计算机毕业设计源码:Python得物鞋类数据分析可视化与推荐系统 Django框架 协同过滤 可视化 数据分析 大模型 电商 推荐系统 商品 大数据 agent(建议收藏)✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
项目介绍
技术栈:Python语言、django框架、MySQL数据库、协同过滤推荐算法、Echarts可视化、HTML
功能模块:
· 商品首页
· 可视化大屏分析
· 季节性大屏分析
· 协同过滤推荐
· 商品评分详情页
· 后台数据管理
本项目基于得物平台鞋类销售数据,采用Python与Django框架构建后端服务,以MySQL作为数据存储引擎,引入协同过滤推荐算法实现个性化商品推荐,并借助Echarts可视化库将数据渲染为直观图表呈现在前端页面。系统通过商品首页浏览、多维度可视化大屏分析、季节性专题数据展示、用户评分反馈收集以及后台数据管理等功能,为商家提供市场趋势洞察和消费者行为分析,辅助其优化产品规划与营销策略,同时为消费者提供精准的商品推荐和便捷的数据查询服务,帮助用户高效发现心仪商品,改善购物决策体验。
2、项目界面
(1)商品首页
这是商品销售数据可视化分析系统的页面,左侧设有数据大厅、推荐、数据大屏、后台管理等功能导航栏,顶部有搜索栏,中间以卡片形式展示商品信息,可实现商品浏览、搜索及系统功能切换等操作。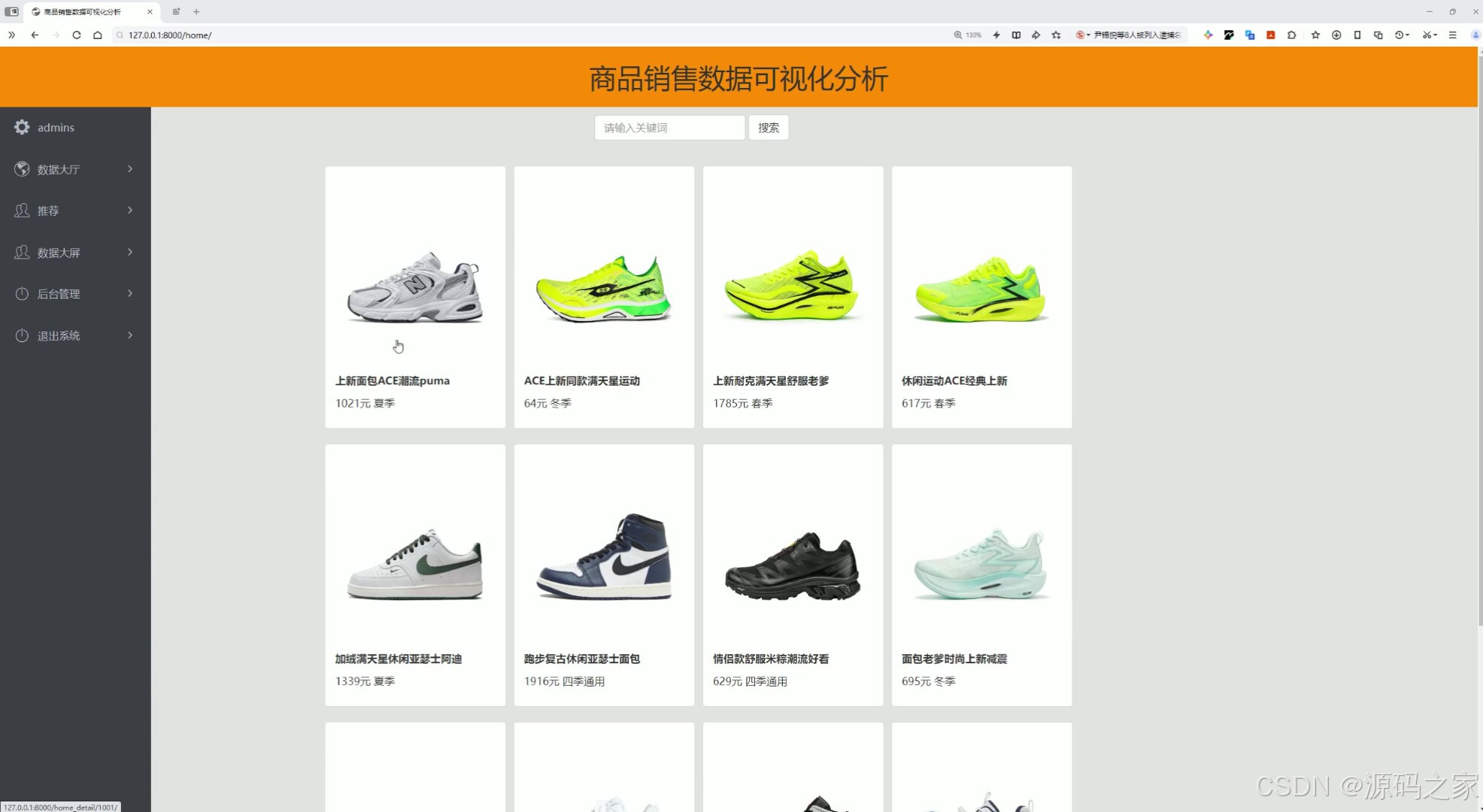
