Synthesizer的大致代码
·
基本信息
论文题目:Synthesizer: Rethinking Self-Attention for Transformer Models(合成器:重新思考变压器模型的自我关注)
会议:ICML2020
摘要:点积自注意力机制被认为是最先进的变压器模型的核心和不可或缺的。但这真的是必须的吗?本文研究了基于点积的自注意力机制机制对变压器模型性能的真正重要性和贡献。通过广泛的实验,我们发现(1)随机对齐矩阵令人惊讶地表现出相当强的竞争力,(2)从令牌-令牌(查询键)交互中学习注意力权重是有用的,但毕竟不是那么重要。为此,我们提出了一个模型SYNTHESIZER,它可以在没有令牌与令牌交互的情况下学习综合注意力权重。在我们的实验中,我们首先展示了简单的合成器在一系列任务中与香草Transformer模型相比具有高度竞争力的性能,包括机器翻译、语言建模、文本生成和GLUE/SuperGLUE基准测试。当组成与点积注意,我们发现合成器始终优于变压器。此外,我们对合成器与动态卷积进行了额外的比较,表明简单的随机合成器不仅快了60%,而且相对提高了3.5%的困惑度。最后,我们证明了简单的分解合成器可以在编码任务上优于线性合成器。
需要更为详细的了解论文的可以看这里的博客:
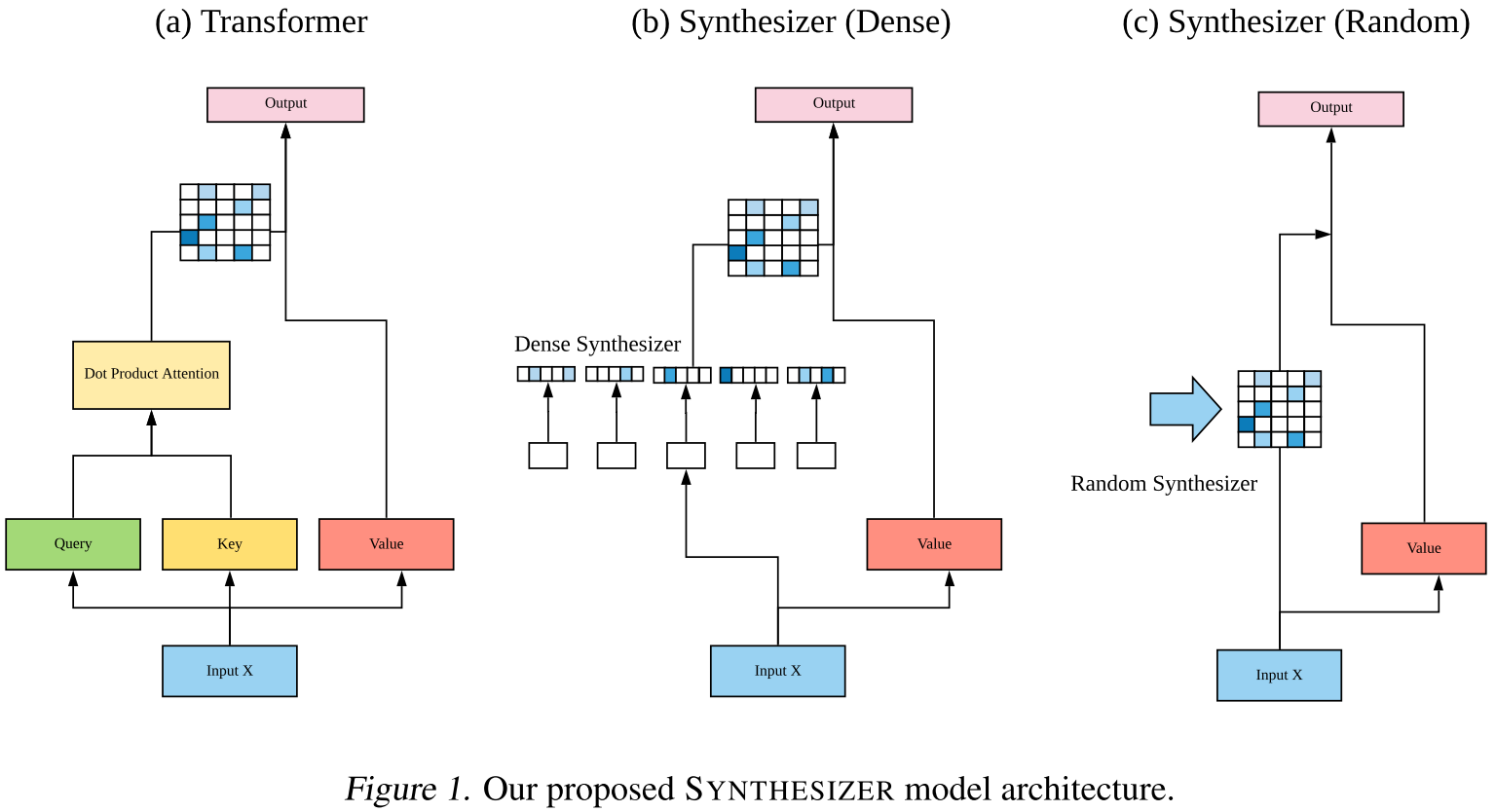
文中的代码以及标准Transformer的代码对比
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class MultiHeadAttention(nn.Module):
"""标准Transformer的多头注意力(作为对比基线)"""
def __init__(self, d_model, num_heads, max_len=512):
super().__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# Query, Key, Value投影
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
"""
x: [batch_size, seq_len, d_model]
"""
batch_size, seq_len, _ = x.size()
# 1. 线性投影并分头
Q = self.W_q(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
# Q, K, V: [batch_size, num_heads, seq_len, d_k]
# 2. 计算注意力分数 (点积)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# scores: [batch_size, num_heads, seq_len, seq_len]
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 3. Softmax得到注意力权重
attn_weights = F.softmax(scores, dim=-1)
# 4. 加权求和
output = torch.matmul(attn_weights, V)
# output: [batch_size, num_heads, seq_len, d_k]
# 5. 合并多头
output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
output = self.W_o(output)
return output
class RandomSynthesizer(nn.Module):
"""Random Synthesizer - 使用可训练的随机矩阵"""
def __init__(self, d_model, num_heads, max_len=512):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.max_len = max_len
# 核心:每个头学习一个随机初始化的注意力矩阵
# R: [num_heads, max_len, max_len]
self.R = nn.Parameter(torch.randn(num_heads, max_len, max_len))
# Value投影(仍然需要)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
"""
x: [batch_size, seq_len, d_model]
"""
batch_size, seq_len, _ = x.size()
# 1. Value投影并分头
V = self.W_v(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
# V: [batch_size, num_heads, seq_len, d_k]
# 2. 使用随机矩阵R作为注意力权重(截取到实际长度)
attn_weights = self.R[:, :seq_len, :seq_len] # [num_heads, seq_len, seq_len]
if mask is not None:
attn_weights = attn_weights.masked_fill(mask == 0, -1e9)
# 3. Softmax
attn_weights = F.softmax(attn_weights, dim=-1)
# attn_weights: [num_heads, seq_len, seq_len]
# 4. 扩展batch维度并加权求和
attn_weights = attn_weights.unsqueeze(0).expand(batch_size, -1, -1, -1)
# attn_weights: [batch_size, num_heads, seq_len, seq_len]
output = torch.matmul(attn_weights, V)
# output: [batch_size, num_heads, seq_len, d_k]
# 5. 合并多头
output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
