内部保存了总行数,直接读取。 |
O(N)。需遍历全表(因 MVCC 机制,不同事务看到的行数不同)。 |
|
自增列 |
灵活。可以是联合索引的非第一列。 |
严格。必须是索引,且若是联合索引必须是第一列。 |
|
崩溃恢复 |
较差。断电易损坏,修复困难。 |
优秀。通过 Redo Log 实现崩溃恢复,数据安全性高。 |
|
全文索引 |
支持 |
5.6+ 支持 |
例:一张表,里面有ID自增主键,当insert了17条记录之后,删除了第15,16,17条记录,
再把Mysql重启,再insert一条记录,这条记录的ID是18还是15 ?
(1)如果表的类型是MyISAM,那么是18
因为MyISAM表会把自增主键的最大ID记录到数据文件里,重启MySQL自增主键的最大
ID 也不会丢失 。
(2)如果表的类型是InnoDB,那么是15
InnoDB 表只是把自增主键的最大ID记录到内存中,所以重启数据库或者是对表进行
OPTIMIZE 操作,都会导致最大ID丢失 。
|
特点 |
InnoDB |
MyISAM |
Memory |
|---|---|---|---|
|
存储限制 |
64TB |
有 |
有 |
|
事务安全 |
支持 |
- |
- |
|
锁机制 |
行锁 |
表锁 |
表锁 |
|
B+tree索引 |
支持 |
支持 |
支持 |
|
Hash索引 |
- |
- |
支持 |
|
全文索引 |
支持(5.6版本之后) |
支持 |
- |
|
空间使用 |
高 |
低 |
N/A |
|
内存使用 |
高 |
低 |
中等 |
|
批量插入速度 |
低 |
高 |
高 |
|
支持外键 |
支持 |
- |
- |
2.2 Memory (Heap)
- 地位:基于内存的临时表引擎。
- 核心特性:
- 数据存储在RAM中,速度极快,重启后数据丢失(易失性)。
- 默认使用哈希索引,适合等值查询,不适合范围查询。
- 表大小受限于 max_heap_table_size。
- 不支持:BLOB 、TEXT
- 1个文件:.sdi (表结构)
- 适用场景:临时中间表、缓存查找表、会话存储。
- 缺点:数据不安全(断电即失),受内存大小限制。
2.3 Archive
- 地位:专为归档设计。
- 核心特性:
- 采用高压缩比存储,节省空间。
- 只支持插入和查询,不支持更新 (UPDATE) 和删除 (DELETE)。
- 不支持索引(除了自增主键)。
- 适用场景:历史数据归档、日志长期存储。
2.4 CSV
- 地位:文本文件映射。
- 核心特性:
- 数据直接以逗号分隔值 (.csv) 文件形式存储在磁盘上。
- 可以用文本编辑器直接查看和修改。
- 不支持索引和事务。
- 适用场景:数据交换、作为外部数据源的接口。
2.5 Blackhole (黑洞)
- 地位:特殊用途引擎。
- 核心特性:
- 接收所有写入操作,但不存储任何数据,查询永远返回空集。
- 会记录二进制日志 (Binlog)。
- 适用场景:主从复制中的中继节点(只转发数据不存储)、审计测试(测试 SQL 语法而不影响数据)。
2.6 Federated
- 地位:远程访问引擎。
- 核心特性:
- 本地不存数据,指向远程 MySQL 服务器上的表。
- 像访问本地表一样访问远程表。
- 适用场景:分布式数据库查询(性能较差,需谨慎使用)。
3. 索引与优化
3.1 索引分类
|
分类 |
含义 |
特点 |
关键字 |
|---|---|---|---|
|
主键索引 |
针对于表中主键创建的索引 |
默认自动创建,只能有一个 |
PRIMARY |
|
唯一索引 |
避免同一个表中某数据列中的值重复 |
可以有多个 |
UNIQUE |
|
常规索引 |
快速定位特定数据 |
可以有多个 |
— |
|
全文索引 |
全文索引查找的是文本中的关键词,而不是比较索引中的值 |
可以有多个 |
FULLTEXT |
在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种:
|
分类 |
含义 |
特点 |
|---|---|---|
|
聚集索引 |
将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据 |
必须有,而且只有一个 |
|
二级索引 |
将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 |
可以存在多个 |
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
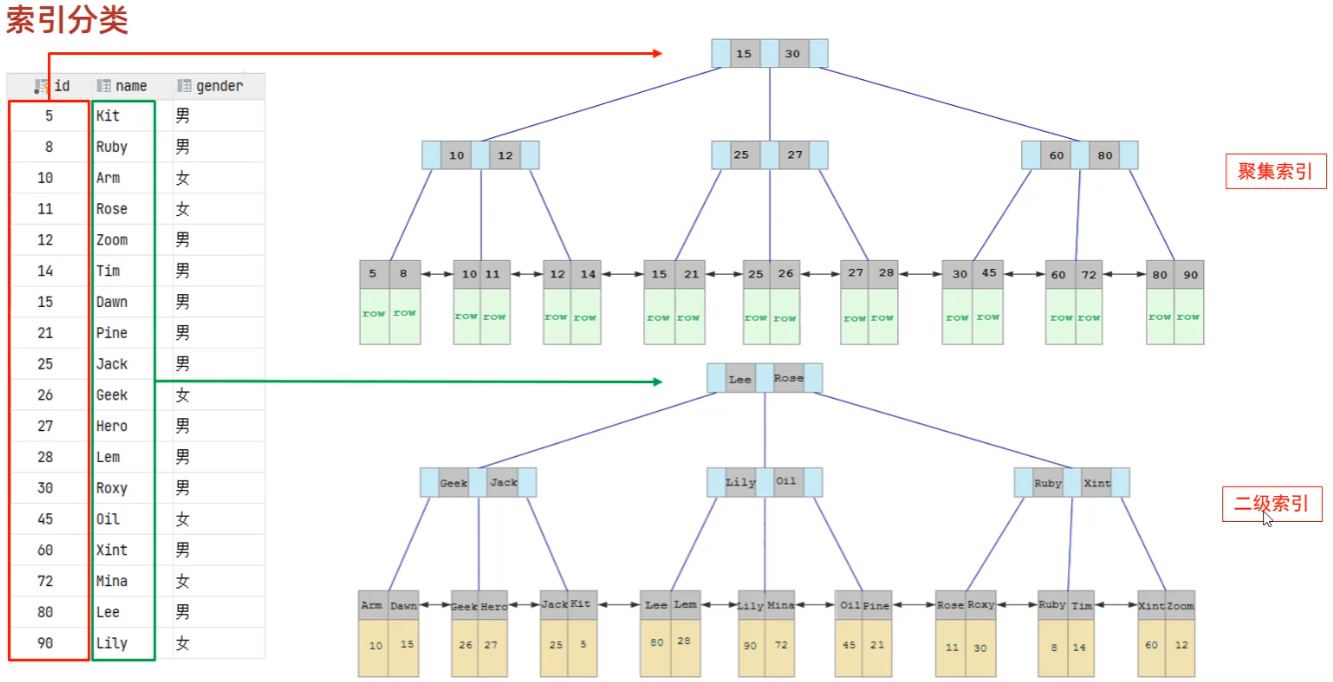
回表查询:先走二级索引查主键,再走聚集索引查这一行。
InnoDB主键索引的B+tree高度:
假设: 一行数据大小为1k,一页中可以存储16行这样的数据。InnoDB的指针占用6个字节的空间,主键即使为bigint,占用字节数为8。
指针比索引多一个。
高度为2: n * 8 + (n + 1) * 6 = 16 * 1024,算出n约为 1170
1171 * 16 = 18736
高度为3: 1171 * 1171 * 16 = 21939856
3.2 索引机制
使用B树变种B+树。
阶数:即一个节点指向的指针数,存储的key数量为阶数 - 1。
- B 树:
- 数据存储:每个节点都存储 键 + 数据。
- 查找逻辑:只要在某个节点找到匹配的 Key,就可以直接返回数据,无需走到叶子节点。
- 如图:
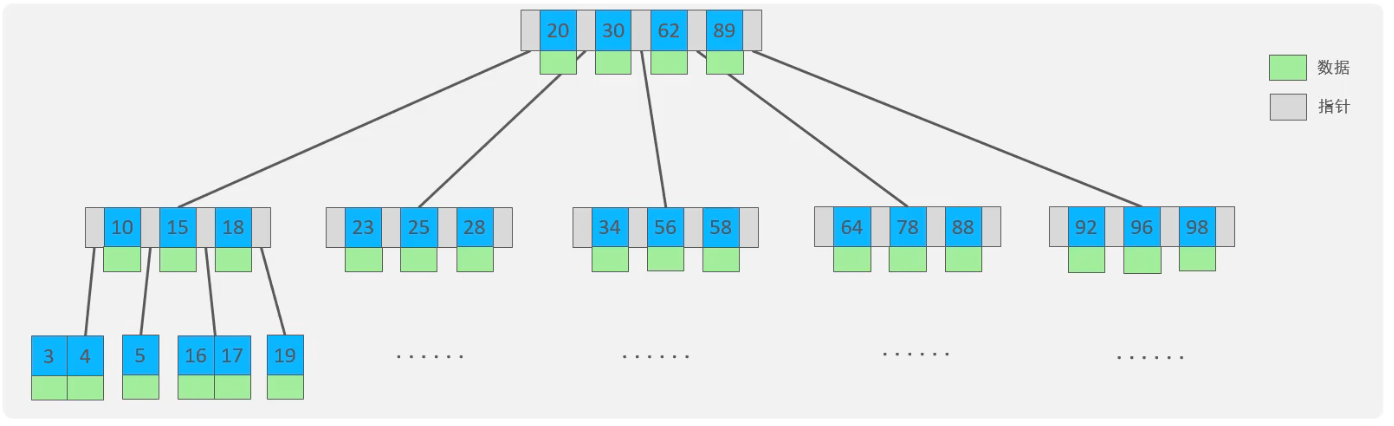
- B+ 树:
- 数据存储:只有叶子节点存储 键 + 数据;非叶子节点只存储键 作为索引指引。
- 链表结构:所有叶子节点连接成一个单向链表。
- 如图:
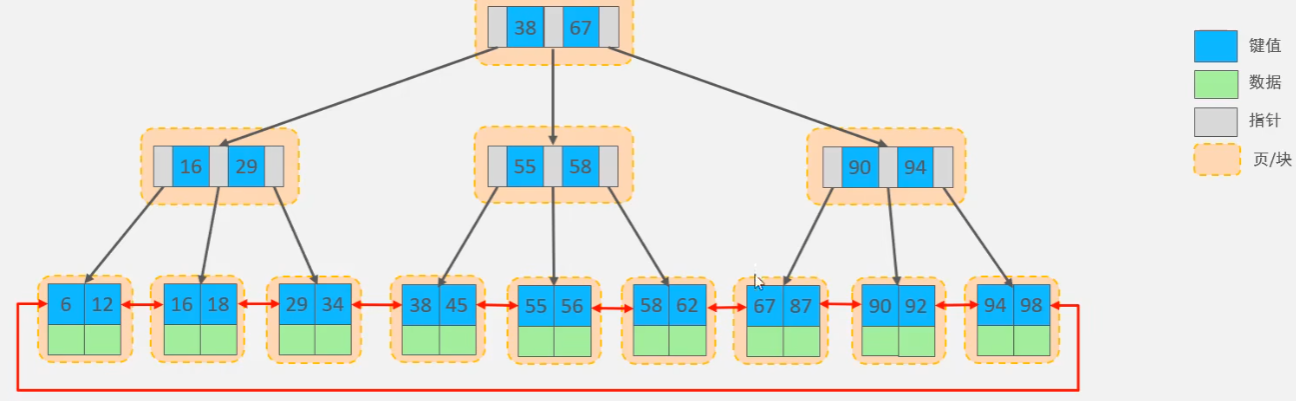
|
特性 |
B 树 |
B+ 树 |
优势解析 |
|---|---|---|---|
|
磁盘 I/O 次数 |
较多 |
更少 |
B+ 树非叶子节点不存数据,单个磁盘页能容纳更多索引键,树的高度更低,查询时读取磁盘的次数更少。 |
|
范围查询性能 |
差 |
极优 |
B+ 树叶子节点有链表连接,范围查询只需找到起点,然后沿链表遍历即可;B 树需要反复进行中序遍历,效率低。 |
