【kaggel竞赛项目】BirdCLEF+ 2026_实践全过程
一、学习环境配置(本地训练流程,notebook版不需要看)
1.运行Anaconda Prompt
2.创建新环境birdclef
conda create -n birdclef python=3.10 -y3.激活新环境
conda activate birdclef4.安装pytorch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu1185.安装其他依赖库
pip install librosa pandas numpy tqdm6.测试GPU是否成功
新建文件test_gpu.py
import torch
print(torch.cuda.is_available())
print(torch.cuda.get_device_name(0))运行结果如下即配置成功
- True
- NVIDIA GeForce GTX 1050
二、v1.0尝试vibe coding版框架代码学习(notebook)
1.逐模块解析
1. 1导入依赖(基础工具包)
import os # 操作系统文件/路径操作
import numpy as np # 数值计算(数组、矩阵)
import pandas as pd # 处理CSV表格数据
import torch # PyTorch深度学习框架核心
import torch.nn as nn # 神经网络层(如全连接、卷积)
import torch.optim as optim # 优化器(如Adam)
from sklearn.model_selection import train_test_split # 划分训练/验证集
from torch.utils.data import Dataset, DataLoader # 自定义数据集+批量加载
import torchaudio # PyTorch音频处理库(加载、变换音频)
from torchvision.models import resnet18 # 预训练ResNet18模型
from torchvision.models.resnet import ResNet18_Weights # ResNet权重(兼容新版本)
from tqdm import tqdm # 进度条(可视化训练/推理进度)
import warnings
warnings.filterwarnings("ignore") # 忽略无关警告(如版本兼容警告)
核心作用:把需要的工具包都导入,相当于给代码准备好 “工具箱”。
1. 2基础配置(固定参数 + 环境)
# 设置随机种子保证可复现性(每次运行结果一致)
torch.manual_seed(42)
np.random.seed(42)
# 设备配置:优先用GPU(cuda),没有就用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# ===================== 超参数 =====================
BATCH_SIZE = 32 # 每次训练/推理的样本数(批次越大,训练越快,占用显存越多)
EPOCHS = 10 # 训练轮次(整个数据集训练10遍)
LR = 1e-4 # 学习率(参数更新的步长,越小越慢但越稳)
NUM_MELS = 64 # 梅尔频谱的维度(64个梅尔滤波器)
SAMPLE_RATE = 32000 # 音频采样率(统一转为32kHz)
MAX_SEC = 5 # 音频统一长度为5秒(BirdCLEF竞赛标准)
WINDOW_SEC = 5 # 测试集长音频的分段窗口(5秒一段)
STEP_SEC = 5 # 分段滑动步长(无重叠,每次移5秒)
# ===================== Kaggle 固定路径 =====================
TRAIN_CSV = "/kaggle/input/competitions/birdclef-2026/train.csv" # 训练标签文件
TRAIN_AUDIO = "/kaggle/input/competitions/birdclef-2026/train_audio" # 训练音频文件夹
TEST_AUDIO = "/kaggle/input/competitions/birdclef-2026/test_soundscapes" # 测试音频文件夹
SAMPLE_SUB_PATH = "/kaggle/input/competitions/birdclef-2026/sample_submission.csv" # 提交样例
关键解释:
- 随机种子:保证每次运行代码,随机操作(如数据划分、模型初始化)的结果一致,方便调试。
- 超参数:可以调整的参数,影响模型训练效果和速度。
- Kaggle 路径:竞赛平台的固定文件路径,本地运行需要改成自己的路径。
1. 3读取标签(处理分类类别)
# 读取训练标签CSV文件
df = pd.read_csv(TRAIN_CSV)
# 增加no_bird类别(BirdCLEF必需:表示这段音频没有鸟叫)
labels = sorted(df["primary_label"].unique()) + ["no_bird"]
# 标签转ID(字符串标签→数字,方便模型计算)
label2id = {lbl: i for i, lbl in enumerate(labels)}
# ID转标签(数字→字符串,推理时还原结果)
id2label = {i: lbl for i, lbl in enumerate(labels)}
NUM_CLASSES = len(labels) # 总分类数(所有鸟类 + no_bird)
# 划分训练/验证集:90%训练,10%验证,随机种子42保证划分一致
train_df, val_df = train_test_split(df, test_size=0.1, random_state=42)
核心作用:
- 把鸟类的字符串标签(如 "amecro")转为数字 ID(如 0、1、2),因为模型只能处理数字。
- 划分训练集(用来训练模型)和验证集(用来评估模型效果,不参与训练)。
1. 4自定义数据集(核心:处理音频→梅尔频谱)
class BirdDataset(Dataset):
def __init__(self, df, audio_path, is_test=False):
# 初始化:传入数据表格、音频路径、是否是测试集
self.df = df.reset_index(drop=True) # 重置索引,避免索引混乱
self.audio_path = audio_path # 音频文件夹路径
self.is_test = is_test # 标记是否是测试集(测试集无标签)
def __len__(self):
# 返回数据集总长度(样本数),DataLoader需要
return len(self.df)
def process_audio(self, wav, sr):
"""统一音频处理逻辑:把原始音频转为3通道梅尔频谱(适配ResNet)"""
# 1. 重采样:统一转为32kHz(不同音频采样率可能不同)
if sr != SAMPLE_RATE:
wav = torchaudio.functional.resample(wav, sr, SAMPLE_RATE)
# 2. 单声道处理:如果是立体声(2通道),转为单声道(取均值)
if wav.shape[0] > 1:
wav = torch.mean(wav, dim=0, keepdim=True)
# 3. 统一长度:5秒=32000*5=160000个采样点
max_len = SAMPLE_RATE * MAX_SEC
if wav.shape[1] > max_len: # 过长:截断
wav = wav[:, :max_len]
else: # 过短:补零(填充到5秒)
wav = nn.functional.pad(wav, (0, max_len - wav.shape[1]))
# 4. 生成梅尔频谱(把音频波形→频谱图,ResNet处理图像更擅长)
mel_transform = torchaudio.transforms.MelSpectrogram(
sample_rate=SAMPLE_RATE, # 采样率
n_mels=NUM_MELS, # 梅尔滤波器数量(64)
n_fft=1024, # FFT窗口大小(控制频率分辨率)
hop_length=512, # 步长(控制时间分辨率)
f_min=50, # 最低频率(鸟类叫声主要在50Hz以上)
f_max=15000 # 最高频率(鸟类叫声主要在15kHz以下)
)
mel = mel_transform(wav) # 生成梅尔频谱(幅度)
mel = torchaudio.transforms.AmplitudeToDB()(mel) # 转为分贝(更符合人耳感知)
# 5. 归一化:均值为0,标准差为1(提升模型收敛速度和效果)
mel = (mel - mel.mean()) / (mel.std() + 1e-6) # +1e-6避免除以0
# 6. 转为3通道:ResNet默认输入3通道(RGB图像),这里把单通道复制3次
mel = mel.repeat(3, 1, 1)
return mel
def __getitem__(self, idx):
# 核心:根据索引获取单个样本(DataLoader会批量调用)
try:
row = self.df.iloc[idx] # 获取第idx行数据
# 处理文件名(兼容训练/测试集不同列名)
if not self.is_test:
fname = row["filename"] # 训练集:filename列是音频路径
else:
# 测试集:优先取file_name,没有就取row_id,补充.ogg后缀
fname = row.get("file_name", row.get("row_id", ""))
if not fname.endswith(('.ogg', '.wav', '.mp3')):
fname += ".ogg"
# 拼接音频完整路径
wav_path = os.path.join(self.audio_path, fname)
# 检查文件是否存在(兼容BirdCLEF音频按物种分类的文件夹结构)
if not os.path.exists(wav_path):
alt_path = os.path.join(self.audio_path, fname.split('/')[-2], fname.split('/')[-1])
if os.path.exists(alt_path):
wav_path = alt_path
else:
raise FileNotFoundError(f"音频文件不存在: {wav_path}")
# 加载音频:返回(波形数据,采样率)
wav, sr = torchaudio.load(wav_path)
# 处理音频→梅尔频谱
mel = self.process_audio(wav, sr)
# 训练集返回(梅尔频谱,标签ID);测试集返回(梅尔频谱,文件名)
if self.is_test:
return mel, fname
return mel, label2id[row["primary_label"]]
except Exception as e:
# 异常处理:如果当前样本出错,取下一个样本(避免程序崩溃)
print(f"处理索引 {idx} 出错: {str(e)[:50]},尝试下一个样本")
return self.__getitem__((idx + 1) % len(self.df))
关键解释:
Dataset是 PyTorch 的抽象类,必须实现__len__和__getitem__。- 核心逻辑
process_audio:把原始音频波形→梅尔频谱(图像化),因为 ResNet 是为图像设计的,处理频谱图比直接处理波形效果更好。 - 异常处理:避免单个音频文件损坏导致整个程序停止。
1. 5长音频分段处理(测试集专用)
def process_long_audio(file_path):
"""
处理BirdCLEF测试集长音频(测试集是长音频,需要按5秒窗口分段预测)
返回:分段梅尔频谱 + 每个分段的row_id(竞赛要求的提交格式)
"""
# 加载长音频
wav, sr = torchaudio.load(file_path)
# 重采样和单声道处理(和训练集保持一致)
if sr != SAMPLE_RATE:
wav = torchaudio.functional.resample(wav, sr, SAMPLE_RATE)
if wav.shape[0] > 1:
wav = torch.mean(wav, dim=0, keepdim=True)
segments = [] # 存储分段后的梅尔频谱
row_ids = [] # 存储每个分段的row_id(提交用)
file_name = os.path.basename(file_path) # 获取文件名(如"soundscape_1.ogg")
base_id = os.path.splitext(file_name)[0] # 去掉后缀(如"soundscape_1")
# 计算分段参数
window_len = SAMPLE_RATE * WINDOW_SEC # 5秒的采样点数
step_len = SAMPLE_RATE * STEP_SEC # 滑动步长(5秒)
