AutoRefine 论文详细解读:检索增强推理的 “搜索 - 精炼 - 思考” 新范式
这篇论文由中国科学技术大学、新加坡国立大学等团队联合发表于 NeurIPS 2025,聚焦检索增强生成(RAG)在复杂问答任务中的核心痛点,提出了基于强化学习的后训练框架 AutoRefine。该框架通过创新的 “search-and-refine-during-think” 范式,解决了传统检索增强推理中文档噪声干扰和检索过程缺乏针对性监督的问题,在单跳和多跳问答任务中均实现了性能突破。

一、研究背景与动机
1. 核心背景
- 大语言模型(LLMs)虽具备强大推理能力,但受限于训练数据的时效性和覆盖范围,在知识密集型任务中易产生事实错误;
- 检索增强生成(RAG)通过引入外部知识库缓解上述问题,已成为知识密集型问答的主流方案;
- 现有 RAG 相关方法多遵循 “search-during-think” 范式,即模型在思考过程中自主调用检索工具,但未解决检索文档噪声和检索过程缺乏有效监督的核心问题。
2. 现有方法的两大核心缺陷
- 缺乏检索文档精炼步骤:检索工具返回的文档常包含大量无关噪声信息,传统方法直接基于原始文档推理,易被干扰,尤其在多跳场景中,早期步骤的噪声会导致整个推理链失效;
- 检索专用奖励未被充分探索:现有强化学习(RL)驱动的方法仅依赖最终答案正确性的结果导向奖励,缺乏对检索过程本身的直接监督,导致模型难以学习到高质量的检索策略。
3. 研究目标
提出一种能够自主精炼检索信息、并通过针对性奖励机制优化检索 - 推理全流程的框架,提升复杂问答任务(尤其是多跳问答)的推理准确性和鲁棒性。
二、核心方法:AutoRefine 框架
AutoRefine 是一种强化学习后训练框架,核心由 “轨迹生成(含知识精炼)”“双奖励机制”“GRPO 优化” 三部分构成,形成 “检索 - 精炼 - 推理 - 优化” 的闭环。
1. 任务定义
给定问答数据集D={(q,a)}(q为问题,a为真实答案)和外部搜索引擎ε,模型需生成推理轨迹o=(τ1,τ2,...,τT),其中每个中间步骤τt=(st,ct)包含动作st(可选 ```<search><documents><refine>`或答案标记``)和对应内容ct,最终通过多轮交互生成正确答案oans。
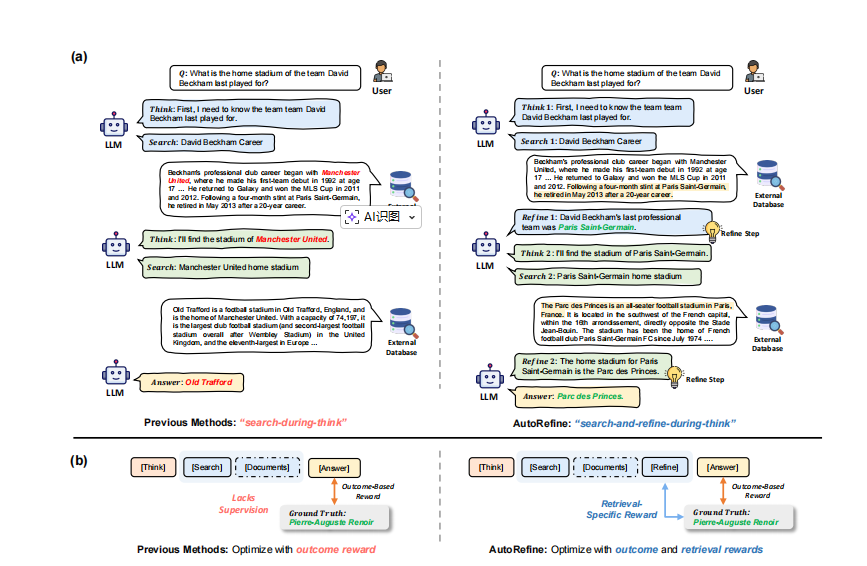
2. 核心创新:“search-and-refine-during-think” 范式
通过结构化模板将 “检索” 与 “知识精炼” 强制融入推理过程,每轮检索后必须完成信息精炼,具体流程如下:
- 思考规划(``):模型基于历史轨迹和原始问题,规划下一步检索或推理方向,对应
...块内容; - 检索调用(
<search>):生成检索查询词,调用搜索引擎获取相关文档(默认返回 Top3),格式为<search> query </search>; - 文档整合(
<documents>):接收搜索引擎返回的原始文档,作为精炼的输入; - 知识精炼(
