DeepSeek-GRPO推导&DeepSeekMathV2模型讲解
一、历史知识回顾(PPO等)
今天来学习GRPO算法,它是针对大语言模型改进的一种强化学习算法。在学习本节之前,请先看完之前讲PPO原理的blog。我们开始。首先我们快速回忆一下策略梯度算法,这就是策略梯度的公式。
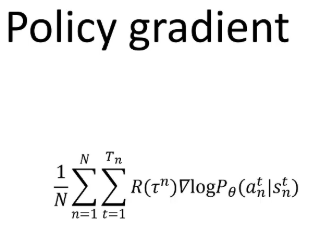
这里N代表N个轨迹trajectory,t代表step,TN代表第N个trajectory,一共有TN个step,R(τ_n),N代表第N个trajectory得到的回报,Pθ(ant|snt)代表在第N个trajectory第t个状态S下当前策略执行动作ant的概率。
策略的梯度算法对策略的调整原则也很直观,如果这个trajectory得到的回报是正的,就增加这个trajectory里所有状态下执行当时动作的概率,回报越大增加的越多。如果这个trajectory得到的回报是负的那就减少这个trajectories里所有状态下执行当时动作的概率,回报越小减少的就越多。
这里对于策略网络在给定一个状态下执行当时动作概率进行调整的信号,就是以所在trajectory的整体回报作为指导信号的。但是这样对一个trajectory里所有步骤的动作都统一做调整,有点不太精确。因为一个动作不会影响它之前的reward,它只会影响它执行之后的reward。另一点是一个动作是可以对他接下来的reward产生影响,但是有可能只影响接下来的几步,而且影响会逐步衰减。后边的reword更多的是受他当时的动作影响的,所以这里就将整个trajectory的回报改为对每一个动作之后reward的逐步衰减累加值。通过这样的修改后,就能给调整每一个状态下执行当时动作更为精确的指导信号。
更进一步,在一些坏的局势下做什么动作都会得到负的奖励。这时候需要策略网络,不是根据每个动作产生的回报的绝对值来调整,还是根据每个动作相比当前情况下其他动作的相对值来调整动作概率。所以引入了baseline,就是用当前动作的回报减去当前状态的期望回报,也就是baseline。
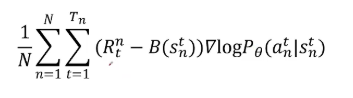
接着引入了优势函数的概念。Qθ(s, a)表示在state s下做出action a期望得到的回报,也叫做动作价值函数。Vθ(s)表示在状态S下,不论做任何动作,期望得到的回报叫做状态价值函数,Aθ(s, a) = Qθ(s, a) - Vθ(s),它就是优势函数,表示在状态S下做出动作A比其他动作能带来多少相对优势。这样用优势函数代替之前的回报,它就能为调整某一状态下执行当时动作的概率提供最精确的指导信号。如果在一个状态下,不论是好的状态还是坏的状态,执行当时动作比其他的动作优势大,那就提升在当时状态下执行当时动作的概率。反之,就减少在当时状态执行当时动作的概率。

