第一篇:四大名著自然语言处理实战教程第二篇:AI编程助手使用教程 第三篇:自然语言处理的应用与我的兴趣
第一篇:四大名著自然语言处理实战教程
一、引言
作为软件工程专业大三学生,本学期在《Python与数据分析》课程中学习了自然语言处理基础知识。为了深入理解中文分词、词频统计、可视化等技术,我选择四大名著作为分析对象,完成了一个完整的NLP分析项目。
二、程序实现的功能
本程序实现了以下功能,并全部封装为函数:
| 功能模块 |
函数名 |
说明 |
| 文本加载 | load_text() | 读取TXT文件 |
| 中文分词 | cut_words() | 使用jieba精确模式分词 |
| 词频统计 | count_words() | 统计高频词 |
| 词性标注 | tag_words() | 标注每个词的词性 |
| 分类保存 | save_by_pos() | 按人名/地名/武器分类保存 |
| 饼状图 | draw_pie() | 可视化词频占比 |
| 柱状图 | draw_bar() | 展示TOP20高频词 |
| 词云 | draw_wordcloud() | 生成词云图 |
| 自定义词典 | load_user_dict() | 加载手动添加的词语 |
| 关系图 | draw_relation() | 展示人物共现关系 |
三、设计思想
1. 模块化设计:每个功能独立成函数,主程序只负责调用,便于调试和复用
2. 数据与逻辑分离:文本文件、停用词表、自定义词典都放在外部
3. 可视化优先:用图表直观展示分析结果,便于理解和汇报
4. 可扩展性:预留接口,方便后续添加情感分析、文本分类等功能
四、用到的库和函数详解
1. jieba —— 中文分词核心库
import jieba
import jieba.posseg as pseg
# 精确模式分词
words = jieba.cut(text)
# 词性标注
words_with_flag = pseg.cut(text)
# 加载自定义词典
jieba.load_userdict('mydict.txt')
# 动态添加词语
jieba.add_word('花果山')2. collections.Counter —— 词频统计
from collections import Counter
word_count = Counter(word_list)
top10 = word_count.most_common(10)3. wordcloud —— 词云生成
from wordcloud import WordCloud
wc = WordCloud(font_path='simhei.ttf', width=800, height=600)
wc.generate(text)4. matplotlib —— 数据可视化
import matplotlib.pyplot as plt
# 饼图
plt.pie(sizes, labels=labels, autopct='%1.1f%%')
# 柱状图
plt.bar(labels, values)
# 显示图形
plt.show()5. networkx —— 关系图
import networkx as nx
G = nx.Graph()
G.add_edges_from(relations)
nx.draw(G, with_labels=True)五、测试数据说明
• 文本来源:《红楼梦》《西游记》《水浒传》《三国演义》TXT版本(UTF-8编码)
• 自定义词典示例(mydict.txt):
text
贾宝玉 nr
林黛玉 nr
孙悟空 nr
猪八戒 nr
金箍棒 n
青龙偃月刀 n
• 停用词表(stopwords.txt):过滤掉“的”“了”“在”等无意义词
