经典CNN网络模型刨析
引入
全连接的问题
-
空间结构特征消失,被展平了
-
参数太多了,难以训练
解决方案:
-
视角层面:全连接,什么都看 => 卷积,只看局部
-
同一组参数,可以共享
-
多个卷积 = 多个观察特征的角度
效果: 空间特征得以保存 + 参数量大大减少

softmax:多分类激活函数,sigmoid:二分类激活函数
经典分类模型
CNN进化简史:四大经典架构
这条脉络的主线是:从“证明有效”到“走向深度”,再到 “解决深度带来的问题”。
LeNet-5
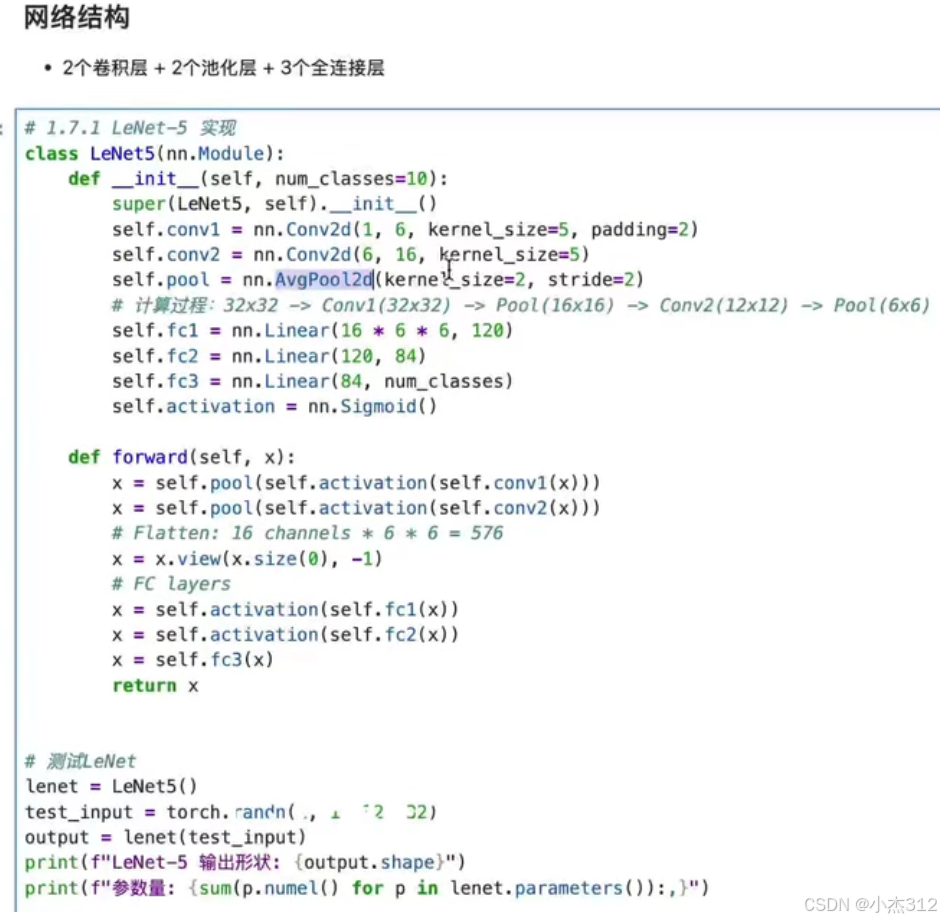
1. 起源与验证:LeNet-5(1998年)
-
核心贡献:首次成功将卷积、池化、全连接堆叠,构成了现代CNN的雏形。它证明了通过梯度下降能够有效训练卷积神经网络。
-
关键结构:
-
卷积层 -> 池化层 -> 卷积层 -> 池化层 -> 全连接层 -
使用 Sigmoid 激活函数。
-
-
历史意义:成功用于手写数字识别(MNIST数据集),但因数据量和算力限制,其思想沉寂了近十年。
-
记忆点:CNN的“祖父”,奠定了基本组件。
AlexNet-8
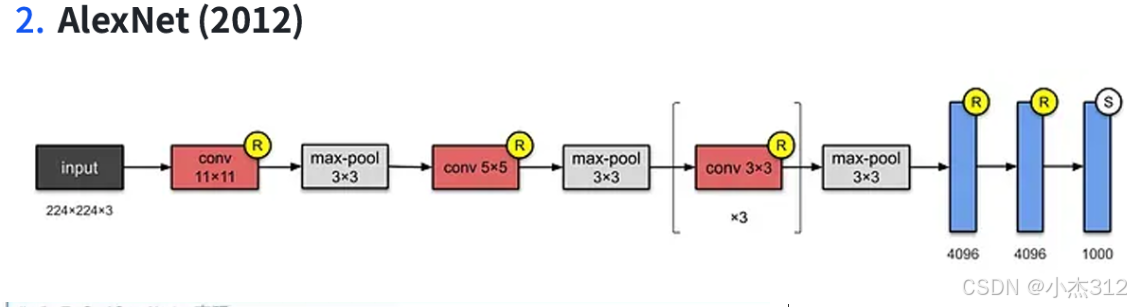
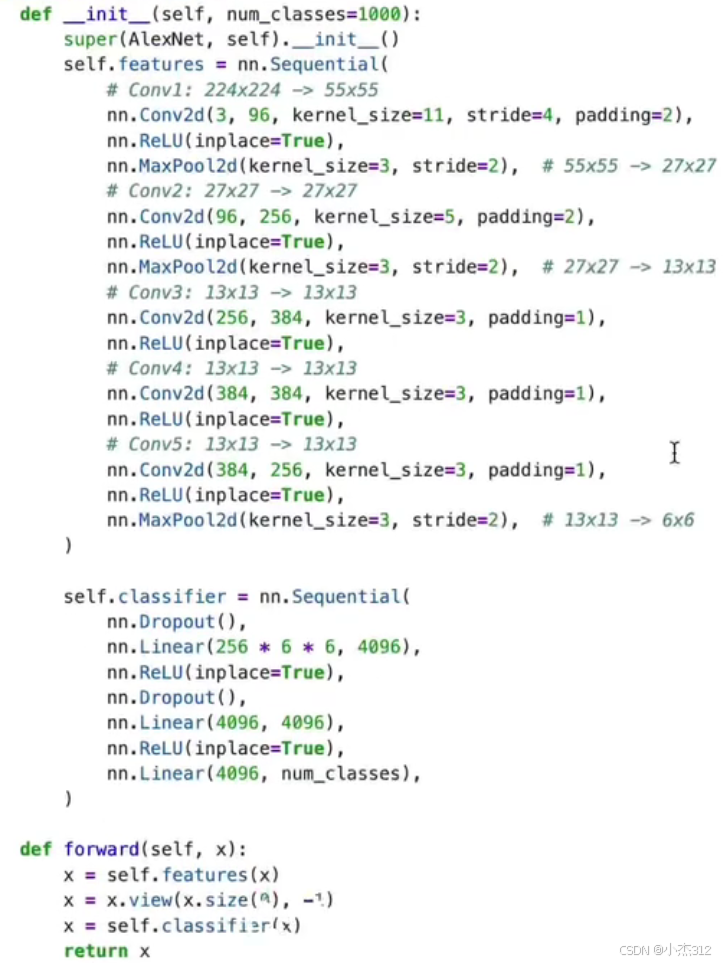
2. 复兴与崛起:AlexNet(2012年)
-
核心贡献:在大数据(ImageNet)和大算力(GPU) 时代,证明了深度CNN的惊人能力,点燃了深度学习的热潮。
-
关键创新:
-
引入ReLU激活函数:代替Sigmoid,极大缓解梯度消失问题,训练速度大幅加快。
-
使用Dropout正则化:在全连接层随机丢弃部分神经元,有效防止模型过拟合。
-
使用GPU并行训练。
-
-
历史意义:以压倒性优势赢得ImageNet图像分类竞赛(Top-5错误率从26%降至16%),标志着深度学习时代的正式来临。
-
记忆点:深度CNN的“引爆点”, “ReLU + Dropout + GPU” 三件套。
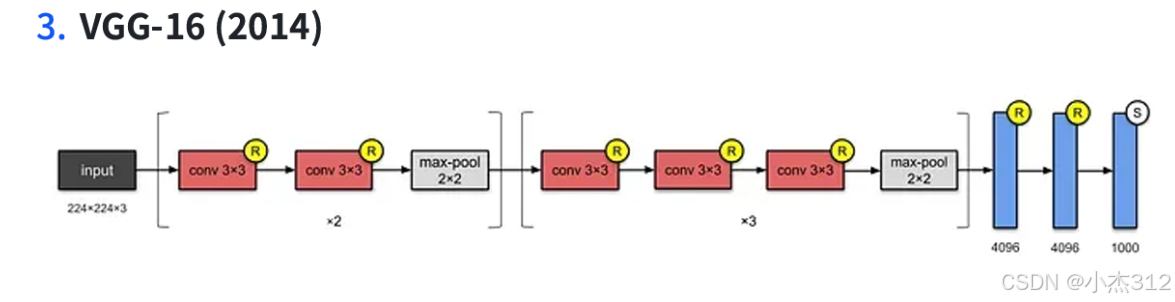
VGG-16
总层数:16层(13个卷积层 + 3个全连接层)
特征提取部分 (features)
cfg = [
64, 64, "M", # 阶段1:2个卷积层 + 1个池化层
