人大高瓴孙浩团队发表Nature子刊封面文章:基于并行符号枚举的物理定律发现

近期,中国人民大学高瓴人工智能学院孙浩教授团队在Nature子刊《自然-计算科学》(Nature Computational Science)发表了题为“Discovering physical laws with parallel symbolic enumeration”的研究论文,论文被该期刊选为2026年首期封面文章(Volume 6,Issue 1)。

引用格式: Ruan, Kai, et al. "Discovering physical laws with parallel symbolic enumeration." Nature Computational Science (2025): 1-14.
一、摘要
这篇论文聚焦于符号回归这一重要方向。所谓符号回归,就是不给定固定模型形式,而是直接从数据中自动发现简洁、可解释的数学表达式。论文指出,传统符号回归长期面临两个核心瓶颈:一是搜索空间近乎无限,容易发生组合爆炸;二是候选表达式的评估效率低,导致复杂问题上准确率和速度都受限。为了解决这一问题,作者提出了PSE(Parallel Symbolic Enumeration,并行符号枚举)框架,用于从有限数据中高效提取通用数学表达式。其核心思想是:通过 PSRN(Parallel Symbolic Regression Network) 识别不同表达式之间共享的公共子树,并结合 GPU 并行计算,实现海量候选公式的同时评估。实验表明,PSE 在 200 多个合成与实验问题上,相比现有先进方法取得了更高的恢复精度和更快的计算速度,最高可将恢复率提升至接近 99% 的增益,并把运行时间降低一个数量级。
二、研究背景
1. 为什么要研究符号回归
在科学研究中,很多时候我们真正关心的不是“预测值是多少”,而是“这个系统背后的规律是什么”。传统回归方法通常只能在模型结构已知的前提下估计参数,而当底层数学结构未知时,这类方法就无能为力。符号回归的价值就在于,它能在不预设函数形式的条件下,直接从观测数据中提炼可解释的公式,因此在天文学、材料科学和物理规律发现等领域都很重要。
2.现有方法的主要问题
论文回顾了几类主流方法。
第一类是 遗传编程(GP) 和贝叶斯方法,它们通过启发式搜索在表达式空间中寻找候选公式。这类方法虽然有效,但普遍存在可扩展性差、对超参数敏感、容易生成复杂且过拟合的表达式等问题。
第二类是 SINDy一类稀疏回归方法。它们把方程发现转化为预定义函数库上的稀疏线性回归问题,因此速度很快,也能找到较简洁的模型。但问题在于:它们的发现能力高度依赖人工设计的函数库,而且本质上局限在线性组合框架内,当真实关系超出库的表达能力时,就很难恢复正确规律。
