openJiuwen-DeepSearch 助力帮我搞定产品经理需求拆解分析工作,打造2026优秀员工
openJiuwen-DeepSearch 是一种基于大语言模型(LLM)的智能搜索范式,其核心在于通过多轮迭代的“搜索-阅读-推理”循环,主动构建证据链、交叉验证信息,并最终生成结构化、高可信度的答案。它不同于传统搜索引擎的一次性关键词匹配,也超越了早期 RAG(检索增强生成)系统的单次检索限制。
一、背景说明:
在传统Agent搜索中,用户在输入问题后,传统搜索与Agent搜索在架构设计和应用逻辑上存在本质差异,导致传统搜索难以满足现代智能任务的需求。其核心痛点主要体现在信息处理模式、语义理解能力、上下文管理及任务执行深度等方面。
1.1 缺乏“持续探索”能力:
- 传统搜索采用“一次性”查询机制,用户输入关键词后返回网页列表,无法根据结果反馈进行迭代优化。
- Agent搜索则具备多轮、流式、可追问的特性,一个任务可能触发数十次搜索请求,持续修正方向直至达成目标。
痛点表现:当查询“北京今年入秋时间及最佳赏秋地”,传统搜索仅返回多个链接,需用户自行整合;而Agent会先查入秋时间,再结合气候数据推荐香山、奥森等地,并评估人流高峰给出出行建议。
1.2 无法应对模糊意图:
- 传统搜索依赖倒排索引和关键词匹配,对同义词、上下位词或隐含语义识别能力弱。
- Agent搜索通过大模型实现语义嵌入与意图拆解,能理解“适合程序员的冬季通勤穿搭”背后涉及“保暖”“久坐舒适性”“办公场景”等多维需求。
痛点表现:搜索“孩子发烧三天不退怎么办”,传统系统可能返回感冒药广告页,而Agent则会推理是否需排查流感、川崎病等,并建议就医指征。
1.3 DeepSearch与传统搜索的核心区别:
传统搜索是“关键词匹配+单次检索”的信息罗列工具,而DeepSearch是“语义理解+多轮推理”的智能求解系统。它不仅回答“有哪些”,更致力于回答“为什么”和“怎么办”。
| 维度 | 传统搜索 | DeepSearch |
|---|---|---|
| 技术基础 | 倒排索引、关键词匹配 | 大语言模型(LLM)+ 检索增强生成(RAG) |
| 信息处理方式 | 静态抓取网页并建立索引 动态执行“搜索 → 阅读 → 推理”循环 | |
| 智能水平 | 被动响应查询 | 主动拆解问题、规划子任务 |
📌 原因解析:
传统搜索依赖爬虫定期抓取网页,构建静态数据库,用户输入关键词后通过匹配相关页面。而DeepSearch基于LLM的语义理解能力,能识别“程序员冬季通勤穿搭”背后的真实需求——舒适、保暖、适合办公室场景,并结合上下文动态调整搜索策略。
从“找链接”到“给答案”:
| 目标 | 传统搜索 | DeepSearch |
|---|---|---|
| 核心目的 | 快速返回相关网页 | 直接生成高质量、可信赖的答案 |
| 服务对象 | 信息浏览者 | 决策支持者、研究人员、专业人士 |
| 典型场景 | 查天气、找官网、看新闻 | 医疗方案评估、投资风险分析、科研综述撰写 |
📌 目的差异:
传统搜索服务于“我知道我要查什么”,例如“百度官网”;而DeepSearch服务于“我还不完全清楚问题该怎么问”,例如“孩子发烧三天不退,最近有流感爆发吗?”——它会主动推理:先确认症状是否符合流感特征,再查询本地疫情数据,最后给出就医建议。
接下来,我们使用 openJiuwen-DeepSearch(一款知识增强高性能、高精准深度检索与研究引擎),有效利用结构化知识及大模型,提供企业级Agentic AI 搜索及研究能力,解决复杂推理问题及研究任务,来看看DeepSearch如何解决复杂推理问题及研究任务。
二、openJiuwen-DeepSearch 安装与部署:
在系统前期需要安装好docker,有关docker的安装教程可以参考官方文档:https://docs.docker.com/engine/install/
以下是在Ubuntu 22.04 Server LTS版本安装 openJiuwen agent-studio v0.1.5 版本为例,可以按需替换成需要安装的版本,部署 DeepSearch SDK 服务和前端界面服务,可通过浏览器界面便捷地使用 DeepSearch Agent,适合希望通过UI界面体验 DeepSearch 的用户。
$ wget https://openjiuwen-ci.obs.cn-north-4.myhuaweicloud.com/agentstudio/deployTool_0.1.5_amd64.zip
$ unzip deployTool_0.1.5_amd64.zip
