三种窃取模型的方式
基于查询数据的类型,将窃取模型的方式分为三种:基于种子样本的攻击,基于替代样本的攻击,以及无数据的攻击。
基于种子样本的攻击:
攻击者手中没有目标模型训练时所使用的完整数据集,也无法获取目标模型的参数。但是攻击者可以:
向目标模型输入少量样本,以此获取模型给出的预测结果
攻击者的目的,就是训练一个替代模型,让他的行为尽量接近目标模型。这个替代模型不一定要和目标模型一模一样,但要保证输入相同的数据时输出的结果也要尽量一致,这相当于摸到了目标模型的决策边界。
在正常情况下攻击者没有足够的数据,怎么办?
这个时候就用到了“种子样本”,所谓种子样本,就是一小批初始输入,通常规模不大,但至少能覆盖一些基本类别特征。攻击者先用这些种子样本去查询目标模型,拿到标签,再用这些“输入—输出对”训练一个初始替代模型。但是,如果只有少量的样本显然不足以训练一个模型,于是攻击者需要做进一步的操作:
利用当前替代模型,沿着它最敏感的方向去“制造新样本”
这就是Jacobian-based Data Augmentation,也就是基于雅可比矩阵的数据扩充。
JBDA 方法(Papernot 等人,2017)
第一步:准备少量的种子样本
假设目标模型属于图片分类器,则种子样本就是一些图片。
第二步:将这些样本输入目标模型,得到输出标签,构造输入--输出对。用这些输入--输出对训练出一个效果较弱的模型。
第三步:计算替代模型的Jacobian
什么是 Jacobian
对于一个分类模型来说,输入是样本 x,输出是各类别分数 F(x)。
Jacobian 本质上描述的是:
输入的每个维度稍微变动一点,会让输出怎么变化。
写成形式就是:
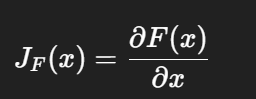
如果输入是图像,那 Jacobian 可以理解成:
-
改某个像素一点点
-
模型输出会变化多少
所以 Jacobian 反映了模型对输入各个方向的敏感程度。
第四步:利用Jacobian生成新的样本
攻击者根据 Jacobian 找到“最能影响模型判断的方向”,然后对原始种子样本做微小扰动,生成新的查询样本。
直观上就是:
把原样本沿着模型最敏感的方向轻轻推一下,得到一个新的样本。
这些新样本通常会落到原样本附近,但更有可能靠近决策边界,因此对学习模型边界特别有帮助。
第五步:再次查询目标模型,获取新样本的标签
这一步很关键,因为:新样本是攻击者自己生成的,但标签仍然来自目标模型,所以这些新增数据能不断把替代模型往目标模型的行为上拉近。
第六步:更新替代模型
把旧样本+新样本一起创新训练替代模型,这样不仅可以让替代模型知道最初几个样本该怎么分,还学到了这些样本附近区域的决策规律。
最后一步就是重复迭代
-
用当前替代模型算 Jacobian
-
生成更多新样本
-
查询目标模型
-
重新训练替代模型
每一轮都能让替代模型更接近目标模型。
JBDA之所以有效,因为它不同于简单的数据增强,只是对样本进行裁切,旋转,加噪,JBDA制造的是对模型当前的决策最敏感,最有信息量的数据,所以它生成的新样本更可能靠近分类边界。
而模型的决策边界恰恰是最难学、也最重要的部分。同时他的局限也很明显:
1.依赖初始种子样本
如果连少量种子样本都没有,就没法直接启动。
2.扩充出的样本可能不自然
Jacobian 方向生成的样本有时更像“算法探针”,不一定符合真实数据分布。
3.查询容易被检测
如果防御方发现输入中出现大量非自然、边界探索型样本,可能识别出异常行为。
4.高维复杂任务上成本更高
输入维度越高、模型越复杂,Jacobian 引导扩充的代价越大
基于替代数据的攻击
核心思想是:
攻击者拿不到目标模型的训练集,但能找到一批公开自然数据,把这些数据当作查询输入,送给目标模型拿到输出,再据此训练一个替代模型。
和“基于种子样本的攻击”相比,它不再依赖少量真实种子样本不断做对抗扩充;
和“无数据攻击”相比,它也不需要自己训练生成器造数据。
它走的是一条更现实的路线:
“没有原始训练数据没关系,互联网上有很多公开数据,我挑一些最有价值的去问目标模型。”
攻击流程:
设想目标模型为图像分类器,现在有一个该图像分类器的API。攻击者对于目标模型的训练集,内部结构,参数一概不知,但是攻击者可以输入图片查询模型的输出结果。此时攻击者的目的仍然是训练一个替代模型,尽可以还原目标模型的决策行为。而基于替代数据的方法,就是在无法获取种子样本的前提下,采用公开的数据集替代原始训练数据集。
这些公开数据可能来自:
-
ImageNet
-
COCO
-
OpenImages
-
Places
-
网络爬取图片
-
其他开源图像集
它们未必和目标模型的训练分布完全一致,但只要和目标任务有一定相关性,就可能帮助攻击者逼近目标模型。
第一步:准备一个公开的数据池
攻击者先收集一个很大的自然数据池,记作 Dpool。这个池子里的样本通常很多,而且来源公开。
关键点在于:
-
它不需要等于目标模型训练集
-
但最好和目标任务领域接近
例如目标模型是动物分类器,那么攻击者找自然图片库就会更有帮助。如果目标模型是细粒度鸟类识别器,那么找一般物体图像也能用,但效果可能差一些。
第二步:设计选取样本的策略
查询通常是有成本的:
总预算有限,每次 API 调用要花钱。
调用API有频率限制,查询过多容易被检测。
所以攻击者需要在大规模的数据池中选出最值得查询的样本。而这恰恰事替代数据攻击的核心步骤。
第三步:查询目标模型
攻击者从数据池中选出一部分样本 x,送到目标模型,得到输出 f_v(x)。输出形式可能有两种,软标签(soft label,这种信息最丰富,因为不仅知道预测类别,还知道模型的偏好程度)和硬标签(hard label)。
Soft label Hard label
返回完整概率分布,例如: 只返回最终类别,例如:
-
cat: 0.82 cat
-
dog: 0.12
-
fox: 0.04
-
wolf: 0.02
第四步:构造迁移样本集,用迁移样本集训练替代模型
迁移样本集(transfer set/transfer dataset)它是从公开数据里“迁移”过来的,用来把目标模型的知识迁移到替代模型中。攻击者用“公开数据输入 + 目标模型输出”来训练自己的模型。如果拿到的是 soft label,就可以让替代模型去拟合完整输出分布;如果拿到的是 hard label,就当作普通监督分类去训练。随着查询数据越来越多,替代模型会越来越接近目标模型。
最后重复上述步骤,
很多方法不会一次性选完样本,而是分轮进行:
-
先选一批样本查询
-
训练当前替代模型
-
评估哪些样本最有价值
-
再选新的一批去查询
-
继续训练替代模型
因此,这类攻击本质上是一个:
选样本 → 查询 → 学习 → 再选样本 的迭代过程
不同论文的主要差别,正体现在“如何选样本”上,Knockoff 方法(Orekondy、Schiele 和 Fritz,2019)利用强化学习从大规模数据池中筛选迁移样本集;ActiveThief 方法(Pal 等人,2020)采用主动学习策略;MExMI 方法(Xiao 等人,2022)则将模型窃取攻击与成员推理攻击相结合,以此提升攻击效果。
Knockoff Nets:用强化学习挑最值钱的样本,它的核心贡献是把问题明确化成:在查询预算有限的情况下,如何从大规模数据池中挑选最有价值的查询样本?
