大模型应用开发核心认知与技巧指引:从提示工程到智能Agent的完整实践.111
一、前言
当下大模型的应用早已突破单纯的 “问答” 范畴,正在以通用智能中枢的角色,深度重构各行各业的工作模式与生产效率。从智能文档解析、多模态内容生成、自动化工作流编排,到跨系统协同、实时数据决策、专业领域辅助,大模型正在从 “对话工具” 升级为可感知、可理解、可执行、可优化的智能能力底座。
它不再局限于被动应答,而是能自主处理非结构化信息:快速从合同、报表、音视频、图片中提取关键数据,自动生成结构化结果;能串联多个系统与工具,把重复繁琐的流程自动化执行;能结合行业知识给出专业建议,辅助人做更精准的判断与决策。这种从交互到执行、从辅助到协同的跃迁,正在大幅降低数字化门槛,提升组织效率,让技术真正服务于业务本身,也标志着大模型从概念热潮走向深度产业落地的全新阶段。今天我们从最基础的提示工程,到能自主完成复杂任务的智能 Agent,系统的梳理讲解正规过程的核心逻辑,让我们有针对性的理解大模型应用的底层逻辑,而非简单调用API。

二、核心基础
1. 大模型应用开发的核心认知
大模型的价值不在于能聊天,而在于它能作为通用智能基座,解决传统编程难以应对的非结构化问题:
- 传统编程:我们需要明确告诉计算机“每一步该做什么”,就是我们常说的指令式编程;
- 大模型编程:我们只需要告诉计算机“要达成什么目标”,转变为了新的目标式编程;
举个直观的例子:
- 传统方式提取1000份合同中的“甲方名称、签约金额、有效期”:需要编写复杂的正则表达式、文本解析逻辑,且一旦合同格式变化,代码全部失效;
- 大模型方式:只需给大模型一个清晰的提示,就能精准提取信息,适配不同格式的合同。
这种认知能力是大模型最核心的价值,也是我们学习的核心,不是学习大模型本身如何训练,这需要超大规模算力和数据,而是学习如何驾驭大模型的认知能力解决实际问题。
2. 核心概念拆解
2.1 大模型
不是更大的模型这么简单,而是:
- 本质:基于海量文本数据训练的语言概率模型,核心能力是“预测下一个最可能出现的词”;
- 关键特征:参数量达到“亿级、千亿级”,能捕捉语言的上下文逻辑、语义甚至常识;
- 通俗理解:把大模型比作一个“读过人类所有书籍、文档、对话的超级学霸”,我们问它问题,它不是回忆答案,而是根据读过的内容,生成最合理的回答。
2.2 提示工程
不是写漂亮的提问话术,而是:
- 本质:向大模型传递“任务目标、约束条件、上下文”的结构化指令设计;
- 核心目的:让大模型的输出“可控、精准、符合预期”;
- 通俗理解:我们要给超级学霸清晰的考试要求,不仅要告诉他考什么题,还要告诉他答题格式、评分标准、不能犯的错误。
2.3 智能 Agent
大模型应用的高阶形态”,超越单纯的一问一答:
- 本质:具备“感知 - 思考 - 行动 - 反馈”闭环能力的大模型应用;
- 核心特征:能自主拆解复杂任务、调用工具(如计算器、搜索引擎、API)、纠正错误、完成多步骤任务;
- 通俗理解:从“你问它答”的学霸,变成能自主完成项目的项目经理,我们只需要说“帮我完成一份市场分析报告”,它会自己拆解步骤:找数据→分析趋势→生成图表→撰写报告→修改优化。
3. 核心流程

流程说明:
- 1. 需求与拆解:明确业务目标,分解为具体任务模块
- 2. 模型与提示词设计:选择合适的模型,设计高质量的Prompt
- 3. 功能开发与工具集成:实现核心调用逻辑,连接外部工具,选择数据库或API
- 4. 验证与部署:测试评估效果,上线部署+监控
- 5. 持续迭代:收集反馈,持续优化改进
三、大模型API调用
1. API 密钥配置
大模型应用开发通常需要调用第三方大模型 API,我们现在基于混元API为例,通常我们将密钥存放在系统环境变量中,以下示例通过环境变量加载密钥测试;
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
api_key = os.getenv("TENCENT_API_KEY")
# 验证密钥是否加载成功
if api_key:
print("API密钥加载成功!")
print(f"密钥前缀:{api_key[:15]}...")
else:
print("请检查环境变量中的密钥是否配置正确")输出结果:
API密钥加载成功!
密钥前缀:sk-bWlJPKjBrSFG...
