基于生产者-消费者模型+环形缓冲区的数据流解耦
目录
一、串口组件开发的基础:持续数据流
为了在后续实现各种高性能组件,我们首先需要把单片机端改为持续发送数据;而Linux上位机端改成循环读取数据。
(1)8051单片机侧:从单次发送到循环数据流
8051侧我暂时只是用软件模拟数据,在后期可能替换成真实的传感器数据采集。目前我们仅考虑把整个通路跑通即可。

这里使用了一个无符号char类型暂存每次要发送的起始编号,由于unsigned char最高只有255,即0xFF,当超过这个之后会发生溢出截断,使得下一次++后仍然是从0开始,直到255结束。这种方法有点取巧,你当然可以直接在每次到达255之后手动置零,我这里就不改了。
还有一个关键点是:主函数修改temp的速率远高于串口一次发完16字节数据的速率,所以必须保证temp发完了后再使得start_val+=16,否则会造成数据混乱。一般来说可以使用标志位实现,但是这里我为了快速验证是不是这个原因,直接加了延时函数测试。
#include <reg52.h>
#include <stdio.h>
// 全局变量定义(补充缺失的关键变量)
bit recv_error_flag = 0; // 接收校验错误标志(备用)
//全局接收缓冲区
unsigned char recv_buf[16]; // 接收缓冲区
unsigned char recv_idx = 0; // 接收索引
unsigned char send_idx = 0; // 发送索引
// 全局发送缓冲区(由于这里只能写C,不能使用STL容器,很遗憾)(sdcc、keil-C51、51单片机本身都不是很支持C++,最好在stm32中再尝试 )
unsigned char send_buf[16];
unsigned char send_len = 0;
// 函数声明
bit calc_even_parity(unsigned char datas);
void UART_Init(void);
void Creat_And_Send_Datas(unsigned char *datas, unsigned char len);
void Read_Datas(unsigned char byte);
// 奇偶校验函数(已修正参数名,避免关键字冲突)
bit calc_even_parity(unsigned char datas)
{
unsigned char count = 0;
unsigned char i;
// 统计数据中1的个数
for (i = 0; i < 8; i++)
{
if (datas & (1 << i))
{
count++;
}
}
// 偶校验:如果1的个数是偶数,校验位为0;如果是奇数,校验位为1
return (count % 2);
}
// 串口初始化函数
void UART_Init()
{
// 1.PCON、SCON配置(波特率加倍+9位帧+允许接收)
SCON |= 0xD0; // SM0=1,SM1=1,REN=1(方式3、允许接收)
PCON |= 0x80; // SMOD=1(波特率加倍)
// 2.定时器1配置为8位自动重载(9600bps)
TMOD |= 0x20; // 定时器1模式2
TL1 = 0xFD; // 重装值 //FA=9.6k;FD=19.2k;FE=57.6;FF=115.2k
TH1 = 0xFD;
ET1 = 0; // 关闭定时器1中断(波特率发生器无需中断)
// 3.中断配置
ES = 1; // 开启串口中断(关键!否则中断服务函数不执行)
EA = 1; // 开启总中断
TR1 = 1; // 启动定时器1
}
// 数据的构造与发送函数
void Creat_And_Send_Datas(unsigned char *datas, unsigned char len)
{
unsigned char i;
send_len = len;
send_idx = 0; // 重置发送索引,避免续发错乱
for (i = 0; i < len; i++)
{
send_buf[i] = datas[i];
}
// 启动发送:先发送第一个字节
if (send_len > 0)
{
TB8 = calc_even_parity(send_buf[0]);
SBUF = send_buf[0];
}
}
// 接收数据函数
void Read_Datas(unsigned char byte)
{
//将接收的数据存入缓冲区
if (recv_idx < 16)
{
recv_buf[recv_idx++] = byte;