<refine>):从噪声文档中提取与问题直接相关的关键信息,格式为<refine> key evidence </refine>,核心是过滤冗余、保留核心事实; - 答案生成(``):当精炼信息足够时,生成最终答案。
该范式通过 Prompt 模板(图 3)明确告知模型上述流程,确保每步检索后都进行信息提纯,避免噪声干扰。
3. 双奖励机制:结果导向 + 过程导向
设计互补的两类奖励,同时优化最终答案准确性和中间检索 - 精炼质量:
(1)结果导向奖励(RAns)
基于预测答案与真实答案的 F1 分数,衡量最终结果正确性:RAns=F1(oans,a)=∣oans∣+∣a∣2∣oans∩a∣其中oans为模型最终答案,a为真实答案,取值范围[0,1]。
(2)检索专用奖励(RRet)
基于<refine>块内容的质量,衡量信息精炼的有效性:RRet=I(a∩orefine=a)其中I(⋅)为指示函数,orefine为所有精炼步骤内容的拼接,当真实答案的全部组件都包含在精炼信息中时,奖励为 1,否则为 0,强制模型提取关键事实。
(3)融合奖励(ROverall)
采用非线性融合策略,平衡结果与过程优化:ROverall=⎩⎨⎧RAns,0.1,0,if RAns>0if RAns=0 and RRet>0if RAns=RRet=0
- 正确答案获全额奖励,鼓励最终准确性;
- 答案错误但精炼有效时获少量奖励,避免模型因短期失败放弃高质量中间步骤;
- 两者均无效时无奖励,抑制无效行为。
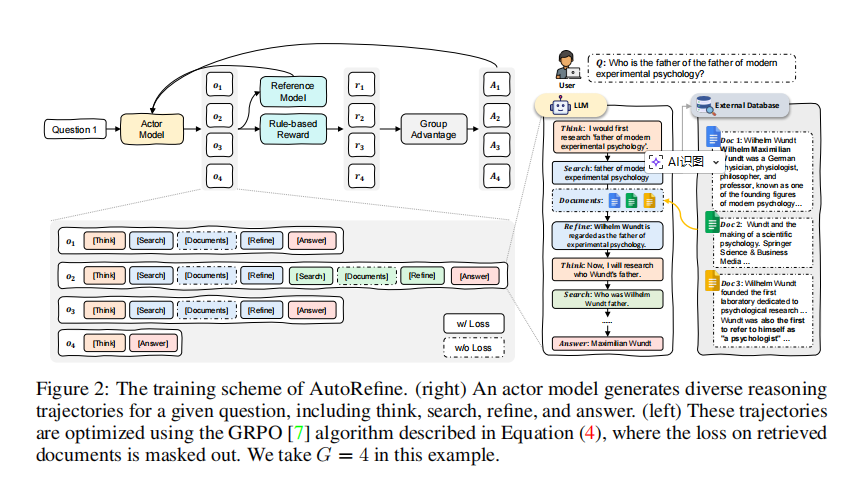
4. 训练优化:Group Relative Policy Optimization(GRPO)
采用 GRPO 算法优化模型策略,避免传统 PPO 的高资源消耗,核心是通过 “群体相对优势” 更新策略,同时引入 KL 散度约束防止模型偏离原始能力:θargmaxJGRPO(θ)=E(q,a)∼D,{oi}i=1G∼πθold(⋅∣q)[G1∑i=1G∣oi∣1∑t=1∣oi∣min(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ϵ,1+ϵ)A^i,t)−βD±[πθ∣πref]]
- G为群体大小(实验中设为 5),A^i,t为归一化的 token 级优势值;
- ϵ=0.2为裁剪系数,β=0.001为 KL 系数;
- 训练时屏蔽检索文档的损失计算,避免模型学习噪声文档内容。
5. 关键实现细节
- 基础模型:采用 Qwen2.5-3B/7B(Base/Instruct 变体);
- 检索引擎:E5-base-v2+2018 年 12 月 Wikipedia 快照,默认每轮检索返回 3 篇文档;
- 训练配置:8 张 NVIDIA A100-80GB GPU,FSDP 分布式训练,BFloat16 精度,学习率1e−6,总训练步数 250 步;
- 生成约束:每轮轨迹最多允许 5 次检索,响应长度上限 2048token。
三、实验设计与结果
1. 实验设置
(1)数据集
- 单跳 QA:Natural Questions(NQ)、TriviaQA、PopQA;
- 多跳 QA:HotpotQA、2WikiMultiHopQA(2Wiki)、MuSiQue、Bamboogle;