2. 极简大模型应用:文本生成
一个简单的大模型应用示例,用于指定指令的文本生成,注意其中的基础文本生成函数def generate_text,后面的示例中也会调用到;
from openai import OpenAI
# 初始化客户端(使用混元大模型)
client = OpenAI(
api_key=os.getenv("TENCENT_API_KEY"),
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
# 基础文本生成函数
def generate_text(prompt: str, model: str = "hunyuan-lite") -> str:
"""
基础大模型文本生成函数
:param prompt: 提示词
:param model: 模型名称,hunyuan-lite是腾讯混元轻量级模型
:return: 生成的文本
"""
try:
# 调用混元大模型API
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "你是一个专业的 Python 讲师"},
{"role": "user", "content": prompt} # user代表用户输入
],
temperature=0.7, # 随机性,0-1,越低越精准,越高越有创意
max_tokens=500, # 生成文本的最大长度
)
# 提取生成的内容
return response.choices[0].message.content.strip()
except Exception as e:
return f"生成失败:{str(e)}"
# 测试:生成一份"新手学习大模型的周计划"
if __name__ == "__main__":
prompt = """请为零基础学习大模型应用开发的人制定一份7天学习计划,要求:
1. 每天的学习内容不超过2小时
2. 从基础到进阶,循序渐进
3. 包含理论学习和代码实战
4. 语言通俗易懂,避免专业术语堆砌
"""
result = generate_text(prompt)
print("生成的学习计划:")
print(result) 细节参数:
- role参数:大模型的对话有角色区分,核心角色包括:
- user:用户(提问者)
- assistant:助手(大模型)
- system:系统(设定大模型的整体行为,如 “你是一个专业的 Python 讲师”)
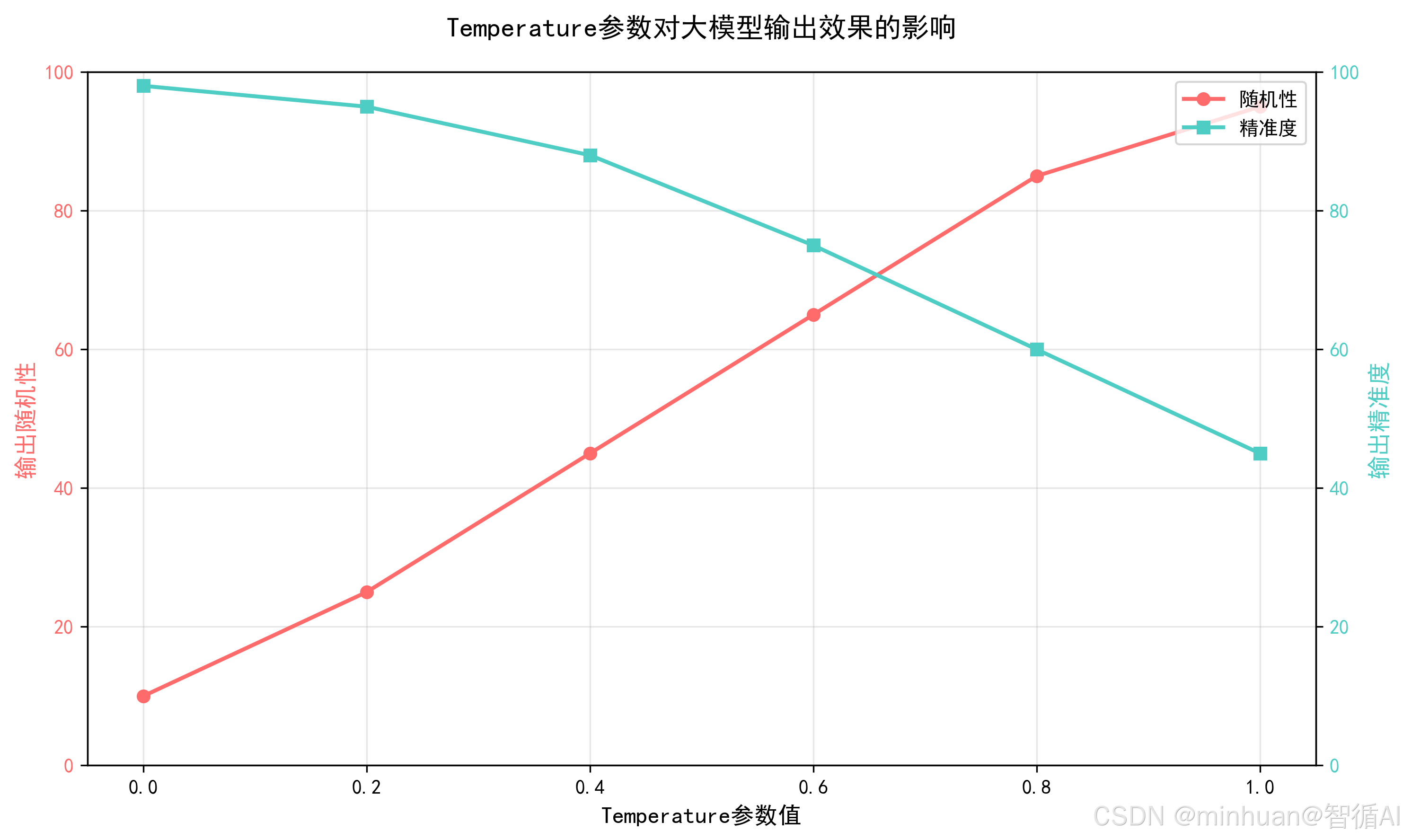
- temperature:控制生成的随机性,0 代表“绝对精准”,适合数据提取、逻辑推理),1 代表“高度创意”,适合文案、故事生成;
- max_tokens:API调用的模型都是按token计费,设置合理的最大值可避免生成过长内容,控制成本。
输出结果:
生成的学习计划:
### 7天大模型应用开发学习计划**第一天:Python编程基础**
* **上午**:
+ 学习Python的基本语法,如变量、数据类型、条件语句等。
+ 实战:编写简单的Python程序,如计算器、字符串处理等。* **下午**:
+ 学习Python的函数和模块,理解如何组织代码。
+ 实战:创建一个包含多个函数的程序,实现一个简单的任务。**第二天:Python进阶与数据处理**
* **上午**:
+ 深入学习Python的高级特性,如列表推导式、字典、异常处理等。
+ 实战:使用Pandas库进行简单的数据处理和分析。* **下午**:
+ 学习如何使用Python连接数据库,进行数据的增删改查操作。
+ 实战:编写一个简单的Python脚本,连接数据库并执行一些基本的数据操作。**第三天:深度学习基础**
* **上午**:
+ 了解深度学习的概念和原理,包括神经网络、激活函数等。
+ 学习Python中常用的深度学习库,如TensorFlow或PyTorch的基础用法。* **下午**:
+ 实战:构建一个简单的神经网络模型,用于解决一个分类问题(如图像分类)。
+ 学习模型的训练和评估方法。**第四天:模型训练与调优**
* **上午**:
+ 深入学习模型的训练过程,包括前向传播、反向传播等。
+ 学习如何调整模型参数以提高性能。* **下午**:
+ 实战:使用一个公开的数据集(如MNIST)训练一个更复杂的神经网络模型。
+ 学习如何评估模型性能,并进行调优。**第五天:模型部署与实际应用**
* **上午**:
+ 学习如何将训练好的模型部署到Web服务或移动应用中。
+ 了解常用的部署平台和工具。* **下午**:
+ 实战:选择一个实际的应用场景(如智能客服、图像识别等),并尝试部署自己的模型。
+ 学习如何收集和处理实际应用中的数据。**第六天:扩展学习与大模型实践**
* **上午**:
+ 深入学习大模型的相关知识,如模型压缩、加速等技术。
+ 了解如何使用分布式计算框架(如PyTorch Lightning)来训练大规模模型。* **下午**:
+ 实战:尝试使用一个大型的预训练模型(如BERT、GPT等)进行微调,以适应特定的任务。
+ 学习如何评估和优化大模型的性能。**第七天:总结与展望**
* 回顾过去一周的学习内容,总结重点和难点。
* 探讨大模型应用开发的未来趋势和技术方向。
* 制定个人的学习和发展计划,为后续的学习和实践奠定基础。
四、提示工程
提示工程是让大模型准确理解用户输入的核心技术,大模型的“回答质量”直接取决于我们给的“提示质量”,哪怕是同一个问题,不同的提示方式会得到完全不同的结果。
1. 基础示例对比
1.1 反面例子(模糊的提示)
# 模糊提示
bad_prompt = "写一份产品推广文案,200字以内"
bad_result = generate_text(bad_prompt)
print("模糊提示的结果:")
print(bad_result)输出结果:
模糊提示的结果:
**💥新品上市💥**
引领潮流的智能手环,让你的生活更精彩!💫