}
}
// 串口中断服务函数
unsigned char recv_byte;
bit calc_parity;
void UART_ISR() interrupt 4
{
// 读中断处理
if (RI)
{
RI = 0;
// 读取数据
recv_byte = SBUF;
// 奇偶校验
calc_parity = calc_even_parity(recv_byte);
if (calc_parity != RB8)
{
// recv_error_flag = 1; // 暂时先不设置错误码
}
else
{
Read_Datas(recv_byte);
}
}
// 写中断处理(补充自动续发逻辑)
if (TI)
{
TI = 0;
send_idx++; // 索引+1,准备发送下一字节
// 判断是否还有数据未发送
if (send_idx < send_len)
{
TB8 = calc_even_parity(send_buf[send_idx]);
SBUF = send_buf[send_idx]; // 自动发送下一字节
}
}
}
void Delay100ms() //@11.0592MHz
{
unsigned char i, j;
i = 180;
j = 73;
do
{
while (--j);
} while (--i);
}
// 主函数(修正变量定义位置,符合C51语法)
void main()
{
// 变量定义必须放在函数体最前面(C51语法要求)
unsigned int i;
unsigned char temp[16];
unsigned char start_val=0;//记录每次循环开始发送的值
UART_Init();
while(1)
{
// 构造测试数据:100~115(共16字节)
for(i=0; i<16; i++)
{
temp[i] =start_val+i;
}
//更新start_val
start_val+=16;
// 发送16字节测试数据
Creat_And_Send_Datas(temp, 16);
//软件延时,防止main跑太快而串口跟不上(因为我们的逻辑是先把数据缓存到temp缓冲区中,然后在每次循环的时候把temp的数据拿出来由串口发送,
//但是串口发送一组16字节大概要8ms,而主函数修改temp时间是远远小于8ms的,所以出现了一个情况:temp第一次刚刚发到中间,主函数就修改了temp,所以下一次发送的不是连贯的数据了)
//而主动加上软件延时,是相当于让主函数修改temp缓冲区的时间延长成100ms,这个时间是完全足够串口发完16字节数据的。
Delay100ms();
}
}注意:这里我改成了用VSCode中的插件EIDE编写代码,ui更美观。但是由于EIDE使用的是sdcc编译器,所以有一些头文件、宏定义可能与keil-C51编译器不一样,需要针对报错修改一下。比如种类的头文件是reg52.h,而之前在keil-C51中则是regx52.h。
(2)Linux上位机侧:从单次接收到持续接收
Linux端就是基础的文件read操作,而read本身就是阻塞读取的,所以只需在外层增加while循环即可实现持续读取操作。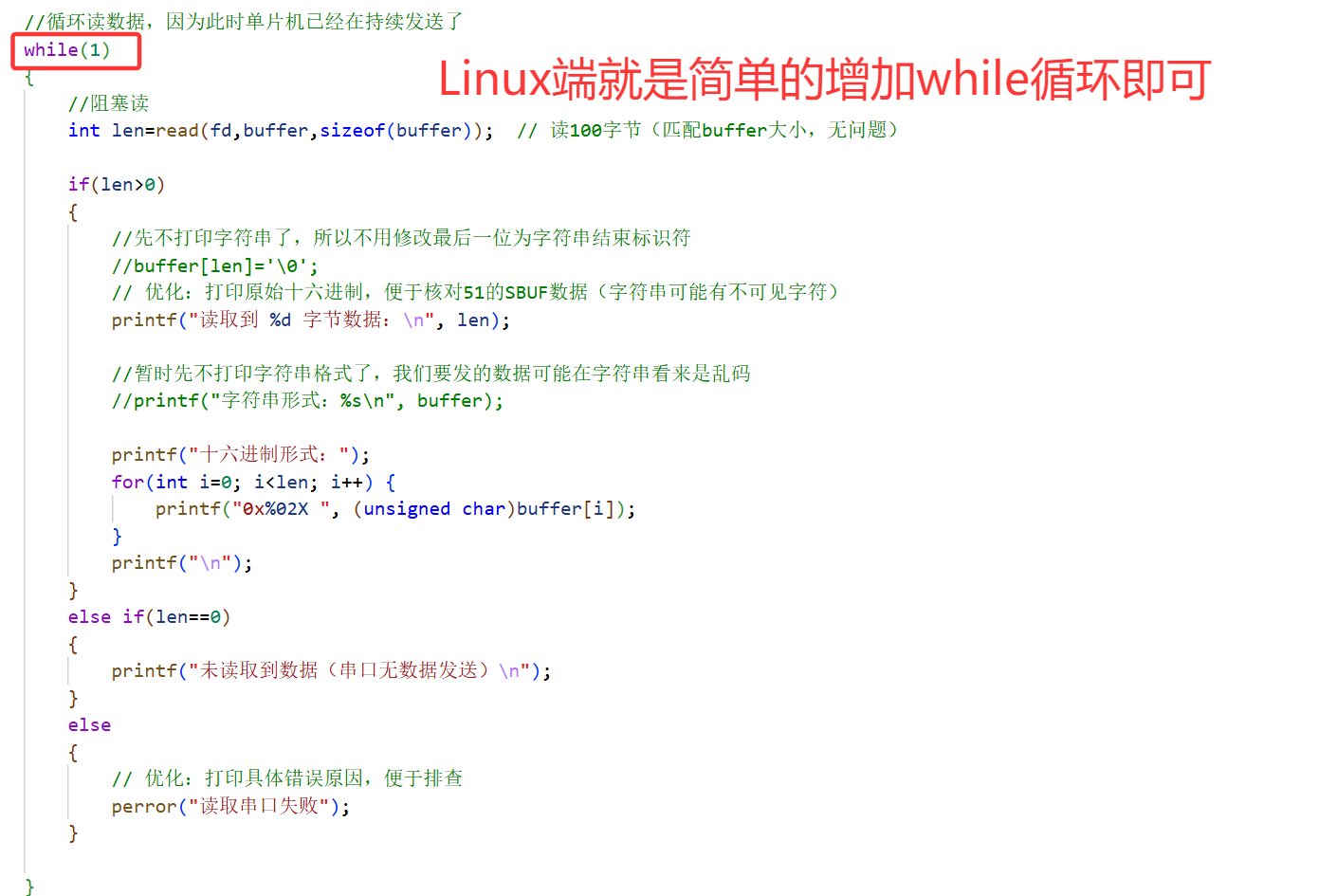
#include<fcntl.h>
#include<unistd.h>
#include<stdio.h>
#include<errno.h>
#include<termios.h>
#include<string.h>
//配置termios中参数的函数
int configure_uart(int fd) {
struct termios uart_cfg;
struct termios old_cfg;
// 1. 获取当前串口配置(保存原始配置,用于程序退出时恢复)
if (tcgetattr(fd, &old_cfg) != 0) {
perror("tcgetattr get old config failed");
return -1;
}
// 2. 清空新配置结构体,避免脏数据
memset(&uart_cfg, 0, sizeof(struct termios));
// 3. 核心配置:c_cflag(硬件层,11位帧格式关键)
uart_cfg.c_cflag |= CLOCAL; // 本地模式,忽略Modem状态线(嵌入式必开)
uart_cfg.c_cflag |= CREAD; // 启用接收器(必须开,否则收不到数据)
uart_cfg.c_cflag &= ~CSIZE; // 清空数据位掩码,准备设置8位数据位
