多模态嵌入模型:CLIP如何架起视觉与语言的桥梁
在前面的内容中,我们已经了解了多模态嵌入模型的核心思想——将不同模态的数据映射到同一个向量空间,使得图像和文本可以直接进行语义比较。而CLIP(对比语言-图像预训练)正是这类模型中最具代表性的杰作。
现在,让我们深入CLIP的内部机制,并通过实际代码演示,亲眼见证它是如何实现跨模态对齐的。
1 CLIP的跨模态嵌入生成机制
从相似度分数到语义理解
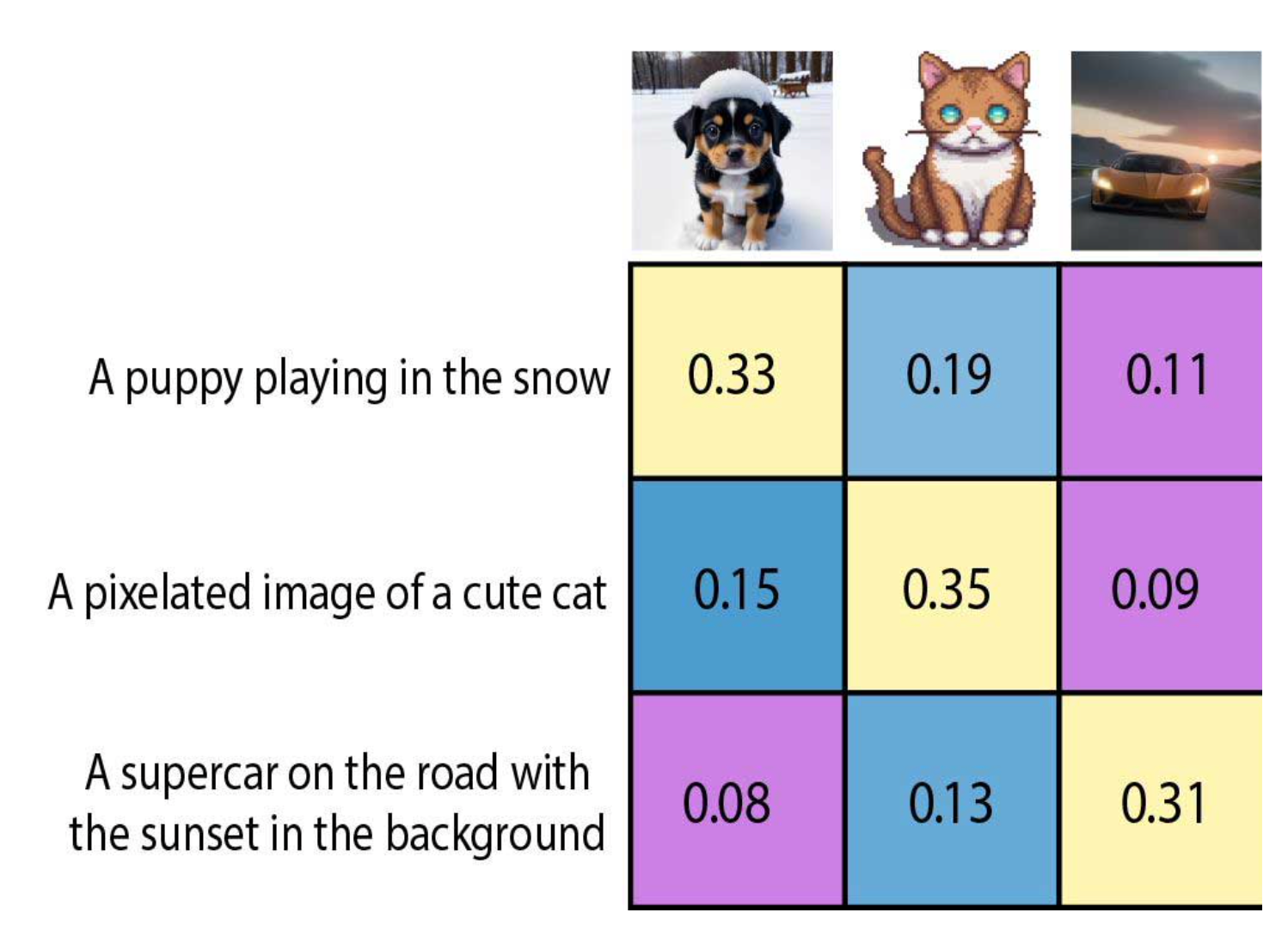
在上一节的代码示例中,我们计算了小狗图像与描述文本“a puppy playing in the snow”之间的相似度分数,得到了约0.33的结果。这个数字本身意义不大,但当我们把它放在一个包含多个图像和多个文本的矩阵中时,它的真正价值就显现出来了。
图9-14展示了一个3×3的相似度矩阵:
| 图像 \ 文本 | “A puppy playing in the snow” | “A pixelated image of a cute cat” | “A supercar on the road with the sunset in the background” |
|---|---|---|---|
| 小狗雪地图 | 0.33 | 0.19 | 0.11 |
| 像素化猫图 | 0.15 | 0.35 | 0.09 |
| 超跑日落图 | 0.08 | 0.13 | 0.31 |
观察这个矩阵,我们可以得出两个关键结论:
-
对角线上的分数最高——每张图像与其正确描述的相似度都明显高于与其他文本的相似度。这说明CLIP成功地将匹配的图文对在向量空间中拉近了距离。
-
非对角线分数较低——不匹配的图文对相似度普遍偏低,表明模型学会了区分不同语义内容。
正是这种能力,让CLIP能够执行零样本分类:对于一张新图像,我们可以准备一组候选类别文本(如“狗”、“猫”、“汽车”),计算图像与每个类别文本的相似度,然后选择相似度最高的类别作为预测结果。整个过程完全不需要训练数据!
2 使用sentence-transformers轻松上手CLIP
虽然直接使用Transformers库调用CLIP已经相当简洁,但sentence-transformers库进一步封装了常用操作,让多模态嵌入的生成变得像“傻瓜式”一样简单。
安装与加载模型
python
# 安装sentence-transformers(如果尚未安装)
# pip install sentence-transformers
from sentence_transformers import SentenceTransformer, util
from PIL import Image
import urllib.request
import torch
# 加载预训练的CLIP模型(ViT-B/32版本)
model = SentenceTransformer("clip-ViT-B-32")
准备图像和文本数据