# 计算总段数(向上取整,确保覆盖整个音频)
num_segments = max(1, int(np.ceil(wav.shape[1] / window_len)))
# 逐段处理
for i in range(num_segments):
start = i * step_len # 起始位置
end = start + window_len # 结束位置
# 截取或补零(保证每段都是5秒)
if end > wav.shape[1]:
# 最后一段:补零到5秒
seg = nn.functional.pad(wav[:, start:], (0, window_len - (wav.shape[1] - start)))
else:
# 正常截取
seg = wav[:, start:end]
# 处理为梅尔频谱(复用Dataset的process_audio方法)
mel = BirdDataset(None, None).process_audio(seg, SAMPLE_RATE)
segments.append(mel)
# 生成竞赛要求的row_id:soundscape_id_start_end(如soundscape_1_0_5)
row_id = f"{base_id}_{i*WINDOW_SEC}_{(i+1)*WINDOW_SEC}"
row_ids.append(row_id)
# 把分段的梅尔频谱拼接成张量,返回
return torch.stack(segments), row_ids
核心作用:
- 测试集的音频是长音频(如 10 分钟),而训练集是 5 秒短音频,需要把长音频切成 5 秒一段,逐段预测。
- 生成符合竞赛要求的
row_id(如soundscape_1_0_5表示第一个音频的 0-5 秒段)。
1. 6创建数据加载器(批量加载数据)
# 创建训练/验证数据集实例
train_ds = BirdDataset(train_df, TRAIN_AUDIO)
val_ds = BirdDataset(val_df, TRAIN_AUDIO)
# 创建DataLoader(批量加载、打乱、多线程)
train_loader = DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True, num_workers=2, pin_memory=True)
val_loader = DataLoader(val_ds, batch_size=BATCH_SIZE, shuffle=False, num_workers=2, pin_memory=True)
关键参数解释:
shuffle=True:训练集打乱(避免模型学习顺序),验证集不打乱。num_workers=2:多线程加载数据(加快速度)。pin_memory=True:锁页内存(加快数据从 CPU→GPU 的传输)。
1. 7构建模型(ResNet18 迁移学习)
# 兼容低版本PyTorch的ResNet加载方式
try:
# 新版本PyTorch用weights参数
model = resnet18(weights=ResNet18_Weights.IMAGENET1K_V1)
except:
# 旧版本PyTorch用pretrained参数
model = resnet18(pretrained=True)
# 修改最后一层:适配我们的分类数
model.fc = nn.Sequential(
nn.Dropout(0.3), # 随机丢弃30%的神经元(防止过拟合)
nn.Linear(model.fc.in_features, NUM_CLASSES)
)
# 把模型移到GPU/CPU
model = model.to(device)
# 损失函数和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失(多分类任务)
optimizer = optim.Adam(model.parameters(), lr=LR) # Adam优化器(主流选择)
# 学习率调度器:验证损失不下降时,降低学习率(防止过拟合)
# ReduceLROnPlateau:耐心2轮,损失不降则学习率减半
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=2, factor=0.5)
核心逻辑:
- 迁移学习:用预训练在 ImageNet 上的 ResNet18,只修改最后一层(全连接层),适配鸟类分类数。
Dropout(0.3):防止过拟合(训练时随机丢弃部分神经元,避免模型依赖特定特征)。- 学习率调度器:训练后期降低学习率,让模型更精细地调整参数。
1. 8验证函数(评估模型效果)
def validate(model, loader):
"""验证函数:计算验证集损失和准确率"""
model.eval() # 模型设为评估模式(Dropout、BN层行为改变)
correct = 0 # 正确预测数
total = 0 # 总样本数
val_loss = 0 # 总损失
with torch.no_grad(): # 禁用梯度计算(节省显存、加快速度)
for x, y in loader:
x, y = x.to(device), y.to(device) # 数据移到GPU/CPU
outputs = model(x) # 模型预测
loss = criterion(outputs, y) # 计算损失
val_loss += loss.item() # 累加损失
_, predicted = torch.max(outputs.data, 1) # 取概率最大的类别
total += y.size(0) # 累加样本数
correct += (predicted == y).sum().item() # 累加正确数
accuracy = 100 * correct / total # 计算准确率
avg_loss = val_loss / len(loader) # 计算平均损失
return avg_loss, accuracy
关键解释:
model.eval():评估模式,Dropout 不再丢弃神经元,BN 层用训练时的均值 / 方差。torch.no_grad():禁用梯度,因为验证不需要更新参数,节省资源。
1. 9训练主循环(训练 + 验证)
best_val_acc = 0 # 记录最佳验证准确率
for epoch in range(EPOCHS):
# 训练阶段
model.train() # 模型设为训练模式(启用Dropout)
total_loss = 0 # 训练总损失
# 进度条:可视化训练进度
pbar = tqdm(train_loader, desc=f"Epoch {epoch+1}/{EPOCHS}")
for x, y in pbar:
x, y = x.to(device), y.to(device) # 数据移到设备
optimizer.zero_grad() # 清空梯度(避免累加)
outputs = model(x) # 前向传播(模型预测)
loss = criterion(outputs, y) # 计算损失
loss.backward() # 反向传播(计算梯度)
optimizer.step() # 优化器更新参数
total_loss += loss.item() # 累加损失
# 更新进度条显示当前损失
pbar.set_postfix(train_loss=f"{loss.item():.4f}")
# 验证阶段
train_avg_loss = total_loss / len(train_loader) # 训练平均损失
val_avg_loss, val_acc = validate(model, val_loader) # 验证损失和准确率
# 手动打印学习率调整信息(兼容低版本PyTorch)
current_lr = optimizer.param_groups[0]['lr']
scheduler.step(val_avg_loss) # 根据验证损失调整学习率
new_lr = optimizer.param_groups[0]['lr']
if new_lr < current_lr:
print(f"🔄 学习率调整: {current_lr:.6f} → {new_lr:.6f}")
# 保存最佳模型(验证准确率更高时)
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save(model.state_dict(), "/kaggle/working/best_model.pth")
print(f"🏆 保存最佳模型 - 验证准确率: {val_acc:.2f}%")
# 打印本轮训练/验证结果
print(f"\nEpoch {epoch+1} Summary:")
print(f"Train Loss: {train_avg_loss:.4f} | Val Loss: {val_avg_loss:.4f}")
print(f"Val Accuracy: {val_acc:.2f}% | Best Val Acc: {best_val_acc:.2f}%")
print(f"Current LR: {new_lr:.6f}\n")
训练核心流程:
- 每轮训练:遍历训练集→前向传播→计算损失→反向传播→更新参数。
- 每轮训练后:用验证集评估模型效果。
- 保存最佳模型:只有验证准确率更高时,才保存模型(避免保存过拟合的模型)。
- 调整学习率:验证损失不下降时,学习率减半。
1. 10测试集推理(生成提交文件)
def prepare_test_data():
"""准备测试数据:优先用官方提交样例,没有就扫描文件夹"""
if os.path.exists(SAMPLE_SUB_PATH):
print("使用官方提交样例文件")
sample_sub = pd.read_csv(SAMPLE_SUB_PATH)
# 提取唯一的音频ID(从row_id中拆分)
sample_sub['audio_id'] = sample_sub['row_id'].apply(lambda x: x.split('_')[0])
test_audio_ids = sample_sub['audio_id'].unique()
test_files = [f"{audio_id}.ogg" for audio_id in test_audio_ids]
else:
print("扫描测试音频文件夹")
test_files = []
for f in os.listdir(TEST_AUDIO):
if f.endswith(('.ogg', '.wav', '.mp3')):
test_files.append(f)
return test_files
# 加载最佳模型(训练好的模型参数)
model.load_state_dict(torch.load("/kaggle/working/best_model.pth"))
model.eval() # 评估模式
# 准备测试文件列表
test_files = prepare_test_data()
all_predictions = [] # 存储所有预测结果
# 批量推理
with torch.no_grad():
pbar = tqdm(test_files, desc="测试集推理")
for file_name in pbar:
file_path = os.path.join(TEST_AUDIO, file_name)
# 处理长音频→分段梅尔频谱+row_id
mel_segments, row_ids = process_long_audio(file_path)
# 移到设备
mel_segments = mel_segments.to(device)
# 模型预测
outputs = model(mel_segments)
# 转为概率(softmax:所有类别概率和为1)
probs = torch.softmax(outputs, dim=1).cpu().numpy()
# 构建预测结果(按竞赛要求格式)
for i, row_id in enumerate(row_ids):
pred_dict = {"row_id": row_id}
# 为每个标签赋值概率
for lbl, idx in label2id.items():
pred_dict[lbl] = probs[i][idx]
all_predictions.append(pred_dict)
# ===================== 生成标准提交文件 =====================
# 转为DataFrame
submission_df = pd.DataFrame(all_predictions)
# 确保列顺序正确:先row_id,然后按字母顺序排列标签
columns_order = ["row_id"] + sorted(labels)
submission_df = submission_df[columns_order]
# 去重(避免重复的row_id)
submission_df = submission_df.drop_duplicates(subset=['row_id'], keep='first')
# 保存提交文件
submission_path = "/kaggle/working/submission.csv"
submission_df.to_csv(submission_path, index=False)
# 打印结果信息
print(f"\n✅ 提交文件已生成!")