$ ./server.sh up
但是这里发生一个报错,提示"netstat is not installed. Please install it first"。
=== Executing command: up ===
=== ARGS_MODULES: ===
=== Operating System: linux ===
=== Checking Docker... ===
=== Version: 29.3.0 → 290300, 20.10 → 201000 ===
✅ Docker: 29.3.0 (≥ 20.10)
=== Checking Docker Compose installation... ===
=== Version: 5.1.0 → 50100, 2.19.1 → 21901 ===
✅ Docker Compose: 5.1.0 (≥ v2.19.1)
✅ sed is OK.
✅ awk is OK.
✅ grep is OK.
✅ sort is OK.
✅ head is OK.
✅ wc is OK.
✅ tr is OK.
✅ cut is OK.
✅ od is OK.
✅ chmod is OK.
✅ mkdir is OK.
✅ cp is OK.
✅ rm is OK.
✅ mv is OK.
✅ cat is OK.
✅ echo is OK.
✅ printf is OK.
✅ seq is OK.
❌ netstat is not installed. Please install it first.
接下来我们使用一条命令来进行手动安装netstat:
sudo apt-get install net-tools
如果在安装的过程中遇到报错,可以重新来尝试一下命令的安装(可能是网络的问题导致安装失败):
=== Using template file: /home/root/openjiuwen/deployTool_0.1.5_amd64/conf/docker-jiuwen.template.yml ===
=== cp -f /home/root/openjiuwen/deployTool_0.1.5_amd64/conf/docker-jiuwen.template.yml /home/root/openjiuwen/deployTool_0.1.5_amd64/conf/docker-jiuwen.yml ===
=== Starting placeholder replacement... ===
✅ Generated config file: /home/root/openjiuwen/deployTool_0.1.5_amd64/conf/docker-jiuwen.yml
=== Skip processing UPGRADE/UPGRADE_TOOL: disabled in deployment config ===
=== [PROCESSING SERVICE] Module: MYSQL, Component: MYSQL, Cmd: up ===
=== docker compose -f /home/root/openjiuwen/deployTool_0.1.5_amd64/conf/docker-mysql.yml up -d mysql-p95at ===
[+] up 7/11
⠏ Image swr.cn-north-4.myhuaweicloud.com/openjiuwen/mysql-amd64:8.4.5 [⣿⣿⣿⣄⣿⣿⣿⣿⡀⣦] 85.98MB / 235.1MB Pulling 80.0s
^C❌ docker compose -f /home/root/openjiuwen/deployTool_0.1.5_amd64/conf/docker-mysql.yml up -d mysql-p95at failed
root@administartor:/home/root/openjiuwen/deployTool_0.1.5_amd64# ./service.sh up
=== Executing command: up ===
通过几分钟的等待,可以看到所有的服务都已经启动成功了,这里跟网速有关系,请耐心等待,因为他是边在下载镜像,有的镜像都超过1G了,下载镜像后启动容器,以下表示已经启动好了,可以看到提示映射的端口为3000:“Local access: https://localhost:3000”。
