SBERT:如何让BERT学会“秒懂”句子相似度,还快得飞起?
上一篇文章我们聊了对比学习,知道了它是如何通过“为什么是P而不是Q”的方式让AI真正理解概念的。今天,我们聚焦一个具体的明星框架——sentence-transformers,以及它的核心模型SBERT。它解决了BERT家族一个让人头疼的问题:计算太慢!
你可能要问:BERT不是已经很强大了吗?为什么还需要SBERT?别急,我们先从一个场景入手。
一、一个让人崩溃的场景:从1万句话里找“灵魂伴侣”
假设你是一个产品经理,手里有1万条用户评论,你想找出其中最相似的那些评论,比如所有的好评、所有的差评、或者所有提到“发货慢”的吐槽。用BERT怎么搞?
传统的方法是使用交叉编码器。它的工作方式如下图所示:把两个句子拼在一起,中间加个<SEP>分隔符,然后一股脑儿扔给BERT,最后通过一个分类器输出它们的相似度分数(比如0.8代表很相似)。
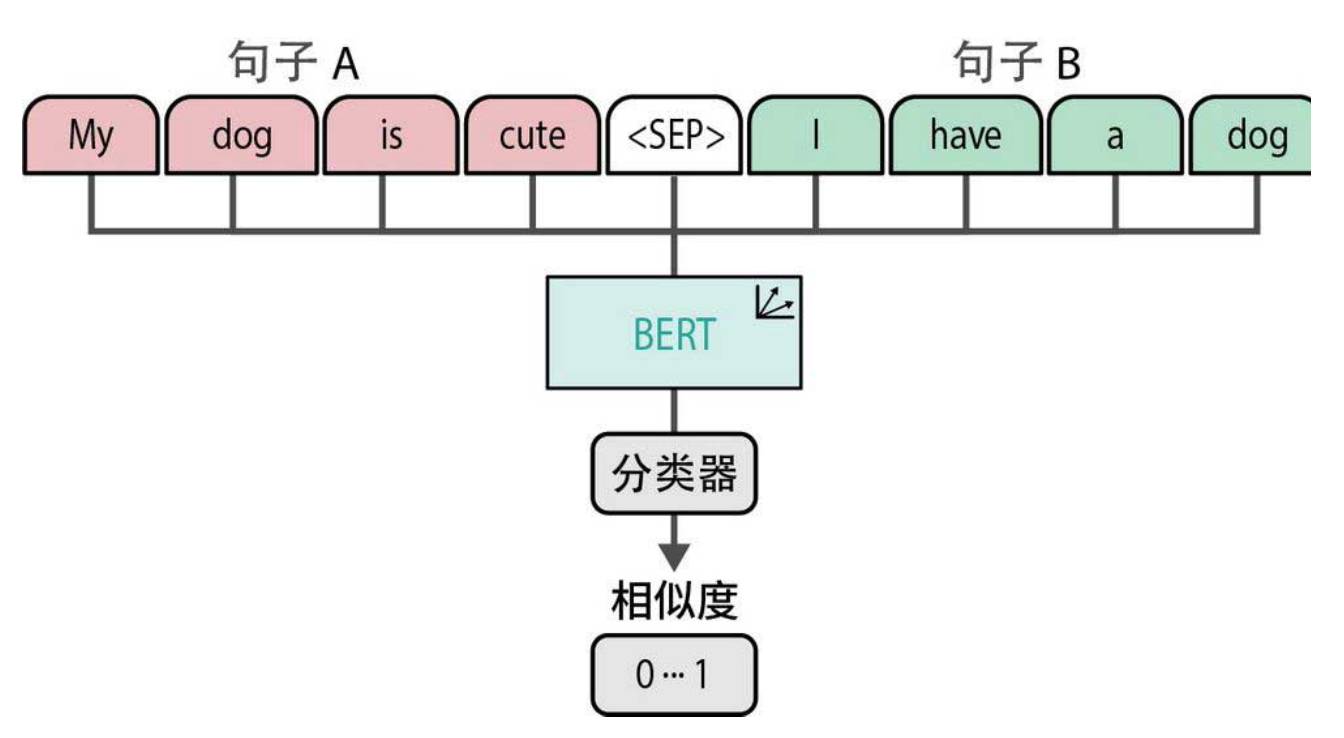
这听起来很直接,但问题来了:你要比较1万条评论,需要做多少次这样的操作?