128, 128, "M", # 阶段2:2个卷积层 + 1个池化层
256, 256, 256, "M", # 阶段3:3个卷积层 + 1个池化层
512, 512, 512, "M", # 阶段4:3个卷积层 + 1个池化层
512, 512, 512, "M", # 阶段5:3个卷积层 + 1个池化层
]
# make_layers: make_features_receive_layers
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers) 分类器部分 (classifier)
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096), # 将7×7×512=25088展平,连接4096个神经元
nn.ReLU(True), # ReLU激活
nn.Dropout(), # Dropout正则化(防止过拟合)
nn.Linear(4096, 4096), # 第二全连接层:4096个神经元
nn.ReLU(True), # ReLU激活
nn.Dropout(), # Dropout正则化
nn.Linear(4096, num_classes), # 输出层:1000个类别(ImageNet)
)输入图像 (224×224×3)
↓
[特征提取部分]
↓ 13个卷积层 + 5个池化层
特征图 (7×7×512)
↓
自适应平均池化 (AdaptiveAvgPool2d) → 固定为7×7
↓
展平 (Flatten) → 512×7×7 = 25088维向量
↓
[分类器部分]
↓
全连接层1:25088 → 4096
↓ ReLU + Dropout
全连接层2:4096 → 4096
↓ ReLU + Dropout
全连接层3:4096 → 1000(分类结果)
def forward(self, x)
x = self.features(x)
avgpool = nn.AdaptiveAvgPool2d((7, 7)) # 应该在 __init__中
x = avgpool(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x输入(224,224,3)
├─ 2×[Conv3×3(64)] → MaxPool
├─ 2×[Conv3×3(128)] → MaxPool
