【交易策略】Zorro决策树模型实战:用机器学习做日内交易(含代码)
研究目标:构建一个基于决策树模型的最小可行性策略,深度拆解 Zorro 机器学习引擎的底层机制,特征预处理逻辑以及目标变量的加权运算原理。
1. 核心引擎:adviseLong / adviseShort 函数解析
在 Zorro 中,adviseLong 和 adviseShort 是连接交易逻辑与底层机器学习引擎的桥梁。为了适应金融市场多空结构的不对称性,系统要求分别为多头和空头训练独立的模型。
该函数在系统处于不同模式时,表现出截然不同的行为特征:
- 训练模式:充当数据采集器。它负责收集当前的特征向量,等待相关的历史交易平仓后,将特征与实际盈亏(PnL)打包成训练样本。此时函数返回系统硬编码值
100。 - 测试与实盘模式:充当预测器。它将当前特征输入已训练好的模型,输出预测置信度分数。
关键参数配置:
- Method (
DTREE + RETURNS):指定使用原生的决策树算法。+RETURNS标志是一个极其核心的设定,它指示引擎摒弃传统的自定义目标变量,直接追踪下一笔实际开仓交易的 PnL(包含滑点与成本)作为目标变量。 - Objective (
0):由于使用了+RETURNS,此处需设为0。 - Signals:输入的特征向量数组。Zorro 原生算法要求特征的量纲需对齐,官方推荐通过预处理将其映射至
[-100, 100]区间,以优化底层 C 引擎的分箱(Binning)计算效率。
2. 特征工程与归一化预处理
为了建立良好的基线策略,本次提取了两个具有清晰逻辑的正交特征。在量化特征预处理中,若指标的理论边界已知,采用静态线性映射远优于动态平滑缩放(如Z-Score),这能避免高低波动期带来的特征畸变。
特征 1:趋势概率
- 逻辑:对价格应用低通滤波器提取趋势,利用模糊逻辑(Fuzzy Logic,
risingF/fallingF)将趋势斜率转化为[0, 1]的概率值。趋近 1 为强多头,趋近 0 为强空头,0.5 附近代表震荡。 - 标准化:将其去中心化并放大,映射至
[-100, 100]。- 公式:
(RisingProb - 0.5) * 200
- 公式:
特征 2:短期动量 (Fisher Transform)
- 逻辑:衡量价格的短期极值与均值回归倾向。原生态取值通常在
[-4, 4]之间。 - 标准化:放大 25 倍映射至核心区间,并利用
clamp()函数对罕见的黑天鹅极值进行截断,防止数据溢出污染模型。- 公式:
clamp(Cycles[0] * 25, -100, 100)
- 公式:
3. 目标变量:伪分类与加权信息熵
在标准机器学习中,预测连续的 PnL 属于回归问题,或将 PnL 的正负转化为 +1/-1 的纯二元分类。但在交易中,纯分类存在致命缺陷:它忽略了盈亏的绝对大小。 高胜率的微利样本如果与极低胜率的爆仓样本被错误打包,将会导致策略破产。
Zorro 采用了一种极其高明的处理策略:以 PnL 绝对值为样本权重的二元分类。
当一笔交易结束并产生 PnL 时:
- 分类标签:
PnL > 0记为正类,PnL < 0记为负类。 - 样本权重:
|PnL|的绝对值作为计算信息熵的权重因子。
加权信息增益的切分逻辑:
P(正类)=节点内所有盈利交易的利润总和节点内所有交易的盈亏绝对值总和P(正类) = \frac{节点内所有盈利交易的利润总和}{节点内所有交易的盈亏绝对值总和}P(正类)=节点内所有交易的盈亏绝对值总和节点内所有盈利交易的利润总和
- 案例:某节点包含 4 笔 +10 美元盈利和 1 笔 -100 美元亏损。
- 标准分类器因拥有 80% 胜率,会将其视为高纯度盈利节点。
- Zorro 引擎计算其正类加权概率仅为 40140≈28.5%\frac{40}{140} \approx 28.5\%14040≈28.5%。算法会认定该节点包含毁灭性做多风险,从而继续进行深度特征切分,试图将那笔 -100 美元的交易孤立(或剪枝)。
模型输出解析(置信度得分):叶节点最终的输出跨度为 [-100, 100]。它并非统计学概率,而是基于上述公式映射的盈亏期望值(Expectancy Score)。数值越趋近于 +100,表明落入该特征空间的样本具有极高的胜率且平均利润丰厚。在实战中,我们通过设置阈值(如 >30)来过滤低置信度的噪音信号。