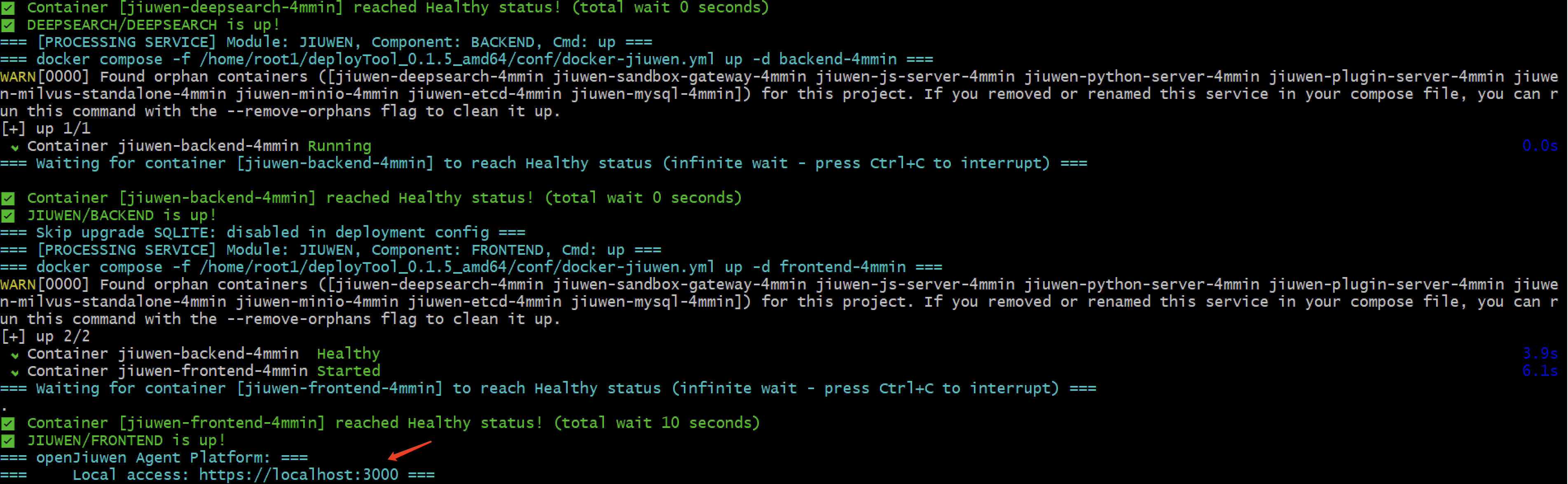
接下来我们可以来查看一下启动的容器,新的版本还加入了etcd服务,可以看到一共有11个容器正在运行,其中包括前端、后端、插件服务、沙箱服务等。
root@cx:/home/root1/deployTool_0.1.5_amd64# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
bdfc9be68169 swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-web-amd64:0.1.5 "/usr/local/bin/star…" 2 hours ago Up 2 hours (healthy) 80/tcp, 0.0.0.0:3000->3001/tcp, [::]:3000->3001/tcp jiuwen-frontend-4mmin
c96d7656248a swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-server-amd64:0.1.5 "/entrypoint.sh pyth…" 9 hours ago Up 9 hours (healthy) 0.0.0.0:3007->8000/tcp, [::]:3007->8000/tcp jiuwen-backend-4mmin
2693e4ffd00f swr.cn-north-4.myhuaweicloud.com/openjiuwen/deepsearch-studio-server-amd64:0.1.0 "python start_backen…" 9 hours ago Up 9 hours (healthy) 0.0.0.0:3012->8000/tcp, [::]:3012->8000/tcp jiuwen-deepsearch-4mmin
a859ce82d6b4 swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-sandbox-gateway-amd64:0.1.5 "python -m openjiuwe…" 9 hours ago Up 9 hours (healthy) 0.0.0.0:3009->8188/tcp, [::]:3009->8188/tcp jiuwen-sandbox-gateway-4mmin
a3f3d4ff6ec3 swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-sandbox-js-amd64:0.1.5 "docker-entrypoint.s…" 9 hours ago Up 9 hours (healthy) 0.0.0.0:3011->5002/tcp, [::]:3011->5002/tcp jiuwen-js-server-4mmin
3679c9447860 swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-sandbox-py-amd64:0.1.5 "python -m openjiuwe…" 9 hours ago Up 9 hours (healthy) 0.0.0.0:3010->5001/tcp, [::]:3010->5001/tcp jiuwen-python-server-4mmin
f5b2c11b0fd3 swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-plugin-server-amd64:0.1.5 "python -m openjiuwe…" 9 hours ago Up 9 hours (healthy) 0.0.0.0:3008->8185/tcp, [::]:3008->8185/tcp jiuwen-plugin-server-4mmin
a2b7702b4992 swr.cn-north-4.myhuaweicloud.com/openjiuwen/milvusdb/milvus-amd64:v2.6.2 "/tini -- milvus run…" 10 hours ago Up 10 hours (healthy) 0.0.0.0:3006->9091/tcp, [::]:3006->9091/tcp, 0.0.0.0:3005->19530/tcp, [::]:3005->19530/tcp jiuwen-milvus-standalone-4mmin