为了演示,我们使用三张图像和三段描述文本(与下图对应):
python
# 图像URL列表(实际使用时请替换为本地路径或有效URL)
image_urls = [
"https://raw.githubusercontent.com/HandsOnLLM/Hands-On-Large-Language-Models/main/chapter09/images/puppy.png",
"https://raw.githubusercontent.com/HandsOnLLM/Hands-On-Large-Language-Models/main/chapter09/images/cat_pixel.png",
"https://raw.githubusercontent.com/HandsOnLLM/Hands-On-Large-Language-Models/main/chapter09/images/supercar.png"
]
# 加载图像
images = [Image.open(urllib.request.urlopen(url)).convert("RGB") for url in image_urls]
# 定义文本描述
captions = [
"A puppy playing in the snow",
"A pixelated image of a cute cat",
"A supercar on the road with the sunset in the background"
]
生成嵌入并计算相似度矩阵
python
# 对图像进行编码 image_embeddings = model.encode(images, convert_to_tensor=True) # 对文本进行编码 text_embeddings = model.encode(captions, convert_to_tensor=True) # 计算余弦相似度矩阵 similarity_matrix = util.cos_sim(image_embeddings, text_embeddings) # 打印结果 print(similarity_matrix)
输出结果应该类似于:
text
tensor([[0.33, 0.19, 0.11],
[0.15, 0.35, 0.09],
[0.08, 0.13, 0.31]])
与我们之前手动计算的矩阵完全一致。现在,我们可以轻松地用这个矩阵完成各种任务:
-
图像检索:给定文本“a puppy playing in the snow”,找出相似度最高的图像(第一列的最大值对应第一行)。
-
文本检索:给定图像,找出最匹配的描述(每行的最大值对应的列)。
-
聚类:将图像和文本的嵌入拼接后,进行聚类分析,可以发现视觉与语义的潜在关联。
3 CLIP的应用场景再探索
除了零样本分类和跨模态检索,CLIP还催生了许多令人惊叹的应用:
1. 生成模型的“导航仪”