output = self.W_o(output)
return output
class FixedRandomSynthesizer(nn.Module):
"""Fixed Random Synthesizer - 使用固定的随机矩阵(不训练)"""
def __init__(self, d_model, num_heads, max_len=512):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.max_len = max_len
# 固定的随机矩阵(不作为参数)
self.register_buffer('R', torch.randn(num_heads, max_len, max_len))
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
batch_size, seq_len, _ = x.size()
V = self.W_v(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
attn_weights = self.R[:, :seq_len, :seq_len]
if mask is not None:
attn_weights = attn_weights.masked_fill(mask == 0, -1e9)
attn_weights = F.softmax(attn_weights, dim=-1)
attn_weights = attn_weights.unsqueeze(0).expand(batch_size, -1, -1, -1)
output = torch.matmul(attn_weights, V)
output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
output = self.W_o(output)
return output
class DenseSynthesizer(nn.Module):
"""Dense Synthesizer - 每个token学习对整个序列的注意力"""
def __init__(self, d_model, num_heads, max_len=512):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.max_len = max_len
# 核心:两层前馈网络,将d_model映射到max_len
# 对每个头,每个token独立地学习一个长度为max_len的向量
self.synthesizer = nn.ModuleList([
nn.Sequential(
nn.Linear(d_model, d_model),
nn.ReLU(),
nn.Linear(d_model, max_len)
) for _ in range(num_heads)
])
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
"""
x: [batch_size, seq_len, d_model]
"""
batch_size, seq_len, _ = x.size()
# 1. Value投影
V = self.W_v(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
# V: [batch_size, num_heads, seq_len, d_k]
# 2. 对每个头,用synthesizer网络生成注意力权重
attn_weights_list = []
for head_idx in range(self.num_heads):
# 对每个token应用synthesizer
B = self.synthesizer[head_idx](x) # [batch_size, seq_len, max_len]
B = B[:, :, :seq_len] # 截取到实际长度 [batch_size, seq_len, seq_len]
attn_weights_list.append(B)
# 堆叠所有头
attn_weights = torch.stack(attn_weights_list, dim=1)
# attn_weights: [batch_size, num_heads, seq_len, seq_len]
if mask is not None:
attn_weights = attn_weights.masked_fill(mask == 0, -1e9)
# 3. Softmax
attn_weights = F.softmax(attn_weights, dim=-1)
# 4. 加权求和
output = torch.matmul(attn_weights, V)
# 5. 合并多头
output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
output = self.W_o(output)
return output
class FactorizedRandomSynthesizer(nn.Module):
"""Factorized Random Synthesizer - 低秩分解版本"""
def __init__(self, d_model, num_heads, max_len=512, k=8):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.max_len = max_len
self.k = k # 低秩维度
# 低秩分解:R = R1 @ R2^T
# R1, R2: [num_heads, max_len, k]
self.R1 = nn.Parameter(torch.randn(num_heads, max_len, k))
self.R2 = nn.Parameter(torch.randn(num_heads, max_len, k))