├─ 3×[Conv3×3(256)] → MaxPool
├─ 3×[Conv3×3(512)] → MaxPool
├─ 3×[Conv3×3(512)] → MaxPool
├─ AdaptiveAvgPool(7×7)
├─ Flatten(512×7×7=25088)
├─ FC(25088→4096) → ReLU → Dropout
├─ FC(4096→4096) → ReLU → Dropout
└─ FC(4096→1000) → 输出3. 深化与统一:VGGNet(2014年)
-
核心贡献:探索了网络“深度”的重要性,并证明通过堆叠更小的卷积核(3x3)是构建更深、更强网络的有效途径。
-
关键结构:
-
规律化设计:全部使用3x3卷积和2x2最大池化,不断加深网络(VGG-16, VGG-19)。
-
小卷积核优势:多个3x3卷积串联可达到大卷积核的感受野,但参数更少,非线性更强。
-
-
历史意义:提供了简洁、统一、模块化的设计范式,其结构清晰,易于迁移学习,至今仍是常用的骨干网络之一。
-
记忆点:“更小、更深、更规整”,3x3卷积的教科书。
ResNet-50
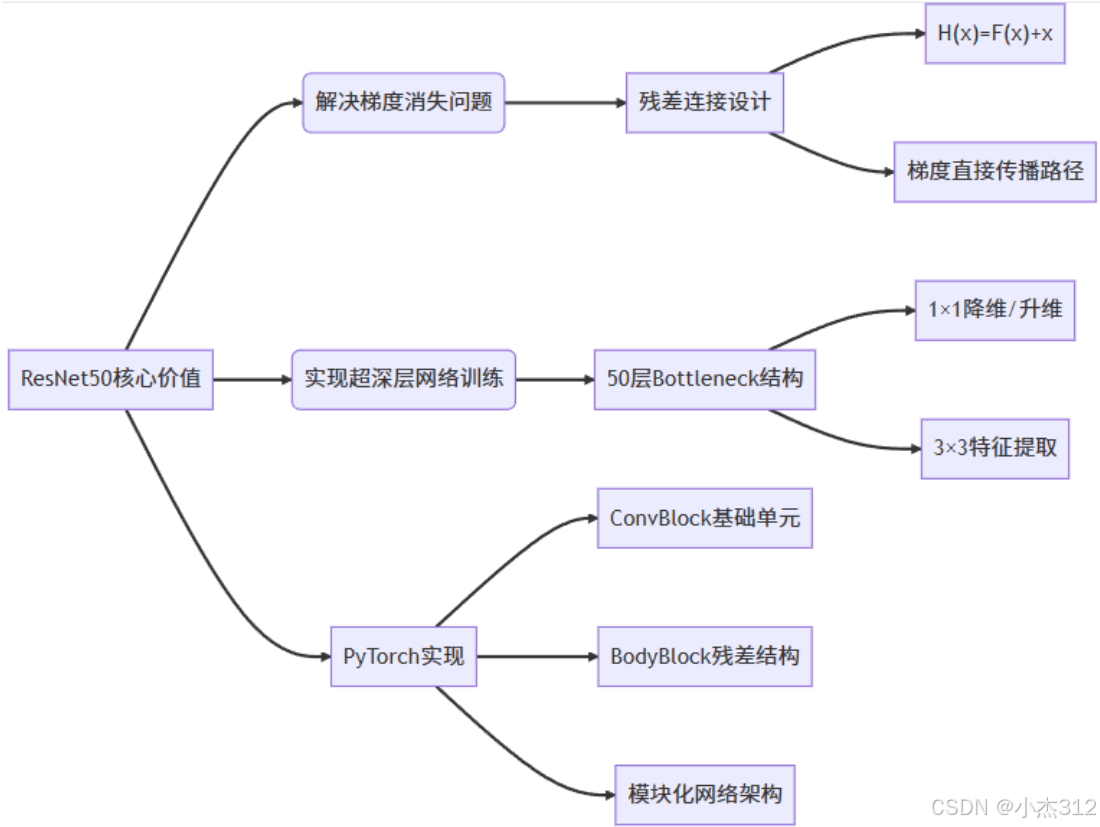

4. 突破与升华:ResNet(2015年)
-
核心贡献:提出了残差学习,通过跳跃连接解决了超深网络中的梯度消失/爆炸和网络退化问题。
-
关键创新:残差块
-
不是让网络直接拟合目标映射
H(x),而是拟合残差F(x) = H(x) - x。 -
通过
跳跃连接实现恒等映射:H(x) = F(x) + x。 -
这使得信息(包括梯度)可以无损地穿越很多层。
-
-
历史意义:让网络深度突破千层大关,在多项任务上达到人类水平。其思想深刻影响了后续几乎所有网络设计。
-
记忆点:“跳跃连接,大道至简”,“让网络学会恒等变换”,解决了深度网络的核心瓶颈。
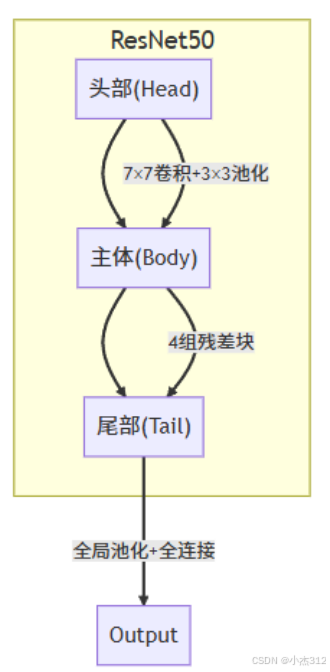
ResNet50架构详解
-
头部(Head):初始特征提取
-
主体(Body):多个残差块堆叠
-
尾部(Tail):分类器
Bottleneck设计
# 参数量对比示例
传统结构 = 256×256×3×3×2 = 1,179,648
Bottleneck = 256×64×1×1 + 64×64×3×3 + 64×256×1×1 = 69,632
参数减少约94%!
