大模型面试第二期:层归一化篇
这里讲解依旧以底层堆积木的方式来讲解,这样理解更深,记忆更牢。因为有些人特爱拽几句英语,所以我还是会把重要名词用英语翻译出来。
第一题:讲解一下Layer norm?
在这里一般会问你:
1.Layer norm公式是什么?
2.Layer norm用处是什么?
3.Layer norm最后一步的缩放和平移的作用是什么?
大家看完讲解之后尝试解答一下以上问题。
讲解:
在大语言模型(LLM)中,层归一化(Layer Normalization,简称 Layer Norm) 是一个至关重要的组件。它的主要作用是稳定深度神经网络的训练过程,防止数值爆炸或消失,并加速模型的收敛。
在像 Transformer 这样的深层网络中,如果没有归一化,随着层数的加深,数据分布会发生剧烈的偏移(内部协变量偏移),导致模型极难训练。
一、 Layer Norm 的核心原理
在自然语言处理中,输入序列的每一个词(Token)都会被映射成一个高维向量(例如维度 H = 4096)。
Layer Norm 的特点是:它独立地对“每一个词”的特征向量进行归一化。 它不在不同样本之间(Batch)做计算,而是在同一个词的特征维度(Feature Dimension)上做计算。
Layer Norm 的计算分为四个步骤:
-
计算均值 (Mean): 计算该词汇向量中所有特征值的平均数。
-
计算方差 (Variance): 计算该向量中所有特征值偏离均值的程度。
-
标准化 (Standardization): 将原向量的每个元素减去均值,并除以标准差(方差的平方根)。这里会加上一个极小的常数
(如
),防止分母为零。
经过这一步,向量的数据分布会被强行拉回到均值为 0、方差为 1 的标准状态。
-
缩放和平移 (Scale and Shift): 标准化可能会破坏模型原本学到的特征表示。因此,Layer Norm 引入了两个可训练的参数:缩放因子
(Gamma) 和平移因子
(Beta)。
这两个参数允许模型在需要的时候,将归一化后的数据再还原或映射到更有利于下一层计算的分布状态。
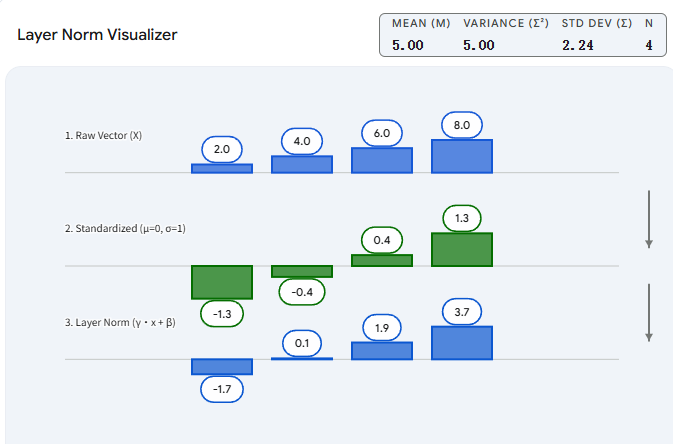
二、 具体实例拆解
假设我们有一个非常迷你的 LLM,它的隐藏层维度(特征数)只有 。
输入了一句话中的某个词(比如“猫”),该词经过上一层网络后,得到的基础向量是:
我们来看看 Layer Norm 是如何处理这个向量的(为了方便计算,忽略 ):
第一步:计算均值 ()
-
5.0
第二步:计算方差 ()
-
分别计算每个元素与均值的差的平方:
-
-
方差
5.0
-
标准差
2.236
第三步:标准化 ()
将原向量的每个元素减去 5.0,再除以 2.236:
-
-1.342
-
-0.447
-
0.447
-
1.342
此时,新的向量变成了 [-1.342, -0.447, 0.447, 1.342]。如果你去计算这个新向量,会发现它的均值变成了 0,方差变成了 1。
第四步:缩放和平移 ()
假设模型在训练过程中,针对这一层学到的参数是 ,
。
-
-1.342
-
0.106
-
0.447
-
1.684
最终输出的向量就变成了 [-1.342, 0.106, 0.447, 1.684],随后这个向量会被送入下一层(比如自注意力机制层)。
三、 为什么 LLM 偏爱 Layer Norm?
