高通跃龙IQ-9100平台上工业缺陷检测实战(2): 安装 QAIRT/QNN,并把 ONNX 跑到 HTP/NPU
💡 前言
上一篇我们用 ONNXRuntime(CPU)把链路跑通了,这一步很关键:至少证明“摄像头/预处理/后处理/画框”都没问题。
在此基础上,本篇将完成两项工作:在 Host 端完成 QAIRT/QNN 环境搭建与模型转换,并在高通跃龙IQ-9100平台设备端使用 HTP backend 跑通一次推理执行,得到稳定的输出结果。
接下来要做的事也很实在:把推理换到 QNN(最好是 HTP/NPU),让性能和稳定性上一个台阶。本文主要做三件事:
- 在 Host(x86 Ubuntu 22.04)安装 QAIRT(Community)并完成依赖检查;
- 把 ONNX 模型转换成 QNN 可运行的模型库(
.so); - 在 Target 端(高通跃龙IQ-9100平台Linux OS)用 HTP backend 跑通一次推理(先跑通,再谈优化)。
小提醒:QAIRT/QNN 不同版本的参数名/路径会有差异,所以本文把“先跑 --help 确认参数”当作必做步骤。照这个流程走,就能稳定落地。
1. 总体流程
Host (x86 Ubuntu 22.04)
- 安装 QAIRT SDK
qnn-onnx-converter: ONNX → QNN 中间产物qnn-model-lib-generator: 生成可在 Target (aarch64) 加载的模型库.so
Target (高通跃龙IQ-9100平台Linux OS)
- 拷贝 QNN runtime/backends 动态库 + 你的模型库
- 用
qnn-net-run或qnn-sample-app先验证推理可执行
以下流程图更直观地展示了从 Host 环境搭建到 Target 端运行验证的完整流程: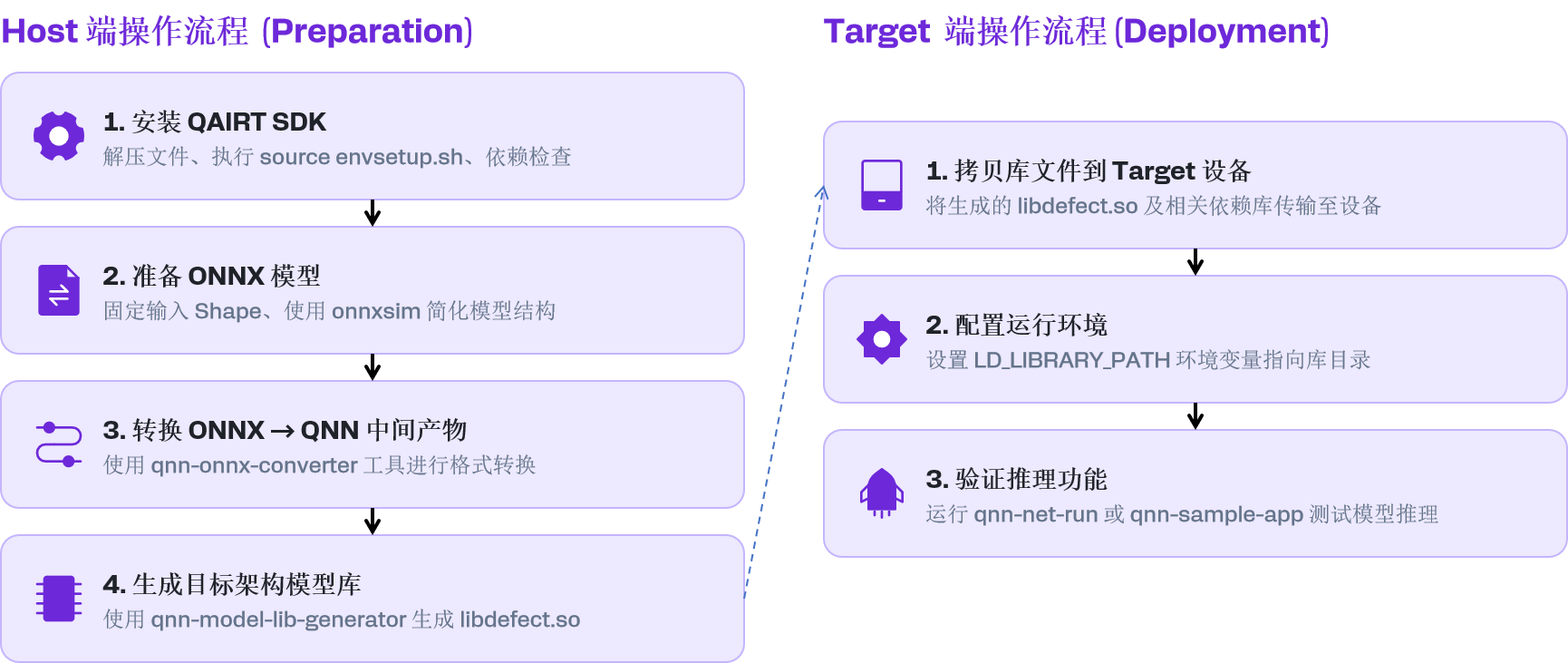
2. Host 环境搭建 (QAIRT)
这里以公开可下载的 QAIRT Community v2.37.1.250807 为例。安装文档可参考(用于读者复现):Radxa QAIRT SDK Installation。
2.1 下载与解压
(实际版本号以你下载的版本为准)
unzip v2.37.1.250807.zip
cd qairt/2.37.1.250807
2.2 配环境(这一步别漏)
source bin/envsetup.sh
2.3 依赖检查(下面三条都跑一遍)
sudo ${QAIRT_SDK_ROOT}/bin/check-linux-dependency.sh
${QAIRT_SDK_ROOT}/bin/envcheck -c
python3 ${QAIRT_SDK_ROOT}/bin/check-python-dependency
3. 模型准备
QNN 对模型形状/算子支持更敏感,按下面三步做完再进入转换:
3.1 固定输入 shape(必须做)
导出固定输入(例如 1x3x640x640)。动态 shape 会显著增加转换与运行的不确定性,第一次跑通不要用动态 shape。
3.2 onnxsim 简化(本文流程固定使用简化后的模型)
pip install onnxsim
python -m onnxsim defect.onnx defect_simplified.onnx
3.3 记录输入/输出 tensor 名
后续喂输入/解析输出会用到:
python3 -c "import onnx; m=onnx.load('defect_simplified.onnx'); print([i.name for i in m.graph.input]); print([o.name for o in m.graph.output])"