🌟精准心率监测、睡眠分析、运动记录,全方位健康管理,让你的健康一目了然。🩲
🎁时尚设计,多种颜色可选,佩戴舒适,展现个性魅力。🌈
💡超长续航,轻松陪伴你的每一天。🕒
🎉限时优惠,快来抢购吧!错过不再有!🏃♂️
让这款智能手环成为你生活中的得力助手,陪你探索更多可能!🌱
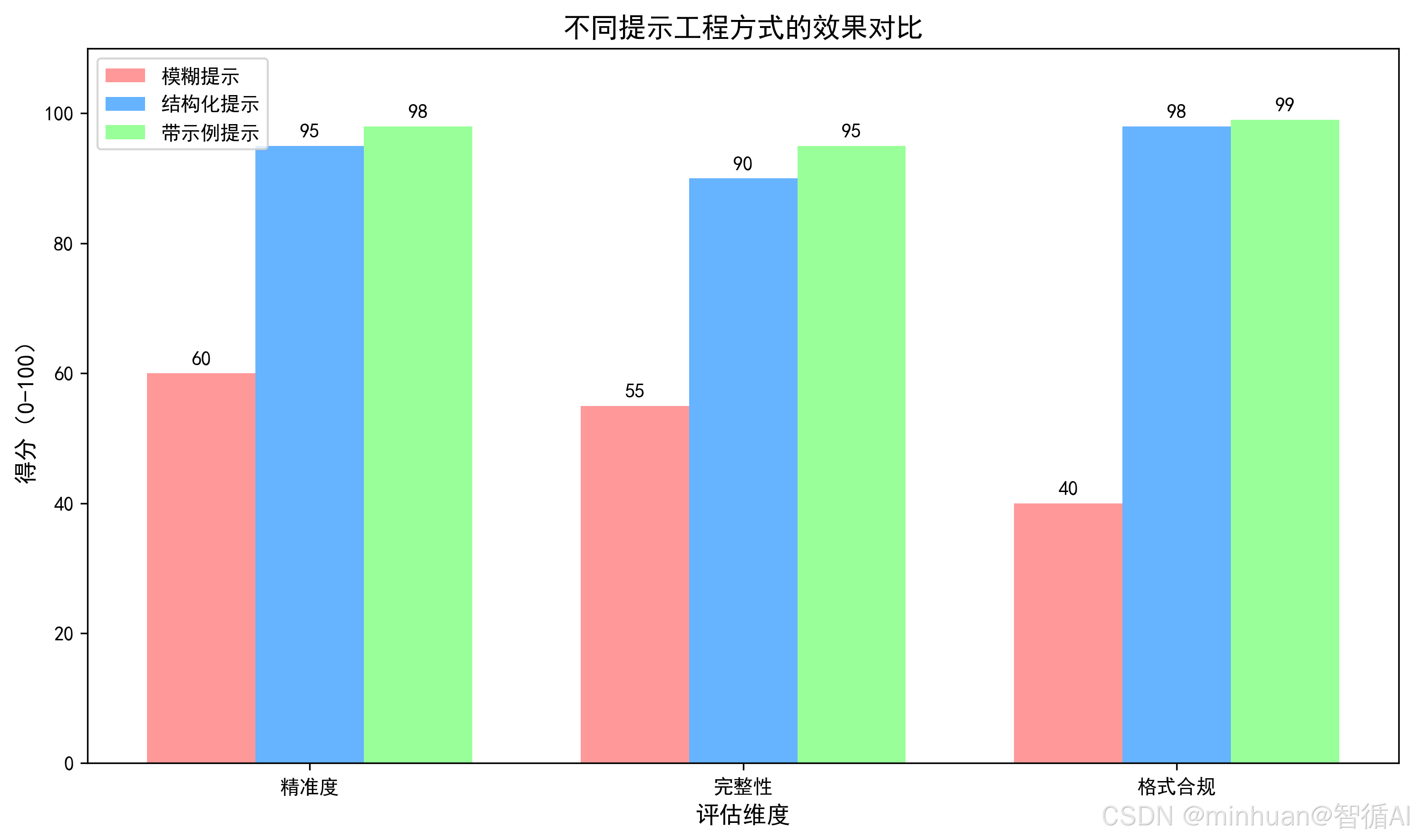
运行效果:生成的文案泛泛而谈,没有目标人群、没有产品卖点、没有风格要求,完全无法直接使用。
1.2 正面例子(结构化提示)
# 结构化提示(遵循SPOT原则:Specific-具体、Purpose-目的、Output-输出格式、Tone-语气)
good_prompt = """请为一款"便携式智能保温杯"撰写产品推广文案,要求:
1. 核心卖点:
- 精准控温(45-95℃可调)
- 超长续航(一次充电可用7天)
- 轻量化设计(仅200g)
2. 目标人群:25-35岁的职场白领
3. 输出格式:
- 标题(不超过20字)
- 正文(分3段,每段不超过50字)
- 结尾slogan(不超过10字)
4. 语气风格:温馨、专业、有质感,避免网络流行语, 200字以内
"""
good_result = generate_text(good_prompt)
print("结构化提示的结果:")
print(good_result)输出结果:
结构化提示的结果:
**标题:职场小助手,温暖随行****正文:**
职场如战场,一杯好水至关重要。我们这款便携式智能保温杯,精准控温45-95℃,无论冬日热茶还是夏日冷饮,都能恰到好处。超长续航,一次充电可用7天,让你 随时随地享受温暖。轻量化设计,仅200g,便携又不失品味。专为25-35岁职场白领打造,实用又贴心,让工作之余的温暖与关怀一路相伴。**结尾slogan:温暖随行,职场更精彩**
运行效果:生成的文案精准命中卖点,符合目标人群和格式要求,可直接用于推广。
2. 带示例的提示词(Few-shot)
当任务复杂时,给例子比讲道理更有效,直接给“输入 - 输出”示例,大模型能快速理解我们的需求:
# 带示例的提示(Few-shot)
few_shot_prompt = """请按照指定规则提取文本中的关键信息,规则如下:
1. 提取维度:人物、事件、时间、地点
2. 输出格式:JSON
3. 示例:
输入:2024年5月10日,张三在杭州市西湖区的咖啡馆和李四讨论了大模型应用开发的项目。
输出:{"人物":["张三","李四"],"事件":["讨论大模型应用开发项目"],"时间":["2024年5月10日"],"地点":["杭州市西湖区咖啡馆"]}
请处理以下文本:
输入:2024年6月15日,王五在上海市浦东新区的科技园区参加了大模型Agent技术分享会,并和赵六交流了智能工具集成的经验。
"""
few_shot_result = generate_text(few_shot_prompt)
print("带示例的提示结果:")