PyTorch实现精解
核心组件
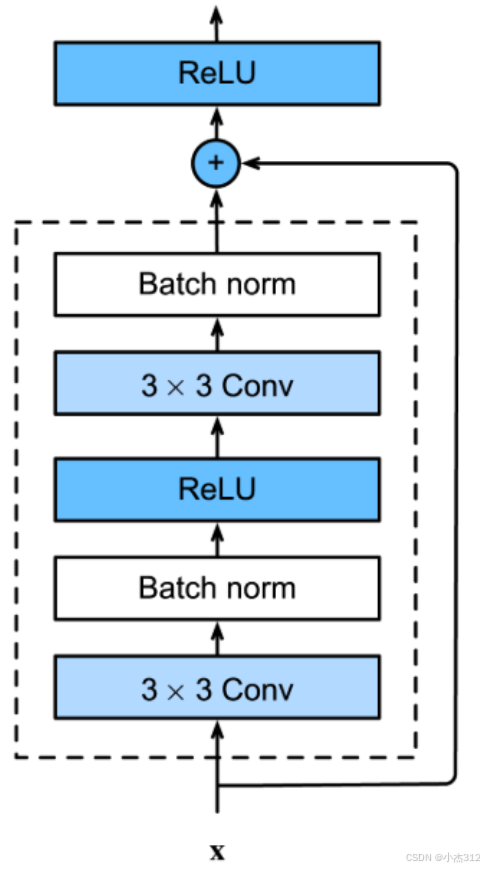
class ConvBlock(nn.Module):
""" 卷积三件套:nn.Conv2d + BN + ReLU """
def __init__(self, in_c, out_c, ks, stride, pad):
super().__init__()
self.conv = nn.Conv2d(inc, out_c, ks, stride, pad) #ks: kernal_sz
self.bn = nn.BatchNorm2d(out_c) # BN:
self.relu = nn.ReLU()残差块实现
# 实现Bottlenet残差结构(nn.Module)
class BodyBlock(nn.Module):
"""
残差块模块
实现了ResNet中的残差连接结构,包含多个卷积层和跳跃连接
Args:
in_channels (int): 输入通道数
out_channels (int): 输出通道数
copy_cnt (int): 卷积层重复次数
specical_stride (int, optional): 特殊步长,默认为1
"""
def __init__(self, in_channels, out_channels, copy_cnt, specical_stride=1):
super(BodyBlock, self).__init__()
self.copy_cnt = copy_cnt
# 标准Bottleneck结构中间通道数为输出通道数的1/4
mid_channels = out_channels // 4
# 第一个残差块的主路径
self.conv1 = nn.Sequential(
ConvBlock(in_channels, mid_channels, 1, 1, 0), # 降维
ConvBlock(mid_channels, mid_channels, 3, specical_stride, 1), # 保持维度
ConvBlock(mid_channels, out_channels, 1, 1, 0) # 升维
)
# 第一个残差块的捷径连接,当输入输出通道不一致时需要调整
self.conv2 = ConvBlock(in_channels, out_channels, 1, specical_stride, 0)
# 后续残差块的主路径
self.conv3 = nn.Sequential(
ConvBlock(out_channels, mid_channels, 1, 1, 0), # 降维
ConvBlock(mid_channels, mid_channels, 3, 1, 1), # 保持维度
ConvBlock(mid_channels, out_channels, 1, 1, 0) # 升维
)
def forward():
# 第一个块:主路径 + 调整捷径
x = self.conv1(x) + self.conv2(x)
# 后续块: 主路径 + 恒等映射
for _ in range(self.copy_cnt): # copy_cnt: 重复次数
x = self.conv3(x) + x # 残差连接
return x网络整体构建
net = nn.Sequential(
# head
nn.Sequential(
ConvBlock(in_channel=3, out_channel=64, kernel_size=7, stride=2, padding=3),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
),
# body
nn.Sequential(
BodyBlock(in_channels=64, out_channels=256, copy_cnt=3, specical_stride=1),
BodyBlock(in_channels=256, out_channels=512, copy_cnt=4, specical_stride=2),
BodyBlock(in_channels=512, out_channels=1024, copy_cnt=6, specical_stride=2),
BodyBlock(in_channels=1024, out_channels=2048, copy_cnt=3, specical_stride=2)
),
# tail
nn.Sequential(
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(2048, 1000)
)
)优势:
参数效率与总参数量
-