4. 策略与代码实现
策略源码
#include <profile.c>
#include <utils.c>
#include <myindicators.c>
void tradeStrategy() {
// ==================== 计算指标 ====================
vars Prices = series(price());
vars Trends = series(LowPass(Prices, 300));
vars Cycles = series(fisherTransform(Prices, 10));
var ATR100 = ATR(100);
FuzzyRange = 0.1*ATR100;
var RisingProb = risingF(Trends);
var FallingProb = fallingF(Trends);
// ==================== 特征缩放 ====================
var Sigs[2];
// Sig[0]: 概率范围映射
// 原范围 [0, 1] -> 新范围 [-100, 100]
// 详解: RisingProb=1 输出 100;RisingProb=0 输出 -100;RisingProb=0.5 输出 0
Sigs[0] = (RisingProb - 0.5) * 200;
// Sig[1]: Fisher 动态映射
// 原大部分范围 [-4, 4] -> 新范围 [-100, 100]
// 使用 clamp 防止罕见的极端黑天鹅数据超出边界
Sigs[1] = clamp(Cycles[0] * 25, -100, 100);
// ==================== 重要设置 ====================
// 训练模式下允许同时建立多头和空头仓位,否则多头进场会关闭空仓,影响训练结果
if(Train) Hedge = 2;
// 定义退出条件,训练模式会生成幽灵订单,并根据这些平仓条件计算 pnl
Stop = 3*ATR100; // ATR 止损
TakeProfit = 6*ATR100; // ATR 止盈,风险回报率为2:1
LifeTime = 42; // 最长持仓时间,约1周
// 测试/交易模式最多持有一个多头/空头仓位,多头进场会平仓空头,反之亦然
MaxLong = MaxShort = 1;
// ==================== 机器学习 ====================
// 训练模式:收集训练样本(包括特征和目标变量)。返回 100。
// 测试模式:将当前信号喂给模型,获取真正的预测分数 (-100 ~ 100)。
var LongPrediction = adviseLong(DTREE+RETURNS, 0, Sigs, 2);
var ShortPrediction = adviseShort(DTREE+RETURNS, 0, Sigs, 2);
if(Train) {
// ==================== 训练期:海量取样 ====================
// 用极低的门槛 (>0) 让 enterLong 尽可能多地在每一根 K 线上被触发。
// 在底层,系统为训练集记录了海量的、相互重叠的虚拟订单结算是赚是亏。
if(LongPrediction > 0) enterLong();
if(ShortPrediction > 0) enterShort();
} else {
// ==================== 测试期:苛刻执行 ====================
// 我们必须保证不会频繁换手,且只有在大趋势确认的情况下才入场。
var EntryThreshold = 30;
var DivergenceThreshold = 15;
// 基于模型的智能止损(发现局势不对提前跑路)
if(NumOpenLong > 0 && LongPrediction < 0) exitLong();
if(NumOpenShort > 0 && ShortPrediction < 0) exitShort();