uart_cfg.c_cflag |= CS8; // 设置8位数据位
uart_cfg.c_cflag |= PARENB; // 启用奇偶校验(关键:开启后才会有校验位)
uart_cfg.c_cflag &= ~PARODD; // 偶校验(PARODD=1是奇校验,清0是偶校验)
uart_cfg.c_cflag &= ~CSTOPB; // 1位停止位(CSTOPB=1是2位,清0是1位)
// 注:起始位由硬件自动处理,无需配置;11位帧=1起始+8数据+1校验+1停止
// 4. 设置波特率19200(输入/输出波特率一致)
if (cfsetispeed(&uart_cfg, B19200) != 0 || cfsetospeed(&uart_cfg, B19200) != 0) {
perror("set baud rate 19200 failed");
return -1;
}
// 5. 关闭所有数据转换(嵌入式裸传需求,和你要求的清零逻辑一致)
uart_cfg.c_iflag = 0; // 关闭输入转换(奇偶校验由硬件处理,软件不干预)
uart_cfg.c_oflag = 0; // 关闭输出转换
uart_cfg.c_lflag = 0; // 关闭人机交互(回显、规范模式等)
// 6. 配置非规范模式读取规则(嵌入式常用)
uart_cfg.c_cc[VMIN] = 1; // 最少读取1个字节就返回(实时性优先)//阻塞读取
uart_cfg.c_cc[VTIME] = 50; // 超时时间0.5秒(避免无限等待,可根据需求调整)
// 7. 应用配置(TCSANOW:立即生效;TCSAFLUSH:清空缓冲区后生效,可选)
if (tcsetattr(fd, TCSANOW, &uart_cfg) != 0) {
perror("tcsetattr apply config failed");
// 应用配置失败才会走到这里:恢复原始配置
tcsetattr(fd, TCSANOW, &old_cfg);
return -1;
}
printf("UART配置成功:19200波特率、8数据位、偶校验、1停止位(11位帧)\n");
return 0;
}
int main()
{
int fd=open("/dev/ttyUSB0",O_RDWR | O_NOCTTY);
if(fd==-1)
{
perror("打开串口失败");
//打开失败后直接退出,避免后续操作无效fd
return -1;
}
//配置串口信息
configure_uart(fd);
// 读取串口信息:原代码仅读1次,无阻塞/循环,大概率读不到数据
char buffer[100];
// 补充:打印提示,告知用户程序在等待数据
printf("等待51单片机发送数据...\n");
//循环读数据,因为此时单片机已经在持续发送了
while(1)
{
//阻塞读
int len=read(fd,buffer,sizeof(buffer)); // 读100字节(匹配buffer大小,无问题)
if(len>0)
{
//先不打印字符串了,所以不用修改最后一位为字符串结束标识符
//buffer[len]='\0';
// 优化:打印原始十六进制,便于核对51的SBUF数据(字符串可能有不可见字符)
printf("读取到 %d 字节数据:\n", len);
//暂时先不打印字符串格式了,我们要发的数据可能在字符串看来是乱码
//printf("字符串形式:%s\n", buffer);
printf("十六进制形式:");
for(int i=0; i<len; i++) {
printf("0x%02X ", (unsigned char)buffer[i]);
}
printf("\n");
}
else if(len==0)
{
printf("未读取到数据(串口无数据发送)\n");
}
else
{
// 优化:打印具体错误原因,便于排查
perror("读取串口失败");
}
}
close(fd);
return 0;
}最后的结果也是符合预期的:从0读取到255,然后一直循环这个过程。

为什么我们的缓冲区是100字节,但是read每次都只会读取到16字节数据呢?
其实是因为Linx内核中的串口驱动程序决定的,由于在8051发送端一次只发送了16字节数据,且每次发送完成后睡眠休息100ms,而Linux端可能几十ms就返回给应用层了,所以每次read都只拿到16字节数据。
二、环形缓冲区+多线程
(1)为什么需要应用层缓冲区+消费者生产者解耦?
