揭秘Transformer架构设计 1
承接 初遇Open AI,深入了解大语言模型训练范式 与 初识神经网络与机器学习 相关内容,我们本次揭开Transformer模型架构的底层机制,解析它如何连接训练范式、神经网络和机器学习。
Transformer模型框架由多个功能模块组成,每个模块负责特定任务,这些模块串联起来形成完整的模型架构。每个模块可能包含神经网络,也可能是数学公式、数据预处理或后处理环节。整个框架通过各模块的协同工作,实现从输入到输出的端到端转换,是LLM模型智能表达的结构基础。
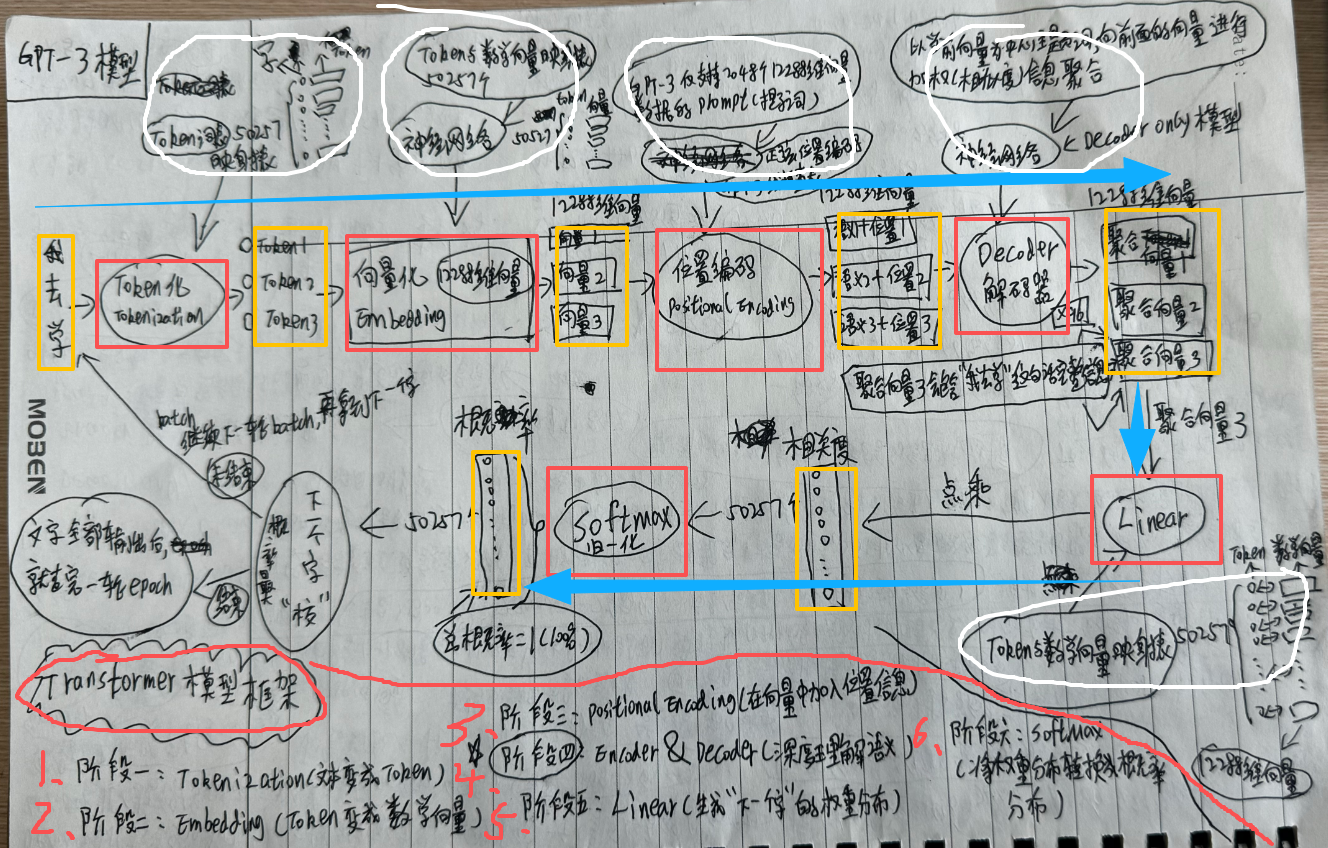
Transformer整个框架结构
Transformer模型内的各个阶段
- 阶段一:Tokenization - 文本变成Token
- 阶段二:Embedding - Token变成数学向量
- 阶段三:Positional Encoding - 在向量中加入位置信息
- 阶段四(核心阶段):Encoder(编码器)& Decoder(解码器) - 深度理解语义
- 阶段五:Linear - 生成 “下一个字” 的权重分布
- 阶段六:Softmax - 将权重分布转换成概率分布
Transformer 是由Google 在 2017 年《Attention is All You Need》中提出的。它彻底抛弃了传统的循环神经网络(RNN/LSTM),完全基于自注意力机制(Self-Attention)。
2017年Transformer框架图:
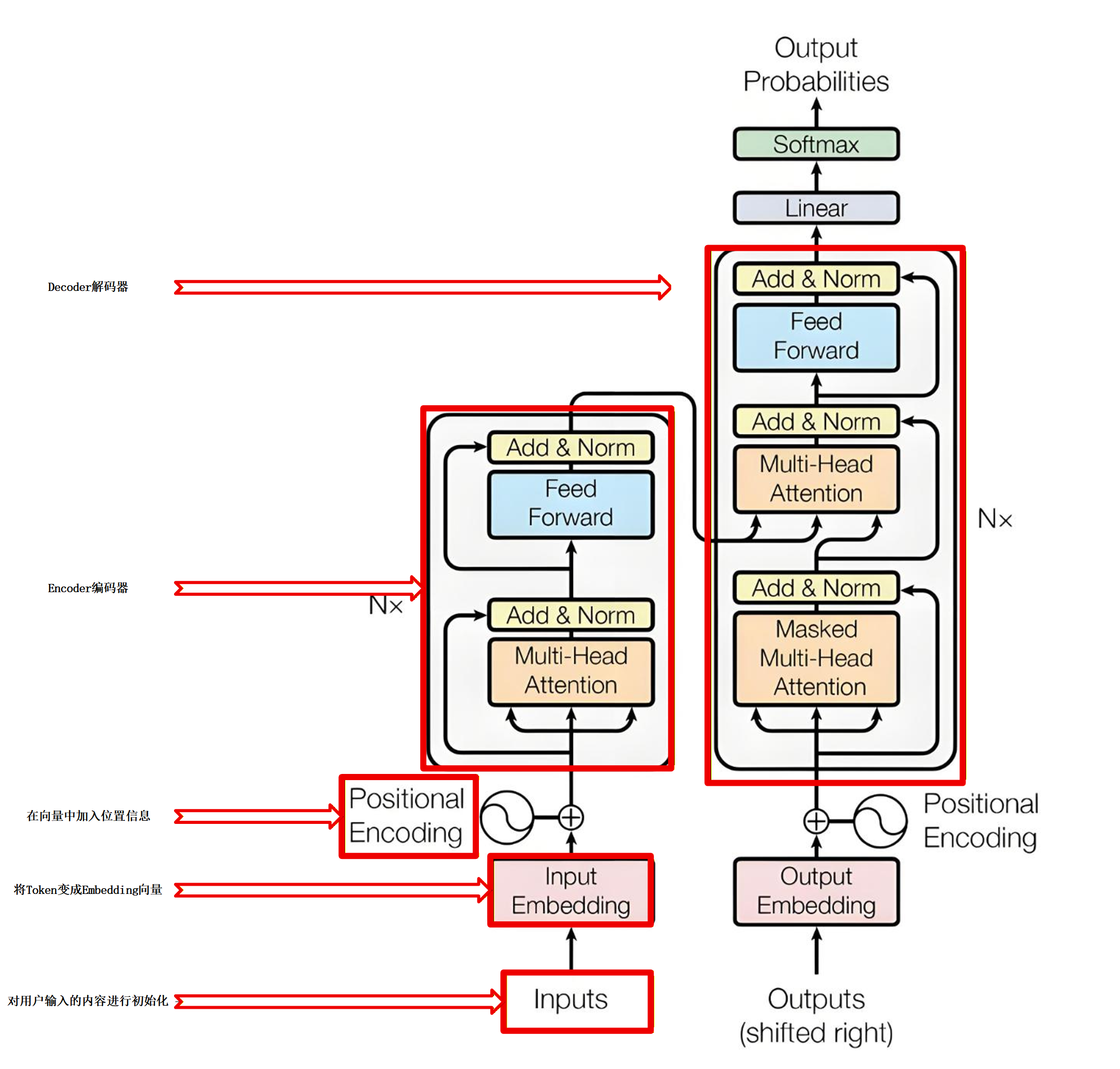
Transformer的核心模块是Encoder(编码器) 与Decoder(解码器)。
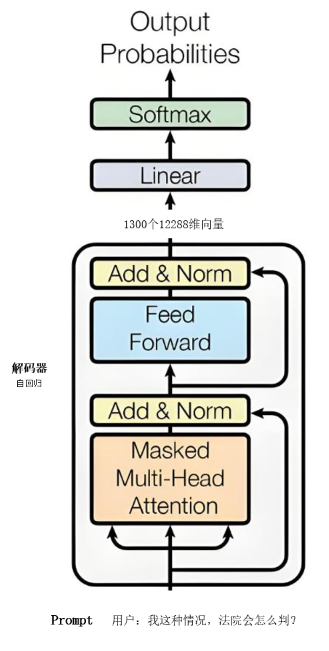