4. Host 转换与生成模型库
4.1 先看帮助(这是步骤的一部分)
qnn-onnx-converter --help
qnn-model-lib-generator --help
4.2 转换(示例形态)
参数名以你的版本为准,常见形态如下:
qnn-onnx-converter \
--input_network defect_simplified.onnx \
--output_path build_qnn \
--output_model defect
4.3 生成模型库(示例形态)
qnn-model-lib-generator \
--model_cpp build_qnn/defect.cpp \
--model_bin build_qnn/defect.bin \
--output_dir build_qnn/lib \
--target_arch aarch64
最终你关心的是类似 build_qnn/lib/libdefect.so 的模型库文件(名称以实际输出为准)。
5. Target 部署
目录结构按下面放(第一次直接整包拷贝,跑通后再精简):
/opt/defectd/
|-- lib/ # libQnnHtp.so / libQnnSystem.so 以及依赖
|-- model/ # 你的 libdefect.so
|-- inputs/ # input_list.txt 与 raw 输入
|-- outputs/
配置动态库路径:
export LD_LIBRARY_PATH=/opt/defectd/lib:$LD_LIBRARY_PATH
6. Target 运行验证
6.1 用 qnn-net-run 验证
qnn-net-run --help
常见运行形态(以 --help 为准):
qnn-net-run \
--backend /opt/defectd/lib/libQnnHtp.so \
--model /opt/defectd/model/libdefect.so \
--input_list /opt/defectd/inputs/input_list.txt \
--output_dir /opt/defectd/outputs
6.2 用 qnn-sample-app 再验证一遍(后面做常驻会直接用它)
qnn-sample-app 和 qnn-net-run 类似,但它就是官方示例工程。后面(五)做 C++ 常驻服务的时候,我会直接基于它改,所以你现在提前跑通一下,后面会更顺。
qnn-sample-app --help
7. 常见问题
-
板端缺依赖库:出现
error while loading shared libraries
处理:把 SDK 的aarch64/lib/目录先整包拷到/opt/defectd/lib/,跑通后再瘦身。 -
HTP backend 初始化失败
处理:先用 CPU backend 跑通(验证模型/输入没问题),再排查 BSP/驱动/HTP 组件。 -
转换失败(不支持算子/动态 shape)
处理:固定输入 shape;使用 onnxsim;必要时换导出方式/降低 opset/替换模型结构。 -
输出解析不一致
处理:先用同一份输入 raw 对齐qnn-net-run与 ONNXRuntime 输出的基本分布;输出 shape/dtype 必须按实际读取。
📢下一篇介绍
**下一篇**在该基础上,把“能跑通”推进到“可长期运行”:实现采集、推理、输出三段解耦的流水线结构,并落地事件截图与结构化结果落盘/上报。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)