第三类是近年来兴起的 深度符号回归方法,比如基于 RNN、VAE、图网络、Transformer 或符号神经网络的方案。论文指出,这些方法虽然很有潜力,但常常依赖经验性阈值来做表达式简化,在小样本、有噪声的数据场景下,容易得不到真正有意义的公式。
此外,MCTS也被用于符号回归搜索,但传统做法往往把搜索树中的每个节点映射到唯一表达式,这种一对一映射会限制搜索效率,不利于快速恢复正确的符号表达。
3.真正的瓶颈在哪里
作者最核心的判断是:符号回归之所以难,不只是因为“不会搜索”,更因为候选表达式的评估效率太低。符号回归本身是 NP-hard 问题,表达式由变量、算子和常数组成,搜索空间巨大。现有方法大多把每个候选表达式独立评估,即便某些表达式共享中间子结构,也无法重复利用这些计算结果,造成了严重的重复开销。论文认为,如果能显著提升候选表达式的评估效率,就有机会同时提高恢复率并减少计算时间。
三、研究方法
1. 整体框架:PSE
针对上述问题,论文提出了 PSE(并行符号枚举)。它的目标是:在有限数据上高效评估大量候选表达式,并尽可能直接找到正确的、可解释的数学结构。PSE 的核心搜索引擎是 PSRN,同时还结合了一个 token generator,如 GP 或 MCTS,用来生成更有希望的子表达式作为后续搜索的起点。token generator负责提出“值得继续探索的构件”;PSRN负责对这些构件进行大规模并行扩展和评估。
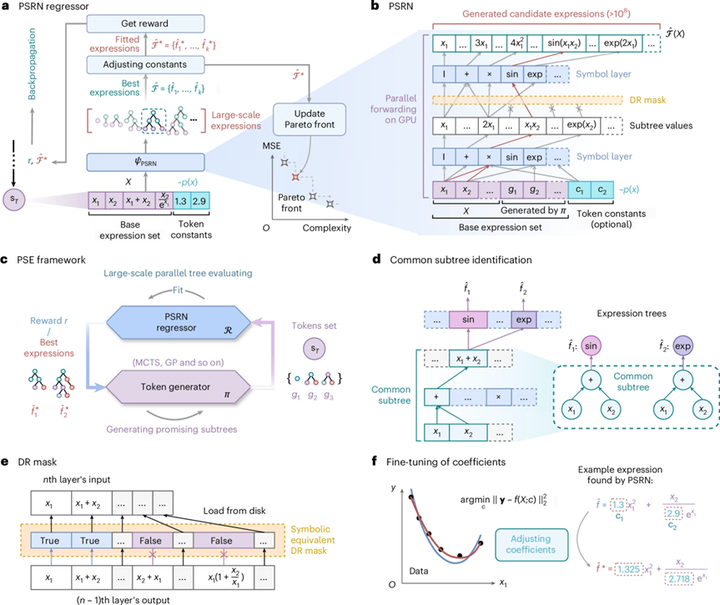
2. PSRN 的核心思想:公共子树复用
PSRN 最关键的创新,是能自动识别不同表达式之间的公共子树,并共享这些子树的计算结果。比如sin(x1+x2)和 exp(x1+x2)都包含 x1+x2这一子结构,传统方法通常会分别重复计算,而 PSE 则只算一次,再把结果复用到多个表达式中。论文把这一机制视为加速的核心。
这一点非常重要,因为在真实符号搜索中,大量候选表达式都共享局部结构。谁能更好地复用这些中间结果,谁就真正具备大规模搜索的能力。
3. Symbol layer:逐层生成表达式
PSRN 由多个symbol layer叠加而成。每一层不是普通神经网络那种学习特征的层,而更像一个“表达式组合层”:它会把输入表达式按照指定算子进行单步组合,从而生成新一层的子树值。这样逐层展开以后,就能构建出深度更高、结构更复杂的大量候选表达式。论文指出,若有l层 symbol layer,那么 PSRN 就能生成所有深度不超过l的表达式树。
4. GPU并行评估
