为何性能分析选 LLM 与 Ranking 模型?
在 AI 模型的训练 / 推理性能分析中,LLM(大语言模型) 和Ranking(排序模型) 是两大核心选择,本质是二者分别代表了AI 领域最主流的两大技术范式(生成式大模型范式、判别式 / 在线服务式小中模型范式),且覆盖了训练 / 推理阶段几乎所有的核心性能瓶颈与技术挑战—— 其他 AI 模型的性能问题,本质都是这两类模型性能特征的子集、简化或变体。
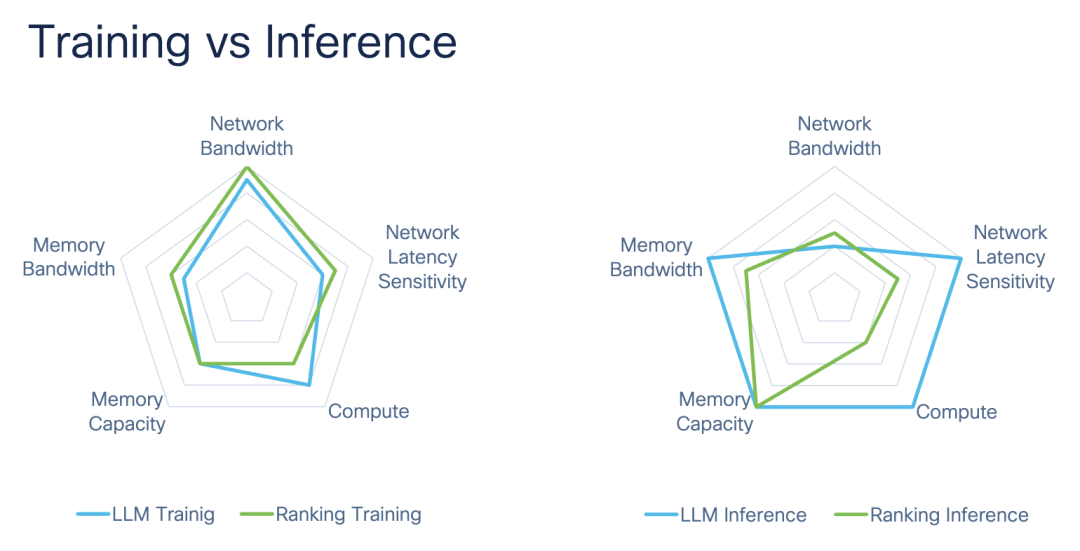
同时,这两类模型也是工业界和学术界的核心落地场景:LLM 是大模型时代的标杆,代表了 “高算力、大参数量、长序列” 的极端性能挑战场景;Ranking 是推荐、搜索、广告等工业级在线服务的核心,代表了 “高并发、低延迟、多特征、小批量” 的通用性能落地场景。二者结合,就能完整覆盖从实验室大模型到工业界在线服务的所有 AI 模型性能分析维度。
一、LLM 与 Ranking 模型的核心定义
1. LLM(Large Language Model,大语言模型)
核心定位:基于Transformer Decoder/Decoder-Only架构的生成式预训练大模型,以自然语言为核心载体,具备大参数量、长上下文建模、自回归生成的核心特征。
- 核心技术特征:大参数量(从亿级到万亿级)、基于自注意力的上下文依赖建模、自回归逐 token 生成(推理阶段串行输出)、预训练 + 微调的两阶段训练模式、对算力 / 显存 / 通信的极致需求;
- 代表模型:GPT 系列、LLaMA 系列、文心一言、通义千问、Claude 等;
- 核心落地场景:对话交互、文本生成、机器翻译、摘要总结、代码生成等生成式 NLP 任务,也是多模态大模型(如 GPT-4V、文生图模型)的核心底座。
2. Ranking(排序模型)
核心定位:面向候选集打分排序的判别式模型(部分融合生成式特征),多基于Transformer Encoder / 双塔 / 单塔架构,是推荐系统、搜索引擎、广告投放等工业级场景的核心模型,核心目标是从海量候选集中筛选出用户最感兴趣的内容并排序。
- 核心技术特征:多特征融合(稠密特征 + 稀疏特征,如用户行为、商品属性、文本标签)、排序专用损失函数(Pairwise/Listwise/Multiclass)、小参数量 / 中参数量(百万级到亿级)、工业级在线推理的高并发 / 低延迟要求、支持增量训练 / 在线学习;
- 代表模型 / 架构:双塔 Ranking、单塔 Ranking、DIN/DIEN/DeepFM(推荐领域)、ESIM(文本排序)、CrossEncoder(检索排序)等;
- 核心落地场景:电商推荐(如淘宝 / 京东商品推荐)、搜索引擎(如百度 / 谷歌网页排序)、广告投放(如抖音 / 朋友圈广告排序)、内容推荐(如抖音 / 小红书视频排序)等工业级在线服务场景。
二、核心原因:两类模型覆盖了 AI 的主流技术范式与全维度性能瓶颈
AI 模型的种类繁多(图像分类、目标检测、语音识别、NLP 分类、生成式多模态等),但从训练 / 推理的性能特征和技术架构本质来看,所有模型都能归为生成式或判别式 / 在线服务式两大阵营:
- 生成式模型的性能瓶颈,以 LLM 为极致代表(大参数量、长序列、串行生成、高算力通信需求),其他生成式模型(如文生图的扩散模型、语音生成的 TTS 模型)只是瓶颈的简化版;
- 判别式 / 在线服务式模型的性能瓶颈,以 Ranking 为通用代表(高并发、低延迟、多特征、小批量推理、增量训练),其他判别式模型(如图像分类、NLP 情感分析、目标检测)只是无稀疏特征的简化版。
简言之,解决了 LLM 和 Ranking 的性能问题,就等于解决了 90% 以上 AI 模型的性能问题,这也是二者成为性能分析核心标的的底层逻辑。
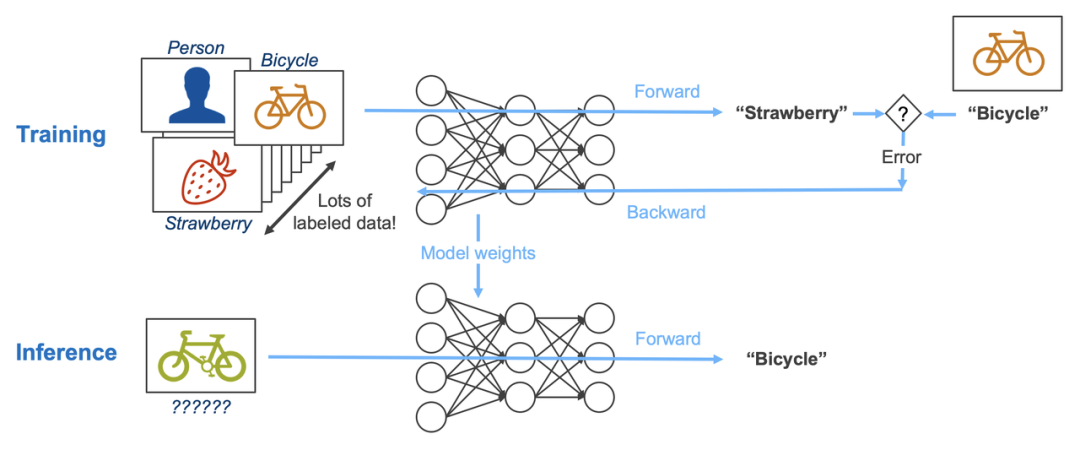
三、训练阶段:二者覆盖了所有 AI 模型的核心训练性能瓶颈
模型训练的性能分析核心维度是:显存利用率、算力利用率、并行效率、通信开销、数据处理效率。LLM 和 Ranking 分别在这些维度上体现了极端挑战和通用挑战,覆盖了所有 AI 模型的训练瓶颈。
1. LLM:代表大模型训练的所有极端性能挑战
LLM 是目前 AI 模型中对训练性能要求最高的类型,其训练瓶颈是所有大参数量、长序列、生成式模型的共性,其他大模型(如大视觉模型、多模态大模型)的训练优化方法均直接迁移自 LLM 的优化思路:
- 显存瓶颈:大参数量导致 “内存墙”,需采用模型并行、流水线并行、ZeRO 优化、显存重计算等技术 —— 这也是所有大模型训练的核心问题,小模型仅需基础显存优化,是其简化版;
- 并行效率瓶颈:多卡 / 多机并行时,数据并行、模型并行、流水线并行的组合调度极其复杂,通信开销占比极高(如千亿级 LLM 训练,通信开销可达算力开销的 50% 以上)—— 这是所有分布式训练模型的核心问题,小模型并行通信开销可忽略,无本质挑战;
- 计算效率瓶颈:自注意力机制的时间复杂度为O(n^2)(n 为上下文长度),长上下文(如 128k)训练时计算量呈指数级增长 —— 这是所有长序列建模模型(如长文本分类、视频理解)的共性问题;
- 数据处理瓶颈:预训练阶段需要海量语料(千亿级 tokens),数据的加载、分词、预处理需高度并行化 —— 这是所有预训练模型的共性问题,小模型的小数据量无此挑战。
2. Ranking:代表工业级判别式模型训练的所有通用性能挑战
Ranking 是工业界最主流的判别式模型,其训练瓶颈是所有小中参数量、多特征、在线增量训练模型的共性,覆盖了图像分类、NLP 分类、目标检测等绝大多数判别式模型的训练需求:
- 多特征显存优化瓶颈:融合稠密特征(如用户年龄、商品价格)和稀疏特征(如用户点击序列、商品 ID),稀疏特征的 embedding 层显存占用极高 —— 这是 Ranking 的特有挑战,其他判别式模型(如图像分类)无稀疏特征,只是简化版的显存优化;
- 样本与损失效率瓶颈:排序损失(如 Pairwise)需要难负例采样,样本选择直接影响训练效率和模型效果,且工业级数据是海量非均衡数据 —— 这是所有分类 / 排序模型的共性问题,如图像检测的正负样本均衡、NLP 分类的样本采样;
- 增量训练瓶颈:工业界需实时融入用户最新行为数据(如用户刚点击的商品),进行增量训练 / 在线学习,要求模型支持轻量更新、低算力消耗—— 这是所有工业级在线服务模型的核心需求,实验室静态模型无此挑战;
