麻雀优化算法SSA结合LSTM实现时间序列单输入单输出预测
麻雀优化算法SSA结合LSTM做时间序列单输入单输出预测模型,要求数据是单列的时间序列数据,直接替换数据就可以用。 程序语言是matlab,需求最低版本为2018及以上。 程序可以出真实值和预测值对比图,线性拟合图,可打印多种评价指标。
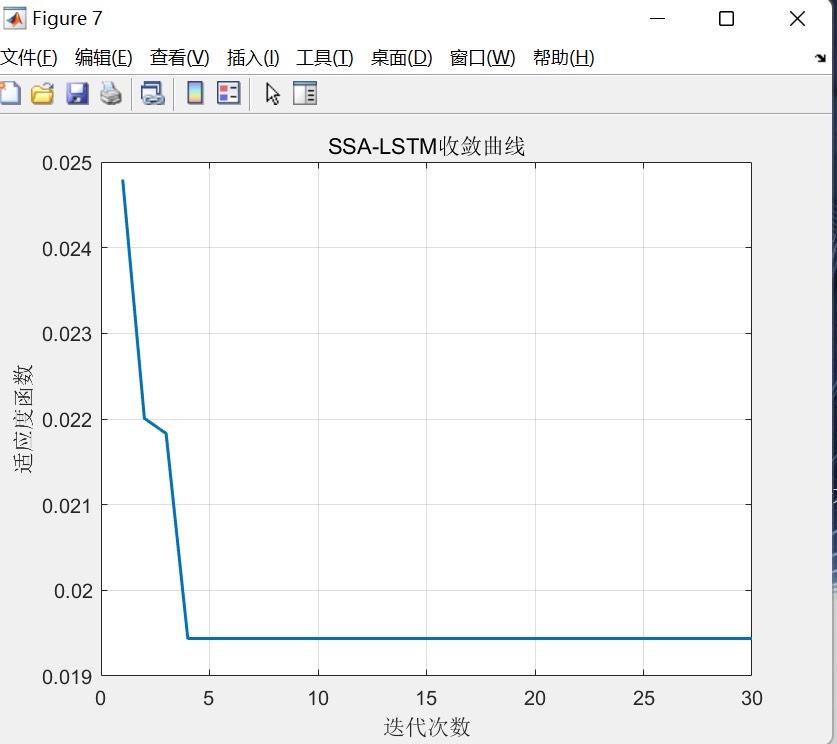
在数据分析和预测领域,时间序列预测一直是个热门话题。今天咱们就来聊聊如何用麻雀优化算法(SSA)结合长短期记忆网络(LSTM),在Matlab环境下搭建一个时间序列单输入单输出预测模型。这个模型最大的好处就是,只要是单列的时间序列数据,直接替换就能用。咱们要求Matlab最低版本是2018及以上哈。
一、算法原理简单介绍
1.1 麻雀优化算法(SSA)
麻雀优化算法是一种新型的群智能优化算法,灵感来源于麻雀觅食和反捕食行为。简单来说,麻雀们在觅食时,有发现者和追随者两种角色。发现者负责寻找食物源,追随者跟着发现者找吃的。同时,当察觉到危险时,麻雀们会做出相应的躲避动作。通过模拟这些行为,SSA可以在解空间中搜索最优解,这里我们就用它来优化LSTM的参数,让模型效果更好。
1.2 长短期记忆网络(LSTM)
LSTM是一种特殊的循环神经网络(RNN),专门用来处理时间序列数据中的长期依赖问题。传统RNN在处理长序列时容易出现梯度消失或梯度爆炸,LSTM通过引入门控机制,像输入门、遗忘门和输出门,有效地解决了这个问题。它能很好地捕捉时间序列中的长期信息,非常适合时间序列预测。
二、Matlab代码实现
2.1 数据准备
假设我们的数据保存在一个单列的文本文件 data.txt 里。
% 读取数据
data = load('data.txt');
% 划分训练集和测试集
trainRatio = 0.8;
trainLen = floor(length(data)*trainRatio);
trainData = data(1:trainLen);
testData = data(trainLen+1:end); 这段代码先读取数据,然后按照80%训练集,20%测试集的比例划分数据。为啥选80%训练集呢?通常这样能在训练充分和保留测试数据量之间找到个不错的平衡,让模型既学到足够知识,又有足够数据来评估效果。
2.2 数据预处理
% 归一化
[trainNorm,ps] = mapminmax(trainData',0,1);
trainNorm = trainNorm';
testNorm = mapminmax('apply',testData',ps);
testNorm = testNorm'; 这里对训练集和测试集进行归一化处理,把数据映射到 [0, 1] 区间。mapminmax 函数是Matlab里专门做这个的,ps 是归一化参数,测试集用训练集得到的参数 ps 来归一化,保证数据尺度一致。
2.3 构建LSTM模型
inputSize = 1;
hiddenSize = 10;
outputSize = 1;
layers = [...
