C2SSM:Scan Clusters, Not Pixels: A Cluster-Centric Paradigm for Efficient-CVPR2026
Paper:https://arxiv.org/pdf/2602.21917
Code:XXX
Baseline:XXX
文章目录
3.2. Cluster-Centric Scanning Module
3.3. Spatial-Channel Feature Modulator
4.2. Comparisons with the State-of-the-art Methods
前言

问题: 超高清(UHD)图像恢复陷入了可伸缩性危机:现有的模型必须进行像素级操作,需要不可持续的计算。虽然像Mamba这样的状态空间模型(SSM)承诺线性复杂性,但它们的像素顺序扫描仍然是UHD内容中数百万像素的根本瓶颈。我们问:我们必须处理每个像素才能理解图像吗?
动机: 虽然基于 SSM 的 IR 框架[8、9、46]避免了 Transformer 的二次复杂性,但它们仍然受限于像素或补丁级别的扫描,这本质上与可视数据的统计属性不一致。这些方法将像素视为独立的实体,未能充分利用图像特征的底层低等级结构和语义内聚,从而产生了大量和不必要的计算开销。我们认为,高效的超高清恢复的关键不在于更快的像素处理,而在于从以像素为中心的表示方式向以聚类为中心的表示方式的转变。自然图像不是随机的像素集合;它们表现出很强的统计规律性,其中特征收敛到一组稀疏的语义连贯区域。
受此启发,我们引入了一种新的视觉状态空间模型 C2SSM,该模型将图像恢复重新表述为一个神经参数化混合分布建模和推理的过程。
贡献: 本文介绍了一种视觉状态空间模型C2SSM,它打破了这一禁忌,从像素序列扫描转变为聚类序列扫描。我们的核心发现是,通过神经参数混合模型,可以将超高清图像丰富的特征分布提取成稀疏的语义质心集。
C2SSM 利用这一点将全局建模重新表述为一种新颖的双路径过程:它扫描少数几个聚类中心并进行推理,然后通过有原则的相似性分布将全局上下文扩散回所有像素,同时轻量级调制器保留精细细节。这种以聚类为中心的模式实现了效率的决定性飞跃,大幅削减了计算成本,同时在五个超高清恢复任务中建立了新的最先进的结果。
C2SSM不仅是一种解决方案,它还为高效的大规模视觉绘制了一条新的路线:扫描集群,而不是像素。