print(few_shot_result)输出结果:
带示例的提示结果:
{"人物":["王五","赵六"],"事件":["参加大模型Agent技术分享会","交流智能工具集成经验"],"时间":["2024年6月15日"],"地点":["上海市浦东新区科技园区"]}
运行效果:输出严格遵循 JSON 格式,提取的信息精准无遗漏。
3. 高级提示技巧:思维链(CoT)
思维链是提示工程的杀手锏,核心是让大模型一步步思考,而不是直接给出答案,尤其适合数学计算、逻辑推理、复杂问题拆解。
思维链的底层原理:
- 大模型本身不具备真正的推理能力,但思维链通过“强制分步思考”,让大模型在每一步都基于前一步的结果生成,避免了一步到位的错误;
- 相当于让“超级学霸”把解题过程写出来,而不是直接写答案,大大降低出错概率。
def cot_prompt_example():
"""思维链提示示例:复杂数学题推理"""
cot_prompt = """请解决以下数学问题,要求:
1. 先分步说明解题思路
2. 再给出最终答案
3. 每一步都要清晰易懂
问题:某商店进了一批商品,先以进价的150%定价,然后打8折出售,每件仍获利20元,请问该商品的进价是多少元?
"""
result = generate_text(cot_prompt)
print("思维链提示结果:")
print(result)
if __name__ == "__main__":
cot_prompt_example()输出结果:
思维链提示结果:
为了找出这批商品的进价,我们可以按照以下步骤进行计算:### 步骤1:设定变量并建立方程
**解题思路**:
- 设商品的进价为 x 元。
- 根据题意,商品以进价的150%定价,即定价为 1.5x 元。
- 然后商品打8折出售,即实际售价为 1.5x × 0.8 元。
- 题目告诉我们,每件商品仍获利20元,即实际售价比进价多20元。**建立方程**:
1.5x × 0.8 = x + 20### 步骤2:解方程
**解题思路**:
- 将方程 1.5x × 0.8 = x + 20 展开并简化。
- 解这个方程,求出 x 的值。**计算过程**:
1.5x × 0.8 = x + 20
1.2x = x + 20
1.2x - x = 20
0.2x = 20
x = 20/0.2
x = 100### 步骤3:得出结论
**解题思路**:
- 通过计算,我们得到了商品的进价 x 为100元。**最终答案**:
这批商品的进价是100元。
4. 提示工程的核心原则
4.1 清晰性原则:消除所有歧义
- 错误做法:“帮我优化这段代码”,没有说明优化目标:速度?可读性?内存?
- 正确做法:“帮我优化这段 Python 数据处理代码,目标是提升运行速度至少 30%,同时保证代码可读性,兼容 Python 3.8+”
4.2 结构化原则:用格式降低理解成本
大模型对“列表、分点、明确的分隔符”更敏感,推荐使用:
- 数字编号(1. 2. 3.)