ResNet50采用Bottleneck设计,通过1×1卷积进行通道降维和升维,大大减少了参数量和计算量,同时保持了模型的表达能力。根据我们的实现,ResNet50的总参数量约为25.5M(2550万),这个数字相对于其50层的深度来说是相当高效的。
相比之下,VGG16虽然只有16层,但参数量高达138M,ResNet50在深度增加的同时,通过巧妙的结构设计将参数量控制在了更低的水平。
这种参数效率主要得益于以下几点:
-
Bottleneck结构:通过1×1卷积进行通道降维和升维,大幅减少参数量
-
共享权重:残差连接允许网络重用特征,减少了冗余参数
-
全局平均池化:在网络末端使用全局平均池化代替多个全连接层,显著减少了参数量
梯度流动
-
残差连接使得梯度可以直接流过捷径,有效缓解了深层网络中的梯度消失问题,使得训练更加稳定和高效。
总结

你可以想象一个故事:
有一位科学家(LeNet)造出了一个概念车(CNN雏形),但当时路况(数据)和燃料(算力)不好,被搁置了。 十几年后,另一位极客(AlexNet)搞来了大量优质燃料(大数据+GPU),改进了引擎(ReLU)和刹车系统(Dropout),开着改装车一举赢得了世界赛车大奖(ImageNet冠军),震惊世界! 接着,一家大公司(VGG)决定工业化生产这款车。他们发现,用一堆小齿轮(3x3卷积)组合,比用一个大齿轮更高效、更灵活,于是造出了又长又稳的加长豪华车(16-19层)。 但是,车造得太长(网络太深)后,车头和车尾的通信出现了问题(梯度消失/网络退化)。这时,一位天才工程师(ResNet)想出了一个绝妙主意:在车里直接修建一些“传送门”或“高速公路”(跳跃连接),让信息可以不经过复杂的机械结构直接传递。从此,车想造多长就造多长(1000+层),性能还越来越好。
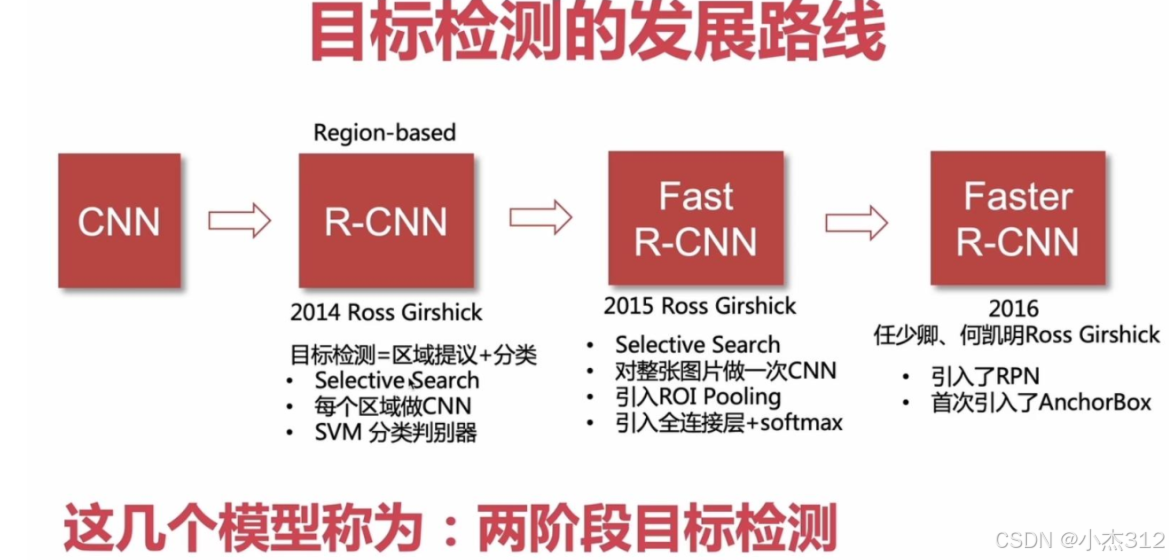
目标检测模型
Faster-RCNN
目标检测过程:框出目标、判断分类
Faster-RCNN
Anchor Box
Anchor Box来源:源于滑动窗口缺点处理

将原图映射到特征图,并且每个特征图像素均预制多个锚框,不同形状的预制框、更为方便的进行框选不同形状的物体


IOU定义:锚框与标注框的交集情况

Anchor 和 Ground Trust 做IOU时的 单位统一问题:
一个是特征图像素为单位,另一个则是原始图片像素为单位

Selective Search
Selective Search 是一种目标候选区域生成算法,核心目的是:在没有先验框的情况下,从一张图片里自动找出所有可能包含目标的区域,为后续的分类和定位任务提供候选;
它是解决传统目标检测 “如何找目标位置” 的经典方案,主要用在 R-CNN 系列模型(R-CNN、Fast R-CNN)中。
核心原理(通俗版)
-
初始分割:先用图像分割算法把图片分成很多小区域(比如基于颜色、纹理的超像素分割)。
-
区域合并:计算相邻小区域的相似度(颜色、纹理、大小、形状),把相似的区域不断合并成更大的区域。
-
生成候选框:把所有合并过程中产生的区域,都转换成对应的矩形框,这些框就是候选区域。
通俗例子
就像你找一张照片里的猫:先把照片分成 “猫耳朵”“猫脸”“背景草地” 等小区域,再把 “猫耳朵” 和 “猫脸” 合并成一个大区域,最后给这个大区域画个框,作为 “可能有猫” 的候选框。
缺点(关键痛点)
-
速度慢:合并过程是纯 CPU 计算,一张图要生成 1000~2000 个候选框,耗时几秒到十几秒,完全无法实时。
-
候选框冗余:很多候选框是重复或无效的,后续分类时会做大量无用功。
-
无法端到端训练:候选区域生成和后续的分类、回归是分开的两个步骤,不能一起优化模型参数。
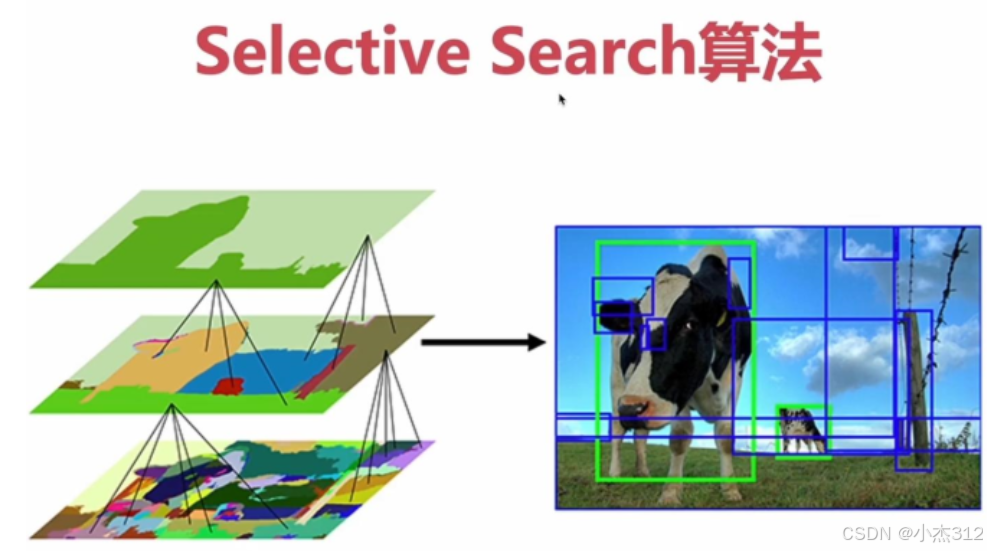

-
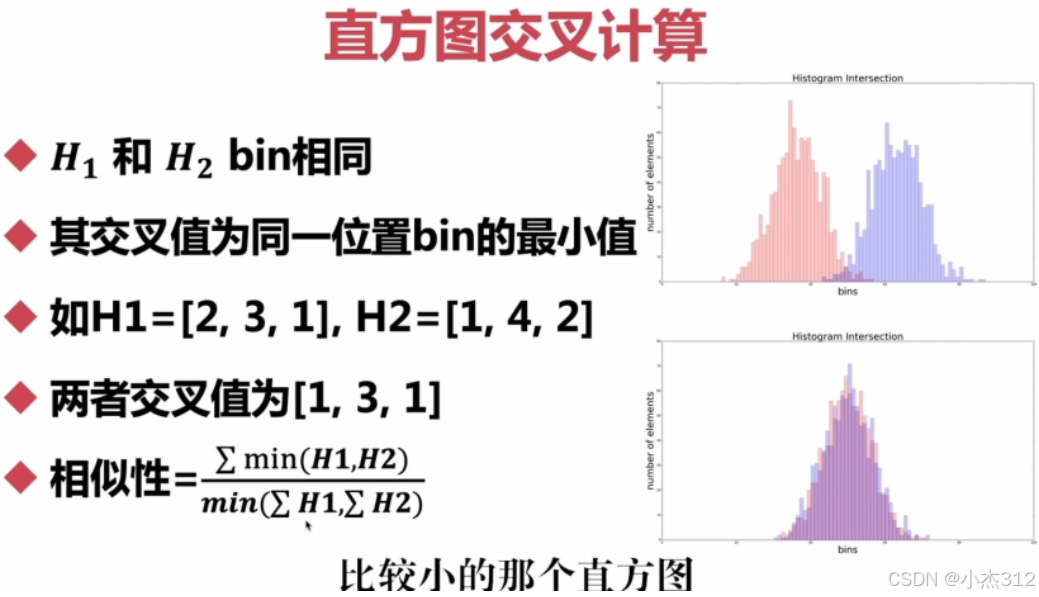
区域合并算法细节,用直方图交叉计算来计算相似性?然后由相似性进行合并相邻相似区域
RPN&Anchor Box
RPN(Region Proposal Network)和 Anchor Box 是为了解决 Selective Search 的痛点,实现 “候选区域生成 + 分类 + 回归” 端到端训练,同时大幅提升检测速度,是 Faster R-CNN 模型的核心创新
1. 核心需求:用神经网络替代手工生成候选框
Selective Search 是手工设计的规则算法,速度慢且不可学习。而深度学习的核心是 “让模型自己学”,因此研究者希望:
用一个 卷积神经网络(RPN)直接从图像特征图上 生成候选区域,替代 Selective Search
但这里有个关键问题:卷积神经网络输出的是特征图(理解Anchor Box技术诞生的关键),怎么从特征图上确定候选框的位置和大小? 解决特征图和候选框的映射问题
→ Anchor Box(锚框)就是为解决这个问题而生的。
2. Anchor Box:给特征图 “预设参考框” (不同类别目标的预制框,对应到原图上)
eg:人:长条框,人脸:方正框,车辆:方正框,木棍:长条框
