Transformer
文章目录
Transformer:Attention is All You Need
Transformer 是在 2017 年的论文《Attention is All You Need》中引入的模型。它完全基于注意力机制:即没有循环或卷积。除了更高的翻译质量外,该模型的训练速度还提高了一个数量级。目前,Transformer(及其变体)不仅在序列到序列任务中,而且在语言建模和预训练设置中都是事实上的标准模型,我们将在下一讲中讨论这些内容。
Transformer 引入了一种新的建模范式:与以前在编码器和解码器内使用循环或卷积进行处理的模型相比,Transformer 仅使用注意力进行操作。

不涉及太多细节,让我们用语言来表达刚才在插图中所看到的内容。我们将得到类似以下的内容:

好的,但是有什么理由说明这比 RNN 更适合语言理解吗?让我们看一个例子。

在编码句子时,RNN 在读完整个句子之前不会理解 bank 的含义,对于长序列来说这可能需要一段时间。相反,在 Transformer 的编码器中,词元同时相互交互。
直观上,Transformer 的编码器可以被认为是一系列的推理步骤(a sequence of reasoning steps,layers 层)。在每一步中,词元互相查看(这就是我们需要注意力——自注意力的地方),交换信息,并尝试在整个句子的上下文中更好地理解彼此。这发生在多个层中(例如,6 层)。
在每个解码器层中,前缀的词元(tokens of the prefix)也通过自注意力机制相互交互,但此外,它们还会查看编码器状态(没有这个,就不会发生翻译,对吧?)。
现在,让我们尝试了解这在模型中究竟是如何实现的。
Self-Attention: the “Look at Each Other” Part
自注意力是该模型的关键组件之一。注意力机制和自注意力机制(self-attention)之间的区别在于,自注意力在相同性质的表示之间进行操作:例如,某一层中的所有编码器状态。

- 解码器-编码器注意力 是从:一个当前解码器状态,查看:所有编码器状态
- 自注意力 是从:一组状态中的每个状态,查看:同一组中的所有其他状态
自注意力是模型中词元相互交互的部分。每个词元通过注意力机制 “查看” 句子中的其他词元,收集上下文,并更新先前的“自我”表示。请看插图。
encoder_self_attention
请注意,在实践中,这是并行发生的。
Query, Key, and Value in Self-Attention
形式上,这种直觉是通过 query-key-value 注意力机制实现的。自注意力中的每个输入词元接收与它可以扮演的角色相对应的三种表示:
- query (查询) - 询问信息;
- key (键) - 表示它有一些信息;
- value (值) - 给出信息。
- 当一个词元查看其他词元时使用 query——它在寻找信息以更好地理解自己。
- key 响应 query 的请求:它用于计算注意力权重。
- value 用于计算注意力输出:它将信息提供给那些“说”需要它的词元(即为该词元分配了高权重)。

计算公式如下:

Masked Self-Attention: “Don’t Look Ahead” for the Decoder
在解码器中,也有一个自注意力机制:它是执行 “查看前面词元” 功能的机制。
解码器中的自注意力与编码器中的有点不同。
- 编码器一次接收所有词元,并且词元可以查看输入句子中的所有词元;
- 而在解码器中,我们一次生成一个词元:在生成过程中,我们不知道未来将生成哪些词元。
为了禁止解码器向前看,模型使用了掩蔽自注意力:未来的词元被掩蔽掉了。请看插图。
But how can the decoder look ahead?
在生成过程中,它不能向前看,我们不知道接下来会出现什么。但在训练中,我们使用reference translations(我们是知道的)。因此,在训练中,我们将整个目标句子输入给解码器——如果没有掩蔽,词元将“看到未来”,而这不是我们想要的。
我们之所以需要 Mask,完全是因为 Transformer 在训练时“为了图快,一次性塞入了全部答案”。如果不加 Mask 人为地遮挡住未来的词,模型就会在训练时养成“偷看答案”的坏毛病,导致它在生成阶段时啥也不会
这样做是为了提高计算效率:Transformer 没有循环结构,因此所有的词元都可以被一次性同时处理。这也是它在机器翻译领域变得如此受欢迎的原因之一——它的训练速度比曾经占据主导地位的循环模型要快得多。对于循环模型来说,完成一个训练步骤需要 O ( len(source) + len(target) ) O(\text{len(source)} + \text{len(target)}) O(len(source)+len(target)) 步,但对于 Transformer 而言,时间复杂度为 O ( 1 ) O(1) O(1) ,即常数级别的步数。
Multi-Head Attention: Independently Focus on Different Things
通常,理解一个单词在句子中的作用需要理解它与句子不同部分之间的关系。这不仅在处理源句子时很重要,在生成目标句子时也很重要。例如,在某些语言中,主语决定了动词的变化(verb inflection,例如,性别一致),动词决定了其宾语的格,等等。我想说的是:每个单词都是许多关系的一部分。
因此,我们必须让模型关注不同的事物:这就是多头注意力背后的动机。多头注意力没有采用单一的注意力机制,而是有几个独立工作的“头”。
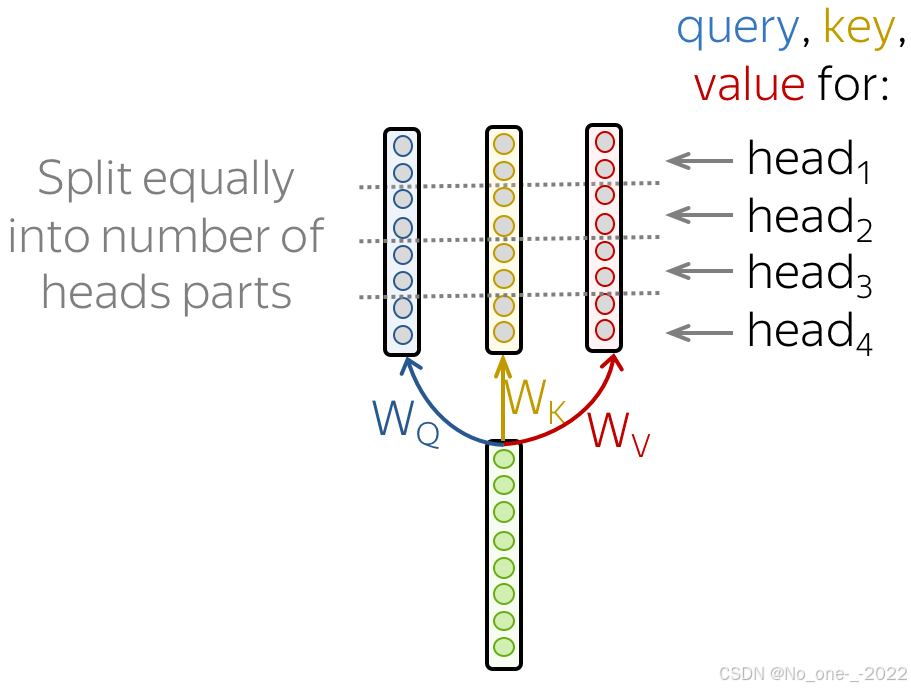
形式上,这被实现为几个注意力机制,它们的结果被拼接组合在一起:
MultiHead ( Q , K , V ) = Concat ( head 1 , … , head n ) W o \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_n)W_o MultiHead(Q,K,V)=Concat(head1,…,headn)Wo
head i = Attention ( Q W Q i , K W K i , V W V i ) \text{head}_i = \text{Attention}(QW_Q^i, KW_K^i, VW_V^i) headi=Attention(QWQi,KWKi,VWVi)
在实现中,你只需将为单头注意力计算的查询、键和值拆分成几个部分。这样一来,具有一个注意力头或多个注意力头的模型大小相同——多头注意力并不会增加模型的大小。
Transformer: Model Architecture
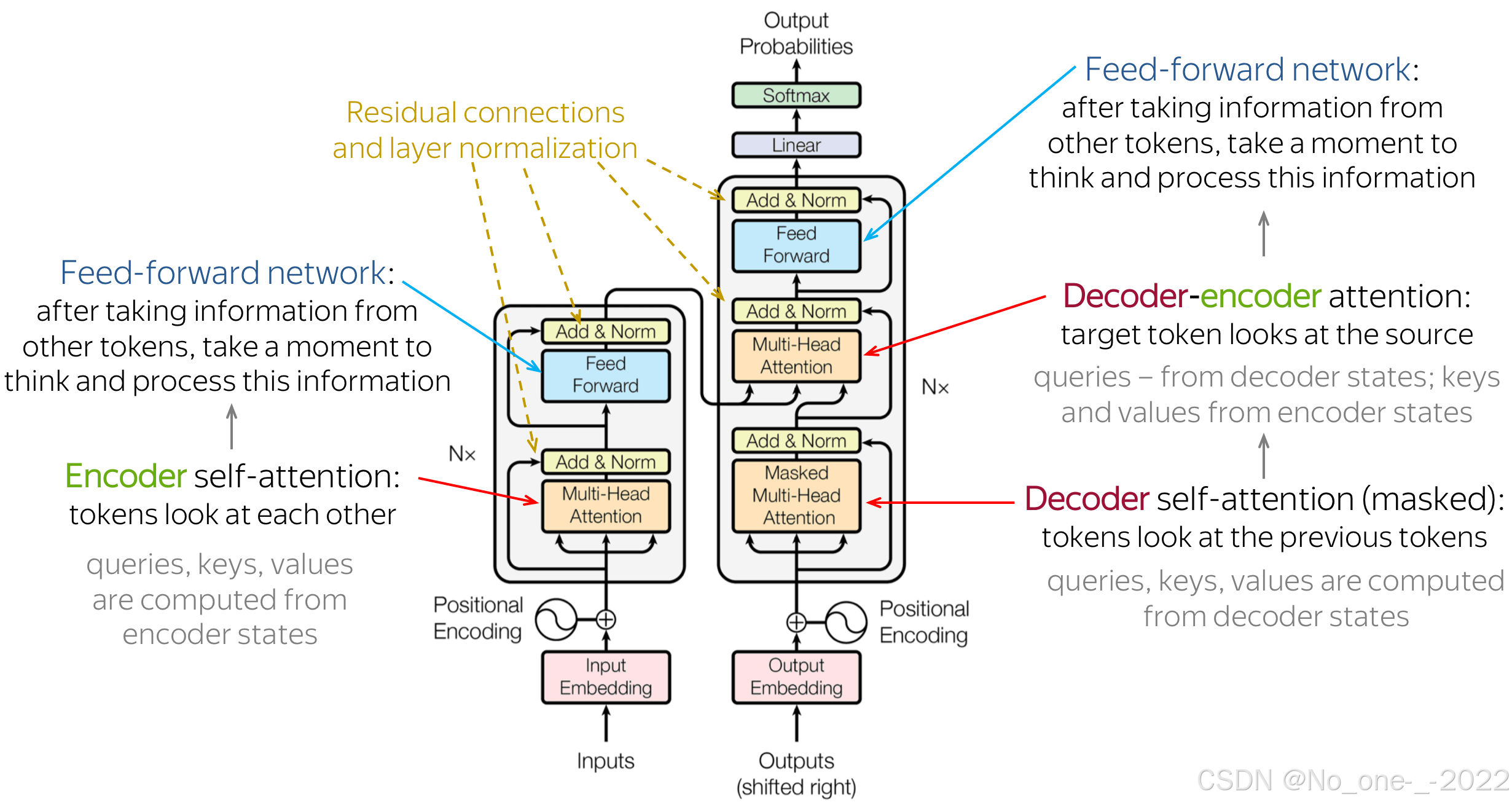
直观上,模型完全按照我们之前讨论的执行:在编码器中,词元相互交流并更新它们的表示;在解码器中,目标词元首先查看先前生成的目标词元,然后查看源句子,最后更新其表示。这发生在多个层中,通常是 6 层。
让我们更详细地看看其他模型组件。
前馈块 (Feed-forward blocks)
除了注意力机制之外,每一层都有一个前馈网络块:两个线性层,中间带有 ReLU 非线性激活:
F F N ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x) = \max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
在通过注意力机制查看其他词元之后,模型使用 FFN 块来处理这些新信息(注意力——“查看其他词元并收集信息”,FFN——“花点时间思考并处理这些信息”)。

