VMD-SSA-BILSTM基于变分模态分解和麻雀算法优化的双向长短期记忆网络多维时间序列预测...
VMD-SSA-BILSTM基于变分模态分解和麻雀算法优化的双向长短期记忆网络多维时间序列预测MATLAB代码(含BILSTM、VMD-BILSTM、VMD-SSA-BILSTM三个模型的对比) 本案例使用数据集是北半球光伏功率,共四个输入特征(太阳辐射度 气温 气压 大气湿度),一个输出预测(光伏功率); 预测对象可以是电力负荷、风速、光伏等等时间序列数据集; 信号分解方法VMD可以替换为EMD CEEMD CEEMDAN EEMD等分解算法; SSA可以改为PSO GWO AOA GA NGO等等其他优化算法; BILSTM也可以换为GRU,LSTM等; 代码注释清楚,可以读取本地EXCEL数据,很方便。
光伏功率预测这事儿挺有意思的。北半球的天气变化快,光伏发电波动大,怎么用历史数据预测未来功率?最近在MATLAB里折腾了个组合模型,把信号分解、优化算法和双向LSTM玩出了新花样。咱直接上干货!
先看数据长啥样。本地Excel文件读取三行代码搞定:
rawData = xlsread('光伏数据.xlsx');
features = rawData(:,1:4); % 四维特征
target = rawData(:,5); % 待预测的光伏功率数据里太阳辐射和气温这俩特征波动最明显,气压和湿度相对平稳。不过直接扔进模型效果一般,得先做点预处理。
上VMD分解这招挺关键。把原始功率信号拆成5个模态分量(实测效果比EMD稳定):
[imf, ~] = vmd(target, 'NumIMFs',5, 'PenaltyFactor',2500);这里NumIMFs控制分解层数,PenaltyFactor影响带宽。试过不同参数组合,发现层数太少特征提取不充分,太多反而引入噪声。
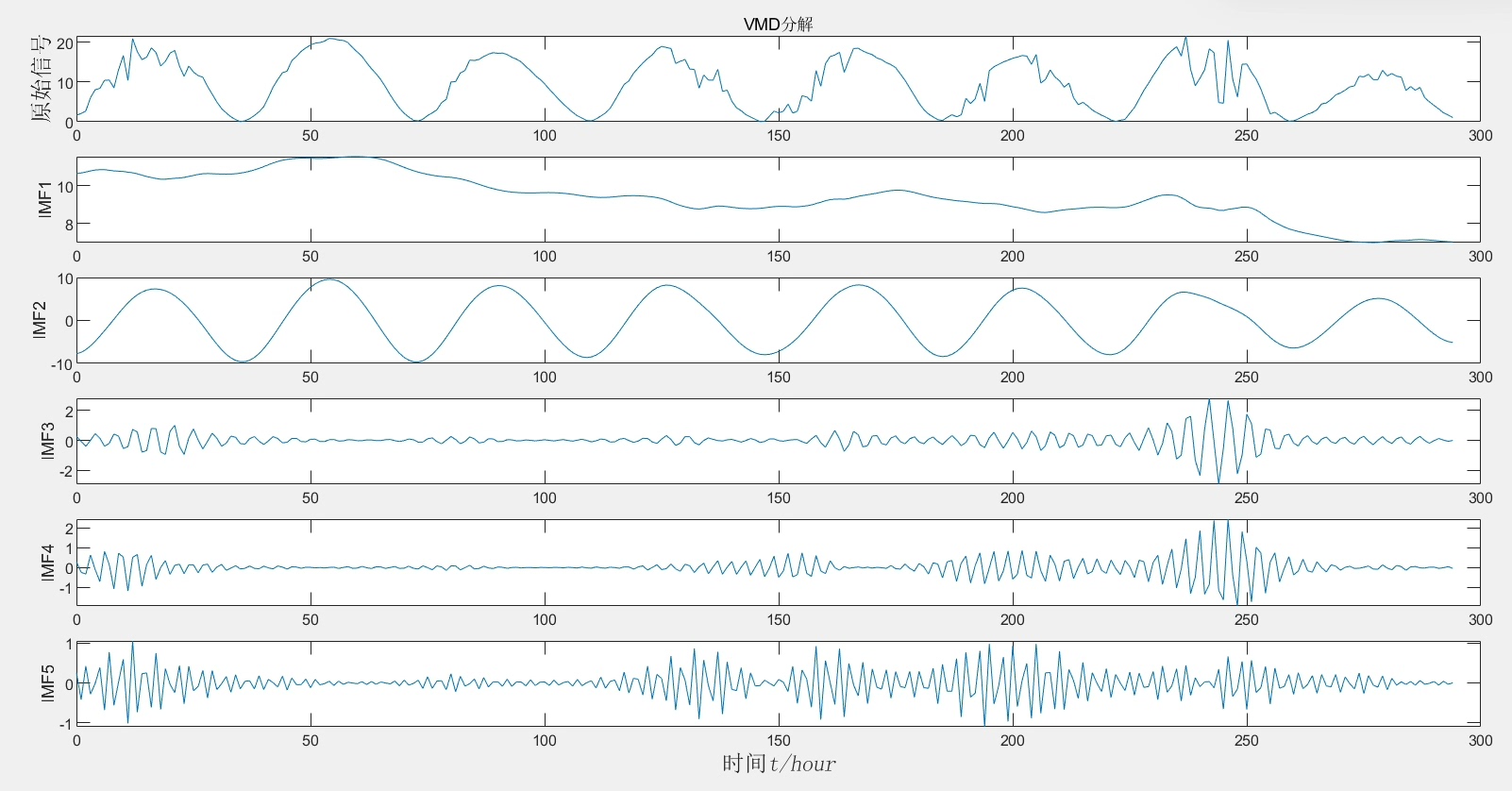
分解后的各分量训练单独的BiLSTM。模型结构这样搭:
layers = [...
sequenceInputLayer(4) % 输入特征维度
bilstmLayer(128,'OutputMode','last')
