Meta 工程团队JiT Testing(Just-in-Time Testing)自动化测试的未来方向之一

1、自动化测试概述
自动化测试,简单来说,就是使用自动化工具和编写好的脚本来代替人工进行软件测试的过程。想象一下,你要测试一个大型的电商网站,需要对商品的搜索、添加到购物车、下单支付等多个功能进行反复测试。如果靠人工手动操作,不仅耗时耗力,还容易出现遗漏和错误。而自动化测试就像是一个不知疲倦、精准无误的测试员,能够快速、准确地执行大量的测试用例,大大缩短测试周期,提高软件质量。
常见的自动化测试类型有单元测试、集成测试和系统测试。单元测试主要针对软件中的最小可测试单元,比如一个函数或一个类,确保它们的功能正确。集成测试则是将多个单元组合在一起进行测试,检查它们之间的交互是否正常。系统测试是对整个软件系统进行全面测试,模拟真实用户的使用场景,验证系统是否满足需求。
传统自动化测试的底层假设是:
代码变更缓慢、可预测。工程师先写代码,再手动写测试(或用覆盖率驱动),测试变成代码库的永久居民,每次改动都要全量回归。
传统的自动化测试虽然能够提高测试效率,但也存在一些局限性。
例如,它需要测试人员编写大量的测试用例和脚本,对于复杂的业务逻辑和多样化的测试场景覆盖能力有限。
而 AI 技术的引入则为自动化测试带来了新的突破,AI时代自动化测试代码从静态代码维护变成了自主动态优化,AI 可以通过学习历史测试数据,自动生成更全面、更有效的测试用例。就好比一个经验丰富的测试员,通过对过去测试情况的总结和分析,能够准确地找出可能出现问题的地方,从而设计出更有针对性的测试用例。
2、Agentic 开发彻底改变了游戏规则
• AI Agent 能在几分钟内完成过去几天的工作量;
• 代码评审、上线节奏从“周”变成“小时”甚至“分钟”;
• 人类根本来不及为每一次“微小但致命”的变更预先写好测试,更别提长期维护。
结果就是:测试维护成本爆炸、假阳性泛滥、测试覆盖率形同虚设。Meta 在博客中直言:“工程师必须同时理解当前代码并预测未来所有可能的变更——这在 Agentic 时代根本不可能。”
从传统单元测试到 TDD、从 mutation testing 到 property-based testing测试方法逐渐跟不上AI开发的节奏。