(2)可视化大屏分析
这是商品销售数据可视化分析系统的数据大屏页面,顶部设有不同季节大屏切换及返回系统功能,页面通过柱状图、词云图、饼图、环形图、折线图等多种图表,实现所属季节统计、评论词云、男女鞋统计、各阶段销量占比、性别占比、所属季节占比、标题词云、鞋子价格统计等多维度数据可视化展示功能。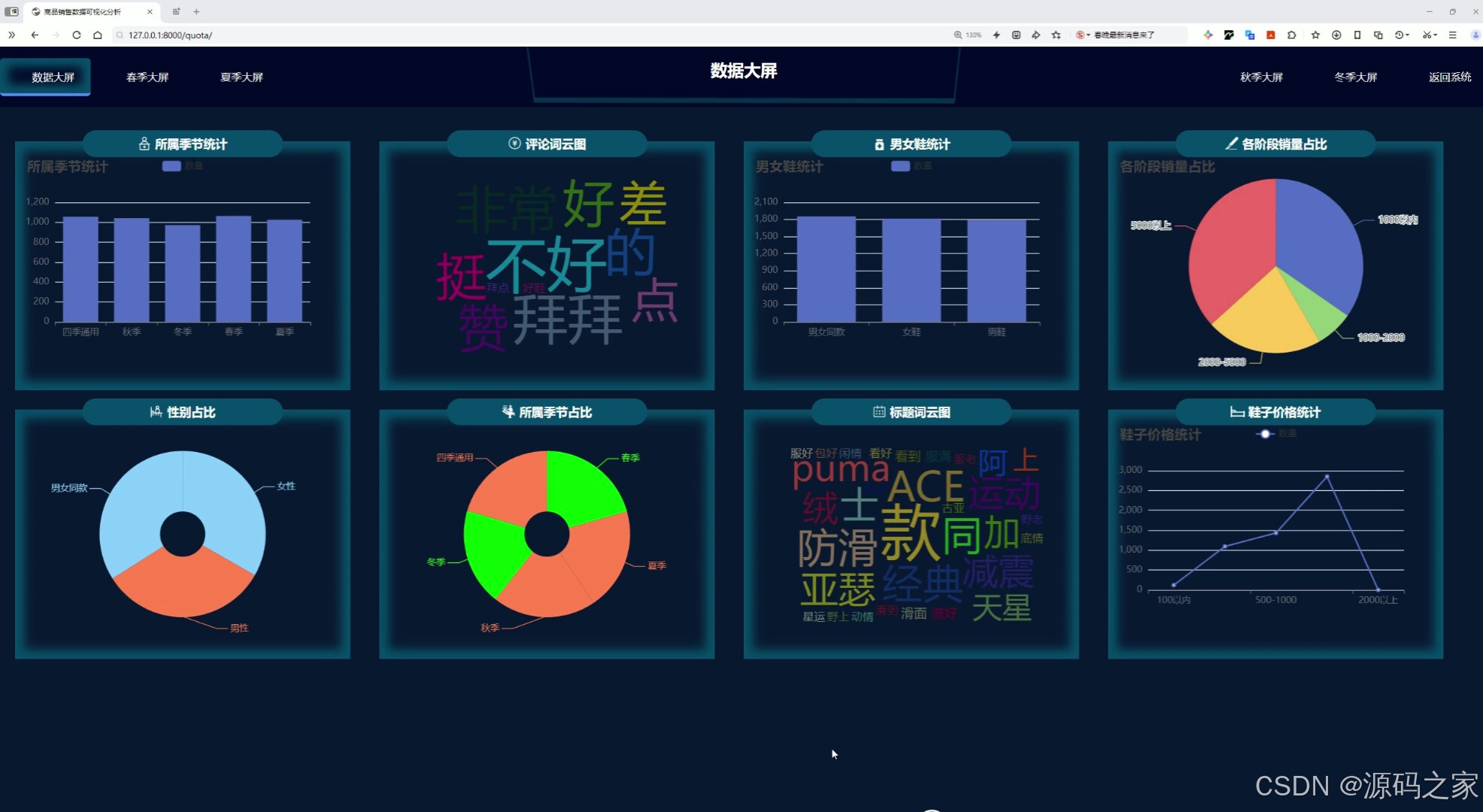
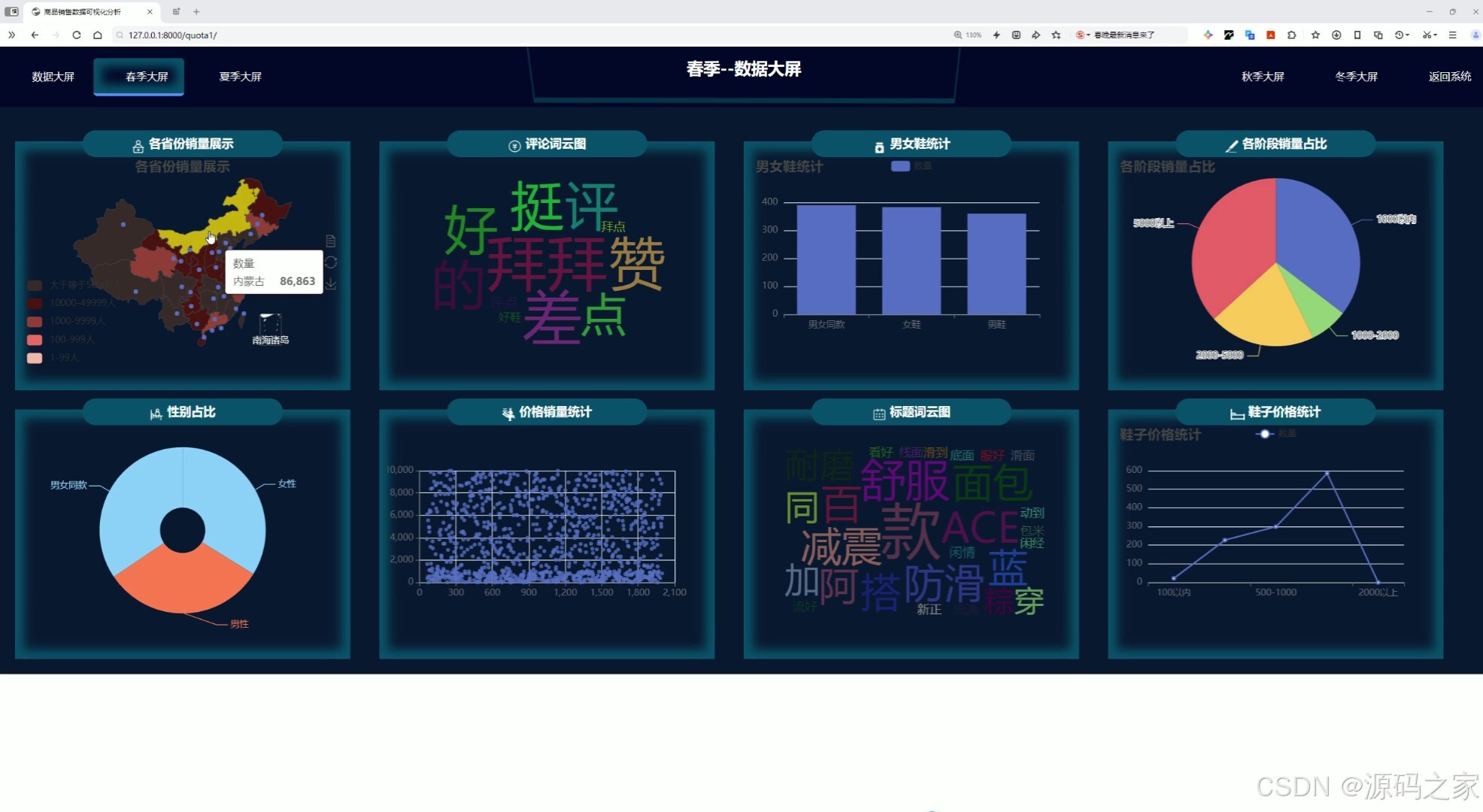
(3)春季大屏分析(此处省略-夏秋冬大屏分析图)
这是商品销售数据可视化分析系统的春季数据大屏页面,顶部设有不同季节大屏切换及返回系统功能,页面通过地图、柱状图、词云图、饼图、散点图、折线图等多种图表,实现各省份销量展示、评论词云、男女鞋统计、各阶段销量占比、性别占比、价格销量统计、标题词云、鞋子价格统计等多维度春季商品数据可视化展示功能。
(4)推荐—协同过滤推荐算法
这是商品销售数据可视化分析系统的推荐页面,左侧设有数据大厅、推荐、数据大屏、后台管理等功能导航栏,顶部有搜索栏,中间以卡片形式展示算法推荐的商品信息,可实现商品浏览、搜索及系统功能切换等操作。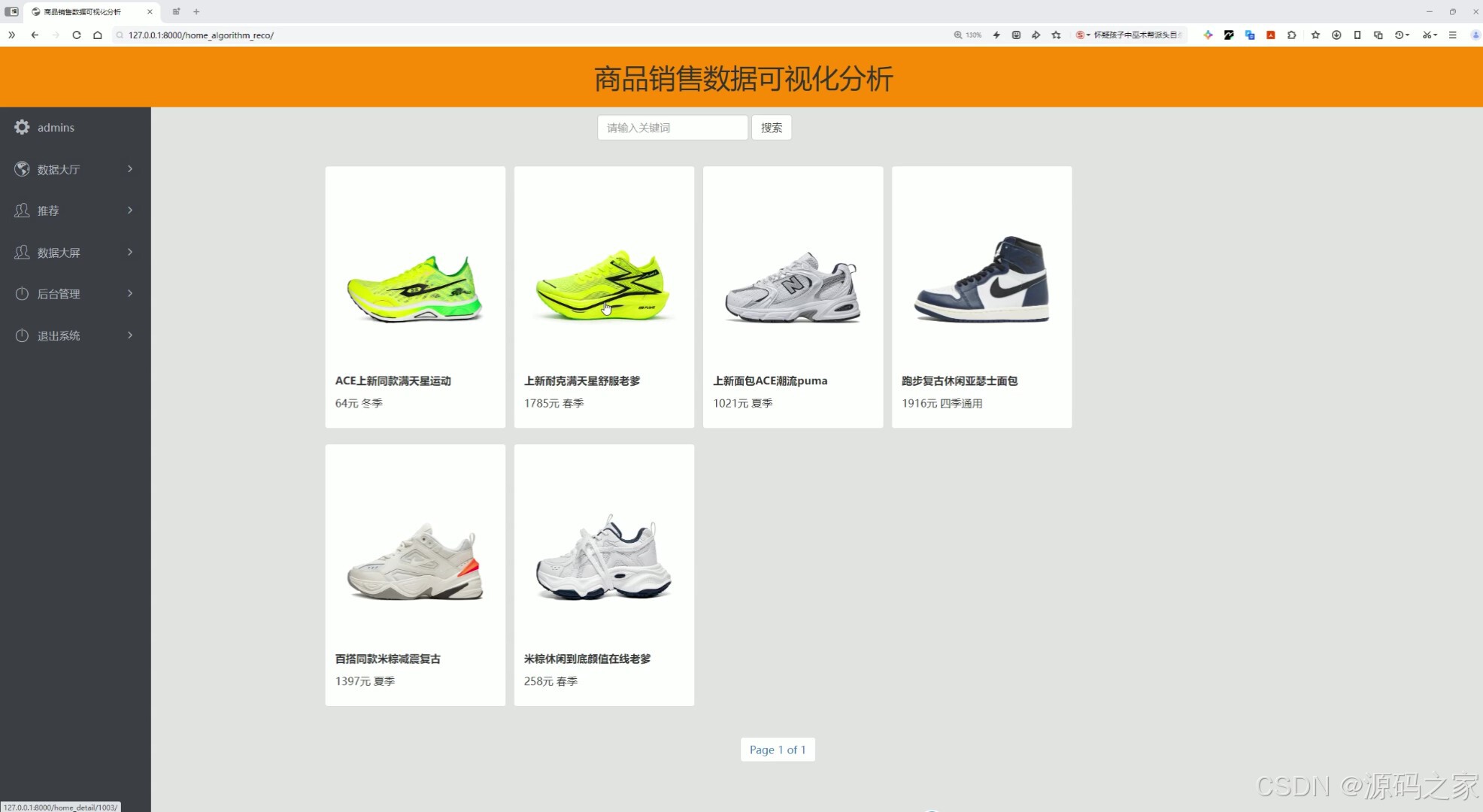
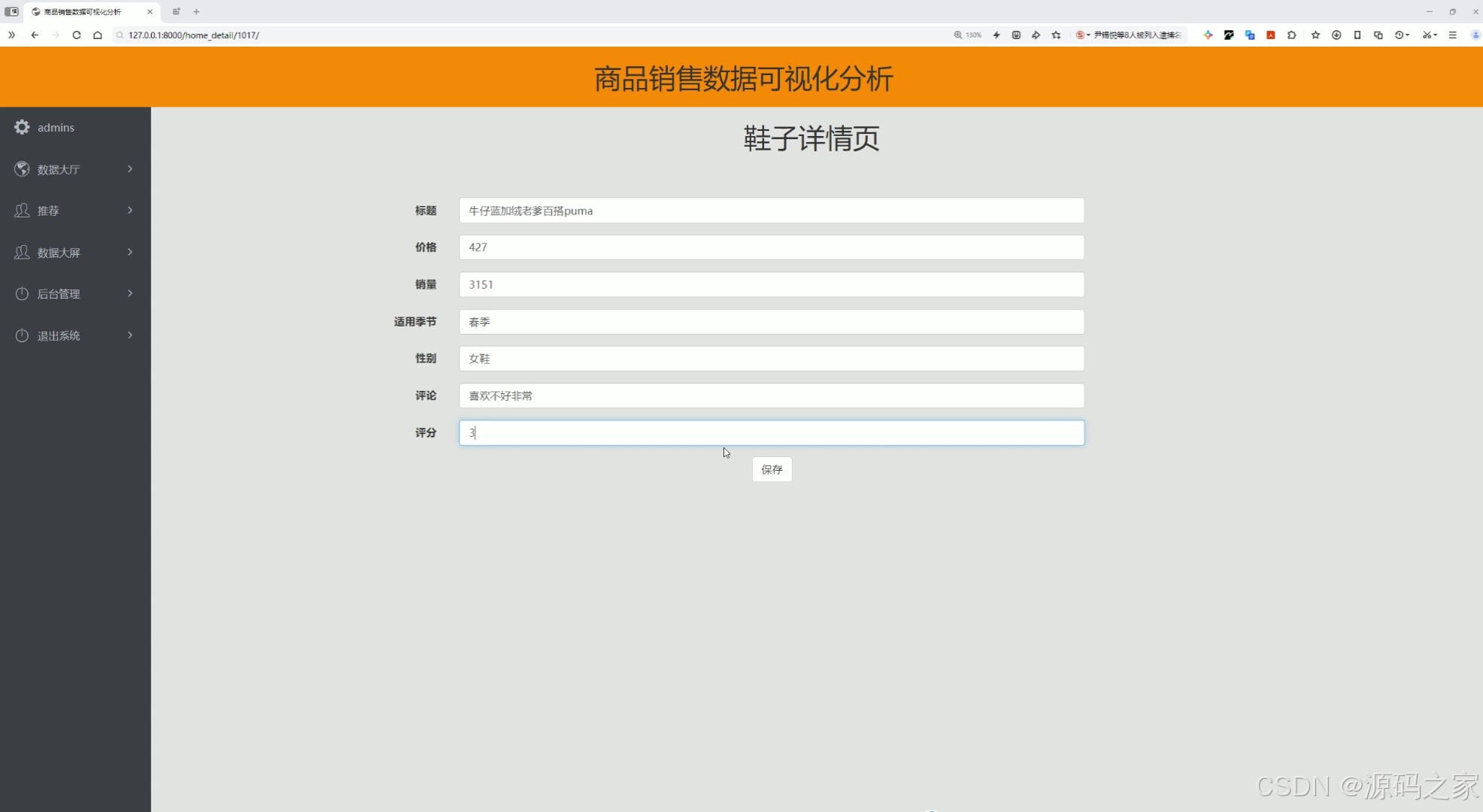
(5)商品评分—详情页