- 符号分隔(### 输入数据 ###、### 输出要求 ###)
- 固定格式(JSON、Markdown)
4.3 示例原则(Few-shot):给例子比讲道理更有效
当任务复杂时,直接给“输入 - 输出”示例,大模型能快速理解具体需求:
- 输入:2024年5月10日,张三在杭州市余杭区的咖啡馆和李四讨论了大模型应用开发的项目。
- 输出:{"人物":["张三","李四"],"事件":["讨论大模型应用开发项目"],"时间":["2024年5月10日"],"地点":["杭州市余杭区咖啡馆"]}
4.4 约束原则:明确“不能做什么”
避免大模型生成无关内容,必须明确约束条件:
- 错误做法:“写一篇关于大模型的文章”
- 正确做法:“写一篇 800 字左右的大模型应用文章,仅限讲解提示工程,不涉及模型训练、算力等内容,语言通俗易懂,适合初学者”
五、智能 Agent
1. 智能 Agent 的核心价值
智能Agent是大模型应用的高阶形态,结合上面的提示词示例,提示工程能解决“单步任务”,但面对“多步骤、需要调用工具、需要自主决策”的复杂任务,单纯的提示工程就不够用了:
- 例子 1:“帮我写一份2024年新能源汽车市场分析报告”
- 单步提示:大模型只能基于自身训练数据生成,但数据可能过时;
- Agent 方式:先调用搜索引擎获取2024年最新数据→调用数据分析工具处理数据→生成图表→撰写报告→检查报告是否符合要求→修改优化。
- 例子 2:“帮我计算公司 Q2 的销售利润率,并生成可视化图表”
- 单步提示:大模型可能计算错误(尤其复杂计算);
- Agent 方式:读取销售数据文件→调用计算器工具计算利润率→调用 Matplotlib 生成图表→保存图表并生成分析说明。
2. 智能 Agent 的核心架构
智能Agent的核心是“感知 - 思考 - 行动 - 反馈”的闭环,架构如下:

模块说明:
- 1. 感知模块:理解用户的核心需求,本质是进阶版的提示工程;
- 2. 任务拆解模块:把复杂任务拆成多个可执行的子任务,如“写报告”拆成“找数据→分析数据→写内容→排版”;
- 3. 思考模块:核心决策层,决定每个子任务该用什么工具、按什么顺序执行;
- 4. 行动模块:执行具体操作,包括调用外部工具(搜索引擎、计算器、API)、调用大模型生成内容;
- 5. 结果反馈模块:检查子任务的执行结果是否符合要求,若不符合则重新拆解、执行;
- 6. 闭环逻辑:直到所有子任务完成,才生成最终结果。
3. 智能 Agent 的核心组件
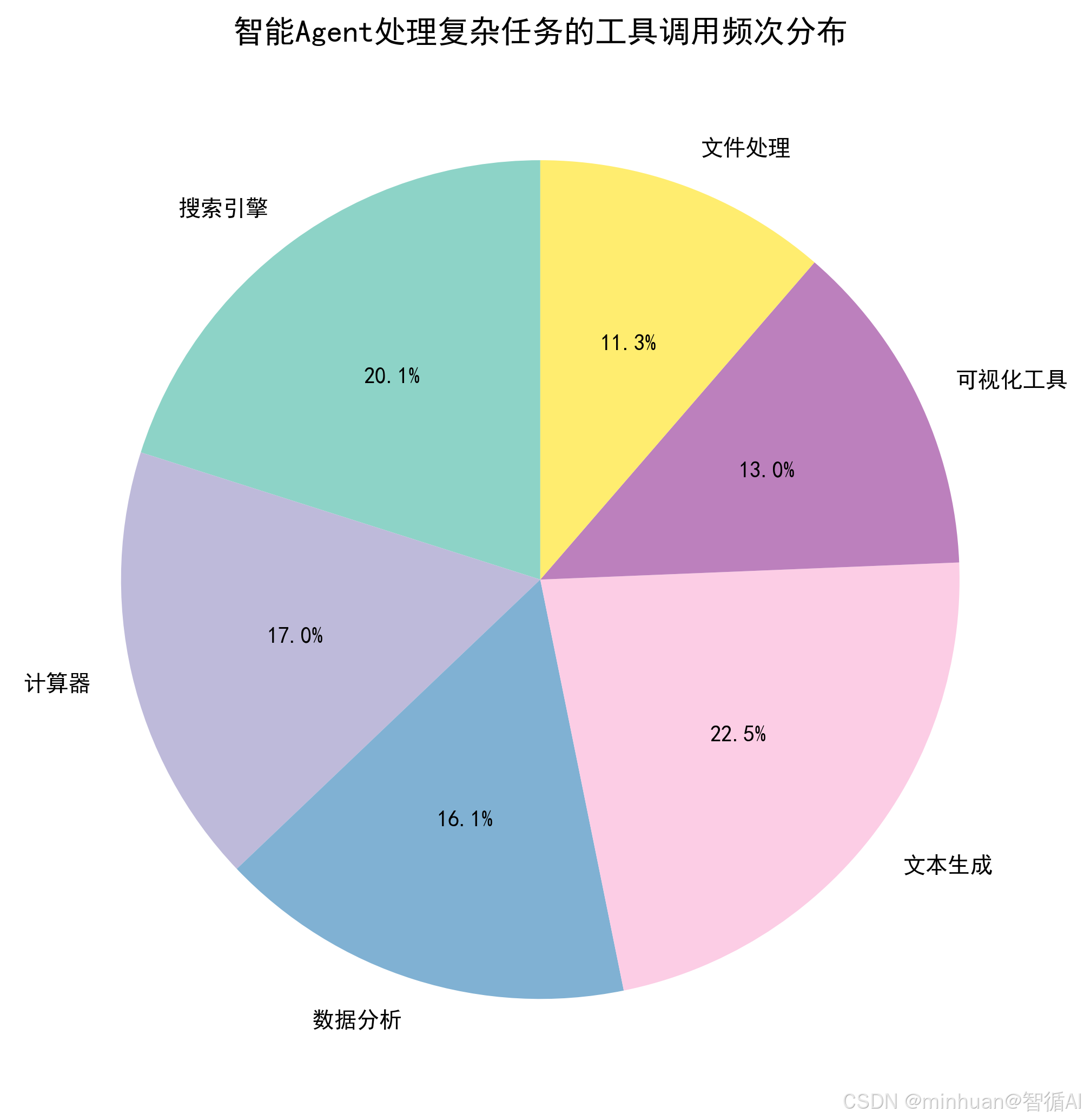
3.1 工具(Tools)
Agent能调用的“外部能力,常见工具包括:
- 基础工具:计算器、文本处理工具、日期工具;
- 网络工具:搜索引擎、API 调用工具;
- 文件工具:读取或写入文件、Excel 处理工具;
- 自定义工具:根据业务需求开发的专用工具,如数据库查询工具、报表生成工具。
3.2 工具调用(Tool Calling)
大模型根据任务需求,自主选择并调用合适的工具,核心是让大模型输出“工具调用指令”,代码解析后执行。
3.3 记忆(Memory)
Agent 能记住之前的操作和结果,分为:
- 短期记忆:当前任务的执行步骤和结果;
- 长期记忆:历史任务的经验,如“处理销售数据时,优先使用Excel工具而不是手动计算”。
3.4 规划(Planning)
Agent 能自主规划任务执行步骤,常见策略:
- 分步规划:把复杂任务拆成线性步骤(Step 1→Step 2→Step 3);
- 分层规划:先确定大目标,再拆分子目标,最后拆分子步骤;
- 反馈规划:根据执行结果动态调整步骤。
4. 基础智能 Agent 实现
我们以"带工具调用的计算器Agent"为例,开发一个能自主处理复杂数学计算的Agent,具备:
- 1. 理解用户的计算需求;
- 2. 拆解复杂计算为多个子计算;
- 3. 调用计算器工具执行计算;
- 4. 验证计算结果;
- 5. 输出分步计算过程和最终结果。
import os
import json
import re
from openai import OpenAI
from typing import List, Dict, Any
# 初始化客户端(使用混元大模型)
client = OpenAI(
api_key= os.getenv("TENCENT_API_KEY"),
base_url="https://api.hunyuan.cloud.tencent.com/v1"
)
# -------------------------- 工具定义 --------------------------
class CalculatorTool:
"""计算器工具类,提供基础数学计算功能"""
@staticmethod
def calculate(expression: str) -> float:
"""
执行数学计算
:param expression: 数学表达式(如"20+30*2")
:return: 计算结果
"""
# 安全过滤:只允许数字和基础运算符,避免代码注入
safe_expression = re.sub(r"[^0-9\+\-\*\/\(\)\.]", "", expression)