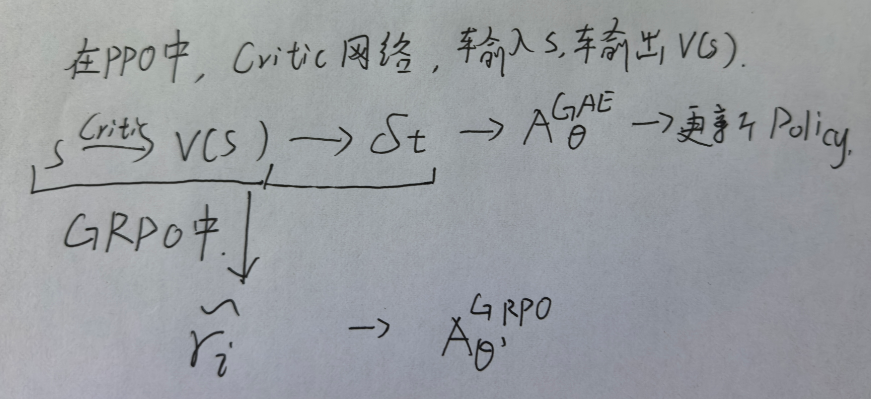
可以看到,优势函数可以为策略网络的学习提供准确的监督信号。但随之而来的问题是如何准确的评估在某一状态下采取某一动作的优势。在我之前讲PPO的算法里,我详细讲过GAE优势函数。
这里我们快速再看一下,优势函数等于动作价值函数减去状态价值函数。然后动作价值函数可以表示为当前步的reward加上衰减因子gamma乘以下一步的状态价值函数。然后将动作价值函数的表达式代入优势函数里,就可以看到优势函数里就只有状态价值函数了。这样我们就只需要训练一个状态价值函数的网络,用来预测从一个状态到整个trajectory结束的获得的回报的期望。

而每一个状态价值函数都约等于采样当前步的真实reward值加上衰减因子乘以下一个状态的状态价值。这样可以一步采样、两步采样、三步采样来估算优势函数了。采样越少,大部分都是状态价值网络估计的值,越稳定,但是系统偏差越大,采样越多,方差越大。GAE优势函数就是给不同的采样步骤赋予不同的权重加权求和得到的,从而得到一个不错的优势。
估计可以看看到从最初原始的策略网络里,用整个trajectory的回报值作为调整某一状态下做出当时动作概率的指导信号。到后来考虑action只影响自己后面step的reward,并且会逐步衰减,再到后面考虑到每个action要减去当时状态的baseline,再到最后定义出优势函数。我们做的努力就是让对某个状态下做出当时动作的概率的指导信号越来越精确化。

现在我们回到大模型生成场景下的强化学习。我们看一下GAE优势函数的计算。比如用户问了一个问题,什么是数据库?大模型生成了两个回答,并且我们用训练好的reward模型给这两个回答不同的打分。Reward模型只能对整个回答给出一个得分,而大模型是逐个生成token的。它以当前已经生成的序列作为当前状态,生成下一个token作为action。Reward的模型不能给每个action,也就是每个token给出reward值,他只能把回答作为一个整体给出一个打分。但是在训练状态价值网络时是需要每一步的reward的这该怎么办呢?
之前我们在PPO里讲过,reward模型给出的得分只放在最后一个token那里,其他token的得分都为零,然后在此基础上加上当前训练模型和参考模型之间的KL散度乘以一个负值,这样我们就得到每个token对应的reward值了。很明显最后一个token的reward的值是有意义的,其他的token reward的值只是用来限制新的模型,不能和原来的模型差别太大的KL散度。这些用KL散度生成的reward值是有一些作用,但是作用有限。