Knockoff 的流程可以理解为两层:
外层目标:训练一个替代模型去模仿目标模型。
内层策略:训练一个查询策略,决定下一次该从数据池里抽什么样的样本去问目标模型。
论文把“选择查询样本”看成一个序列决策问题:
-
当前已经查询了一些数据
-
替代模型已有一定水平
-
现在要决定下一步查询哪类数据
-
查询之后,替代模型性能可能会提升
-
这种提升就可以作为“奖励”
于是可以把样本选择策略视为一个 agent:
-
状态:当前替代模型的学习情况、已选样本分布等
-
动作:选择某个类别或某类数据去查询
-
奖励:替代模型性能的提升
换句话说,Knockoff 不只是“偷模型”,它还在学:
怎样偷,偷得最划算。
具体直观理解
假设公开数据池里有很多类图片:
-
狗
-
猫
-
汽车
-
花
-
建筑
-
食物
而目标模型可能实际上更像是一个动物识别模型。
如果攻击者不知道这一点,随机查询会浪费很多预算在建筑和食物上。
Knockoff 的强化学习策略会逐步发现:
-
查询动物类样本时,替代模型提升更明显
-
查询某些与目标任务无关的样本时,提升很小
于是它会越来越倾向于选择“高回报”的数据类别。
ActiveThief:用主动学习选“最有信息量”的样本
如果说 Knockoff 更强调“从大池子里学会挑更有收益的类别或样本”,
那么 ActiveThief 更强调一个经典思想:
优先查询当前最不确定、最有信息量的样本。
这正是主动学习(active learning)的核心。
1. 主动学习思想先讲清楚
主动学习不是随机拿数据去标注,而是挑那些:
-
最难判断的
-
最模糊的
-
最可能改变模型边界的
因为这些样本对模型学习最有帮助。
在模型窃取里,这就变成:
先用已查询数据训练一个当前替代模型,再让替代模型帮忙判断:数据池里哪些样本最值得拿去问目标模型。
2. 整个过程怎么走
ActiveThief 的过程一般可以理解成下面几步。
第一步:初始化
先从公开数据池中取一小批样本查询目标模型,得到初始迁移集。
第二步:训练初始替代模型
用这批带标签样本训练一个初始替代模型。
第三步:评估未查询样本的信息量
对还没查询过的数据池样本,利用当前替代模型做预测。这时候替代模型虽然不等于目标模型,但已经是一个近似器。攻击者可以根据替代模型的输出判断:
-
哪些样本预测最不确定
-
哪些样本处在当前决策边界附近
-
哪些样本最可能给模型带来新信息
3. 什么叫“不确定样本”
比如替代模型对一张图片的输出是:
-
cat: 0.51
-
dog: 0.49
这说明它很纠结。
而如果另一张图片输出是:
-
cat: 0.98
-
dog: 0.01
-
fox: 0.01
那说明这张图已经“很确定”了,再拿去问目标模型,获得的新信息可能不多。
所以 ActiveThief 倾向于挑前一种样本。
4. 然后做什么
挑出这些“高不确定度”的样本后:
-
送去查询目标模型
-
拿到目标模型输出
-
加入迁移样本集
-
重新训练替代模型
然后再次循环。
他和JBDA表面上两者都在“找边界附近的样本”,但来源不同:JBDA:从少量种子样本出发,通过 Jacobian 扩充出新样本。ActiveThief:直接在大规模公开自然数据池中,筛选当前最有信息量的样本。前者是“造样本”,后者是“挑样本”。
MExMI:把模型窃取和成员推理结合起来
MExMI 比前两者更进一步。
它意识到一个问题:
公开数据虽然很多,但不是所有公开数据都同样接近目标模型的训练分布。
如果能优先找到那些“更像目标训练数据”的样本,模型窃取效果会更好。
于是它引入了 成员推理攻击(Membership Inference Attack) 的思想。
1. 什么是成员推理
成员推理攻击的目标是判断:
某个样本是否曾经出现在目标模型的训练集中。
因为模型通常对训练样本和非训练样本的行为会有差异,比如:
-
对训练样本更自信
