为什么我越来越觉得,AI 模型越来越强,产品却是越来越难聊了
这段时间,我越来越频繁地感受到一种微妙的不适。
不是某个 AI 突然彻底不能用了,也不是它真的什么都答不上来。恰恰相反,很多时候它依然能回答,依然能组织语言,依然能看起来“像那么回事”。
但问题是,聊天变累了。
以前,我更习惯把 AI 产品当作一个对话对象。输入一句自然语言,它大致能理解我真正想问的是什么,也能顺着我的语境,把隐含的信息补全,给出一个八九不离十的回答。
现在,越来越多的时候,我发现自己不是在“聊天”,而是在“下指令”。
我需要补充时间范围,需要指定信息来源,需要声明不要历史背景,需要强调我要的是最新进展而不是概念解释。否则,它就很可能给出一个形式正确、内容完整,但其实并不是我真正想要的答案。
这不是完全不能接受。
作为一个做 IT 的人,我很理解做产品和聊天之间的差异,也理解一个系统为了降低风险、减少幻觉、保证稳定,可能会主动采取更保守的策略。
但理解归理解,体验归体验。
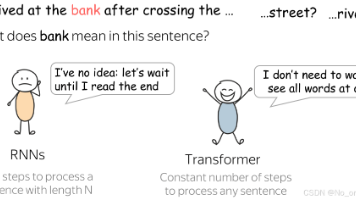
当一个对话系统越来越需要用户自己补全语境,它也就越来越不像“对话”,而更像一个需要精确参数的查询接口。
而这,正是我最近最强烈的感受。
一、问题不在于它答不出来,而在于它越来越不“懂你在问什么”
最典型的例子,是时间。
我问一个问题,原本默认语境很明确:我是在问“现在”。
但它给我的回答,却很容易滑向“历史上最相关的那个解释”。
比如我问某场国际冲突的“进展如何”,它并不一定优先理解为“截至今天发生了什么”,而是可能先把这个词匹配到历史上最成熟、最常见、资料最完整的那个旧主题上,然后开始给你讲背景、讲来龙去脉、讲过去几十年的脉络。
这些内容当然不算错。
甚至从知识完整性的角度,它还很认真。
但问题是,我不是来上历史课的。
我问“进展如何”,很多时候其实默认包含的是:
- 截至现在
- 最近发生了什么
- 局势有没有升级
- 有哪些新变化
- 我需要的是动态,不是背景
以前,好的对话式 AI 在某种程度上是能接住这种默认语境的。
现在越来越多的情况是:如果你不把这些全写出来,它就不会主动替你补。
于是你不得不把一句自然问题,改写成一条完整指令:
- 截至今天
- 基于最近72小时
- 只总结最新进展
- 不要历史背景
- 优先新闻和官方通报
这时它往往就答对了。
但这件事本身已经说明了问题:
不是它不能答对,而是它把“理解你”的成本转移给了你。
二、这不是“不会”,而是“更保守了”
从产品角度讲,这种变化其实并不难理解。
一个面向大众的 AI 产品,在经历了早期“什么都敢接、什么都敢答”的阶段之后,往往会逐步进入另一个阶段:尽量稳。
什么叫稳?
就是宁可慢一点、笨一点、钝一点,也不要太激进;
宁可给出安全的旧答案,也不要贸然去赌一个高风险的新判断;
宁可解释一个成熟话题,也不要误解一个当前事件。
从系统设计上看,这样做有很多合理性:
第一,旧资料更稳定。
历史背景、百科条目、成熟专题,信息密度高,冲突少,结构完整,最适合模型总结。
第二,最新信息更危险。
新闻更新快,来源杂,真伪混杂,措辞微妙,一旦答错就容易引发用户不信任。
第三,模糊问题最容易出事。
用户问得越自然,系统需要补的语境越多;补得越多,猜错的风险越大。
于是更保守的系统就会倾向于少猜、少补、少主动做语义延伸。
这在工程上很合理。
但在体验上,副作用也非常明显。
那就是:系统变得更“谨慎”,同时也变得更“不体贴”。
它不再努力理解你想问的“真实问题”,而更倾向于回答它最有把握的“表层问题”。
三、联网搜索也不一定能解决这个问题
很多人会以为,既然开了联网搜索,这类问题就不该存在。
但实际使用下来会发现,联网并不自动等于“理解当前语境”。
因为一个问题从输入到输出,中间至少有几层:
第一层,是意图理解。
系统要先判断:你到底在问背景、问定义,还是问最新进展。
第二层,是检索改写。
系统要把你的自然语言,改写成适合搜索的 query。
第三层,是结果排序。
搜回来的东西里,哪些被认为更可信、更相关、更值得引用。
第四层,是答案生成。
模型会从这些材料里挑选、组织、压缩,形成最后的回答。
这四层里,任何一层保守了,最后的体验都会打折。
最常见的情况就是:
系统虽然联网了,但它没把你的“现在”真正写进搜索里。
你问的是“进展如何”,它内部搜索的却可能只是一个通用概念。
这样搜回来的内容,很可能仍然是旧专题、背景综述、百科化信息,而不是你期待的当下动态。
于是就出现一种很奇怪的结果:
- 它不是没联网
- 也不是没搜索
- 甚至不是完全没找到相关信息
但最后给你的,仍然不是你真正要的那一个答案
这也是为什么很多用户会产生一种非常直观的感觉:
它看起来更强了,但用起来更笨了。