PSRN的另一个关键点是 GPU 并行。在前向传播过程中,网络会对海量表达式同步计算其在数据上的数值结果,而不是像传统方法那样一个个试。论文指出,PSRN 可以一次评估数亿个候选表达式,这使得它能够直接、大规模地覆盖搜索空间。
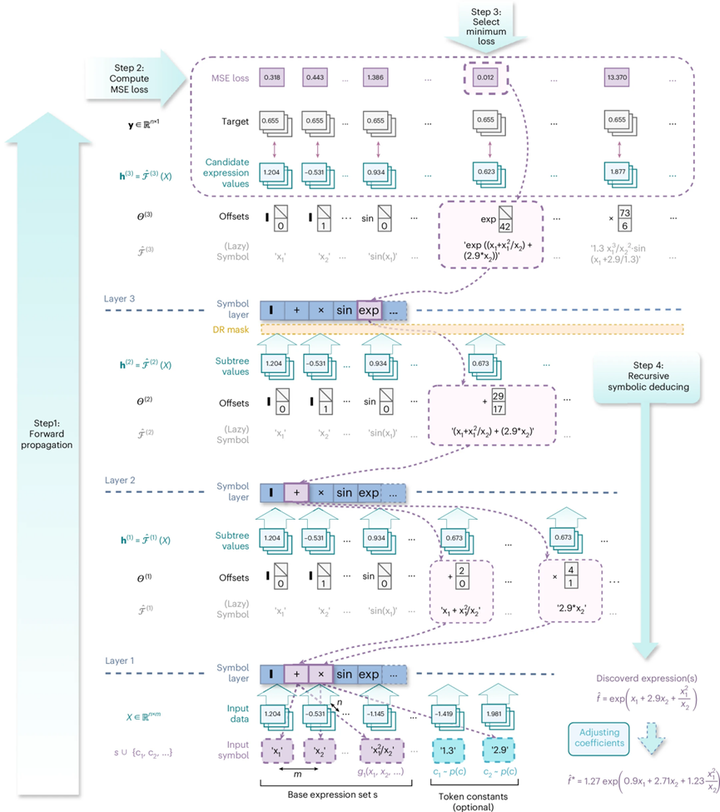
5. PSRN 的具体求解流程
图 2 给出了完整流程,大体可以概括为四步:
第一步,把输入数据X、基础表达式集合s和可选常数 token 输入 PSRN,逐层生成大量子树值;第二步,将最终层输出与目标y比较,计算每个候选表达式的 MSE;第三步,找到误差最小的位置;第四步,利用构网时保存的 offset tensor递归回溯,恢复出对应的最优符号表达式;必要时再进行系数微调。
PSE 的思路并不是“先写出每个公式再逐个评估”,而是“先批量算出大量表达式在数据上的行为,再从最优索引反推公式”。
6. DR mask:去掉重复表达式
为了减少显存占用,作者还设计了DR mask(duplicate removal mask)。它作用在倒数第二层输出上,用于过滤掉那些符号上等价的重复子表达式,从而降低 GPU 内存消耗。论文指出,这种设计能显著减少内存占用,提升模型处理更复杂表达式的能力。
7. 系数后处理:先找结构,再调参数
PSE 并不强求在结构搜索时同时精确确定常数,而是先找到表达式结构,再通过最小二乘法对系数进行识别和微调。这种“结构搜索—参数优化”分离的思路,可以有效降低搜索难度,同时提升最终公式的精度和可解释性。
四、研究结果
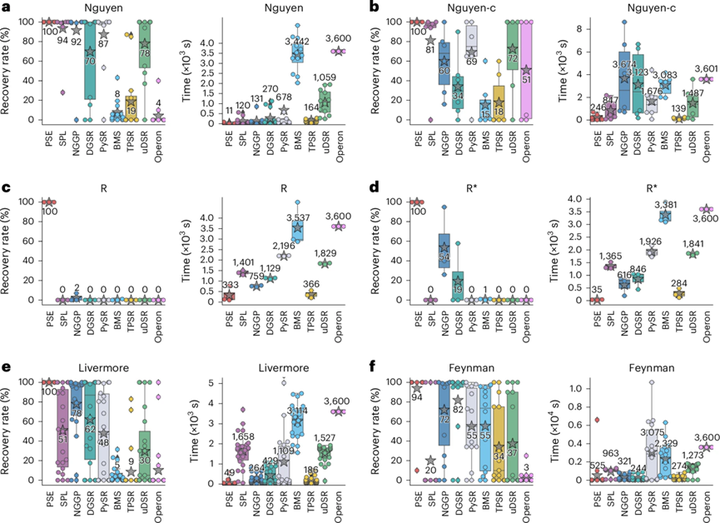
1. 标准符号回归基准测试
作者首先在 Nguyen、Nguyen-c、R、Livermore、Feynman 等经典基准问题上测试PSE。结果表明,PSE 在这些 benchmark 上总体取得了最高的恢复率,同时也保持了很高效率,某些情况下可实现两个数量级的加速。特别是在 R benchmark 这类有理分式表达式上,PSE 达到了 100% 恢复率,而许多基线方法几乎全部失败。作者解释说,这类表达式在某些区间上与多项式很相似,容易诱导其他方法陷入局部最优,而 PSE 能依靠直接的大规模并行评估准确恢复复杂分式结构。
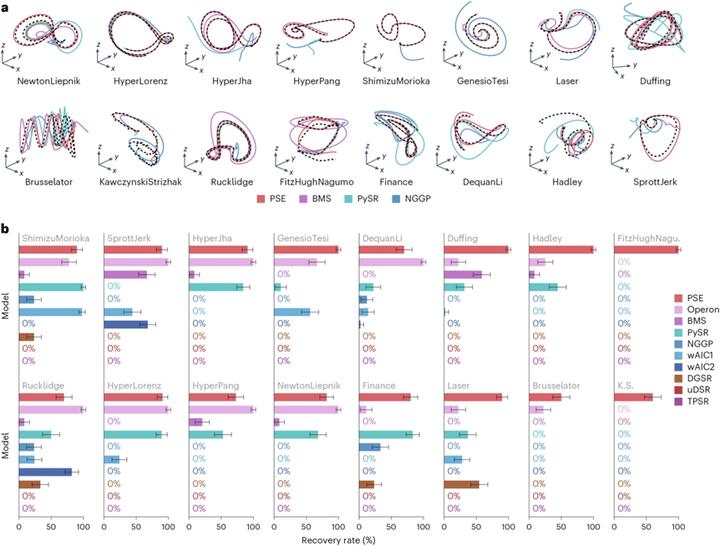
2. 混沌动力系统
接着,论文把方法应用到 16 个混沌动力系统的控制方程发现中。实验使用了含噪轨迹数据,并在 1%、2%、5%、10% 四种噪声水平下进行对比。结果显示,PSE 在不同噪声水平下都取得了更高的符号恢复率,能够更准确地识别底层 governing equations,说明它不仅适合简单静态公式恢复,也适用于更复杂的动态系统规律发现。