六、核心代码实现
import os
import jieba
import jieba.posseg as pseg
from collections import Counter
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import matplotlib
matplotlib.use('TkAgg') # 强制使用弹窗后端
from wordcloud import WordCloud
import networkx as nx
# 1. 加载文本
def load_text(filepath):
with open(filepath, 'r', encoding='utf-8') as f:
return f.read()
# 2. 加载停用词
def load_stopwords(filepath):
with open(filepath, 'r', encoding='utf-8') as f:
return set([line.strip() for line in f])
# 3. 分词(过滤停用词和单字词)
def cut_words(text, stopwords):
words = jieba.lcut(text)
return [w for w in words if w not in stopwords and len(w) > 1]
# 4. 词频统计
def count_words(word_list, topN=20):
counter = Counter(word_list)
return counter.most_common(topN)
# 5. 按词性分类保存
def save_by_pos(text, pos, filename):
words = pseg.cut(text)
result = [w.word for w in words if w.flag == pos]
with open(filename, 'w', encoding='utf-8') as f:
f.write('\n'.join(set(result))) # 去重保存
# 6. 绘制饼图
def draw_pie(data, title, savepath=None):
labels, sizes = zip(*data)
plt.figure(figsize=(8, 6))
plt.pie(sizes, labels=labels, autopct='%1.1f%%')
plt.title(title)
if savepath:
plt.savefig(savepath)
plt.show()
# 7. 绘制柱状图
def draw_bar(data, title, savepath=None):
labels, values = zip(*data)
plt.figure(figsize=(12, 6))
plt.bar(labels, values)
plt.title(title)
plt.xticks(rotation=45)
if savepath:
plt.savefig(savepath)
plt.show()
# 8. 生成词云
def draw_wordcloud(text, imgname):
wc = WordCloud(
font_path='simhei.ttf',
width=800,
height=600,
background_color='white',
max_words=200
).generate(text)
plt.figure(figsize=(10, 8))
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.savefig(imgname)