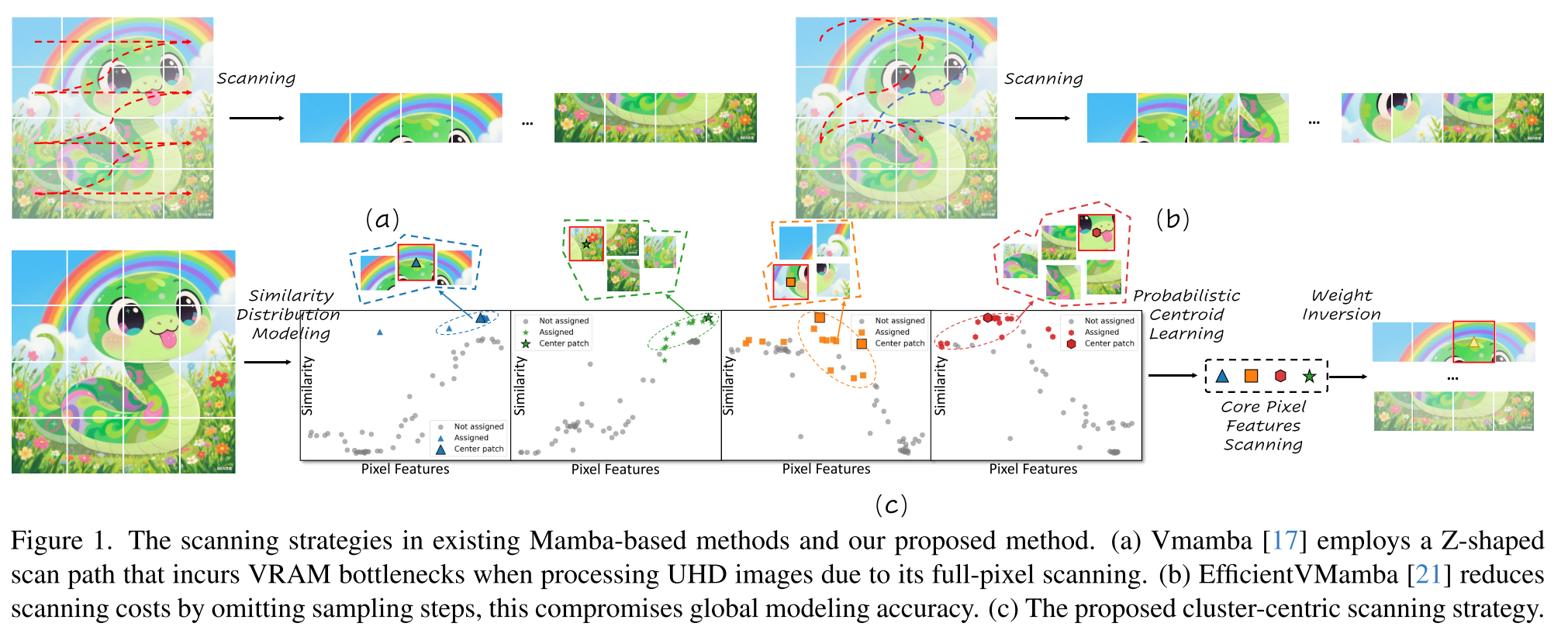
3. Methodology
为了解决UHD图像恢复中全像素扫描的二次复杂度问题,我们提出了一种新的概率驱动聚类中心C2SSM框架。核心创新在于用“质心学习+全局权重反演”取代全像素遍历——关键聚类分配和质心细化都在一步操作中完成——在保持全局上下文的同时实现了可接受的计算开销。
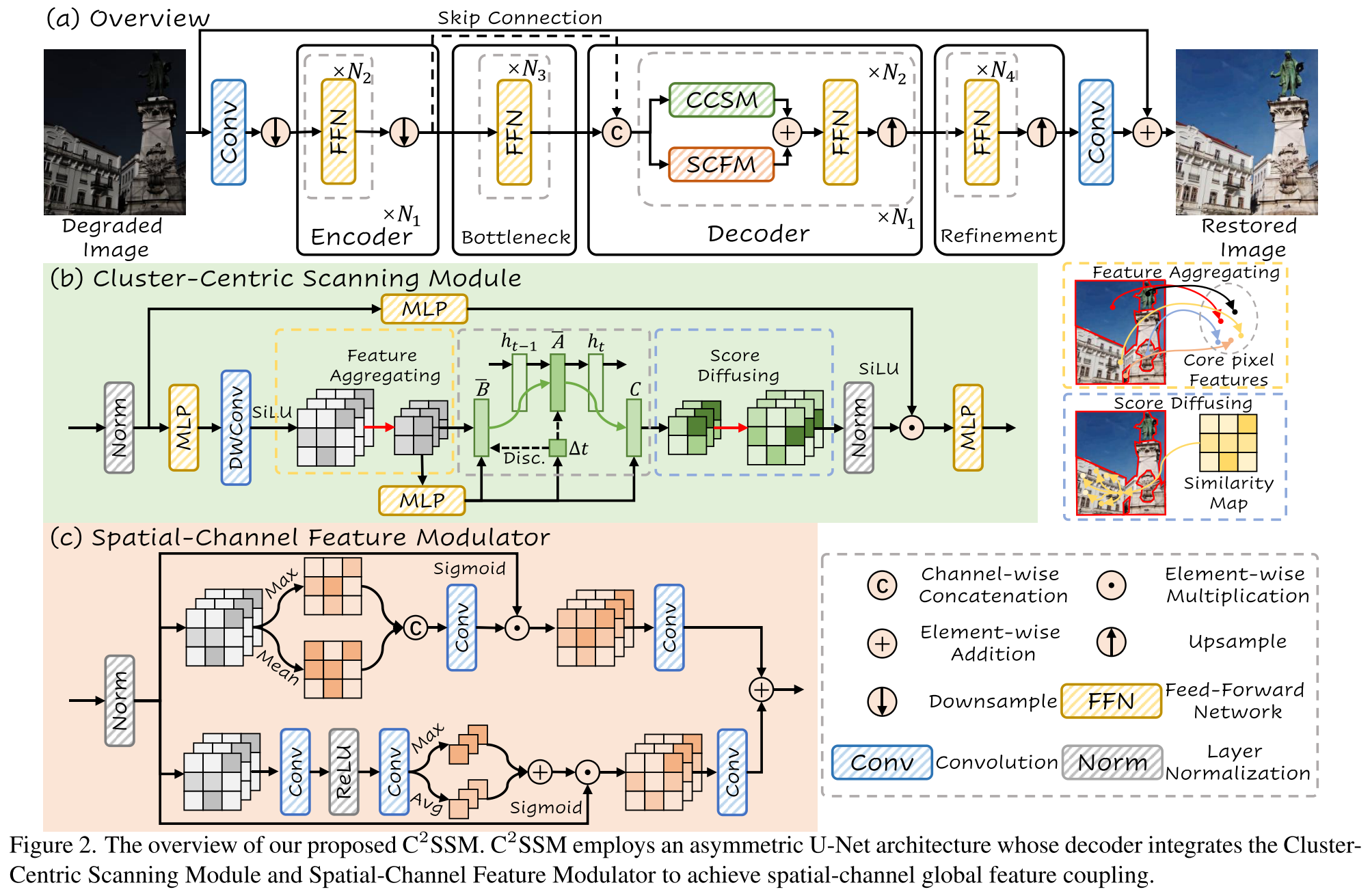
3.1. Overall Architecture
如图 2 (a) 所示,本文提出的 C2SSM 采用编码器-解码器架构,其中退化图像经过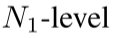 恢复 pipeline。每个编码器/解码器级别包含
恢复 pipeline。每个编码器/解码器级别包含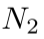 个基本块与卷积采样层(下/上采样)。根据先前的工作[11,45],实现了不对称设计:编码器仅包含 FFN 以减少计算负载,而解码器受MetaFormer[38]的启发,将我们的 CCSM 和 SCFM 与 FFN 集成在一起。编码器和解码器之间的瓶颈层允许深度特征提取,通过将编码器特征纳入解码器层的 1 × 1 卷积进行跳过连接。特征细化阶段的后解码器增强了学习到的表示,并通过将学习到的残差添加到退化的输入中获得最终的恢复图像。
个基本块与卷积采样层(下/上采样)。根据先前的工作[11,45],实现了不对称设计:编码器仅包含 FFN 以减少计算负载,而解码器受MetaFormer[38]的启发,将我们的 CCSM 和 SCFM 与 FFN 集成在一起。编码器和解码器之间的瓶颈层允许深度特征提取,通过将编码器特征纳入解码器层的 1 × 1 卷积进行跳过连接。特征细化阶段的后解码器增强了学习到的表示,并通过将学习到的残差添加到退化的输入中获得最终的恢复图像。
3.2. Cluster-Centric Scanning Module
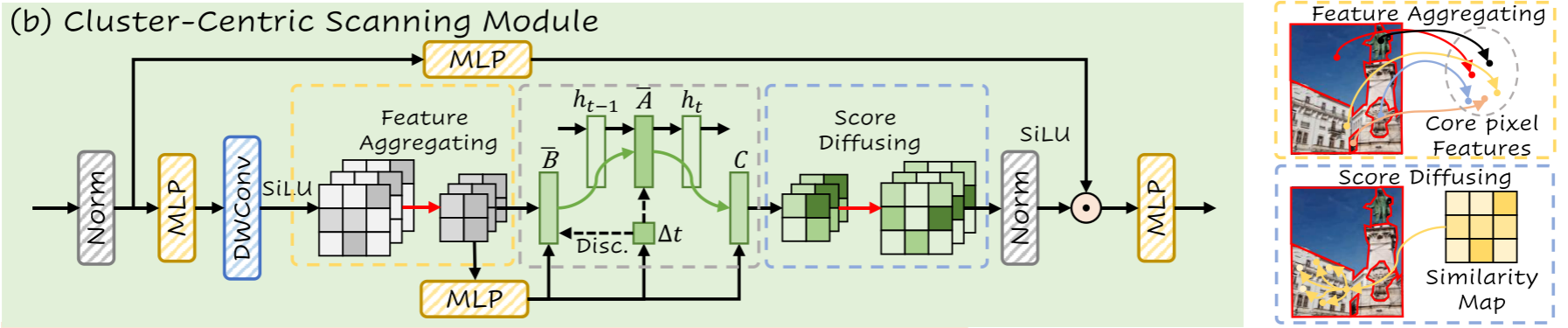
由于空间相邻区域倾向于共享收敛的特征权重模式,视觉图像自然包含高度的语义冗余。为了解决这个问题,CCSM采用特征聚合来集中在上下文聚合的重要像素上,从而大大减少了与全局扫描模型相关的计算负担。随后,分数扩散丰富了非必要像素的可用数据,便于从稀疏中心点重构整个区域。CCSM架构如图 2 (b)所示。对于一层归一化的输入特征映射![]() , CCSM的计算更新为:
, CCSM的计算更新为:

其中, ![]() 为SiLU激活函数。
为SiLU激活函数。![]() 表示归一化层。
表示归一化层。![]() 和
和![]() 分别设计为特征聚合和分数扩散。
分别设计为特征聚合和分数扩散。![]() 代表曼巴[7]提出的选择性扫描机制。
代表曼巴[7]提出的选择性扫描机制。
3.2.1. Feature Aggregating
该阶段旨在从超高清图像特征中学习一组有效的、语义上具有代表性的质心,避免随机聚类或空间约束聚类的低效率。关键是将像素与初始质心之间的相似性建模为概率分布,实现一步跨空间像素分配和一步自适应质心细化,无需任何迭代过程,保证了计算效率。
(1)Initial Centroid Initialization
定层归一化特征张量![]() (编码器输出),我们首先选择
(编码器输出),我们首先选择![]() 个初始质心
个初始质心![]() 其中
其中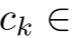
![]() 。初始化遵循跨特征空间的统一采样策略:我们随机选择
。初始化遵循跨特征空间的统一采样策略:我们随机选择![]() 个像素位置并计算它们的 k 近邻值以增强局部偏差。这确保了初始质心覆盖了超高清图像的各种特征模式。
个像素位置并计算它们的 k 近邻值以增强局部偏差。这确保了初始质心覆盖了超高清图像的各种特征模式。
(2)n-Dimensional Similarity Distribution Modeling
对于每个初始质心![]() ,我们计算每个像素特征
,我们计算每个像素特征![]() 之间的余弦相似度 (被 flatten 为
之间的余弦相似度 (被 flatten 为![]() ,以构建具有
,以构建具有![]() 的一维相似度分布
的一维相似度分布![]() )。
)。![]() 个质心共同形成一个
个质心共同形成一个![]() 维相似分布
维相似分布![]() ,其中每个维度
,其中每个维度![]() 定义为概率密度函数(PDF):
定义为概率密度函数(PDF):
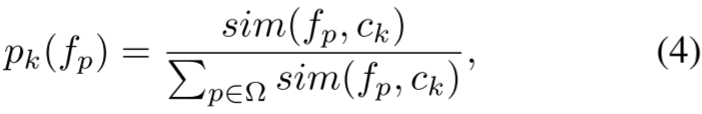