在大语言模型(LLM) 的实践中,发现可以省略Encoder流程,直接使用Prompt(提示词) 输入到Decoder(解码器),因为提示词最后的数学向量已经聚合了整段文本的语义及丰富含义,只需将其传给Linear阶段即可输出结果。基于这一发现,衍生出了目前最主流的Transformer-Decoder Only架构。
目前主流LLM模型的Transformer,几乎都采用了Decoder Only的架构,如下图所示:
Tokenization(Token化)
把一段文字,变成一组 Token,也就是词元化(Tokenization)。
子词(subword) 词元化,⽐如:
"subword"这个词,可以拆分成 "sub" 和 "word" 两个⼦词。
"encoded"可以拆解为 "encod" 和 "ed"。
"encoding"可以拆解为 “encod” 和 "ing"。
OpenAI的官网上,1000 Tokens大概是750个英文单词上下(500个汉字上下),并且在github上,OpenAI有个项目仓库,专门做Token化工程 [tiktoken](GitHub - openai/tiktoken: tiktoken is a fast BPE tokeniser for use with OpenAI’s models. · GitHub)。
如果输入内容是:海南麒麟瓜
海, unicode:28023, utf8:b'\xe6\xb5\xb7'
南, unicode:21335, utf8:b'\xe5\x8d\x97'
麒, unicode:40594, utf8:b'\xe9\xba\x92'
麟, unicode:40607, utf8:b'\xe9\xba\x9f'
瓜, unicode:29916, utf8:b'\xe7\x93\x9c'
通过tiktoken处理之后得到的Token序列是:(共11个Token)