-
不受序列长度限制: 在 NLP 任务中,句子的长度是动态变化的(Batch 中的样本长度不一)。Batch Normalization 在处理变长序列时非常麻烦,而 Layer Norm 是针对单个 Token 的特征维度进行操作的,完美契合文本数据。
-
更稳定的前向传播: 无论前一层的输出值变得多大或多小,Layer Norm 都会将其强行“拽回”合理的区间,防止在多层叠加后发生数值溢出。
第二题:讲解一下RMS Nrom
在这里一般会问你:
1.RMS Nrom公式是什么?
2.RMS Nrom对比Layer升级了什么?
试着看完讲解后回答以上问题
讲解:
一、 RMSNorm 的核心原理
RMSNorm 的作者(Biao Zhang 和 Rico Sennrich 在 2019 年提出)发现了一个现象:在 Layer Norm 中,真正起关键作用的是缩放(缩减方差),而平移(减去均值)的作用其实微乎其微。
因此,RMSNorm 做了一个极其大胆的简化:直接假设均值为 0,也就是彻底砍掉了计算均值和减去均值的步骤!
它的计算过程缩减为了三步:
-
计算均方根 (Root Mean Square, RMS): 直接把向量中每个元素的平方加起来求平均,然后再开根号。这里同样会加上一个小常数
-
标准化 (Standardization): 用原向量的每个元素,直接除以算出来的 RMS。
-
缩放 (Scale): 就像去掉了均值计算一样,RMSNorm 通常也抛弃了平移参数
优势总结: 计算量显著变小了(少了均值计算、减法操作和加法平移),在保证模型训练效果几乎不下降的前提下,计算速度提升了大约 10% 到 50%。这对于动辄千亿参数的大模型来说,是极其宝贵的性能提升。
二、 具体实例拆解
为了让你清晰地看出它和 Layer Norm 的区别,我们依然使用上一局的那个迷你向量:
,隐藏层维度
。
(同样,为了方便计算,忽略极小的 )
第一步:计算均方根 (RMS)
-
先算平方和:120.0
-
算均方 (Mean Square):30.0
-
开根号算 RMS: 5.477
(对比一下:刚才 Layer Norm 算出来的标准差是 2.236,这里算出来的 RMS 是 5.477)
第二步:标准化 ()
直接用原向量的每个元素除以 5.477:
此时,新的向量变成了 [0.365, 0.730, 1.095, 1.461]。
第三步:缩放 ()
假设模型学到的缩放参数 依然是
。注意,RMSNorm 一般没有平移参数
了。
最终输出的向量就变成了 [0.365, 1.460, 1.095, 2.922]。
通过这两步拆解,你应该能发现:Layer Norm 是精细调节(考虑均值),而 RMSNorm 是粗暴缩放(只管数值大小),但在高维空间中,后者的“性价比”高得多。
第三题:讲解一下Deep Norm
在这里一般会问你:
1.Deep Norm 公式是什么?
2.Deep Norm有什么优点?
讲解:
如果说 Layer Norm 和 RMSNorm 是解决“单层”数据分布的问题,那么由微软在 DeepNet 中提出的 DeepNorm,就是为了解决“极深网络”(例如高达 1000 层的大模型)如何稳定叠加的世界级难题。
它和前两者有一个本质的区别:Layer Norm 和 RMSNorm 是底层的数学计算方式,而 DeepNorm 更像是一种架构层面的“统筹策略”,它修改了 Transformer 的残差连接(Residual Connection)和参数初始化。
一、 为什么需要 DeepNorm?