- 训练集:NQ+HotpotQA 的训练集(共 169,615 个样本),测试集为 7 个数据集的测试 / 验证集(共 51,713 个样本)。
(2)基线方法
- 无检索:Direct Generation(纯 LLM)、SFT、R1(无检索强化学习);
- 单跳检索:Naive RAG(问题直接检索);
- 多跳检索:Search-o1、IRCoT、Search-R1、ReSearch(均为 RL 驱动的检索增强推理方法)。
(3)评估指标
- 核心指标:精确匹配准确率(Exact Match);
- 补充指标:F1 分数、覆盖精确匹配(CEM)。
2. 核心实验结果
(1)整体性能(RQ1)
AutoRefine 在所有 7 个数据集上均显著超越基线,平均准确率提升显著:
- AutoRefine-Base 平均准确率达 40.5%,较最强基线(Search-R1-Instruct,33.6%)提升 6.9%;
- AutoRefine-Instruct 平均准确率 39.6%,较最强基线提升 6.0%;
- 多跳场景提升更明显:2Wiki 数据集提升 21%,Musique 提升 26.7%,验证了精炼步骤对多跳推理的关键作用。
(2)检索行为分析(RQ2)
- 检索频率:模型能自适应调整检索次数,单跳问题平均 1.2 次检索,多跳问题达 2.0~2.5 次,符合任务复杂度需求;
- 检索质量:多跳场景中,AutoRefine 的检索成功率(检索文档含真实答案的比例)达 50%+,较基线(30%~40%)提升 10%~15%,证明模型学会了生成高质量检索查询。
(3)知识精炼有效性(RQ3)
- 精炼步骤的成功 rate 与检索成功 rate 趋于一致(约 70%),说明模型能有效从有效文档中提取关键信息;
- 精炼内容长度仅 100~200token,是原始文档(≥600token)的 1/4,实现了 “去噪 + 压缩” 双重目标。
(4)检索深度鲁棒性(RQ4)
当检索文档数量k从 1 增至 7 时,AutoRefine 始终保持稳定提升:
- k≥3时优势更明显,k=5时性能增益达 9%;
- 证明模型在噪声增多的情况下,仍能通过精炼步骤筛选有效信息,鲁棒性优于基线。
3. 消融实验
(1)核心组件必要性
表格
| 模型配置 | AutoRefine-Base | 无检索奖励 | 无检索奖励 + 无精炼 |
|---|---|---|---|
| 平均准确率 | 40.5% | 37.6% | 31.2% |
- 移除检索奖励:平均准确率下降 2.9%,证明过程导向奖励对优化检索策略的作用;
- 同时移除奖励和精炼步骤:准确率下降 9.3%,且多跳场景性能暴跌(2Wiki 从 393% 降至 257%),验证 “检索 - 精炼” 联动的核心价值。
(2)外部精炼器对比
将 AutoRefine 的 RL 驱动精炼,与 BART、Qwen2.5-Instruct 作为外部精炼器的方案对比:
- 外部精炼器仅在部分单跳数据集(如 PopQA)略有提升,多跳场景性能下降;