b'\xe6\xb5\xb7'
b'\xe5\x8d\x97'
# 麒
b'\xe9'
b'\xba'
b'\x92'
# 麟
b'\xe9'
b'\xba'
b'\x9f'
# 瓜
b'\xe7'
b'\x93'
b'\x9c'
Token化的意思是,我有8万个汉字,每个汉字对应一个特殊的Token,那么就会有8万个不同种类的Token。
对于Tokenizationde来说,8万个汉字对应8万个Token,实在是太稀疏了,而且这只是中文,还有其他国家的文字呢?那我有没有什么办法,即可以表达字/词的含义,有可以让Token少呢?对于LLM模型来说,Token的数量与计算所需的算力是成正比的,所以Token在能表达字/词的含义的情况下,需要尽可能数量少。
就比如上面举例的“海南麒麟瓜”,麒被分配了3个Token,麟也被分配了3个Token,但是在中文内,麒麟绝大部分是组合在一起使用的,很少只使用单个字,或者跟其他文字进行组合,那对我来说麒麟可以组成一个词,只给一个Token。这样,麒麟从6个Token变成了1个Token,一下子减少6倍的消耗。
其实,这种做法在主流LLM模型内广泛使用,以GPT-3、GPT-4、Llama 3为例:
- 2020年的GPT-3,Token词表:50257个Token,涵盖多个国家文字,包含中文汉字。
- 2023年的GPT-4,Token词表:100256个Token,涵盖上百个国家文字。
- 2024年的Llama 3,Token词表:128000个Token,涵盖200多个国家文字。
Token化非常有利于减少词表的数量(Token的总数少于文字的总数)
Embedding(向量化)
Embedding其实就是把Token变成数学向量。
在了解Embedding之前,我们需要先了解3个概念:向量、空间、特征。
向量
什么是向量?