在 Transformer 中,为了防止信息在层层传递中丢失,每一层都有一个“残差连接”(直接把上一层的输入加到这一层的输出上)。在 DeepNorm 出现之前,主流模型分为两派:
-
Post-Norm(后归一化,原版 Transformer): 先把输入和这一层的计算结果相加,再做归一化。它的效果上限极高,但极难训练,层数一多就容易发生梯度爆炸(也就是楼塌了)。
-
Pre-Norm(前归一化,GPT、LLaMA 的选择): 先做归一化,再进网络层计算,最后再相加。它极度稳定,但牺牲了部分效果,在极其深的网络中,早期层的作用会被无限稀释。
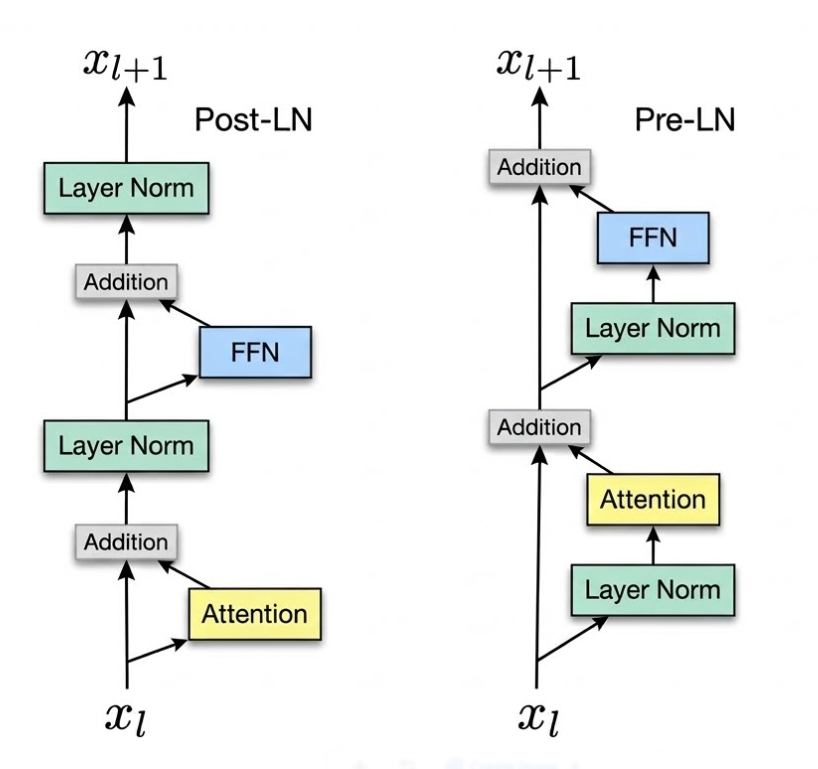
微软想要一种“既要稳定,又要极限性能”的方案,于是通过严密的数学推导,发明了 DeepNorm。
DeepNorm 的核心公式非常简单,它基于 Post-Norm 修改而来:
它做了两件极其巧妙的事(一放大,一缩小):
-
放大残差(乘
):
加给新层
之前,强行把上一层的信息放大
-
缩小新层(用
时,将新网络层(如注意力层和前馈层)的权重按照一个小于 1 的常数
这里没有的原因是
其实是一个初始化缩放因子(Initialization Scaling Factor)。
在模型开始训练之前(也就是 epoch 0 的时候),程序会对网络中所有新层 (比如注意力机制和前馈网络)的权重矩阵(Weight Matrices)进行一次干预。
普通的 Transformer 初始化可能就是在一个标准正态分布里随机取值。但在 DeepNorm 中,初始化代码是这样的(伪代码):
# 假设 W 是刚刚随机初始化出来的原始权重矩阵
W_standard = random_normal(mean=0, std=sigma)
# DeepNorm 会在它出生的这一刻,强行给它乘上 beta
W_deepnorm = W_standard * betaDeepNorm 的作者之所以选择在“初始化”时动手脚,而不是在“前向计算”时加个乘法,是因为这样计算效率更高。既然权重要在训练中不断更新,不如直接给它一个极小的起点( 缩放),让模型自己慢慢往大学,省去了每次前向传播都要多做一次乘法的算力开销。
不过后面的实例我为了更清晰,还是以前向乘法为例。
因为矩阵乘法有一个性质:如果你把网络层里面所有的权重参数 都提前缩小了
倍,那么当输入
乘进去之后,它计算出来的输出结果
,自然在初始阶段也就约等于原来未缩放时输出结果的
倍。
二、 具体实例拆解:
我们来做一个极其直观的对比。
假设当前的输入向量依然是:
(这是一个带有明显递增趋势的特征)
假设这一层网络(比如自注意力机制层)计算出的原始更新向量是:
(它试图打破刚才的递增趋势)
A:如果使用传统的 Post-Norm
-
直接相加:
-
计算均值
,计算方差
,标准差
。
-
归一化输出:
[-1.0, -1.0, 1.0, 1.0]
仅仅过了一层,原来 中
阶梯状的细腻特征,被
的粗暴干扰直接抹平了,变成了绝对的方块波。如果这种扰动叠加 1000 次,模型就彻底崩溃了(梯度爆炸)。
B:如果使用 DeepNorm(放大与缩小)
假设这是一个很深的网络,DeepNorm 算出的常数是 (放大历史),
(新层初始化缩小一半,因此新层的输出也减半)。
放大残差:
缩小新层输出:
两者相加:
进行 Layer Norm:
-
算均值
-
算方差
-
标准差
-
归一化输出:
[-1.287, -0.585, 0.585, 1.287]
DeepNorm 输出的向量,不仅加入了新特征(数字的间距有了微小波动),而且完美保留了原来向量递增的趋势。这就保证了哪怕再堆叠 1000 层,数据也不会“突变失控”。
第四题:不同位置的Norm有什么区别?