if not safe_expression:
raise ValueError("无效的数学表达式")
# 执行计算
try:
result = eval(safe_expression) # 仅用于示例,生产环境需用更安全的计算方式
return float(result)
except Exception as e:
raise ValueError(f"计算失败:{str(e)}")
# 工具注册表:管理所有可用工具
TOOL_REGISTRY = {
"calculator": {
"name": "calculator",
"description": "用于执行数学计算的工具,输入是数学表达式(如'20+30*2'),输出是计算结果",
"function": CalculatorTool.calculate
}
}
# -------------------------- Agent核心逻辑 --------------------------
class SimpleCalculatorAgent:
"""简单的计算器Agent,能拆解复杂计算任务并调用工具"""
def __init__(self):
self.tools = TOOL_REGISTRY
self.memory = [] # 存储执行步骤和结果(短期记忆)
def _parse_task(self, user_query: str) -> List[Dict[str, Any]]:
"""
解析用户查询,拆解为工具调用步骤
:param user_query: 用户的计算需求
:return: 工具调用步骤列表,格式:[{"tool": "calculator", "expression": "表达式", "description": "步骤说明"}]
"""
prompt = f"""请将以下数学计算需求拆解为具体的工具调用步骤,要求:
1. 每一步只能调用"calculator"工具,执行一个简单的数学表达式计算
2. 步骤要清晰,按计算顺序排列
3. 每个步骤包含:tool(固定为"calculator")、expression(数学表达式)、description(该步骤的说明)
4. 输出格式为JSON数组,不要添加任何额外内容
用户计算需求:{user_query}
示例输出:
[
{{"tool": "calculator", "expression": "30*2", "description": "计算30的2倍"}},
{{"tool": "calculator", "expression": "20+60", "description": "将20和第一步的结果相加"}}
]
"""
# 调用大模型拆解任务
response = client.chat.completions.create(
model="hunyuan-lite",
messages=[{"role": "user", "content": prompt}],
temperature=0.1,
max_tokens=500
)
# 输出原始响应用于调试
raw_content = response.choices[0].message.content.strip()
print(f"[DEBUG] 原始返回内容:\n{raw_content}\n")
# 解析结果
try:
steps = json.loads(raw_content)
return steps
except json.JSONDecodeError:
raise ValueError("无法解析计算步骤,请简化你的计算需求")
def _execute_step(self, step: Dict[str, Any]) -> float:
"""
执行单个计算步骤
:param step: 步骤字典
:return: 计算结果
"""
tool_name = step.get("tool")
expression = step.get("expression")
# 检查工具是否存在
if tool_name not in self.tools:
raise ValueError(f"未知工具:{tool_name}")
# 调用工具
tool_func = self.tools[tool_name]["function"]
result = tool_func(expression)
# 记录到记忆中
self.memory.append({
"step": step,
"result": result
})
return result
def _generate_final_report(self) -> str:
"""生成最终的计算报告"""
report = "### 计算过程与结果\n"
total_result = 0
for i, item in enumerate(self.memory, 1):
step = item["step"]
result = item["result"]
report += f"{i}. {step['description']}:{step['expression']} = {result}\n"