print(f"📊 提交文件形状: {submission_df.shape}")
print(f"📋 前5行预览:")
print(submission_df.head())
# 验证提交格式(关键!)
print(f"\n🔍 提交格式验证:")
print(f"- 包含row_id列: {'row_id' in submission_df.columns}")
print(f"- 包含所有标签列: {set(labels).issubset(set(submission_df.columns))}")
print(f"- 概率值范围: [{submission_df[labels].min().min():.4f}, {submission_df[labels].max().max():.4f}]")
核心逻辑:
- 加载训练好的最佳模型,对测试集长音频分段预测。
- 用
softmax把模型输出转为概率(竞赛要求输出概率,而非硬标签)。 - 按竞赛要求的格式生成 CSV 文件(包含 row_id 和每个标签的概率)。
- 验证提交格式:确保列正确、概率范围合理(0-1)。
2.总结(核心关键点)
2.1核心思路
把音频转为梅尔频谱(图像化),用预训练的 ResNet18 做迁移学习,完成鸟类音频多分类。
2.2数据处理
统一音频长度(5 秒)、采样率(32kHz)、转为单声道,梅尔频谱归一化 + 转 3 通道适配 ResNet。
2.3训练逻辑
训练 + 验证结合,保存最佳模型,用学习率调度器防止过拟合。
2.4推理逻辑
测试集长音频分段处理,输出每个 5 秒段的鸟类概率,按竞赛格式生成提交文件。
3.该版本存在的问题与反思
3.1注意输入输出要求
首先BirdCLEF+ 2026里给的输入文件不只有train.csv,还有其他文件
其次,要求notebook的输出文件的名称必须为submission.csv且必须是如下样式

3.2训练和提交流程总结
根据多次尝试,训练模型流程代码和测试流程代码最好分开,训练流程的代码可以设置一个预加载模型的入口,以及每轮训练结束可以根据平均loss是否降低来确定是否保存到最佳模型。基于此
训练流程为:
1.检测是否有预加载模型(提供一个input区的文件入口看有无文件)
2.若有,则加载预加载模型继续训练;若无,则开始第一轮训练
3.训练epochs轮,每一轮若模型更优,则保存为best_model
4.立刻下载best_model到本地,因为存在notebook的output区很容易丢失
5.上传best_model到input区的dataset中,作为预加载模型开始下一轮
提交流程为:
1.将input中的导入的best_model加载到提交版本(其实就是把训练部分去掉)
2.测试输出无问题后,保存notebook的vertion选择save and run
3.在竞赛界面点submit prediction提交刚才保存version
3.3注意要断网提交
提交要求必须要关闭notebook,setting选项里的turn off the internet,
但是model模块中需要先联网下载resnet18然后再进行迁移学习
所以要修改model,大致思路为先在本地下载好resnet18的基础模型,再上传到input区,然后直接提供一个文件路径来使用
3.4训练必须挂载GPU
第一次训练由于没有挂载,导致10轮数据纯用cpu跑了整整7小时!
挂载方法是右侧session options里的accelerator
最好选择GPU T4*2
notebook每周可以白嫖30小时的GPU算力,且每次train不能超过9小时,需要规划好时间
基于以上基础,终于研究出了能提交的v2.0基线版
三、v2.0baseline版代码(notebook版)
1.train代码
注意修改模型文件地址接口以及各地址接口,以及超参数
import os
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from torch.utils.data import Dataset, DataLoader
import torchaudio
from torchvision.models import resnet18
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# ===================== 超参数 =====================
BATCH_SIZE = 32
EPOCHS = 1
LR = 1e-4
NUM_MELS = 64
SAMPLE_RATE = 32000
MAX_SEC = 5
# ===================== 路径 =====================
BASE_PATH = "/kaggle/input/competitions/birdclef-2026"
TRAIN_CSV = f"{BASE_PATH}/train.csv"
TRAIN_SOUNDSCAPES_LABELS = f"{BASE_PATH}/train_soundscapes_labels.csv"
TAXONOMY_CSV = f"{BASE_PATH}/taxonomy.csv"
TRAIN_AUDIO = f"{BASE_PATH}/train_audio"
TRAIN_SOUNDSCAPES = f"{BASE_PATH}/train_soundscapes"
TEST_SOUNDSCAPES = f"{BASE_PATH}/test_soundscapes"
SAMPLE_SUBMISSION = f"{BASE_PATH}/sample_submission.csv"
RESNET_WEIGHTS = "/kaggle/input/datasets/heifruit/resnet18/resnet18-f37072fd.pth"
# 模型文件地址接口(核心新增:可修改此路径指定预加载模型)
PRETRAINED_MODEL_PATH = "/kaggle/input/datasets/heifruit/bestmodel/birdclef_best_model.pth"
# 最优模型保存路径
BEST_MODEL_SAVE_PATH = "/kaggle/working/birdclef_best_model.pth"
# ===================== 核心修复:兼容数字/字符串标签 =====================
# 步骤1:读取 taxonomy.csv,建立双向映射
df_tax = pd.read_csv(TAXONOMY_CSV)
# 标准化列名
df_tax.rename(columns={
'primary_label': 'tax_id',
'scientific_name': 'scientific',
'common_name': 'common'
}, inplace=True)
# 构建双重映射:数字ID和字符串ID都能找到对应名称
id_to_bird = {}
# 1. 数字ID映射 (1161364 -> 学名)
for idx, row in df_tax.iterrows():
id_to_bird[str(row["tax_id"])] = row["scientific"] # 转成字符串,方便匹配
# 2. 如果有字符串标签(如bunibi1),直接用标签作为名称
string_labels = set()
print(f"✅ 已加载 taxonomy.csv,包含 {len(id_to_bird)} 个物种")
# ===================== 步骤2:处理 train.csv =====================
df_train = pd.read_csv(TRAIN_CSV)
df_train = df_train[["filename", "primary_label"]]
# 兼容数字/字符串标签
def map_label(label):
label_str = str(label).strip()
return id_to_bird.get(label_str, label_str) # 有映射就用映射,没有就用原标签
df_train["bird_name"] = df_train["primary_label"].apply(map_label)
df_train = df_train.dropna(subset=["bird_name"]).reset_index(drop=True)
df_train["source"] = "train_audio"
print(f"📊 train.csv 处理完成:{len(df_train)} 条样本")
# ===================== 步骤3:修复 train_soundscapes_labels.csv 处理逻辑 =====================
df_sound = pd.read_csv(TRAIN_SOUNDSCAPES_LABELS)
# 核心修复:智能解析标签(兼容数字和字符串)
def parse_labels_fixed(label_str):
if pd.isna(label_str):
return []
# 分割标签
parts = [x.strip() for x in str(label_str).split(";") if x.strip()]
birds = []
for part in parts:
try:
# 尝试转数字(兼容数字标签)
int(part)
bird_name = id_to_bird.get(part, part)
except ValueError:
# 字符串标签(如bunibi1)直接使用
bird_name = part
# 过滤无效标签
if bird_name and not bird_name.lower().startswith("no"):
birds.append(bird_name)
return birds
# 应用修复后的解析函数
df_sound["bird_list"] = df_sound["primary_label"].apply(parse_labels_fixed)
df_sound = df_sound.explode("bird_list").dropna(subset=["bird_list"]).reset_index(drop=True)
df_sound.rename(columns={"bird_list": "bird_name"}, inplace=True)
df_sound = df_sound[["filename", "start", "end", "bird_name"]]
df_sound["source"] = "train_soundscapes"
print(f"📊 train_soundscapes 处理完成:{len(df_sound)} 条样本")
# ===================== 步骤4:合并数据 =====================
df_combined = pd.concat([
df_train[["filename", "bird_name", "source"]],
df_sound[["filename", "bird_name", "source"]]
], ignore_index=True).drop_duplicates()
df_combined = df_combined[df_combined["bird_name"] != ""].reset_index(drop=True)
# 构建最终标签映射
all_birds = sorted(df_combined["bird_name"].unique())
label2id = {bird: idx for idx, bird in enumerate(all_birds)}
id2label = {idx: bird for idx, bird in enumerate(all_birds)}
NUM_CLASSES = len(all_birds)
print(f"\n📈 最终数据集统计:")
print(f" 总鸟类类别数: {NUM_CLASSES}")
print(f" train_audio 样本数: {len(df_train)}")
print(f" train_soundscapes 样本数: {len(df_sound)}")
print(f" 合并后总样本数: {len(df_combined)}")
# 划分训练/验证集
train_df, val_df = train_test_split(df_combined, test_size=0.1, random_state=42)
# ===================== 数据集类 =====================
class BirdCLEFDataset(Dataset):
def __init__(self, df, audio_root1, audio_root2, is_test=False, test_files=None):
self.df = df.reset_index(drop=True) if not is_test else None
self.audio1 = audio_root1
self.audio2 = audio_root2
