传统机器学习推理 vs 大语言模型推理

导读
大语言模型推理相较于传统机器学习推理,面临着独特的挑战,也正因如此,诞生了 vLLM、LMCache、SGLang 以及 TensorRT LLM等这类专用的高性能大语言模型推理引擎。今天我们就来解析这些挑战,以及对应的解决办法!
连续批处理
卷积神经网络这类传统模型的图像输入尺寸固定,输出长度也固定(如分类标签),批处理的实现因此十分简便。

而大语言模型要处理的输入(提示词)和生成的输出,长度均为可变的。

若对多个请求进行批处理,各请求的完成时间会各不相同,显卡必须等待耗时最久的请求完成后,才能处理新的请求,这就会造成显卡出现空闲时间:
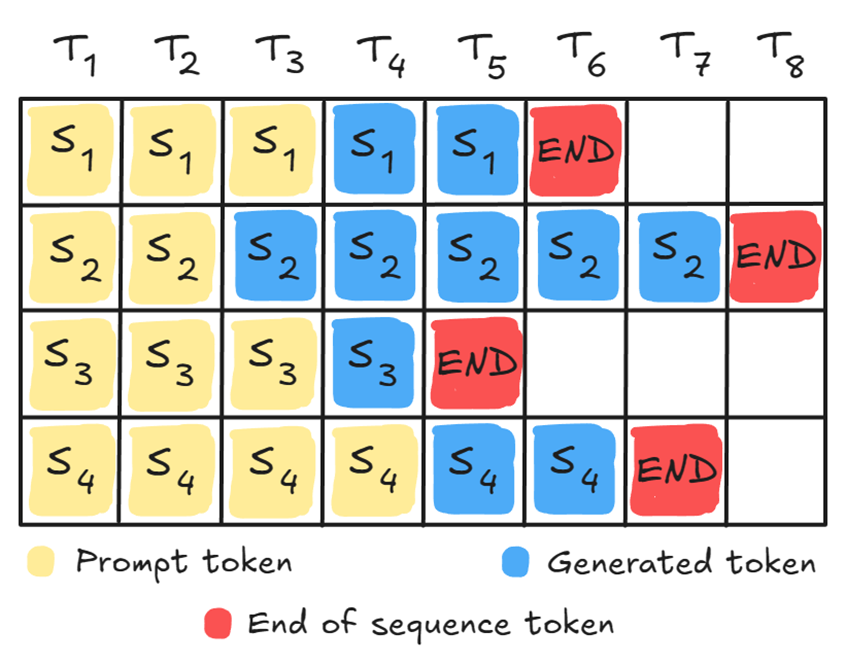
连续批处理(Continuous batching)则能解决这一问题。该机制不会等待整个批次的请求全部完成,而是持续监控所有序列,将已完成的序列(出现序列结束token)替换为新的query请求:
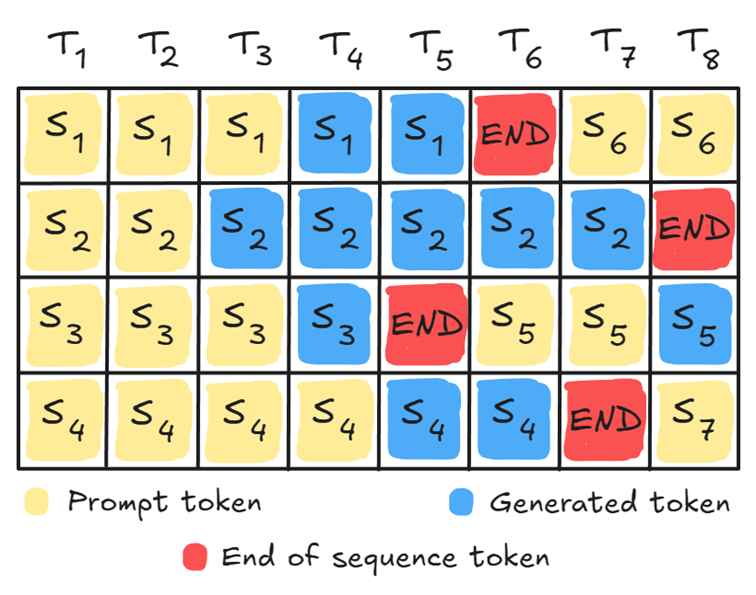
这一方式能让显卡计算流水线保持满载,实现算力利用率的最大化。
预填充 - 解码解耦
大语言模型的推理过程分为两个阶段,且两个阶段对计算资源的需求有着本质区别。
- 预填充阶段:一次性处理所有输入的提示词tokens,属于计算密集型阶段。
- 解码阶段:以自回归的方式生成输出内容,对延迟性要求极高。

- 如果两个阶段都在同一显卡上运行,计算密集型的预填充请求会干扰对延迟敏感的解码请求,影响推理效率。
预填充 - 解码解耦(Prefill-decode disaggregation)的解决思路是,为预填充阶段分配专属的显卡资源池,解码阶段则使用另一组独立的显卡资源池,实现两个阶段的资源隔离。