- 小批量并行瓶颈:稀疏特征导致单卡批量大小(batch size)无法过大,多卡并行时负载均衡难度高 —— 这是所有小批量训练模型的共性问题,如目标检测的小批量训练。
训练阶段的代表性总结
LLM 代表了 “实验室大模型” 的训练性能极限 ,Ranking 代表了 “工业界小中模型” 的训练性能通用需求 ,二者结合,覆盖了从“大参数量预训练” 到“小参数量增量训练” 的所有 AI 模型训练场景,其优化技术(如显存优化、并行调度、数据处理)可直接迁移到其他所有模型。
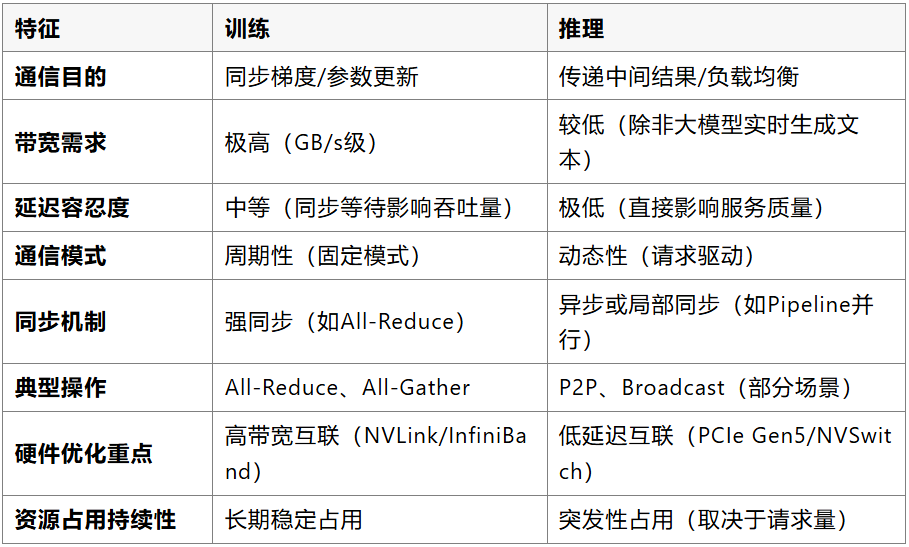
四、推理阶段:二者覆盖了所有 AI 模型的核心推理性能瓶颈
模型推理的性能分析核心维度是:延迟(首包 / 端到端)、吞吐、资源利用率、动态调度、服务稳定性,这也是工业界模型落地的核心考核指标。LLM 和 Ranking 分别代表了生成式推理和在线判别式推理的两大极致场景,其推理瓶颈是所有 AI 模型的共性。
1. LLM:代表生成式推理的核心性能瓶颈 —— 低吞吐、高延迟、长序列内存
LLM 的推理是生成式模型的极致代表,其核心瓶颈源于自回归逐 token 生成,这也是所有生成式模型(扩散模型、TTS、文生图)的共性,只是生成方式不同,优化思路完全一致:
- 端到端延迟瓶颈:自回归生成导致串行输出,生成一个句子需要逐 token 计算(如生成 100 个 token 需计算 100 次),且首 token 延迟(第一次计算的延迟)远高于后续 token—— 这是所有生成式模型的核心问题,如扩散模型的多步采样、TTS 的帧级生成,均为串行计算导致的高延迟;
- 吞吐提升瓶颈:串行生成导致单卡吞吐极低,需通过动态批处理(Dynamic Batching)、连续批处理(Continuous Batching)、投机采样等技术提升吞吐 —— 这是所有生成式模型推理的核心优化方向;
- 长序列内存瓶颈:上下文窗口扩展(如 128k)导致注意力机制的显存占用呈指数级增长,需通过注意力稀疏化、KV Cache 优化、量化(INT4/INT8) 等技术压缩显存 —— 这是所有长序列推理模型的共性问题,如长文本分类、视频理解;
- 大模型部署瓶颈:千亿级 LLM 无法单卡部署,需采用模型切分、张量并行、流水线并行、分布式推理等技术 —— 这是所有大模型推理的共性问题,大视觉模型、多模态大模型的部署均直接复用该技术。
2. Ranking:代表工业级在线推理的核心性能瓶颈 —— 高并发、低延迟、实时特征
Ranking 是工业界在线推理的标杆场景(如电商推荐需支持十万级 QPS、毫秒级响应),其推理瓶颈是所有工业级在线服务模型的共性,覆盖了图像分类、NLP 情感分析、目标检测等所有需要在线部署的判别式模型:
- 高并发低延迟瓶颈:要求端到端推理延迟控制在10-50 毫秒,且支持十万级 QPS,需通过模型量化、剪枝、蒸馏压缩模型,同时采用批处理调度、GPU/CPU 异构计算提升资源利用率 —— 这是所有在线服务模型的核心需求,如图像分类的安防检测、NLP 的情感分析在线接口,均要求毫秒级响应;
- 实时特征计算瓶颈:在线推理时需实时获取用户最新特征(如用户刚浏览的商品),特征计算的延迟直接影响整体服务延迟,需通过特征缓存、预计算、分布式特征服务优化 —— 这是所有工业级模型的特有挑战,实验室静态推理(固定输入)无此问题;