sequenceInputLayer(inputSize)
lstmLayer(hiddenSize)
fullyConnectedLayer(outputSize)
regressionLayer]; 这里构建LSTM网络结构。sequenceInputLayer 是输入层,inputSize 设为1是因为我们是单输入。lstmLayer 是LSTM层,hiddenSize 设为10,这个值可以根据实际情况调,太大可能过拟合,太小可能欠拟合。fullyConnectedLayer 是全连接层,最后 regressionLayer 是回归层,因为我们做的是预测,所以用回归。
2.4 用SSA优化LSTM参数
这部分代码相对复杂点,这里简单示意下核心思路。
% 定义适应度函数,评估LSTM模型在训练集上的性能
fitnessFunction = @(params) evaluateLSTM(params,trainNorm);
% 用SSA优化参数
[bestParams,fval] = SSA(fitnessFunction, numParams, lb, ub, maxIter, numSparrows); evaluateLSTM 函数就是用传入的参数 params 构建LSTM模型,在训练集 trainNorm 上训练并返回性能指标。SSA 函数就是实现麻雀优化算法的核心,它在给定参数范围 lb(下限),ub(上限),最大迭代次数 maxIter 和麻雀数量 numSparrows 下,找最优参数 bestParams。
2.5 模型训练与预测
% 根据优化后的参数构建并训练模型