-
输出分布更尖锐
-
损失更低
-
更容易表现出过拟合痕迹
成员推理就是利用这些差异去猜:
-
这个样本像不像训练集成员
2. MExMI 的关键想法
MExMI 把这个判断用于模型窃取:
如果一个公开样本看起来“更可能属于目标模型训练分布”甚至“更像训练成员”,
那么拿它去查询目标模型,通常更有价值。
于是它不只是考虑“不确定性”或“类别收益”,还会考虑:
-
哪些样本更接近目标模型熟悉的分布
-
哪些样本更可能反映目标模型真实训练经验
3. 整体流程怎么理解
MExMI 的流程可以拆成两个交织的模块:
模块 A:模型窃取
正常进行替代模型训练:
-
从公开池选样本
-
查询目标模型
-
训练替代模型
模块 B:成员推理辅助筛选
对候选公开样本评估它们的“成员可能性”或“接近训练分布的程度”。
然后优先选择那些:
-
更可能是“成员风格”的样本
-
更接近目标模型训练分布的样本
4. 为什么这样会更有效
因为模型窃取真正需要的,不是任意自然数据,而是:
能代表目标模型决策规则的数据。
如果候选样本离目标模型训练分布太远,即便拿到标签,也可能只是在边缘区域学习,帮助有限。
而如果样本和目标模型训练分布更接近,那么目标模型在这些点上的决策更“核心”,学到的知识更有价值。接下来做一个假设,假设目标模型是一个“宠物犬品种分类器”。公开数据池里有很多图像:
-
宠物狗
-
野狼
-
狐狸
-
汽车
-
花卉
-
室内家具
随机选样本当然也能问,但效果不佳。ActiveThief 会倾向选当前替代模型最不确定的图。而 MExMI 更进一步,会想办法识别:
-
哪些图看起来更像目标模型真正训练过的那类“宠物犬分布”
-
哪些图更可能是训练分布附近的“高价值样本”
于是它会优先去查询这些样本,训练出的替代模型往往更接近目标模型。
(一)Knockoff 的完整过程 (二)ActiveThief 的完整过程
-
准备一个大规模公开数据池 准备公开数据池
-
初始化替代模型和查询策略 初始随机选一小批样本查询目标模型
-
查询策略从数据池中挑选一批样本 用返回标签训练初始替代模型
-
把这些样本送入目标模型,拿到标签 用替代模型预测未标记公开样本
-
用查询到的数据训练替代模型 计算样本不确定性或信息量
-
根据替代模型性能提升给查询策略反馈奖励 选择最有信息量的一批样本
-
查询策略更新,学会更有效地选数据 查询目标模型获取标签
-
重复迭代,最终得到高保真的替代模型 合并到迁移集,重新训练替代模型
-
多轮循环,逐步提升窃取效果
三)MExMI 的完整过程
-
准备公开数据池
-
初始选取一部分样本查询目标模型
-
训练替代模型
-
额外构建成员推理机制,评估候选样本与目标训练分布的接近程度
-
优先选取更可能属于训练分布附近的样本
-
查询目标模型得到标签
-
用新增样本继续训练替代模型
-
迭代进行成员筛选与模型更新
-
得到更贴近目标模型的替代模型
无数据攻击(Data-Free Model Stealing / Data-Free Model Extraction)
它要解决的核心难题是:
攻击者既没有目标模型的训练数据,也没有可直接利用的公开替代数据,但仍想通过查询黑盒模型,训练出一个功能接近的替代模型。
这类方法的关键突破在于:不用真实样本,而是先训练一个生成器来“造查询样本”,再用这些合成样本去查询目标模型,并和替代模型一起迭代优化。DFME、MAZE、DFMS-HL 以及后来的双学生/双模型方法,基本都围绕这个主线展开。
普通模型窃取至少还能依赖:
-
少量种子样本
-
公开自然数据
-
某种近似同分布的数据池
但在无数据场景里,这些都没有。攻击者能做的通常只有:
-
向目标模型输入一个样本
-
读到它返回的输出
-
可能是概率分布(soft label)
-
也可能只有最终类别(hard label)
-
问题是:
如果连查询样本都没有,怎么开始问?