其中,![]() 为UHD图像中的所有像素,
为UHD图像中的所有像素,![]() 为余弦相似度:
为余弦相似度:
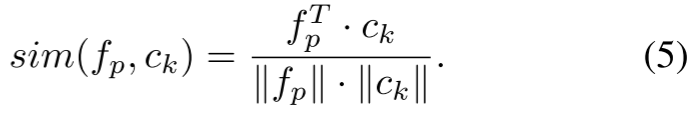
对于![]() ,横轴表示像素的特征值 (为了可解释性,通过 PCA 投影到
,横轴表示像素的特征值 (为了可解释性,通过 PCA 投影到![]() ),纵轴表示归一化相似度(即像素属于
),纵轴表示归一化相似度(即像素属于![]() 主导的聚类的概率)。这种
主导的聚类的概率)。这种![]() 维分布有效地模拟了每个像素和
维分布有效地模拟了每个像素和![]() 个质心之间的语义相关性,将两两相似性转化为概率关联。
个质心之间的语义相关性,将两两相似性转化为概率关联。
(3)Centroid Refinement via Learnable Function
对于每个初始质心![]() ,预先计算出质心与每个像素特征
,预先计算出质心与每个像素特征![]() 之间的相似度分布
之间的相似度分布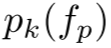 ,在可学习的门控机制引导下,通过自适应特征聚合得到精细化的质心
,在可学习的门控机制引导下,通过自适应特征聚合得到精细化的质心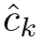 。该算法结合了两个可学习的参数来调整基于相似性的像素选择的灵敏度,以适应不同聚类和数据集的不同特征模式。与自注意[25]中的 qkv 机制类似,我们不直接计算它;相反,我们首先使用 MLP 将
。该算法结合了两个可学习的参数来调整基于相似性的像素选择的灵敏度,以适应不同聚类和数据集的不同特征模式。与自注意[25]中的 qkv 机制类似,我们不直接计算它;相反,我们首先使用 MLP 将![]() 和
和![]() 分别映射到
分别映射到![]() 和
和![]() 。 优化后的质心公式如下:
。 优化后的质心公式如下:
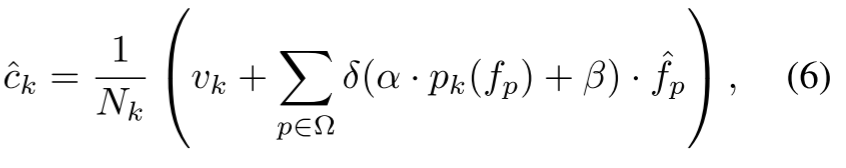
其中,门控函数![]() 采用平滑激活来软选择与初始质心有意义相似的像素,在训练过程中平衡选择性和梯度流。归一化因子
采用平滑激活来软选择与初始质心有意义相似的像素,在训练过程中平衡选择性和梯度流。归一化因子![]() 由激活的门控值和加 1 导出,确保在缩放聚合像素特征以保持数值稳定性的同时保留初始质心的贡献。该因子计算为:
由激活的门控值和加 1 导出,确保在缩放聚合像素特征以保持数值稳定性的同时保留初始质心的贡献。该因子计算为:
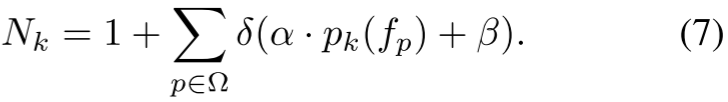
可学习的缩放参数![]() 用于调节基于相似度选择的锐度:在边缘主导的区域中增大该参数,以施加更严格的相关性阈值;而在纹理丰富的区域中减小该参数,从而纳入更加多样的特征。可学习的偏置参数
用于调节基于相似度选择的锐度:在边缘主导的区域中增大该参数,以施加更严格的相关性阈值;而在纹理丰富的区域中减小该参数,从而纳入更加多样的特征。可学习的偏置参数![]() 用于平移激活阈值,以适应每个簇整体的相似度分布,从而避免对相关像素的过度剪枝或选择不足。该门控机制会自然地剪除与质心相似度不显著的像素,在保持语义相关性的同时减少有效计算量。
用于平移激活阈值,以适应每个簇整体的相似度分布,从而避免对相关像素的过度剪枝或选择不足。该门控机制会自然地剪除与质心相似度不显著的像素,在保持语义相关性的同时减少有效计算量。
3.2.2. Score Diffusing
这个阶段利用 Mamba 在远程依赖关系建模方面的优势,但只将其应用于![]() 个精细化的质心(而不是所有像素),然后根据
个精细化的质心(而不是所有像素),然后根据![]() 维相似性分布反转全局像素权重。该过程模仿Transformer的注意力机制,但避免了全像素成对计算。
维相似性分布反转全局像素权重。该过程模仿Transformer的注意力机制,但避免了全像素成对计算。
(1)Mamba-Based Centroid Weight Estimation
我们给优化后的质心![]() 输入 mamba 的选择性扫描模块(S6块),以了解它们精确的全局权重。Mamba 的状态空间建模有效地捕获质心之间的远程依赖关系,输出一组质心特定权重
输入 mamba 的选择性扫描模块(S6块),以了解它们精确的全局权重。Mamba 的状态空间建模有效地捕获质心之间的远程依赖关系,输出一组质心特定权重![]()
![]() ,其中
,其中![]() 为质心
为质心![]() 的全局上下文权值:
的全局上下文权值:
![]()
这里,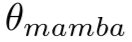 是 Mamba 模块的可学习参数。这一步的复杂度为