net = configureNetwork(layers, trainNorm);
net = trainNetwork(trainNorm, net, options);
% 预测
[~, trainPred] = predictAndUpdateState(net, trainNorm);
[~, testPred] = predictAndUpdateState(net, testNorm); 先根据优化后的参数配置网络,然后训练。训练好后对训练集和测试集做预测。predictAndUpdateState 函数会更新LSTM的状态,适合处理时间序列数据。
2.6 结果可视化与评价指标计算
% 反归一化
trainPred = mapminmax('reverse',trainPred',ps);
trainPred = trainPred';
testPred = mapminmax('reverse',testPred',ps);
testPred = testPred';
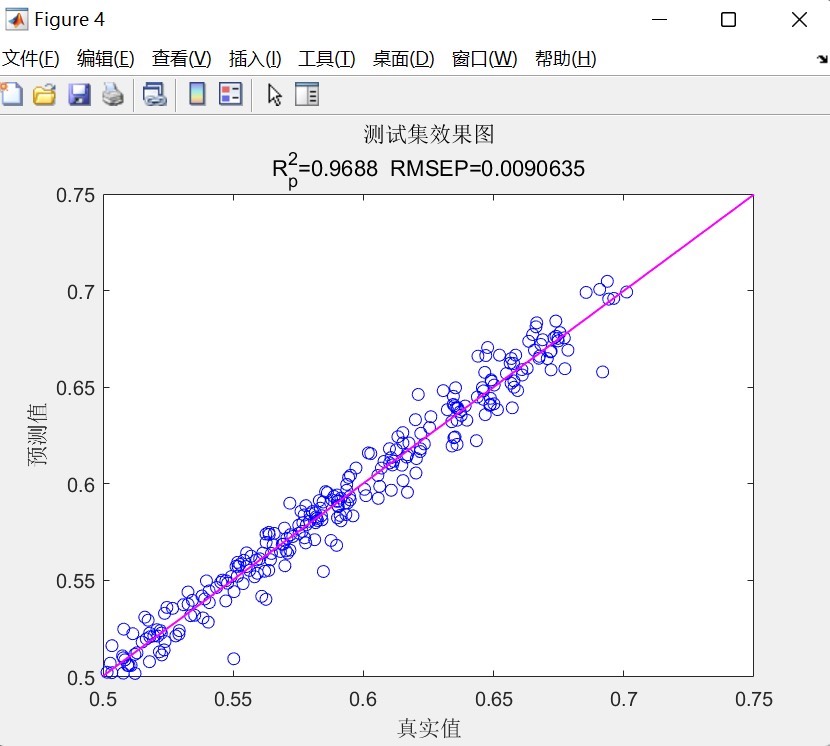
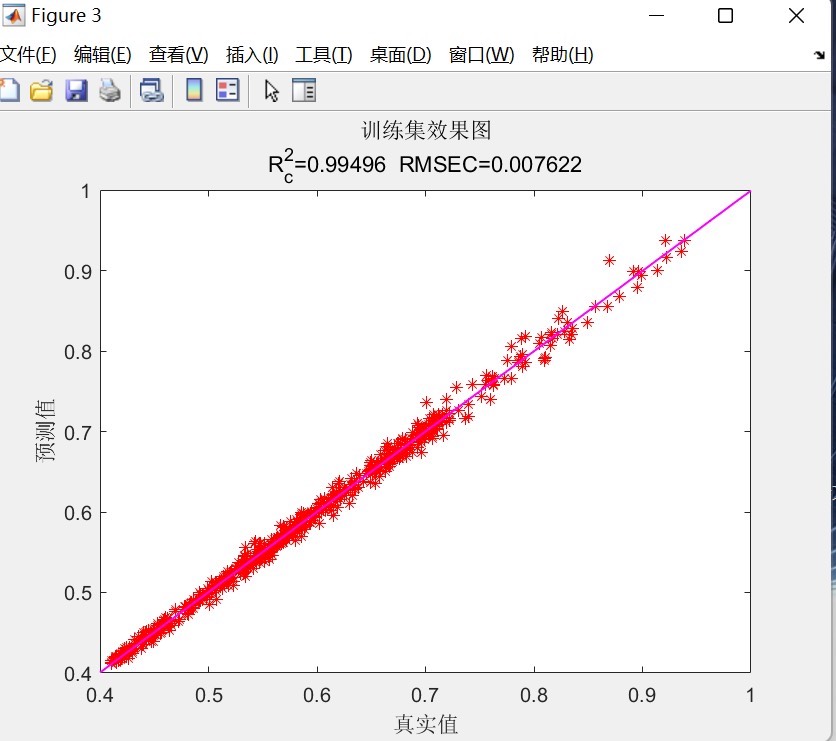
% 真实值和预测值对比图
figure;
plot([1:length(trainData)],trainData,'b', 'DisplayName','真实值 - 训练集');
hold on;
plot([1:length(trainPred)],trainPred,'r--', 'DisplayName','预测值 - 训练集');