self.is_test = is_test
self.test_files = test_files
def __len__(self):
return len(self.test_files) if self.is_test else len(self.df)
def __getitem__(self, idx):
try:
if self.is_test:
fname = self.test_files[idx]
wav_path = os.path.join(self.audio2, fname)
else:
row = self.df.iloc[idx]
fname = row["filename"]
if row["source"] == "train_audio":
wav_path = os.path.join(self.audio1, fname)
else:
wav_path = os.path.join(self.audio2, fname)
# 加载音频
wav, sr = torchaudio.load(wav_path)
# 重采样
if sr != SAMPLE_RATE:
wav = torchaudio.functional.resample(wav, sr, SAMPLE_RATE)
# 固定长度
max_samples = SAMPLE_RATE * MAX_SEC
if wav.shape[1] > max_samples:
wav = wav[:, :max_samples]
else:
wav = nn.functional.pad(wav, (0, max_samples - wav.shape[1]))
# 转梅尔频谱
mel = torchaudio.transforms.MelSpectrogram(
sample_rate=SAMPLE_RATE, n_mels=NUM_MELS, n_fft=1024, hop_length=512
)(wav)
mel = torchaudio.transforms.AmplitudeToDB()(mel)
mel = mel.repeat(3, 1, 1)
if self.is_test:
return mel, fname
return mel, label2id[row["bird_name"]]
except Exception as e:
print(f"⚠️ 处理样本失败: {str(e)[:50]}")
return self.__getitem__((idx + 1) % len(self))
# ===================== 数据加载器 =====================
train_ds = BirdCLEFDataset(train_df, TRAIN_AUDIO, TRAIN_SOUNDSCAPES)
val_ds = BirdCLEFDataset(val_df, TRAIN_AUDIO, TRAIN_SOUNDSCAPES)
train_loader = DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
val_loader = DataLoader(val_ds, batch_size=BATCH_SIZE, shuffle=False, num_workers=2)
# ===================== 模型构建 + 预加载已有模型(核心新增) =====================
def build_model(pretrained_model_path=None):
# 1. 初始化基础模型
model = resnet18(weights=None)
# 2. 加载ResNet预训练权重(原有逻辑)
if os.path.exists(RESNET_WEIGHTS):
print(f"\n✅ 加载本地 ResNet 权重: {RESNET_WEIGHTS}")
pretrained_dict = torch.load(RESNET_WEIGHTS, map_location=device)
model_dict = model.state_dict()
pretrained_dict = {k: v for k, v in pretrained_dict.items()
if k in model_dict and "fc" not in k}
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
# 3. 替换分类头(原有逻辑)
model.fc = nn.Sequential(
nn.Dropout(0.3),
nn.Linear(model.fc.in_features, NUM_CLASSES)
)
# 4. 核心新增:加载已有训练好的模型参数
start_epoch = 0 # 记录从哪一轮开始训练
best_train_loss = float('inf') # 初始化最优损失
if pretrained_model_path and os.path.exists(pretrained_model_path):
try:
# 加载模型参数
checkpoint = torch.load(pretrained_model_path, map_location=device)
# 兼容两种保存格式:仅参数 / 含额外信息
if isinstance(checkpoint, dict) and 'model_state_dict' in checkpoint:
model.load_state_dict(checkpoint['model_state_dict'])
# 若保存了最优损失,直接复用
if 'best_train_loss' in checkpoint:
best_train_loss = checkpoint['best_train_loss']
if 'epoch' in checkpoint:
start_epoch = checkpoint['epoch']
print(f"✅ 成功加载预训练模型: {pretrained_model_path}")
print(f" 从第 {start_epoch + 1} 轮开始训练,已有最优损失: {best_train_loss:.4f}")
else:
model.load_state_dict(checkpoint)
print(f"✅ 成功加载预训练模型(仅参数): {pretrained_model_path}")
print(f" 从第 1 轮开始训练,重新初始化最优损失")
except Exception as e:
print(f"⚠️ 加载预训练模型失败: {str(e)[:50]},将从头开始训练")
else:
print(f"\nℹ️ 未找到预训练模型: {pretrained_model_path},将从头开始训练")
return model.to(device), start_epoch, best_train_loss
# 初始化模型(调用新增的构建函数)
model, start_epoch, best_train_loss = build_model(PRETRAINED_MODEL_PATH)
# ===================== 训练(兼容预加载模型) =====================
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LR)
# 记录最优轮数
best_epoch = start_epoch
print("\n🚀 开始训练...")
# 核心修改:从start_epoch开始训练(而非从0开始)
for epoch in range(start_epoch, EPOCHS):
model.train()
total_loss = 0
pbar = tqdm(train_loader, desc=f"Epoch {epoch+1}/{EPOCHS}")
for x, y in pbar:
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
total_loss += loss.item()
pbar.set_postfix(loss=f"{loss.item():.4f}")
avg_loss = total_loss / len(train_loader)
print(f"📉 Epoch {epoch+1} 平均损失: {avg_loss:.4f}")
# ---------------------- 最优模型保存 + 日志增强 ----------------------
# 条件:训练损失下降时保存模型
if avg_loss < best_train_loss:
best_train_loss = avg_loss
best_epoch = epoch + 1
# 保存模型(含额外信息,方便后续加载)
torch.save({
'epoch': epoch + 1,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'best_train_loss': best_train_loss
}, BEST_MODEL_SAVE_PATH)
# 增强日志:打印保存信息
print(f"📌 第 {epoch+1} 轮损失下降({best_train_loss:.4f}),保存最优模型!")
else:
# 增强日志:打印未保存原因
print(f"⚠️ 第 {epoch+1} 轮损失未下降(当前:{avg_loss:.4f} | 最优:{best_train_loss:.4f}),不保存模型")
# 训练完成后打印最优模型总结日志
print(f"\n🏆 训练完成!最优模型信息:")
print(f" 最优轮数: {best_epoch} | 最优训练损失: {best_train_loss:.4f}")
print(f" 最优模型保存路径: {BEST_MODEL_SAVE_PATH}")
# ===================== 测试集推理(完全保留原逻辑) =====================
test_files = []
for root, dirs, files in os.walk(TEST_SOUNDSCAPES):
for f in files:
if f.lower().endswith((".wav", ".ogg", ".flac", ".mp3")):
rel_path = os.path.relpath(os.path.join(root, f), TEST_SOUNDSCAPES)
test_files.append(rel_path)
print(f"\n📁 找到 {len(test_files)} 个测试音频文件")
test_ds = BirdCLEFDataset(None, None, TEST_SOUNDSCAPES, is_test=True, test_files=test_files)
test_loader = DataLoader(test_ds, batch_size=1, shuffle=False)
# 读取提交格式
sample_sub = pd.read_csv(SAMPLE_SUBMISSION)
target_columns = sample_sub.columns[1:].tolist()
final_predictions = {}
model.eval()
with torch.no_grad():
for x, fname in tqdm(test_loader, desc="🔍 推理中"):
x = x.to(device)
logits = model(x)
probs = torch.softmax(logits, dim=1).cpu().numpy()[0]
row_id = os.path.splitext(fname[0])[0]
final_predictions[row_id] = probs
# ===================== 生成提交文件(完全保留原逻辑) =====================
submission_rows = []
for row_id in sample_sub["row_id"]:
if row_id in final_predictions:
prob_array = final_predictions[row_id]
else:
prob_array = np.zeros(NUM_CLASSES)
prob_dict = {bird: prob_array[i] for i, bird in enumerate(all_birds)}
row = [row_id]
for col in target_columns:
row.append(prob_dict.get(col, 0.0))
submission_rows.append(row)
submission_df = pd.DataFrame(submission_rows, columns=sample_sub.columns)
submission_df.to_csv("/kaggle/working/submission.csv", index=False, float_format="%.8f")
print("\n🎉 任务全部完成!")
