“养龙虾”太贵?焱融AI存储让OpenClaw Agent实现降本提效
继去年年初 DeepSeek 点燃 AI 推理浪潮之后,2026 年年初,OpenClaw 开启了 Agent 范式变革。这款图标酷似红色龙虾的开源 AI 智能体,凭借其连接 12+ 消息平台、控制浏览器、执行Shell命令、自动化处理邮件和 PPT 等全能表现,迅速引爆全球极客圈,引发“养龙虾”热潮。
然而,这场狂欢的背后,却隐藏着一个触目惊心的“成本黑洞”。一方面,OpenClaw 的 token 消耗是传统问答式对话的数十至上百倍。另一方面,为支撑庞大的上下文,GPU 显存压力巨大,算力成本飙升。
如何才能让 OpenClaw 这昂贵的“龙虾”变成真正低成本、可落地的生产力工具?本文将从 OpenClaw 的成本结构出发,深度解析焱融 YRCache 推理存储系统如何通过 AI Memory 管理,大幅降低 Agent 运行成本。
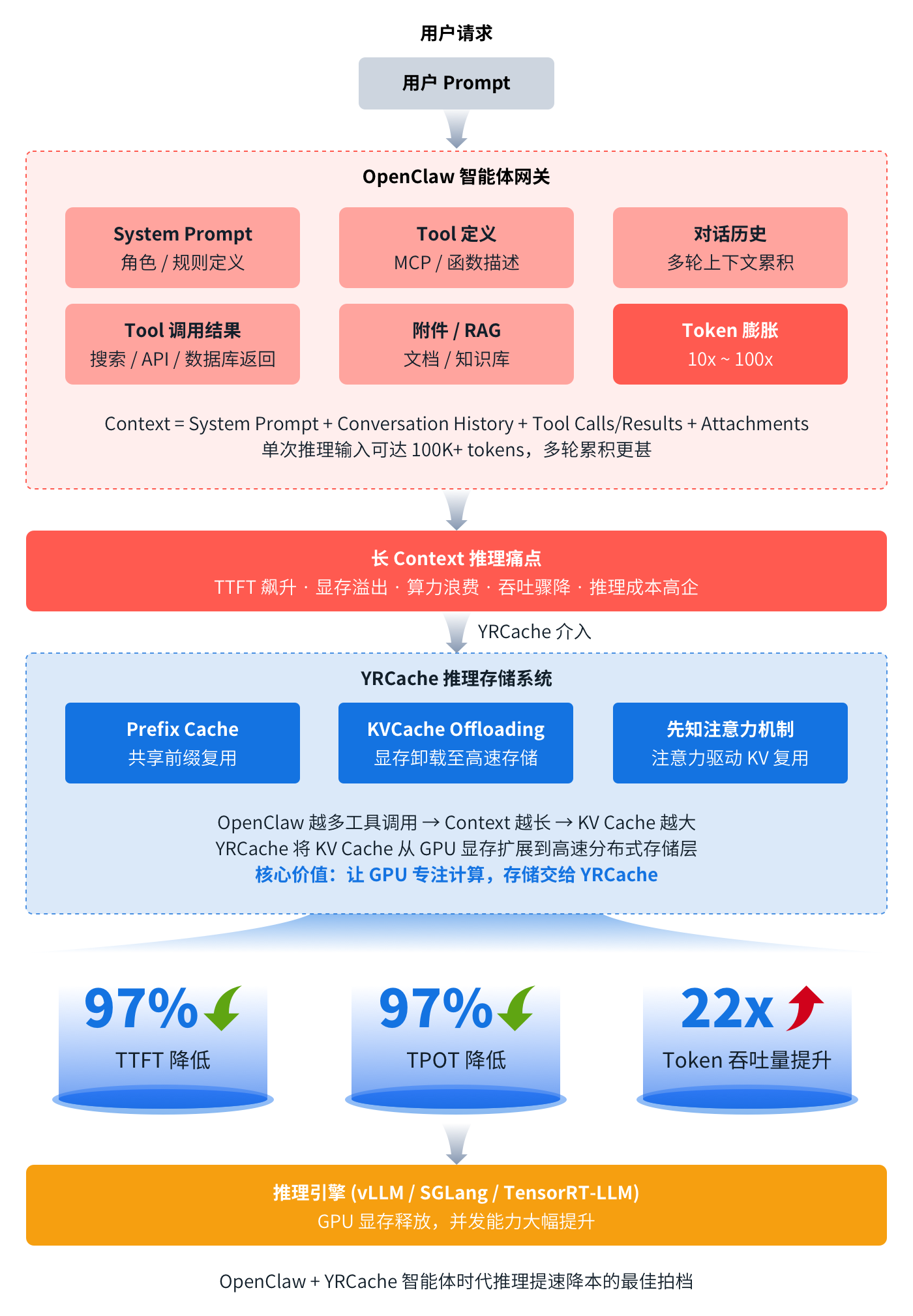
一图看懂本文核心精华,详细解读请见下文
为什么养龙虾会这么费钱?