问题:
1.说一下不同位置的归一化区别
2.现在主流用的什么位置的Norm
3.为什么主流都用Pre-norm,他有什么缺点或者优点?
解析:
在大模型的架构设计中,Layer Norm 放哪里,往往决定了一个大模型“能不能训练得起来”以及“能叠多深”。
为了让你直观地理解,我们可以把 Transformer 模型想象成一条主干道(残差流,Residual Stream),而每一层网络(如自注意力机制层、前馈网络层)就是建在主干道旁边的加工厂(Sublayer)。数据在主干道上跑,时不时进入加工厂处理一下,再合并回主干道。
Norm 层就像是收费站兼整流站。它放在哪里,直接决定了交通状况。
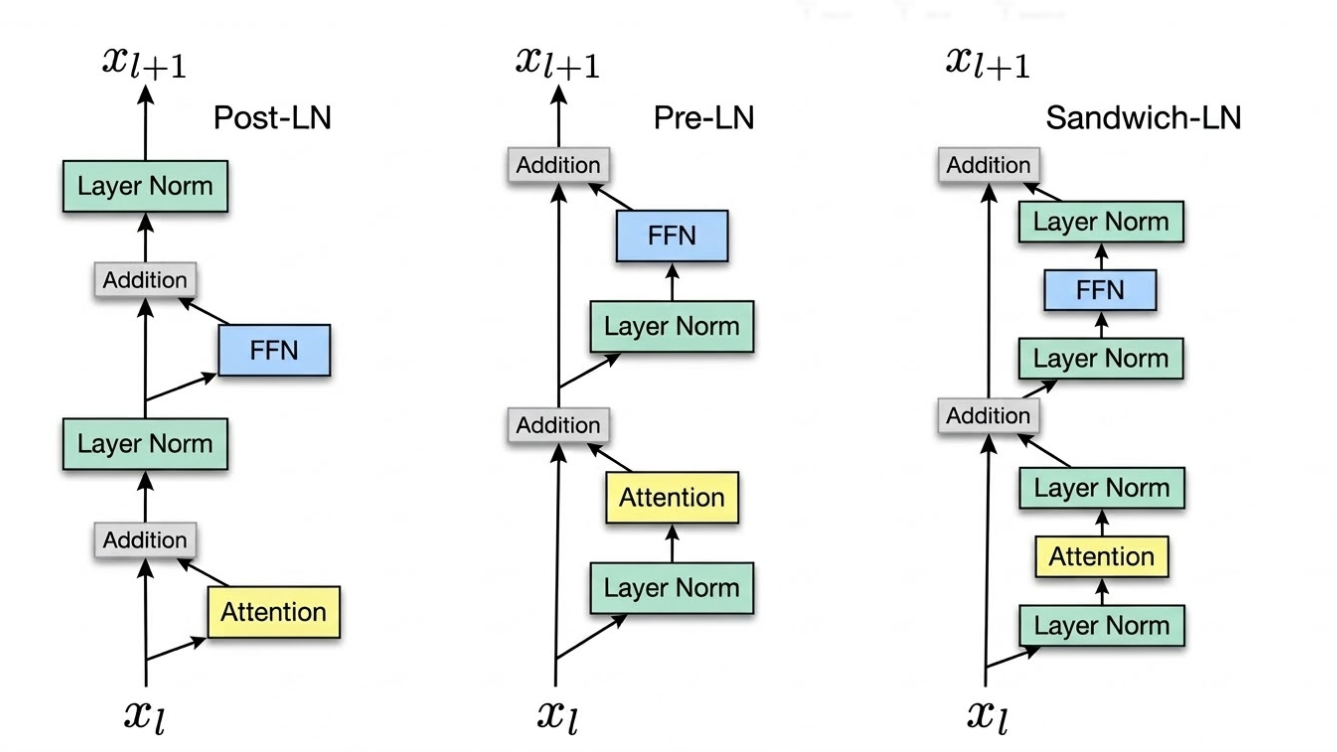
我们来看看这三种主流架构的区别:
1. Post-Norm(后归一化):
这是 2017 年那篇经典的《Attention Is All You Need》最初提出的原始设计。
-
公式:
-
交通图景: 数据
-
优势(天花板高): 因为每一次更新主干道的数据后,都会被强制拉回到均值 0、方差 1 的标准状态,所以模型每一层的输出都非常规矩。理论上,它的表达能力和最终性能上限是最高的。
-
致命缺陷(极难训练): 由于每次都在主干道上做非线性的归一化,导致反向传播时,梯度(误差信号)很难顺畅地从最后一层传回第一层。层数一多,底层的参数就收不到更新信号了(梯度消失)。为了防止训练初期模型崩溃,它必须搭配非常精细的“学习率预热(Warm-up)”策略。
2. Pre-Norm(前归一化):
因为 Post-Norm 太难伺候了,后来的研究者(如 GPT 系列、LLaMA、Qwen 等绝大多数现代 LLM)全部倒戈,改用了 Pre-Norm。
-
公式:
-
交通图景: 收费站从主干道上撤掉了,挪到了加工厂的“入口处”。 数据要进工厂处理前,先做一次归一化;但主干道 (
-
优势(稳如老狗): 这是它一统天下的原因。因为主干道上没有任何阻拦,梯度可以直接“一镜到底”从第 100 层瞬间传回第 1 层。模型极度容易训练,甚至不需要预热也能收敛。
-