plot([length(trainData)+1:length(data)],testData,'b', 'DisplayName','真实值 - 测试集');
plot([length(trainPred)+1:length(trainPred)+length(testPred)],testPred,'r--', 'DisplayName','预测值 - 测试集');
legend;
xlabel('时间步');
ylabel('值');
title('真实值与预测值对比');
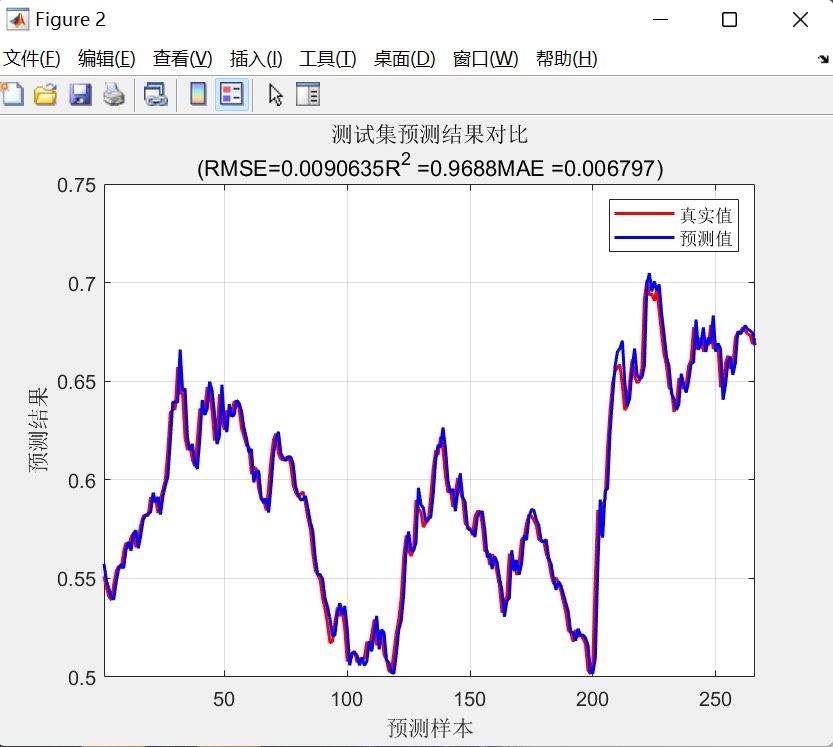
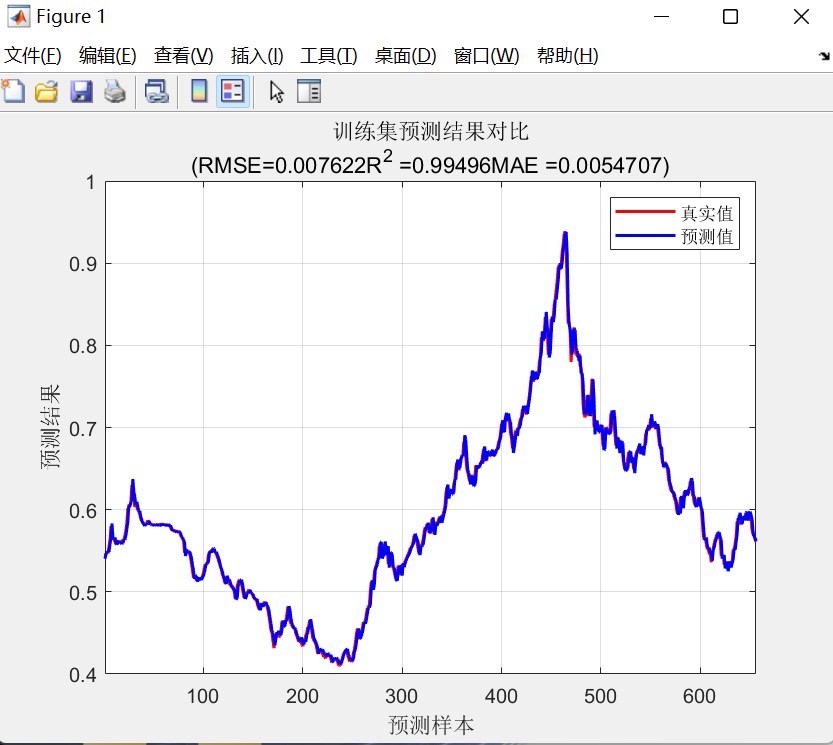
% 线性拟合图
figure;
scatter(trainData,trainPred);
hold on;
p = polyfit(trainData,trainPred,1);
yfit = polyval(p,trainData);
plot(trainData,yfit,'r');
xlabel('真实值');
ylabel('预测值');
title('训练集线性拟合');
% 计算评价指标
maeTrain = mean(abs(trainData - trainPred));
maeTest = mean(abs(testData - testPred));
mseTrain = mean((trainData - trainPred).^2);
mseTest = mean((testData - testPred).^2);
rmseTrain = sqrt(mseTrain);