# 最后一步的结果就是总结果
if i == len(self.memory):
total_result = result
report += f"\n### 最终结果:{total_result}"
return report
def run(self, user_query: str) -> str:
"""
运行Agent处理用户查询
:param user_query: 用户的计算需求
:return: 计算报告
"""
# 重置记忆
self.memory = []
try:
# 1. 拆解任务
steps = self._parse_task(user_query)
if not steps:
return "无法拆解你的计算需求,请重新描述"
# 2. 执行每一步
for step in steps:
self._execute_step(step)
# 3. 生成报告
return self._generate_final_report()
except Exception as e:
return f"计算失败:{str(e)}"
# -------------------------- 测试Agent --------------------------
if __name__ == "__main__":
# 创建Agent实例
agent = SimpleCalculatorAgent()
# 测试复杂计算需求
user_query = "请计算:(25+35)*4 - 120/3 + 80,分步展示计算过程"
# 运行Agent
result = agent.run(user_query)
# 输出结果
print("Calculator Agent 计算结果:")
print(result)代码细节:
- 工具安全过滤:使用正则表达式re.sub(r"[^0-9\+\-\*\/\(\)\.]", "", expression)过滤非法字符,避免eval()函数执行恶意代码;
- 任务拆解逻辑:通过大模型将复杂计算拆分为多个单步计算,确保每一步都能被计算器工具处理;
- 记忆模块:用self.memory存储每一步的执行过程和结果,用于生成最终报告;
- 工具注册表:TOOL_REGISTRY统一管理所有可用工具,方便扩展,如后续添加平方根、幂运算工具;
- 异常处理:覆盖工具调用、JSON 解析、计算执行等环节的异常,保证 Agent 的健壮性。
输出结果:
[DEBUG] 原始返回内容:
[
{"tool": "calculator", "expression": "25+35", "description": "计算25加上35的和"},
{"tool": "calculator", "expression": "(25+35)*4", "description": "将上一步的结果乘以4"},
{"tool": "calculator", "expression": "120/3", "description": "计算120除以3的商"},
{"tool": "calculator", "expression": "(25+35)*4 - 120/3", "description": "将上一步的结果减去120除以3的商"},
{"tool": "calculator", "expression": "(25+35)*4 - 120/3 + 80", "description": "在上一步的结果上加80"}
]
Calculator Agent 计算结果:
### 计算过程与结果
1. 计算25加上35的和:25+35 = 60.0
2. 将上一步的结果乘以4:(25+35)*4 = 240.0
3. 计算120除以3的商:120/3 = 40.0
4. 将上一步的结果减去120除以3的商:(25+35)*4 - 120/3 = 200.0
5. 在上一步的结果上加80:(25+35)*4 - 120/3 + 80 = 280.0
### 最终结果:280.0
六、总结
今天对大模型应用开发做了一个基础链路梳理,首先咱们明确了,学大模型应用,不是必须要去训练模型,那得要大算力、大数据,普通玩家普通设备都玩不起,核心是学会调用驾驭它,用它解决实际问题。最基础的就是提示工程,说白了就是会提问,不是随便问,而是要结构化、讲清楚要求,甚至给例子,让大模型精准输出你要的东西,比如文本提取、写文案这些,用对提示词,效果能差一倍。
然后进阶到智能 Agent,这是超越单纯问答的关键,相当于给大模型加了手脚和脑子,它能自己拆解复杂任务,调用搜索引擎、计算器、图表工具这些,比如我们让它写市场分析报告,它能自己找数据、分析数据、做图表,最后生成完整报告,不用我们一步步指挥。
整体来说,就是从基础的 API 调用、提示工程,到高阶的Agent开发,一步步逐渐深入,让我们不用懂复杂的底层原理,也能开发出实用的大模型应用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 36
36 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)