是 Mamba 模块的可学习参数。这一步的复杂度为![]() ,与全像素扫描的
,与全像素扫描的![]() 相比可以忽略不计(因为
相比可以忽略不计(因为![]() ,尽管网络中存在尺寸变换,导致通道数量不等,但所有通道仍处于同一数量级)。
,尽管网络中存在尺寸变换,导致通道数量不等,但所有通道仍处于同一数量级)。
(2)Weight Inversion via Similarity Distribution
我们将像素![]() 对聚类
对聚类![]() 的赋值概率
的赋值概率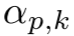 形式化为从
形式化为从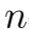 维相似分布
维相似分布![]() 导出的后验概率。与独立参数化不同,
导出的后验概率。与独立参数化不同,![]() 直接从相似分布
直接从相似分布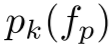 (来自方程 4)归一化,以保持概率一致性:
(来自方程 4)归一化,以保持概率一致性:
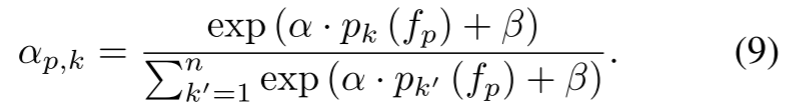
其中,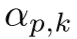 量化了像素
量化了像素![]() 属于质心
属于质心![]() 主导的聚类的概率。我们采用 softmax 归一化来严格满足概率公理
主导的聚类的概率。我们采用 softmax 归一化来严格满足概率公理![]() ,其中
,其中![]() 和
和![]() 是调制分布锐度的可学习参数。这个定义直接将权重反演与之前的相似分布建模联系起来,形成一个封闭的概率环。根据全概率定律,像素
是调制分布锐度的可学习参数。这个定义直接将权重反演与之前的相似分布建模联系起来,形成一个封闭的概率环。根据全概率定律,像素![]() 的全局权值
的全局权值![]() 为质心权值
为质心权值![]() 的期望值(来自方程(8)),以像素的相似度分布
的期望值(来自方程(8)),以像素的相似度分布![]() 为条件,反演公式为:
为条件,反演公式为:
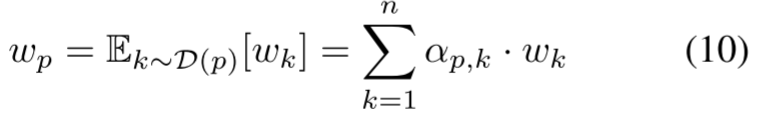
其中,![]() 表示像素
表示像素![]() 的全局权重,期望
的全局权重,期望![]() 明确强调权重是基于像素跨