1. OpenClaw 会消耗大量 token
与普通聊天应用不同,AI Agent 的工作模式本质上是多轮推理工作流。在传统聊天应用中,一次交互通常只有一次模型推理:
用户问题
↓
模型回答 而在 OpenClaw 中,一个任务往往包含多个推理步骤,例如:
用户请求
↓
任务规划(Planning)
↓
选择工具(Tool Selection)
↓
调用工具(Tool Call)
↓
处理结果(Observation)
↓
再次推理(Reflection)
↓
生成最终回答在实际运行中,一个任务往往需要触发 5~10 次 LLM 推理。更关键的是,每一次对大模型的调用都会重新构建一份完整的 Context(根据 OpenClaw 官方文档,Context 指的是 OpenClaw 在一次运行时发送给模型的全部信息),这意味着,用户实际上在为大量重复的信息反复支付 token 和计算成本。
从 OpenClaw 应用的角度,可以将 Context 抽象为以下公式:
其中:
- System Prompt:系统提示词。包含规则、可用工具、技能列表、时间/运行环境信息,以及注入的工作区文件。在缺乏高效缓存机制的情况下,每一次推理都在重复为这些固定内容买单。
- Conversation History:用户与助手的对话历史。在每一轮新的调用中,系统通常会将之前的聊天记录、Shell 执行结果以及 JSONL 日志等内容重新发送给模型,以保持上下文连续性。
- Tool Calls / Results + Attachments:工具调用及其结果及相关附件。为了完成任务,OpenClaw 会频繁调用各类工具,例如检索文档或网页,并将命令执行输出、读取的文件内容、图片或音频等一并纳入 Context。
上述几部分叠加,使得 OpenClaw 每一次请求都背负着巨大的 token 和算力消耗负担。同时,由于 Context 受到模型上下文窗口(token 上限)的限制,无法无限容纳所有历史信息,很快就会超出模型的处理能力,导致系统显得不那么“聪明”,使用效果大打折扣。
2. Token 背后:更大的成本来自推理记忆和算力资源消耗
为了让 Agent 始终保持高效、智能的状态,它必须依赖大量历史记忆,包括上下文信息、RAG 检索文档等。这些内容会在运行过程中不断累积,从而维持模型的推理能力和任务连续性。如果没有足够的存储空间来承载这些数据,系统往往不得不舍弃掉很多历史信息,这也使得 Agent 在长任务或多轮交互中容易出现“记性不太好”的问题。
此外,每个 Token 的生成都需消耗 GPU 计算资源,特别是在处理 Transformer 的 Attention 中间状态时。随着对话轮数增加或多会话并发运行,GPU 资源需求将迅速攀升,成为制约系统性能和扩展能力的关键瓶颈。
焱融 YRCache 推理存储系统为“养龙虾”降本增效
焱融 YRCache 推理存储系统是焱融科技自主研发、专为大规模 AI 推理场景设计的高性能存储系统。通过构建多级缓存架构,YRCache 能够显著扩展 KV Cache 的可用空间,将原本受限于 GPU 显存的缓存数据有效外延至高性能存储层,从而突破显存容量限制,在保障低延迟访问的同时大幅提升推理系统的整体效率与稳定性,为大规模推理和多会话并发提供更强的数据支撑能力。
基于 “以存代算” 的核心架构理念以及高效的 KVCache 管理机制,YRCache 可以对 OpenClaw 运行过程中产生的全部上下文数据进行高效的管理与调度,使 Agent 的历史记忆与上下文状态不再受限于模型窗口和显存容量。同时,系统能够实现上下文与 KV 数据的快速加载与复用,显著提升 GPU 利用率,减少重复计算与冗余 token 消耗,从而有效降低整体推理成本,支撑更大规模、更长周期的智能体任务运行。
-
全生命周期 Prefix Cache(前缀缓存)复用
针对固定且频繁复用的 System Prompt,将其 KVCache 结果进行持久化存储,实现一次计算、长期复用。后续推理请求可直接命中缓存,无需重复计算,从而显著降低 Token 消耗和算力开销。
-
KVCache Offloading(KVCache 卸载)