反观传统的机器学习模型,通常只有单一、统一的计算阶段,无需进行此类资源拆分。
显卡内存管理与键值缓存
大语言模型生成新token时,需要用到此前所有tokens对应的键向量和值向量。为避免反复重新计算这些向量,我们会对其进行缓存:
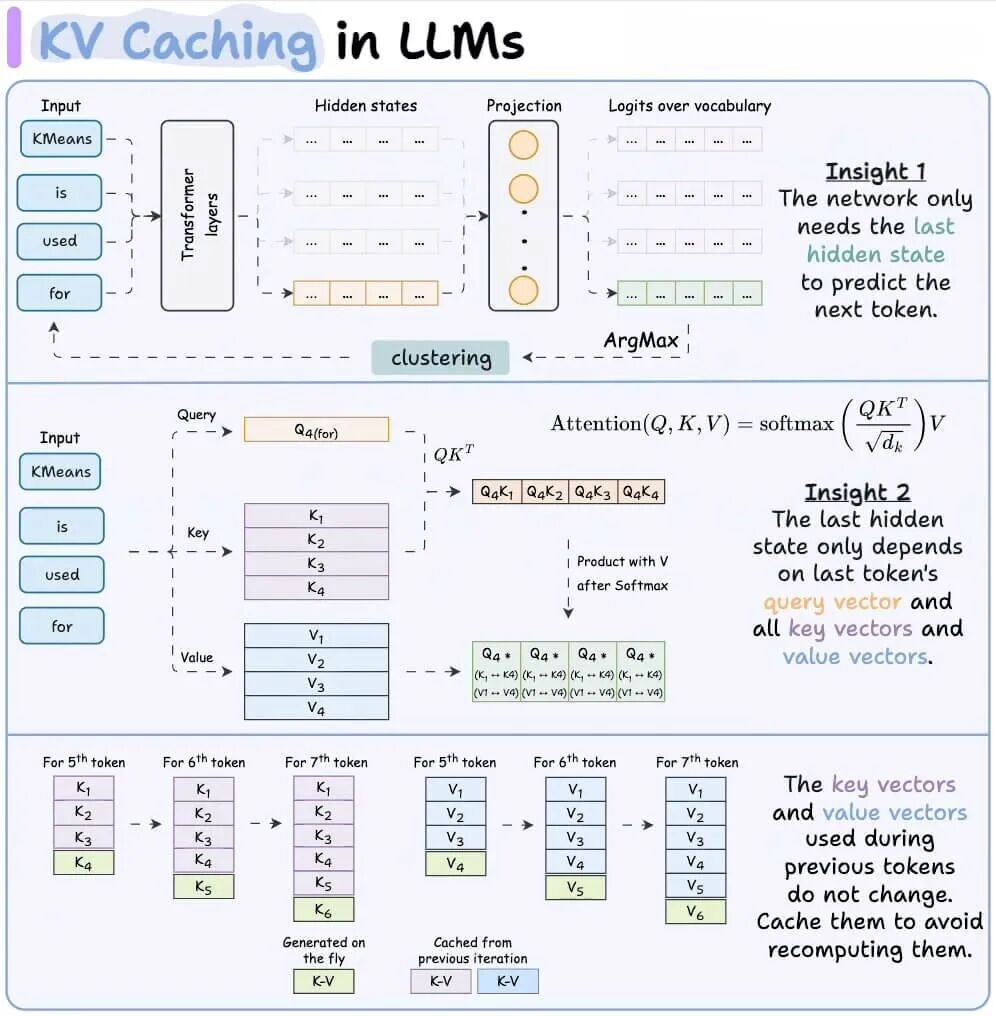
键值缓存(KV Cache)的数据量会随对话历史的总长度呈线性增长。
但在很多实际业务流程中,系统提示词这类输入内容会被多个请求共享。因此,我们可在所有对话中复用这些共享内容的键值向量,避免重复计算。
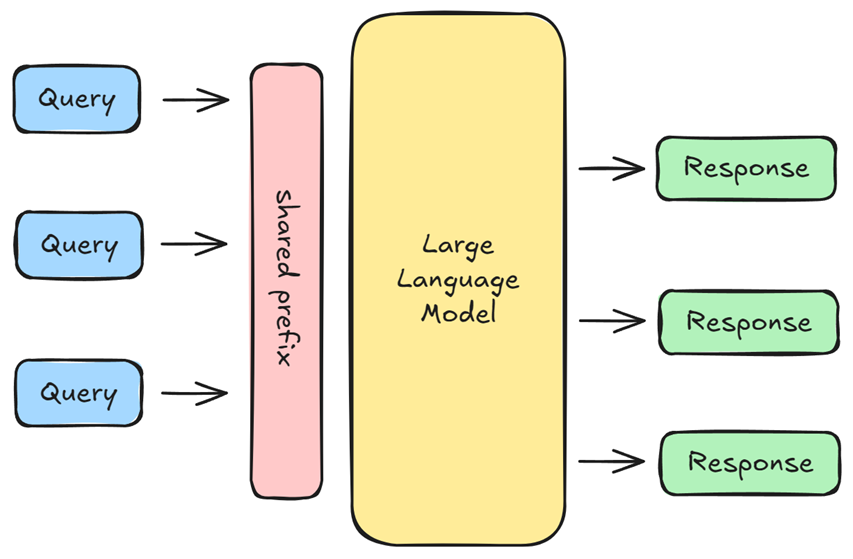
尽管如此,键值缓存需要占用连续的内存块来存储,这会占用大量显卡内存,还容易引发内存碎片问题:
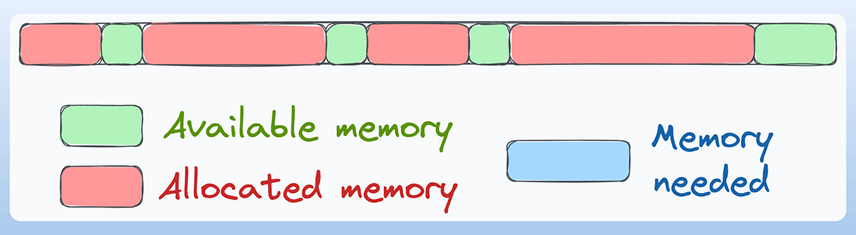