这是商品销售数据可视化分析系统的鞋子详情页,左侧提供数据大厅、推荐、数据大屏、后台管理等功能入口,页面展示商品标题、价格、销量、适用季节、性别等基础信息,并支持用户在线修改商品评论与评分并进行保存提交。
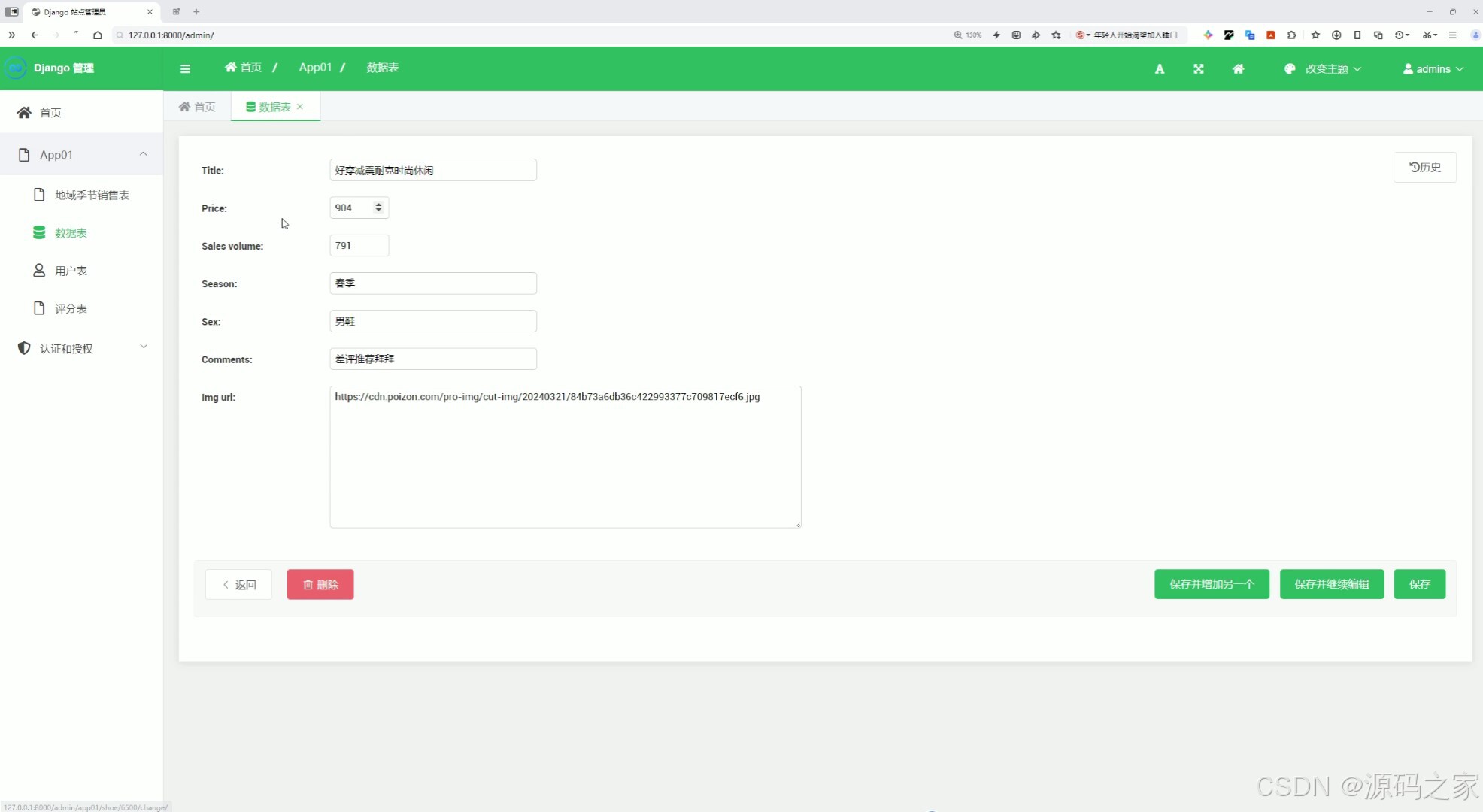
(6)后台数据管理
这是Django站点管理系统的数据编辑页面,左侧提供首页、各数据表及认证授权等功能导航,页面内可编辑商品的标题、价格、销量、季节、性别、评论、图片链接等数据信息,支持返回、删除、保存及继续编辑等操作,实现对商品数据的管理维护。
3、项目说明
一、技术栈简要说明
本系统后端采用Python语言进行开发,基于Django框架构建完整的业务逻辑层,利用其内置的ORM模块实现与MySQL数据库的高效数据交互。MySQL作为系统的数据存储引擎,负责持久化保存鞋类商品信息、用户评分记录及销售数据。在推荐引擎层面,系统采用协同过滤推荐算法,通过分析用户对商品的评分数据,计算用户间或物品间的相似度,从而挖掘用户的潜在兴趣点,实现个性化的商品推送服务。前端数据展示层面,系统引入Echarts可视化库,将后端处理好的统计数据渲染为柱状图、折线图、饼图、词云图、地图等多种动态图表,构建出直观的数据大屏。前端页面整体使用HTML进行结构搭建,配合CSS进行样式布局,确保用户界面的友好性与交互的流畅性。
二、功能模块详细介绍
· 商品首页