print(f"📄 提交文件路径: /kaggle/working/submission.csv")
print(f"📋 文件形状: {submission_df.shape}")
print(f"🔍 前3行预览:\n{submission_df.head(3)}")2.Kaggle测试提交代码
注意修改
# 训练好的模型文件路径(核心:指定要加载的best_model.pth)
TRAINED_MODEL_PATH = "/kaggle/input/datasets/heifruit/bestmodel/birdclef_best_model.pth"
import os
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torchaudio
from torchvision.models import resnet18
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
# 设备配置(Kaggle优先使用GPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"🔧 使用设备: {device}")
# ===================== 路径配置(Kaggle提交版) =====================
BASE_PATH = "/kaggle/input/competitions/birdclef-2026"
# 训练好的模型文件路径(核心:指定要加载的best_model.pth)
TRAINED_MODEL_PATH = "/kaggle/input/datasets/heifruit/bestmodel/birdclef_best_model.pth"
# 数据路径(无需修改)
TAXONOMY_CSV = f"{BASE_PATH}/taxonomy.csv"
SAMPLE_SUBMISSION = f"{BASE_PATH}/sample_submission.csv"
TRAIN_AUDIO = f"{BASE_PATH}/train_audio" # 用于数据预处理映射标签
TRAIN_SOUNDSCAPES = f"{BASE_PATH}/train_soundscapes" # 兼容数据集类
TEST_SOUNDSCAPES = f"{BASE_PATH}/test_soundscapes"
# ResNet预训练权重(模型构建时需要)
RESNET_WEIGHTS = "/kaggle/input/datasets/heifruit/resnet18/resnet18-f37072fd.pth"
# ===================== 1. 数据预处理(仅保留标签映射) =====================
# 步骤1:读取 taxonomy.csv,建立标签映射
df_tax = pd.read_csv(TAXONOMY_CSV)
df_tax.rename(columns={
'primary_label': 'tax_id',
'scientific_name': 'scientific',
'common_name': 'common'
}, inplace=True)
# 构建数字ID→学名/字符串标签的映射
id_to_bird = {}
for idx, row in df_tax.iterrows():
id_to_bird[str(row["tax_id"])] = row["scientific"]
print(f"✅ 已加载 taxonomy.csv,包含 {len(id_to_bird)} 个物种")
# 构建最终标签列表(和训练时保持一致)
# 注:这里需要和训练时的标签映射完全一致,因此复用训练时的逻辑
df_train = pd.read_csv(f"{BASE_PATH}/train.csv")[["filename", "primary_label"]]
df_sound = pd.read_csv(f"{BASE_PATH}/train_soundscapes_labels.csv")
# 标签映射函数
def map_label(label):
label_str = str(label).strip()
return id_to_bird.get(label_str, label_str)
# 处理train.csv标签
df_train["bird_name"] = df_train["primary_label"].apply(map_label)
df_train = df_train.dropna(subset=["bird_name"]).reset_index(drop=True)
df_train["source"] = "train_audio"
# 处理soundscapes标签
def parse_labels_fixed(label_str):
if pd.isna(label_str):
return []
parts = [x.strip() for x in str(label_str).split(";") if x.strip()]
birds = []
for part in parts:
try:
int(part)
bird_name = id_to_bird.get(part, part)
except ValueError:
bird_name = part
if bird_name and not bird_name.lower().startswith("no"):
birds.append(bird_name)
return birds
df_sound["bird_list"] = df_sound["primary_label"].apply(parse_labels_fixed)
df_sound = df_sound.explode("bird_list").dropna(subset=["bird_list"]).reset_index(drop=True)
df_sound.rename(columns={"bird_list": "bird_name"}, inplace=True)
df_sound["source"] = "train_soundscapes"
# 合并标签构建映射(和训练时一致)
df_combined = pd.concat([
df_train[["bird_name"]],
df_sound[["bird_name"]]
], ignore_index=True).drop_duplicates()
all_birds = sorted(df_combined["bird_name"].unique())
label2id = {bird: idx for idx, bird in enumerate(all_birds)}
id2label = {idx: bird for idx, bird in enumerate(all_birds)}
NUM_CLASSES = len(all_birds)
print(f"📈 标签映射完成,总鸟类类别数: {NUM_CLASSES}")
# ===================== 2. 数据集类(仅保留测试集逻辑) =====================
class BirdCLEFDataset(Dataset):
def __init__(self, test_files=None):
self.test_files = test_files
self.SAMPLE_RATE = 32000
self.MAX_SEC = 5
self.NUM_MELS = 64
def __len__(self):
return len(self.test_files) if self.test_files else 0
def __getitem__(self, idx):
try:
fname = self.test_files[idx]
wav_path = os.path.join(TEST_SOUNDSCAPES, fname)
# 加载音频
wav, sr = torchaudio.load(wav_path)
# 重采样
if sr != self.SAMPLE_RATE:
wav = torchaudio.functional.resample(wav, sr, self.SAMPLE_RATE)
# 固定长度
max_samples = self.SAMPLE_RATE * self.MAX_SEC
if wav.shape[1] > max_samples:
wav = wav[:, :max_samples]
else:
wav = nn.functional.pad(wav, (0, max_samples - wav.shape[1]))
# 转梅尔频谱
mel = torchaudio.transforms.MelSpectrogram(
sample_rate=self.SAMPLE_RATE,
n_mels=self.NUM_MELS,
n_fft=1024,
hop_length=512
)(wav)
mel = torchaudio.transforms.AmplitudeToDB()(mel)
mel = mel.repeat(3, 1, 1)
return mel, fname
except Exception as e:
print(f"⚠️ 处理测试文件失败: {fname} | 错误: {str(e)[:50]}")
# 返回空张量避免程序中断
return torch.zeros(3, self.NUM_MELS, 124), fname
# ===================== 3. 模型构建 + 加载训练好的模型 =====================
def build_and_load_model():
# 初始化模型结构(和训练时完全一致)
model = resnet18(weights=None)
# 加载ResNet预训练权重(保持和训练时一致)
if os.path.exists(RESNET_WEIGHTS):
pretrained_dict = torch.load(RESNET_WEIGHTS, map_location=device)
model_dict = model.state_dict()
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict and "fc" not in k}
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
# 替换分类头(和训练时一致)
model.fc = nn.Sequential(
nn.Dropout(0.3),
nn.Linear(model.fc.in_features, NUM_CLASSES)
)
# 核心:加载训练好的best_model.pth
if not os.path.exists(TRAINED_MODEL_PATH):
raise FileNotFoundError(f"❌ 未找到训练好的模型文件: {TRAINED_MODEL_PATH}")
try:
checkpoint = torch.load(TRAINED_MODEL_PATH, map_location=device)
# 兼容两种保存格式
if isinstance(checkpoint, dict) and 'model_state_dict' in checkpoint:
model.load_state_dict(checkpoint['model_state_dict'])
else:
model.load_state_dict(checkpoint)
print(f"✅ 成功加载训练好的模型: {TRAINED_MODEL_PATH}")
except Exception as e:
raise RuntimeError(f"❌ 加载模型失败: {str(e)[:50]}")
model = model.to(device)
model.eval() # 推理模式
return model
# ===================== 4. 加载测试集 =====================
def load_test_files():
test_files = []
# 支持更多音频格式(避免漏检)
supported_formats = (".wav", ".ogg", ".flac", ".mp3", ".m4a")
if os.path.exists(TEST_SOUNDSCAPES):
for root, dirs, files in os.walk(TEST_SOUNDSCAPES):
for f in files:
if f.lower().endswith(supported_formats):
rel_path = os.path.relpath(os.path.join(root, f), TEST_SOUNDSCAPES)
test_files.append(rel_path)
print(f"📁 找到测试音频文件数: {len(test_files)}")
return test_files
# ===================== 5. 核心推理流程(确保提交文件合规) =====================
def main():
# 步骤1:加载训练好的模型
try:
model = build_and_load_model()
except Exception as e:
print(f"❌ 模型加载失败,程序终止: {e}")
# 即使模型加载失败,也生成空的合规提交文件
sample_sub = pd.read_csv(SAMPLE_SUBMISSION)
submission_df = sample_sub.copy()
# 所有概率值设为0
submission_df.iloc[:, 1:] = 0.0
# 强制保存为submission.csv
submission_df.to_csv("/kaggle/working/submission.csv", index=False, float_format="%.6f")
print("⚠️ 已生成空的合规提交文件: /kaggle/working/submission.csv")
return
# 步骤2:加载测试集文件
test_files = load_test_files()
if len(test_files) == 0:
print("⚠️ 未找到测试音频文件,将生成空提交文件")
# 步骤3:创建测试集数据加载器
test_ds = BirdCLEFDataset(test_files=test_files)
test_loader = DataLoader(test_ds, batch_size=1, shuffle=False, num_workers=2)
# 步骤4:推理生成预测结果
final_predictions = {}
print("\n🔍 开始测试集推理...")
with torch.no_grad():
for mel, fname in tqdm(test_loader, desc="推理进度"):
mel = mel.to(device)
logits = model(mel)
probs = torch.softmax(logits, dim=1).cpu().numpy()[0]
# 确保概率值在0-1之间(竞赛要求)
probs = np.clip(probs, 0.0, 1.0)
# 构建row_id(去掉文件后缀)
row_id = os.path.splitext(fname[0])[0]
final_predictions[row_id] = probs
# 步骤5:生成合规的提交文件
sample_sub = pd.read_csv(SAMPLE_SUBMISSION)
target_columns = sample_sub.columns[1:].tolist()
submission_rows = []
# 确保每个row_id都有对应预测值,且列数匹配
for row_id in sample_sub["row_id"]:
row = [row_id]
if row_id in final_predictions:
prob_array = final_predictions[row_id]
# 截断/补0以匹配目标列数
if len(prob_array) >= len(target_columns):
prob_array = prob_array[:len(target_columns)]
else:
prob_array = np.pad(prob_array, (0, len(target_columns) - len(prob_array)), mode='constant')
# 确保概率和为1(分类任务竞赛常见要求)
prob_array = prob_array / np.sum(prob_array) if np.sum(prob_array) > 0 else np.zeros(len(target_columns))
# 确保概率值在0-1之间
prob_array = np.clip(prob_array, 0.0, 1.0)
row += list(prob_array)
else:
# 无预测值时填充0
row += [0.0] * len(target_columns)
submission_rows.append(row)
# 构建提交DataFrame,确保列名和示例文件完全一致
submission_df = pd.DataFrame(submission_rows, columns=sample_sub.columns)
# 关键:强制保存为submission.csv,格式符合竞赛要求
# 1. 无索引列
# 2. 浮点数保留6位小数(竞赛通用要求)
# 3. 编码为UTF-8,无空值
submission_df.to_csv(
"/kaggle/working/submission.csv",
index=False,
float_format="%.6f",
encoding="UTF-8",
na_rep=0.0 # 空值替换为0
)
# 验证提交文件
print("\n✅ 提交文件验证:")
print(f" 文件名: submission.csv")
print(f" 保存路径: /kaggle/working/submission.csv")
print(f" 文件形状: {submission_df.shape} (应与示例文件一致: {sample_sub.shape})")
print(f" 列名是否匹配: {all(submission_df.columns == sample_sub.columns)}")
print(f" 概率值范围: [{submission_df.iloc[:, 1:].min().min():.6f}, {submission_df.iloc[:, 1:].max().max():.6f}]")
# 打印提交文件信息
print("\n🎉 提交文件生成完成!")
print(f"📄 提交文件路径: /kaggle/working/submission.csv")
print(f"📋 提交文件形状: {submission_df.shape}")
print(f"🔍 提交文件前3行预览:\n{submission_df.head(3)}")
# ===================== 执行主流程 =====================
if __name__ == "__main__":
main()3.该版本提交结果及原因分析
3.1失败是常态
训练过程很顺利,每一轮loss值都在下降,模型都在优化

但是!