- AutoRefine 的精炼步骤能结合后续检索规划,而非单纯 summarization,更适配多跳推理。
(3)奖励设计影响
- 基于精炼内容的奖励优于直接基于检索文档的奖励,证明 “精炼质量” 比 “文档相关性” 更能反映过程有效性;
- 非线性奖励融合(本文方案)优于线性融合,避免过度强调中间步骤而忽视最终答案正确性。
4. 案例研究
通过两个多跳问题验证 AutoRefine 的优势:
- 案例 1(“现代实验心理学之父的父亲是谁?”):基线模型仅检索到 “Wilhelm Wundt 是实验心理学之父” 后直接输出,而 AutoRefine 通过精炼明确核心后,进一步检索 “Wilhelm Wundt 的父亲”,得到正确答案 “Maximilian Wundt”;
- 案例 2(“亚历山大・马佐维亚之父的去世日期?”):基线模型误将亚历山大的出生年份(1400)当作其父去世日期,AutoRefine 通过精炼先确认其父为 “Siemowit IV”,再检索其去世日期(1426 年 1 月 21 日),避免事实混淆。
四、相关工作与局限性
1. 相关工作对比
- 传统 RAG:依赖单次检索或线性多轮检索,无专门精炼步骤,易受噪声干扰;
- 现有 RL 驱动的检索增强推理(如 Search-R1、ReSearch):遵循 “search-during-think” 范式,缺乏过程导向奖励和强制精炼,检索策略优化不充分;
- AutoRefine:首次将 “强制精炼” 与 “双奖励机制” 结合,实现检索 - 推理 - 优化的闭环。
2. 局限性
- 评估指标单一:仅采用精确匹配和 F1,未考虑语义相似的正确答案,不适用于开放域长文本生成;
- 检索语料静态:使用固定的 Wikipedia 快照,缺乏时效性信息,难以适配实时问答场景;
- 精炼粒度有限:当前精炼基于规则判断是否包含真实答案,未考虑精炼信息的结构化和连贯性。
五、结论与未来工作
1. 核心结论
AutoRefine 通过 “search-and-refine-during-think” 范式和双奖励机制,有效解决了传统检索增强推理中的噪声干扰和检索策略优化不足问题,在单跳和多跳问答任务中均实现性能突破,尤其在复杂多跳场景中优势显著。
2. 未来方向
- 引入更灵活的评估指标(如 LLM-as-a-Judge),适配开放域问答;
- 适配动态检索场景(如实时网页搜索),提升时效性;
- 优化精炼步骤,引入结构化精炼(如知识图谱构建),进一步提升多跳推理的连贯性;
- 探索更大参数量模型与 AutoRefine 的结合,挖掘性能上限。
六、核心贡献总结
- 提出 “search-and-refine-during-think” 新范式,将知识精炼强制融入推理过程,有效过滤检索文档噪声;
- 设计 “结果导向 + 过程导向” 双奖励机制,为检索策略优化提供针对性监督信号;
- 基于 GRPO 实现高效强化学习训练,兼顾性能与训练效率;
- 在 7 个 QA 数据集上验证了方法的有效性、鲁棒性和泛化性,为复杂检索增强推理提供了新范式。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)