- 双塔模型的检索瓶颈:主流的工业级 Ranking 采用双塔模型(用户塔 + 物品塔),先通过向量检索获取候选集,再打分排序,向量检索的召回率 + 延迟是核心瓶颈 —— 这是所有检索类模型的共性问题,如文本检索、图像检索、语音检索;
- 动态负载调度瓶颈:工业界流量存在波峰波谷(如电商 618 的流量峰值是日常的 10 倍以上),需通过弹性伸缩、动态资源调度保证服务稳定性 —— 这是所有工业级在线服务的通用需求,实验室固定负载推理无此挑战。
推理阶段的代表性总结
LLM 代表了 “生成式模型推理” 的低吞吐、高延迟、大模型部署挑战 ,Ranking 代表了 “工业级在线推理” 的高并发、低延迟、动态负载挑战 ,二者覆盖了 AI 模型推理的所有核心场景:
- 实验室的静态推理(如论文实验、模型效果验证),可参考 LLM 的基础推理优化;
- 工业界的在线服务推理(90% 以上的 AI 落地场景),核心参考 Ranking 的优化思路;
- 生成式模型的工业级落地(如 ChatGPT、文生图 API),需融合 LLM 和 Ranking 的优化思路(如 LLM 的动态批处理 + Ranking 的高并发调度)。
五、补充:工业界与学术界的选择逻辑强化了二者的代表性
- 学术界:聚焦极致性能挑战的突破,LLM 是大模型时代的核心研究对象,其训练 / 推理的性能优化(如并行算法、注意力优化、量化技术)是顶会的核心议题,研究成果可直接迁移到其他大模型;
- 工业界:聚焦通用场景的落地,Ranking 是推荐 / 搜索 / 广告的核心,其在线推理的性能优化(如高并发调度、特征缓存、模型压缩)是 AI 工程化的核心,而 LLM 的工业级落地(如大模型 API 服务)是目前的技术热点,二者共同构成工业界 AI 性能优化的核心工作;
- 技术迁移性:LLM 和 Ranking 的性能优化技术具有高度通用性,如为 LLM 开发的量化、并行技术,可直接用到大视觉模型;为 Ranking 开发的高并发调度、模型蒸馏技术,可直接用到图像分类、NLP 分类的在线服务。
最终总结
- 定义层面:LLM 是生成式预训练大模型的标杆,代表大参数量、长序列、自回归生成的技术特征;Ranking 是判别式排序模型的核心,代表多特征、高并发、低延迟的工业级在线服务特征;
- 范式层面:二者分别覆盖了 AI 的生成式和判别式 / 在线服务式两大核心技术范式,所有 AI 模型均可归为这两类的简化或变体;
- 瓶颈层面:训练阶段,LLM 代表大模型的显存 / 通信 / 计算极致挑战,Ranking 代表工业级模型的多特征 / 增量训练 / 小批量通用挑战;推理阶段,LLM 代表生成式模型的低吞吐 / 高延迟瓶颈,Ranking 代表工业级模型的高并发 / 低延迟瓶颈;
- 技术层面:二者的性能优化技术具有高度通用性,解决了二者的性能问题,即可迁移到 90% 以上的 AI 模型,这是其成为性能分析核心标的的关键。
简言之,LLM 和 Ranking 并非 “单独的模型类型”,而是AI 模型性能特征的两大集大成者,选择二者进行性能分析,就是选择了最具代表性的极端场景和通用场景,其分析结果具有普适性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)