532dd6fec528 swr.cn-north-4.myhuaweicloud.com/openjiuwen/minio/minio-amd64:RELEASE.2024-12-18T13-15-44Z "/usr/bin/docker-ent…" 10 hours ago Up 10 hours (healthy) 0.0.0.0:3003->9000/tcp, [::]:3003->9000/tcp, 0.0.0.0:3004->9001/tcp, [::]:3004->9001/tcp jiuwen-minio-4mmin
0fc5d0a08b25 swr.cn-north-4.myhuaweicloud.com/openjiuwen/bitnami/etcd-amd64:v3.5.18 "/opt/bitnami/script…" 10 hours ago Up 10 hours (healthy) 2379-2380/tcp jiuwen-etcd-4mmin
2ce23e01d491 swr.cn-north-4.myhuaweicloud.com/openjiuwen/mysql-amd64:8.4.5 "docker-entrypoint.s…" 10 hours ago Up 10 hours (healthy) 33060/tcp, 0.0.0.0:3001->3306/tcp, [::]:3001->3306/tcp jiuwen-mysql-4mmin
另外,再查询一下所有的镜像,可以看到最大的镜像都超过3个GB了,所以,在下载安装的过程中,需要有足够的磁盘空间(本人已踩过坑),不然会报错。
root@cx:/home/root1/deployTool_0.1.5_amd64# docker images
i Info → U In Use
IMAGE ID DISK USAGE CONTENT SIZE EXTRA
swr.cn-north-4.myhuaweicloud.com/openjiuwen/bitnami/etcd-amd64:v3.5.18 2e6a8c7bd0ad 273MB 66.5MB U
swr.cn-north-4.myhuaweicloud.com/openjiuwen/deepsearch-studio-server-amd64:0.1.0 cfca35be8b83 1.92GB 472MB U
swr.cn-north-4.myhuaweicloud.com/openjiuwen/milvusdb/milvus-amd64:v2.6.2 87a273625e7b 3.35GB 894MB U
swr.cn-north-4.myhuaweicloud.com/openjiuwen/minio/minio-amd64:RELEASE.2024-12-18T13-15-44Z 18904f631037 244MB 62.4MB U
swr.cn-north-4.myhuaweicloud.com/openjiuwen/mysql-amd64:8.4.5 d6ad54391acd 1.06GB 236MB U
swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-plugin-server-amd64:0.1.5 811618aa3e8c 1.03GB 261MB U
swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-sandbox-gateway-amd64:0.1.5 6b2801ac8bc6 1.03GB 268MB U
swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-sandbox-js-amd64:0.1.5 03e78a9fb9fb 307MB 76.7MB U
swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-sandbox-py-amd64:0.1.5 ca838b8fcfc7 896MB 234MB U
swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-server-amd64:0.1.5 e9e71c6d0982 2.09GB 495MB U
swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-web-amd64:0.1.5 4e62f16ff1db 171MB 55.1MB U