|
查询稳定性 |
不稳定 |
稳定 |
B 树查询最好在根节点命中,最坏在叶子节点;B+ 树所有查询都必须走到叶子节点,耗时固定,性能可预测。 |
|
全表扫描 |
慢 |
快 |
B+ 树只需遍历叶子节点链表;B 树需要递归遍历整棵树。 |
|
空间利用率 |
较低 |
较高 |
B+ 树内部节点只存 Key,空间利用率高,能建立更宽更矮的树。 |
3.3 索引使用与优化
3.3.1 最左前缀法则
联合索引查询从索引的最左列开始,并且不跳过索引中的列。
- 如果跳跃某一列,后面的字段索引失效。
- 出现范围查询(>,<),范围查询右侧的列索引失效。
- 联合索引在底层是按从左到右的顺序构建的。
按照 (name, age, city)的顺序建立索引树:
-
如果查询只用到了 name→ ✅ 可用索引
-
如果查询用到了 name + age→ ✅ 可用索引
-
如果查询用到了 name + city(跳过了 age)→ ❌ city的索引失效(因为没按顺序)
-
如果查询只用到了 age或 city→ ❌ 无法使用该联合索引(因为没有从最左列开始)
-
SELECT * FROM users WHERE name = '张三' AND age > 30 AND status = '0';
-
name是索引第一列,可以匹配;age是第二列,且是范围查询(>),那么 age之后的列(即 status)将无法使用该索引。
-
优化:
-
设计索引时:按查询高频、高选择性的列从左到右排列。
3.3.2 索引失效
- 在索引上进行运算会失效;
- 字符串不加单引号会失效;
- 头部模糊 (&) 匹配会失效,尾部不会;
- 用 or 分割开的条件,如果 or 前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都失效;
- MySQL评估走索引比扫描全表更慢,则不使用索引
3.3.3 sql提示
使用use, force, ignore等建议/指定/忽略使用的索引
3.3.4 覆盖索引
尽量使用覆盖索引(查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到),减少 SELECT *,避免回表查询。
联合索引是覆盖索引的一种实现方式,一个索引包含多个列,且要考虑顺序。
3.3.5 前缀索引
当字段类型为字符串(varchar,text等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO,影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大节约索引空间,从而提高索引效率。
选择前缀长度的原则是:保证索引的选择性足够高,即索引能尽可能区分不同的值
选择性 = 唯一值数量 / 总行数
3.3.6 设计原则
- 针对于数据量较大,且查询比较频繁的表建立索引。
- 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
- 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
- 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定
4. SQL优化
4.1 SQL性能分析
- 查看执行频率:SHOW GLOBAL STATUS LIKE 'Com______';
- 慢查询日志:记录所有执行时间超过指定时间(默认10s)的语句
- show profiles:了解当前会话的sql语句的耗时情况
- 查看每一条SQL的耗时基本情况:show profiles;
- 查看指定query_id的SQL语句各个阶段的耗时情况:show profile for query query_id;
- 查看指定query_id的SQL语句CPU的使用情况:show profile cpu for query query_id;
- explain执行计划:
|
字段 |
含义 |
|---|---|
|
id |
查询的序号,表示执行的先后顺序(越大越先执行,相同则从上到下) |
|
select_type |
查询类型(SIMPLE、PRIMARY、SUBQUERY、DERIVED 等) |
|
table |
当前行引用的表名 |
|
partitions |
匹配的分区(如果有分区表) |
|
type |
访问类型(最重要,从好到差:system > const > eq_ref > ref > range > index > ALL) |
|
possible_keys |
可能使用的索引 |
|
key |
实际使用的索引 |
|
key_len |
使用的索引长度(字节) |
|
ref |
显示哪些列或常量被用于查找索引列上的值 |
|
rows |
预估扫描的行数(越小越好) |
|
filtered |
表示按条件过滤后,剩余行的百分比(MySQL 5.7+) |
|
Extra |
额外信息(如 Using where、Using index、Using temporary、Using filesort 等) |
4.2 插入优化
- insert 插入:
- 批量插入;
- 手动事务提交,默认是自动,提交太频繁;
- 主键顺序插入;
- 大批量插入用 load
4.3 主键优化
顺序插入:页1:[1, 2, 3, ...] → 页满 → 新建页2:[4, 5, 6, ...]
乱序插入:页1:[50, 100] → 插入150 → 页满需要分裂!
-
数据需要“插入到中间位置”,导致页频繁分裂,调整B+Tree指针
-
页填充率降低(约50%),性能下降明显
页合并:当删除数据后,某些页的数据量低于阈值(通常是页容量的一半),InnoDB 会尝试将相邻的页合并,以释放空间。
优化:
- 降低主键长度
- 顺序插入,AUTO_INCREMENT自增主键
- 不要用uuid或身份证号这种乱序的做主键
- 业务中避免修改主键
4.4 order by 优化
排序:
- Using filesort:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫FileSort排序。
- Using index:order by 字段即为索引且索引与 order 顺序一致,操作效率高。
优化:
- 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。
- 尽量使用覆盖索引。
- 多字段排序,一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)。
- 如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小sort_buffer_size(默认256k)。
4.5 group by 优化
1. 在分组操作时,可以通过索引来提高效率。
-
原理:索引是有序的,分组操作本质上就是对数据进行分组聚合,如果数据已经按分组字段排好序,MySQL 就可以直接“顺序扫描 + 计数”,无需额外排序。减少 Using temporary和 Using filesort,提升性能。
2. 分组操作时,索引的使用也是满足最左前缀法则的。
-
含义:联合索引 (A, B, C),可以用于 GROUP BY A、GROUP BY A, B,但不能用于 GROUP BY B或 GROUP BY C。
4.6 limit 优化
深分页:limit 2000000,10 ,此时需要MySQL排序前2000010记录,仅仅返回2000000 - 2000010的记录,其他记录丢弃,查询排序的代价非常大。
优化: 覆盖索引 + 子查询
SELECT * FROM tb_sku t, (SELECT id FROM tb_sku ORDER BY id LIMIT 2000000, 10) a WHERE t.id = a.id;-
原始写法:排序全表,排序 2000010 行 × 1KB = ~2GB 数据在内存/磁盘中排序 → 极慢。
-
优化写法:
-
子查询:排序索引列 id,排序 2000010 行 × 8字节(id)= ~16MB 。
-
外层:子查询只取 id,外层再通过 id回表取完整行,只回表 10 次 → 读取 10 行 × 1KB = 10KB。
-
4.7 count 优化
count的几种用法
➢ count(主键)
InnoDB 引擎会遍历整张表,把每一行的 主键id 值都取出来,返回给服务层。服务层拿到主键后,直接按行进行累加(主键不可能为null)。
➢ count(字段)
没有not null 约束:InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为null,不为null,计数累加。
有not null 约束:InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加。
➢ count(1)
InnoDB 引擎遍历整张表,但不取值。服务层对于返回的每一行,放一个数字 “1” 进去,直接按行进行累加。
➢ count(*)
InnoDB引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加。
按照效率排序:count(字段) < count(主键 id) < count(1) ≈ count(*),所以尽量使用 count(*)。
4.8 update 优化
-- 示例1:通过主键更新
update student set no = '2000100100' where id = 1 ;
-- 示例2:通过普通字段(非主键索引)更新
update student set no = '2000100105' where name = '韦一笑';-
优先用主键/唯一索引做更新条件:
主键和唯一索引能精准定位行,触发行锁,效率高,并发好。比如示例1用 id = 1(主键),更新速度快,锁冲突少。
-
确保更新条件的索引有效:
如果必须用普通字段(如 name)做条件,一定要保证该字段有有效的索引,且查询时不破坏索引(比如避免类型转换、函数操作、隐式转换等)。
-
错误示例:WHERE name = 123(如果 name是 VARCHAR,会把 name转为数字,索引失效)。
-
正确示例:WHERE name = '韦一笑'(与索引字段类型一致,索引生效)。
-
-
避免全表扫描触发表锁:
索引失效会导致全表扫描,进而触发表锁,严重影响并发。因此,要定期检查索引状态,确保更新条件的索引可用。
4.9 DISTINCT 优化
DISTINCT 用于去除重复行。它的底层实现通常依赖于排序或哈希。
思路:避免全表扫描,利用索引直接获取有序数据,或者用 GROUP BY 替代。
|
策略 |
核心动作 |
原理与效果 |
|---|---|---|
|
1. 建立索引 |
在 DISTINCT 涉及的列上建联合索引 |
利用索引的有序性,直接跳过排序步骤,避免 Using temporary 和 Filesort。 |
|
2. 改写 EXISTS |
将 SELECT DISTINCT ... JOIN 改为 WHERE EXISTS |
若只需判断“是否存在”,EXISTS 找到一条即停止,比全量去重快得多。 |
|
3. GROUP BY |
用 GROUP BY 替换 DISTINCT |
常常等价,但意图更清晰,便于强制走索引。 |
|
4. 业务层去重 |
查出所有数据,在代码中用 Set/HashMap 去重 |
适用于数据量小但 SQL 极复杂的场景,将压力从数据库转移到应用服务器。 |
5. 视图
5.1 检查选项
视图是基于表或其他视图的虚拟表,本质是一条 SELECT 查询的封装。
WITH CHECK OPTION 的作用是:当你通过视图修改数据(插入、更新、删除)时,MySQL 会强制检查修改后的数据是否仍然满足视图的 WHERE 条件。如果不符合,就拒绝这个修改操作。
MySQL 允许基于另一个视图创建新视图(即视图嵌套)。此时,WITH CHECK OPTION的 CASCADED/LOCAL决定了:除了检查当前视图的条件,是否需要递归检查所有依赖的父视图的条件。
-
CASCADED(默认):
检查当前视图的条件 + 所有直接或间接依赖的父视图的条件(递归检查,层层向上)。
-
LOCAL:
只检查当前视图的条件,不检查父视图的条件。
5.2 视图更新
要使视图可更新,视图中的行与基础表中的行之间必须存在一对一的关系。如果视图包含以下任何一项,则该视图不可更新:
-
聚合函数或窗口函数(SUM()、MIN()、MAX()、COUNT()等)
-
DISTINCT
-
GROUP BY
-
HAVING
-
UNION或者 UNION ALL
6. 存储过程
存储过程是事先经过编译并存储在数据库中的一段 SQL 语句的集合,调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的。
存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。
7. 触发器
每个表最多支持 6 个触发器(2 种时机 × 3 种操作)。
触发器是与表有关的数据库对象,指在 insert/update/delete 之前或之后,触发并执行触发器中定义的 SQL 语句集合。触发器的这种特性可以协助应用在数据库端确保数据的完整性、日志记录、数据校验等操作。
使用别名 OLD 和 NEW 来引用触发器中发生变化的记录内容,这与其他的数据库是相似的。现在触发器还只支持行级触发,不支持语句级触发。
|
触发器类型 |
NEW 和 OLD |
|---|---|
|
INSERT 型触发器 |
NEW 表示将要或者已经新增的数据 |
|
UPDATE 型触发器 |
OLD 表示修改之前的数据,NEW 表示将要或已经修改后的数据 |
|
DELETE型触发器 |
OLD 表示将要或者已经删除的数据 |
8. 锁
8.1 全局锁
对整个数据库加锁,加锁后整个数据库实例处于只读状态,后续的非查询语句被阻塞。
使用场景:全库的逻辑备份,获取一致性视图保证数据完整性。
问题:
- 如果在主库上备份,那么在备份期间都不能执行更新,业务基本上就得停摆。
-
如果在从库上备份,那么在备份期间从库不能执行主库同步过来的二进制日志(binlog),会导致主从延迟。
在InnoDB引擎中,可以在备份时加上 --single-transaction 参数来完成不加锁的一致性数据备份。
8.2 表级锁
- 表锁:锁定整张表的数据
- 元数据锁:保护表结构定义
- 意向锁:标识事务对行的加锁意图
|
锁类型 |
主要作用 |
锁模式 |
触发场景 |
特点 |
|---|---|---|---|---|
|
表锁 |
保护表中的数据不被并发修改 |
• 读锁 |
• LOCK TABLES ... READ |
读锁阻塞其他客户端写; 写锁阻塞其他客户端读写 |
|
元数据锁 |
保护表的结构定义不被并发修改 |
• MDL读锁 |
• DML操作自动加MDL读锁 |
• 系统自动控制 |
|
意向锁 |
快速判断表内是否有被锁定的行,避免遍历检查每一行的低效操作 |
• 意向共享锁 (事务打算对行加共享锁) (事务打算对行加排他锁) |
• 行级锁操作前 • 需要快速判断表锁定状态 |
• InnoDB特有,自动控制 |
锁兼容性:
|
锁类型 |
共享锁(S) |
排他锁(X) |
意向共享锁(IS) |
意向排他锁(IX) |
MDL读锁 |
MDL写锁 |
|---|---|---|---|---|---|---|
|
共享锁(S) |
✓ |
✗ |
✓ |
✗ |
✓ |
✗ |
|
排他锁(X) |
✗ |
✗ |
✗ |
✗ |
✗ |
✗ |
|
意向共享锁(IS) |
✓ |
✗ |
✓ |
✓ |
✓ |
✗ |
|
意向排他锁(IX) |
✗ |
✗ |
✓ |
✓ |
✓ |
✗ |
|
MDL读锁 |
✓ |
✗ |
✓ |
✓ |
✓ |
✗ |
|
MDL写锁 |
✗ |
✗ |
✗ |
✗ |
✗ |
✗ |
8.3 行级锁
行级锁,每次操作锁住对应的行数据。锁定粒度最小,发生锁冲突的概率最低,并发度最高。应用在InnoDB存储引擎中。InnoDB的数据是基于索引组织的,行锁是通过对索引上的索引项加锁来实现的,而不是对记录加的锁。对于行级锁,主要分为以下三类:
- 行锁(Record Lock):锁定单个行记录的锁,防止其他事务对此行进行update和delete。在RC、RR隔离级别下都支持。
- 间隙锁(Gap Lock):锁定索引记录间隙(不含该记录),确保索引记录间隙不变,防止其他事务在这个间隙进行insert,产生幻读。在RR隔离级别下都支持。
- 临键锁(Next-Key Lock):行锁和间隙锁组合,同时锁住数据,并锁住数据前面的间隙Gap。在RR隔离级别下支持。
|
锁类型 |
作用说明 |
锁定范围 |
支持的隔离级别 |
主要目的 |
|---|---|---|---|---|
|
行锁 |
锁定单个已存在的行记录,阻止其他事务对该行执行 UPDATE / DELETE |
单条记录本身 |
RC, RR |
防止修改或删除正在被操作的行 |
|
间隙锁 |
锁定索引记录之间的“空隙”,不包含记录本身 |
索引区间(不含端点记录) |
RR |
防止插入新记录导致“幻读” |
|
临键锁 |
行锁 + 间隙锁 的组合,既锁住记录本身,也锁住其前一个间隙 |
记录 + 前一个间隙 |
RR |
综合防止更新/删除 + 插入导致的幻读 |
8.3.1 行锁
- 共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排它锁。
- 排他锁(X):允许获取排他锁的事务更新数据,阻止其他事务获得相同数据集的共享锁和排他锁。
|
SQL 语句 |
行锁类型 |
说明 |
|---|---|---|
|
|
排他锁 |
自动加锁 |
|
|
排他锁 |
自动加锁 |
|
|
排他锁 |
自动加锁 |
|
|
不加任何锁 |
默认不加锁(依赖 MVCC 实现非阻塞读) |
|
|
共享锁 |
需要手动在 SELECT 之后加 |
|
|
排他锁 |
需要手动在 SELECT 之后加 |
默认情况下,InnoDB在 REPEATABLE READ事务隔离级别运行,InnoDB使用 next-key 锁进行搜索和索引扫描,以防止幻读。
- 针对唯一索引进行检索时,对已存在的记录进行等值匹配时,将会自动优化为行锁。
- InnoDB的行锁是针对于索引加的锁,不通过索引条件检索数据,那么InnoDB将对表中的所有记录加锁,此时 就会升级为表锁。
- 即:没有走索引的查询会导致全表锁定,严重降低并发性能!
8.3.2 间隙锁、临键锁与优化