商品首页作为系统的入口界面,承担着商品展示与导航的核心功能。页面左侧设置了固定的垂直导航栏,集成了数据大厅、协同过滤推荐、可视化大屏、后台管理等多个核心模块的快捷入口,方便用户在不同业务场景间快速切换。页面顶部配备全局搜索框,支持用户通过商品名称或关键词进行模糊查询,快速定位目标商品。页面主体区域采用瀑布流卡片布局展示鞋类商品,每张卡片包含商品主图、名称、价格等关键信息,点击卡片可跳转至对应的商品详情页。该模块为用户提供了一个直观的商品浏览窗口,是用户进行深度交互的起点。
· 可视化大屏分析
可视化大屏模块是系统数据展示能力的集中体现。页面顶部设置了季节性切换按钮,支持用户在春、夏、秋、冬四季的数据视图间自由跳转,同时提供返回系统主功能的快捷通道。页面主体采用网格化布局,嵌入了柱状图、词云图、饼图、环形图、折线图等多种Echarts图表组件。这些图表从多个维度对数据库中的鞋类销售数据进行解析,具体包括所属季节分布统计、用户评论词云分析、男女鞋数量对比、各价格区间销量占比、用户性别比例分布、所属季节销量占比、商品标题关键词云以及鞋子价格区间统计等功能。通过这一模块,管理者可以一目了然地掌握整体销售状况与用户画像特征,为决策提供直观的数据支撑。
· 季节性大屏分析
考虑到鞋类消费具有明显的季节性波动特征,系统在通用大屏基础上,进一步开发了春、夏、秋、冬四个独立的季节性数据分析大屏。以春季大屏为例,页面在保留顶部季节切换功能的同时,引入了中国地图组件用于展示各省份的销量分布热力情况,帮助管理者直观了解区域市场表现。