Reward值最好是能直接评价这个动作对整个trajectory带来的是正面影响还是负面影响。比如玩游戏时,某一步你吃到金币reward值就为正,你掉血reward的值就为负。但是在大模型生成时,我们都是以整体回答作为评判标准的,很难给每个token生成reward值。这里用KL散度实在是有些牵强。
再来回顾一下PPO算法里是怎么计算每个token的GAE优势值的。
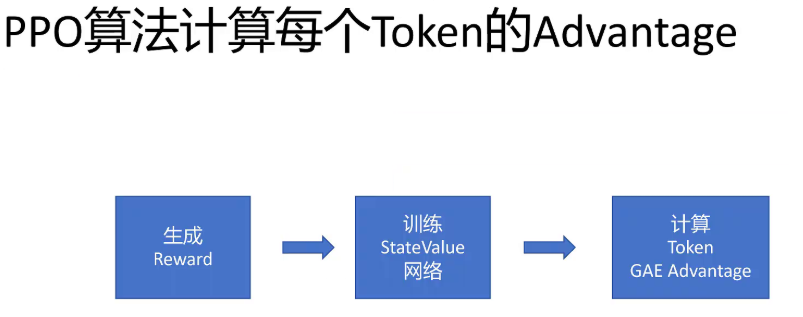
首先要为每个token生成reward值,然后用这些reward值训练状态价值网络。最终利用每个token的reward的值和状态价值共同计算出GAE的值。不论是对状态价值网络的训练,还是计算GAE的优势值,其基础监督信号都来自每个token的reward。而我们之前说过,我们给每个token的reward值并不准确,所以这里的状态价值网络和GAE的优势计算并不是最优的。
注意这里并不是说PPO的算法这一套做法不好,而是不适合大模型生成的场景。因为我们只能对最终输出给出一个奖励值,而无法给其中每一步,也就是每一个token给出具有参考价值的奖励值,导致PPO在训练大模型时不是最优的。
二、GRPO推导
GRPO是怎么解决这个问题的呢?首先针对同一个prompt,通过采样生成多个不同的回答。然后调用reward模型或者基于规则的reward的函数,只要能给出一个reward的值,表示这个回答的好坏就可以。
GRPO的思想是,既然reward是针对整个回答的,无法给出每个token具有意义的reward的值,那就把一个回答序列看成一个整体。Prompt是当前的状态,那么一个回答序列就是一个action。一个prompt下我们生成多个回答,就相当于在一个状态下采取了多个不同的action。大模型回答问题的场景下,整个trajectory就只有一个状态。一个action状态就是prompt序列,action就是输出序列。
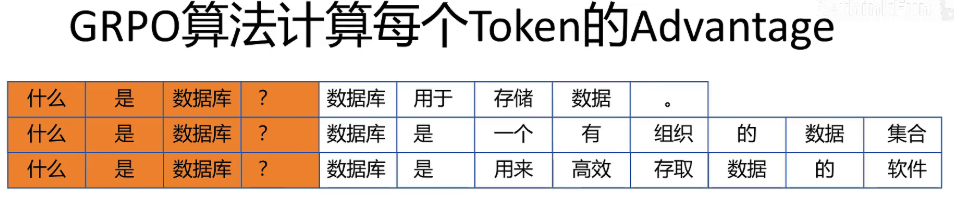
那么根据前面我们讲的优势函数的思想,怎么体现不同回答 也就是不同action的优势呢?那就是每个回答得到的reward值减去所有回答得到的reward的值的均值。同时为了在不同的prompt和回答之间的数据的一致性,在减去均值时同时除以这一组回答reward值的标准差,这样就得到了GRPO算法里每个回答的优势值。
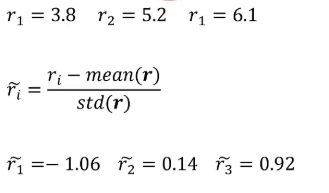