“间隙锁”和“临键锁”是 InnoDB 在 RR(Repeatable Read)隔离级别下防止“幻读”的核心机制。
默认情况下,InnoDB在 REPEATABLE READ 事务隔离级别运行,InnoDB使用 临键锁 进行搜索和索引扫描,以防止幻读。
- 索引上的等值查询(唯一索引),给不存在的记录加锁时,临键锁优化为间隙锁。
-
场景: 使用唯一索引(通常是主键)进行等值查询(=),并且加锁(FOR UPDATE / LOCK IN SHARE MODE / UPDATE / DELETE),但该记录在数据库中 不存在。
- 默认行为:InnoDB 本应加 临键锁(即锁住该记录以及它前面的间隙)。
- 优化行为:因为索引是 唯一 的,数据库明确知道这条记录 绝对不存在。既然记录不存在,就不需要锁住“记录本身”(行锁),只需要锁住它周围的“间隙”(间隙锁),防止其他事务在这个位置插入这条记录即可。
- 结果:临键锁 退化为 间隙锁。
-
- 索引上的等值查询(普通索引),向右遍历时最后一个值不满足查询需求时,next-key lock 退化为间隙锁。
-
场景: 使用 普通索引(非唯一) 进行等值查询,并且加锁。因为普通索引可能包含重复值,InnoDB 必须向右遍历,直到遇到一个 不等于 查询值的记录为止,以确保没有漏掉任何匹配的行。
- 遍历过程:InnoDB 会锁定所有匹配的记录(行锁)。
- 停止条件:当向右遍历遇到第一个 不满足 等值条件的记录时,扫描停止。
- 优化行为:对于这个“第一个不满足条件的记录”,InnoDB 不需要锁住它本身(因为它不匹配查询条件),但需要锁住它与前一个匹配记录之间的 间隙,以防止其他事务插入一个符合查询条件的新记录(防止幻读)。
- 结果:在这个边界记录上,临键锁 退化为 间隙锁。
-
- 索引上的范围查询(唯一索引)--会访问到不满足条件的第一个值为止。
-
场景: 使用唯一索引进行范围查询(例如 >, <, between),并且加锁。
- 扫描逻辑:InnoDB 会扫描索引,锁定所有 满足条件 的记录。
- 边界处理:为了彻底防止幻读,InnoDB 必须锁住“最后一个满足条件的记录”与“第一个不满足条件的记录”之间的间隙。
- 关键点:为了确定这个间隙的右边界,InnoDB 必须访问(读取并加锁间隙)到第一个不满足条件的那条记录。它不能只在最后一条满足条件的记录处停下,否则别人可以在后面插入数据。
-
例:表 users 有如下数据(按主键 id 排序):
id: 1 3 5 7 9场景1:对 id=5 加锁(比如 SELECT ... FOR UPDATE WHERE id=5)
→ InnoDB 会加一个 临键锁,范围是 (3, 5]
也就是:
- 锁住 id=5 这条记录(Record Lock)
- 同时锁住 (3,5) 这个间隙(Gap Lock),防止别人插入 id=4
效果:别人不能改 id=5,也不能插入 id=4
场景2:查询 id=6(但这个记录不存在)
→ InnoDB 发现没有 id=6,于是加一个 间隙锁,范围是 (5,7)
因为这是“间隙”,所以只锁区间,不锁具体记录。
效果:别人不能插入 id=6(否则就幻读了),但可以改 id=5 或 id=7
场景3:范围查询 id > 5 AND id < 9
→ InnoDB 会对满足条件的记录(id=7)加 行锁,同时对前后间隙加 间隙锁
最终锁定范围可能是 (5,9) —— 包含 id=7 和间隙 (5,7)、(7,9)
效果:别人不能插入 id=6 或 id=8,也不能改 id=7
9. 系统数据库与常用工具
Mysql数据库安装完成后,自带了一下四个数据库,具体作用如下:
|
数据库 |
含义 |
|---|---|
|
mysql |
存储MySQL服务器正常运行所需要的各种信息(时区、主从、用户、权限等) |
|
information_schema |
提供了访问数据库元数据的各种表和视图,包含数据库、表、字段类型及访问权限等 |
|
performance_schema |
为MySQL服务器运行时状态提供了一个底层监控功能,主要用于收集数据库服务器性能参数 |
|
sys |
包含了一系列方便 DBA 和开发人员利用 performance_schema 性能数据库进行性能调优和诊断的视图 |
|
工具名称 |
主要用途 |
典型命令示例 |
适用场景 |
注意事项 / 技巧 |
|---|---|---|---|---|
|
mysql |
连接数据库执行 SQL |
|
日常开发、调试、查询 |
可用 |
|
mysqladmin |
管理操作(启停、刷新、状态等) |
|
启动/关闭服务、查看状态、创建库 |
需要权限;部分操作需停止服务 |
|
mysqldump |
逻辑备份(导出 SQL 脚本) |
|
备份、迁移、克隆数据库 |
大表慢;可加 |
|
mysqlbinlog |
解析二进制日志(Binlog) |
|
恢复数据、审计、主从同步问题排查 |
需知道 binlog 文件名;可过滤时间/位置点恢复 |
|
mysqlslap |
压力测试工具 |
|
模拟负载、 benchmark 测试 |
默认使用 test 库;可自定义 SQL |
|
mysqlimport |
导入文本数据(类似 LOAD DATA) |
|
批量导入 CSV/TXT 数据 |
要求文件名与表名一致;字段顺序匹配 |
|
mysqlshow |
快速查看库/表/列结构 |
|
快速浏览元数据 |
类似 |
10. 日志
10.1 错误日志
错误日志是 MySQL 中最重要的日志之一,它记录了当 mysqld 启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息。当数据库出现任何故障导致无法正常使用时,建议首先查看此日志。
该日志是默认开启的,默认存放目录 /var/log/,默认的日志文件名为 mysqld.log 。查看日志位置:show variables like '%log_error%'
10.2 二进制日志
二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句
作用:① 灾难时的数据恢复;② MySQL的主从复制。在MySQL8版本中,默认二进制日志是开启着的,涉及到的参数如下:show variables like '%log_bin%'
日志格式:
MySQL服务器中提供了多种格式来记录二进制日志,具体格式及特点如下:
|
日志格式 |
含义 |
|---|---|
|
STATEMENT |
基于SQL语句的日志记录,记录的是SQL语句,对数据进行修改的SQL都会记录在日志文件中。 |
|
ROW |
基于行的日志记录,记录的是每一行的数据变更。(默认) |
|
MIXED |
混合了STATEMENT和ROW两种格式,默认采用STATEMENT,在某些特殊情况下会自动切换为ROW进行记录。 |
show variables like '%binlog_format%';
日志查看:
由于日志是以二进制方式存储的,不能直接读取,需要通过二进制日志查询工具 mysqlbinlog 来查看,具体语法:
mysqlbinlog [ 参数选项 ] logfilename
参数选项:
-d 指定数据库名称,只列出指定的数据库相关操作。-o 忽略掉日志中的前 n 行命令。-v 将行事件(数据变更)重构为SQL语句-vv 将行事件(数据变更)重构为SQL语句,并输出注释信息
日志删除:
对于比较繁忙的业务系统,每天生成的binlog数据巨大,如果长时间不清除,将会占用大量磁盘空间。可以通过以下几种方式清理日志:
|
指令 |
含义 |
|---|---|
|
reset master |
删除全部 binlog 日志,删除之后,日志编号,将从 binlog.000001重新开始 |
|
purge master logs to 'binlog.*******' |
删除 ******* 编号之前的所有日志 |
|
purge master logs before 'yyyy-mm-dd hh24:mi:ss' |
删除日志为 "yyyy-mm-dd hh24:mi:ss" 之前产生的所有日志 |
也可以在mysql的配置文件中配置二进制日志的过期时间,设置了之后,二进制日志过期会自动删除。show variables like '%binlog_expire_logs_seconds%';
10.3 查询日志
查询日志中记录了客户端的所有操作语句,而二进制日志不包含查询数据的SQL语句。默认情况下,查询日志是未开启的。如果需要开启查询日志,可以设置以下配置:
mysql> show variables like '%general%';
+------------------+--------------------------------+
| Variable_name | Value |
+------------------+--------------------------------+
| general_log | OFF |
| general_log_file | /var/lib/mysql/localhost.log |
+------------------+--------------------------------+
2 rows in set (0.01 sec)修改MySQL的配置文件 /etc/my.cnf 文件,添加如下内容:
#该选项用来开启查询日志,可选值:0 或者 1;0 代表关闭,1 代表开启
general_log=1
#设置日志的文件名,如果没有指定,默认的文件名为 host_name.log
general_log_file=mysql_query.log10.4 慢查询日志
慢查询日志记录了所有执行时间超过参数 long_query_time 并且扫描记录数不小于 min_examined_row_limit 的所有的SQL语句的日志,默认未开启。long_query_time 默认为 10 秒,最小为 0,精度可以到微秒。
#慢查询日志
slow_query_log=1
#执行时间参数
long_query_time=2默认情况下,不会记录管理语句,也不会记录不使用索引进行查找的查询。可以使用 log_slow_admin_statements 和更改此行为 log_queries_not_using_indexes,如下所述。
#记录执行较慢的管理语句
log_slow_admin_statements = 1
#记录执行较慢的未使用索引的语句
log_queries_not_using_indexes = 111. 主从复制(binlog 和 relaylog)
主从复制是指将主数据库的DDL和DML操作通过二进制日志binlog传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
MySQL支持一台主库同时向多台从库进行复制,从库同时也可以作为其他从服务器的主库,实现链状复制。
优点:
-
主库出现问题,可以快速切换到从库提供服务。
-
实现读写分离,降低主库的访问压力。
-
可以在从库中执行备份,以避免备份期间影响主库服务。
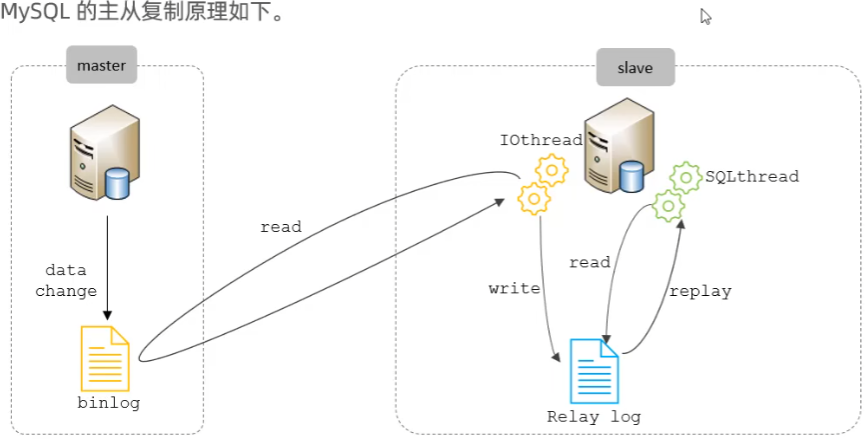
复制分成三步:
-
Master主库在事务提交时,会把数据变更记录在二进制日志文件Binlog中。
-
从库读取主库的二进制日志文件Binlog,写入到从库的中继日志Relay Log。
-
slave重做中继日志中的事件,将改变反映它自己的数据。
复制到三种类型:
1. 基于语句的复制: 在主服务器上执行的SQL语句,在从服务器上执行同样的语句。MySQL默认采用基于语句的复制,效率比较高。 一旦发现没法精确复制时,会自动选着基于行的复制。
2. 基于行的复制:把改变的内容复制过去,而不是把命令在从服务器上执行一遍. 从mysql5.0开始支持
3. 混合类型的复制: 默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制。
12. 分库分表
采用单数据库进行数据存储,存在以下性能瓶颈:
-
IO瓶颈:热点数据太多,数据库缓存不足,产生大量磁盘IO,效率较低。请求数据太多,带宽不够,网络IO瓶颈。
-
CPU瓶颈:排序、分组、连接查询、聚合统计等SQL会耗费大量的CPU资源,请求数太多,CPU出现瓶颈。
分库分表的中心思想都是将数据分散存储,使得单一数据库/表的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的。
垂直分库:以表为依据,根据业务将不同表拆分到不同库中。特点:
-
每个库的表结构都不一样。