残差连接 (Residual connections)
在讨论卷积语言模型时,我们已经看到过残差连接。残差连接非常简单(将块的输入加到其输出上),但同时非常有用:它们促进了网络中的梯度流动,并允许堆叠大量的层。
在 Transformer 中,残差连接在每个注意力和 FFN 块之后使用。在上面的插图中,残差显示为绕过一个块到达黄色“Add & Norm”层的箭头。在“Add & Norm”部分中,“Add”代表残差连接。

层归一化 (Layer Normalization)
“Add & Norm”层中的“Norm”部分表示层归一化。它独立地对批次中每个示例的向量表示进行归一化——这样做是为了控制到下一层的“流”。层归一化提高了收敛稳定性,有时甚至能提升质量。
在 Transformer 中,你必须对每个词元的向量表示进行归一化。此外,这里的 LayerNorm 具有可训练的参数 s c a l e scale scale 和 b i a s bias bias ,这些参数在归一化后用于重新缩放层的输出(或下一层的输入)。请注意, μ k \mu_k μk 和 σ k \sigma_k σk 是为每个示例分别评估的,但 s c a l e scale scale 和 b i a s bias bias 是相同的,它们是层参数。

位置编码 (Positional encoding)
请注意,由于 Transformer 不包含循环或卷积,因此它不知道输入词元的顺序。因此,我们必须让模型显式地知道词元的位置。为此,我们有两组嵌入(two sets of embeddings):
- 用于词元的嵌入(像往常一样)和
- 用于位置的嵌入(此模型需要的新嵌入)。
然后,一个词元的输入表示就是这两种嵌入的总和:词元嵌入和位置嵌入(token and positional)。
位置嵌入是可以学习的,但作者发现使用固定的位置嵌入并不会损害质量。Transformer 中使用的固定位置编码是:
P E p o s , 2 i = sin ( p o s / 10000 2 i / d m o d e l ) PE_{pos, 2i} = \sin(pos / 10000^{2i/d_{model}}) PEpos,2i=sin(pos/100002i/dmodel) P E p o s , 2 i + 1 = cos ( p o s / 10000 2 i / d m o d e l ) PE_{pos, 2i+1} = \cos(pos / 10000^{2i/d_{model}}) PEpos,2i+1=cos(pos/100002i/dmodel)
其中 p o s pos pos 是位置, i i i 是向量维度。位置编码的每个维度对应一个正弦波,并且波长形成一个从 2 π 2\pi 2π 到 10000 ⋅ 2 π 10000 \cdot 2\pi 10000⋅2π 的等比数列。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)