1.1 一次失败的实验
前面我们已经能做到让单片机一直发送数据,而Linux上位机循环读取的操作。但仅仅这样是不够的,在未来我们可能需要给串口消息加入帧头帧尾等格式,需要文件操作写入日志,还可能将数据通过网络发送出去,这些都是比较费时的操作,一旦任意一个环节卡住,我们目前的单线程读+处理就无法适用了,会使得大量串口数据丢包、网络服务器长时间监测不到硬件数据等问题诞生。
最开始我的想法是让Linux在某个时间突然睡眠几秒钟,使得串口发送的数据快速填满缓冲区,但是很快实践发现问题:Linux的串口缓冲区较大,默认为64KB(Ubuntu24.04版本),而且无法通过命令修改大小,于是我在单片机侧将发送延时减小到50ms。

经过多种延时策略的测试,发现串口数据并没有按照预期的跳变,于是我查询了一下相关资料: 主要是因为这里我们使用的是串口转USB接口,蕴含了CH340驱动,而这个驱动早就已经实现了流量控制等等,所以只要CH340是正常的,永远都看不到数据跳变。
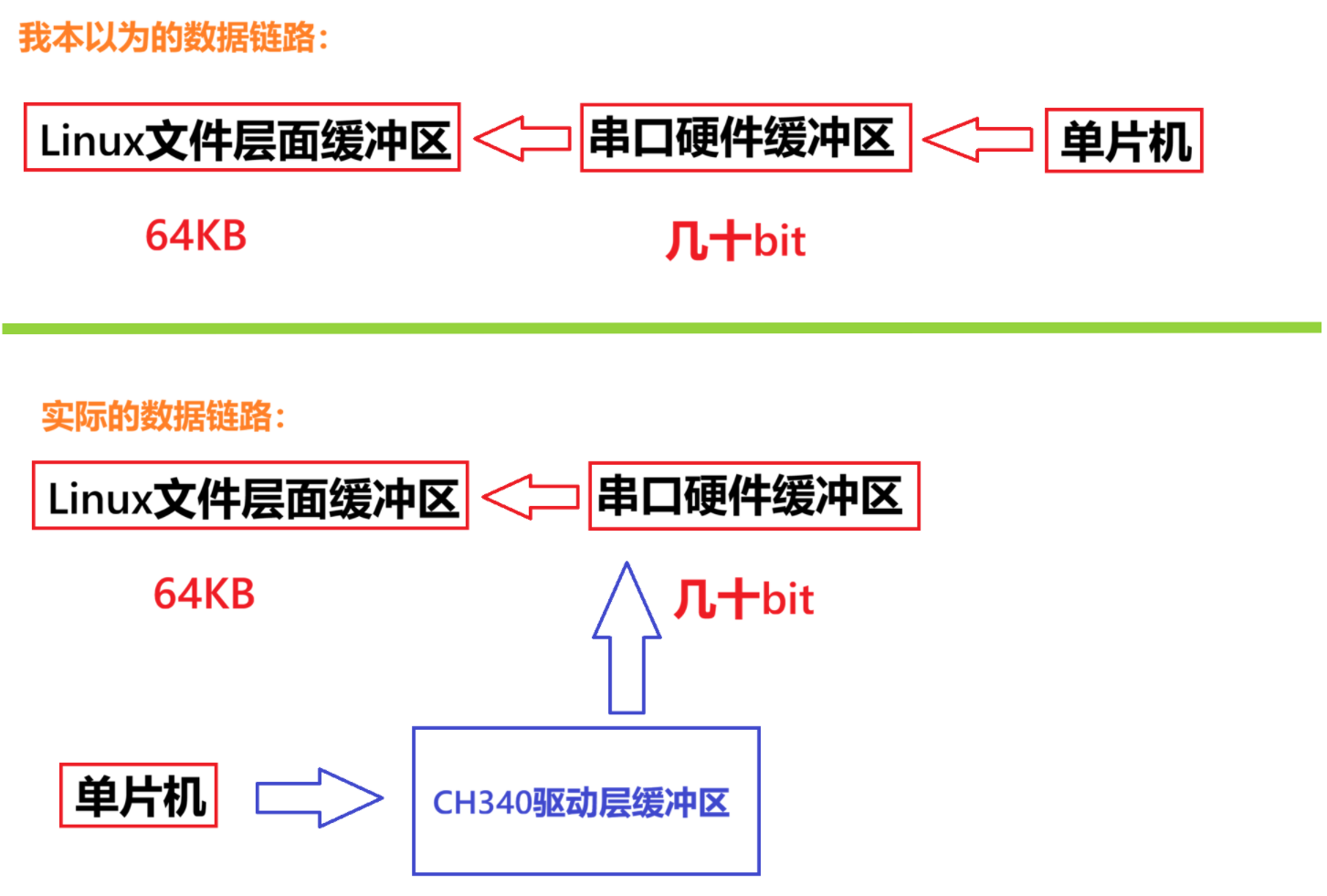
当CH340驱动层缓冲区满了后,会由硬件流控部分向单片机侧发送暂停发送信号(纯硬件,程序员感知不到),从而导致数据始终连贯无跳变。
1.2 消费者-生产者模型的引入
看似驱动层的流控设计已经完美解决了应用层速度小于单片机发送的问题,但这只是缓兵之计,如果你的网络崩溃,长时间卡死,比如9.00am卡住了,10.00am才修好网络,那么这中间一个小时的串口数据都没有监测到,数据大量丢失;再比如应用层处理数据的速度长期小于串口发送的数据(假设800BPS/1200BPS),那么流控的存在使得单片机侧速度强行降低到800BPS,传递到Linux的是高延迟的历史数据,实时性下降。
最为致命的问题是:目前的代码是单线程逻辑,处理和读取都在同一个循环中进行,网络稍微波动一下就能影响上传数据的速度,而如果引入消费者-生产者模型,让读取串口和应用层处理解耦,则能起到削峰填谷的作用,让网络服务器平滑的监测串口实时数据。
单线程的问题:
- 强耦合:读取串口数据和应用层处理(解析、日志、网络上传)是串行执行的。
- 多米诺骨牌效应:任何一个环节(比如网络波动、日志写入卡顿)都会阻塞整个循环,导致串口数据无法及时读取。
- 数据堆积与丢失:一旦读取被阻塞,CH340 缓冲区满,流控触发,单片机停发,最终导致数据丢失或实时性下降。
(2)环形缓冲区的各成员分析
首先由于缓冲区需要作为媒介,将数据在多个线程之间交换,那么缓冲区本身一定是属于进程中各线程公共的资源,只有两种可能:全局数组、堆中申请的内存块。那么这里我为了后续方便扩容等操作,选择使用malloc申请大块内存。当然,既然学过C++,那么还可以使用更优雅的vector容器,简单高效。
其次,缓冲区是一个临界资源,各线程都有访问它的可能,所以需要让不同线程互斥访问,即引入互斥锁的概念,防止读写同时进行造成数据混乱。理论上来说应该使用RAII思想对互斥锁进行封装,自动管理声明周期从而方式忘记解锁导致的死锁问题,但我这个项目中暂时只有两个线程,所以直接使用Linux原生的锁操作即可。
最后,仅仅只有互斥锁是不够的,这样可能导致效率低下的问题。比如消费者消耗的速率远低于生产者(符合上述网络卡顿问题),此时极易造成环形缓冲区占满,而消费者无法写入数据。
比如下面这种代码,仅仅只有互斥锁的存在,使得每次生产者都被调度器放入CPU运行,而一运行却发现缓冲区没有空间,又释放锁回去歇着了。至此在整个时间片内陷入自旋锁类似的忙等待问题。(可以阅读我本专栏的上一篇文章,里面详细分析了互斥锁、条件变量的优缺点,以及在消费者、生产者模型中我们该如何使用)
// 生产者伪代码
while(1) {
加锁();
if (缓冲区有空间---通过容量和队列中的数据数量相当比较判断) {
写数据();
} else {
解锁(); // 先释放锁,不然别人连锁都拿不到
usleep(10000); // 睡10毫秒
}
}总结一下:环形缓冲区需要4个基本成员:读、写两个指针;互斥锁;条件变量。
(3)环形缓冲区的示例代码
这是我手写的一份使用vector为容器的环形缓冲区,后续文章都将以此为基础组件。
//环形缓冲区是应用层的,用于生产者、消费者线程之间的稳定波动作用
#include<vector>
#include<pthread.h>
#include<string.h>
#include <algorithm>
#include<stdio.h>
class Ring_Buffer
{
public:
//构造函数