// 严苛的多空排他性入场(解决震荡期多空双杀的痛点)
bool triggerLong = (LongPrediction > EntryThreshold) && ((LongPrediction - ShortPrediction) > DivergenceThreshold);
bool triggerShort = (ShortPrediction > EntryThreshold) && ((ShortPrediction - LongPrediction) > DivergenceThreshold);
// 只有在空仓时,拿到确信度极高的信号才出击
if(NumOpenLong == 0 && triggerLong) enterLong();
if(NumOpenShort == 0 && triggerShort) enterShort();
}
// ==================== 图表 ====================
if(Test && !is(LOOKBACK)) {
// plot("RiseProb", RisingProb, NEW, RED);
// plot("Cycle", Cycles[0], NEW, RED);
plot("Sig0", Sigs[0], NEW, RED);
plot("Sig1", Sigs[1], NEW, RED);
plot("LongPrediction", LongPrediction, NEW|BARS, GREEN+TRANSP);
plot("ShortPrediction", ShortPrediction, 0|BARS, RED+TRANSP);
plot("Pred+", EntryThreshold, 0, GREY);
}
}
function run() {
// --------------------------------------------------------- //
// Zorro 设置
// --------------------------------------------------------- //
// 日志
set(LOGFILE);
Verbose = 3;
// 图表
set(PLOTNOW);
setf(PlotMode,PL_DIFF);
PlotScale = 8;
PlotHeight2 = 320;
// 训练
set(PARAMETERS|RULES);
setf(TrainMode,TRADES);
DataSplit = 85;
NumWFOCycles = 10;
NumCores = 0;
// k线生成规则,7*24小时交易
resf(BarMode,BR_WEEKEND);
StartWeek = 0;
EndWeek = 62359;
StartMarket = 0;
EndMarket = 2359;
BarPeriod = 240;
BarZone = UTC;
BarOffset = 0;
TickFix = 60000;
if(Live) TickFix = 0;
// 测试样本
StartDate = 20180101;
EndDate = 20251230;
LookBack = 5000;
// 下一根k线开盘时进场/平仓
Fill = 3;
// 固定头寸
Lots = 100;
// --------------------------------------------------------- //
// 策略逻辑
// --------------------------------------------------------- //
asset("BTCUSDT");
Leverage = 5;
MarginCost = priceClose()*LotAmount/Leverage;
tradeStrategy();
}
架构解析:训练和测试模式的逻辑分割
上述代码中最核心的逻辑在于:训练期无节制取样,测试期严苛化执行。
- 在训练模式下,系统需要大量数据以规避欠拟合。只要条件允许,引擎便会在每根 K 线启动“虚拟追踪订单”。它们平行存在且不触发实际资金占用,以最密集的方式试探市场的每一种特征组合。这必须要设置显性的退出条件(如
