DiT原理及代码实现
DiT模型基本原理及代码实现
多模态体系知识地图
关注公众号:AI 模力圈
作者:昇腾实战派 x 哒妮滋
1 概述
DiT(Diffusion Transformer, DiT)Diffusion Transformer是一种新型的扩散模型,结合了去噪扩散概率模型(DDPM)和Transformer架构。用于图像和视频生成任务,能够高效地捕获数据中的依赖关系并生成高质量的结果。
核心思想:使用Transformer作为扩散模型的骨干网络,而不是传统的卷积神经网络(如U-Net),以处理图像的潜在表示。
2 DDPM回顾
2.1 算法整体流程

DDPM(Denoising Diffusion Probabilistic Models)是扩散模型最重要的奠基作之一,核心思想是从真实数据分布中逐渐添加高斯噪声,直到数据完全退化为标准高斯分布,然后通过一个学习到的反向过程逐步去噪,恢复出原始数据。可以被概括总结为两个步骤:
2.2 前向过程(Forward Process)
前向过程对应上图从左往右,从 x 0 x_0 x0到 x T x_T xT的过程。从真实数据出发,逐步向数据中添加高斯噪声。通过多步迭代,数据会逐渐被噪声污染,最终接近标准高斯分布$x_{T} \sim N\left ( 0,I \right ) $ 。前向过程也被称为加噪过程。
正向加噪过程目标:给图片逐步加高斯白噪声,让图片每个像素变为从均值为0,方差为1的正态分布里的采样。
一般想法:

上述加噪过程存在的问题:
- 随着 t t t的增加,均值一直为 x 0 x_{0} x0,方差一直增大。而我们希望最终$x_{T} \sim N\left ( 0,I \right ) $
- 每一步控制噪声强度的 β \beta β不变,噪声应该越加越多
加噪过程修正:
定义以下参数序列:
0 < β 1 < β 2 < β 3 < . . . < β T < 1 ( 0.0001 − 0.02 ) 0<\beta_{1}<\beta_{2}<\beta_{3}<...<\beta_{T}<1 (0.0001 - 0.02) 0<β1<β2<β3<...<βT<1(0.0001−0.02)
则一步加噪过程可以写成:
q ( x t ∣ x t − 1 ) = 1 − β t x t − 1 + β t ϵ t q\left ( x_{t}\mid x_{t-1}\right)=\sqrt{1-\beta _{t}}x_{t-1}+\sqrt{\beta _{t}}\epsilon _{t} q(xt∣xt−1)=1−βtxt−1+βtϵt
令 α t = 1 − β t \alpha_t=1-\beta _{t} αt=1−βt,则上式可以表示为:
q ( x t ∣ x t − 1 ) = α t x t − 1 + 1 − α t ϵ t = N ( x t ; α t x t − 1 , ( 1 − α t ) I ) q\left ( x_{t}\mid x_{t-1}\right)=\sqrt{\alpha_t}x_{t-1}+\sqrt{1-\alpha_t}\epsilon _{t}=N\left (x_t;\sqrt{\alpha_t}x_{t-1},(1-\alpha_t)I \right ) q(xt∣xt−1)=αtxt−1+1−αtϵt=N(xt;αtxt−1,(1−αt)I)
2.3 反向过程(Reverse Process)
反向过程对应上图中从右往左,从 x T x_T xT到 x 0 x_0 x0的过程,从纯噪声中生成数据的过程。DDPM模型通过学习如何逐步去除噪声,将噪声样本 x T x_T xT恢复为与训练数据分布 x 0 x_0 x0相似的样本,这里的转移概率通过神经网络 θ \theta θ来学习。反向过程也被称为去噪过程或采样过程。
从加噪过程中学习去噪