-
每个库的数据也不一样。
-
所有库的并集是全量数据。
垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中。特点:
-
每个表的结构都不一样。
-
每个表的数据也不一样,一般通过一列(主键/外键)关联。
-
所有表的并集是全量数据。
水平分库:以字段为依据,按照一定策略,将一个库的数据拆分到多个库中。特点:
-
每个库的表结构都一样。
-
每个库的数据都不一样。
-
所有库的并集是全量数据。
水平分表:以字段为依据,按照一定策略,将一个表的数据拆分到多个表中。特点:
-
每个表的表结构都一样。
-
每个表的数据都不一样。
-
所有表的并集是全量数据。
-
shardingJDBC:基于AOP原理,在应用程序中对本地执行的SQL进行拦截,解析、改写、路由处理。需要自行编码配置实现,只支持java语言,性能较高。
-
MyCat:数据库分库分表中间件,不用调整代码即可实现分库分表,支持多种语言,性能不及前者。
13. 其他
13.1 HAVNG 和 WHERE
|
特性 |
WHERE |
HAVING |
|---|---|---|
|
执行时机 |
分组前过滤 (先过滤,再分组) |
分组后过滤 (先分组,再过滤) |
|
作用对象 |
原始数据行 (Rows) |
分组后的聚合结果 (Groups) |
|
聚合函数 |
不可用 (如 SUM, COUNT) |
可用 (专门用于判断聚合值) |
|
性能影响 |
高效 (减少参与分组的数据量) |
较低 (需先完成所有分组计算) |
FROM → WHERE (过滤行) → GROUP BY (分组) → HAVING (过滤组) → SELECT → ORDER BY
13.2 CHAR_LENGTH() 和 LENGTH()
|
特性 |
CHAR_LENGTH(str) |
LENGTH(str) |
|---|---|---|
|
计量单位 |
字符数 (Characters) |
字节数 (Bytes) |
13.3 LIKE 和 REGEXP
|
特性 |
LIKE |
REGEXP (正则表达式) |
|---|---|---|
|
匹配能力 |
简单模糊匹配 |
复杂模式匹配 |
|
通配符 |
仅支持 % (任意字符序列) 和 |
支持完整正则语法 (^, $, [], *, +, ?, ` |
|
匹配位置 |
默认匹配字符串任意位置 (除非手动加 %) |
可精确控制匹配开头 (^)、结尾 ($) 或特定结构 |
|
性能效率 |
高 (若前缀无 %,可利用索引) |
低 (通常无法利用普通索引,需全表扫描) |
13.4 BLOB 和 TEXT
|
特性 |
BLOB (Binary Large Object) |
TEXT |
|---|---|---|
|
数据类型 |
二进制字节串 |
非二进制字符串 |
|
字符集 |
无字符集概念,按字节存储 |
有字符集(如 utf8mb4),按字符存储 |
|
大小写敏感 |
区分大小写 (Case Sensitive) |
默认不区分 (取决于排序规则 Collation) |
|
排序/比较 |
基于字节值比较 |
基于字符集规则比较(可忽略大小写、重音等) |
|
典型用途 |
图片、视频、音频、加密数据、压缩包 |
文章、评论、日志、HTML 代码等文本内容 |
13.5 主键和候选键
- 主键是从候选键中选择的、用于唯一标识表中每个记录的一个特定键(不允许 NULL 值)。
- 候选键是表中所有能唯一标识记录的一个或多个字段集合(都满足唯一性且字段数量最少),主键是其中被“选定”的那个键,每个表只能有一个主键。
13.6 TIMESTAMP 与 UPDATE CURRENT_TIMESTAMP
TIMESTAMP 数据类型可以被配置为自动更新。在定义列时加上 ON UPDATE CURRENT_TIMESTAMP 子句,每当该行数据发生任何修改(UPDATE 操作)时,MySQL 会自动将该字段的值更新为当前的系统时间。
13.7 MyISAM Static 和 Dynamic
MyISAM 存储引擎的两种表格形式,主要区别在于列存储方式:
-
Static(静态):表中所有行都使用固定的存储长度。如果声明的列是 CHAR 或固定长度的类型,它总是静态的。即使 VARCHAR 列,如果表中没有 BLOB/TEXT,且所有 VARCHAR 列都声明了足够大的长度,MySQL 也可能将其转为静态格式以提升性能。
-
Dynamic(动态):表中包含可变长度列(如 VARCHAR、BLOB、TEXT),每行仅存储实际数据长度,节省空间但可能产生碎片。
13.8 NOW()和CURRENT_DATE()
- NOW()命令用于显示当前年月日、时分秒。
- CURRENT_DATE()仅显示当前年月日。
13.9 获取当前的Mysql版本
SELECT VERSION();13.10 列设置为AUTO INCREMENT时在表中达到最大值,会发生什么
它会停止递增,任何进一步的插入都将产生错误,因为密钥已被使用。
13.11 找出最后一次插入时分配了哪个自动增量
LAST_INSERT_ID 将返回由 Auto_increment 分配的最后一个值,并且不需要指定表名称。
13.12 看到为表格定义的所有索引
SHOW INDEX FROM 表名;13.13 得到受影响的行数
-- 执行更新
UPDATE users SET status = 1 WHERE age > 18;
-- 立即获取受影响行数
SELECT ROW_COUNT();
-- 结果:例如 50 (表示有 50 行的 status 从 0 变成了 1)-- 第一次查询获取数据
SELECT * FROM users WHERE age > 18;
-- 第二次查询获取数量 (开销较大,不推荐在大表频繁使用)
SELECT COUNT(*) FROM users WHERE age > 18;13.14 运行批处理模式
source /path/to/脚本文件.sql;13.15 显示前50行
SELECT * FROM 表名 LIMIT 50;13.16 最多可以使用多少列创建索引
16个。
13.17 访问控制列表