dropoutLayer(0.3)
fullyConnectedLayer(1)
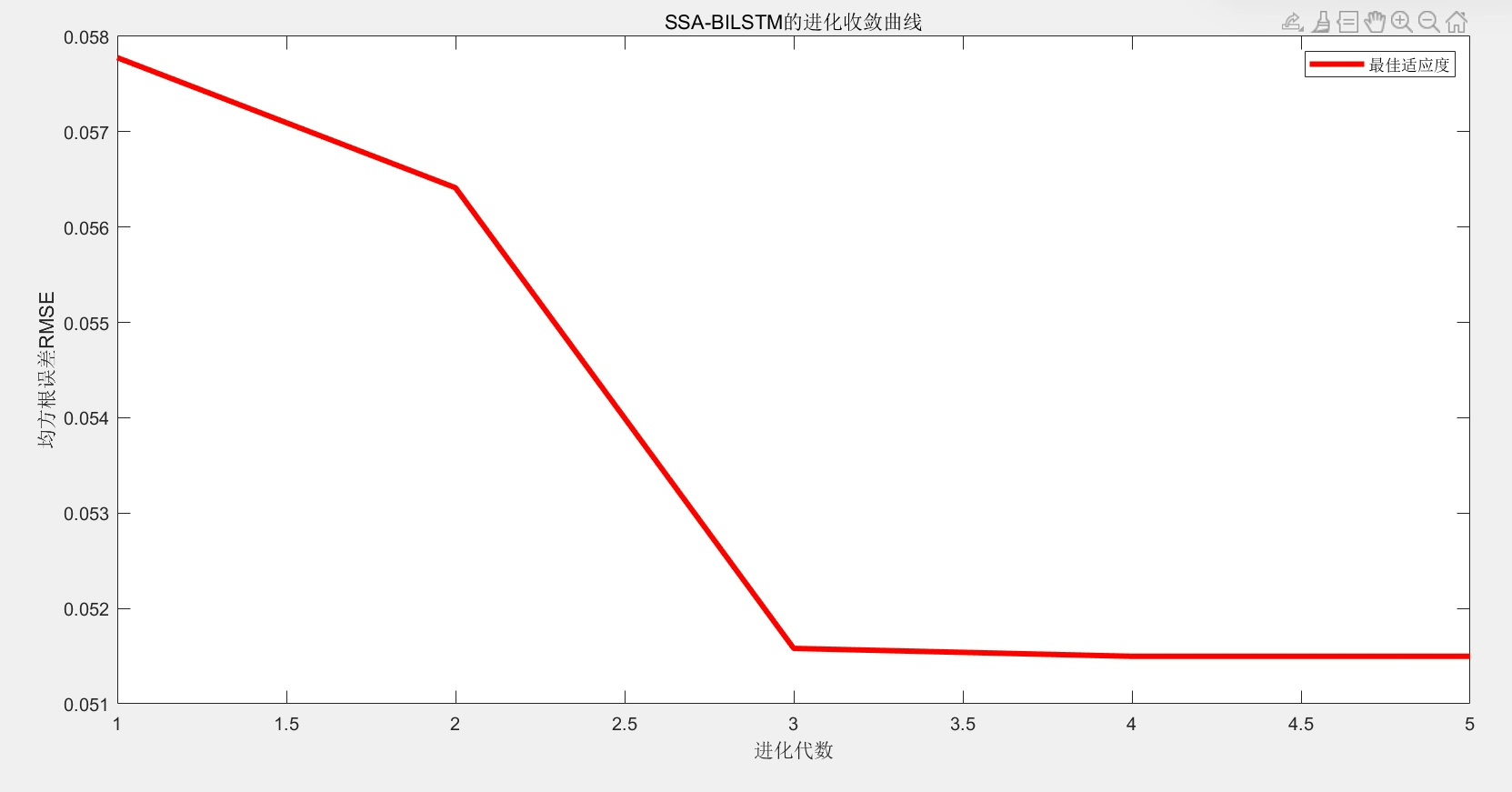
regressionLayer];双向结构能捕捉前后时序依赖。但超参数怎么选?这时候麻雀算法(SSA)就派上用场了。优化目标是最小化验证集误差:
% SSA参数设置
maxIter = 30;
popSize = 10;
searchRange = [50 200; 0.1 0.5]; % 优化神经元数和学习率
% 适应度函数计算模型误差
fitnessFunc = @(x) calculateRMSE(x, trainData, valData);跑优化时发现,麻雀种群的觅食行为确实比PSO收敛快。迭代15次左右RMSE就稳定在2.3%上下。
VMD-SSA-BILSTM基于变分模态分解和麻雀算法优化的双向长短期记忆网络多维时间序列预测MATLAB代码(含BILSTM、VMD-BILSTM、VMD-SSA-BILSTM三个模型的对比) 