因为我们把整个回答所有的token都看成一个整体,就把这个优势值复制分配给每个token,这就是GRPO(group relative policy optimization)群体相对策略优化。、
相比PPO它不用训练状态价值函数就可以直接得到优势值,简化了训练过程。并且这里的优势值在大模型场景下也更有意义一些。这是PPO算法里的重要性采样函数。

这里就引入了一个老的策略网络θ一撇。然后就可以用策略网络θ一瞥采集的数据计算优势函数,用当前策略网络的概率除以老的策略网络的概率。然后就可以重复利用数据多次训练当前的策略网络。
最后我们来对比一下PPO和GRPO的公式。首先这是PPO的目标函数,就是让这个值尽可能的大损失函数。在之前PPO的视频里也详细讲过,它有两种方式,一种是增加KL散度的,一种是采用截断函数的方式。
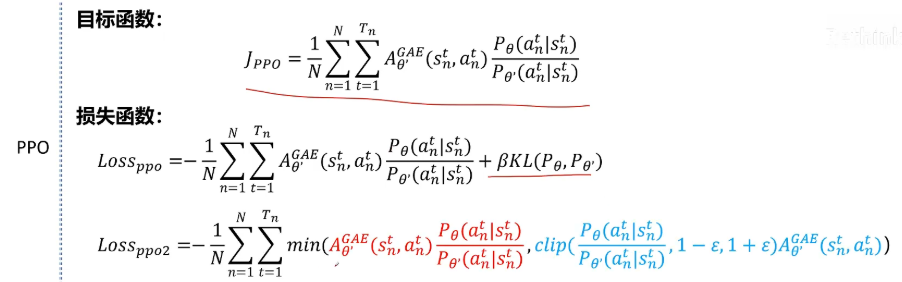
为了和原始GRPO论文里的目标函数一致,这里GRPO的目标函数除了将优势函数替换为GRPO的优势函数外,同时应用了截断函数和KL散度。截断函数和KL散度都是为了约束当前训练的策略网络不能和参考的网络差别太大,实际上只要一个就可以,没有必要两个都加。
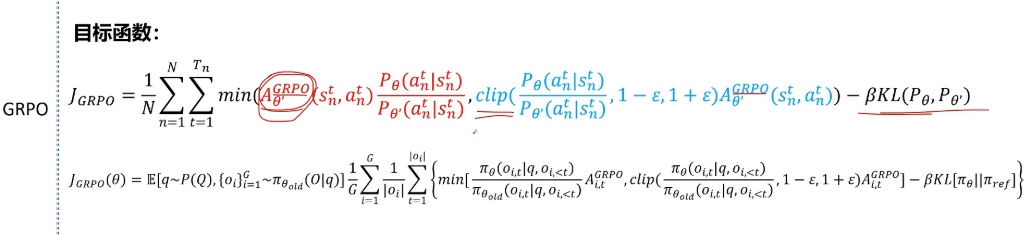
后边我们看transformer TRL库里的GRPO trainer的实现时就可以发现,他只用了KL散度,没有用截断函数。所以GRPO的目标函数和PPO的唯一区别就是将PPO里的GAE优势函数替换成了GRPO的优势函数。其他像增加KL散度和截断函数这些都是辅助的,而且PPO里也都出现过。
所以GRPO的贡献就是提出了一个不需要训练状态价值网络就可以估算出每个token优势值的方法。而且这个方法更适合大模型生成强化学习这个场景。
再看一下GRPO 论文里给的这个公式,实际上它和我上面的式子是完全一致的。前面这里大Q表示问题,从问题大Q里采集问题小q,然后老的策略网络基于这个问题Q生成一组output O,output一共有G个?其中i表示每个。Oi的绝对值表示每个输出序列的长度,然后这里的Πθ表示当前的训练网络,括号里表示第i个输出序列里根据他位置之前的token预测出t位置token的概率。这里是Πθold的概率,这是第i个输出序列。第t个位置token的GRPO 优势值,后边是截断函数,后边是KL散度。另外一个小的细节是这里不光对所有的输出序列,也对一个序列内所有的token求了平均值。
GRPO的贡献就是提出了一个不需要训练状态价值网络就可以估算出每个token优势值的方法。
三、DeepSeekMathV2模型讲解