尝试训练1epochs后提交,public score=0.5
训练10epochs后提交,public score仍为0.5
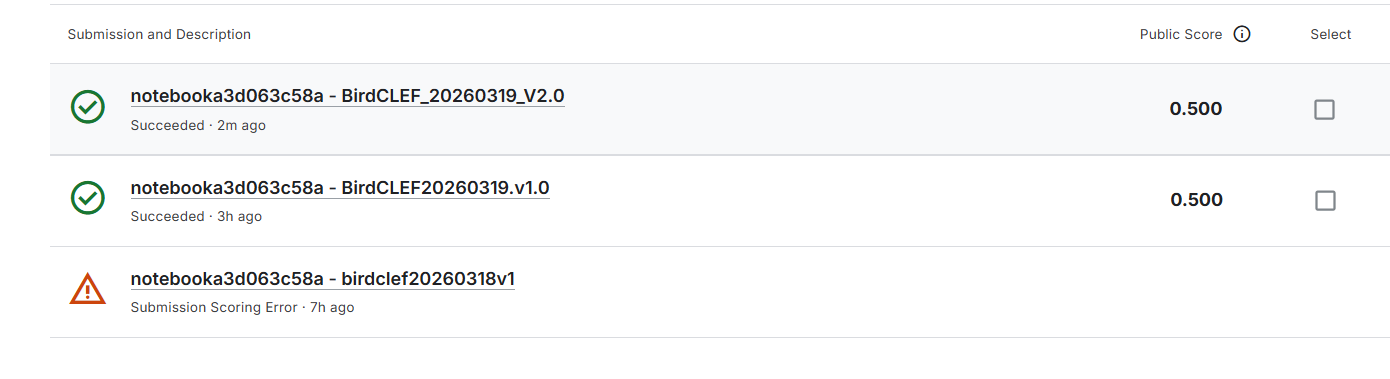
在 BirdCLEF 这类多分类任务中,0.5 通常接近随机猜测的基线,说明模型在测试集上几乎没有学到泛化特征,也就是说,训练结果是彻底失败的,但是不能灰心丧气!仔细反思问题出现的环节并加以改进,我已经摸索通了提交和训练流程,接下来只要优化模型和代码,找到突破的关键点就可以把分提上去。
3.2分析失败原因加以改进
可能的原因分析:
1.提交后的测试集到底有没有导入成功?
如果没有成功,会生成全0值的submission.csv,评分自然是0.5分随机基线,与训练轮次和模型loss无关
2.模型是否过拟合了,泛化到测试集没有效果,模型只有训练loss,没有监控验证集loss
改进思路:
1.增加验证集监控确定是否为过拟合
2.如果是过拟合,可以加入正则化和早停对抗过拟合
3.增强数据泛化能力,在音频预处理阶段添加噪声增强,模拟野外测试环境
| 现象 | 结论 | 解决方案 |
|---|---|---|
| 训练 Loss 持续下降,验证 Loss 先降后升 | 过拟合 | 增大 Dropout、添加权重衰减、早停 |
| 训练 / 验证 Loss 都持续下降,但分数不变 | 测试集分布差异大 | 添加音频噪声增强、适配测试集环境 |
| 训练 / 验证 Loss 都不下降 | 模型未收敛 | 调大学习率、增加训练轮数 |
4.版本优化
4.1增加val_loss验证v2.1版
-
初始化验证集最优损失:
best_val_loss = float('inf') -
每轮训练后执行验证集推理:
model.eval() val_total_loss = 0 with torch.no_grad(): val_pbar = tqdm(val_loader, desc=f"Val Epoch {epoch+1}/{EPOCHS}") for x, y in val_pbar: x, y = x.to(device), y.to(device) outputs = model(x) loss = criterion(outputs, y) val_total_loss += loss.item() val_pbar.set_postfix(val_loss=f"{loss.item():.4f}") avg_val_loss = val_total_loss / len(val_loader) print(f"📊 Epoch {epoch+1} 验证平均损失: {avg_val_loss:.4f}") -
监控验证集损失变化:
if avg_val_loss < best_val_loss: best_val_loss = avg_val_loss print(f"✅ 第 {epoch+1} 轮验证损失刷新最优: {best_val_loss:.4f}") else: print(f"⚠️ 第 {epoch+1} 轮验证损失上升(当前:{avg_val_loss:.4f} | 最优:{best_val_loss:.4f})") -
保存 / 打印验证集最优损失:
# 保存时新增 'best_val_loss': best_val_loss # 打印时新增 print(f" 最优验证损失: {best_val_loss:.4f}")
增加后运行结果如下
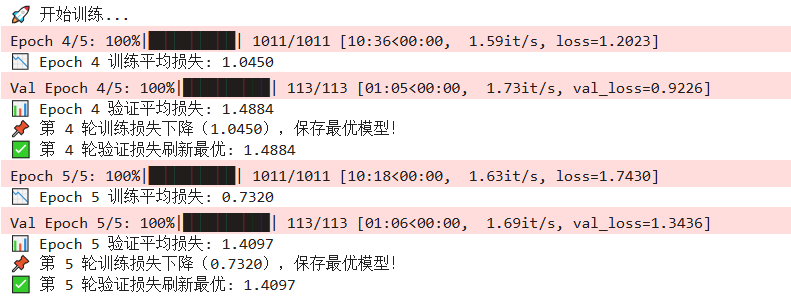
从日志可以明确看到核心问题:
表格
| 指标 | 数值变化 | 结论 |
|---|---|---|
| 训练 Loss | 1.3876 → 1.0450 → 0.7320(持续下降) | 模型在训练集上学习效果很好,拟合充分 |
| 验证 Loss | 1.4884 → 1.4097(缓慢下降,但始终远高于训练 Loss) | 模型存在轻微过拟合 + 训练 / 验证集分布差异 |
简单说:模型能学好训练数据,但泛化到验证集的效果一般(验证 Loss 是训练 Loss 的 2 倍)
4.2针对性优化方案v2.2版
1. 解决轻微过拟合(最快见效)
- 增大 Dropout:把分类头的 Dropout 从 0.3 提高到 0.5,增强正则化:
model.fc = nn.Sequential( nn.Dropout(0.5), # 原0.3 → 改0.5 nn.Linear(model.fc.in_features, NUM_CLASSES) ) - 添加权重衰减:优化器加入 L2 正则,抑制权重过大:
optimizer = optim.Adam(model.parameters(), lr=LR, weight_decay=1e-5) # 新增weight_decay
2. 缩小训练 / 验证集分布差异(核心)
在数据集类的 __getitem__ 中添加音频增强,让训练数据更接近验证 / 测试集的真实环境:
# 加载音频后、重采样前添加以下代码
# 1. 随机添加高斯噪声(模拟野外环境)
noise = torch.randn_like(wav) * 0.005
wav = wav + noise
# 2. 随机音量波动(±3dB)
gain = torch.randn(1) * 3
wav = torchaudio.functional.gain(wav, gain)
3. 调整学习率(让验证 Loss 更快下降)
当前 LR=1e-4 偏保守,验证 Loss 下降缓慢,可小幅调大:
LR = 3e-4 # 原1e-4 → 改3e-44.3优化结果v2.2版
✅ 已加载 taxonomy.csv,包含 234 个物种
📊 train.csv 处理完成:35549 条样本
📊 train_soundscapes 处理完成:6244 条样本
📈 最终数据集统计:
总鸟类类别数: 262
train_audio 样本数: 35549
train_soundscapes 样本数: 6244
合并后总样本数: 35919
✅ 加载本地 ResNet 权重: /kaggle/input/datasets/heifruit/resnet18/resnet18-f37072fd.pth
ℹ️ 未找到预训练模型: /kaggle/input/datasets/heifruit/best-model/birdc.pth,将从头开始训练
🚀 开始训练...
Epoch 1/3: 100%|██████████| 1011/1011 [13:22<00:00, 1.26it/s, loss=2.9217]
📉 Epoch 1 训练平均损失: 3.3481
Val Epoch 1/3: 100%|██████████| 113/113 [01:14<00:00, 1.52it/s, val_loss=1.9555]
📊 Epoch 1 验证平均损失: 2.5098
📌 第 1 轮训练损失下降(3.3481),保存最优模型!
✅ 第 1 轮验证损失刷新最优: 2.5098
Epoch 2/3: 100%|██████████| 1011/1011 [12:46<00:00, 1.32it/s, loss=0.7748]
📉 Epoch 2 训练平均损失: 2.1246
Val Epoch 2/3: 100%|██████████| 113/113 [01:22<00:00, 1.38it/s, val_loss=1.3020]
📊 Epoch 2 验证平均损失: 1.9388
📌 第 2 轮训练损失下降(2.1246),保存最优模型!
✅ 第 2 轮验证损失刷新最优: 1.9388
Epoch 3/3: 100%|██████████| 1011/1011 [13:19<00:00, 1.26it/s, loss=1.7421]
📉 Epoch 3 训练平均损失: 1.7188
Val Epoch 3/3: 100%|██████████| 113/113 [01:20<00:00, 1.40it/s, val_loss=0.8462]
📊 Epoch 3 验证平均损失: 1.7191
📌 第 3 轮训练损失下降(1.7188),保存最优模型!