plt.show()
# 9. 生成人物共现关系图
def draw_relation(text, characters, imgname):
relations = []
paragraphs = text.split('\n')
for para in paragraphs:
present = [c for c in characters if c in para]
for i in range(len(present)):
for j in range(i+1, len(present)):
relations.append((present[i], present[j]))
G = nx.Graph()
G.add_edges_from(relations)
plt.figure(figsize=(12, 10))
nx.draw(G, with_labels=True, node_color='skyblue',
node_size=2000, font_size=10)
plt.savefig(imgname)
plt.show()
# 10. 主程序
def main():
# 配置路径
text_file = 'hlm.txt'
stopwords_file = 'stopwords.txt'
user_dict = 'mydict.txt'
# 加载自定义词典
if os.path.exists(user_dict):
jieba.load_userdict(user_dict)
# 加载数据
text = load_text(text_file)
stopwords = load_stopwords(stopwords_file)
# 分词
words = cut_words(text, stopwords)
# 词频统计
top20 = count_words(words, 20)
print('TOP20高频词:', top20)
# 可视化
draw_bar(top20, '《红楼梦》高频词TOP20', 'hlm_top20.png')
draw_wordcloud(' '.join(words), 'hlm_wordcloud.png')
# 分类保存
save_by_pos(text, 'nr', '红楼梦人物.txt')
save_by_pos(text, 'ns', '红楼梦地名.txt')
# 人物关系图
if os.path.exists('红楼梦人物.txt'):
with open('红楼梦人物.txt', 'r', encoding='utf-8') as f:
characters = [line.strip() for line in f if line.strip()]
if characters:
draw_relation(text, characters[:20], 'hlm_relation.png')
print('所有任务完成!')
if __name__ == '__main__':
main()
七、运行结果展示
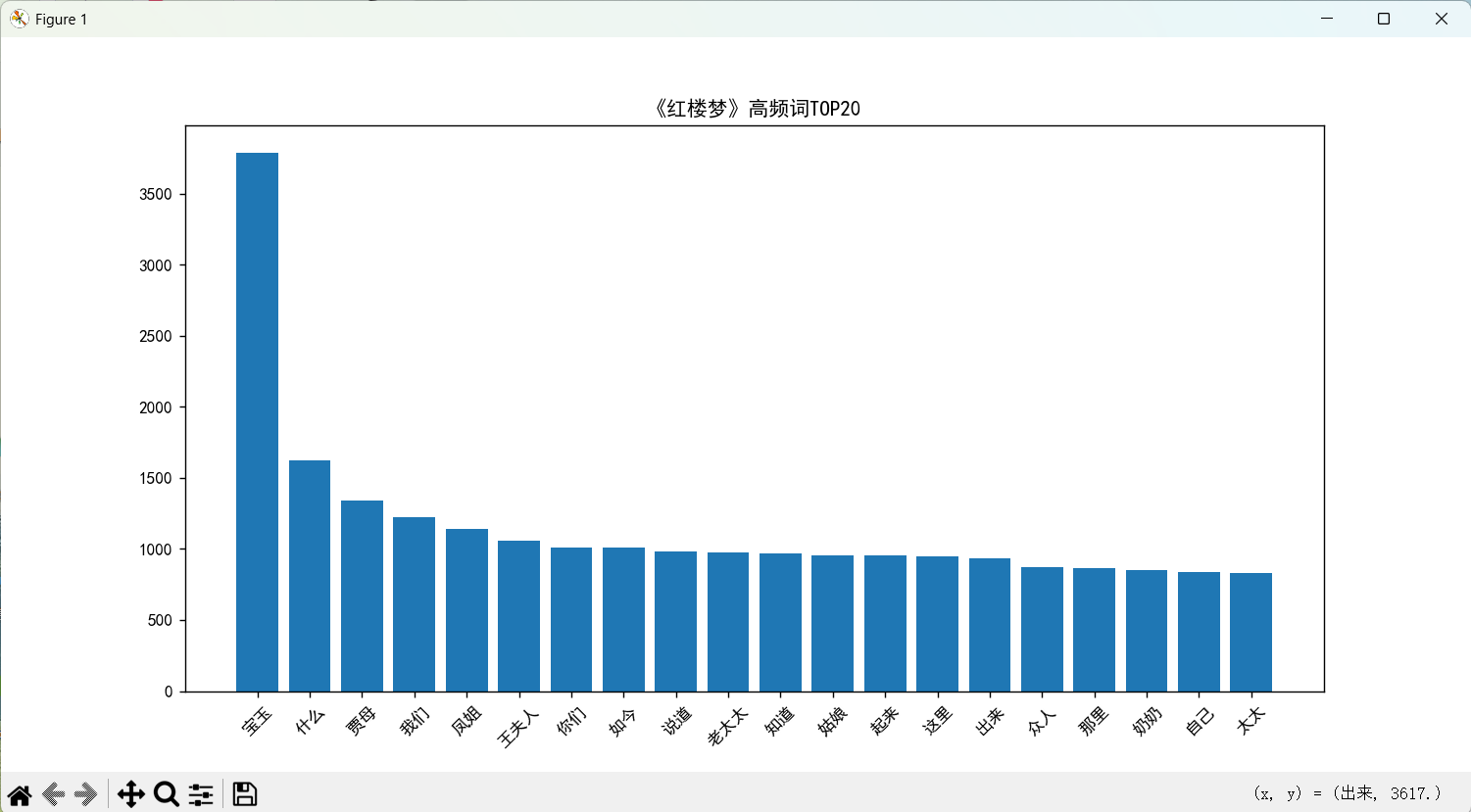
图一:红楼梦高频词柱状图

图二:词云图
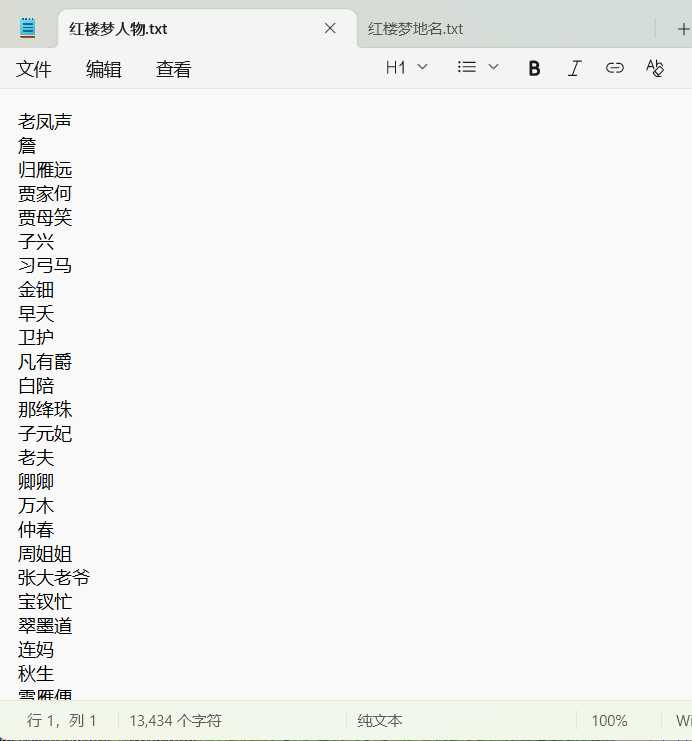
图三:红楼梦人物
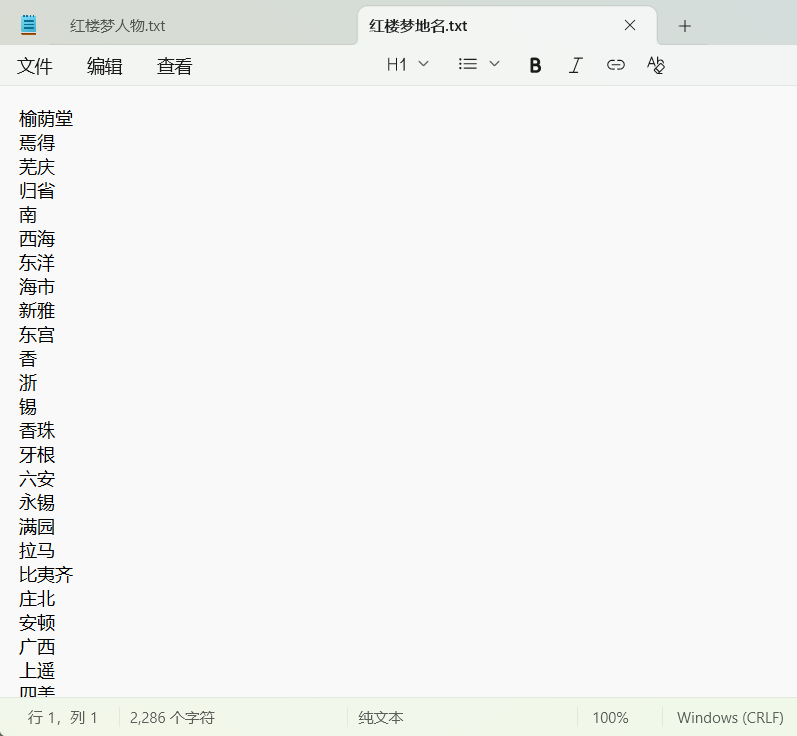
图四:红楼梦地名
八、遇到的问题及解决
1. 编码问题:TXT文件必须保存为UTF-8格式
2. 自定义词典不生效:需要在分词前加载
3. 词云中文乱码:必须指定中文字体路径
4. 内存溢出:处理大文本时分批读取
九、总结与收获