无数据攻击的回答是:
先随机生成一些输入,再训练一个生成器,让它越来越会产生“对窃取最有用”的样本。
无数据攻击的总体流程
你可以把它理解成一个三方互动系统:
-
目标模型(victim):黑盒,只能查询输出
-
替代模型 / 学生模型(student / clone):攻击者想训练出来的模型
-
生成器(generator):专门负责产生查询样本
整个过程通常分成下面几步。
第一步:初始化两个模型
攻击者先准备:
-
一个替代模型,初始参数随机
-
一个生成器,输入噪声,输出伪样本
生成器一开始输出的样本通常很差,甚至像噪声,但没关系,它会在后续迭代中逐渐学会生成更“有信息量”的样本。
第二步:生成伪样本
攻击者给生成器输入随机向量,得到一批合成样本。如果任务是图像分类,这些输出通常是合成图像。这些样本此时不一定“自然”,但它们的作用不是给人看,而是给模型问问题:
“如果输入长这样,目标模型会怎么判断?”
第三步:查询目标模型
把合成样本送入目标模型,得到预测结果。如果目标模型返回 soft label,信息会更丰富;
如果只返回 hard label,攻击难度会明显增加,因为攻击者只能知道“它判成了哪一类”,不知道“它有多确信”。
第四步:训练替代模型
攻击者用“合成样本 + 目标模型输出”来训练替代模型,使替代模型尽量模仿目标模型在这些样本上的行为。这一步本质上就是知识蒸馏,只不过老师是一个黑盒目标模型,训练数据不是自然数据,而是生成器造出来的伪样本。
第五步:反过来更新生成器
接下来最关键:
生成器不能随便造样本,而要造“最能帮助窃取”的样本。
因此生成器会被训练去产生这样一些输入:
-
能暴露目标模型和替代模型差异的样本
-
能覆盖更丰富输入空间的样本
-
能逼近目标模型关键决策边界的样本
也就是说,生成器和替代模型是联动的:
-
替代模型越像目标模型,说明当前样本有效
-
如果替代模型和目标模型在某些样本上差异很大,这些样本就特别有价值
-
生成器会被鼓励多造这种“高价值样本”
第六步:循环迭代
然后重复:
-
生成器造样本
-
查询目标模型
-
训练替代模型
-
根据差异更新生成器
多轮之后:
-
生成器越来越擅长造“有效查询”
-
替代模型越来越接近目标模型
这就是无数据攻击的主闭环。无数据攻击的完整过程可以概括为:
攻击者首先初始化一个生成器和一个替代模型,通过生成器从随机噪声中合成伪样本,并将这些样本输入目标模型获得输出;随后使用目标模型的输出监督替代模型训练,使其逐步逼近目标模型;与此同时,再根据替代模型与目标模型之间的差异来反向优化生成器,使其持续产生更有信息量、覆盖更广的查询样本。DFME 和 MAZE 主要解决黑盒场景下生成器无法直接获得梯度的问题,因此采用梯度估计或零阶优化来更新生成器;DFMS-HL 则针对仅返回硬标签的更困难场景,通过利用替代模型梯度作为代理并增强样本多样性来维持攻击效果;进一步的双学生/双模型方法则通过两个替代模型之间的分歧来为生成器提供更稳定、更高效的探索信号,从而降低查询开销并提升窃取效率。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)