Stop/TakeProfit),才能完成 PnL 的计算。 - 在测试模式下,由于分别独立训练了多/空两棵决策树,可能会出现“信号互绞”(多空模型分数同时居高)的现象。此时引入阈值过滤(
EntryThreshold)与排他性分歧度验证(DivergenceThreshold),能有效规避无序震荡期的频繁换手。
WFO 生命周期透视图
每次 WFO 循环,底层完整的运作流如下:
========================================================================================
阶段 1:数据高频取样 (Data Sampling) / 对应 Zorro Run 循环
========================================================================================
[Bar 1] [Bar 2] ... [Bar N]
│ │ │
计算[Sig0, Sig1] 计算[Sig0, Sig1] │
│ │ │
adviseLong()拍快照 adviseLong()拍快照 │
│ │ │
enterLong()启动 enterLong()启动 │
虚拟订单 #1 开始-- > 虚拟订单 #2 开始-- > │ 触发 Stop/TP/LifeTime
. . ╰==> 核算 PnL,缝合样本:[Sig0, Sig1, PnL]
========================================================================================
阶段 2:数据阵列聚合 (Data Aggregation) / 对应 WFO Cycle 训练窗结束
========================================================================================
组装该窗口内所有闭环的追踪样本:
[条件 X (Sigs)] || [预期 Y (PnL & Weight)]
样本1: [ A1, B1 ] || -$50 (亏损,权重50)
样本2: [ A2, B2 ] || +$120 (盈利,权重120)
========================================================================================
阶段 3 & 4:模型生成与热编译 (Model Generation & Hot-Compile)
========================================================================================
寻找加权信息增益最大切分点 -> 若特征致噪则触发剪枝(Pruning)
-> 导出为 Lite-C 源码 (*.c) -> 引擎毫秒级内存热编译 -> 立刻应用于相邻的外置测试集(OOS)
5. 回溯检验
将策略应用于 BTCUSDT(4小时线,样本期 2018-2025),执行 WFO = 10 的滚动样本外测试。
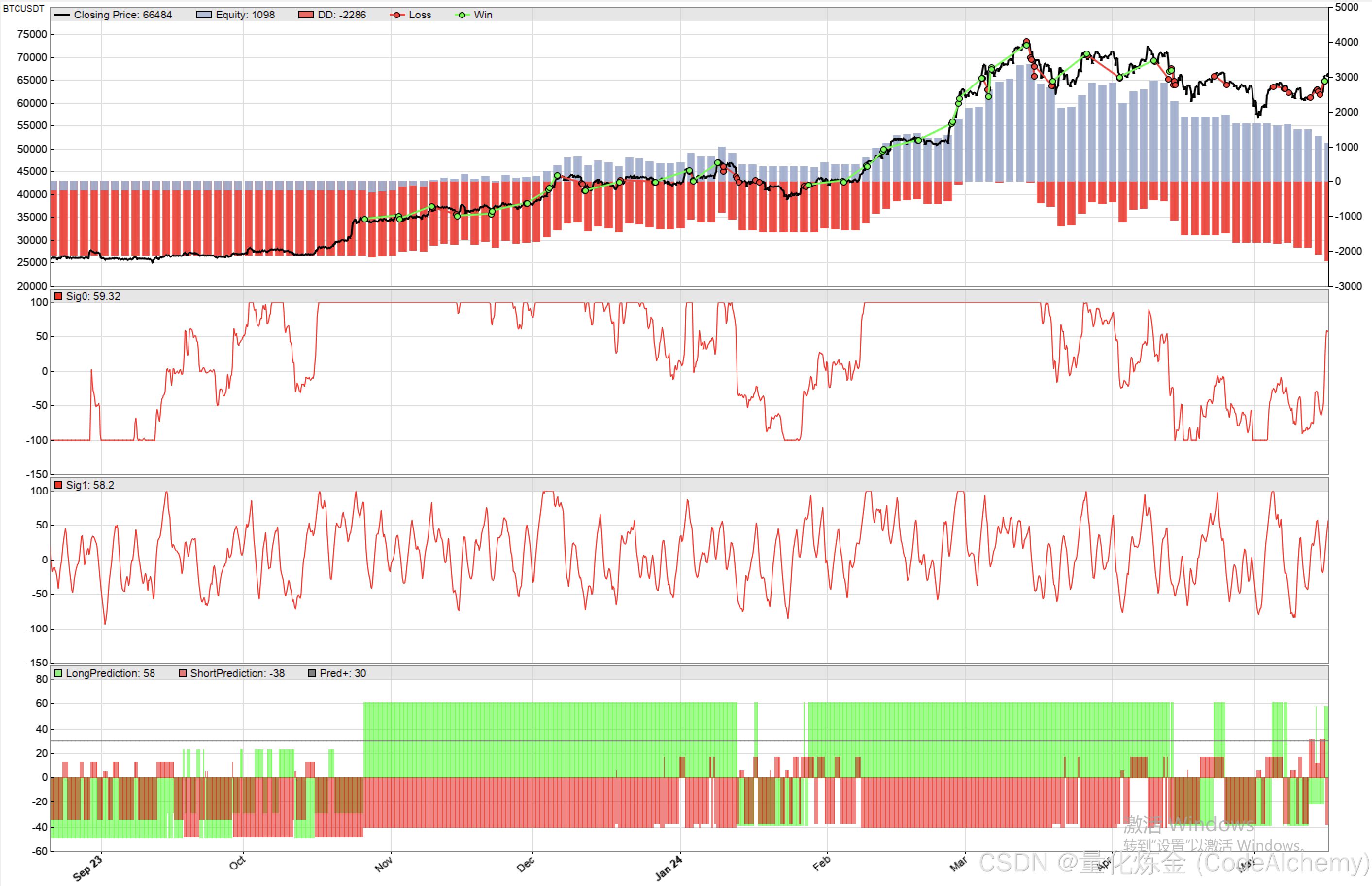
图表中下方绿色柱体为多头得分,红色柱体为空头得分。可以观察到明显的“市场状态切换”效应对模型的影响:
- 趋势状态:在 2023 Q4 至 2024 Q1 的主升浪中,决策树模型精准识别了多头状态,绿色柱体长期呈压倒性优势,策略获取了丰厚的利润。
- 震荡状态:在随后的宽幅震荡行情中,现有特征组无法有效识别“假突破”,多空信号陷入混乱,导致策略持续亏损。
6. 总结
- 该 MVP 策略初步跑通,最终录得 Profit Factor 1.04,PRR 0.88。虽然未能实现盈利,但作为一个无过拟合的基线策略,代码已经足够。
- 未来方向:模型在震荡期的失效表明当前的趋势概率与动量特征不足以描述完整的市场全貌。接下来的研究将回归特征工程,引入更多具备强预测能力的特征,目标是打造可稳定盈利的机器学习交易系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)