下面来学习DeepSeekMathV2模型,它是一个可自验证的数学推理模型。他在数学竞赛数据集上碾压其他模型,并且表现已经超越人类。首先我们看问题背景,DeepSeek为什么一直对数学模型情有独钟呢?因为数学作为人类知识皇冠上的明珠,通过解决数学问题可以大大提升大模型的推理能力。DeepSeek在自己的MathV1版本时提出了GRPO强化学习算法,后来被成功的应用在DeepSeekR1上面。DeepSeekMathV2也就是我们今天这个视频要学习的模型,可自我验证的数学推理模型。它的训练方法也被应用了在刚发布的DeepSeekV3.2上,所以DeepSeek一直都是在数学问题上验证训练方法,然后将这个方法应用于通用大语言模型的训练。
之前在用强化学习训练数学模型时,都是以有确定答案的问题来训练模型,并以最终答案是否正确作为奖励信号来训练数学模型。如果模型给出的最终结果正确,即使推理过程错误,也能得到全部奖励,这明显是不合理的。

而且有很多数学问题是纯证明题,在意的是严谨的证明过程。另外,我们最终的目的是训练通用大语言模型,我们更看重的是模型的推理过程的严谨性,而不是只看重答案。所以研究人员在训练DeepSeekMathV2模型之前的一个期望就是得到一个能推理并且能验证自己推理是否正确的模型。如果一个模型拥有了这种能力,那可以大大增加模型的智能水平。
并且在这里研究人员通过对比人类有以下几个见解来指导模型的训练过程,1、人类在不知道参考答案的情况下也可以发现证明中的问题,挑问题总是比解决问题容易。2、如果经过多次努力的检查,仍无法发现证明的错误,那这个证明更可能是正确的。3、发现一个证明中的错误越困难,说明这个证明越接近正确答案。

接下来我们就来看DeepSeekMathV2是怎么实现的。首先我们看训练数据的采集,第一步从AOPS竞赛中抓取题目,优先选择奥数题选拔赛以及2010年之后明确要求写证明的题,一共收集了17503道题,把这个题目数据集记作Dp。第二步用DeepSeekV3.2 exp thinking模型让它多轮迭代优化,生成所有这些题的候选证明。第三步,请数学专家按照评估标准对候选证明打分,得到数据集Dv其中Xi是数学题,Yi是模型生成的候选证明,Si是数学专家给这个证明的打分,打分必须是0,0.5或1分,1分代表证明完全没有问题,0.5分代表证明基本正确,但是有瑕疵。0代表证明有明显的错误。

数学专家看完了所有大模型生成的证明过程,并给出了评分。我们可以把这些专家的评分作为生成模型的奖励值来训练生成模型。但是这个数据可来之不易,我们不用这些数据直接训练生成模型,我们要用这个数据训练一个验证模型。这个验证模型你输入一个数学证明题和一个证明过程,这个验证模型可以输出证明的得分。这样我们就训练了一个reward model,将来可以对任意的数学题根据生成模型的生成证明给出奖励值,监督生成模型的训练。

