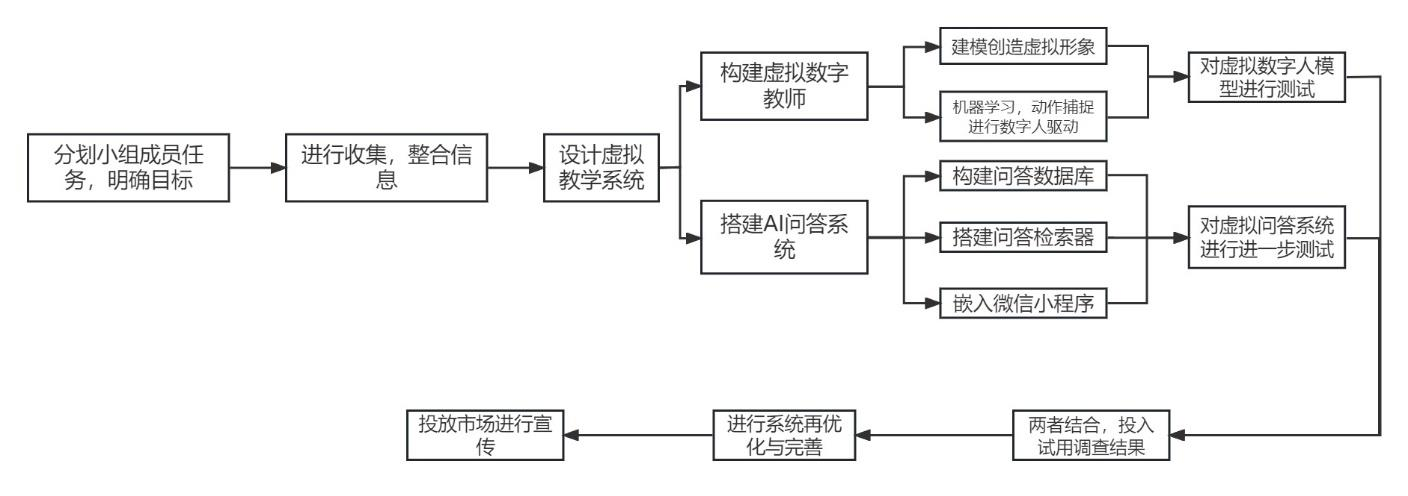
复试简历复盘--大创
自我介绍部分:大一的时候参与了大学生创新创业项目,在老师的指导下学习阅读文献、撰写申报书,最终项目获得了国家级立项,并基于这个项目以第一作者身份发表了一篇 EI 会议论文。由于当时年级还比较低,后续系统实现我参与相对较少,所以这段经历对我来说更重要的是科研启蒙和文献阅读训练。同时在大一的时候,我开始接触算法竞赛,因为比较感兴趣,就 先于学校课程自学了 C++ 和数据结构等内容。
因为你提到 两篇论文 + 国创项目,导师很可能追问。
关于国创项目:这个项目是我大一时参与的一个国家级大创项目,我当时主要参与的是前期申报阶段的工作,主要负责文献阅读、资料整理和申报书撰写。通过这个过程,我对项目的研究背景、整体目标和大致技术路线有了比较初步的认识。项目本身是围绕智慧教学场景展开的, 结合了课堂问答、小程序呈现等内容。因为当时我还是大一,科研和工程基础都比较有限, 所以后续系统实现和具体开发我参与得相对少一些,并不是我主导完成的。对我来说,这 段经历更重要的收获是第一次接触科研训练,学会了怎么查阅文献、梳理研究现状,以及 怎么把一个想法整理成比较规范的项目申报材料。
研究背景
顺应时代发展的趋势,各地学校要积极打造教育元宇宙教学空间,让教师适应“元宇宙”教学场景,并在教育元宇宙空间开展丰富多彩的教学活动。
研究基础:随着人工智能(Artificial Intelligence,AI)、扩展现实(Extended Reality,XR)、物联网(Internet of Things,IoT)、5G、区块链、数字孪生、脑机控制等新技术的迅猛发展,“元宇宙”快速走进大众视野。2021 年 10 月 29 日,扎克伯格将“脸书”(Facebook)更名为“元”(Meta),“元宇宙”成为了年度流行热词,2021 年亦被视为“元宇宙元年”。2021 年 3 月,元宇宙第一股 Roblox(沙盒游戏平台)上市,它是第一家把“元宇宙”概念写进招股书的公司。同年 10 月,扎克伯格宣布将社交平台 Facebook 更名为 Meta,这个名字正是来源于 Metaverse(元宇宙)。元宇宙的进程可谓一点即燃。
文献阅读
有一篇文献贡献较大《中小学教育元宇宙空间的构建及其教学应用》,来自广州市电化教育馆。这篇文章提出了“三师课堂”的概念,里面提出采用虚拟数字人教师进行线上教学,人类教师在线下进行面对面的实时讲解,智能机器人教师作为实体助教进行答疑,三类教师角色不同、分工不同,协同完成教学任务。
基于实现考虑,我改了一些思路,虚拟数字教师线上教学,人类教师在线下进行督促讲解,以及设计实现一个课堂 AI 问答系统,让学生随时随地可以通过微信小程序平台向系统提出一个课堂中知识点的疑问。
主要技术
主要采用 检索增强问答架构。
首先使用 BM25 和 TF-IDF 检索算法从问答库和知识文档中选取相关文本;然后利用 DrQA Retriever筛选候选文章;接着使用 BERT 阅读理解模型对候选文本进行语义理解并抽取答案;最后通过 答案选择器融合多源结果,输出最优回答。整个系统最终通过 微信小程序前端提供智能问答服务。