假设 z z z是原始图片经过前向处理后的隐向量(均值为0,方差为1的正态分布),我们的目标是通过神经网络生成的分布 P θ ( x ) P_\theta(x) Pθ(x)与原始分布 P d a t a ( x ) P_{data}(x) Pdata(x)越接近越好。
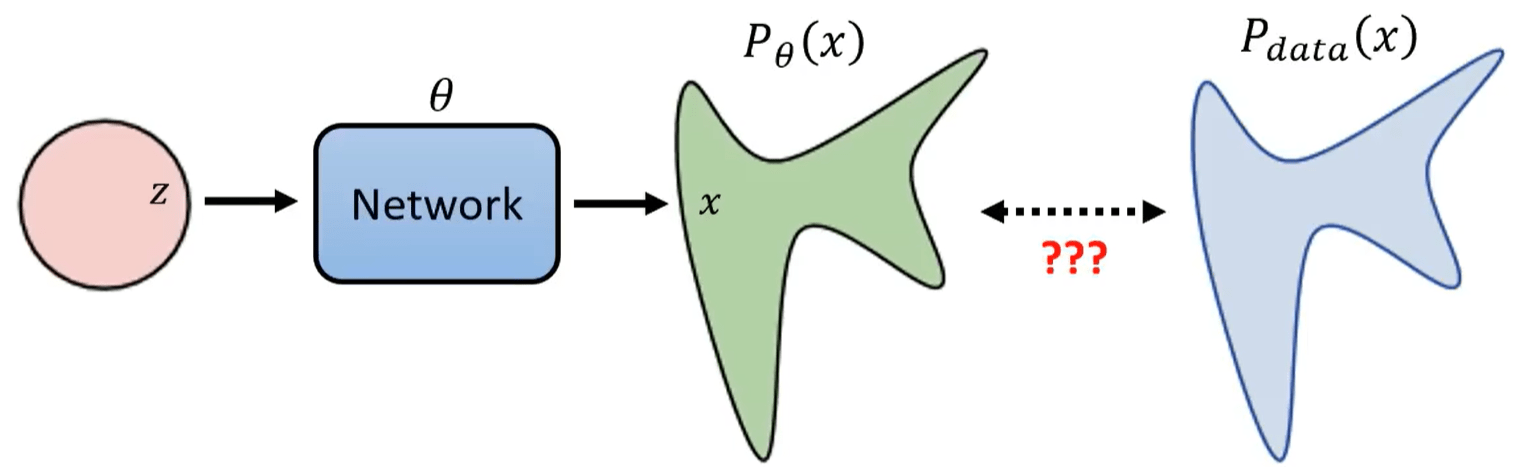
VAE回顾:Lower bound of logP(x)

类推DDPM:Lower bound of logP(x)


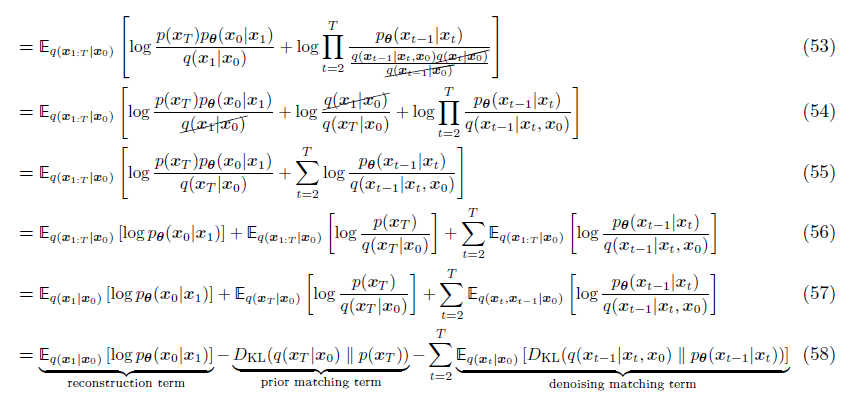
我们的目标其实是minimize公式第三项,其中
q ( x t − 1 ∣ x t , x 0 ) = q ( x t − 1 , x t , x 0 ) q ( x t , x 0 ) = q ( x t ∣ x t − 1 ) q ( x t − 1 ∣ x 0 ) q ( x 0 ) q ( x t ∣ x 0 ) q ( x 0 ) = q ( x t ∣ x t − 1 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) q\left ( x_{t-1}\mid x_{t},x_0\right)=\frac{q\left ( x_{t-1},x_{t},x_0\right)}{q\left (x_{t},x_0\right)}=\frac{q\left ( x_{t}\mid x_{t-1}\right)q\left ( x_{t-1}\mid x_{0}\right)q\left (x_0\right)}{q\left ( x_{t}\mid x_{0}\right)q\left (x_0\right)}=\frac{q\left ( x_{t}\mid x_{t-1}\right)q\left ( x_{t-1}\mid x_{0}\right)}{q\left ( x_{t}\mid x_{0}\right)} q(xt−1∣xt,x0)=q(xt,x0)q(xt−1,xt,x0)=q(xt∣x0)q(x0)q(xt∣xt−1)q(xt−1∣x0)q(x0)=q(xt∣x0)q(xt∣xt−1)q(xt−1∣x0)
由前面的推导可知,概率密度 q ( x t ∣ x t − 1 ) q\left ( x_{t}\mid x_{t-1}\right) q(xt∣xt−1)、 q ( x t − 1 ∣ x 0 ) q\left ( x_{t-1}\mid x_{0}\right) q(xt−1∣x0)、 q ( x t ∣ x 0 ) q\left ( x_{t}\mid x_{0}\right) q(xt∣x0)均是已知的,故:

训练时通过贝叶斯公式计算出 q ( x t − 1 ∣ x t , x 0 ) q\left ( x_{t-1}\mid x_{t},x_0\right) q(xt−1∣xt,x0)的均值(和方差),然后用神经网络 p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1}\mid x_{t}) pθ(xt−1∣xt)(denoise model)去拟合这个均值(和方差)。
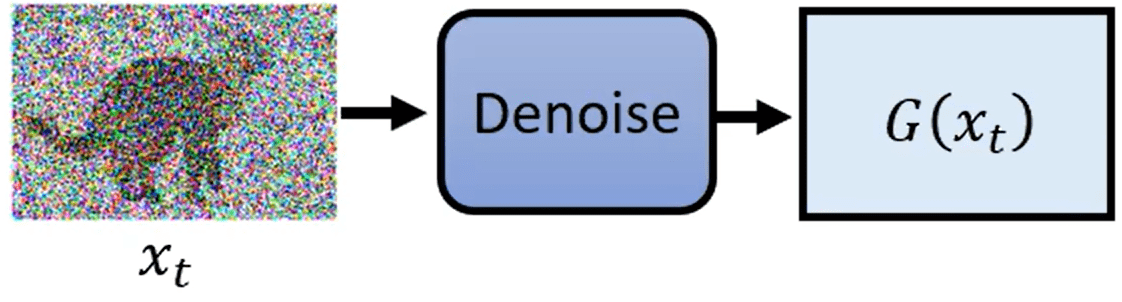

由于
x t = α ˉ t x 0 + 1 − α ˉ t ϵ x 0 = x t − 1 − α ˉ t ϵ α ˉ t x_t=\sqrt{\bar{\alpha} _t} x_0+\sqrt{1-\bar{\alpha} _t}\epsilon \\ x_0=\frac{x_t-\sqrt{1-\bar{\alpha} _t}\epsilon }{\sqrt{\bar{\alpha} _t}} xt=αˉtx0+1−αˉtϵx0=αˉtxt−1−αˉtϵ
带入上式化简后得到
α ˉ t − 1 ( 1 − α t ) x 0 + α t ( 1 − α ˉ t − 1 ) x t 1 − α ˉ t = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ ) \frac{\sqrt{\bar{\alpha}_{t-1}}(1-\alpha_t)x_0+\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})x_t}{1-\bar{\alpha}_t}= \frac{1}{\sqrt{\alpha_t}} (x_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon ) 1−αˉtαˉt−1(1−αt)x0+αt(1−αˉt−1)xt=αt1(xt−1−αˉt1−αtϵ)
由上式可以看出,实际需要denoise model来预测的就只有 ϵ \epsilon ϵ。
2.4 算法总结
2.4.1 完整训练流程

2.4.2 反向的采样算法

3 LDM:latent diffusion models
Latent diffusion models 直接在高分辨率像素空间中训练 Diffusion Model 会导致巨大的计算量。LDM[1]通过两阶段方法解决这个问题:\
- 学习一个 AutoEncoder,用学习过的 AutoEncoder E E E 将图像压缩为更小的空间表征。
- 在 z = E ( x ) z=E(x) z=E(x)而非原图 x x x上训练一个扩散模型,这个过程中 E E E 被冻结。
- 在生成新图片时,从扩散模型中采样 z z z ,再最后经过学习过的解码器解码为图像 x = D ( z ) x=D(z) x=D(z) 。
4 DiT的原理
4.1 Patchify过程
对于 256 × 256 × 3 256×256×3 256×256×3的图片, z z z 的维度是 32 × 32 × 4 32×32×4 32×32×4 。DiT 的第1步和 ViT 一样,都是把图片 Patchify,并经过 Linear Embedding,最终变为 T T T 个 d d d 维的 tokens。
token T T T 的数量由 Patch 的大小 p p p 决定。如下图1所示,Patch 的大小 p p p 和 token 的数量 T T T 之间满足 T = ( I / p ) 2 T=(I/p)^2 T=(I/p)2 的关系。当 Patch 的大小 p p p 越小时,token 的数量 T T T 越大。