Ring_Buffer()
{
//降低后续扩容的可能--8kb
_buffer.reserve(8192);
//将下标访问[]的范围扩展,否则reserve扩容只适用于push_back,而[]只认resize
_buffer.resize(8192);
//初始时刻,没有数据,数据量为0
_now_size=0;
//初始时刻读写指针都在0位置
_read_pos=_write_pos=0;
//初始化互斥锁和条件变量
pthread_mutex_init(&_mutex,nullptr);
pthread_cond_init(&_not_empty,nullptr);
pthread_cond_init(&_not_full,nullptr);
}
//析构函数
~Ring_Buffer()
{
//销毁互斥锁、条件变量
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_not_empty);
pthread_cond_destroy(&_not_full);
}
//缓冲区写入数据(生产者调用功能)
size_t push(const char* datas,size_t len)
{
//空指针检测,防止后续对空指针进行操作,程序崩溃
if(datas==nullptr||len<=0)
{
return 0;
}
//要访问公共临界资源,必须得有锁保护
pthread_mutex_lock(&_mutex);
//按照逻辑来说,应该是判断缓冲区是否有空位生产,使用if,但是我们前面分析了要使用while
//如果满了没有空位,就挂起自己并同步释放锁
while(is_full())
{
//wait只要返回了,就表示他已经竞争到锁了,然后才进行条件判断
pthread_cond_wait(&_not_full,&_mutex);
}
//走到这里说明既有空位写,又竞争到的了互斥锁
//1.计算当前可写的最大容量
size_t now_capacity=_buffer.capacity()-_now_size; //关于这种数组越界问题,最好自己在草稿纸上画图验证一下,到底需不需要+1-1
//2.比较得到本次真实要写入的数量
size_t write_len=std::min(now_capacity,len);
//3.写入环形缓冲区
//情况1:直接顺着往后写,不会绕圈
if(_write_pos+write_len<=_buffer.capacity())
{
memcpy(&_buffer[_write_pos],datas,write_len);
//更新写指针
_write_pos+=write_len;
}
//情况2:顺着写不下了,必须要绕圈从头继续写
else
{
//1.先写一部分
size_t part1_number=_buffer.capacity()-_write_pos; //关于这种数组越界问题,最好自己在草稿纸上画图验证一下,到底需不需要+1-1
memcpy(&_buffer[_write_pos],datas,part1_number);
//2.再写第二部分(绕圈回头的部分)
size_t part2_number=write_len-part1_number;
memcpy(&_buffer[0],datas+part1_number,part2_number);
//3.最终更新写指针
_write_pos=part2_number;
}
//更新当前总数据量
_now_size+=write_len;
//写完之后唤醒一个条件变量下挂起的线程(避免使用广播)
pthread_cond_signal(&_not_empty);
//解锁
pthread_mutex_unlock(&_mutex);
return write_len;
}
//缓冲区读取数据(消费者使用)
size_t pop(char* out_buf,size_t len)
{
//防止接收缓冲区为空指针的崩溃,所以直接返回
if(out_buf==nullptr||len<=0)
{
return 0;
}
//要访问公共临界资源,必须得有锁保护
pthread_mutex_lock(&_mutex);
//判断条件变量是否满足
while(is_empty())
{
//如果条件变量不满足(缓冲区为空,无法读)则挂起,释放锁
pthread_cond_wait(&_not_empty,&_mutex);
}
//走到这里说明:条件判断满足了,且获取到了锁
//1.计算当前可读的最大容量