此外,该页面还结合散点图、柱状图、折线图等可视化工具,针对特定季节的商品数据进行深度挖掘,如价格与销量的相关性分析、特定季节下的男女鞋偏好差异、季节性爆款商品的特征提取等。这一模块能够帮助商家精准把握不同季节的市场需求变化规律,为季节性选品策略、库存周转管理和营销活动策划提供精准的数据支持。
· 协同过滤推荐
推荐模块基于协同过滤推荐算法构建,旨在提升用户的购物效率与个性化体验。当用户进入推荐页面时,系统后台会实时调用推荐算法引擎,根据该用户的历史评分行为数据,结合与其兴趣相似的其他用户的偏好信息,计算并生成个性化的商品推荐列表。页面布局与商品首页保持一致,左侧保留功能导航栏,顶部保留搜索框,主体区域以卡片形式展示被推荐的鞋类产品。用户可以像浏览普通列表一样查看这些根据其兴趣偏好筛选出的商品,并可直接点击进入详情页。该模块实现了从传统的被动搜索到主动个性化推荐的转变,有效降低了用户的信息筛选成本,增强了用户对系统的粘性和满意度。
· 商品评分详情页
商品详情页是对单件商品信息的深度展开与交互界面。页面在保留左侧功能导航栏的同时,集中展示了商品的标题、当前价格、累计销量、适用季节、适用性别等详细属性参数。该模块的核心交互功能在于用户评分与评论系统,用户可以在浏览商品详细信息后,在线提交或修改自己对商品的评分星级和文字评论内容,并点击保存按钮完成数据上传。这些由用户实时贡献的评分数据不仅为其他潜在消费者提供了真实的购买参考依据,更重要的是,它们作为核心训练数据源源不断地输入到协同过滤推荐算法模型中,保障了推荐系统的持续优化和准确性,形成了用户反馈与算法迭代的良性循环。