3. 真实机电系统:EMPS
在真实实验数据方面,作者选取了 EMPS(electro-mechanical positioning system)。这是一类常见的机电驱动系统,具有噪声和非线性。论文结合先验知识,假设系统遵循牛顿第二定律形式,并额外加入 sign算子用于描述摩擦项。这个设计说明,PSE 并不是完全“无先验”的盲搜,而是可以与物理知识结合,更有效地发现真实系统方程。
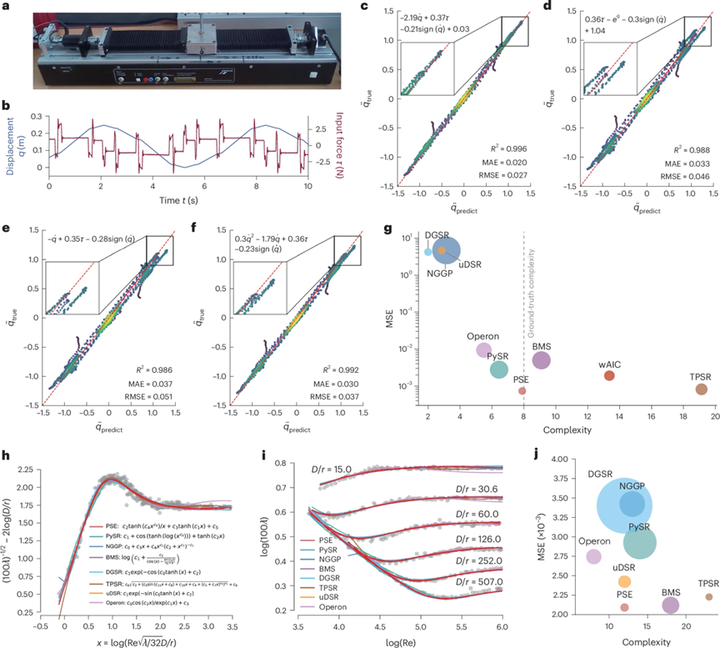
4. 整体实验结论
论文总体结论是:PSE 在标准 benchmark、混沌系统和真实实验物理建模中,都展现出优于多种现有基线方法的恢复能力和计算效率。作者特别指出,PSRN 通过公共子树复用和 GPU 并行,表达式评估效率最多可以提高四个数量级。
五、总结与展望
1. 论文的核心贡献
本文提出了一种新的思路:符号回归的突破点,不一定只在搜索策略本身,也可能在候选表达式的评估机制上。PSE 通过“公共子树复用 + GPU 并行 + token generator + 系数后处理”的组合,建立了一个更高效、更系统的符号搜索框架。它显著提高了大规模表达式评估能力,从而在准确率和速度上都取得了明显优势。
2. 论文的局限性
作者也明确承认,PSE 和大多数符号回归方法一样,仍然受限于预定义的离散算子集合。也就是说,如果真实规律包含当前算子库中没有的数学形式,方法就无法自动发现。此外,虽然 PSE 已经大幅提升了评估效率,但对于极大规模问题,它依然会受到输入变量维数、算子集合大小和硬件资源的限制。
3. 未来展望
论文提出了几条很有价值的未来方向:一是把 PSE 与其他符号回归技术进一步融合,例如集成式 SR 或其他深度/稀疏方法,以继续提升性能;二是在前处理阶段加入显式特征选择,从而提高在超高维问题上的可扩展性;三是继续改进 token generation 策略,例如引入领域结构先验、多目标奖励或更强的搜索引导;四是将物理先验知识,例如量纲约束,显式地融入搜索过程,以减少无效搜索并提高科学发现效率。
公众原文链接(文末附论文资源):
https://mp.weixin.qq.com/s/WRGbXH3gYJhZiz2eCg25tA
相关论文推荐:
CJA|西工大林海涛、张伟伟等:关联函数学习:适用飞行器外形泛化的稀疏气动数据重构方法
EAAI | 西工大夏明坤,张伟伟等:分层无量纲学习:一种物理和数据混合驱动的无量纲关联参数提取方法
注:文章由秦晋投稿分享,向本公众号授权发布。
更多精彩内容,敬请关注微信公众号“力学与人工智能”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)