通过本次实战,我不仅掌握了jieba、wordcloud、matplotlib等库的使用,更重要的是学会了如何将自然语言处理技术应用到真实文本分析中。模块化编程思想让代码更加清晰,也为后续添加新功能打下基础。
第二篇:AI编程助手使用教程
一、引言
最近在写代码时,我开始尝试使用AI编程助手。从最开始的怀疑,到现在的“真香”,我想分享一下我对OpenClaw、CodeX等工具的使用心得。
二、什么是AI编程助手?
AI编程助手是基于大语言模型的代码生成工具,可以根据自然语言描述生成代码、解释代码、优化算法、添加注释等。
常见的AI编程助手:
| 名称 | 开发者 | 特点 |
| GitHub Copilot | GitHub/OpenAI | 基于CodeX,IDE插件 |
| CodeX | OpenAI | 强大的代码生成能力 |
| OpenClaw | 国内团队 | 免费、支持中文 |
| 通义灵码 | 阿里云 | 中文友好 |
| CodeGeeX | 智谱AI | 开源免费 |
三、OpenClaw使用教程
1. 安装
在VS Code插件市场搜索“OpenClaw”并安装
2. 基本用法
• 代码生成:输入注释,按Tab键接受建议
# 生成一个快速排序函数
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)-
代码解释:选中代码,右键选择“Explain this code”
-
代码优化:选中代码,右键选择“Optimize this code”
-
添加注释:选中代码,右键选择“Add comments”
3. 实战案例
在写四大名著NLP项目时,我需要一个函数来统计两个人物在同一段落出现的次数,OpenClaw直接帮我生成了:
def count_cooccurrence(text, char1, char2):
"""
统计两个人物在同一段落出现的次数
"""
paragraphs = text.split('\n')
count = 0
for para in paragraphs:
if char1 in para and char2 in para:
count += 1
return count四、CodeX使用教程
1. 访问方式
• 通过OpenAI API调用
• 或使用GitHub Copilot(基于CodeX)
2. 提示词技巧
• 明确需求:告诉AI你要什么
• 提供上下文:给出已有代码片段
• 分步生成:先写主逻辑,再补充细节
示例:
text
请帮我写一个Python函数,功能是:
1. 读取一个TXT文件
2. 使用jieba进行分词
3. 过滤停用词
4. 返回词频统计结果
3. CodeX生成的代码
def analyze_text(filepath, stopwords_file):
import jieba
from collections import Counter
with open(filepath, 'r', encoding='utf-8') as f:
text = f.read()
with open(stopwords_file, 'r', encoding='utf-8') as f:
stopwords = set([line.strip() for line in f])
words = jieba.lcut(text)
words = [w for w in words if w not in stopwords and len(w) > 1]
return Counter(words).most_common(20)五、AI编程助手的优缺点
优点
✅ 提高编码速度
✅ 减少查阅文档时间
✅ 提供多种实现思路
✅ 帮助学习新语法
缺点
❌ 可能生成错误代码
❌ 需要人工审核
❌ 对复杂业务理解有限
❌ 隐私安全问题
六、将来我能在编程中运用吗?