Anchor Box 是一组预设的、不同大小和长宽比的矩形框,提前定义好,然后 “铺” 在特征图的每个像素点上。
-
作用 :为每个特征点提供 参考基准,让 RPN 可以基于这些基准框,预测 “这个位置有没有目标” “框需要往哪个方向调整” 。
-
通俗理解 :
就像你找目标时,提前准备了一堆不同尺寸的 “模板框”(比如小框、大框、竖框、横框),然后把这些模板框一个个放在图片的每个位置,再判断 “哪个模板框和目标最像,需要怎么微调”。
-
举例 :
通常预设 3 种尺寸(比如 128×128、256×256、512×512)和 3 种长宽比(1:1、1:2、2:1),总共 9 个 Anchor Box,每个特征点都会对应这 9 个框。
3. RPN:用神经网络高效生成候选框
RPN(区域提议网络) 是一个轻量级的卷积网络,输入是图像的特征图,输出是两部分:
-
分类分支:预测每个 Anchor Box 里 “ 是前景(有目标)还是背景(无目标)”。
-
回归分支:预测每个前景 Anchor Box 需要调整的偏移量(x、y 坐标偏移,宽高缩放),把 Anchor Box 修正成更贴合目标的候选框。

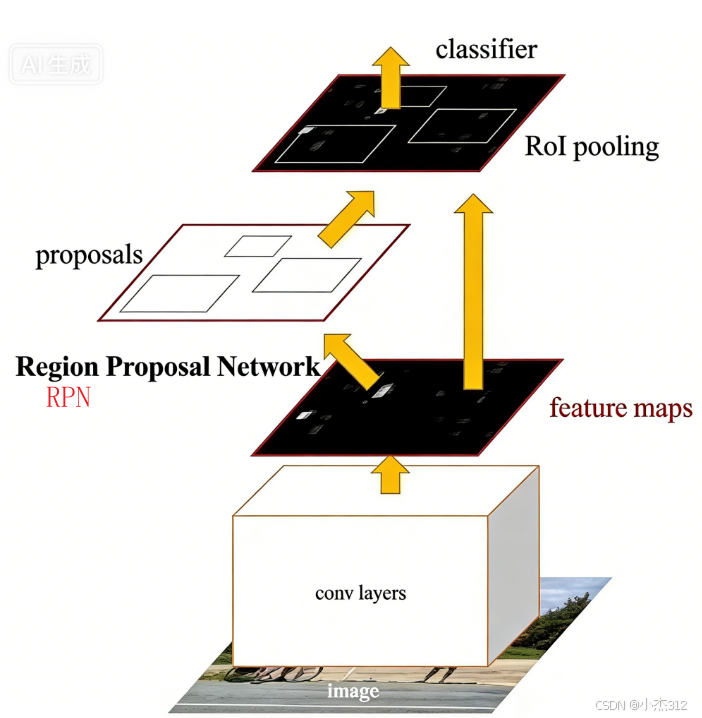
整体流程图解+代码
prorosals:输入RPN结果+anchorbox,输出真正的候选区域,目标框选区域
RPN:输入feature maps,输出分类器 和 BoundingBox偏移量
#每个batch调用一次,batch_size=1
def forward(self, images, targets=None):
feature_map = self.backbone(images) # 先经过主干网络获取feature_map
batch_size, _, h, w = feature_map.shape # 获取feature_map的形状
# 执行rpn分类,获取分类分数 + bbox 偏移预测
rpn_cls_scores, rpn_bbox_preds = self.rpn(feature_map)
# 生成锚框
anchors = generate_anchors((h, w), stride=self.stride).to(images.device)
if self.training:
assert targets is not None, "Targets must be provided during training"
losses = {}
for i in range(batch_size):
rpn_loss_cls, rpn_loss_bbox = self.compute_rpn_loss(
rpn_cls_scores[i], rpn_bbox_preds[i], anchors, targets[i]
)
proposals = self.generate_proposals(
rpn_cls_scores[i:i+1],
rpn_bbox_preds[i:i+1],
anchors) # 生成候选区域
#然后将新创建的tensor与proposals进行按列拼接,得到rois,其形状为:(n,5)
#其中n是proposals的数量,5是[batch_index, x1, y1, x2, y2]
rois = torch.cat(
[torch.full((proposals.shape[0], 1),
i, device=proposals.device), proposals]
, dim=1)
# ROI Pooling
roi_features = self.roi_align(feature_map, rois)
# roi_features.size(0)表示获得roi_features的行数,也就是roi的数量
# 将roi_features的形状从(N, 256, 7, 7)变成(N, 256 * 7 * 7)
x = roi_features.view(roi_features.size(0), -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
cls_scores = self.cls_score(x)
bbox_deltas = self.bbox_pred(x)
det_loss_cls, det_loss_bbox = self.compute_detection_loss(
cls_scores, bbox_deltas, targets[i], proposals)
losses[f"rpn_loss_cls_{i}"] = rpn_loss_cls
losses[f"rpn_loss_bbox_{i}"] = rpn_loss_bbox
losses[f"det_loss_cls_{i}"] = det_loss_cls
