Hermes Agent开源45天登顶GitHub,深度解析其记忆机制与部署方案
·
一、项目背景
Hermes Agent开源45天,GitHub星标突破6.6万。作为对比,Claude Code达到同等星标用了半年时间。
本文从技术视角,分析Hermes Agent的核心架构、记忆机制,并提供完整的部署方案。另附「Hermes Agent 完整部署教程」可自取。
二、技术架构分析
2.1 与传统AI Agent的差异
传统AI Agent(包括OpenClaw)本质上是无状态的:
- 每次对话独立
- 用户偏好无法持久化
- 历史需求无法复用
Hermes的设计理念完全不同,采用闭环学习系统。
2.2 闭环学习系统架构
┌─────────────────────────────────────────┐
│ 用户需求输入 │
└─────────────────┬───────────────────────┘
│
┌─────────────────▼───────────────────────┐
│ 需求理解与解析 │
└─────────────────┬───────────────────────┘
│
┌─────────────────▼───────────────────────┐
│ 跨会话记忆召回(核心) │
│ - 从Memory检索历史相关内容 │
│ - 向量相似度匹配 │
└─────────────────┬───────────────────────┘
│
┌─────────────────▼───────────────────────┐
│ 任务执行 │
└─────────────────┬───────────────────────┘
│
┌─────────────────▼───────────────────────┐
│ 动态Skill生成(关键特性) │
│ - 识别重复任务模式 │
│ - 自动创建可复用技能 │
└─────────────────────────────────────────┘
2.3 核心技术点
1. 跨会话记忆召回
不是简单的关键词检索,而是:
- 向量化存储用户历史需求
- 语义相似度匹配
- 关联任务链召回
2. 动态Skill生成
当识别到用户反复执行某类任务时:
- 自动抽象任务模式
- 生成可复用的Skill
- 后续直接调用,无需重复配置
3. 技术栈
- 语言:Python(比Node.js更轻量)
- 部署:Docker容器化
- 存储:本地持久化+向量数据库
- 浏览器:Camoufox(隐身浏览器)
三、部署方案
3.1 环境要求
| 组件 | 最低要求 | 推荐配置 |
|---|---|---|
| 内存 | 4GB | 8GB+ |
| CPU | 2核 | 4核+ |
| 存储 | 10GB | 20GB+ |
| 系统 | Linux/macOS/Windows | Linux |
3.2 Docker部署
Step 1:创建docker-compose.yml
services:
hermes:
image: hermes/hermes:latest
container_name: hermes-agent
environment:
- LOG_LEVEL=INFO
- LLM_PROVIDER=openai
- LLM_MODEL=gpt-4
- LLM_API_KEY=${LLM_API_KEY}
volumes:
- ./data:/app/data
- ./config:/app/config
ports:
- "8000:8000"
deploy:
resources:
limits:
memory: 4G
cpus: '2'
restart: unless-stopped
Step 2:启动容器
docker-compose up -d
Step 3:进入容器配置
docker exec -it hermes-agent /bin/bash
3.3 渠道配置
Hermes原生支持以下渠道:
| 渠道 | 说明 |
|---|---|
| 企业微信 | 企业内部使用 |
| 微信 | 个人微信接入 |
| 飞书 | 字节跳动旗下 |
| 钉钉 | 阿里旗下 |