四、真正让人疲惫的,是“你必须像写查询语句一样说话”
对技术人员来说,这种体验很容易被识别出来。
因为我们太熟悉这种系统行为了。
你会发现,自己和 AI 说话时,开始不自觉地做这些事情:
- 提前补上时间锚点
- 说明任务类型
- 明确不要什么
- 指定信息来源
- 规定输出顺序
比如不是问“最近怎么样”,而是问:
“截至今天,基于最近72小时公开信息,总结事件最新进展,先说变化,再补背景,不要展开历史脉络。”
这类提示当然有效。
问题在于,它有效,恰恰说明自然对话失效了。
一段好的对话,本质上应该是系统来承担“语境补全”的工作。
而不是用户先把脑子里的隐含条件全部转成显式参数,再交给系统处理。
换句话说:
真正高级的聊天,不是你说得越像 prompt engineer,它答得越好;而是你说得越像人,它越能接住。
当一个系统越来越依赖用户提供精确参数时,它也许还是一个可用的工具,但已经不再是一个轻松的聊天对象。
而“累”,就是从这里开始的。
五、这不是能力问题,而是交互责任分配问题
我越来越觉得,很多人说某些 AI “变笨了”,其实不一定是在说模型本身的推理能力退化了。
更多时候,他们感受到的是另一件事:
交互责任发生了转移。
以前,系统承担更多理解责任。
它会主动推断你的默认时间、默认任务、默认意图。
现在,系统把这部分责任往回收。
你不说清楚,它就不补;你不限定,它就按最稳妥的方式走;你不显式指定,它就更愿意给你一个保守答案。
这样做的结果是,模型未必真的更差了。
但用户会非常真实地觉得:它变笨了。
因为对用户来说,体验不是由模型参数决定的,
而是由这样一个简单的问题决定的:
我说一句自然话,你到底能不能懂我?
如果答案越来越接近“不能,除非你把条件写全”,那无论底层多么复杂,最终感受到的就只有两个字:费劲。
六、做产品的人,其实最应该警惕这种“看起来没问题”的退化
这类问题的麻烦在于,它不容易在普通指标里暴露出来。
从某些产品指标上看,系统可能仍然很好:
- 回答字数够长
- 表达流畅
- 错误率下降
- 风险内容减少
- 用户没有立即报错
但从真实用户体验上看,问题已经出现了:
- 用户开始反复重写问题
- 用户开始学习“怎么提问才不会跑偏”
- 用户开始形成一套复杂提示模板
- 用户越来越少自然聊天,越来越像在操作接口
这个时候,产品表面上可能更稳定了,
但实际上,它已经在慢慢失去一种最重要的东西:
让用户愿意轻松开口的能力。
对话产品和普通工具最大的不同就在这里。
工具可以要求用户学习用法,
但聊天产品如果总让用户适应它,就会逐渐失去“聊天”的意义。
用户当然可以适应。
尤其是技术用户,通常适应得很快。
但适应,并不等于体验好。
更不等于产品做对了。
七、我并不认为这是不可接受的,只是它提醒了我们:聊天产品最珍贵的,是“低摩擦理解”
说到底,我并不觉得这种变化完全不能接受。
如果你把它视为一个查询引擎、分析工具,甚至一个需要较高提示精度的智能接口,那么补充条件、限定范围、明确时间,本来就是合理的。
问题在于,很多 AI 产品卖给用户的,并不是“高级查询接口”的想象,而是“自然对话伙伴”的想象。
一旦你承诺的是后者,用户对你的要求就不会只是“功能完成”,而会变成:
- 我能不能随口一问
- 你能不能理解我没说出口的那部分
- 你能不能自动抓住当前语境
- 我能不能不用时时刻刻做提示词工程
这也是我最近越来越明确的一种想法:
AI 最难的部分,也许从来不是回答,而是理解。
更准确地说,不是理解字面,而是理解人类在自然对话里默认省略掉的大量上下文。
如果这部分能力退化了,即使它还能答、还能搜、还能组织语言,用户依然会迅速感受到:不顺了。
而一旦“不顺”,聊天就会开始变累。
八、好的 AI,不是让你学会怎么跟它说话,而是它学会怎么接住你
我现在越来越倾向于用一句很简单的话来描述这种变化:
不是 AI 变笨了,而是它把本该由系统承担的理解成本,重新丢回给了用户。
于是我们看见的表面现象就是:
- 你得补日期
- 你得补范围
- 你得补来源
- 你得补格式
- 你得提醒它别跑题
- 你得防止它把“现在”理解成“历史上最相关”
这当然还能用。
但这已经不是最初人们期待的那种聊天了。
真正优秀的对话系统,不是每次都需要用户小心翼翼地把问题包装好,
而是即使用户说得自然、模糊、带省略,它也能尽量沿着人的语境去理解。
因为人类聊天本来就是这样的。
我们从来不会在日常对话里,把所有限定条件都讲完整。
所以从这个角度说,衡量一个 AI 是否“更聪明”,有时不在于它能不能写出更长、更完整、更像样的答案,而在于:
当你像个人一样说话时,它还能不能像个理解你的人一样回应。
这才是聊天产品真正的门槛。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)