size_t now_capacity=_now_size;
//2.比较期望读取数量和当前可读容量,取得最小值
size_t read_len=std::min(now_capacity,len);
//3.从缓冲区中读取数据
//情况1:直接读取,不会经过尾巴跳转
if(read_len+_read_pos<=_buffer.capacity())
{
memcpy(out_buf,&_buffer[_read_pos],read_len);
//更新读指针
_read_pos+=read_len;
}
//情况2:经过了末尾,需要分两次读取
else
{
//1.先读第一部分
size_t part1_number=_buffer.capacity()-_read_pos;
memcpy(out_buf,&_buffer[_read_pos],part1_number);
//2.再从头读第二部分
size_t part2_number=read_len-part1_number;
memcpy(out_buf+part1_number,&_buffer[0],part2_number);
//更新读指针
_read_pos=part2_number;
}
//更新当前总数据量
_now_size-=read_len;
//读完之后,唤醒生产者(同样需要避免广播)
pthread_cond_signal(&_not_full);
//解锁
pthread_mutex_unlock(&_mutex);
return read_len;
}
//判断缓冲区是否为满(是否有位置写入)
bool is_full()
{
//当read指针和write指针走完一圈重合时,既表示空又表示满,所以不能这样判断
// return _read_pos==_write_pos;
return _now_size==_buffer.capacity();
}
//判断缓冲区是否为空(是否可以继续消费)
bool is_empty()
{
return _now_size==0;
}
private:
std::vector<char> _buffer; //缓冲区
size_t _read_pos; //读指针
size_t _write_pos; //写指针
size_t _now_size; //当前已存数据量(消费者还能拿多少出去)
pthread_mutex_t _mutex; //互斥锁
pthread_cond_t _not_empty; //未空条件变量(用于阻塞消费者)
pthread_cond_t _not_full; //未满条件变量(用于阻塞生产者)
};(4)消费者、生产者的示例代码
前面我们已经分析出:Linux上位机想要平滑各种模块的延迟(不确定性),需要引入应用层环形缓冲区+消费者生产者模型,于是这一部分我们主要实现多线程方面的代码。
#pragma once
#include"Ring_Buffer.hpp"
#include<pthread.h>
#include<fcntl.h>
#include<unistd.h>
#include<stdio.h>
#include<errno.h>
#include<termios.h>
#include<string.h>
#include <sys/ioctl.h>
//由于使用pthread_create创建线程的时候,需要两个关键参数:void*类型的参数指针、void*类型的返回值(二者组成一个函数指针),线程的执行流函数。
//而我们前面写的RingBuffer里面的pop、push函数就不是很适配了,所以我们需要在外增加一层包裹适配层
//整个框架是这样的:
//main函数只负责开两个线程,然后这两个线程共享同一个环形缓冲区。其中生产者负责从串口读取数据填入缓冲区;消费者负责从缓冲区读取数据处理
//配置termios中参数的函数
int configure_uart(int fd) {
struct termios uart_cfg;
struct termios old_cfg;
// 1. 获取当前串口配置(保存原始配置,用于程序退出时恢复)
if (tcgetattr(fd, &old_cfg) != 0) {
perror("tcgetattr get old config failed");
return -1;
}
// 2. 清空新配置结构体,避免脏数据
memset(&uart_cfg, 0, sizeof(struct termios));