明确强调权重是基于像素跨![]() 个簇的概率分布计算的。
个簇的概率分布计算的。
3.3. Spatial-Channel Feature Modulator
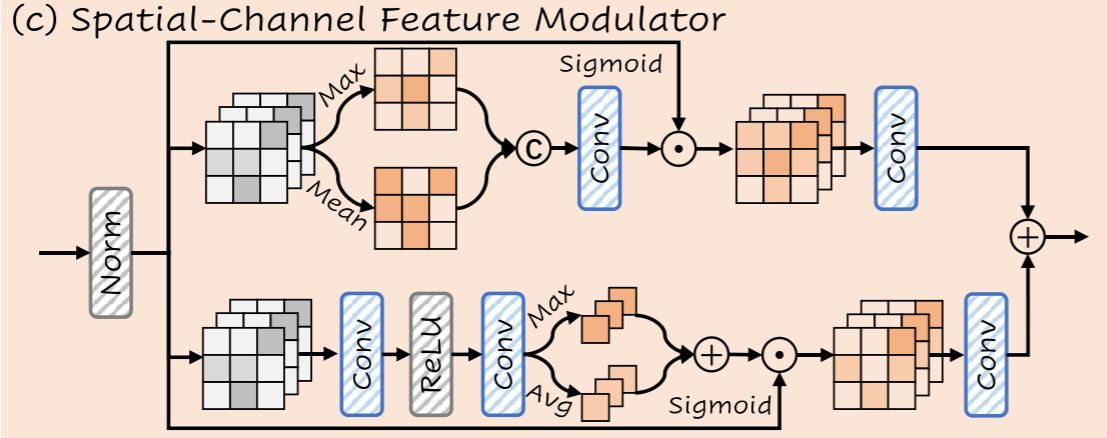
为了解决由质心聚集引起的高频细节丢失问题,SCFM 与权重反演阶段并行进行。采用双分支注意(空间+通道),最大限度地提高输入输出特征之间的互信息[33]:
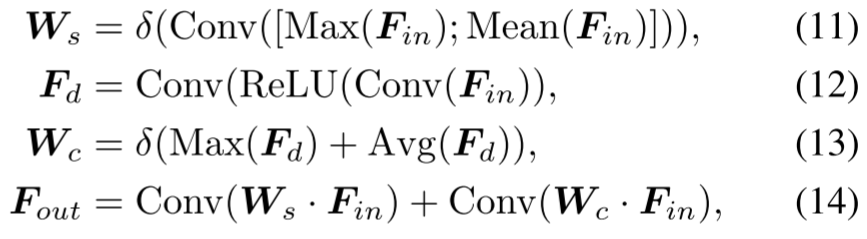
其中,![]() 为最大值操作,
为最大值操作,![]() 为平均值操作。
为平均值操作。![]() 是连接操作。
是连接操作。![]() 表示ReLU激活函数。
表示ReLU激活函数。
4. Experiments
4.1. Experimental Settings
我们的实验使用 PyTorch 在 4 个NVIDIA A800GPU 的设置上进行。为了优化网络,我们使用初始学习率为![]() 的 AdamW 优化器,并使用余弦退火策略来处理学习率的衰减。我们将全分辨率4K图像随机裁剪为 768 × 768 的分辨率作为输入,批大小设置为 16。对于所有 UHD 恢复任务,我们执行 150K 次迭代。为了增强训练数据,对输入图像进行随机水平和垂直翻转。我们的方法由一个
的 AdamW 优化器,并使用余弦退火策略来处理学习率的衰减。我们将全分辨率4K图像随机裁剪为 768 × 768 的分辨率作为输入,批大小设置为 16。对于所有 UHD 恢复任务,我们执行 150K 次迭代。为了增强训练数据,对输入图像进行随机水平和垂直翻转。我们的方法由一个![]() 级的编码器-解码器组成,其中编码器和解码器共享相同的块结构:
级的编码器-解码器组成,其中编码器和解码器共享相同的块结构:![]() 。瓶颈和细化阶段各包含
。瓶颈和细化阶段各包含![]() 个块,基本嵌入维数为 32。为了优化网络的权重和偏置,我们利用RGB色彩空间中的 L1 损失和 FFT 损失作为基本重建损失。
个块,基本嵌入维数为 32。为了优化网络的权重和偏置,我们利用RGB色彩空间中的 L1 损失和 FFT 损失作为基本重建损失。
4.2. Comparisons with the State-of-the-art Methods