当然能! 而且已经在用了。
我认为AI不是替代程序员,而是像计算器替代算盘一样,让我们更专注于创造性的工作。
我已经把GitHub Copilot加入日常开发工具链,写作业、做项目、刷LeetCode都用它辅助。未来我会继续探索AI在代码审查、测试生成、文档编写等方面的应用。
七、给同学的建议
1. 不要把AI当“作弊工具”,要当“学习伙伴”
2. 生成的代码一定要自己理解后再使用
3. 多问AI“为什么”,让它解释代码逻辑
4. 遇到不会的问题,先自己想,再看AI建议
第三篇:自然语言处理的应用与我的兴趣
一、引言
自然语言处理(NLP)是人工智能的重要分支,让计算机能够理解、处理和生成人类语言。作为软件工程专业学生,我对这个领域充满好奇。
二、NLP的主要应用领域
1. 智能客服
京东、淘宝的自动回复机器人,可以理解用户问题并给出答案。
2. 机器翻译
Google翻译、DeepL,让跨语言交流成为可能。
3. 语音助手
小爱同学、Siri、天猫精灵,听懂我们的指令并执行。
4. 情感分析
分析社交媒体评论的情感倾向(正面/负面),用于舆情监控。
5. 文本分类
垃圾邮件过滤、新闻分类、意图识别。
6. 信息抽取
从文本中提取人名、地名、时间、事件。
7. 自动摘要
长文档自动生成摘要,如新闻简报。
8. 智能写作
作文批改、新闻撰写、诗歌生成。
三、我身边哪些东西用了NLP?
· 微信输入法:语音转文字、联想输入
· 网易云音乐:歌词分词、评论情感分析
· 百度搜索:关键词提取、语义理解
· CSDN问答:自动推荐相关答案
· 知网:论文关键词提取、文献推荐
· 学校教务系统:智能问答机器人(有的学校已部署)
四、我对NLP的兴趣点
1. 想做一个小型聊天机器人
用Seq2Seq或Transformer模型,做一个能陪我聊天的AI。
2. 想学情感分析
分析微博评论,看看大家对一个事件的态度。
3. 想参与开源NLP项目
比如HuggingFace的中文模型贡献。
4. 未来职业方向
· NLP算法工程师
· AI产品经理(懂技术+懂业务)
· 数据分析师(用NLP处理文本数据)
五、我对NLP的理解
自然语言处理不仅仅是技术,它让计算机更懂人类。未来,随着大模型的发展,NLP会渗透到更多领域:
· 教育:个性化学习助手
· 医疗:病历分析、智能问诊
· 法律:合同审查、案例检索
· 金融:研报分析、舆情监控
作为软件工程专业学生,我会继续深入学习Python、机器学习、深度学习,争取早日入门NLP,做出有实际价值的应用。
六、结语
AI时代,NLP是每个程序员都应该了解的方向。不管将来做开发、算法还是产品,懂NLP都会让你更有竞争力。希望这篇博文能帮你打开NLP的大门!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)