那怎么训练一个验证模型呢?基础模型用的是DeepSeekV3.2 EXP SFT模型。它是一个在数学和代码推理数据集上微调过的模型。通过提示词让它根据数学题和给出的证明生成对证明的验证结果。验证结果必须包含两部分,一部分是问题总结,指出证明中的问题。第二部分是对这个证明的评分。
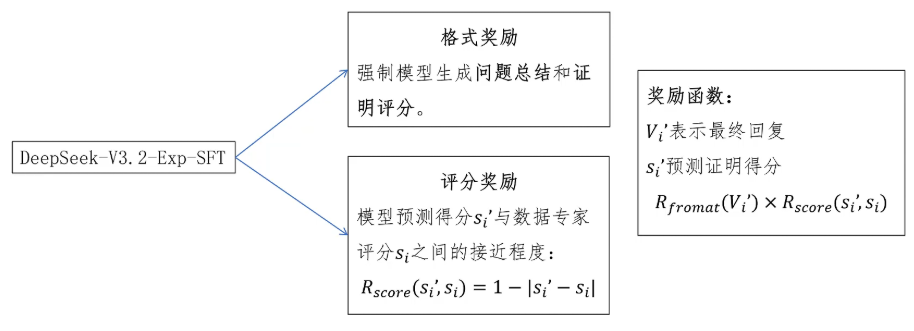
训练方法还是采用GRPO的强化学习方法。它的奖励函数由两部分构成,一部分是格式奖励,它强制模型必须按照固定的格式输出问题总结和证明评分奖励的。另一部分是评分奖励,用来计算模型给出的证明评分si一撇和专家给出的评分si之间的差距,差距越小奖励越大。最终的奖励函数就是格式奖励 * 验证评分奖励。
我们把这个训练出来,可以根据数学题和证明过程给出错误说明和证明得分的模型,叫做验证模型或者验证器。这样训练出来的验证器有个问题,就是当验证器给出的证明得分是0或0.5时,也就是他认为证明过程有问题时,给出的问题描述可能是错误的。我们最终的目标是想让模型根据问题描述来修改自己的证明过程。如果验证器生成的问题描述不对,那就没用了。之前我们让数学专家给的监督信号只是给证明过程是否正确打分,并没有给出具体是什么问题的信息。于是,我们把那些数学专家再叫回来,让根据上边办法训练的初始验证器先生成一批验证信息,其中包含了对证明过程问题的描述,让这些数学专家再看看这个验证器生成的这些验证信息是否正确。

数学专家还是打分,分为0分、0.5分和1分。这个打分叫做Msi,是meta的意思,生成的这个数据集叫做Dmv元验证数据集,它包含数学问题证明,对证明的验证,对验证的打分。因为这是对验证数据的验证数据,所以叫做元验证数据集。这里是进行源验证的提示词。最终用元验证数据集可以训练一个元验证模型,也是采用GRPO强化学习进行训练。
奖励函数和训练验证模型时一样,也是由两部分构成。一部分是格式奖励,一部分是打分奖励。有了元验证模型,可以重新训练一个增强的验证器了,用的数据集还是之前训练验证器的数据集Dv。增强需验证器的奖励函数由三部分构成,一部分是格式奖励,一部分是验证奖励,最后一部分是元验证奖励,用来奖励他对证明过程的验证是否正确。元验证奖励由原验证模型打分生成,训练增强验证器时还同时用了训练原数据验证器的数据集Dmv,让增强验证器同时具备验证和元验证的能力。通过这样训练发现增强的验证器对证明问题描述的质量从0.85分提升到0.96分,这个得分是元验证器给出的,同时还保证了验证器对证明的打分准确率不变。