// 3. 核心配置:c_cflag(硬件层,11位帧格式关键)
uart_cfg.c_cflag |= CLOCAL; // 本地模式,忽略Modem状态线(嵌入式必开)
uart_cfg.c_cflag |= CREAD; // 启用接收器(必须开,否则收不到数据)
uart_cfg.c_cflag &= ~CSIZE; // 清空数据位掩码,准备设置8位数据位
uart_cfg.c_cflag |= CS8; // 设置8位数据位
uart_cfg.c_cflag |= PARENB; // 启用奇偶校验(关键:开启后才会有校验位)
uart_cfg.c_cflag &= ~PARODD; // 偶校验(PARODD=1是奇校验,清0是偶校验)
uart_cfg.c_cflag &= ~CSTOPB; // 1位停止位(CSTOPB=1是2位,清0是1位)
// 注:起始位由硬件自动处理,无需配置;11位帧=1起始+8数据+1校验+1停止
// 4. 设置波特率19200(输入/输出波特率一致)
if (cfsetispeed(&uart_cfg, B19200) != 0 || cfsetospeed(&uart_cfg, B19200) != 0) {
perror("set baud rate 19200 failed");
return -1;
}
// 5. 关闭所有数据转换(嵌入式裸传需求,和你要求的清零逻辑一致)
uart_cfg.c_iflag = 0; // 关闭输入转换(奇偶校验由硬件处理,软件不干预)
uart_cfg.c_oflag = 0; // 关闭输出转换
uart_cfg.c_lflag = 0; // 关闭人机交互(回显、规范模式等)
// 6. 配置非规范模式读取规则(嵌入式常用)
uart_cfg.c_cc[VMIN] = 1; // 最少读取1个字节就返回(实时性优先)//阻塞读取
uart_cfg.c_cc[VTIME] = 50; // 超时时间0.5秒(避免无限等待,可根据需求调整)
// 7. 应用配置(TCSANOW:立即生效;TCSAFLUSH:清空缓冲区后生效,可选)
if (tcsetattr(fd, TCSANOW, &uart_cfg) != 0) {
perror("tcsetattr apply config failed");
// 应用配置失败才会走到这里:恢复原始配置
tcsetattr(fd, TCSANOW, &old_cfg);
return -1;
}
printf("UART配置成功:19200波特率、8数据位、偶校验、1停止位(11位帧)\n");
return 0;
}
// 实时获取内核缓冲区待读取字节数
int get_kernel_buf_used(int fd) {
int bytes_available = 0;
// FIONREAD:核心接口,获取缓冲区待读字节数
if (ioctl(fd, FIONREAD, &bytes_available) < 0) {
perror("ioctl FIONREAD failed");
return -1;
}
return bytes_available;
}
//生产者线程函数
//这里我们传递进去的就是强转后的环形缓冲区RingBuffer指针
void* productor_thread_func(void* arg)
{
//将其强转回来
Ring_Buffer* Rb=(Ring_Buffer*)arg;
//生产者线程负责:打开串口文件,配置串口termios各种参数
int fd=open("/dev/ttyUSB0",O_RDWR | O_NOCTTY);
if(fd==-1)
{
perror("打开串口失败");
//打开失败后直接退出,避免后续操作无效fd
return (void*)-1;
}
//配置串口信息
configure_uart(fd);
printf("等待51单片机发送数据,最多等待5s...\n");
//进入持续从单片机读取数据的循环逻辑(将读取到的数据写入环形缓冲区)
while(1)
{
//先read读到buffer里面,再写入环形缓冲区
char buffer[512]={0};
size_t len=read(fd,buffer,sizeof(buffer));
//正常读取到数据,写入环形缓冲区
if(len>0)
{
ssize_t real_push_len=Rb->push(buffer,len);
printf("生产者线程从51单片机读取到%zd字节数据,现在已经写入环形缓冲区\n",real_push_len);