随着 OpenClaw 会话数量增加,历史上下文不断累积,KVCache 很容易溢出 GPU 显存。YRCache 通过 KVCache Offloading 技术,将 KVCache 从昂贵的 GPU 显存卸载至 CPU 内存、本地 NVMe SSD 以及 YRCloudFile 高性能共享存储,为 OpenClaw 构建一个几乎无限扩展的上下文空间。当需要时,可将相关数据快速预取回 GPU 显存,从而有效缓解显存瓶颈、硬件负载过高以及算力利用率不足等问题。
-
先知注意力机制
传统 KVCache 重用机制通常严格依赖 前缀匹配(Prefix Matching) 来实现缓存复用。只有当新请求的上下文与历史请求具有高度一致的前缀时,缓存才能被有效利用。这种机制在真实应用中往往适用范围较窄。
针对这一问题,焱融科技联合哈尔滨工业大学提出了先知注意力机制方案。该方案突破了传统前缀匹配的限制,通过计算用户查询与各数据块 Token 之间的注意力权重,识别出对当前问题最关键的 Token,仅对这些关键 Token 进行 KV 缓存重计算,而非简单依赖上下文前缀的一致性。这样既能够显著提升 KV Cache 的复用能力,又通过跨层注意力融合保证不同 Transformer 层的重要语义信息被准确捕获,从而在降低计算开销的同时,保证推理语义的准确性。
权威评测:焱融 YRCache实现推理提速降本双突破
在开放数据中心委员会(ODCC)联合 NVIDIA、焱融等发布的 KV Cache 场景评测结果中,YRCache 展现了巨大的价值:
- 性能飞跃:TTFT 和 TPOT 降低 97%,Token 吞吐量最高可提升 22 倍。
- 长上下文场景稳定增益:在输入Token从100扩展至100K的测试中,YRCache始终保持稳定性能优势,且随上下文增长加速效果持续放大。
- 中低配 GPU 推理性能追平高端卡:原生状态下中端 GDDR GPU(比如 RTX 6000D)吞吐量仅为高端 HBM GPU(比如 H20)的 30%,使用 YRCache 后两者性能均大幅提升,且差距急剧缩小,中端 GPU 可达高端 79% 的性能,ROI 提升 14 倍。
查看实测数据详情:ODCC联合NVIDIA、焱融等首发KVCache评测结果|焱融AI存储实现推理提速降本双突破
当 OpenClaw 遇到 YRCache
接下来,让我们看看在本地部署中使用 YRCache 能给 OpenClaw 等 Agent 使用降低多少成本。根据我们实际的运行情况,一个 OpenClaw Agent 助理,会话积累到 10 轮,上下文总量就达到了 100K Tokens。后续随着任务轮次的增加,上下文也在逐渐增长。这里为了简化计算和方便理解,假设后续每轮次上下文都仍为 100K Tokens,每天请求量 100 次,月请求量 3000 次,月总 Token 量 300 M。
以本次发布的 YRCache 实测数据计算:在 400Gbps 网络环境下,在使用 YRCache 前后,8 卡中端 GDDR GPU 服务器 token 吞吐量分别为 4,341 tokens/s 和 78,564 tokens/s。按照每 GPU 卡 5 万元人民币计算。

可以看到,本地部署环境下,使用 YRCache 后,OpenClaw 算力使用成本可降低 94%。对于企业而言,这不仅可以大幅降低 AI Agent 系统的基础设施投入,还能够在不增加 GPU 资源的情况下,快速扩展更多 AI 应用场景。
OpenClaw 的爆火,标志着 AI 应用正从聊天工具迈向真正的智能体系统。与此同时,Agent 架构也带来了 Token 激增与 AI Memory 膨胀等新的基础设施挑战。在 AI Agent 时代,真正决定系统成本的,不再只是算力规模,更是对 AI Memory 的高效管理能力。焱融 YRCache 推理存储系统正是对这一趋势的有力回应。对于每一个想“养好龙虾”的企业来说,记忆缓存优化不再是可选的技术手段,而是实现低成本、大规模落地Agent应用的核心标配。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)