听到这里可能觉得有点绕,我们再来理一遍。首先收集了原始数学题Dp它里面只有题用Xi表示,然后用DeepSeek V3.2 EXP thinking模型生成证明Yi,接着通过数学专家给出Xi和Yi对应的证明,打分si得到验证数据集。Dv有了验证数据集,利用DeepSeek V3.2 EXP SFT 模型训练一个初始验证模型,它的奖励函数是格式奖励乘以验证奖励。有了初始模型,我们让它针对Xi Yi生成验证信息Vi。这些验证信息包含了对证明错误的描述,需要专家来核对这些描述是否正确。于是专家给出元验证打分,Msi得到源验证数据集Dmv有了元验证数据集,可以用GRPO强化训练一个元验证模型。这个强化学习的奖励函数和训练验证器的奖励函数是类似的,是格式奖励 * 元验证奖励。
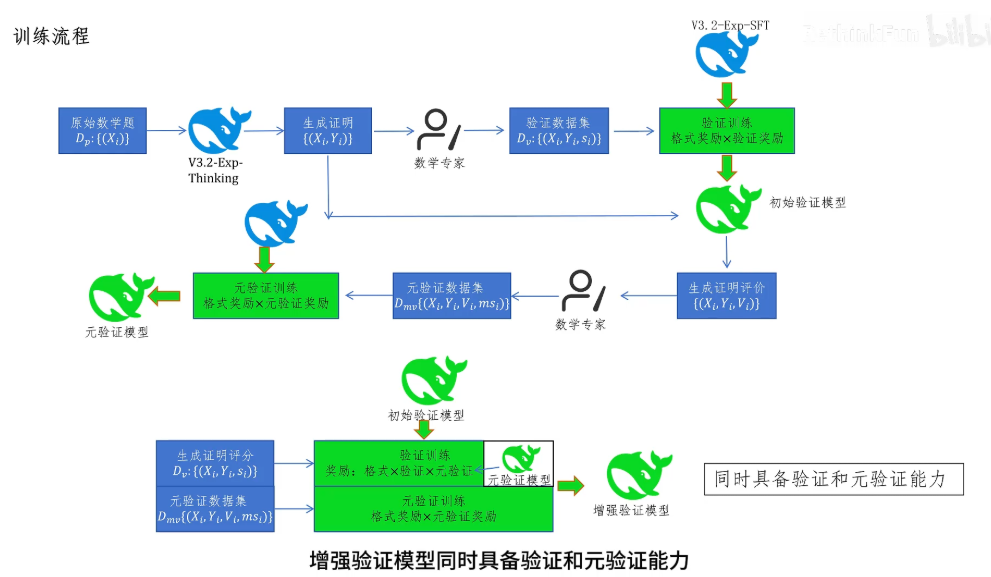
有了元验证模型后,它可以对验证模型输出的证明错误进行评判,可以更好的监督验证模型了。所以我们用初始的验证模型的权重重新训练验证模型。此时对验证模型的奖励就有三部分构成,包括格式奖励、验证打分奖励,还有元验证模型对验证模型生成的证明问题质量打分的元验证奖励。同时还有训练元验证器的数据集和训练方法,对初始验证模型进行训练,最终得到一个增强验证模型。增强验证模型同时具备验证和源验证的能力。
现在我们就来看生成模型之前的强化学习。在训练生成模型时,都是通过最大化验证模型给出的得分的方式来训练模型的。但是这可能导致模型结果正确。但是中间推理错误的问题,作者还有一个观察,那就是对于一个复杂的数学问题,用生成器加验证器一起解题效果最好。生成器先生成证明过程,验证器找出问题,生成器再优化,这样的迭代可以提升模型解题的成功率。但是如果在一次生成中让生成器生成证明过程并自己检验时,生成器都倾向于说自己的证明没有问题,无法发现证明问题。
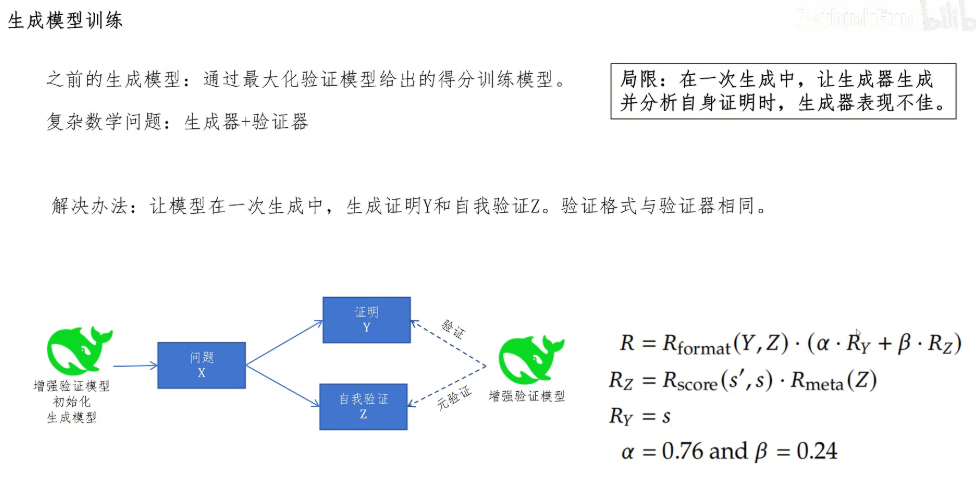
作者想到的改进办法就是让生成模型在一次生成中生成证明Y和自我验证Z,验证格式与验证器相同,具体过程是用增强验证模型初始化生成模型。对于一个问题,X生成模型生成证明Y和自我验证Z然后用增强验证器来验证证明Y元验证自我证明Z分别给出评分,利用这些评分来监督训练一个可自我验证的生成器。我们看这里用GRPO强化学习算法训练生成器的奖励信号R,第一部分是对生成模型生成的证明Y和自我验证Z的格式奖励。后边乘以证明奖励RY和自我验证奖励RZ的加权和,其中证明奖励RY的值就是增强验证器给出的验证打分S,证明α权重是0.76,它的权重比自我验证权重0.24大表明更鼓励模型给出正确的证明。
再看第二部分,自我验证的奖励RZ,它等于生成模型给自己证明的打分与增强验证模型的打分之间的一致性奖励Rscore 乘以 对生成模型找出自身生成问题的Rmeta(Z)打分,Rmeta打分是增强验证模型的元验证给出的打分。这个奖励函数鼓励模型给出正确的证明,在证明错误时,如果能验证出自己的错误也可以得到奖励。如果证明错误并且没有验证出来,得分最低。