1维向量:坐标 [ 3 ],一维空间中的一个点
2维向量:坐标 [ 2, 5 ],二维空间中的一个点
3维向量:坐标 [ -1, 4, -2.5 ],三维空间中的一个点
...
...
512维向量:坐标 [ 3, 5, -2, ...... ],512维空间中的一个点
向量是每个Token都能通过Embedding模型,映射到新的数学空间中的一个点。
我们了解到向量是多维数学空间内的一个点,那么他又有什么用呢?
我们举个例子,现在我有3000个常见的中文汉字,我通过one-hot编码,把它们都变为一个3000维的数学向量,如下图所示:

这个时候,我们会发现三个问题:
- 维度过高,过于稀疏:容纳3000个汉字就需要3000 * 3000的映射表,容纳5000个汉字则需要5000 * 5000的映射表;
- 没有体现出“距离”概念:如果两个字之间的意思相近,那两个对应的向量求“距离”的时候,就应该更相近;
- 没有数学或逻辑关系:最好能满足:国王 - 男人 + 女人 = 女王
在初识神经网络与机器学习讲到过,神经网络虽然借鉴了生物神经元的结构,但距离真正理解大脑的智能机制还很遥远,其实核心的一个原因就是LLM模型内的参数连接是使用相对稀疏的矩阵运算,这也包括数学向量维度。
可以借鉴,目前主流模型的数学向量维度:
2017年的经典Transformer,向量维度:512维
2018年的GPT,向量维度:768
2019年的GPT-2,向量维度:1600
2020年的GPT-3,向量维度:12288维
2024年的Llama 3,向量维度:16384维
空间
什么又是空间?
刚刚也讲到了,向量是多维数学空间内的一个点,那么多维空间是长什么样呢?
我以一个三维数学空间为例,如下图所示:

每个圆球的点,就是一个向量,它有3个数据 [ 3, 2, 2]。
比如2个圆球靠的比较近,就说明它们的向量含位置信息,它们的文字所在的位置也是比较相近的。
特征
特征也叫向量的相似度(距离),比如:
国王:向量a
皇帝:向量b
君王:向量c
它们距离比较近,那么它们的相似度就比较高,字母a与字母b的距离是相连的。
再拿一组数据来对比:
男人:向量e
女人:向量f
男人与国王的向量相似度 a -> e,就没有国王与皇帝的相似度 a -> b 高。
当有一系列特征时,加入神经网络模型,我们可以得出:国王 - 男人 + 女人 ≈ 女王。
这样,我们把汉字变成数学向量,不光能体现一些远近亲疏的相似度(相关性),还能拿这些数学向量做数学计算,未来的想象空间是无限的。