访问控制列表 (ACL) 在 MySQL 中是权限管理系统的核心数据结构,存储用户账号、密码哈希、全局/数据库级/表级权限信息的底层数据,物理上存储在 mysql 系统数据库中。
-- 用户基本信息
mysql.user # 用户账户和全局权限
mysql.db # 数据库级权限
mysql.tables_priv # 表级权限
mysql.columns_priv # 列级权限
mysql.procs_priv # 存储过程和函数权限
mysql.proxies_priv # 代理用户权限- 定义:它是服务器内存中缓存的一组表格,记录了所有用户账号及其对应的权限信息(如能访问哪些库、表、列,能执行什么操作)。
- 工作原理:当用户发起连接或执行 SQL 时,MySQL 会将请求与 ACL 进行比对。只有匹配到允许规则,操作才会被执行;否则拒绝访问。
- 来源:ACL 的内容来源于系统数据库 mysql 中的权限表(如 user, db, tables_priv 等)。
- 刷新机制:执行 GRANT/REVOKE 命令或 FLUSH PRIVILEGES 时,ACL 会重新加载生效。
13.18 记录货币用什么字段
NUMERIC 和 DECIMAL 类型(被Mysql实现为同样的类型),用于存储精确的固定小数,绝对没有精度丢失。
13.19 数据表什么情况下容易损坏
1. 硬件与系统故障 (最常见)
- 突然断电:服务器在写入数据时突然断电,导致磁盘文件头或数据块写入不完整。
- 磁盘坏道:硬盘物理损伤导致存储的数据位翻转或丢失。
- 内存错误:RAM 故障导致写入磁盘的数据本身就是错误的。
- 操作系统崩溃:OS 死机或强制重启,文件系统未正常同步。
2. 不当的操作与管理
- 强制杀死进程:在 MySQL 进行写操作时,使用 kill -9 强制杀掉 mysql 进程,跳过正常的清理和关闭流程。
- 直接操作文件:在 MySQL 服务运行时,直接在操作系统层面复制、移动、删除或修改 .frm, .MYD, .MYI (MyISAM) 或 .ibd (InnoDB) 文件。
- 非正常关机:未执行 service mysql stop 而直接拔电源或重置虚拟机。
13.20 输入字符为十六进制数字
|
场景 |
语法/函数 |
示例 |
结果/说明 |
|---|---|---|---|
|
1. 直接字面量 |
|
SELECT 0x41; |
'A' (自动转为字符串/二进制) |
|
2. 字符串转 Hex |
HEX() |
SELECT HEX('A'); |
'41' (返回十六进制字符串) |
|
3. Hex 转字符串 |
UNHEX() |
SELECT UNHEX('41'); |
'A' (还原为原始字符) |
|
4. 数值进制转换 |
CONV() |
SELECT CONV(10, 10, 16); |
'A' (10 进制转 16 进制通用) |
|
5. 二进制显示 |
HEX() + 列 |
SELECT HEX(blob_col); |
将二进制字段以 Hex 形式查看 |
13.21 数据库三范式
原子性:列不可再分。表中的每一个字段都必须是原子性的,即不能再分割成更小的部分。每一列只能存储一个值,不能存储数组、列表或组合值。
完全依赖:非主键列必须完全依赖于主键。
传递依赖:非主键列之间不能相互依赖。
13.22 默认端口
3306
13.23 控制内存分配的参数
- innodb_buffer_pool_size:最重要。InnoDB 引擎的数据和索引缓存区。通常设置为物理内存的 50%-70%。
- innodb_log_buffer_size:InnoDB 重做日志(Redo Log)的缓冲区。
- sort_buffer_size:排序操作(ORDER BY, GROUP BY)使用的缓冲区。
- read_buffer_size:顺序读操作的缓冲区。
- read_rnd_buffer_size:随机读操作(如排序后读行)的缓冲区。
- join_buffer_size:表连接(JOIN)不使用索引时的缓冲区。
- max_heap_table_size:内存临时表的最大大小(超过则转磁盘)。
- thread_stack:每个线程的栈空间大小。
13.24 大字段拆成子表的好处
表中有大字段如text,且不会经常更新,以读为主,将该字段拆成子表的好处:
- 减少 I/O 开销:主表行宽变窄,单次磁盘读取可加载更多有效数据行,减少物理 I/O 次数。
- 提高缓存命中率:更多热点数据(非大字段部分)能放入内存缓冲池(Buffer Pool),避免大字段挤占宝贵内存。
- 加速索引扫描:若主表需全表扫描或覆盖索引查询,避开大字段可显著降低数据传输量,提升速度。
- 按需加载:仅在真正需要查看大字段内容时才关联子表,符合“读为主但非每次必读”的场景。
13.25 enum
ENUM 是一个字符串对象,用于指定一组预定义的值,并可在创建表时使用。 Create table size(name ENUM('Smail,'Medium','Large');
列中的每个元素只能取这些预定义值中的一个;
ENUM 不是按字母顺序排序,而是按定义时的索引顺序排序。
13.26 一行数据最大长度
65535 字节
13.27 VARCHAR(N) 类型,utf8编码,N最大值
(65535 - 1 - 2) / 3
- 65535:MySQL 行大小的最大硬限制(216−1216−1 字节)。
- -2:VARCHAR 的长度前缀。
- -1:NULL 值标志位。
- /3:utf8 字符集下,每个字符最大占用 3 字节。
13.28 记录不存在时 insert,存在时 update
INSERT ... ON DUPLICATE KEY UPDATE
表中必须定义了 主键 或 唯一索引。只有当插入的数据违反了这些唯一性约束时,才会触发更新逻辑。
INSERT INTO table_name (id, name, age)
VALUES (1, 'Alice', 25)
ON DUPLICATE KEY UPDATE
name = VALUES(name),
age = VALUES(age);
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 44
44 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)