3、JiT的核心理念与思路
Meta 正在大规模落地的“调整方案”:Just-in-Time Testing(简称 JiT Testing),尤其是其中的 Catching JiTTests(捕获型实时测试)。
核心产品叫 Catching JiTTests,专治“这次变更引入的回归 bug”。它的完整流水线(来自同日发布的 arXiv 论文《Just-in-Time Catching Test Generation at Meta》)如下:
1. 意图推断(Intent Inference)LLM 阅读 diff 的标题、描述和代码,总结本次变更的真实意图,同时列出最可能引入的“风险点”(null 处理、边界条件、状态机错误等)。
2.突变体生成(Mutant Generation)基于风险点,在 parent revision 上人为制造各种“可能的 bug 版本”(mutants)。这其实是 mutation testing 的现代 LLM 版,但只针对本次变更。
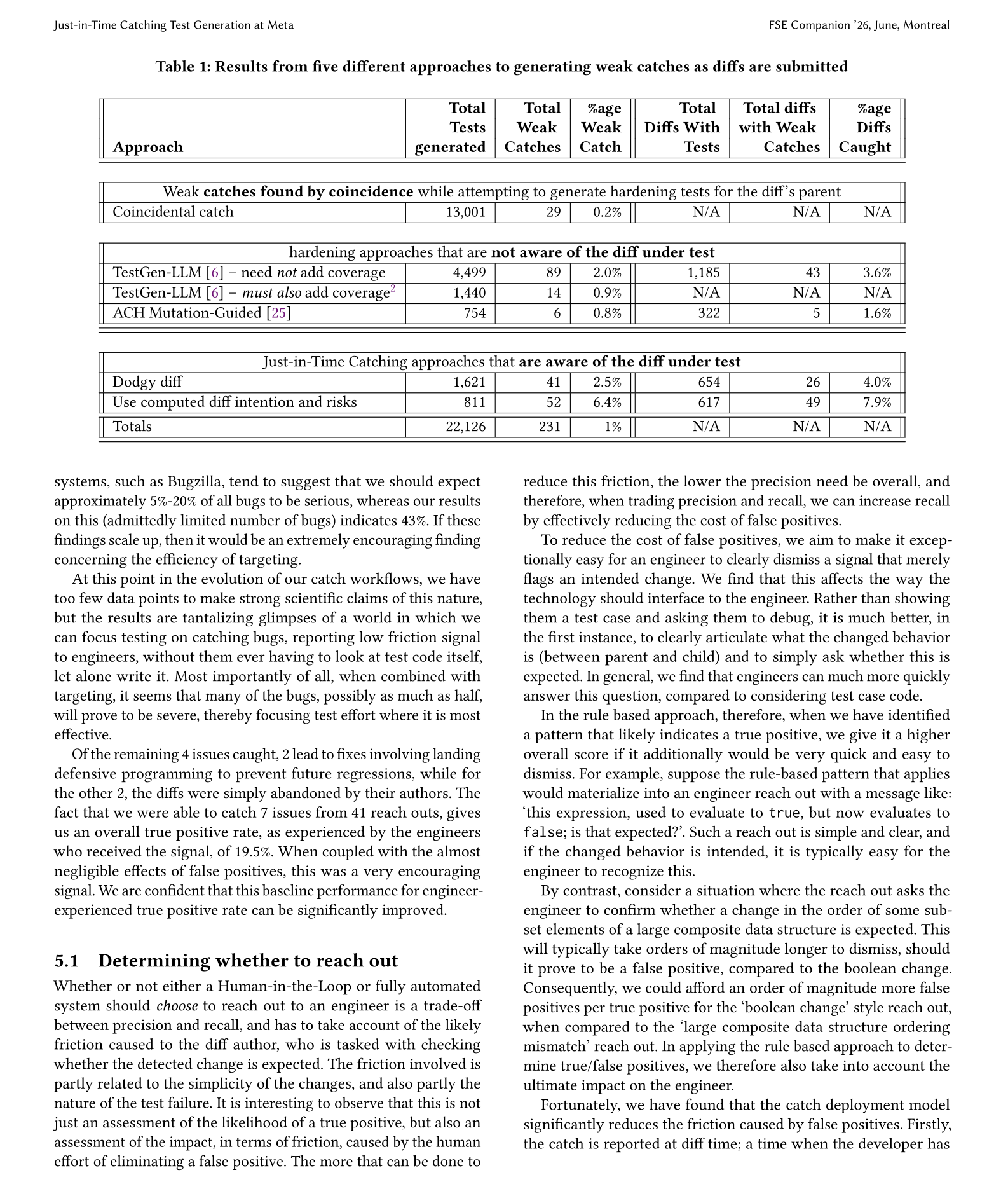
3.测试生成与捕获用 mutation-guided LLM 为每个突变体生成测试(保证在 parent 上通过),然后在真实 diff 上运行。凡是失败的,就是“弱捕获(weak catch)”——说明这个测试能抓住本次变更的异常行为。
4.真假阳性过滤(Assessors Ensemble)这是整个系统的灵魂:
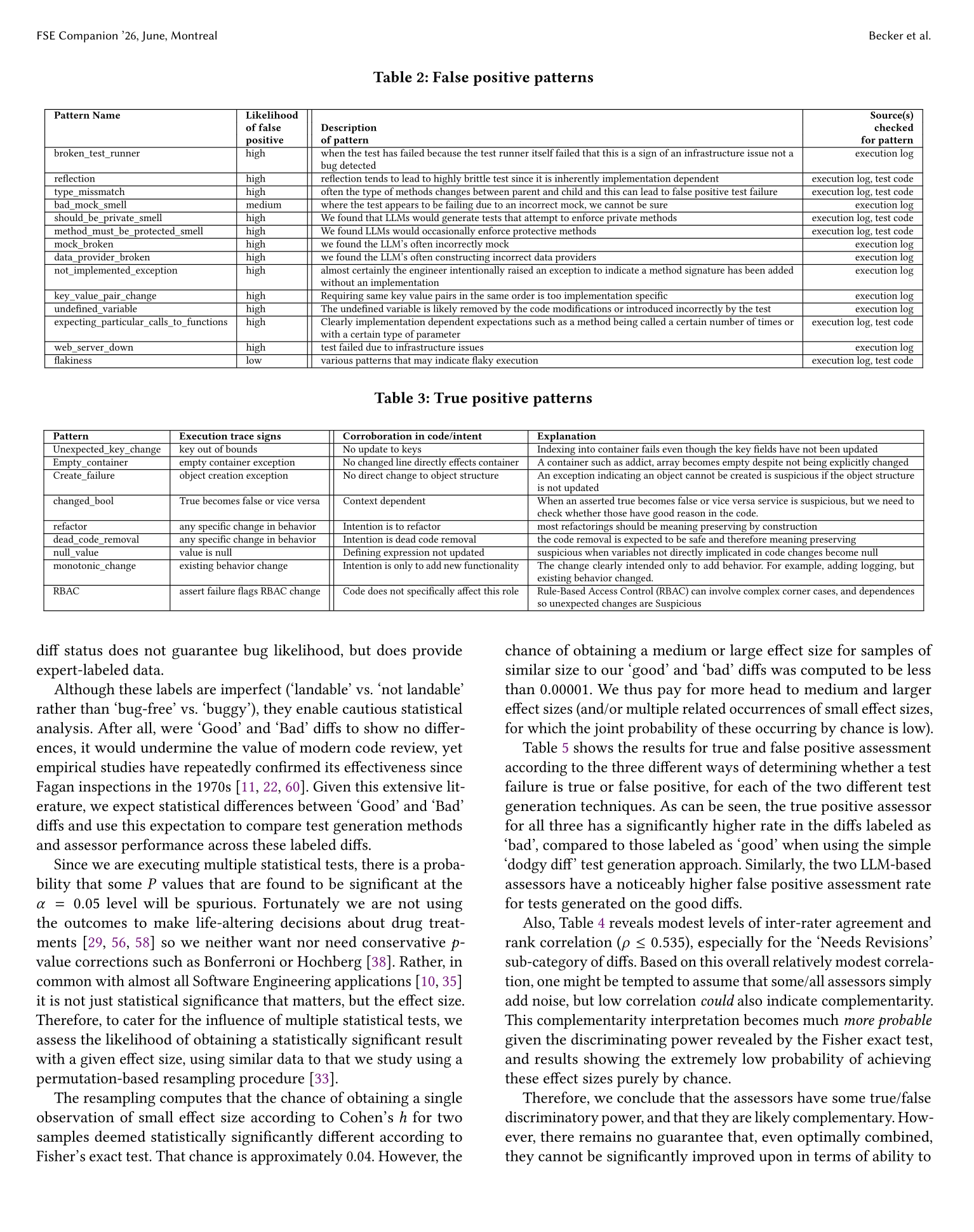
◦ 规则评估器(RubFake):提取 600+ 个历史模式(比如 boolean 翻转、容器为空等),判断是“明显有意变更”还是“真正 bug”。
◦ LLM-as-Judge 集成(Llama 3.3-70B + Gemini 3 Pro + Claude Sonnet 4):给每个弱捕获打分(-1 到 +1),并输出自然语言解释。三模型中位数投票,精度极高。
5.人类极简介入只给工程师发一条聊天消息:“这个行为发生意外变更,是预期的吗?”确认是 bug 就修复;确认是预期就一键 Dismiss。不需要任何人阅读或审查测试代码本身。