losses[f"det_loss_bbox_{i}"] = det_loss_bbox
return losses
RPN代码
# RPN(区域提议网络)
# 生产智能渔网的工厂
class RPN(nn.Module):
def __init__(self, in_channels, mid_channels=256, num_anchors=9):
super(RPN, self).__init__()
self.conv = nn.Conv2d(in_channels, mid_channels, kernel_size=3, stride=1, padding=1) # 转换为纹理、边缘、结构 信息
self.cls_layer = nn.Conv2d(mid_channels, num_anchors * 2, kernel_size=1)
# 判断anchor种有没有物体: 分数1:背景概率、分数2: 前景概率
self.reg_layer = nn.Conv2d(mid_channels, num_anchors * 4, kernel_size=1)
# 调整建议层:dx、dy、dw、dh (平移、拉升)
def forward(self, x):
x = F.relu(self.conv(x))
cls_scores = self.cls_layer(x)
bbox_preds = self.reg_layer(x)
return cls_scores, bbox_predsAnchor生成代码
# 生成 Anchor Box (撒下多张大小形状不同的渔网) 224/4 = 56个特征像素点
def generate_anchors(feature_map_size, stride=4, scales=[8, 16, 32],
ratios=[0.5, 1, 2]):
anchors = []
h, w = feature_map_size
base_size = stride
for i in range(h):
for j in range(w):
cx = j * stride + stride / 2 # 中心点x坐标(原图上)
cy = i * stride + stride / 2
for scale in scales: # 3
for ratio in ratios: # 3*3 = 9种不同的网
w_box = base_size * scale * (ratio ** 0.5)
h_box = base_size * scale / (ratio ** 0.5)
anchors.append([cx - w_box / 2, cy - h_box / 2,
cx + w_box / 2, cy + h_box / 2])
return torch.tensor(anchors, dtype=torch.float32)Proposal生成代码
def apply_bbox_deltas(self, proposals, deltas, labels=None):
#proposals中的数据格式是[x1, y1, x2, y2],
# deltas中的数据格式是[dx, dy, dw, dh]。
proposals_w = proposals[:, 2] - proposals[:, 0]
proposals_h = proposals[:, 3] - proposals[:, 1]
proposals_cx = proposals[:, 0] + proposals_w / 2 # Anchor box的中心点横坐标cx
proposals_cy = proposals[:, 1] + proposals_h / 2 # Anchor box的中心点纵坐标cy
if labels is not None:
#labels是一个一维张量,其长度等于proposals的长度。
#labels中的每个元素表示对应的proposal的类别标签。
batch_size = proposals.shape[0]
indices = torch.arange(batch_size, device=deltas.device) * self.cls_score.out_features + labels
dx = deltas.view(-1, 4)[indices, 0]
dy = deltas.view(-1, 4)[indices, 1]
dw = deltas.view(-1, 4)[indices, 2]
dh = deltas.view(-1, 4)[indices, 3]
else: # 用同一的调整参数
dx = deltas[:, 0]
dy = deltas[:, 1]
dw = deltas[:, 2]
dh = deltas[:, 3]
#dx 表示预测的候选框的偏移比例,比如0.1表示向右移动10%的宽度