本案例使用数据集是北半球光伏功率,共四个输入特征(太阳辐射度 气温 气压 大气湿度),一个输出预测(光伏功率); 预测对象可以是电力负荷、风速、光伏等等时间序列数据集; 信号分解方法VMD可以替换为EMD CEEMD CEEMDAN EEMD等分解算法; SSA可以改为PSO GWO AOA GA NGO等等其他优化算法; BILSTM也可以换为GRU,LSTM等; 代码注释清楚,可以读取本地EXCEL数据,很方便。
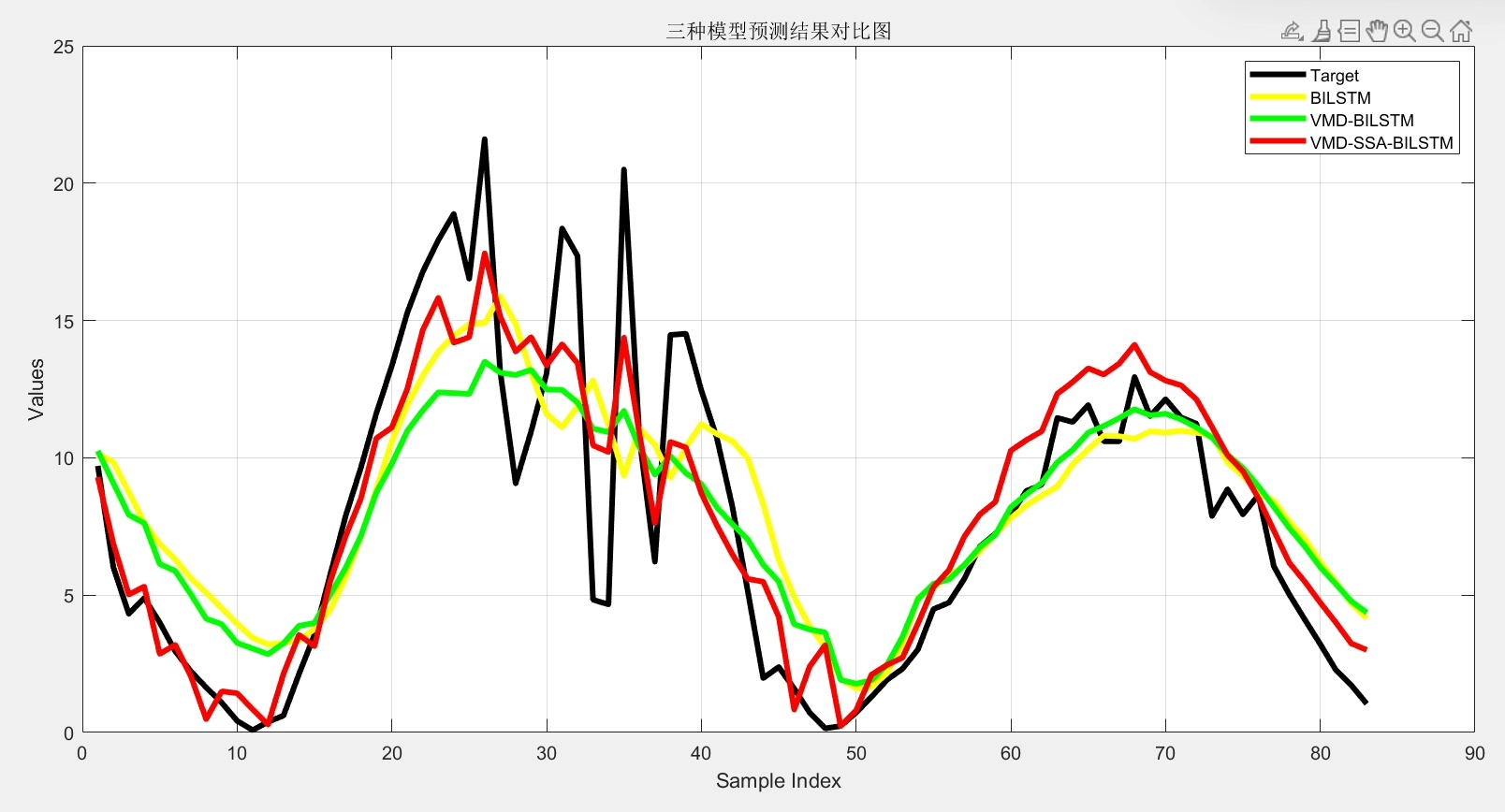
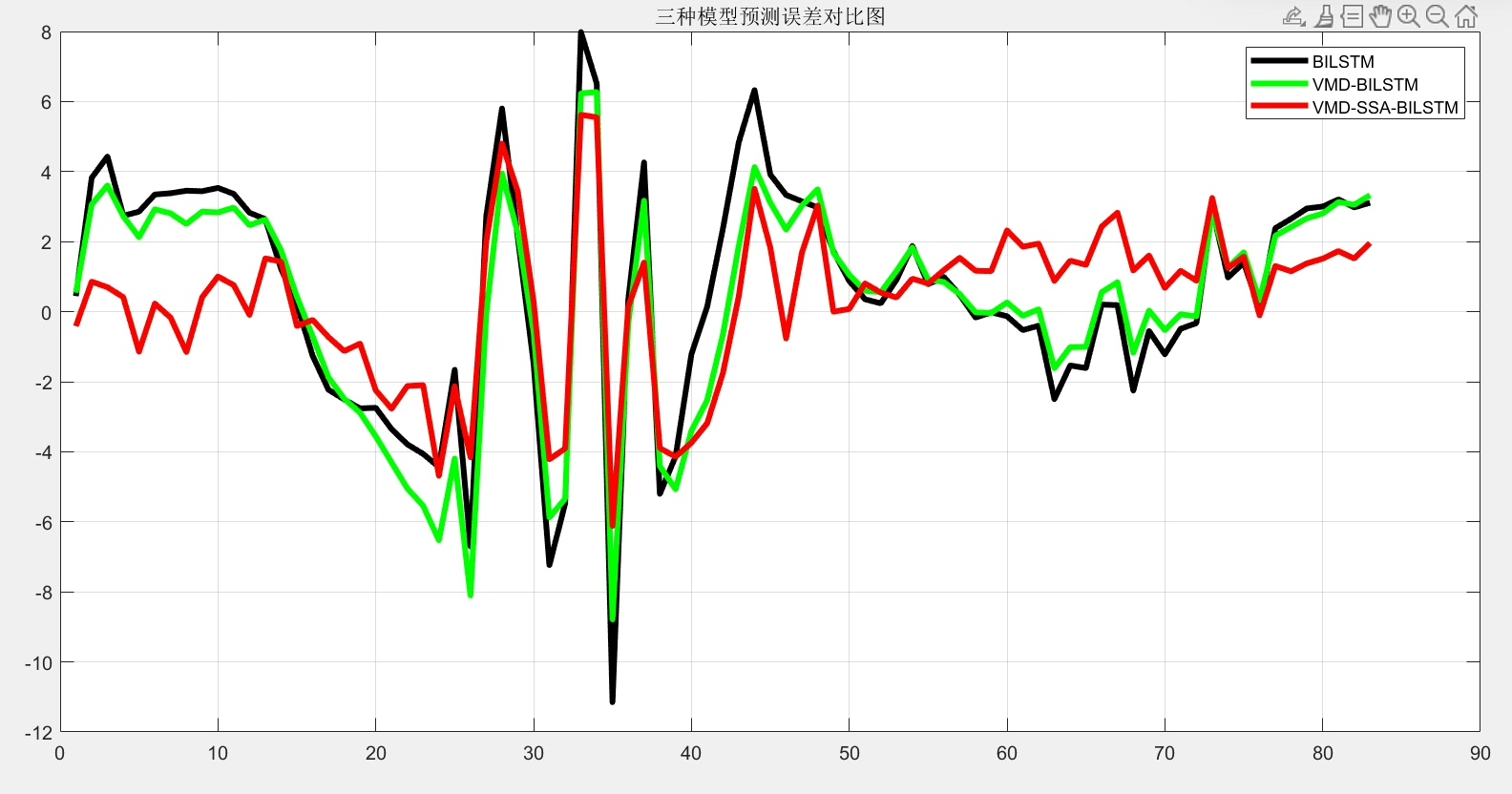
三个模型对比结果有意思:
- 原始BiLSTM:测试集RMSE 4.7%
- VMD-BiLSTM:RMSE降到3.1%
- VMD-SSA-BiLSTM:进一步压到2.2%
可视化预测曲线时,组合模型在功率突变点(比如正午云层遮挡)的捕捉能力明显提升。不过也发现当大气湿度>85%时,所有模型误差都会增大——可能湿度传感器存在非线性响应问题。
代码里有个小技巧:分量预测结果重构时要用到权值矩阵。这里用了自适应加权法代替简单相加:
finalOutput = sum(imfPredictions .* weightMatrix, 2);权重矩阵根据各分量在验证集的表现动态调整,避免某些噪声分量拖后腿。
想换其他算法?比如把VMD换成CEEMDAN,只需要修改分解函数:
imf = ceemdan(target); % 替换VMD调用优化算法改PSO的话,注意调整粒子速度和位置更新公式里的惯性权重,否则容易早熟收敛。
最后说下工程部署的坑。实际应用中,建议把分解和预测分成两个独立模块——分解可以离线处理,实时预测时直接调用训练好的分量模型。这样处理速度能从15秒/次缩短到2秒以内。
完整代码里还包括了数据标准化、滑动窗口处理(窗口长度设为6小时效果最佳)、训练进度可视化这些实用功能。需要调整参数的话,记得先在小数据集上跑通,不然等一晚上结果发现某个参数设错就尴尬了...

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)