用完即删,不在入库。跟阅后即焚有点类似,都是一次性生成,一次性消耗,一次性验证,每次都会重新生成,每次都可能不一样。
4、实际实施验证数据(论文阶段)
论文给出硬核数据(Meta 内部数百亿行代码、35 亿用户规模):
• 分析 22,126 个生成测试 → 231 个弱捕获;
• Intent-Aware 流程:单 diff 捕获率从 4.0% 提升到 7.9%,效果是传统 hardening 测试的 4 倍、随机失败测试的 20 倍;
• 评估器把人类审查负担降低 70%;
• 向工程师推送 41 个候选捕获 → 8 个被确认为真阳性,其中 4 个是如果上线就会导致严重生产故障的 bug(崩溃、数据丢失等)。
真阳性率在工程师眼里达到 19.5%,对“严重故障”的捕获效率远超行业常规 5-20% 的预期。更关键的是:开发者几乎感觉不到拖累,因为虚假信号被大幅过滤。
5、对整个软件测试行业的远期冲击
1.)QA 角色彻底转型未来 QA 不再是“写测试的人”,而是“定义严重性标准、训练评估器、处理真实 bug 的人”。测试生成完全交给 AI,人类只做最终裁判。
2. )AI 编码工具的标配即将到来Cursor、Devin、Aider、Meta 自己的 Agent 系统……谁能把 JiT Testing 集成进去,谁就能在“代码质量”维度甩开对手。想象一下:每次 AI 提交 PR,自动狙击 4 个严重 bug——这才是真正的“可信 AI 开发”。
3. )对中国大厂的启示字节、阿里、腾讯、华为都在狂推大模型 Agent 开发。如果不尽快跟进类似范式,测试团队会成为最先被“卷死”的部门。Meta 这次公开论文(arXiv 2601.22832),本质上是把工业级方案送到了所有人面前——谁先抄作业,谁就能领先一个时代。
4. )潜在挑战也不容忽视
◦ LLM 意图理解是否在复杂业务逻辑上足够可靠?
◦ 评估器是否会随业务领域漂移?
◦ 如何处理非代码变更(配置、数据模型)?
但Meta的 0%减负和4个已阻止的严重故障,已经证明这套体系在超大规模场景下可行。
论文截图供参考:








AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)