通过插件还可支持QQ等渠道。
3.4 模型选择
这是最关键的配置,模型选错会严重影响体验。
推荐方案:
| 场景 | 推荐模型 | 说明 |
|---|---|---|
| 云端(高性能) | GPT-4 / Claude | 效果最好,但成本较高 |
| 云端(性价比) | DeepSeek / GLM | 国产模型,性价比高 |
| 本地部署 | Gemma 4 26B | 通过Ollama运行 |
模型切换命令:
# 设置模型提供商
hermes config set llm.provider openai
# 设置模型名称
hermes config set llm.model gpt-4
# 设置API密钥
hermes config set llm.api_key sk-xxx
四、核心功能与应用场景
4.1 自动化运维
场景:网站监控+自动修复
# 示例:Hermes自动处理用户报告
def auto_fix_metadata():
# 1. 读取用户报告
reports = hermes.read_reports()
# 2. 对照现有数据检查
for report in reports:
if hermes.validate(report):
# 3. 应用修复
hermes.apply_fix(report)
# 4. 记录变更
hermes.log_change(report)
技术要点:
- Camoufox隐身浏览器:避免被网站检测
- Firecrawl:结构化数据提取
- 自动化流程:无人值守运行
4.2 智能知识库
场景:Karpathy LLM Wiki模式
架构设计:
原始信息源(只读)
↓
Wiki页面(AI维护)
↓
Schema规则(保证一致性)
效果:
- 用一个月后,形成复利增长的知识库
- 信息互相链接,可追溯
4.3 自动化交易
场景:Solana链上自动交易
工作流程:
AI分析市场 → 生成策略 → 测试验证 → 部署执行 → 持续优化
关键能力:
- 策略自动生成
- 自动回测验证
- 部署到真实账户
- 持续迭代优化
五、企业微信集成方案
5.1 原生支持
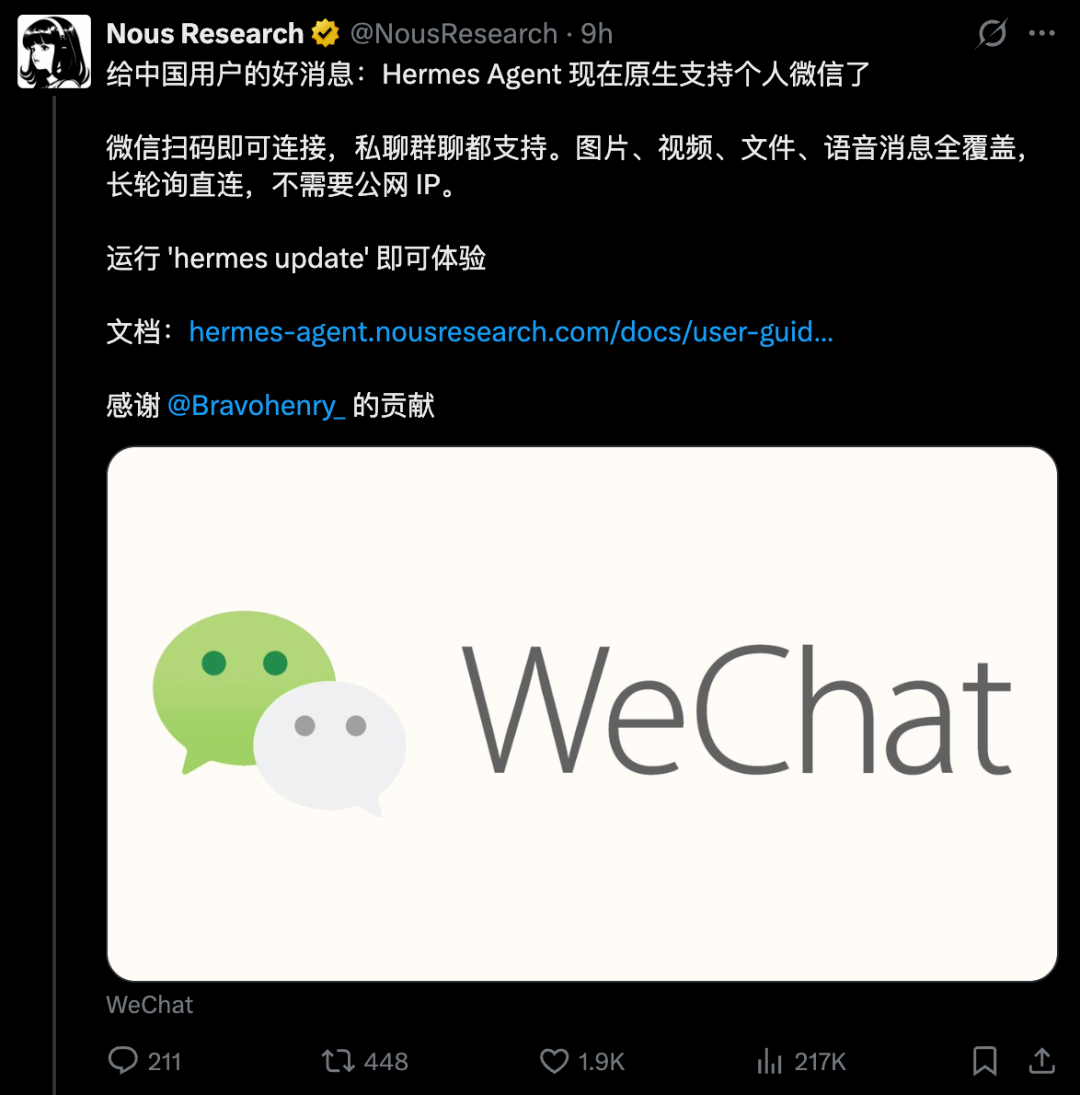
Hermes原生支持企业微信连接,配置后可:
- 在企业微信中直接对话
- 定时任务推送
- 消息自动处理
- 工作流自动化
5.2 企业封装方案
对于企业用户,可以选择服务商提供的封装方案:
优势:
- 无需自己部署
- 开箱即用
- 集成多模型能力(DeepSeek、GPT、Gemini、GLM等)
- 内置企业知识库对接
- 专业技术支持
六、技术局限与发展方向
6.1 当前局限
| 问题 | 说明 |
|---|---|
| 记忆噪音 | 召回相关记忆时可能引入噪音 |
| 技能质量不稳定 | 自动生成的Skill质量参差不齐 |
| 部署门槛 | 需要选对模型,可能遇到bug |
| 多智能体协作 | 尚在探索阶段 |
6.2 发展方向
- 记忆机制优化:减少噪音,提高召回精度
- Skill质量提升:自动验证和优化
- 部署简化:降低技术门槛
- 多智能体协作:支持复杂任务分工
七、总结
Hermes Agent的核心创新在于闭环学习系统:
- 跨会话记忆召回:不是简单的关键词匹配,而是语义级别的关联召回
- 动态Skill生成:从用户行为中自动抽象可复用能力
- 持续进化:用得越久,越懂用户
技术选型建议:
- 个人开发者:自己部署,选择开源方案
- 企业用户:选择服务商封装方案,降低运维成本
参考资料
- Hermes GitHub:https://github.com/hermes-agent/hermes
- Ollama官方文档:https://ollama.ai
- Camoufox项目:https://github.com/camoufox/camoufox
- Hermes Agent 完整部署教程:https://college.wshoto.com/a/308763.html
本文从技术视角分析Hermes Agent,仅供学习交流。实际部署请参考官方文档。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)