三、openJiuwen-DeepSearch 相关配置:
通过浏览器访问 http://xxxx:3000端口,即可访问openJiuwen的WebUI,输入邮箱即可成功进行登录,在最上面就是任务空间,即可开始使用DeepSearch进行任务处理。
1. 模型配置:
华为MaaS模型即服务(后续简称为MaaS),提供端到端的大模型生产工具链和昇腾算力资源,并预置了当前主流的第三方开源大模型,支持大模型数据生产、微调、提示词工程、应用编排等功能。通过访问:https://console.huaweicloud.com/modelarts/?region=cn-southwest-2#/model-studio/homepage,MaaS集成了业界主流开源大模型,含Llama、Baichuan、Yi、Qwen、DeepSeek等模型系列,所有的模型均基于昇腾AI云服务进行全面适配和优化,使得精度和性能显著提升。
注意在使用openJiuwen-DeepSearch时,建议使用128k的模型,这样在体验的过程中,会更加流畅。
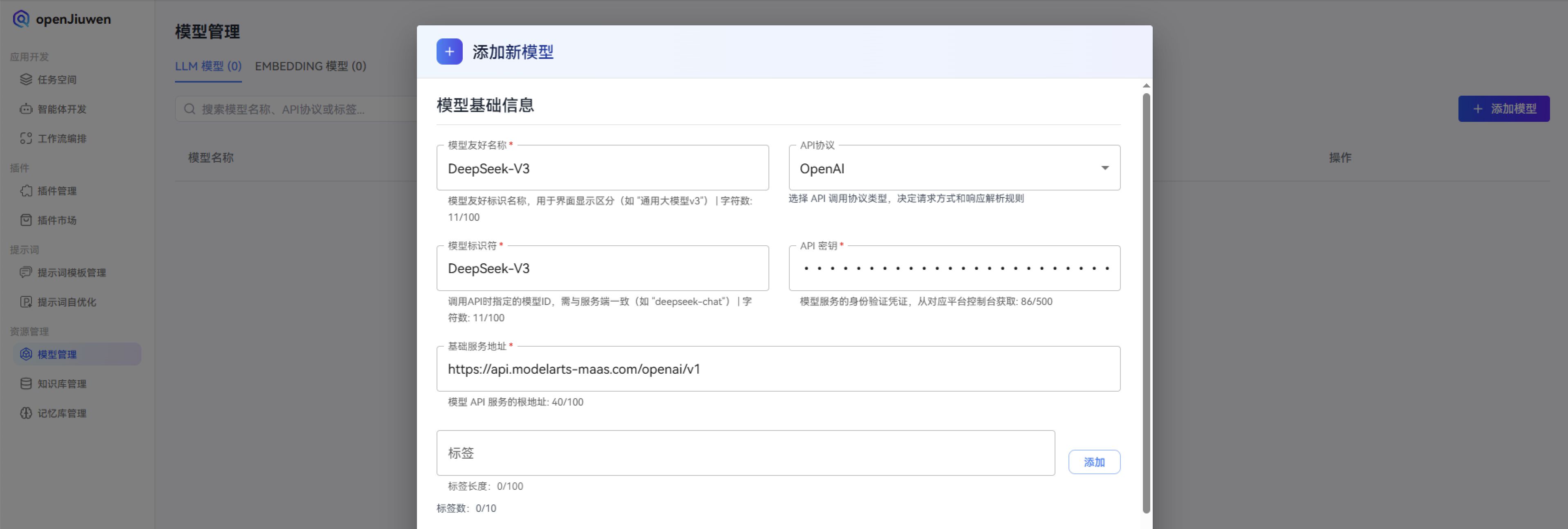
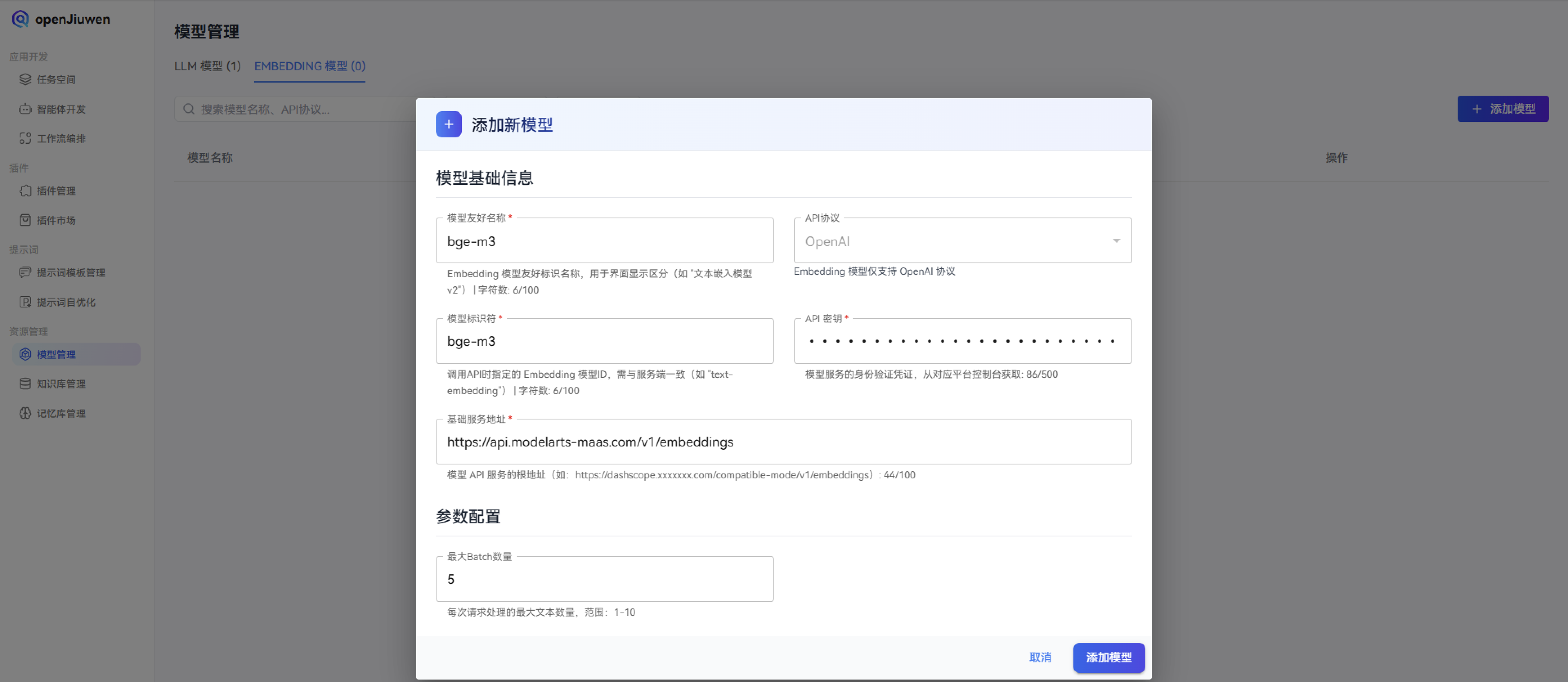
上面是2种模型的设置方案,LLM是“内容生产者”,Embedding是“内容组织者”——就像餐厅里的厨师和配菜员:
- 厨师(LLM):负责把食材做成美味的菜品(把信息变成自然文本)。
- 配菜员(Embedding):负责把食材整理、分类、备好(把文本变成可检索的向量)。
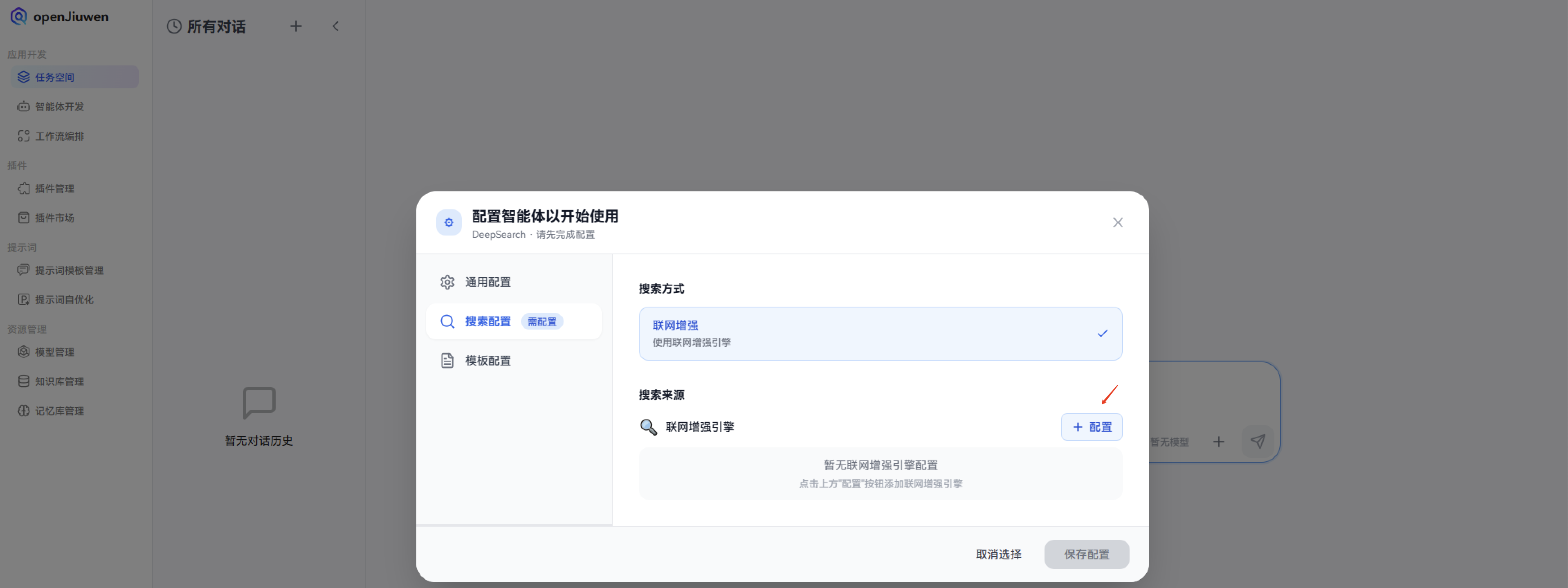
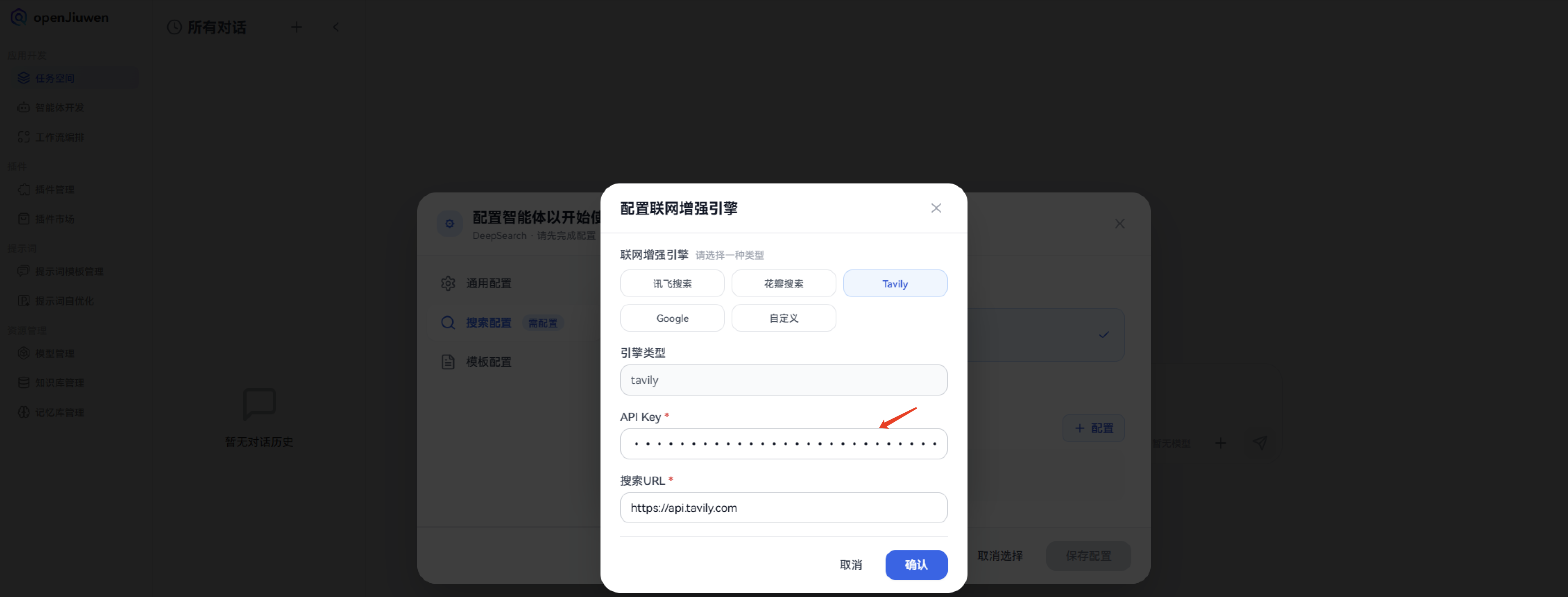
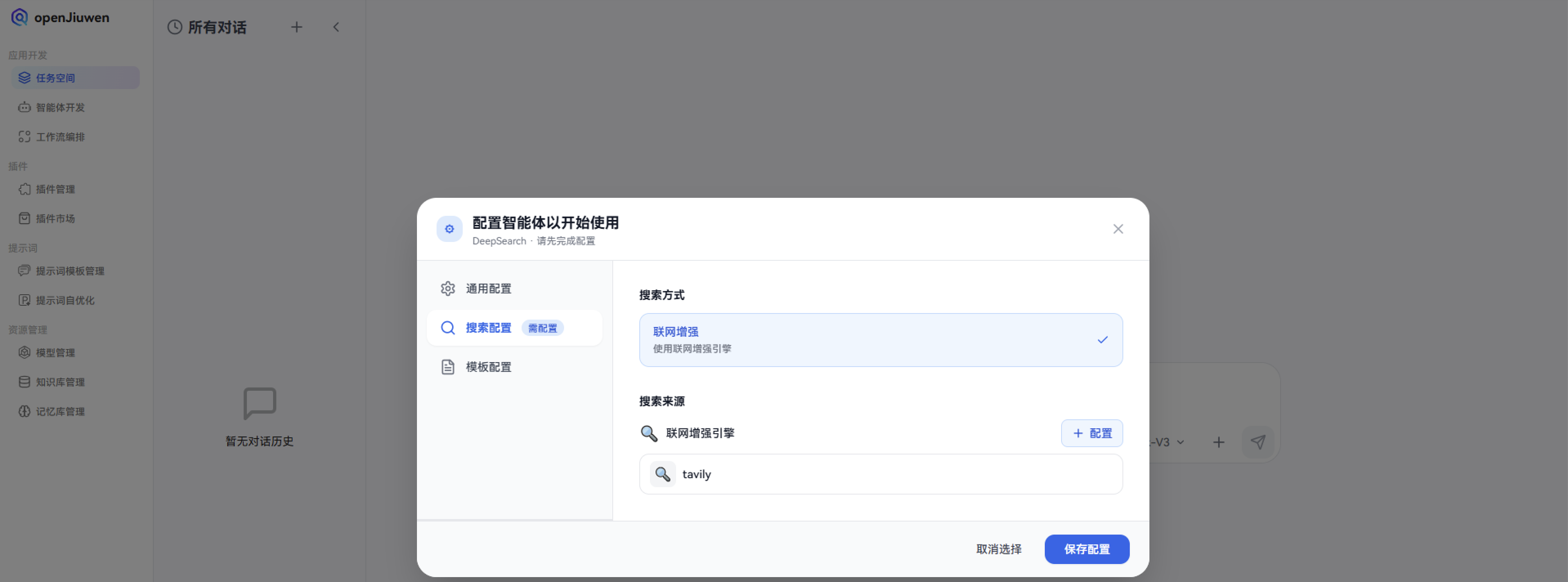
2. 配置联网增强引擎 - Tavily:
Tavily是一款专为AI应用设计的搜索引擎,它能够提供实时、准确的搜索结果,智能化的查询建议以及深入的研究能力。简单来说,它就像一个为AI打造的“超级大脑”,帮助AI快速获取信息并做出更明智的决策。它通过连接大型语言模型(LLMs)和AI应用程序到可靠的实时知识库,从而减少AI在信息获取过程中可能出现的幻觉和偏差。
Tavily主要以API的形式提供服务。开发者可以通过集成Tavily的API,将Tavily的搜索功能嵌入到自己的AI应用中。具体的使用方法需要参考Tavily官方提供的API文档。通过调用API,AI应用可以向Tavily发送查询请求,并接收包含实时、准确信息的响应。Tavily的智能查询建议功能可以帮助AI改进查询策略,从而获取更精确的结果。
用途:实时查最新论文、新闻、产品价格、航班信息等。
可以直接在官网上面直接进行注册即可,注册成功后,就可以在openJiuwen-DeepSearch中进行配置。
四、openJiuwen-DeepSearch 产品经理需求拆解分析工作实践:
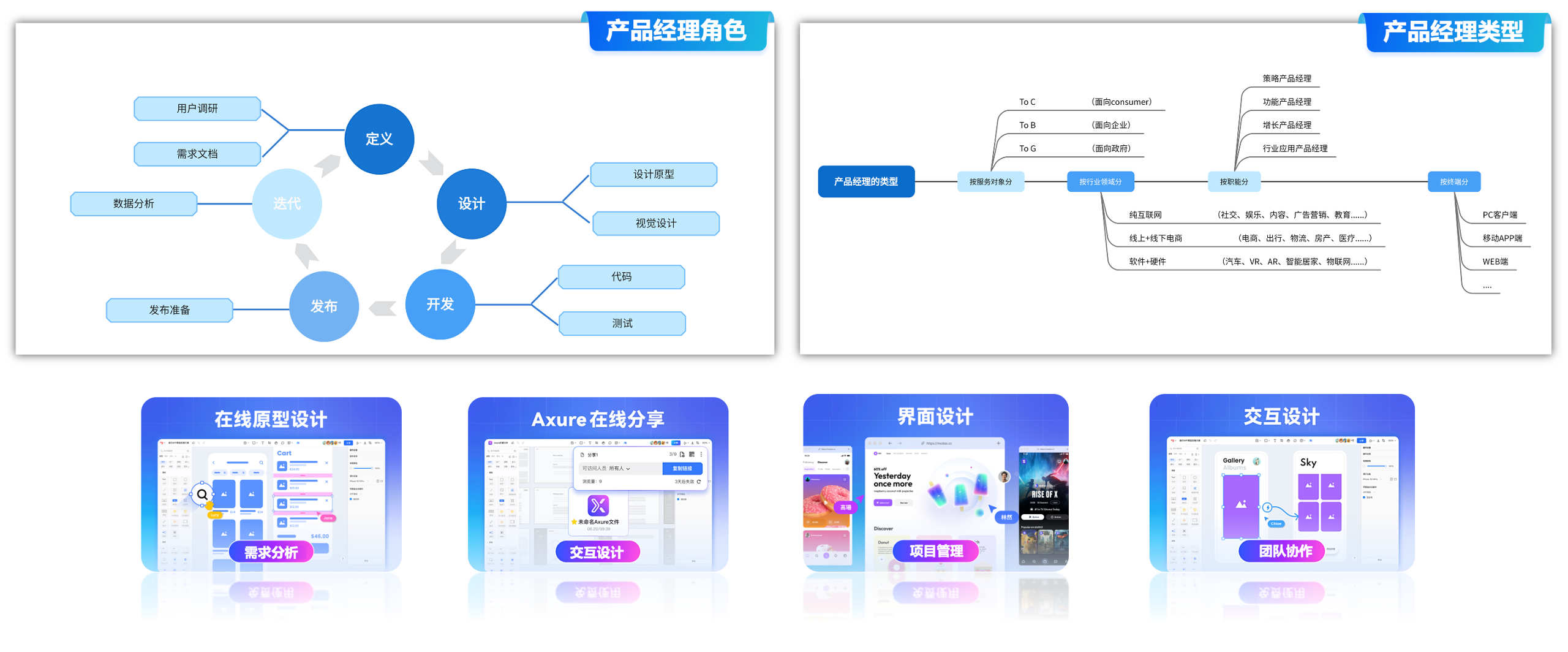
本人目前刚入职一家公司产品经理岗位,由于上家公司比较中规,平时就是开开会、泡泡茶、给领导汇报一下进度,1天就这么过去了,最近换了一家创业型公司,虽然而待遇提高了,但是工作量也急剧增加,“忙成狗”,大概就是来形容我的吧。
这不,上一个项目还没结束over,领导马上安排一个刚接到的甲方“供应链系统”的需求对接,业务系统也比较大,包括小程序、公众号H5页面、后台管理系统等以供应链系统为例,梳理业务需求、项目排期、技术文档等,每天都要面对多项并行任务的繁杂的项目管理工作,而且平时也是涉及多个部门的协作,包括产品部、技术部、UI设计部、各个业务部门等,同时涉及到大量的沟通、需求转化、需求整理的工作。
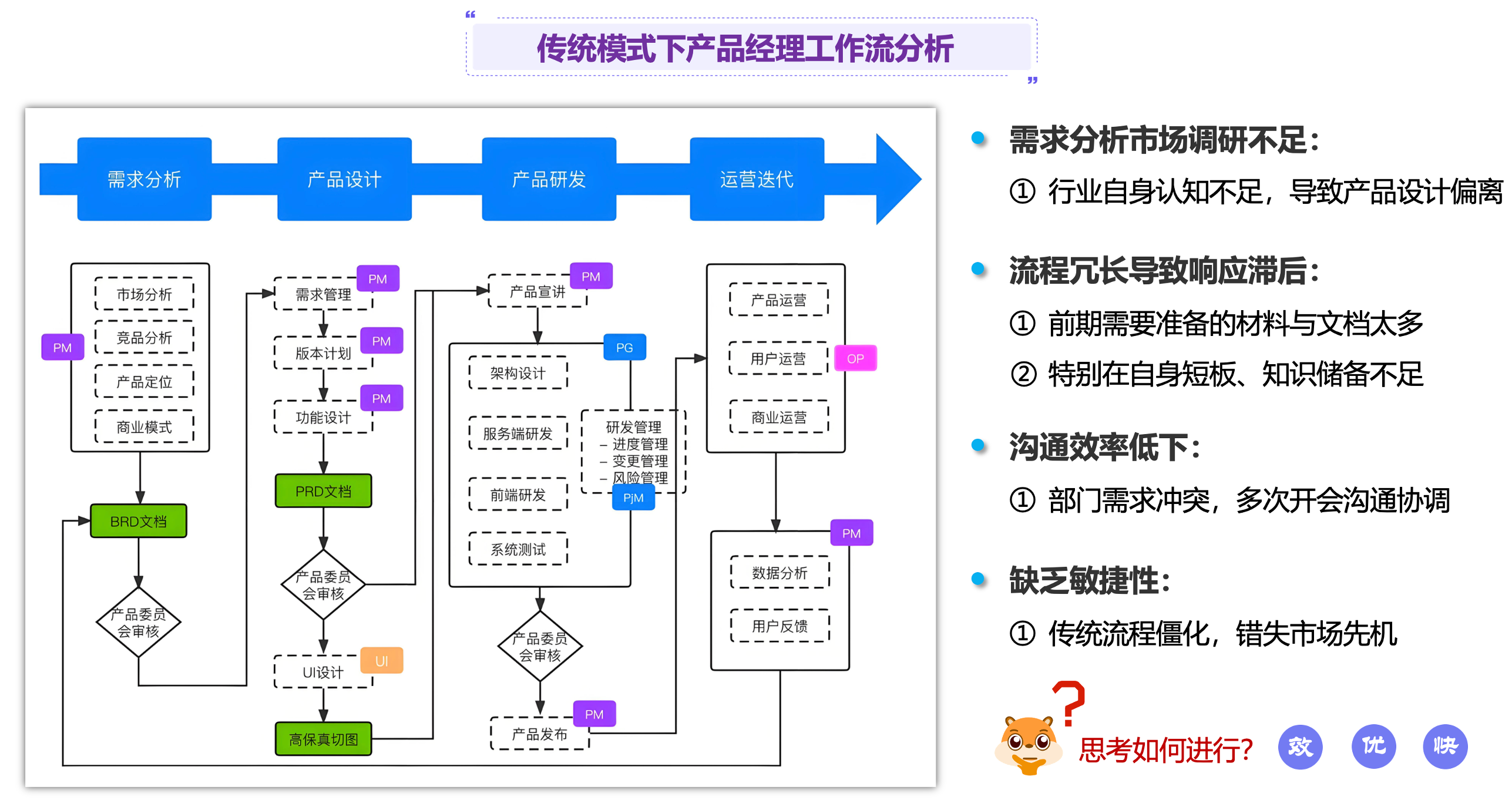
按照传统的工作模式,与甲方进行各种沟通开会,梳理基本的业务需求,写PRD文档,然后进行项目排期,最后是技术文档的编写,此时,需要浪费大量的人力、物力来完成,而且效率低下。而且,如果在项目开发过程中,需求变更,那么又要重新梳理业务需求、写PRD文档、排期等,这样会浪费更多的时间。
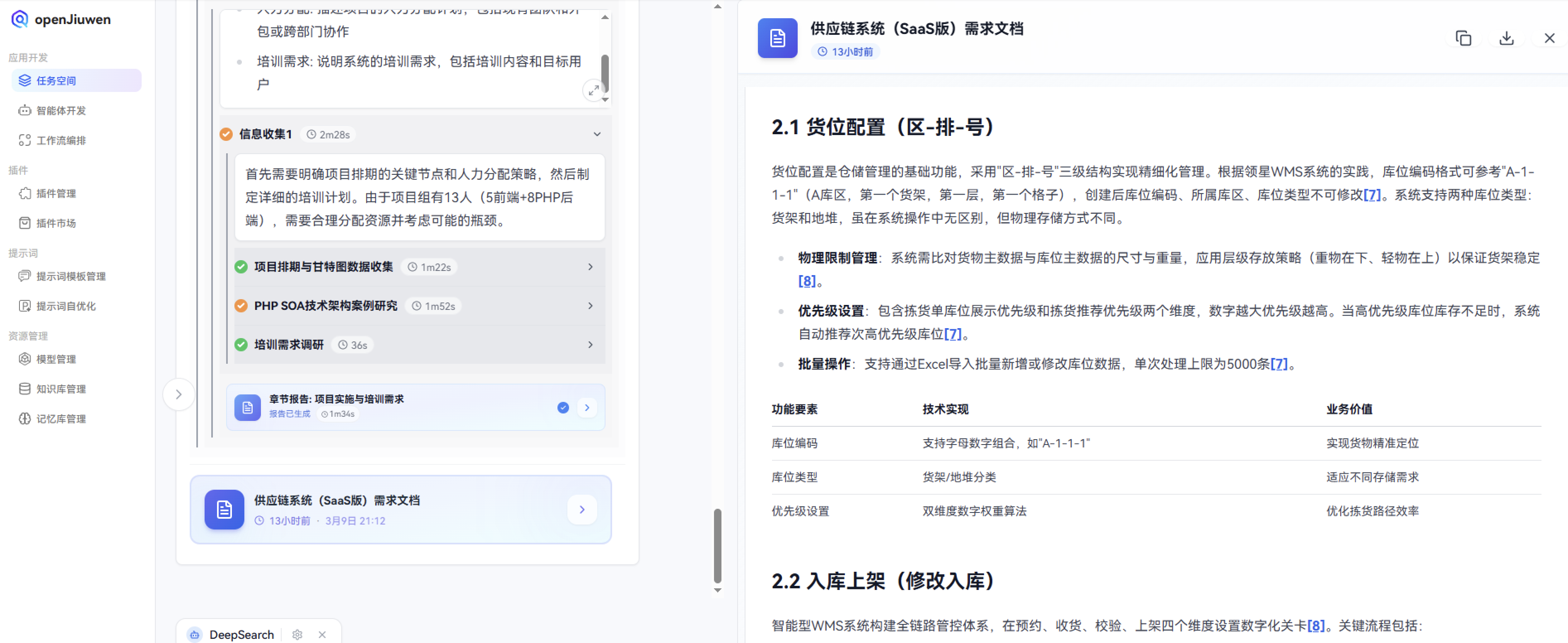
引入"openJiuwen-DeepSearch"任务规划功能——通过自然语言对话,短时间内就能生成比较好的产品方案,涵盖产品原型、技术文档、项目大概的一个排期、项目实施计划甘特图。相对于主流AI工具(如ChatGPT、Deepseek),"openJiuwen-DeepSearch"的交互式深度拆解和多模态输出能力将任务进行拆解,每个块都细化到具体的技术实现。