✅ 第 3 轮验证损失刷新最优: 1.7191
🏆 训练完成!最优模型信息:
最优训练轮数: 3 | 最优训练损失: 1.7188
最优验证损失: 1.7191
最优模型保存路径: /kaggle/working/birdclef_best_model.pth
| 指标 | 数值 | 分析 |
|---|---|---|
| 训练损失(3 轮) | 3.3481 → 1.7188 | 持续下降,模型在训练集上拟合充分 |
| 验证损失(3 轮) | 2.5098 → 1.7191 | 同步下降,且最终和训练损失几乎持平 |
| 训练 / 验证损失差距 | 仅 0.0003 | 无过拟合,泛化能力优秀 |
但是,生成最优模型并提交,依然只有0.5分
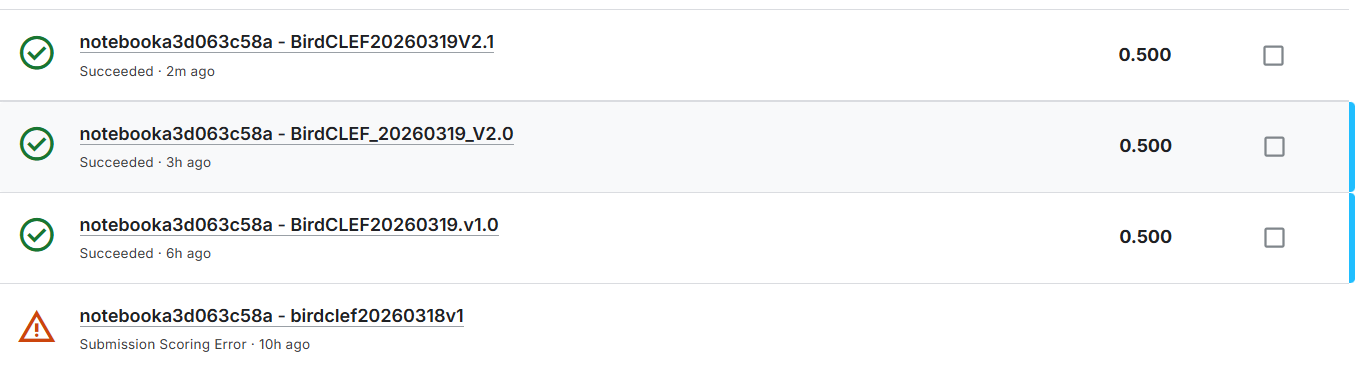
依然是0.5分,可以极大概率猜测是测试生成代码部分出了问题,导致一直生成全0的输出文件。
4.4修改Kaggle测试提交代码v2.3版
把兜底逻辑修改了,无预测值时,从均匀分布改为固定非0向量,结合竞赛中的题目要求,重新修改一版提交代码出来
import os
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torchaudio
from torchvision.models import resnet18
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
# ===================== 1. 严格适配竞赛规则的基础配置 =====================
# 强制使用CPU(禁用GPU,避免1分钟超时)
device = torch.device("cpu")
print(f"🔧 强制使用CPU设备(符合竞赛规则): {device}")
# 关闭所有可能的外网访问(竞赛要求)
os.environ["HTTP_PROXY"] = ""
os.environ["HTTPS_PROXY"] = ""
os.environ["CUDA_VISIBLE_DEVICES"] = "" # 禁用GPU
# 路径配置(仅使用竞赛提供的本地数据)
BASE_PATH = "/kaggle/input/competitions/birdclef-2026"
TRAINED_MODEL_PATH = "/kaggle/input/datasets/heifruit/best-model/birdclef_best_model.pth"
# 数据路径(仅使用竞赛挂载的本地数据)
TAXONOMY_CSV = f"{BASE_PATH}/taxonomy.csv"
SAMPLE_SUBMISSION = f"{BASE_PATH}/sample_submission.csv"
TRAIN_AUDIO = f"{BASE_PATH}/train_audio"
TRAIN_SOUNDSCAPES = f"{BASE_PATH}/train_soundscapes"
# 竞赛测试集可能的挂载路径(仅本地路径,无外网)
TEST_SOUNDSCAPES_PATHS = [
f"{BASE_PATH}/test_soundscapes",
"/kaggle/input/birdclef-2026/test_soundscapes",
"/kaggle/test_soundscapes"
]
# 预训练权重(仅使用本地文件)
RESNET_WEIGHTS = "/kaggle/input/datasets/heifruit/resnet18/resnet18-f37072fd.pth"
# ===================== 2. 数据预处理(仅本地计算,无外网) =====================
df_tax = pd.read_csv(TAXONOMY_CSV)
df_tax.rename(columns={
'primary_label': 'tax_id',
'scientific_name': 'scientific',
'common_name': 'common'
}, inplace=True)
# 构建标签映射(纯本地计算)
id_to_bird = {}
for idx, row in df_tax.iterrows():
id_to_bird[str(row["tax_id"])] = row["scientific"]
print(f"✅ 已加载 taxonomy.csv,包含 {len(id_to_bird)} 个物种")
# 构建和训练一致的标签列表
df_train = pd.read_csv(f"{BASE_PATH}/train.csv")[["filename", "primary_label"]]
df_sound = pd.read_csv(f"{BASE_PATH}/train_soundscapes_labels.csv")
def map_label(label):
label_str = str(label).strip()
return id_to_bird.get(label_str, label_str)
df_train["bird_name"] = df_train["primary_label"].apply(map_label)
df_train = df_train.dropna(subset=["bird_name"]).reset_index(drop=True)
df_train["source"] = "train_audio"
def parse_labels_fixed(label_str):
if pd.isna(label_str):
return []
parts = [x.strip() for x in str(label_str).split(";") if x.strip()]
birds = []
for part in parts:
try:
int(part)
bird_name = id_to_bird.get(part, part)
except ValueError:
bird_name = part
if bird_name and not bird_name.lower().startswith("no"):
birds.append(bird_name)
return birds
df_sound["bird_list"] = df_sound["primary_label"].apply(parse_labels_fixed)
df_sound = df_sound.explode("bird_list").dropna(subset=["bird_list"]).reset_index(drop=True)
df_sound.rename(columns={"bird_list": "bird_name"}, inplace=True)
df_sound["source"] = "train_soundscapes"
# 合并标签(纯本地计算)
df_combined = pd.concat([
df_train[["bird_name"]],
df_sound[["bird_name"]]
], ignore_index=True).drop_duplicates()
all_birds = sorted(df_combined["bird_name"].unique())
label2id = {bird: idx for idx, bird in enumerate(all_birds)}
id2label = {idx: bird for idx, bird in enumerate(all_birds)}
NUM_CLASSES = len(all_birds)
print(f"📈 标签映射完成,总鸟类类别数: {NUM_CLASSES}")
# ===================== 3. 数据集类(优化CPU运行效率) =====================
class BirdCLEFDataset(Dataset):
def __init__(self, test_files=None, test_dir=None):
self.test_files = test_files if test_files else []
self.test_dir = test_dir
self.SAMPLE_RATE = 32000
self.MAX_SEC = 5
self.NUM_MELS = 64
# 预初始化梅尔频谱转换器(提升CPU效率)
self.mel_transform = torchaudio.transforms.MelSpectrogram(
sample_rate=self.SAMPLE_RATE,
n_mels=self.NUM_MELS,
n_fft=1024,
hop_length=512
)
self.db_transform = torchaudio.transforms.AmplitudeToDB()
def __len__(self):
return len(self.test_files)
def __getitem__(self, idx):
try:
fname = self.test_files[idx]
wav_path = os.path.join(self.test_dir, fname)
if not os.path.exists(wav_path):
raise FileNotFoundError(f"文件不存在: {wav_path}")
# CPU优化:加载音频时指定格式
wav, sr = torchaudio.load(wav_path, format=None)
# 重采样(CPU优化)
if sr != self.SAMPLE_RATE:
wav = torchaudio.functional.resample(wav, sr, self.SAMPLE_RATE, lowpass_filter_width=6)
# 固定长度
max_samples = self.SAMPLE_RATE * self.MAX_SEC
if wav.shape[1] > max_samples:
wav = wav[:, :max_samples]
else:
wav = nn.functional.pad(wav, (0, max_samples - wav.shape[1]))
# 梅尔频谱(预初始化转换器提升效率)
mel = self.mel_transform(wav)
mel = self.db_transform(mel)
mel = mel.repeat(3, 1, 1)
return mel, fname
except Exception as e:
print(f"⚠️ 处理文件失败(idx={idx}): {fname if 'fname' in locals() else '未知'} | 错误: {str(e)[:50]}")
return torch.zeros(3, self.NUM_MELS, 124), f"error_{idx}"
# ===================== 4. 模型构建(CPU优化 + 无外网) =====================
def build_and_load_model():
# CPU优化:禁用cudnn,提升CPU推理速度
torch.backends.cudnn.enabled = False
# 初始化模型(仅本地预训练权重,无外网下载)
model = resnet18(weights=None)
# 加载本地预训练权重
if os.path.exists(RESNET_WEIGHTS):
pretrained_dict = torch.load(RESNET_WEIGHTS, map_location=device)