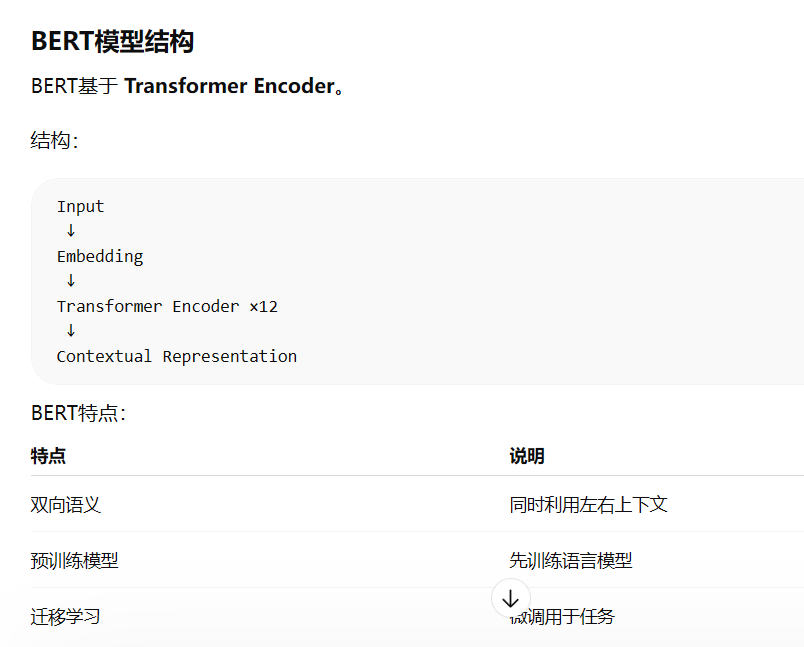


在本系统的问答检索模块中,主要采用 BM25 与 TF-IDF 等经典信息检索算法实现文本相关性计算,从而从大量文档或问答库中快速筛选出与用户问题最相关的候选内容。其核心思想是通过统计查询词在文档中的分布情况来衡量文本之间的语义相关性。
TF-IDF(Term Frequency–Inverse Document Frequency)是一种基础的文本表示方法。该方法通过两个指标来衡量词语的重要程度:词频(TF)表示某个词在当前文档中出现的频率,反映该词对当前文本主题的重要性;逆文档频率(IDF)表示该词在整个语料库中的稀有程度,如果一个词在很多文档中都频繁出现,则其区分能力较弱,因此其权重会被降低。通过将 TF 与 IDF 相乘,可以得到词语在某一文档中的综合权重,从而构建出文档的向量表示。在检索过程中,系统会将用户问题与文档转换为 TF-IDF 向量,并通过相似度计算来判断两者的相关程度,从而筛选出最相关的候选文本。
在 TF-IDF 的基础上,本系统进一步采用 BM25(Best Matching 25)算法对候选结果进行排序优化。BM25 是一种基于概率信息检索模型的改进算法,它在计算相关性时不仅考虑查询词在文档中的出现频率,还引入了 文档长度归一化机制,以避免长文档由于包含更多词而在检索中获得不公平优势。同时,BM25 通过两个参数 k1 与 b 对词频增长速度和文档长度影响进行调节,使得相关性评分更加稳定和合理。通过综合考虑 词频、逆文档频率以及文档长度因素,BM25 能够更准确地评估文档与查询之间的匹配程度,从而提升检索结果的排序质量。(BM25 是一种经典 概率信息检索模型(Probabilistic Retrieval Model),常用于搜索引擎排序。其核心思想是:通过统计查询词在文档中的出现情况来计算相关性得分。)
在系统实际运行过程中,用户问题首先经过分词和文本预处理,然后利用 TF-IDF 或 BM25 算法计算其与知识库中文档的相关性得分,系统会选择得分最高的若干条候选文本(通常为 5 至 8 条)作为后续语义理解模块的输入。通过这一检索机制,可以在大规模文本数据中快速定位可能包含答案的内容,为后续的深度学习阅读理解模型提供高质量的候选文本,从而显著提升问答系统整体的响应效率和准确率。
这个项目是大一参加的一个团队科研项目。当时主要负责前期的文献调研和项目申报书撰写,包括查阅问答系统相关论文,总结了BM25检索、TF-IDF文本表示以及BERT阅读理解等技术路线,并参与设计了系统的整体流程。
后期系统的工程实现主要由团队其他成员完成,最终的小程序版本采用了调用大模型API的方式实现问答功能。我没有深度参与具体开发,但对系统整体的技术方案和实现思路是比较了解的。
“那你当时调研的技术路线是什么?”
可以回答:
当时调研的是典型的检索式问答系统架构。首先利用BM25或TF-IDF从知识库中检索相关文档,然后利用BERT进行阅读理解,从候选文章中抽取答案,最后通过评分机制选择最合适的回答。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)