背景身份设定并叙述任务分解需求:
本人自己也接触过不少的AI产品:比如百度AI、kimi、豆包、Deepseek、IDE云代码助手工具,多次尝试输入了我想要查询的内容,结果只是机械式的回复步骤(网上照搬),根本不是我想要的答案,而且也没有像“openJiuwen-DeepSearch”会进行任务拆解,真是眼前一亮,用过之后爱不释手,值得推荐大家一起来使用。
接下来,让我来给大家介绍一下“openJiuwen-DeepSearch”是如何在任务拆解上化繁为简、从混乱到清晰、从无序到有序,像数据公式一样复杂难题,一步一步拆解迎刃而解。
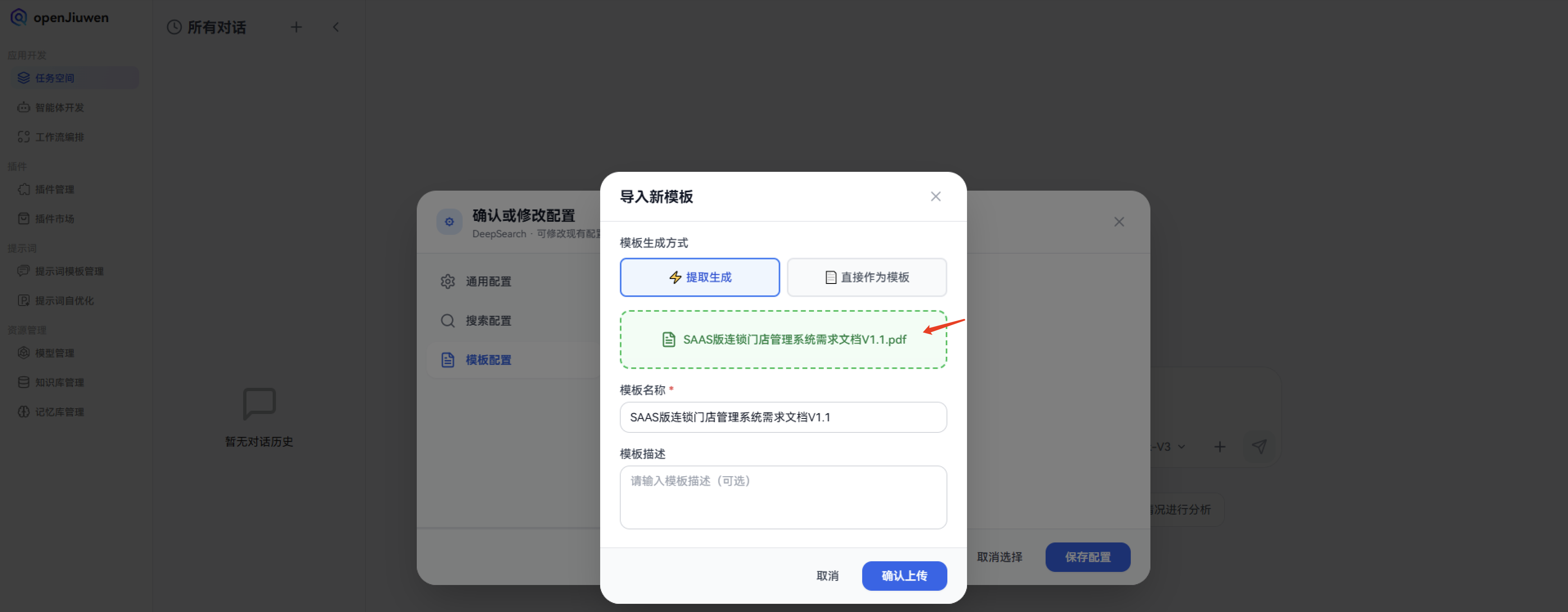
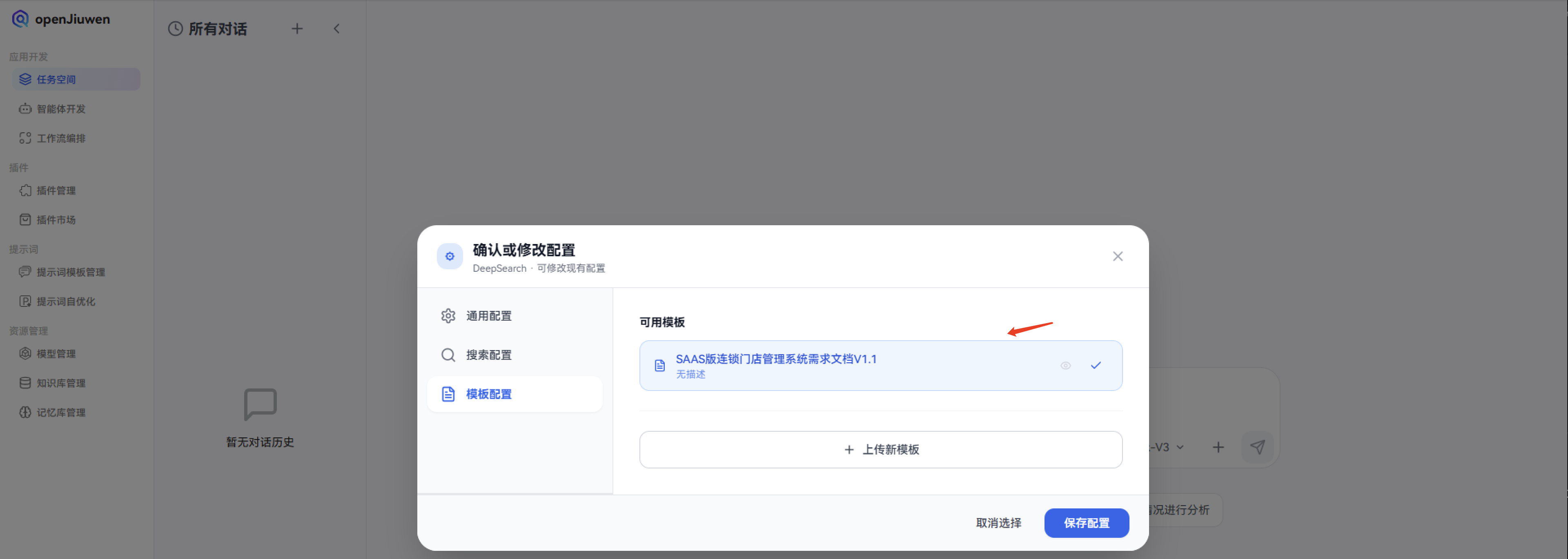
1. 配置相关资料模板:
接下来,我们通过openJiuwen-DeepSearch来进行任务拆解,首先需要配置相关资料模板:
2. openJiuwen-DeepSearch任务规划:
我们通过给出具体的任务,openJiuwen-DeepSearch会自动进行任务拆解,并给出详细的解决方案,这里我们可以设定自己的人设和任务,比如:
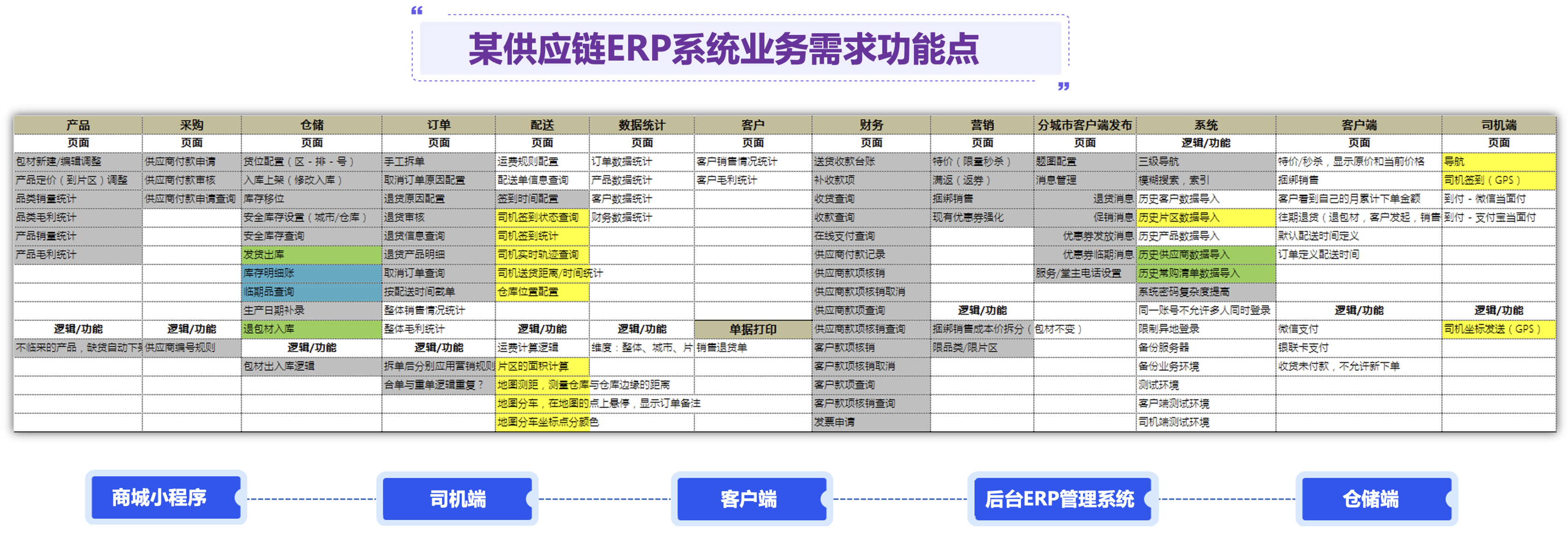
我的角色是一个产品经理,要求根据货位配置(区-排-号)、入库上架(修改入库)、库存移位、安全库存设置(城市/仓库)、安全库存查询、发货出库、库存明细账、临期品查询、生产日期补录、退包材入库、包材出入库逻辑功能模板,帮我设计一个比较全面的供应链系统:
1. 需要包括小程序、司机端、客服端、仓储端、后台管理系统,请帮我梳理一下业务需求流程,并给出比较详细的PRD
2. 目前项目组HC人力是13个人,其中包含5个前端,8个PHP后端,需要给出具体多久的项目的排期,需要甘特图显示
3. 需要给出PHP SOA的技术架构相关文档
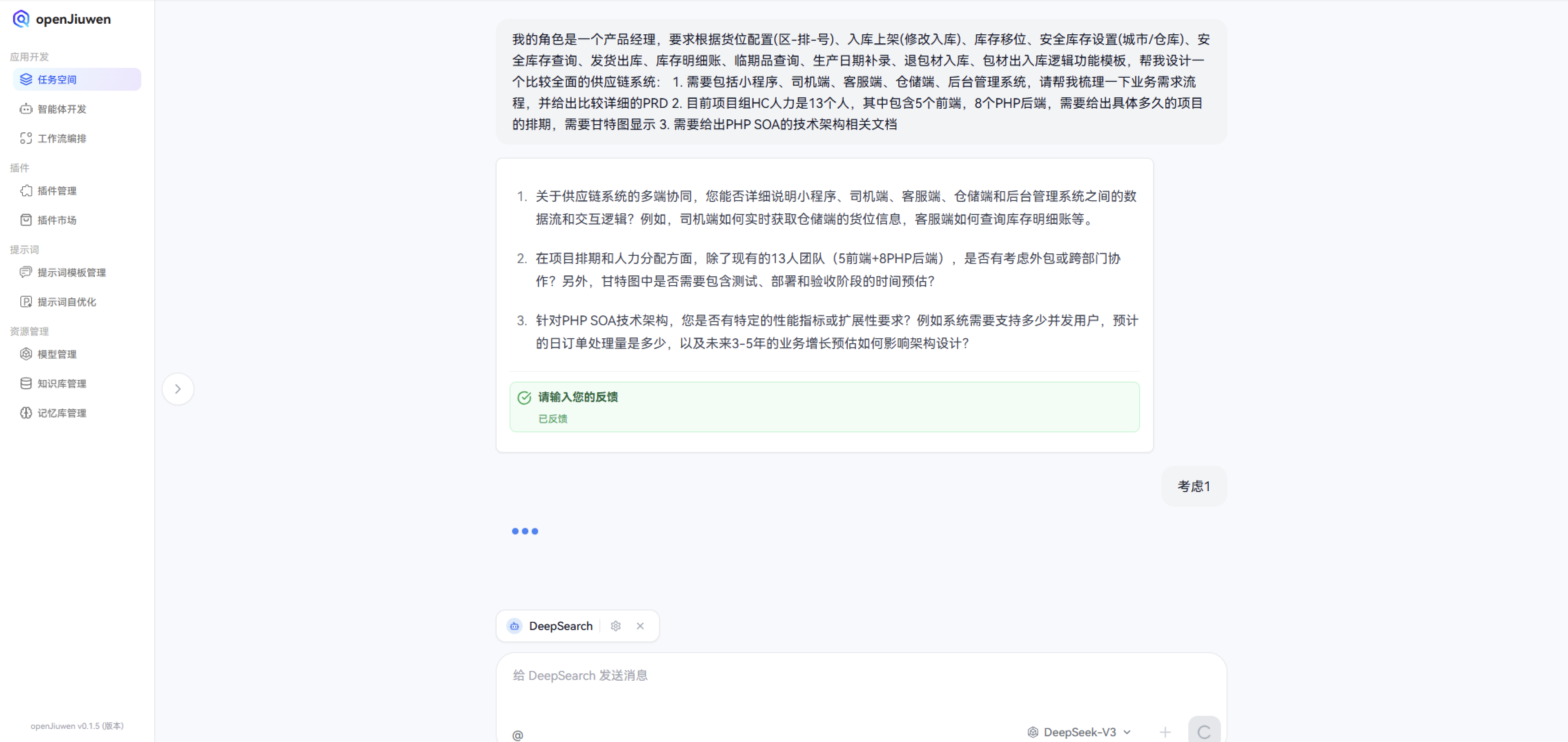
在第一步我们只是给出了一个大概的任务描述,因为提出的任务需求描述比较简单,所以“openJiuwen-DeepSearch”在经过深度思考和剖析后,发现有一些细节没有考虑到的场景,反向思考询问我需要进行补充说明,而且有些还是我没有考虑的一些业务需求,非常适合思维发散。
关于供应链系统的多端协同,您能否详细说明小程序、司机端、客服端、仓储端和后台管理系统之间的数据流和交互逻辑?例如,司机端如何实时获取仓储端的货位信息,客服端如何查询库存明细账等。
在项目排期和人力分配方面,除了现有的13人团队(5前端+8PHP后端),是否有考虑外包或跨部门协作?另外,甘特图中是否需要包含测试、部署和验收阶段的时间预估?
针对PHP SOA技术架构,您是否有特定的性能指标或扩展性要求?例如系统需要支持多少并发用户,预计的日订单处理量是多少,以及未来3-5年的业务增长预估如何影响架构设计?
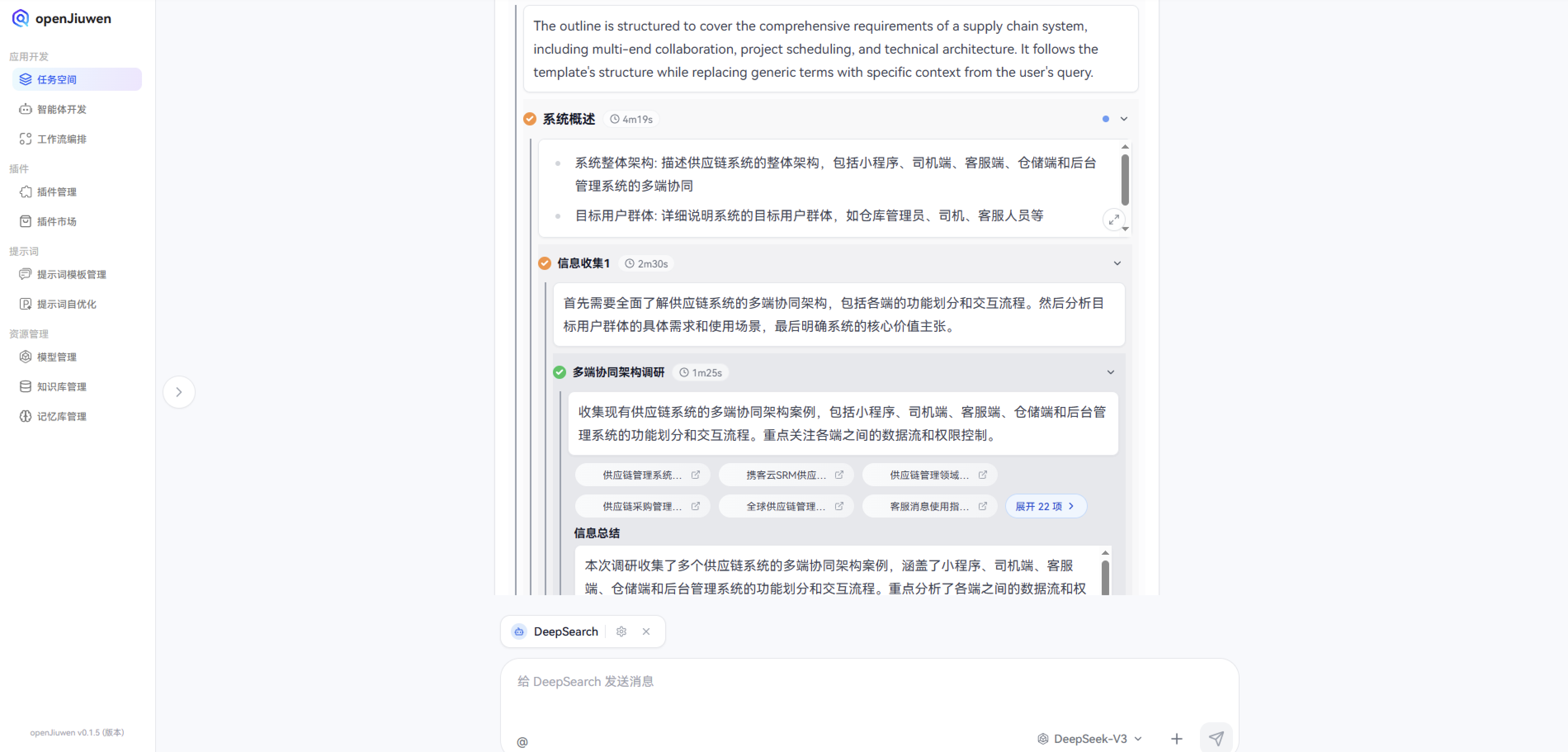
- 系统整体架构: 描述供应链系统的整体架构,包括小程序、司机端、客服端、仓储端和后台管理系统的多端协同
- 目标用户群体: 详细说明系统的目标用户群体,如仓库管理员、司机、客服人员等
- 核心价值主张: 阐述系统的核心价值主张,如提高库存管理效率、优化物流配送流程等
可以看到,会去网上去收集现有供应链系统的多端协同架构案例(可以看到搜索了很多在线的文档和web页面),包括小程序、司机端、客服端、仓储端和后台管理系统的功能划分和交互流程,根据收集到的案例,本次调研收集了多个供应链系统的多端协同架构案例,涵盖了小程序、司机端、客服端、仓储端和后台管理系统的功能划分和交互流程。重点分析了各端之间的数据流和权限控制。
例如:从携客云供应链协同平台、滴滴出行小程序、美团出行司机端、GoWarehouse智能仓储系统等多个案例中,可以看到多端协同架构在供应链系统中的广泛应用:
- 这些系统通常采用分布式架构设计,支持多端数据实时同步,并通过RBAC权限模型实现精细化的权限控制。
- 数据流方面,各端通过API或消息队列实现数据交互,确保业务流程的连贯性。
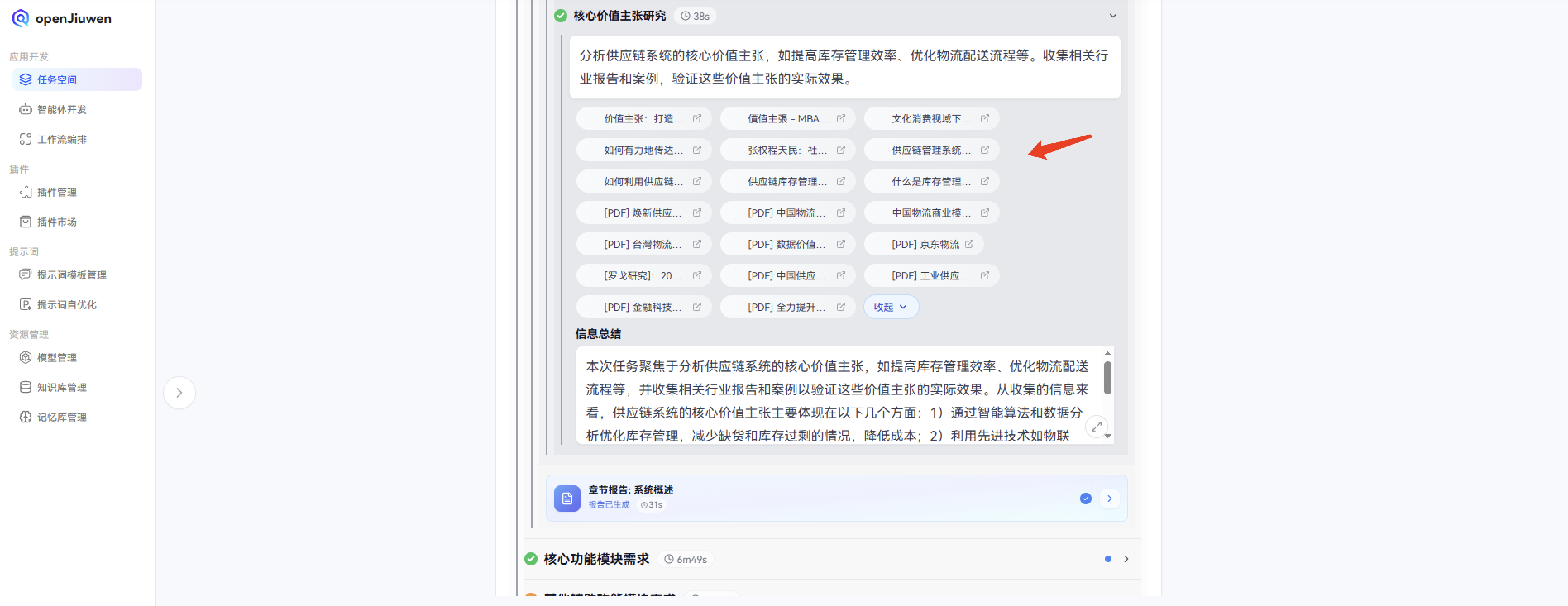
最后根据上面的作务拆解步骤,通过搜索不同步骤给出的解决方案,汇总到一起形成一个完整的解决方案,并给出一个详细的文档:
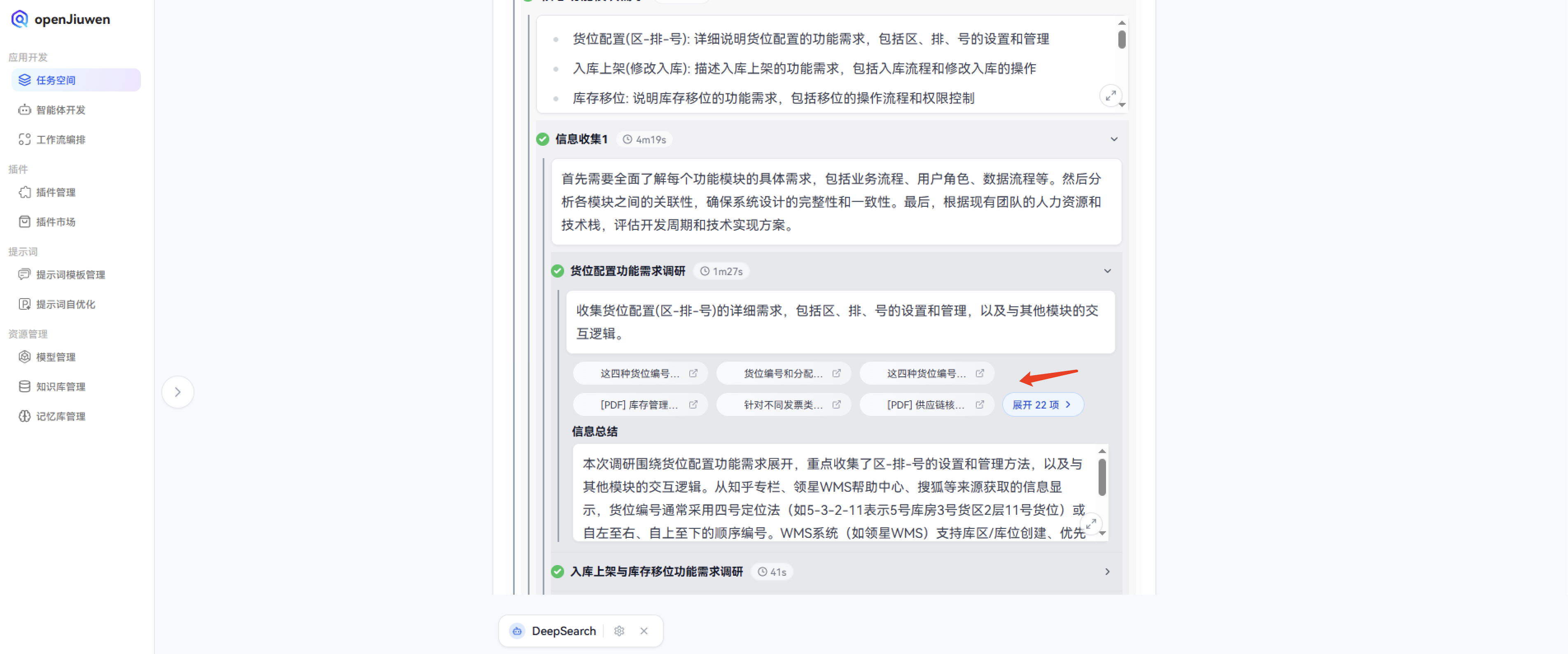