稳定扩散(Stable Diffusion)等文本生成图像模型,正是利用CLIP的文本编码器将用户输入的描述转换为向量,然后引导扩散过程生成符合语义的图像。CLIP在这里扮演了“语义理解”的角色,确保生成的图像与文本描述一致。
2. 图像与文本的联合聚类
将大规模图像库和对应的标签文本映射到同一空间后,我们可以进行联合聚类。例如,在电商平台上,商品图像和用户评论可以被聚类到相同的语义簇中,帮助发现“舒适的运动鞋”或“复古风格的连衣裙”等跨模态概念。
3. 自动化图像标注
对于无标签的图像,我们可以通过计算其与常见描述文本的相似度,自动生成候选标签。这种方法在构建大规模多模态数据集时特别有用。
4. 多模态搜索
在混合了图片和文档的知识库中,用户可以用文字搜索图片,也可以用图片搜索相关文档。CLIP让这一切成为可能。
4 为什么CLIP如此强大?
CLIP的成功可以归结为三个关键因素:
-
海量数据:CLIP在4亿个图文对上进行了训练,涵盖了互联网上各种各样的图像和文本,这使得它具备了极强的泛化能力。
-
对比学习目标:通过最大化匹配图文对的相似度、最小化不匹配对的相似度,模型学会了捕捉跨模态的语义一致性,而不是简单的表面模式。
-
双编码器架构:文本编码器和图像编码器各自独立,但在训练中协同优化。这种设计使得模型在推理时可以分别编码不同模态,并快速计算相似度,非常适合检索任务。
5 局限性与未来方向
尽管CLIP表现出色,但它并非万能:
-
细粒度理解不足:CLIP擅长捕捉整体语义,但在精细的物体关系、计数、空间位置等方面表现不佳。
-
社会偏见:训练数据来自互联网,不可避免地携带了各种偏见,这可能导致模型在敏感内容上产生不公平的结果。
-
文本生成能力缺失:CLIP本身不能生成文本,它只是一个理解模型。
未来的多模态模型正在向统一生成方向发展,例如Flamingo、GPT-4V等,它们不仅能理解,还能生成跨模态内容,真正实现“所见即所得,所说即所画”。
总结
多模态嵌入模型,尤其是CLIP,为我们打开了一扇通往跨模态理解的大门。通过将图像和文本映射到同一个向量空间,我们第一次能够像比较文本与文本一样,直接比较图像与文本的语义相似性。
从技术角度看,CLIP的成功得益于视觉Transformer对图像的优雅处理、对比学习的高效训练,以及双编码器的灵活架构。从应用角度看,它为零样本分类、跨模态检索、生成模型引导等任务提供了强大而简洁的解决方案。
正如我们在本章所见,多模态能力的加入,让大语言模型从“语言高手”进化为“通感智者”。未来,随着技术的不断演进,我们将见证更多模态(如音频、视频、传感器数据)的融合,AI理解世界的方式也将越来越接近人类。
本文参考:图解大模型:生成式AI原理与实战
书籍pdf免费下载地址:https://pan.baidu.com/s/1mTaUQ5czcfGpBM8KvJuS2g?pwd=un44

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献131条内容
已为社区贡献131条内容

所有评论(0)