刚刚我们提到了神经网络,其实Embedding模型内有一个神经网络,我们通过训练数据集、测试数据集进行Pretrain(预训练) 与 SFT(有监督的微调) 来调整神经网络内的参数,从而让神经网络达成我们的要求,这样我们的数学向量内就会包含相似度(相关性)。
Embedding模型专门把我们每个Token映射到一个新的数学空间内,得到一个多维的数学向量(数学空间中的一个点)。
Positional Encoding(在向量中加入位置信息)
位置编码的作用是注入位置信息,而非进行特征提取或非线性变换。
一句话的语义除了取决于文字外,还受文字位置的影响。比如:
狗咬了猫
猫咬了狗
两句话的文字完全一样,因为每个字的位置不同,而得到了完全不同的语义。
比如:
狗的数学向量是 Embedding[0]([2, 1, 5]),当前它所在的位置向量是 Position[0]([1, 0, 0]),我们把它2个向量相加,就会得到一个新的向量Input[0]([3, 1, 5])。
它们的计算方式是:
Embedding[0] = [2, 1, 5]
Position[0] = [1, 0, 0]
Input[0] = [2 + 1, 1 + 0, 5 + 0] = [3, 1, 5]
位置编码的两种主要形式
- Sinusoidal Positional Encoding(正弦位置编码):
使用固定的正弦和余弦函数生成,不包含任何可训练参数,因此不是神经网络的一部分 。 - Learned Positional Embedding(可学习位置编码):
虽然通过训练得到,但它通常只是一个嵌入查找表(embedding table),其输出直接加到词嵌入上。尽管涉及参数学习,但该过程没有神经网络层的非线性变换或权重计算,一般也不被视为神经网络 。
Encoder(编码器) & Decoder(解码器)
Encoder(编码器) 和 Decoder(解码器)是Transformer的核心阶段。
Decoder Only、Encoder Only架构在不同的模型上进行使用。
Encoder(编码器)
Endcoder(编码器) 擅长把我们真实世界里面人类可以看懂的一些文字、图片或者东西,变成一个数学向量,这个数学向量是人类看不懂,但是机器可以看懂的多维数学向量(含相似度)。
简而言之,Encoder(编码器) 是把一句话变成一个向量(含相似度)。
Endcoder(编码器)擅长做分析类的任务。
以文字与文字、文字与图片来举例:
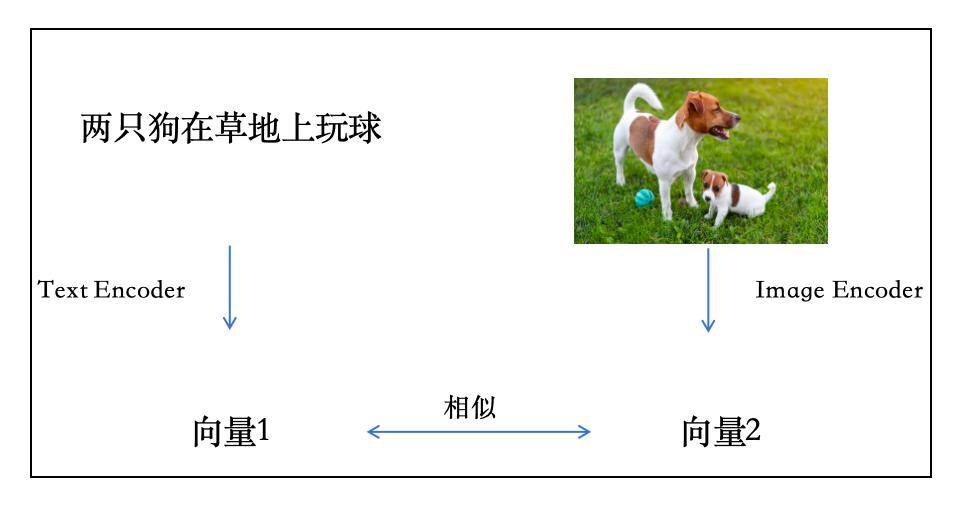