· 后台数据管理
后台数据管理模块基于Django框架原生提供的Admin后台管理系统进行了深度定制和功能扩展。管理员通过特定账号登录后,可以在左侧导航栏中看到项目所有数据表的完整列表,包括商品信息表、用户信息表、评分记录表等。进入具体的商品编辑页面后,管理员可以对商品的标题文本、价格数值、销量数据、季节属性标签、性别属性标签、用户评论文本、商品图片链接地址等字段进行直接的修改、删除或新增操作,并支持保存修改或继续编辑。该页面还提供了返回列表、删除当前记录等便捷操作按钮。这一模块确保了系统底层数据能够被及时更新和有效维护,是整个系统能够持续稳定运行并提供准确分析结果的后勤保障。
三、项目总结
本项目构建了一个聚焦于得物平台鞋类销售数据的一体化分析与个性化推荐系统。系统后端采用Python与Django框架处理业务逻辑与数据交互,依托MySQL数据库进行结构化数据存储,前端则借助Echarts可视化库实现销售数据的多维度图表呈现。通过引入协同过滤推荐算法,系统能够基于用户的真实评分数据提供个性化的商品推荐服务。在功能设计上,项目形成了从前端商品浏览、多维度可视化大屏展示、季节性细分数据分析,到个性化商品推荐、用户评分反馈收集,再到后台数据管理维护的完整业务闭环。该系统旨在帮助鞋类商家深入洞察市场趋势与消费者行为特征,为其产品规划、库存管理和营销决策提供精准的数据支撑,同时也为终端消费者提供了更高效、更精准的购物信息服务和个性化商品发现路径,实现了商家与用户的双赢价值。
4、核心代码
class CF:
def __init__(self, movies, ratings, k=5, n=10):
self.movies = movies
self.ratings = ratings
self.k = k
self.n = n
self.userDict = {}
self.ItemUser = {}
self.neighbors = []
self.recommandList = []
self.cost = 0.0
# def recommendByUser(self, userId):
# self.formatRate()
# self.n = len(self.userDict[userId])
# self.getNearestNeighbor(userId)
# self.getrecommandList(userId)
# self.getPrecision(userId)
def recommendByUser(self, userId):
self.formatRate()
# 检查用户是否是新用户,即没有评分记录
if userId not in self.userDict:
# 如果是新用户,我们可以选择跳过推荐或者返回一个默认的推荐列表
print(f"No ratings found for user {userId}. Skipping recommendations.")