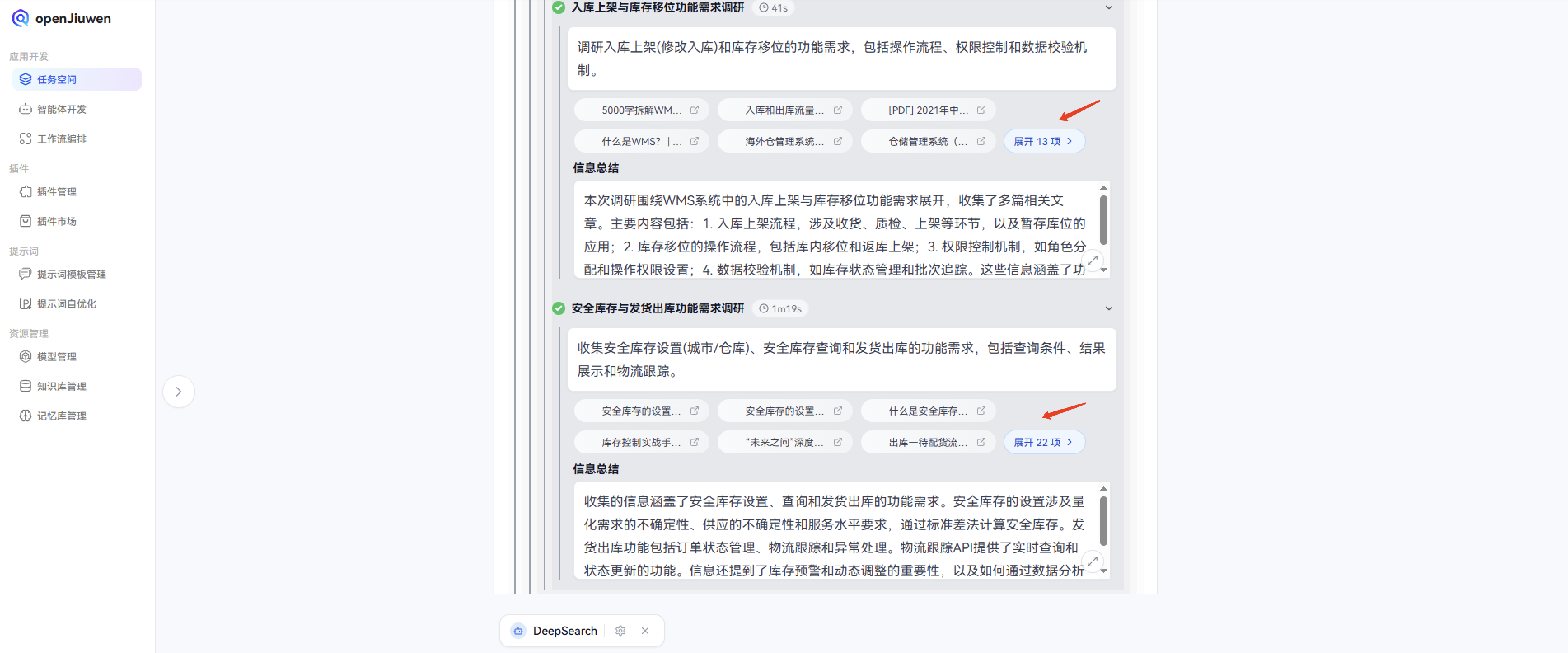
核心功能模块需求:
- 货位配置(区-排-号): 详细说明货位配置的功能需求,包括区、排、号的设置和管理
- 入库上架(修改入库): 描述入库上架的功能需求,包括入库流程和修改入库的操作
- 库存移位: 说明库存移位的功能需求,包括移位的操作流程和权限控制
- 安全库存设置(城市/仓库): 详细说明安全库存设置的功能需求,包括按城市或仓库设置安全库存
- 安全库存查询: 描述安全库存查询的功能需求,包括查询条件和结果展示
- 发货出库: 说明发货出库的功能需求,包括出库流程和物流跟踪
- 库存明细账: 详细说明库存明细账的功能需求,包括账目查询和导出
- 临期品查询: 描述临期品查询的功能需求,包括查询条件和预警机制
- 生产日期补录: 说明生产日期补录的功能需求,包括补录流程和数据校验
- 退包材入库: 详细说明退包材入库的功能需求,包括入库流程和包材管理
- 包材出入库逻辑: 描述包材出入库逻辑的功能需求,包括出入库流程和库存管理
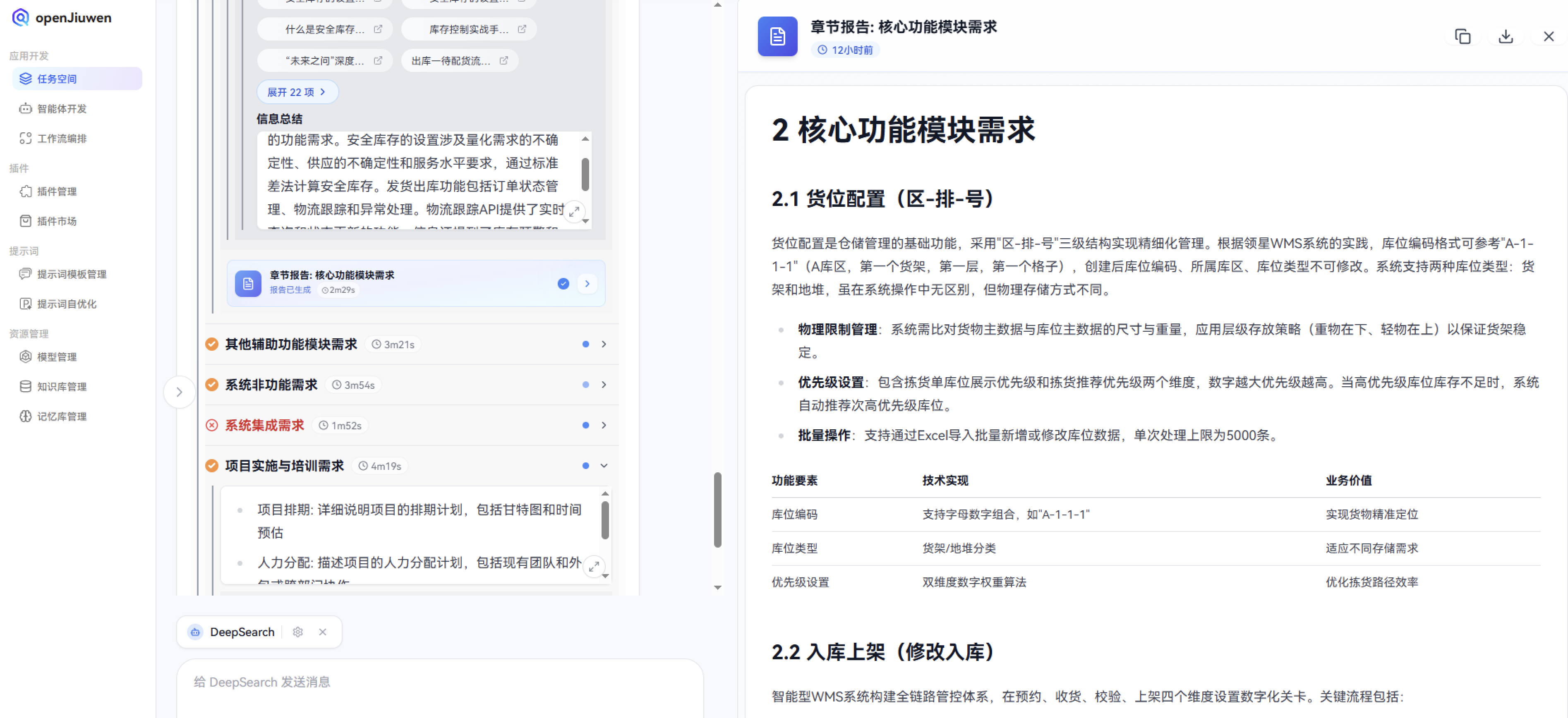
根据收集的信息,供应链系统各端的业务需求流程包括货位配置、入库上架、库存移位、安全库存设置、发货出库等功能模块的具体流程。货位配置方面,仓库需要根据货物特性和动线分析进行分区和标号,以提高仓储效率。入库上架流程涉及采购订单的创建、审核、收货录入、验收和商品上架等步骤。库存移位则包括库存移动、调整和冻结等操作。安全库存设置需要考虑需求预测、ABC分类法和经济订货批量(EOQ)模型。发货出库流程则包括订单拆分、拣货、复核打包和物流运输等环节。
收集的信息涵盖了项目排期、任务分解方法和甘特图制作工具。其中,Ganttable和WBS方法被推荐用于任务分解和优先级设置,PERT时间估算模型用于任务耗时计算。甘特图制作工具包括Excel、Ganttable、boardmix等,支持任务依赖关系可视化和资源分配优化。此外,还提到了动态调整机制和里程碑标记功能,以应对项目进度偏差和关键节点管理。
最终方案:
最后会把上面几个任务的步骤分析的结果再聚合成一个解决方案,并给出一个详细的文档,接下来我们来分析一下要点:
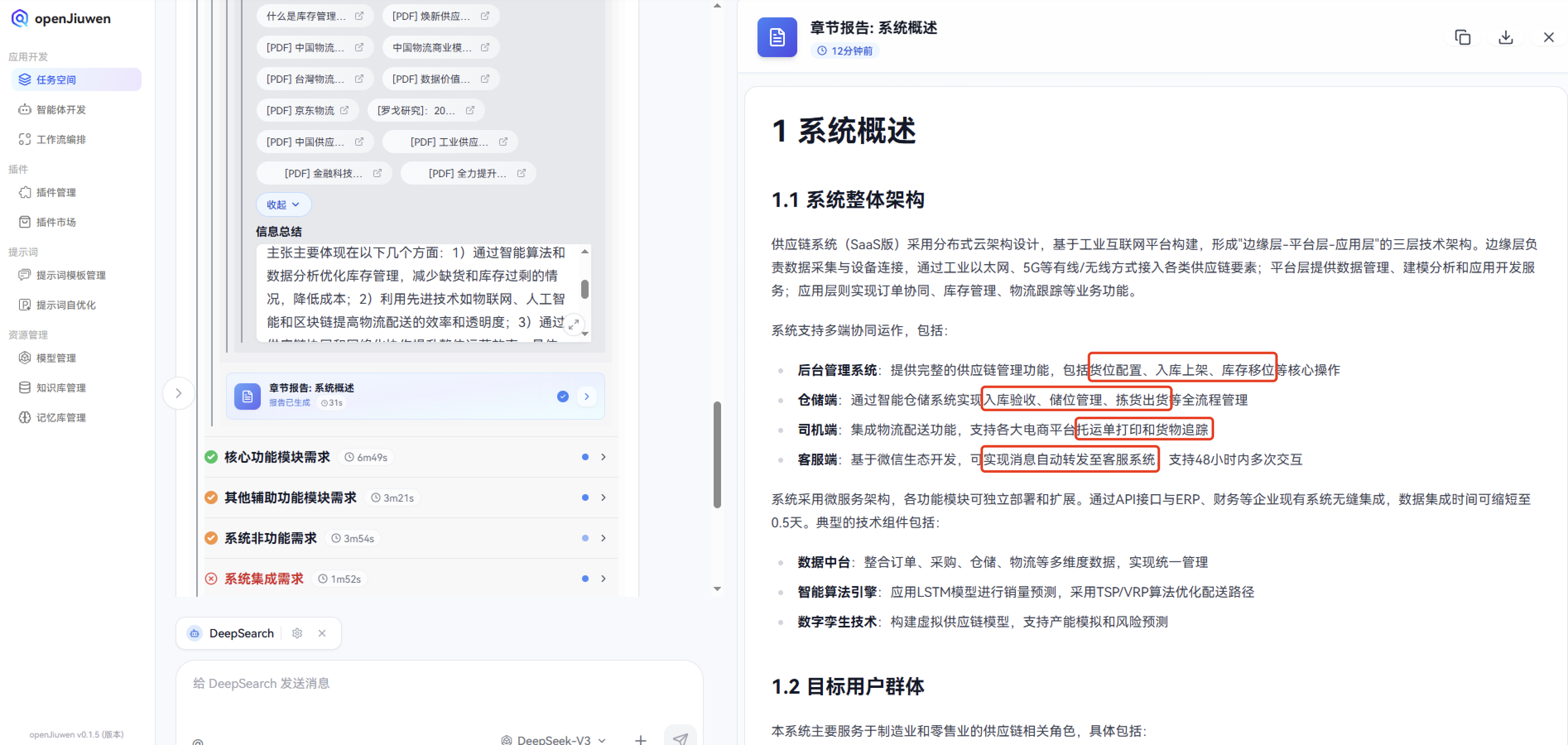
供应链系统(SaaS版)采用分布式云架构设计,基于工业互联网平台构建,形成"边缘层-平台层-应用层"的三层技术架构。平台层提供数据管理、建模分析和应用开发服务;应用层则实现订单协同、库存管理、物流跟踪等业务功能。系统支持多端协同运作,包括:
- 后台管理系统:提供完整的供应链管理功能,包括货位配置、入库上架、库存移位等核心操作
- 仓储端:通过智能仓储系统实现入库验收、储位管理、拣货出货等全流程管理
- 司机端:集成物流配送功能,支持各大电商平台托运单打印和货物追踪
- 客服端:基于微信生态开发,可实现消息自动转发至客服系统,支持48小时内多次交互
系统采用微服务架构,各功能模块可独立部署和扩展。通过API接口与ERP、财务等企业现有系统无缝集成,数据集成时间可缩短至0.5天。典型的技术组件包括:

产品方案方面,会给我们生成一些比较流行的思路供参考,比如:货位配置是仓储管理的基础功能,采用"区-排-号"三级结构实现精细化管理。根据领星WMS系统的实践,库位编码格式可参考"A-1-1-1"(A库区,第一个货架,第一层,第一个格子),创建后库位编码、所属库区、库位类型不可修改。系统支持两种库位类型:货架和地堆,虽在系统操作中无区别,但物理存储方式不同。
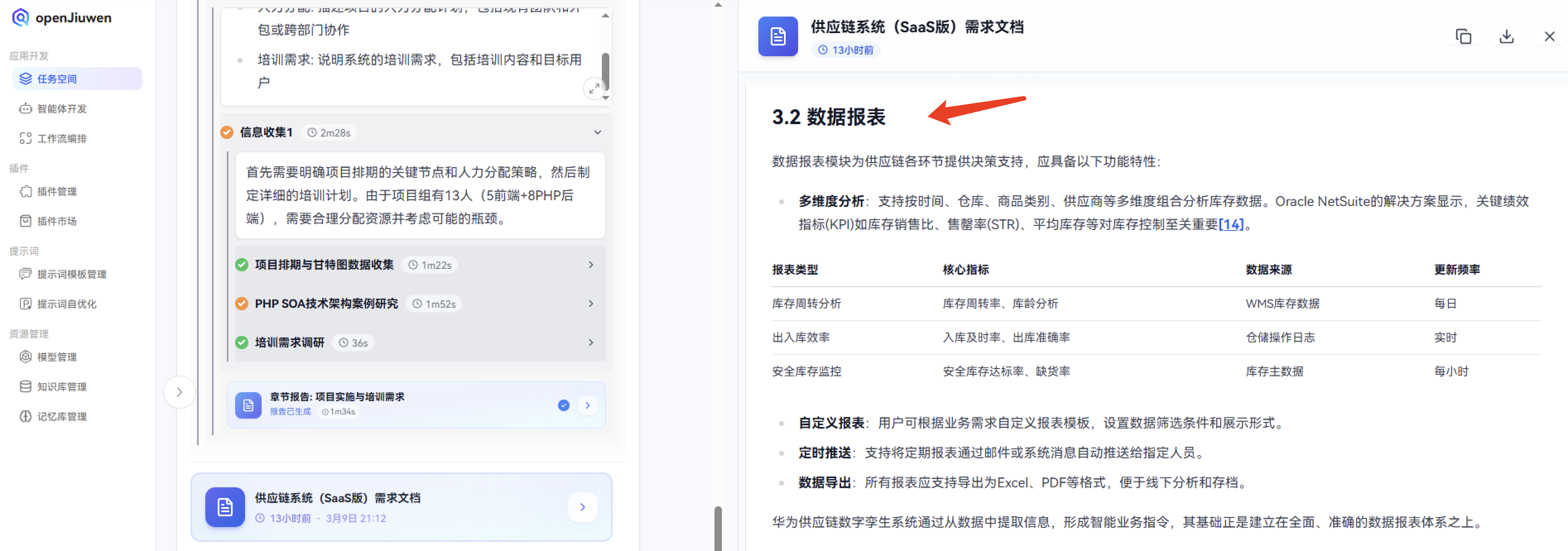
包括数据报表也帮我们考虑了进来,之前也是没想到这一块,可以查缺补漏,支持按时间、仓库、商品类别、供应商等多维度组合分析库存数据。
最后是一个供应链系统(SaaS版)的项目排期需要采用科学的项目管理工具和方法,其中甘特图是最常用的可视化排程工具。甘特图能够清晰地展示项目任务的时间安排、依赖关系和资源分配情况,特别适合供应链系统这类复杂项目的管理。
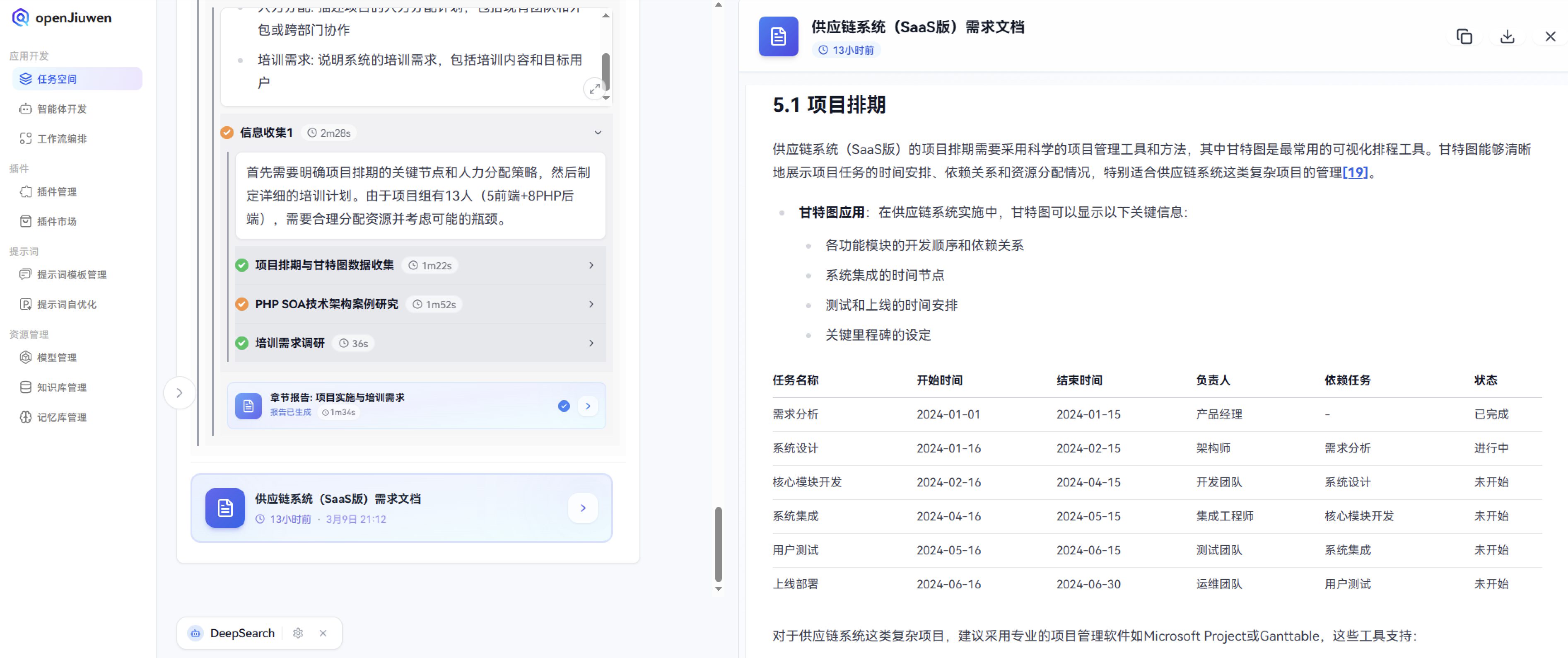
期间遇到的问题点:添加文档时,提示测试失败DeepSearch service request failed. Please try again later,结果排查原因是因为Tavily联网增强引擎的API调用次数过多,超过1000次,会触发限流。
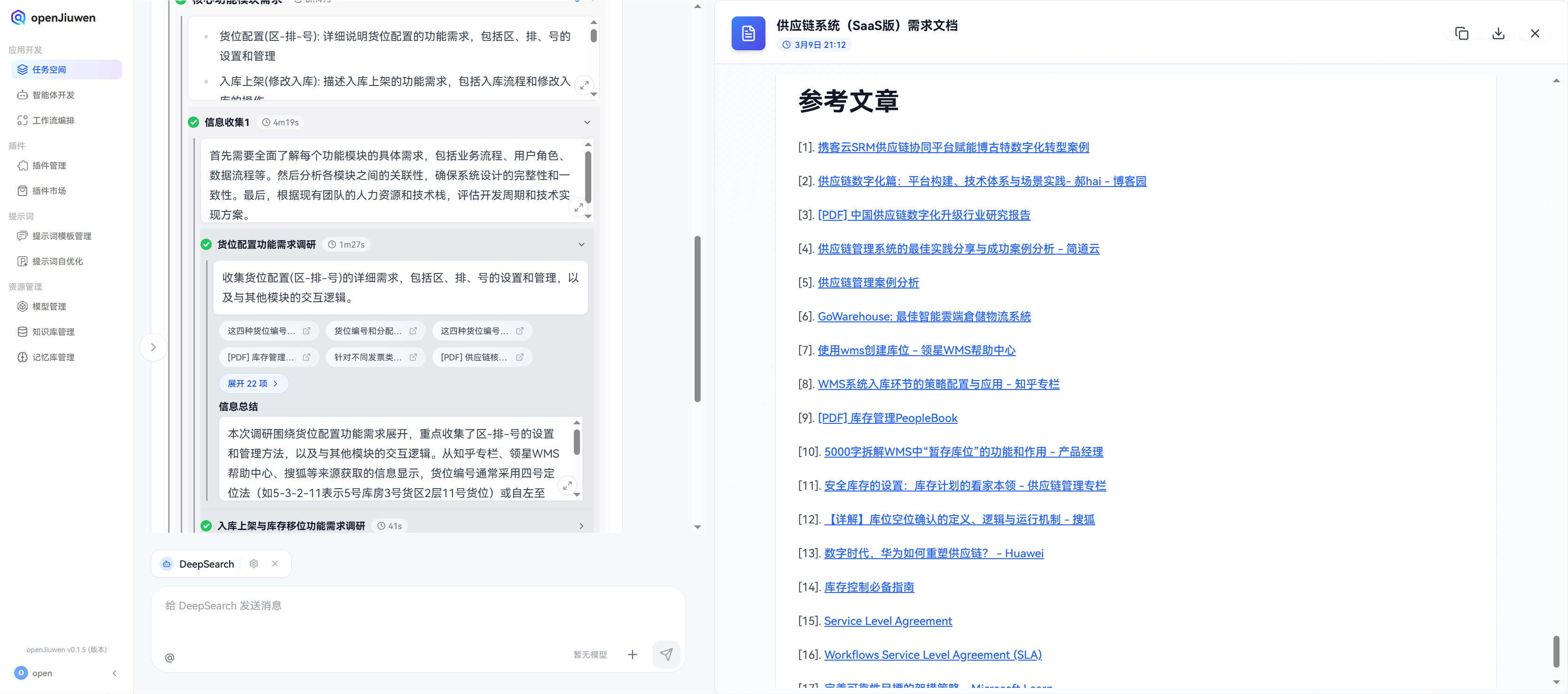