Text Encoder(文字编码器)and Text Encoder ,如图所示:
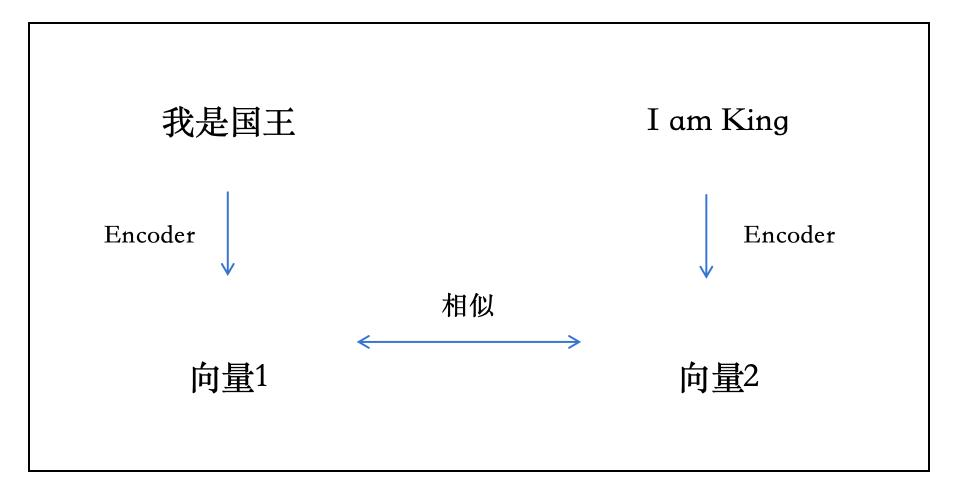
Text Encoder(文字编码器)and Image Encoder(图片编码器) 也能对比向量相似度,如图所示:
Encoder编码流程
我们人类看一篇文章是按照从左到右、从上到下,依次就行阅读。但是AI不像人一样,它是同时在看所有的字,然后把汉字进行Token化,然后把Token转化为数学向量,最后再通过数学向量之间的计算,去深刻理解这篇文章里面的每个字、词、段落的意思。
数学向量之间的计算,以及深刻理解这篇文章里面的每个字、词、段落的意思,就涉及到Encoder编码,这也是Transformer的核心阶段。
举例:
在GPT-3模型内,650个汉字对应1300个12288维的数学向量,在Encoder编码流程中,为了让AI更精准的理解、消化向量所包含的意思,会依次把每个数学向量做为中心主题词,与其他1299个向量进行相似度比对,然后做信息聚合,把1299个向量的信息加到当前向量(中心主题词) 上,让当前向量(中心主题词) 可以表达的意义与含义更全面、丰满,这么一个流程就叫做一轮batch。我们要做1300轮batch后,才算完成第一轮信息聚合(epoch)。完成第一轮聚合(epoch)后,我们会把新的1300个聚合后的数学向量(聚合后的数学向量能表达更全的语义),再进行向量间相似度分析,这轮分析就变成短语与短语的聚合,最后形成的向量信息就更全,语义更丰满,等做完1300次batch后,就完成第二轮信息聚合(epoch)。
一般都要完成2~3轮的信息聚合(epoch) 就可以让AI完整的理解该文章内所表达的含义、语义。
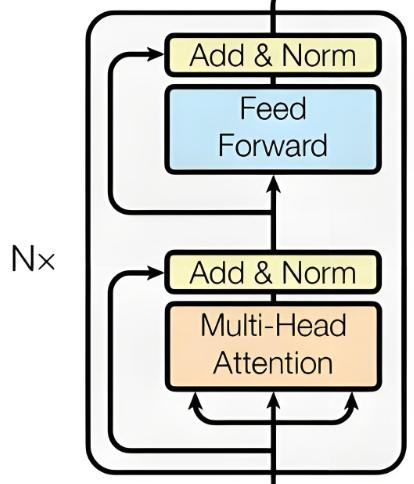
Encoder(编码器)的架构图:
Decoder(解码器)
Decoder(解码器)是把数学空间内,人类看不懂的数学向量转化为人类可以看得懂的东西(文字、图片等信息)。
Decoder(解码器)擅长做生成类的任务。
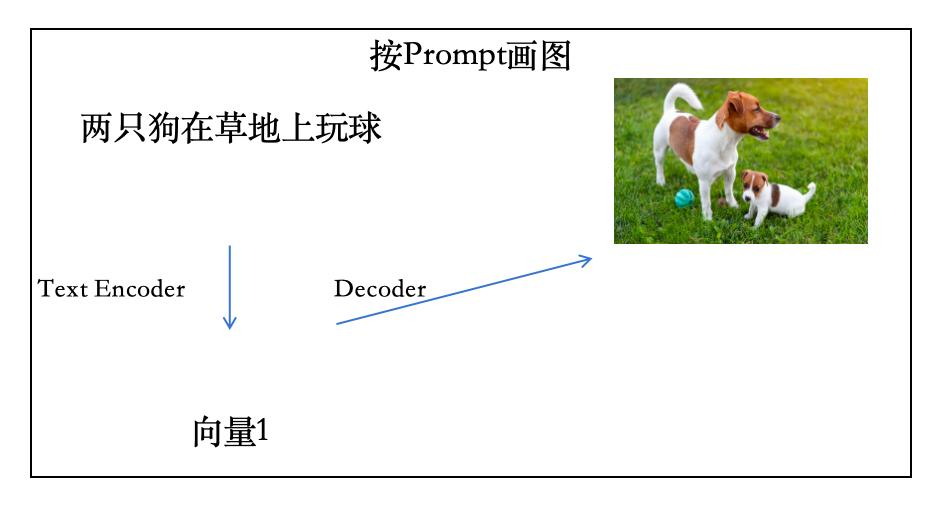
以文字与图片来举例:
Text Encoder(文字编码器)Decoder Image,如图所示:
Decoder解码流程
Decoder解码流程与Encoder解码流程在信息聚合(epoch) 上有部分流程一致。
在Decoder解码过程中,有2部分输入:
- Prompt(提示词) 或者Encoder(编码器) 聚合好的向量信息;
- 之前Decoder(解码器) 输出的向量信息。
这2部分信息都是AI可理解的信息,拿到Decoder(解码器) 的输入信息,通过神经网络,得到信息聚合(epoch),最终输出下一个字与对应的向量信息。
Decoder(解码器) 与 Encoder(编码器) 在信息聚合(epoch) 上有区别,
Encoder(编码器) 的信息聚合(epoch) 是把每个数学向量依次做为中心主题词,与其他1299个数学向量进行信息聚合(epoch),
Decoder(解码器) 的信息聚合(epoch) 也是把每个数学向量 依次做为中心主题词,但是它只会聚合当前向量前面的向量集数据,处于当前向量后面的向量信息是不进行信息聚合(epoch),这也导致,只有最后一个数学向量才包含所有文字想要表达的信息/语义。
一般Decoder(解码器) 有96轮信息聚合,信息聚合(epoch) 轮数越多,每个向量 里面包含的信息就越丰富。
聚合轮次是有算法工程师进行指定。
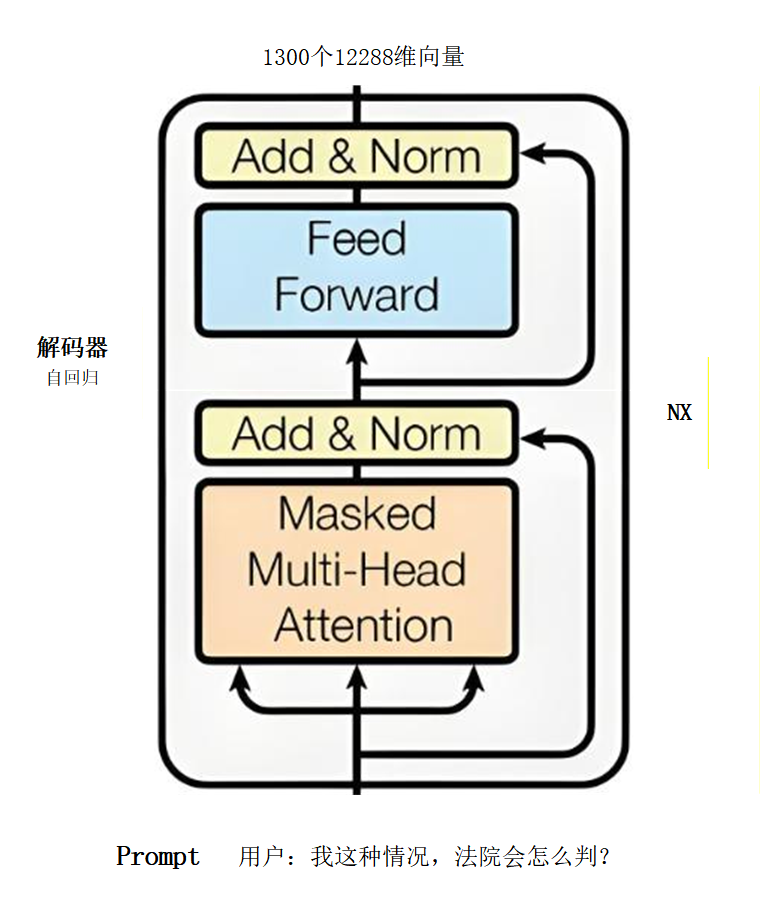
Decoder(解码器)展示最新架构图:
Linear & Softmax
Linear
Linear:生成“下一个字”的权重分布。
Linear流程:
Decoder(解码器) 阶段完成后,会得到一个聚合向量(该向量表达了该段文字所有要表达的信息),然后这个聚合向量会去Token与向量映射表内进行相似度计算(点乘),得到相似度系数,相似度系数越大,下个字就是它,数字越小,它越不适合做为下个字来展示。
Softmax
Softmax也叫归一化。
Linear阶段输出相关度信息集(5万个相关度数值)进行Softmax(归一化) 计算后,会得到5万个概率信息集,这5个万概率信息集加起来会等于1(100%)。
当前模型阶段处于Pretain(预训练)、SFT(有监督的微调) 阶段,每次进行汉字的输出,它都在做Transformer - Softmax(归一化) 阶段得到概率集信息,然后与训练、测试数据集进行对比,会得出一个正常结果的汉字在当前概率集内的概率值,然后通过损失函数(对数函数,y = lnX) 来计算误差值,一段文字的误差值相加就是总误差值,通过总误差值来进行模型内参数的调整。
只要模型内参数变化了,向量也会变化。
Transformer整个框架结构(手纸稿)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)