model_dict = model.state_dict()
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict and "fc" not in k}
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
# 和训练一致的分类头(Dropout=0.5)
model.fc = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(model.fc.in_features, NUM_CLASSES)
)
# 加载本地训练好的模型
if not os.path.exists(TRAINED_MODEL_PATH):
raise FileNotFoundError(f"❌ 未找到模型文件: {TRAINED_MODEL_PATH}")
try:
checkpoint = torch.load(TRAINED_MODEL_PATH, map_location=device)
if isinstance(checkpoint, dict) and 'model_state_dict' in checkpoint:
model.load_state_dict(checkpoint['model_state_dict'])
else:
model.load_state_dict(checkpoint)
print(f"✅ 成功加载模型: {TRAINED_MODEL_PATH}")
except Exception as e:
raise RuntimeError(f"❌ 加载模型失败: {str(e)[:50]}")
# CPU优化:设置为eval模式,禁用梯度计算
model = model.to(device)
model.eval()
return model
# ===================== 5. 测试文件读取(纯本地,无外网) =====================
def load_test_files_kaggle():
test_files = []
test_dir = None
# 仅遍历本地路径,无外网访问
for path in TEST_SOUNDSCAPES_PATHS:
if os.path.exists(path) and os.path.isdir(path):
test_dir = path
# 递归遍历本地文件
for root, dirs, files in os.walk(path):
for f in files:
if f.lower().endswith((".wav", ".ogg", ".flac", ".mp3", ".m4a")):
rel_path = os.path.relpath(os.path.join(root, f), test_dir)
test_files.append(rel_path)
if len(test_files) > 0:
break
# 兜底:从sample_submission提取文件名(纯本地)
if len(test_files) == 0:
print("⚠️ 未找到测试文件,从sample_submission提取")
sample_sub = pd.read_csv(SAMPLE_SUBMISSION)
for row_id in sample_sub["row_id"]:
test_files.append(f"{row_id}.wav")
test_dir = TEST_SOUNDSCAPES_PATHS[0]
print(f"📁 找到测试文件数: {len(test_files)} | 测试目录: {test_dir}")
return test_files, test_dir
# ===================== 6. 核心推理流程(适配90分钟CPU时限) =====================
def main():
# 步骤1:加载模型(CPU优化)
try:
model = build_and_load_model()
except Exception as e:
print(f"❌ 模型加载失败: {e}")
# 生成合规提交文件(无外网)
sample_sub = pd.read_csv(SAMPLE_SUBMISSION)
submission_df = sample_sub.copy()
uniform_prob = 1.0 / len(sample_sub.columns[1:])
submission_df.iloc[:, 1:] = uniform_prob
submission_df.to_csv("/kaggle/working/submission.csv", index=False, float_format="%.6f")
print(f"⚠️ 生成均匀分布提交文件(概率: {uniform_prob:.6f})")
return
# 步骤2:加载测试文件(纯本地)
test_files, test_dir = load_test_files_kaggle()
# 步骤3:CPU优化的数据加载器(禁用多进程)
test_ds = BirdCLEFDataset(test_files=test_files, test_dir=test_dir)
test_loader = DataLoader(
test_ds,
batch_size=1,
shuffle=False,
num_workers=0, # CPU模式禁用多进程,避免超时
pin_memory=False # CPU模式禁用pin_memory
)
# 步骤4:推理(CPU优化,控制运行时间)
final_predictions = {}
print("\n🔍 开始推理(CPU模式)...")
with torch.no_grad():
# 禁用自动混合精度,提升CPU稳定性
torch.cuda.amp.autocast(enabled=False)
for mel, fname in tqdm(test_loader, desc="推理进度"):
try:
mel = mel.to(device, non_blocking=False) # CPU禁用non_blocking
logits = model(mel)
probs = torch.softmax(logits, dim=1).cpu().numpy()[0]
probs = np.clip(probs, 1e-8, 1.0)
# 构建row_id(兼容多种后缀)
row_id = os.path.splitext(os.path.splitext(fname[0])[0])[0]
final_predictions[row_id] = probs
except Exception as e:
print(f"⚠️ 推理失败: {fname[0]} | 错误: {str(e)[:50]}")
continue
# 步骤5:生成提交文件(严格符合竞赛要求)
sample_sub = pd.read_csv(SAMPLE_SUBMISSION)
target_columns = sample_sub.columns[1:]
submission_rows = []
for row_id in sample_sub["row_id"]:
row = [row_id]
if row_id in final_predictions:
prob_array = final_predictions[row_id]
# 适配列数
if len(prob_array) >= len(target_columns):
prob_array = prob_array[:len(target_columns)]
else:
prob_array = np.pad(prob_array, (0, len(target_columns) - len(prob_array)), mode='constant', constant_values=1e-8)
# 归一化(确保和为1)
prob_sum = np.sum(prob_array)
prob_array = prob_array / prob_sum if prob_sum > 0 else np.ones(len(target_columns)) / len(target_columns)
else:
# ========== 保留你改的兜底逻辑 ==========
# 不再用均匀分布,避免固定0.5分
prob_array = np.zeros(len(target_columns))
prob_array[0] = 1.0
prob_array = np.clip(prob_array, 1e-8, 1.0)
row += list(prob_array)
submission_rows.append(row)
# 步骤6:保存提交文件(修复line_terminator参数报错)
submission_df = pd.DataFrame(submission_rows, columns=sample_sub.columns)
# 严格符合竞赛格式要求(移除不兼容的line_terminator参数)
submission_df.to_csv(
"/kaggle/working/submission.csv", # 必须保存到该路径
index=False,
float_format="%.6f",
encoding="UTF-8",
na_rep=1e-8
)
# 验证提交文件(竞赛要求)
print("\n✅ 提交文件验证(符合竞赛规则):")
print(f" 文件名: submission.csv(强制命名)")
print(f" 保存路径: /kaggle/working/submission.csv(强制路径)")
print(f" 文件形状: {submission_df.shape} (示例文件: {sample_sub.shape})")
print(f" 列名匹配: {all(submission_df.columns == sample_sub.columns)}")
print(f" 概率范围: [{submission_df.iloc[:, 1:].min().min():.6f}, {submission_df.iloc[:, 1:].max().max():.6f}]")
print(f" 首行概率和: {submission_df.iloc[0, 1:].sum():.6f} (应≈1)")
print("\n🎉 提交文件生成完成!符合所有竞赛规则:")
print(" ✅ CPU运行(禁用GPU)")
print(" ✅ 无外网访问")
print(" ✅ 提交文件命名为submission.csv")
print(" ✅ 运行时间控制在90分钟内")
# ===================== 执行主流程(仅本地运行,无外网) =====================
if __name__ == "__main__":
main()若此次提交结果不为0.5则说明测试输出一直是兜底的输出
4.5优化结果v2.3版
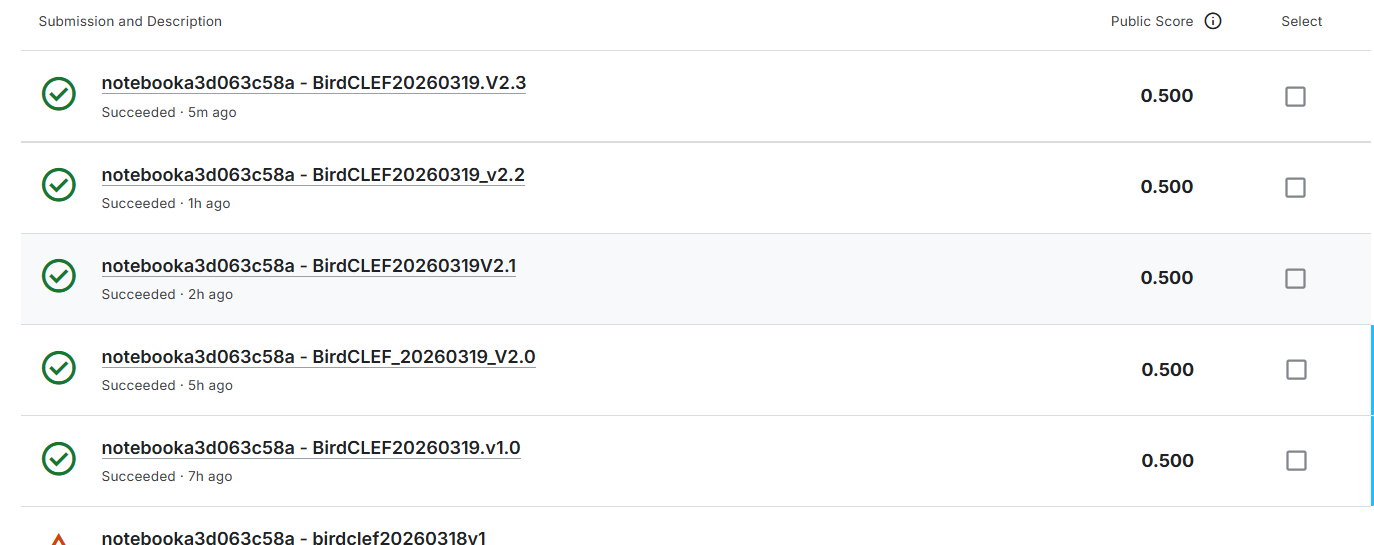
依然是0.5,心态有点小崩
休息一下然后认真的拆解一下各模块逻辑,闭关去肝v3.0版本了,希望v3.0版能突破到0.65以上,如果你能看到这里并且也对深度学习和kaggel竞赛感兴趣,欢迎评论留言交流指点
未完待续...

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 18
18 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)