4.2 DiT Block 设计
在 Patchify 之后,输入的 tokens 开始进入一系列 Transformer Block 中。除了噪声图像输入之外,Diffusion Model 有时会处理额外的条件信息,比如噪声时间步长 t t t , 类标签 c c c , 自然语言等。
**DiT架构:**基于Latent Diffusion Model(LDM)框架,采用Vision Transformer(ViT)作为主干网络,并通过调整ViT的归一化来构建可扩展的扩散模型。

DiT的核心组件DiT有三种变种形式,分别与In-Context Conditioning、Cross-Attention、adaLN-Zero相组合。
对应Diffusion Transformer模型架构图中由右到左的顺序:
- 上下文条件(In-context conditioning):这是模型处理输入数据的一种方式,允许模型根据给定的上下文信息生成输出。
- 交叉注意力块(Cross-Attention): 该模块允许模型在生成过程中关注输入数据中的特定部分,从而提高生成的准确性。
- 自适应层归一化块(Adaptive Layer Normalization, AdaLN):这是一个归一化技术,回归计算缩放参数 α , γ \alpha,\gamma α,γ和移位参数 β \beta β,有助于加速模型的训练并提高性能。
4.3 Transformer Decoder
在最后一个 DiT Block 之后,需要将 image tokens 的序列解码为输出噪声以及对角的协方差矩阵的预测结果。
而且,这两个输出的形状都与原始的空间输入一致。作者在这个环节使用标准的线性解码器,将每个 token 线性解码为 p × p × 2 C p×p×2C p×p×2C的张量,其中 C C C是空间输入到 DiT 的通道数。最后将解码的 tokens 重新排列到其原始空间布局中,得到预测的噪声和协方差。
- 最终,完整 DiT 的设计空间是 Patch Size、DiT Block 的架构和模型大小。
4.4 DiT模型配置
对于 DiT 的其他组件,可以使用Stable Diffusion预训练好的 Variational AutoEncoder (VAE) 模型。VAE Encoder 下采样率是 8:给定256×256×3的输入图片 x x x,得到的编码结果 z z z的尺寸为32×32×4。
从扩散模型中 Sample 出一个新的 latent 结果之后,使用 VAE decoder 将其解码回 pixel: x = D ( z ) x=D(z) x=D(z) 。
5 DiT Block代码实现(AdaLN)
import torch
import torch.nn as nn
import math
from timm.models.vision_transformer import Attention, Mlp
def modulate(x, shift, scale):
return x * (1 + scale.unsqueeze(1)) + shift.unsqueeze(1)
class DitBlock(nn.Mudule):
def __init__(self, hidden_size, num_heads, mlp_ratio=4.0):
super(DitBlock, self).__init__()
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
self.attn = Attention(hidden_size, num_heads=num_heads, qkv_bias=True)
self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
mlp_hidden_dim = int(hidden_size * mlp_ratio)
approx_gelu = lambda: nn.GELU(approximate="tanh")
self.mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, act_layer=approx_gelu)
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 6 * hidden_size, bias=True)
)
def forward(self, x, c):
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(c).chunk(6, dim=1)
x = x + self.attn(modulate(self.norm1(x), shift_msa, scale_msa)) * gate_msa.unsqueeze(1)
x = x + self.mlp(modulate(self.norm2(x), shift_mlp, scale_mlp)) * gate_mlp.unsqueeze(1)
return x
class FinalLayer(nn.Module):
def __init__(self, hidden_size, patch_size, out_channels):
super(FinalLayer, self).__init__()
self.norm_final = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
self.linear = nn.Linear(hidden_size, patch_size * patch_size * out_channels, bias=True)
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 2 * hidden_size, bias=True)
)
def forward(self, x, c):
shift, scale = self.adaLN_modulation(c).chunk(2, dim=1)
x = self.linear(modulate(self.norm_final(x), shift, scale))
return x
如果你对多模态大模型、强化学习、昇腾 NPU 部署、模型性能优化感兴趣,欢迎持续关注【AI模力圈】。
我们会持续更新:
- 多模态模型结构拆解
- 强化学习算法原理与实践
- 昇腾 NPU 迁移部署与踩坑复盘
- 模型训练与推理性能优化
图解版、速读版内容也会同步更新到公众号 / 小红书。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 30
30 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)