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
batch_size, seq_len, _ = x.size()
V = self.W_v(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
# 计算低秩注意力矩阵:R1 @ R2^T
R1 = self.R1[:, :seq_len, :] # [num_heads, seq_len, k]
R2 = self.R2[:, :seq_len, :] # [num_heads, seq_len, k]
attn_weights = torch.matmul(R1, R2.transpose(-2, -1))
# attn_weights: [num_heads, seq_len, seq_len]
if mask is not None:
attn_weights = attn_weights.masked_fill(mask == 0, -1e9)
attn_weights = F.softmax(attn_weights, dim=-1)
attn_weights = attn_weights.unsqueeze(0).expand(batch_size, -1, -1, -1)
output = torch.matmul(attn_weights, V)
output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
output = self.W_o(output)
return output
class FactorizedDenseSynthesizer(nn.Module):
"""Factorized Dense Synthesizer - 分解为a×b两个维度"""
def __init__(self, d_model, num_heads, max_len=512, a=16, b=32):
super().__init__()
assert a * b == max_len, f"a * b must equal max_len, got {a}*{b}={a * b}, max_len={max_len}"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.max_len = max_len
self.a = a
self.b = b
# 两个synthesizer网络,分别生成a维和b维
self.synthesizer_A = nn.ModuleList([
nn.Sequential(
nn.Linear(d_model, d_model),
nn.ReLU(),
nn.Linear(d_model, a)
) for _ in range(num_heads)
])
self.synthesizer_B = nn.ModuleList([
nn.Sequential(
nn.Linear(d_model, d_model),
nn.ReLU(),
nn.Linear(d_model, b)
) for _ in range(num_heads)
])
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
batch_size, seq_len, _ = x.size()
V = self.W_v(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
attn_weights_list = []
for head_idx in range(self.num_heads):
# 生成A和B
A = self.synthesizer_A[head_idx](x) # [batch_size, seq_len, a]
B = self.synthesizer_B[head_idx](x) # [batch_size, seq_len, b]
# Tile操作:A复制b次,B复制a次
# 然后组合成[batch_size, seq_len, a*b]
A_tiled = A.unsqueeze(-1).expand(-1, -1, -1, self.b).reshape(batch_size, seq_len, -1)
B_tiled = B.unsqueeze(-2).expand(-1, -1, self.a, -1).reshape(batch_size, seq_len, -1)
# 元素级乘法组合
C = A_tiled * B_tiled # [batch_size, seq_len, a*b]
C = C[:, :, :seq_len] # 截取到实际长度
attn_weights_list.append(C)
attn_weights = torch.stack(attn_weights_list, dim=1)
if mask is not None:
attn_weights = attn_weights.masked_fill(mask == 0, -1e9)
attn_weights = F.softmax(attn_weights, dim=-1)
output = torch.matmul(attn_weights, V)
output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
output = self.W_o(output)
return output
class MixtureSynthesizer(nn.Module):
"""Mixture Synthesizer - 组合多种synthesizer"""
def __init__(self, d_model, num_heads, max_len=512,
use_random=True, use_dense=True, use_vanilla=True):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.use_random = use_random
self.use_dense = use_dense
self.use_vanilla = use_vanilla