pred_cx = dx * proposals_w + proposals_cx # 横坐标 + 偏移
pred_cy = dy * proposals_h + proposals_cy # 纵坐标 + 偏移
pred_w = torch.exp(dw) * proposals_w # 新宽度
pred_h = torch.exp(dh) * proposals_h # 新高度
# 从新计算矩形框 左上角/右下角 坐标
return torch.stack([pred_cx - pred_w / 2, pred_cy - pred_h / 2, pred_cx + pred_w / 2, pred_cy + pred_h / 2], dim=1)
# 筛选收网 (判断网里有没有🐟) cls_probs = 每个网是 "有🐟" 的概率(0-1之间) 只取 “前景概率”
def generate_proposals(self, cls_scores, bbox_preds, anchors):
#cls_scores原始形状是(batch_size, 9 * 2, 224/4, 224/4)
#cls_scores.view(-1, 2)相当于将一个tensor reshape 成二维tensor, 即转成n行2列
#dim=-1表示按前面参数的最后一个维度计算softmax, 最后一个维度是2
#[:, 1]表示取c前面参数ls_scores的第二列
cls_probs = torch.softmax(cls_scores.view(-1, 2), dim=-1)[:, 1]
bbox_preds = bbox_preds.view(-1, 4)
# 根据预测的调整值(bbox_preds)微调网的位置
proposals = self.apply_bbox_deltas(anchors, bbox_preds)
scores = cls_probs
keep = ops.nms(proposals, scores, iou_threshold=0.7)
# 去掉重复的网(按照"有🐟概率"排序, 保留最高分的网, 删掉重叠度>70%的其他网)
proposals = proposals[keep]
scores = scores[keep]
#proposals是候选区,共有4列,其中第0列表示cx, 1列表示cy, 2列表示w, 3列表示h
#为了不让预测的框超出图像范围,所以对proposals进行裁剪
# clamp(0,224) 限制坐标在图像范围内
proposals[:, 0] = torch.clamp(proposals[:, 0], min=0, max=224)
proposals[:, 1] = torch.clamp(proposals[:, 1], min=0, max=224)
proposals[:, 2] = torch.clamp(proposals[:, 2], min=0, max=224)
proposals[:, 3] = torch.clamp(proposals[:, 3], min=0, max=224)
#numel函数的作用是返回张量中元素的总数
if scores.numel() == 0:
return torch.empty((0, 4), device=anchors.device)
#取值最大的10个值的索引值
top_n = torch.topk(scores, min(10, scores.shape[0])).indices # 只收最好的10张网
return proposals[top_n]from torchvision.ops import roi_align as tv_roi_align
def roi_align(self, feature_map, rois, output_size=(7,7)):
"""
封装ROI Align调用(兼容手动/官方实现)
Args:
feature_map: 特征图 [batch_size, channels, h, w]
rois: [num_rois, 5] 格式 [batch_idx, x1, y1, x2, y2]
output_size: 输出特征尺寸,默认7x7
Returns:
对齐后的ROI特征 [num_rois, channels, 7, 7]
"""
# 推荐使用torchvision官方实现(效率更高、精度更准)
return tv_roi_align(
input=feature_map,
boxes=rois,
output_size=output_size,
spatial_scale=1/self.stride, # 特征图相对于原图的缩放比例
sampling_ratio=2 # 每个bin采样2x2个点(双线性插值)
)两阶段检测发展


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)