生成模型和验证模型是一个互相促进的关系。验证模型可以提供监督信号,提升生成模型。生成模型提升了证明的能力,让验证模型越来越难验证生成的证明是否正确。作者通过巧妙的设计,利用这一点可以生成更好的对验证模型的训练数据,从而提升验证模型。他们两个模型互相共享权重迭代提升,模型性能越来越好。当然这个提升也不是无限制的,它只是能让生成模型的性能逼近它的极限,而它的极限是在预训练时就决定的。
下边我们就来看作者是如何利用提升的生成模型,生成可以提升验证模型的训练数据的。首先我们之前提过作者通过对人类世界的观察得到几个见解。一个是如果经过多次努力检查仍无法发现错误的证明,那么这个证明有很大可能就是正确的。另一个是发现一个证明中的错误越困难,则说明这个证明越接近正确答案。

我们看作者是如何自动生成训练验证器的数据的。1、对于生成器生成的每个证明,用验证器生成N个相互独立的验证分析。2、对于发现问题的分析,再生成M份元验证分析。3、对于一个证明考察验证中找出问题,并且给出最低分(0或0.5分)的那些验证分析。如果有K条原验证判定证明确实有误,则给这个证明最低分(0或0.5分)。如果所有的源验证都认为判定无效,也就是验证器给证明找的问题不成立,则给这个证明1分,否则丢弃该条证明数据或者交给数学专家标注。4、最后收集上面的数据,迭代训练验证模型,通过上面的步骤生成模型,和验证模型共享检查点,互相提升,逼近性能极限。
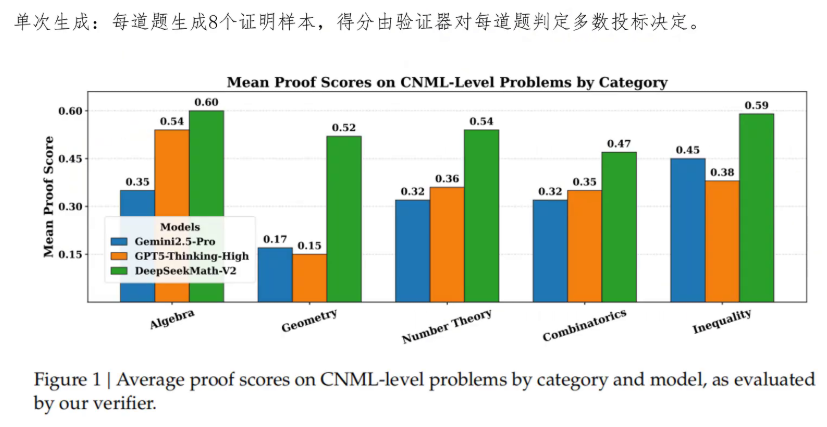
最后就得到了一个可以自我验证的生成模型了,并且这个自我验证是真实的。最后我们看一下DeepSeekMathV2让人惊艳的结果。首先是训练好的生成器单次生成的数学平均成绩,他会用生成器对每道题生成八个证明,样本得分由最后的验证器对每道题的判定的多数投票决定。可以看到,DeepSeekMathv2的性能全面超越Gemini 2.5 pro和GPT5 thinking high模型。
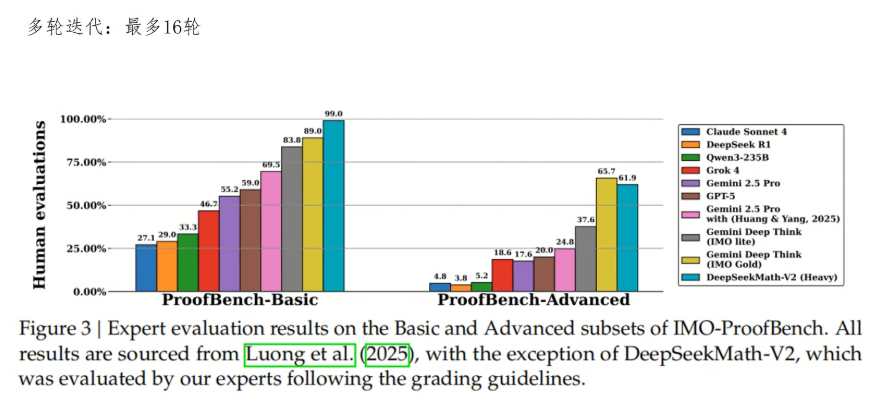
再看多轮迭代的场景,允许模型根据自己的验证信息来修改证明过程。DeepSeekMathV2的表现也非常不错,特别是在basic数据集上几乎接近满分,比第二名高了十分。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 20
20 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)