计算公式:n × (n-1) / 2。1万条评论,就是 10000 × 9999 / 2 ≈ 5000万次!每次都要跑一遍完整的BERT模型,哪怕用GPU也得算到天荒地老。
更扎心的是,交叉编码器只输出相似度分数,不生成句子嵌入。这意味着你没法提前把每条评论的“特征向量”算好存起来,每次对比都得重新跑一遍原句。这就像每次相亲都要重新了解对方的一切,而不是先看简历筛选——效率低到令人发指。
二、BERT自己生成嵌入?效果还不如10年前的老方法!
那有没有什么取巧的办法?比如直接用BERT的输出层搞个嵌入向量出来?
有人试过:要么取所有词元的平均值,要么直接用[CLS]词元的输出。结果呢?效果比直接用GloVe(2014年提出的词向量方法)对词取平均还要差!这就像你让一个博士生去做小学生的算术题,结果算错了——大材小用,方法不对。
显然,BERT这种为句子对交互设计的模型,直接“拧”出来的嵌入向量并不适合做语义比较。于是,sentence-transformers的作者们想出了一个优雅的解决方案。
三、SBERT登场:孪生网络让BERT“分头行动”
2019年,论文《Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks》横空出世。作者提出了一种新的架构——孪生网络,也叫双编码器。
名字听起来挺玄乎,其实原理很简单:两个一模一样的BERT模型,共享完全相同的权重,同时处理两个句子。如下图所示:
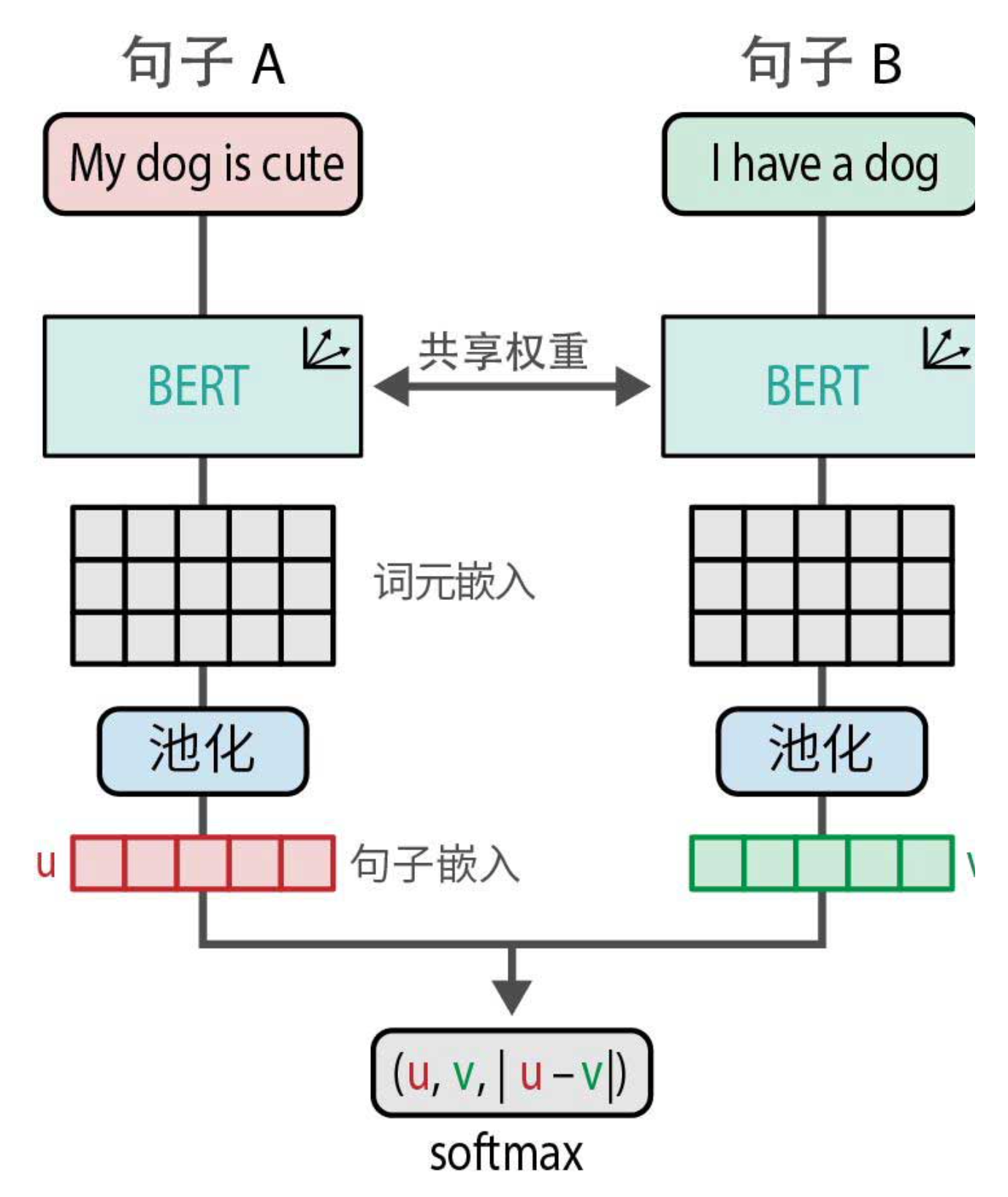
-
句子A:“My dog is cute” → 进入BERT → 池化层 → 得到嵌入向量
u -
句子B:“I have a dog” → 进入同一个BERT(注意是同一个!)→ 池化层 → 得到嵌入向量
v
这里的池化层是关键。BERT输出的是一串词元嵌入(每个词对应一个向量),池化层把它们平均成一个固定长度的向量,比如768维。这样一来,无论句子多长,最终得到的嵌入向量大小都一样。
然后,我们就可以用u和v来计算相似度了,比如余弦相似度。而且这些向量可以预先算好存起来,需要比较时直接取用,计算量瞬间从5000万次推理降为1万次推理(每条评论只算一次)加上一些简单的向量运算。
这就像我们提前把每个人的简历做出来,然后直接比对简历关键词,不用每次都重新面试——效率提升了几个数量级。
四、训练SBERT:对比学习的新战场
SBERT的训练过程依然是典型的对比学习。我们需要构造相似/不相似的句子对:
-
正例:语义相似的句子(比如“我的狗很可爱”和“我有一只可爱的狗”)
-
负例:语义不相关的句子(比如“我的狗很可爱”和“地球是圆的”)