printf("16进制形式:");
for(int i=0; i<len; i++)
{
printf("0x%02X ", (unsigned char)buffer[i]);
}
printf("\n");
}
else if(len==0)
{
printf("未读取到数据(串口无数据发送)\n");
}
else
{
// 优化:打印具体错误原因,便于排查
perror("读取串口失败");
}
}
close(fd);
return nullptr;
}
//消费者线程函数
//依旧把环形缓冲区的指针强转后传进来
void* consumer_thread_func(void* arg)
{
Ring_Buffer* Rb=(Ring_Buffer*)arg;
//业务逻辑为:不断循环的从环形缓冲区中读取数据,上传网络(假设我们用延时替代)
while(1)
{
char buffer[512];
size_t real_read_len=Rb->pop(buffer,sizeof(buffer));
printf("消费者从环形缓冲区中读取到%zd字节数据\n",real_read_len);
printf("16进制形式:");
for(int i=0; i<real_read_len; i++)
{
printf("0x%02X ", (unsigned char)buffer[i]);
}
printf("\n");
}
return nullptr;
}
#include <sys/ioctl.h>
#include"Producer_and_Consumer.hpp"
#include"Ring_Buffer.hpp"
int main()
{
//创建Ring_buffer
Ring_Buffer Rb;
//定义线程ID,用以接收pthread_create的输出型参数
pthread_t productor_tid;
pthread_t consumer_tid;
//创建生产者线程
pthread_create(&productor_tid,nullptr,productor_thread_func,&Rb);
//创建消费者线程
pthread_create(&consumer_tid,nullptr,consumer_thread_func,&Rb);
//5. 主线程在两个jion之前无法结束,还能起到收尸的作用
pthread_join(productor_tid, NULL);
pthread_join(consumer_tid, NULL);
return 0;
}
三、测试结果与思考
(1)测试结果
我们直接运行测试,发现似乎与之前没有环形缓冲区之前差不多结果,这已经能证明环形缓冲区在正常工作,但还没有体现平滑波动的效果,这主要是因为我们没有模拟网络波动等问题,于是我们紧接着修改生产者代码,加入一定程度的sleep。
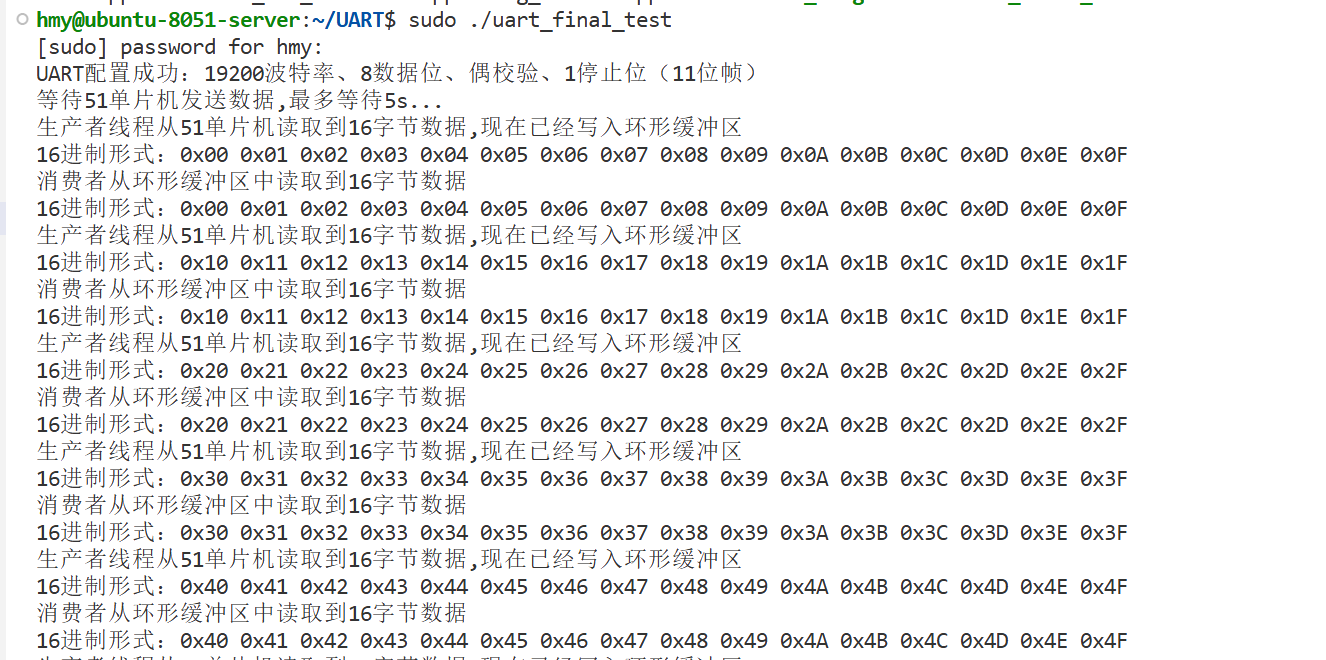
当加入一些测试睡眠函数后(生产者在3次从驱动中read后睡眠20s,用来模拟单片机端发生故障;消费者在前10s先不拿数据,证明在生产者出问题时,仍会从缓冲区拿数据),测试结果如下:缓冲区作为二者的媒介,起到蓄水池的作用,将两个密不可分的单线程读、写操作,解耦成多线程+缓冲区形式,使得任意一方短时间波动后都不会立马影响对方。
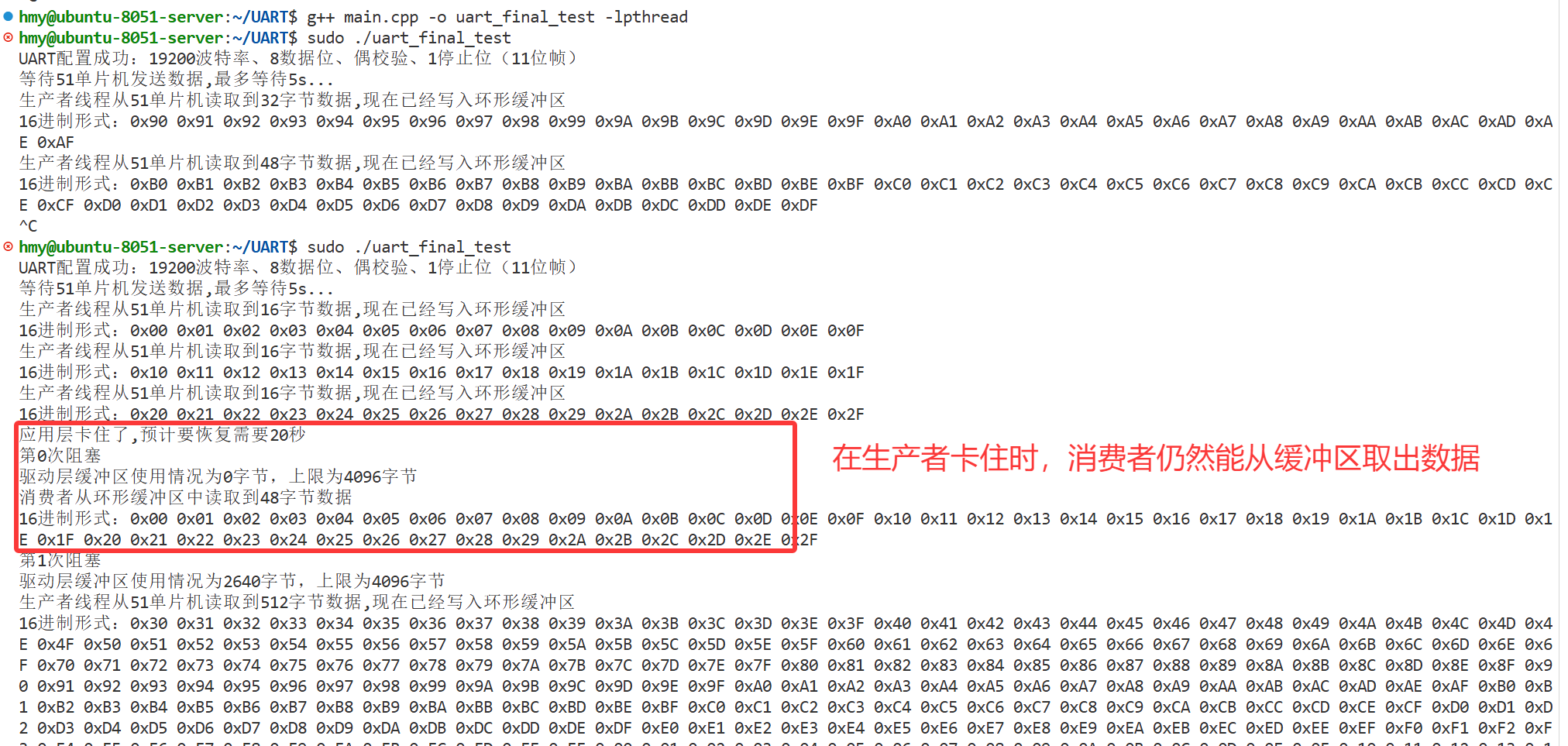
而注意到在生产者恢复后,生产者read突然变成了512字节,这是因为CH340驱动层的有一个4kb缓冲区导致的,如果我们这里不是让生产者睡眠,而是真的工业代码,驱动层缓冲区也有一定调控作用,尽管调控能力很弱。
而在真正的工程上可能还有更多级、更大容量、更高性能的缓冲区,通过他们的调控、平滑作用,使得短时间内的波动可以被忽略。
(2)思考
我们的项目已经实现了一条完整的链路:从物理数据采集到Linux上位机处理,但此时仍然显得比较demo化,与生活中的工程代码还有着不小的差距。
比如可能添加网络线程,实现端侧采集,云服务器端实时监测(端侧可以使用简单socket,而服务器侧则必须实现epoll高并发场景);裸机采集到的数据可能不是单纯的二进制流,而有定制的协议(帧头、帧尾,超时重传等机制);Linux网关侧可能采取无锁化设计、mmap零拷贝策略,更加高性能。
这些不足将会在后续文章中逐步完善。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)