引用详情溯源:
在查看货位配置中,从 openJiuwen-DeepSearch 生成的报告里,对于引用信息来源(即数据源/搜索源),能够回溯到具体的段落和关键性的句子,并且有高亮显示,从而能够快速定位到数据源,并查看数据源的详细内容:
- 1.如果对这个技术方案不太理解,可以看到这里有一个文档链接,点击查看,会跳转到一个文档页面,里面有详细介绍,表示这个方案是从哪里搜索到匹配符合要求的,可以有详情的描述说明。
- 2.右下角还会展示匹配度高低,以及来源十分清晰,可以快速定位到数据源。
- 3.片段级溯源:输出结果并非简单的显示,而是可验证的引用来源,支持对每条结论进行溯源与可信度评估,能具体到段落、句子级别的引用信息,并且"高亮"显示。
货位配置是仓储管理的基础功能,采用"区-排-号"三级结构实现精细化管理。根据领星WMS系统的实践,库位编码格式可参考"A-1-1-1(A库区,第一个货架,第一层,第一个格子),创建后库位编码、所属库区、库位类型不可修改。
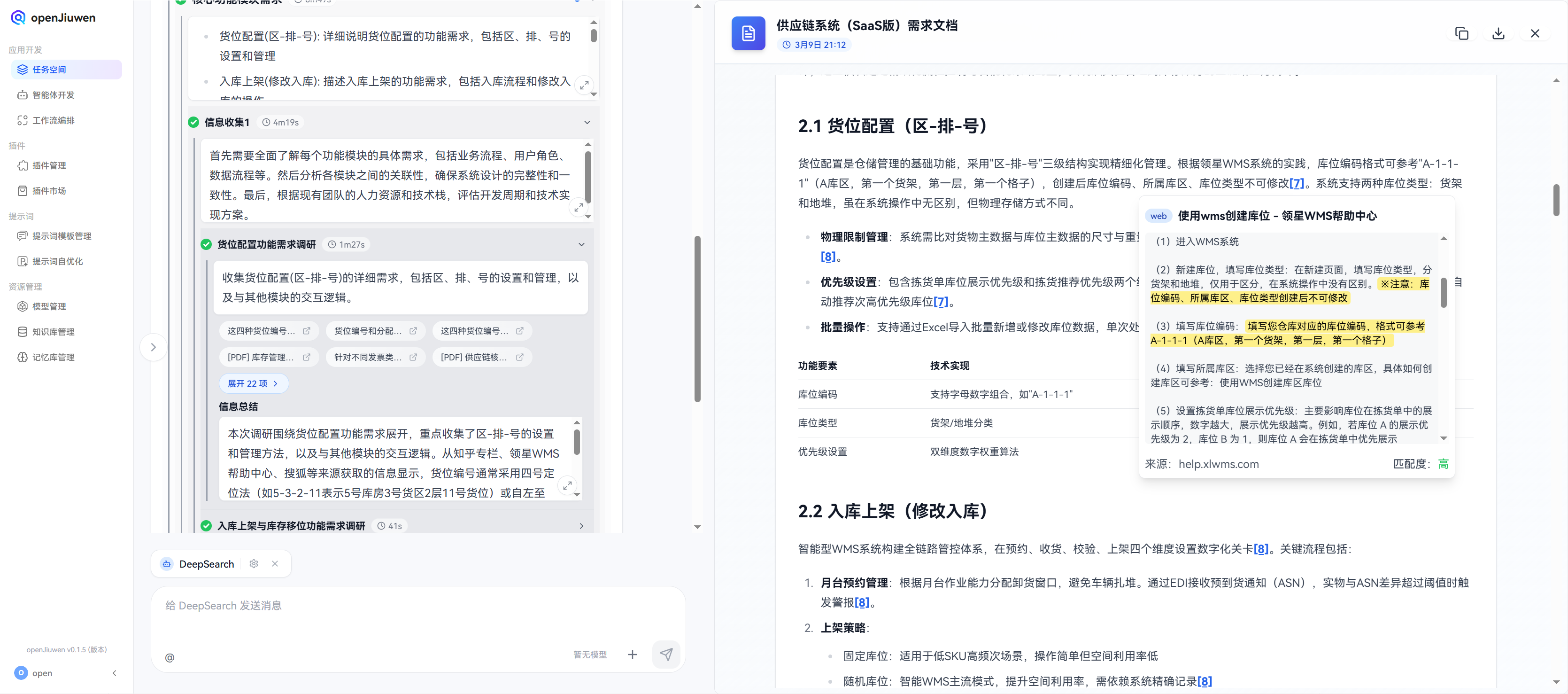
(2)新建库位,填写库位类型:在新建页面,填写库位类型,分货架和地堆,仅用于区分,在系统操作中没有区别。※注意:库位编码、所属库区、库位类型创建后不可修改
(3)填写库位编码:填写您仓库对应的库位编码,格式可参考A-1-1-1(A库区,第一个货架,第一层,第一个格子)
上面表示详细方案的描述,表示库房的货位可以根据库位编码格式来进行不同位置的坐标,实现可以快速定位与查找货源的位置,可以有一个比较成熟的"库位编码格式"方案来实施。
在优先级设置方案:
包含拣货单库位展示优先级和拣货推荐优先级两个维度,数字越大优先级越高。当高优先级库位库存不足时,系统自动推荐次高优先级库位的时候,这里也给出详细的溯源地址:
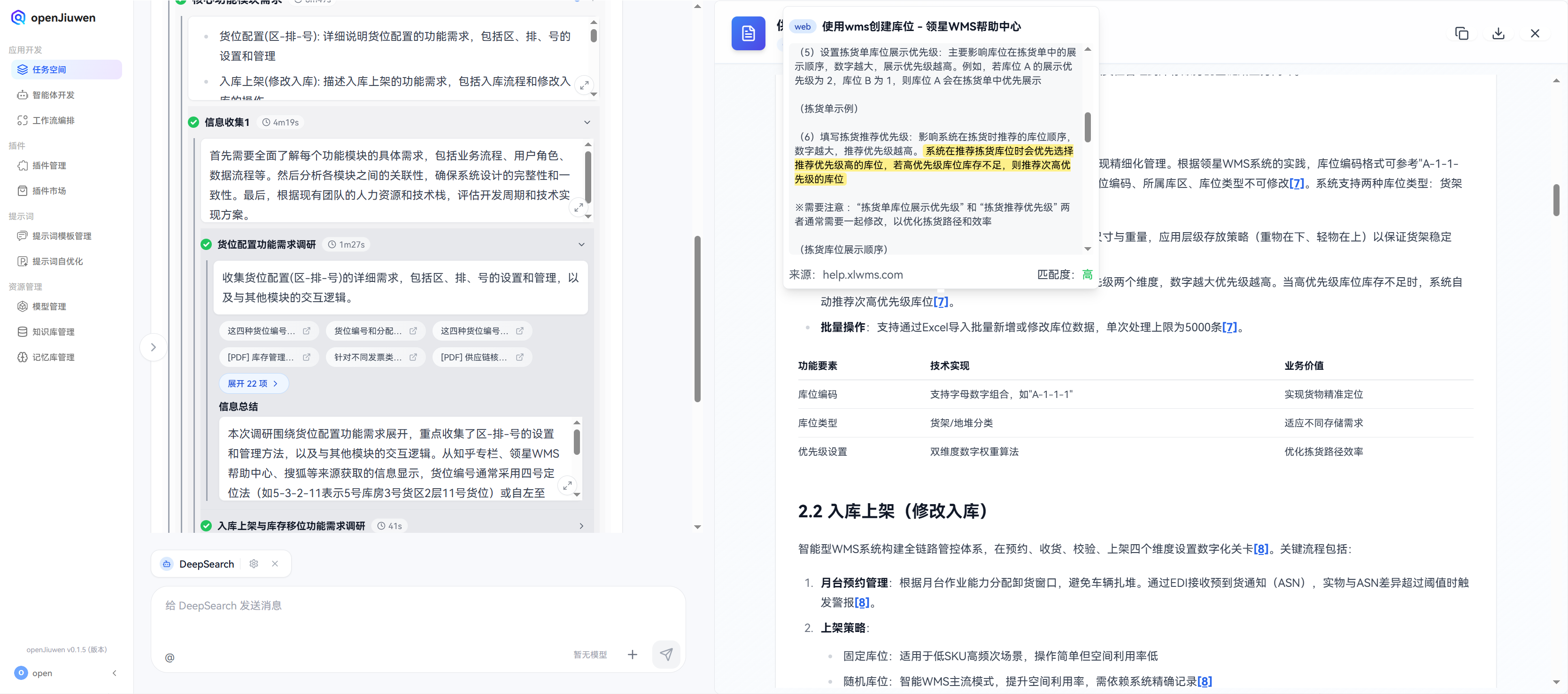
(5)设置拣货单库位展示优先级:主要影响库位在拣货单中的展示顺序,数字越大,展示优先级越高。例如,若库位A的展示优先级为2,库位B为1,则库位A会在拣货单中优先展示
(拣货单示例)
(6)填写拣货推荐优先级:影响系统在拣货时推荐的库位顺序数字越大,推荐优先级越高。系统在推荐拣货库位时会优先选择推荐优先级高的库位,若高优先级库位库存不足,则推荐次高优先级的库位
※需要注意:“拣货单库位展示优先级”和“拣货推荐优先级”两者通常需要一起修改,以优化拣货路径和效率
在优先级的处理方案中,也是给出了一个具体的解决方案,即在系统设置中设置拣货单库位展示优先级和拣货推荐优先级,可以很好的考虑多方面的场景需求案例,提前约定好规则,避免出现无法处理的情况。
异常处理方案:
异常处理:状态为"待检/破损"时,系统自动指引至QC围网区,实现物理隔离。
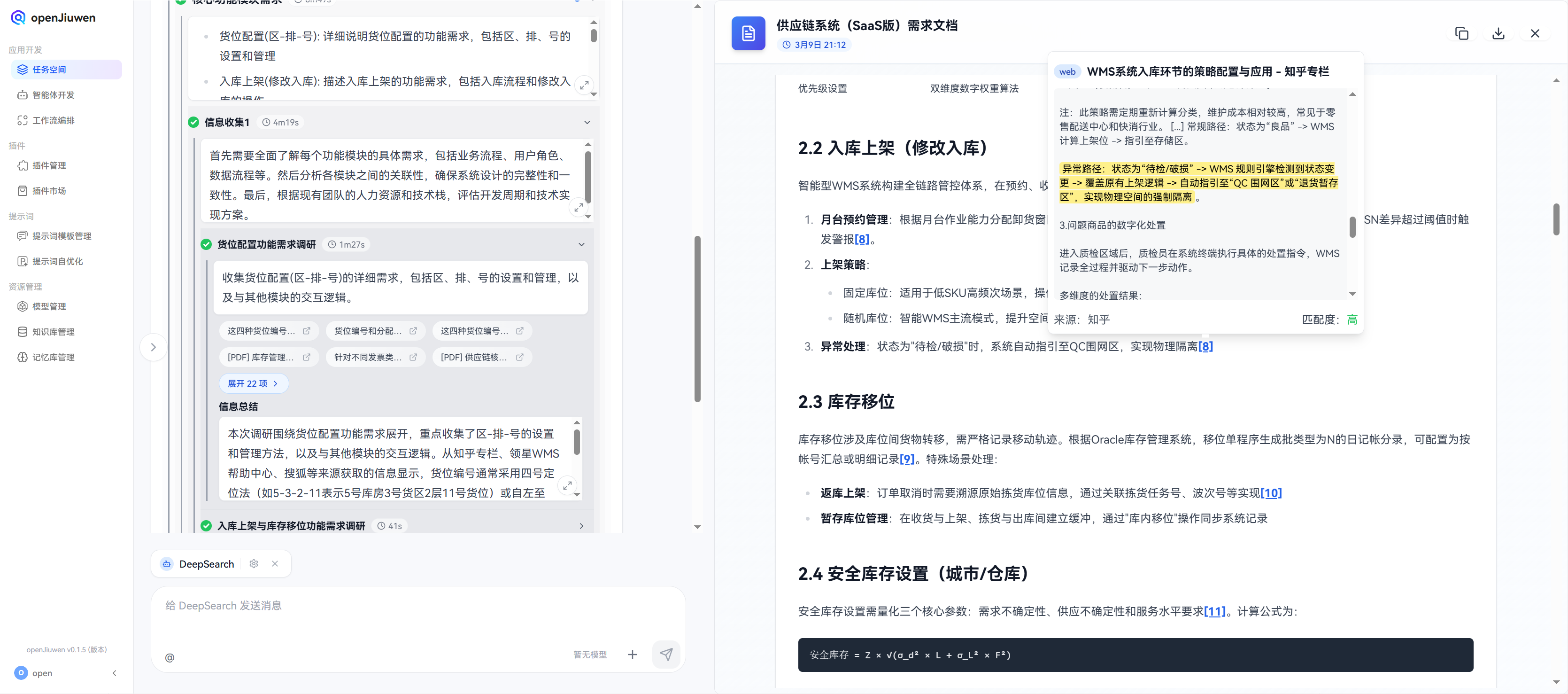
注:此策略需定期重新计算分类,维护成本相对较高,常见于零售配送中心和快消行业。[...]常规路径:状态为“良品”->WMS计算上架位->指引至存储区。
异常路径:状态为“待检/破损”->WMS规则引擎检测到状态变更->覆盖原有上架逻辑->自动指引至“QC围网区”或“退货暂存区”,实现物理空间的强制隔离
3.问题商品的数字化处置
进入质检区域后,质检员在系统终端执行具体的处置指令,WMS记录全过程并驱动下一步动作。
在货物配送过程中,对于货物的异常处理,WMS系统提供了丰富的功能,如异常处理、异常处理方案、异常处理记录、异常处理结果等,这里也是给出了WMS系统对货物配送过程中的异常处理流程的详细描述,我们可以参考对应的方案设计出满足要求的异常处理方案。
最后,可以看到在openJiuwen-DeepSearch的过程中,提供深度搜索与深度研究能力,搜索相关提供对检索结果及其他上下文信息的理解能力,主要包含对搜索结果进行评估、精炼、扩展、融合等功能。
五、总结:
openJiuwen-DeepSearch是一种基于人工智能的深度搜索技术,通过“搜索 → 阅读 → 推理”的循环机制,实现对复杂问题的精准解答。它不再局限于关键词匹配,而是结合语义理解、向量检索与多轮迭代推理,逐步拆解问题、优化查询策略,最终生成更准确、更有逻辑支撑的答案。相比传统搜索仅返回网页列表,openJiuwen-DeepSearch能主动思考“下一步该查什么”,更像一个会自主研究的智能助手。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 21
21 0
0- 0



 已为社区贡献72条内容
已为社区贡献72条内容

所有评论(0)