在训练时,两个BERT(其实是同一个)分别处理两个句子,得到嵌入u和v。然后,作者使用了一个巧妙的组合:将u、v以及|u - v|(元素级差的绝对值)拼接起来,形成一个新向量。这个向量再通过一个softmax分类器,预测这两个句子是相似还是不相似。
为什么要把差向量|u - v|也拼进去?因为差向量捕捉了句子之间的语义差异——如果两个句子相似,它们的差向量应该接近零;如果不相似,差向量就会很大。这个信息对分类器判断相似度非常有用。
通过这种训练,SBERT学会了将语义相近的句子映射到相近的向量空间中。这正是对比学习的目标。
五、双编码器 vs 交叉编码器:各有千秋
既然SBERT这么高效,那是不是可以完全取代交叉编码器?不一定。两者各有利弊:
-
双编码器(SBERT):速度快、可扩展、能生成固定嵌入。适合做大规模语义搜索、聚类、推荐等任务。比如在1万个句子里找最相似的,或者把百万级文档分组。
-
交叉编码器:精度更高,因为两个句子在模型内部进行了深度交互(attention可以跨句子捕捉细微联系)。但速度慢,无法预计算。适合对少量句子对进行高精度评分,比如重排序(reranking)——先用SBERT粗筛出前100个候选,再用交叉编码器精排。
在实际应用中,两者常常搭档使用:SBERT负责“海选”,交叉编码器负责“终审”。既保证了效率,又不牺牲精度。
六、总结:SBERT让语义理解飞入寻常百姓家
SBERT的出现,可以说是自然语言处理领域的一次“平民化革命”。它解决了BERT家族在句子嵌入上的两大痛点:
-
计算开销:从平方级降到线性级,让大规模语义搜索成为可能。
-
嵌入质量:通过孪生网络+对比学习,让句子嵌入真正具备了语义可比性,远超简单池化BERT的方法。
更重要的是,sentence-transformers这个框架把SBERT以及各种变体封装得极其易用,几行代码就能加载预训练模型、计算句子相似度、做语义搜索。如今,它已经成为NLP工程师的标配工具。
回过头看,对比学习贯穿始终:从word2vec的局部上下文对比,到SBERT的句子对对比,再到更复杂的多视角对比。这种“通过区分来理解”的智慧,正在不断推动AI的边界。
所以,下次你用sentence-transformers一秒找出最相似的文档时,别忘了感谢那个看似简单却极其深刻的理念——理解一个事物,最好的方式就是弄清楚它为什么不是另一个。
本文参考:图解大模型:生成式AI原理与实战
书籍pdf免费下载地址:https://pan.baidu.com/s/1mTaUQ5czcfGpBM8KvJuS2g?pwd=un44

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献131条内容
已为社区贡献131条内容

所有评论(0)