隐蔽缺陷(表征坍塌): 既然主干道上没有收费站整流,随着层数加深,主干道上的数值累加得越来越大(方差越来越大)。到了极深的网络层,工厂里加工出来的那点“小数据”,加到数值巨大的主干道上,就像往海里滴了一滴水,根本激不起波澜。这就导致极深层的网络其实在“偷懒”,对模型的贡献度急剧下降。
3. Sandwich-Norm(三明治归一化):双重保险
这个结构主要由清华大学在多模态大模型 CogView 中提出,后来也被应用在一些对数值稳定性要求极高的模型(如 Gemma 的某些变体)中。
-
公式:
-
交通图景: 结合了 Pre-Norm 的畅通主干道,但在加工厂的“入口”和“出口”各设了一个收费站。
-
为什么需要它? 在训练多模态模型(比如文字 + 图像)或者使用 FP16 半精度训练时,经常会出现数据突变。加工厂(Sublayer)由于见到了奇怪的数据,可能会突然输出一个极其巨大的异常值。如果按照 Pre-Norm 的做法,这个巨大的异常值会直接加到主干道上,导致整个大模型瞬间崩溃(Loss 变成 NaN)。
-
优势: Sandwich-Norm 在出口处再做一次归一化(
),死死地压制住了加工厂输出的数值范围。哪怕工厂内部爆炸了,出来的数值也是温和的。这让大模型在面对极其复杂的异构数据时,依然能保持训练不崩。
-
缺陷: 计算量变大了(多了一倍的 Norm 计算),而且有时因为限制得太死,可能会略微降低模型捕捉极端特征的能力。
| 对比维度 | Post-Norm (后归一化) | Pre-Norm (前归一化) | Sandwich-Norm (三明治) |
| 主干道是否畅通 | 否(有 Norm 阻拦) | 是(完全畅通) | 是(完全畅通) |
| 训练稳定性 | 极差(易梯度消失/爆炸) | 极好(无需 Warm-up) | 最优(防异常值爆炸) |
| 深层网络利用率 | 较高 | 较低(存在表征坍塌) | 中等 |
| 代表模型 | 原始 Transformer | GPT-3, LLaMA, Qwen 等 | CogView, 部分多模态模型 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 27
27 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)