【机器学习】基本概念
人工智能,机器学习,深度学习
人工智能(AI):计算机科学的一个广泛领域,目标是让机器具备类人的“智能”,包括自然语言处理(NLP)、计算机视觉、机器人技术、专家系统等等;具体实现手段多种多样,包括规则系统、符号逻辑、统计方法、机器学习等。
机器学习:AI的一个子领域,核心是通过数据驱动,让计算机进行学习并改进性能,自动发现规律(模式),并利用这些规律进行预测或决策。
深度学习:机器学习的一个子领域,基于多层神经网络处理复杂任务。
机器学习应用领域
最主流、高频领域:
- 计算机视觉Computer Vision (CV):人脸识别、图像分类、目标检测、OCR 文字识别
- 自然语言处理Natural Language Processing (NLP):聊天机器人、翻译、文本分类、摘要、情感分析
- 推荐系统Recommendation System:短视频 / 电商 / 音乐 平台“猜你喜欢”
- 语音识别与合成Speech Recognition & Synthesis:语音转文字、语音播报、虚拟人声
- 数据挖掘与预测Data Mining & Prediction:销量预测、用户流失预测、异常检测
行业落地场景
- 金融Finance:风控(risk control)、反欺诈(anti-fraud)、信用评分(credit scoring)
- 医疗Healthcare:病灶检测(lesion detection)、辅助诊断(auxiliary diagnosis)、药物研发(drug discovery)
- 自动驾驶Autonomous Driving:感知(perception)、决策(decision)、规划(planning)
- 安防Security:行为分析(behavior analysis)、入侵检测(intrusion detection)
- 工业Industry:质检(quality inspection)、故障预测(fault prediction)、能耗优化(energy optimization)
- 教育Education:智能批改(intelligent grading)、个性化学习(personalized learning)
机器学习基本术语
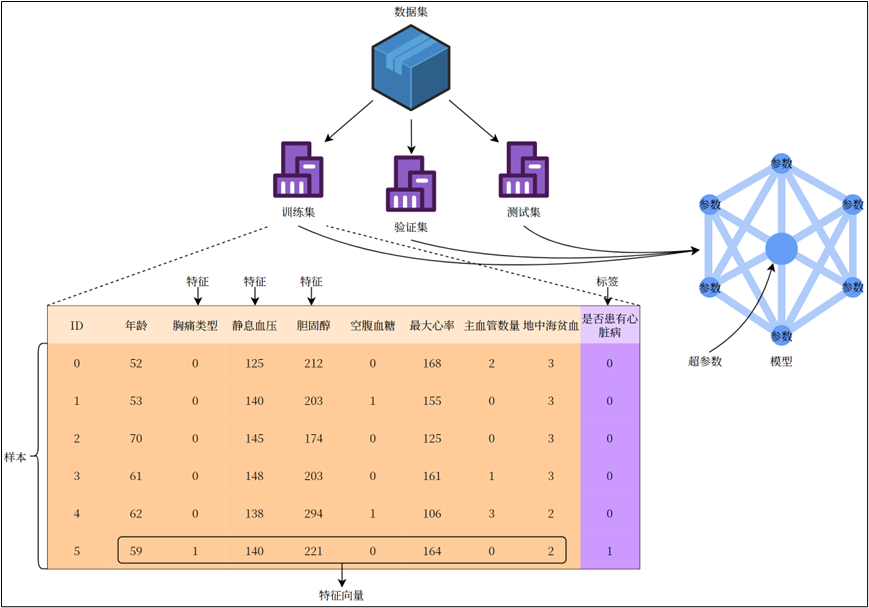
🍪数据集(Data Set):多条记录的集合。
- 训练集(Training Set):用于训练模型的数据。
- 验证集(Validation Set):用于调节超参数的数据。
- 测试集(Test Set):用于评估模型性能的数据。