rmseTest = sqrt(mseTest);
fprintf('训练集MAE: %.4f\n', maeTrain);
fprintf('测试集MAE: %.4f\n', maeTest);
fprintf('训练集MSE: %.4f\n', mseTrain);
fprintf('测试集MSE: %.4f\n', mseTest);
fprintf('训练集RMSE: %.4f\n', rmseTrain);
fprintf('测试集RMSE: %.4f\n', rmseTest); 先把预测值反归一化变回原始尺度,然后分别画真实值和预测值对比图,还有训练集的线性拟合图。最后计算平均绝对误差(MAE)、均方误差(MSE)和均方根误差(RMSE)这些常用评价指标并打印出来。这些指标能直观地告诉我们模型预测的好坏。
麻雀优化算法SSA结合LSTM做时间序列单输入单输出预测模型,要求数据是单列的时间序列数据,直接替换数据就可以用。 程序语言是matlab,需求最低版本为2018及以上。 程序可以出真实值和预测值对比图,线性拟合图,可打印多种评价指标。
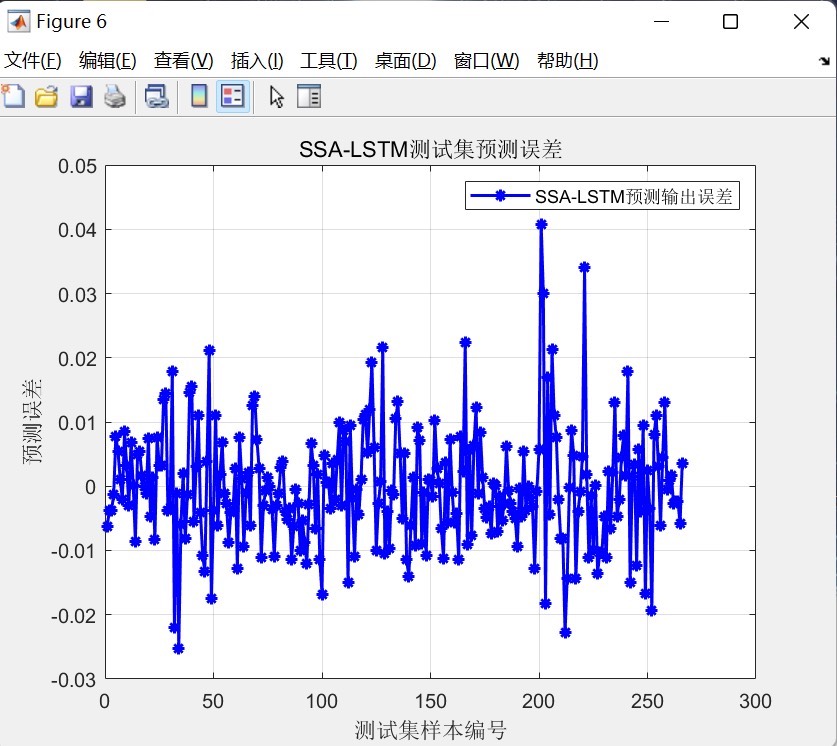
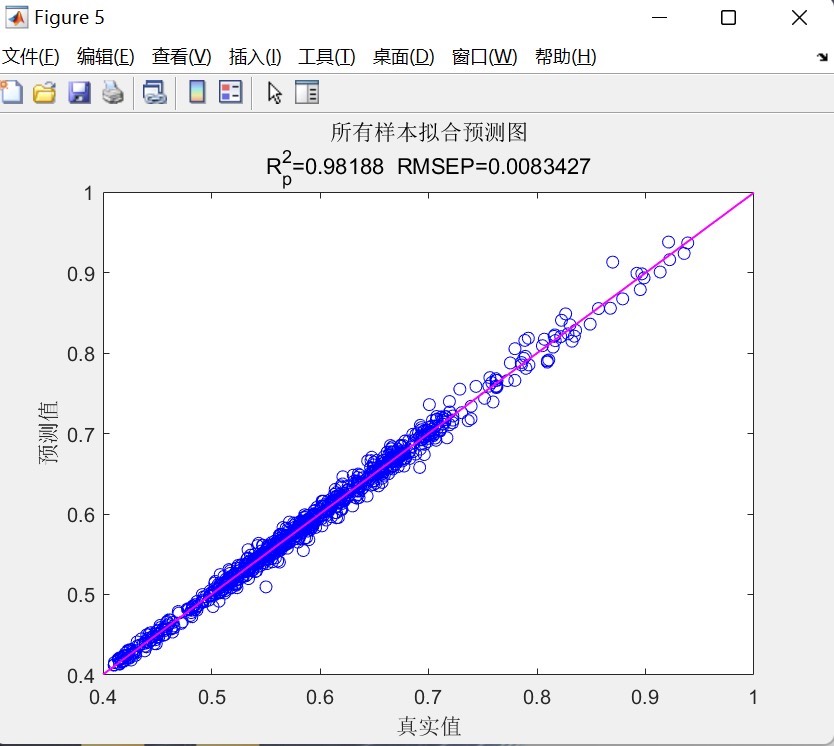
通过以上步骤,咱们就实现了麻雀优化算法SSA结合LSTM的时间序列单输入单输出预测模型,在Matlab环境下对单列时间序列数据进行预测,还能可视化结果和看评价指标。希望这篇文章能对大家有所帮助。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)