(1)Low-light Image Enhancement Results
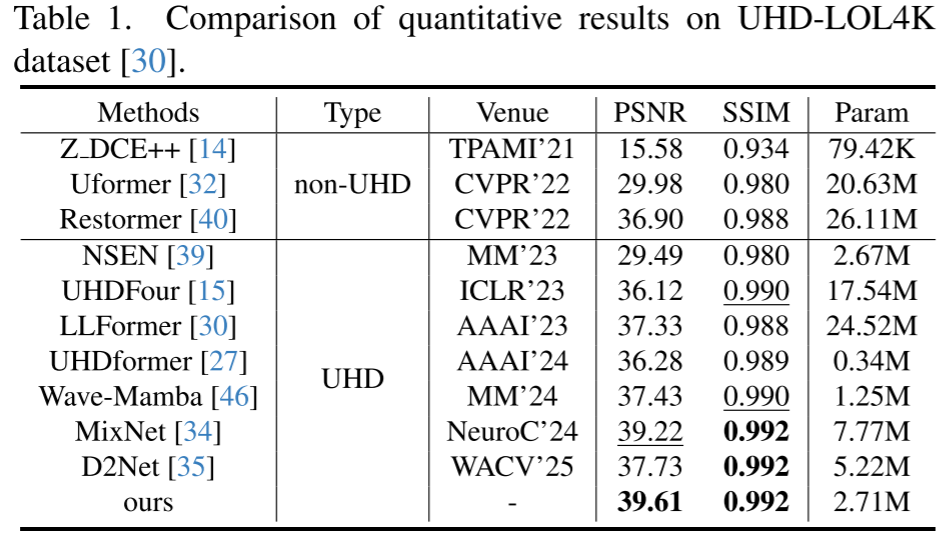
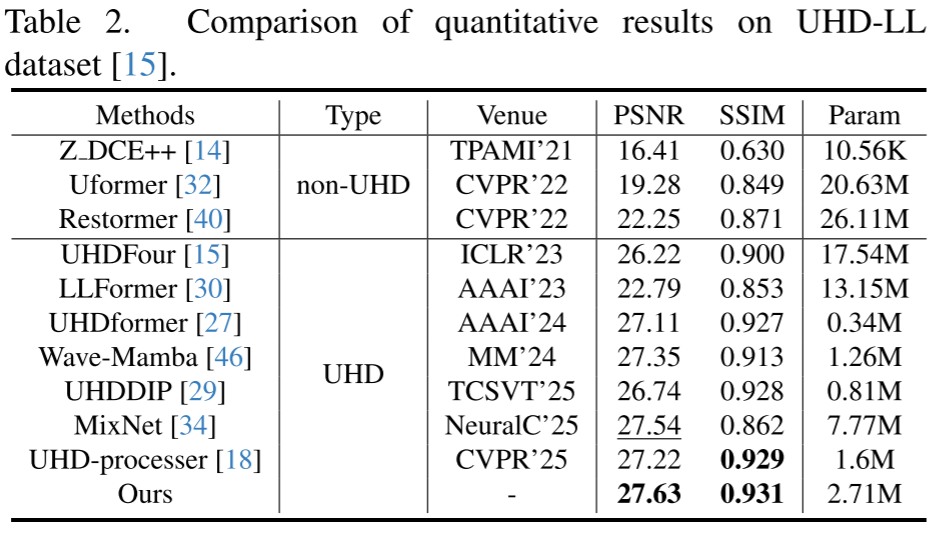
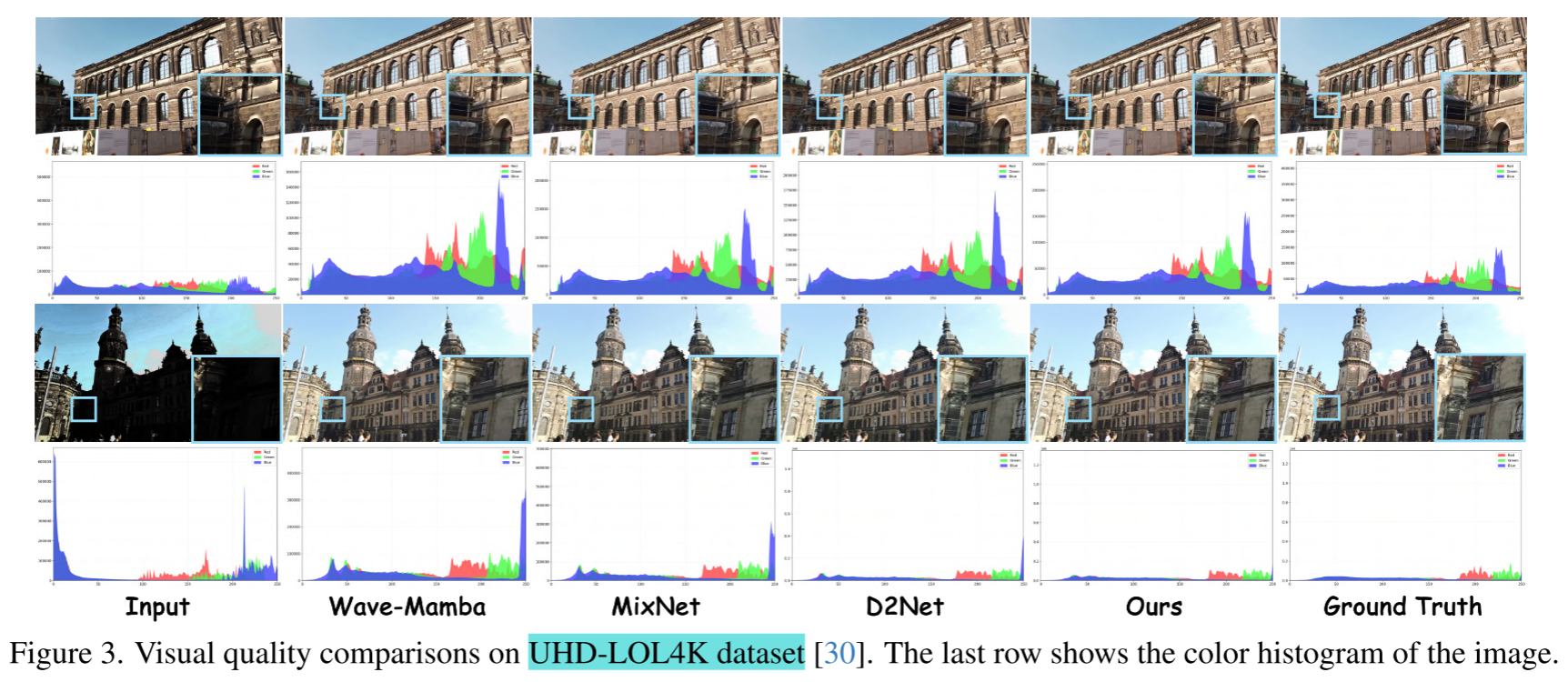
(2)Image Deraining Results


(3)Image Deblurring Results
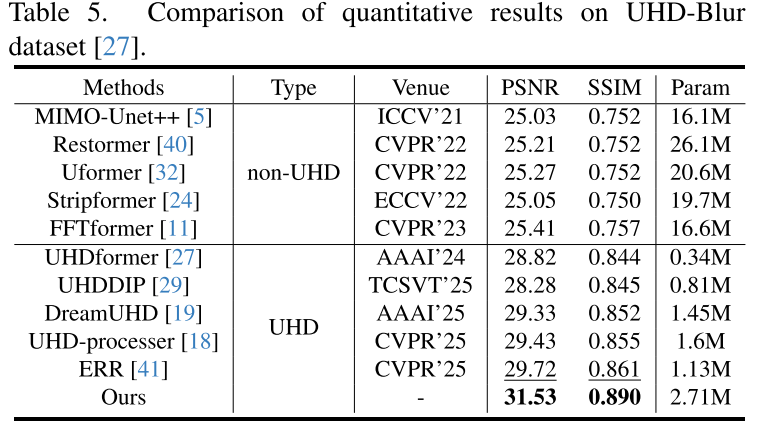
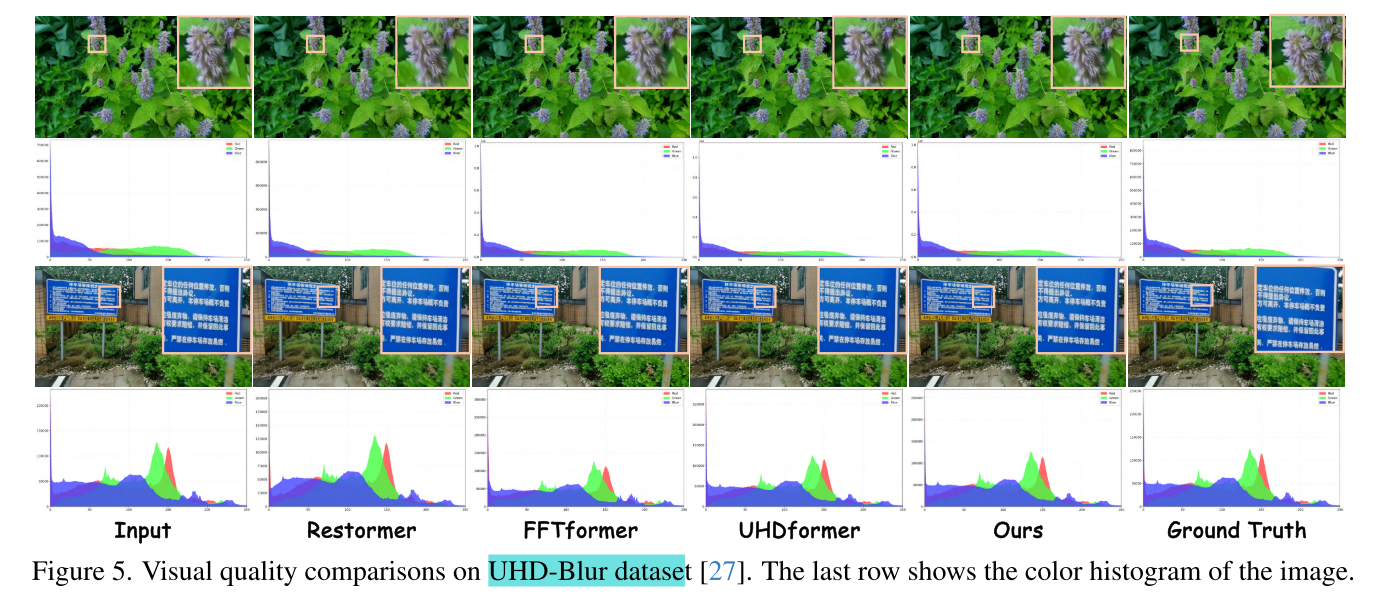
(4)Image Dehazing Results
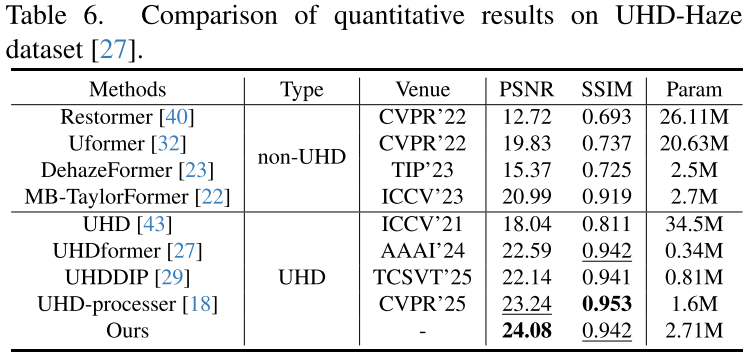
(5)Image Desnowing Results
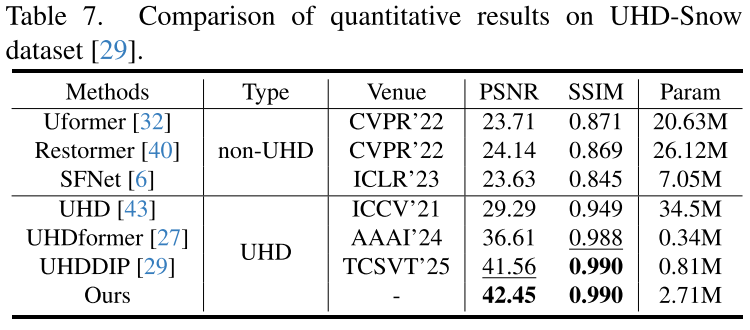
4.3. Ablation Studies and Discussions
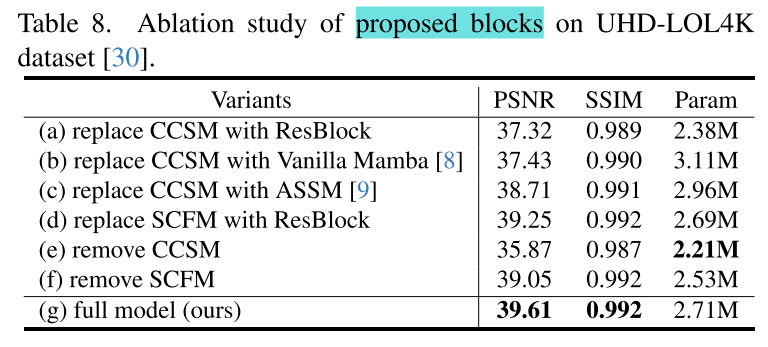
(1)Effectiveness of Proposed Blocks
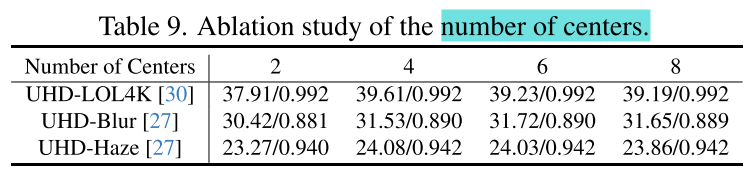
(2)Validation of the Number of Centers
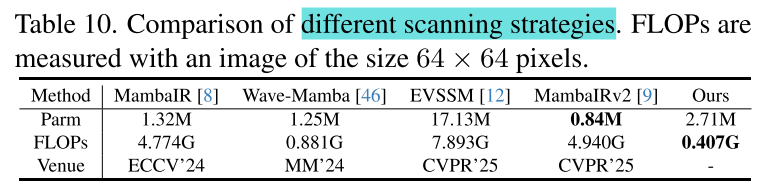
(3)Comparison with Other Scanning Strategy
5. Conclusion
在本文中,我们提出了一种新的视觉状态空间模型C2SSM,它打破了现有的基于 mamba 的超高清图像恢复方法的计算瓶颈,从像素序列扫描转向聚类序列扫描。C2SSM的核心在于CCSM,它将超高清图像建模为一组稀疏的语义质心。通过仅在这些质心上执行全局推理,并通过原则相似分布将学习到的上下文扩散回像素,CCSM在不牺牲性能的情况下显著降低了计算复杂性。作为补充,SCFM确保保留在聚类期间可能被忽略的高频细节。CCSM和SCFM是互补的。在众多超高清图像恢复任务的综合实验表明,我们的方法在定量指标和定性分析方面都优于当前的SOTA方法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)