🍪样本(Sample):数据集中的一条记录是关于一个事件或对象的描述,称为一个样本。
🍪特征(Feature):数据集中一列反映事件或对象在某方面的表现或性质的事项,称为特征或属性。
🍪特征向量(Feature Vector):将样本的所有特征表示为向量的形式,输入到模型中。
🍪标签(Label):监督学习中每个样本的结果信息,也称作目标值(target)。
🍪模型(Model):一个机器学习算法与训练后的参数集合,用于进行预测或分类。
🍪参数(Parameter):模型通过训练学习到的值,例如线性回归中的权重和偏置。
🍪超参数(Hyper Parameter):由用户设置的参数,不能通过训练自动学习,例如学习率、正则化系数等。
机器学习三要素
机器学习的方法一般主要由三部分构成:模型、策略和算法,可以认为:
机器学习方法 = 模型 + 策略 + 算法
- 模型(model):总结数据的内在规律,用数学语言描述的参数系统
- 策略(strategy):选取最优模型的评价准则
- 算法(algorithm):选取最优模型的具体方法
机器学习方法分类
机器学习最主流分类方式是按学习范式分类,分为以下几类:
1. 监督学习(Supervised Learning)
- 核心:有标签 / 标准答案,模型学 “输入→输出” 映射
- 典型任务:
- 分类:图片分类、文本情感分类、垃圾邮件识别
- 回归:房价预测、销量预测、股价预测
- 代表算法:逻辑回归、SVM、决策树 / 随机森林、XGBoost、CNN、RNN、Transformer
2. 无监督学习(Unsupervised Learning)
- 核心:无标签,模型学数据本身的结构、分布、模式
- 典型任务:
- 聚类:用户分群、图像分割、异常检测
- 降维:PCA、特征提取、可视化
- 密度估计 / 生成:学习数据分布
- 代表算法:K-Means、DBSCAN、PCA、AutoEncoder、GMM
3. 半监督学习(Semi-supervised Learning)
- 核心:少量标签 + 大量无标签,用无标签数据提升泛化
- 适用:标注成本高(医疗、金融、语音)
4. 强化学习(Reinforcement Learning)
- 核心:智能体与环境交互,通过奖励 / 惩罚学习最优策略
- 典型任务:游戏 AI、机器人控制、推荐系统排序、自动驾驶决策
- 代表:DQN、PPO、A3C、AlphaGo 系列
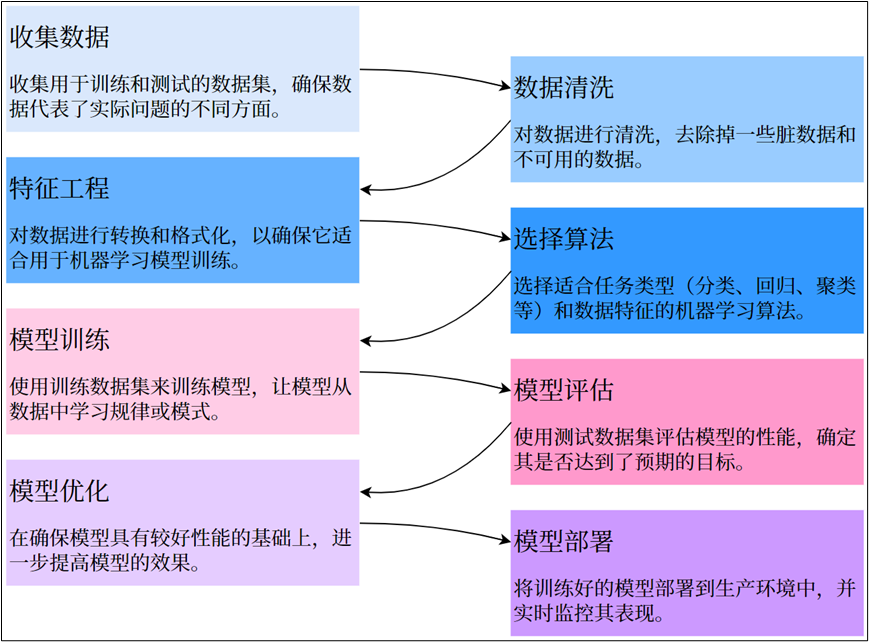
机器学习建模流程

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)