return # 或者返回一个默认的推荐列表
self.n = len(self.userDict[userId])
self.getNearestNeighbor(userId)
self.getrecommandList(userId)
self.getPrecision(userId)
def getrecommandList(self, userId):
self.recommandList = []
recommandDict = {}
for neighbor in self.neighbors:
movies = self.userDict[neighbor[1]]
for movie in movies:
if (movie[0] in recommandDict):
recommandDict[movie[0]] += neighbor[0]
else:
recommandDict[movie[0]] = neighbor[0]
# 建立推荐列表
for key in recommandDict:
self.recommandList.append([recommandDict[key], key])
self.recommandList.sort(reverse=True)
self.recommandList = self.recommandList[:self.n]
# 将ratings转换为userDict和ItemUser
def formatRate(self):
self.userDict = {}
self.ItemUser = {}
for i in self.ratings:
# 评分最高为5 除以5 进行数据归一化
temp = (i[1], float(i[2]) / 5)
# 计算userDict {'1':[(1,5),(2,5)...],'2':[...]...}
if (i[0] in self.userDict):
self.userDict[i[0]].append(temp)
else:
self.userDict[i[0]] = [temp]
# 计算ItemUser {'1',[1,2,3..],...}
if (i[1] in self.ItemUser):
self.ItemUser[i[1]].append(i[0])
else:
self.ItemUser[i[1]] = [i[0]]
# 找到某用户的相邻用户
def getNearestNeighbor(self, userId):
neighbors = []
self.neighbors = []
# 获取userId评分的图书都有那些用户也评过分
for i in self.userDict[userId]:
for j in self.ItemUser[i[0]]:
if (j != userId and j not in neighbors):
neighbors.append(j)
# 计算这些用户与userId的相似度并排序
for i in neighbors:
dist = self.getCost(userId, i)
self.neighbors.append([dist, i])
# 排序默认是升序,reverse=True表示降序
self.neighbors.sort(reverse=True)
self.neighbors = self.neighbors[:self.k]
# 格式化userDict数据
def formatuserDict(self, userId, l):
user = {}
for i in self.userDict[userId]:
user[i[0]] = [i[1], 0]
for j in self.userDict[l]:
if (j[0] not in user):
user[j[0]] = [0, j[1]]
else:
user[j[0]][1] = j[1]
return user
# 计算余弦距离
def getCost(self, userId, l):
user = self.formatuserDict(userId, l)
x = 0.0
y = 0.0
z = 0.0
for k, v in user.items():
x += float(v[0]) * float(v[0])
y += float(v[1]) * float(v[1])
z += float(v[0]) * float(v[1])
if (z == 0.0):
return 0
return z / sqrt(x * y)
# 推荐的准确率
# def getPrecision(self, userId):
# user = [i[0] for i in self.userDict[userId]]
# print("self.recommandList",self.recommandList)
# recommand = [i[1] for i in self.recommandList]
# print(recommand)
# count = 0.0
# if (len(user) >= len(recommand)):
# for i in recommand:
# if (i in user):
# count += 1.0
# self.cost = count / len(recommand)
# else:
# for i in user:
# if (i in recommand):
# count += 1.0
# self.cost = count / len(user)
# 推荐的准确率
def getPrecision(self, userId):
user = [i[0] for i in self.userDict[userId]]
print("self.recommandList", self.recommandList)
recommand = [i[1] for i in self.recommandList]
print(recommand)
count = 0.0
if len(recommand) == 0: # 检查recommand列表是否为空
self.cost = 0 # 如果为空,准确率设置为0
elif (len(user) >= len(recommand)):
for i in recommand:
if (i in user):
count += 1.0
self.cost = count / len(recommand)
else:
for i in user:
if (i in recommand):
count += 1.0
self.cost = count / len(user)
# 显示推荐列表
def showTable(self):
if not self.recommandList: # 检查推荐列表是否为空
print("No recommendations available.")
return []
neighbors_id = [i[1] for i in self.neighbors]
table = Texttable()
table.set_deco(Texttable.HEADER)
table.set_cols_dtype(["t", "t", "t", "t"])
table.set_cols_align(["l", "l", "l", "l"])
rows = []
for item in self.recommandList:
fromID = []
for i in self.movies:
if i[0] == item[1]:
movie = i
break
for i in self.ItemUser[item[1]]:
if i in neighbors_id:
fromID.append(i)
movie.append(fromID)
rows.append(movie)
print(rows)
return rows
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看【用户名】、【专栏名称】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)