# 创建各个组件
if use_random:
self.random_synth = RandomSynthesizer(d_model, num_heads, max_len)
if use_dense:
self.dense_synth = DenseSynthesizer(d_model, num_heads, max_len)
if use_vanilla:
self.vanilla_attn = MultiHeadAttention(d_model, num_heads, max_len)
# 可学习的组合权重
num_components = sum([use_random, use_dense, use_vanilla])
self.alphas = nn.Parameter(torch.ones(num_components) / num_components)
def forward(self, x, mask=None):
outputs = []
if self.use_random:
outputs.append(self.random_synth(x, mask))
if self.use_dense:
outputs.append(self.dense_synth(x, mask))
if self.use_vanilla:
outputs.append(self.vanilla_attn(x, mask))
# Softmax归一化权重
weights = F.softmax(self.alphas, dim=0)
# 加权组合
output = sum(w * out for w, out in zip(weights, outputs))
return output
# ==================== 使用示例 ====================
def test_synthesizers():
"""测试各种Synthesizer"""
batch_size = 2
seq_len = 10
d_model = 64
num_heads = 4
max_len = 512
# 创建输入
x = torch.randn(batch_size, seq_len, d_model)
print("=" * 60)
print("Testing different Synthesizer variants")
print("=" * 60)
# 1. 标准Transformer
model = MultiHeadAttention(d_model, num_heads, max_len)
output = model(x)
print(f"Vanilla Transformer: {output.shape}")
print(f" Parameters: {sum(p.numel() for p in model.parameters()):,}")
# 2. Random Synthesizer
model = RandomSynthesizer(d_model, num_heads, max_len)
output = model(x)
print(f"\nRandom Synthesizer: {output.shape}")
print(f" Parameters: {sum(p.numel() for p in model.parameters()):,}")
print(f" R matrix shape: {model.R.shape}")
# 3. Fixed Random Synthesizer
model = FixedRandomSynthesizer(d_model, num_heads, max_len)
output = model(x)
print(f"\nFixed Random Synthesizer: {output.shape}")
print(f" Trainable Parameters: {sum(p.numel() for p in model.parameters()):,}")
# 4. Dense Synthesizer
model = DenseSynthesizer(d_model, num_heads, max_len)
output = model(x)
print(f"\nDense Synthesizer: {output.shape}")
print(f" Parameters: {sum(p.numel() for p in model.parameters()):,}")
# 5. Factorized Random Synthesizer
model = FactorizedRandomSynthesizer(d_model, num_heads, max_len, k=8)
output = model(x)
print(f"\nFactorized Random Synthesizer: {output.shape}")
print(f" Parameters: {sum(p.numel() for p in model.parameters()):,}")
print(f" Rank k: {model.k}")
# 6. Mixture (Random + Vanilla)
model = MixtureSynthesizer(d_model, num_heads, max_len,
use_random=True, use_dense=False, use_vanilla=True)
output = model(x)
print(f"\nMixture (R+V) Synthesizer: {output.shape}")
print(f" Parameters: {sum(p.numel() for p in model.parameters()):,}")
print(f" Mixture weights: {F.softmax(model.alphas, dim=0).detach()}")
print("\n" + "=" * 60)
if __name__ == "__main__":
test_synthesizers()

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)