分页注意力机制(Paged Attention)能解决这一问题,它将键值缓存存储在非连续的内存块中,同时通过查找表对这些内存块进行追踪。大语言模型仅会加载当前需要的内存块,而非一次性加载全部缓存数据。
关于分页注意力机制的详细内容,我们会在后续专题中讲解。
前缀感知路由
要对传统机器学习模型进行扩容,只需将模型复制到多台服务器 / 多张显卡上,再采用轮询、路由至最空闲服务器这类简单的负载均衡策略即可。
由于传统模型的每个请求相互独立,这种扩容方式的效果良好。
但大语言模型高度依赖缓存(如前文提到的共享键值前缀),导致各请求之间不再相互独立。
假设有一个新query请求包含的共享前缀,已在模型实例A中完成缓存,而路由策略却将其发送至负载更低的模型实例B,那么实例B就需要重新计算该前缀对应的全部键值缓存,造成算力和时间的浪费。
前缀感知路由(prefix-aware routing)正是为解决这一问题而生。
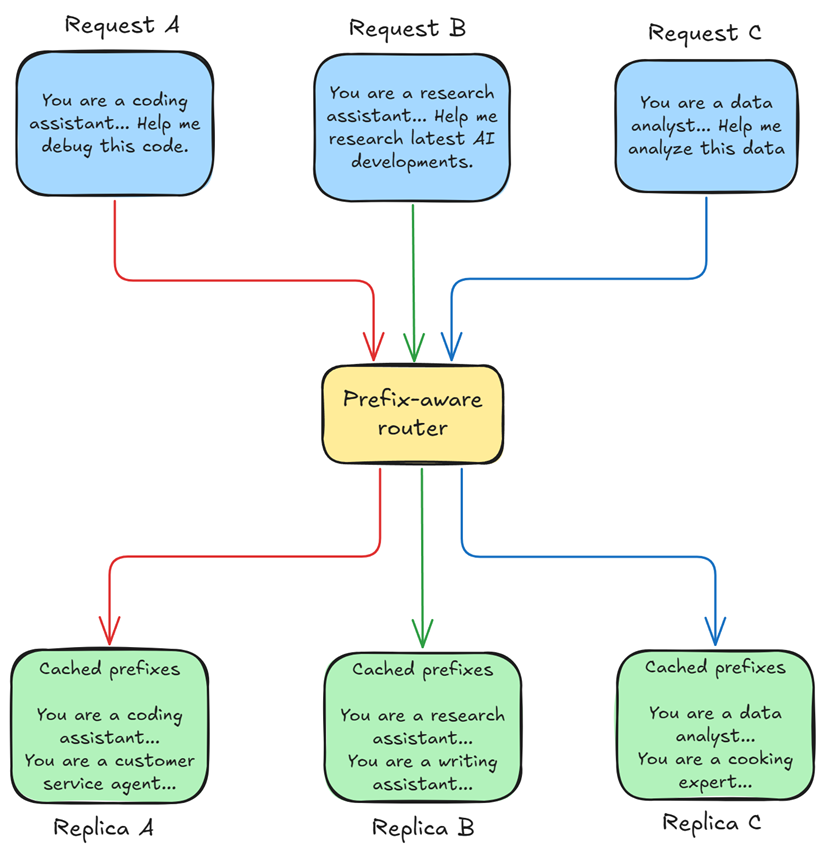
不同的开源框架,对前缀感知路由有着各自的实现方式。
总体而言,前缀感知路由要求router维护一张映射表(或采用预测算法),实时追踪各显卡副本上当前缓存的键值前缀。
当新的query请求到达时,router会将其发送至已缓存相关前缀的显卡副本,实现缓存复用。
模型分片策略
针对稠密的传统机器学习模型,有多种扩容分片策略:
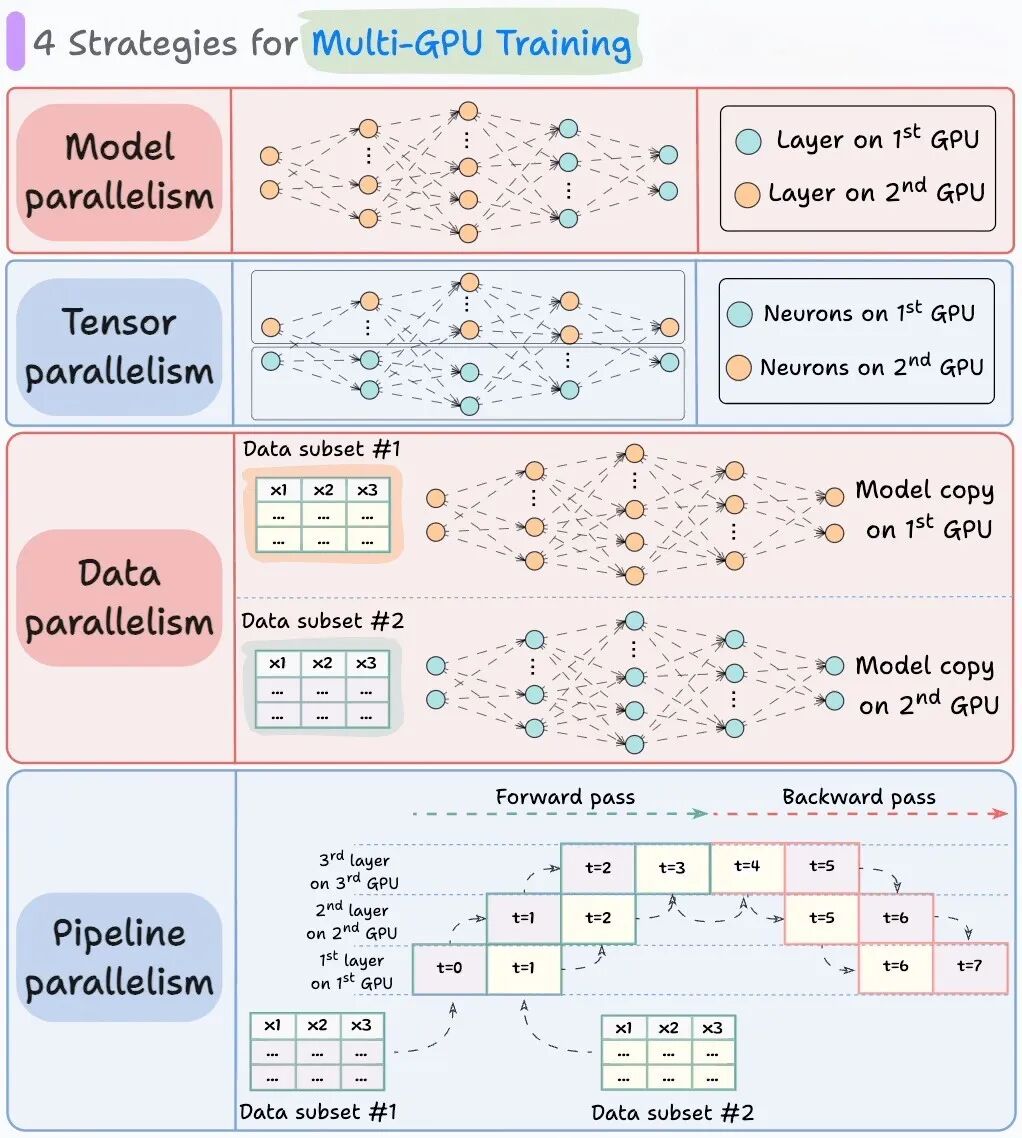
而大语言模型(如混合专家模型)的分片扩容则更为复杂。
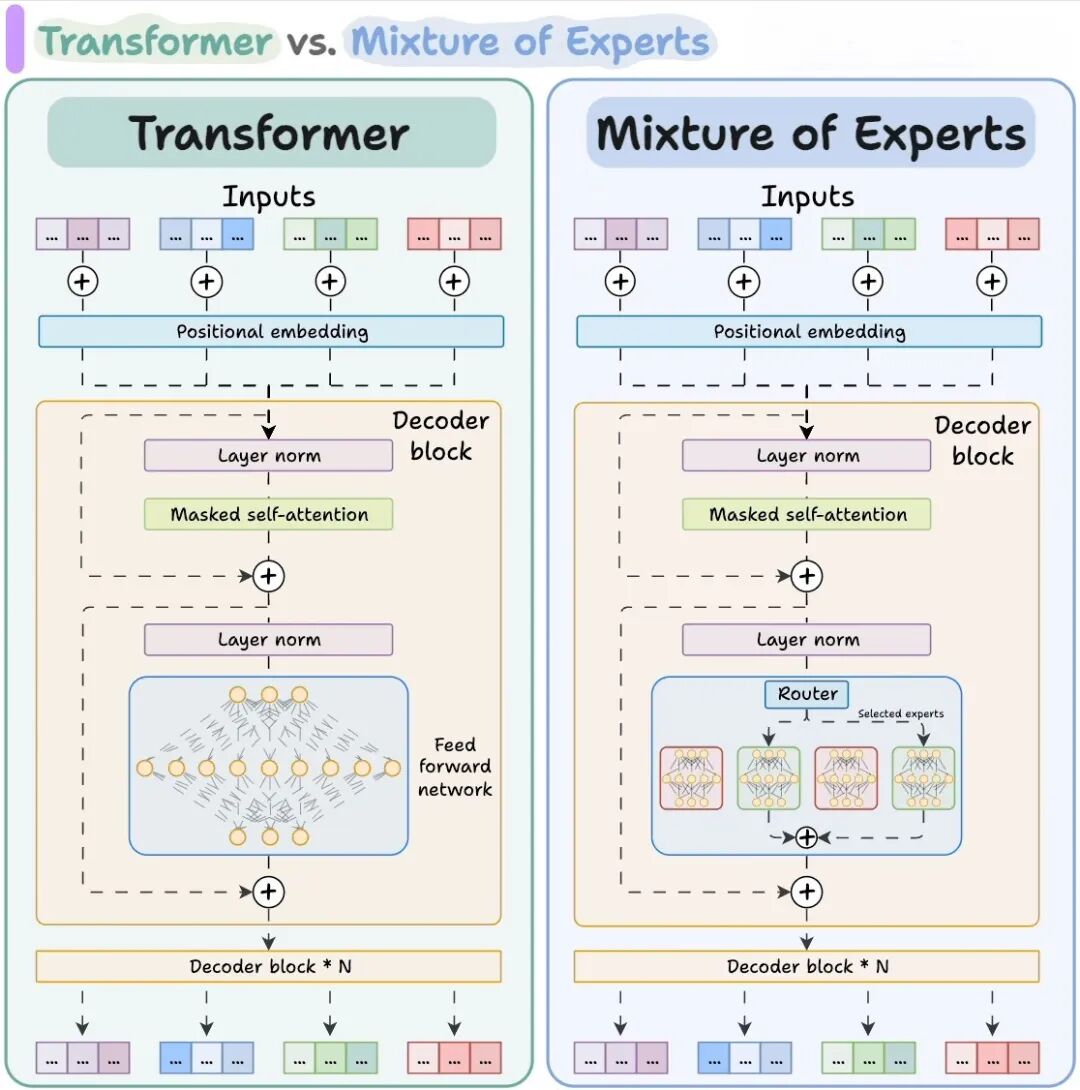
混合专家模型采用一种专用的并行策略 ——专家并行,该策略将模型中的各个专家模块拆分到不同的计算设备上,而注意力层则在所有显卡上进行复制:
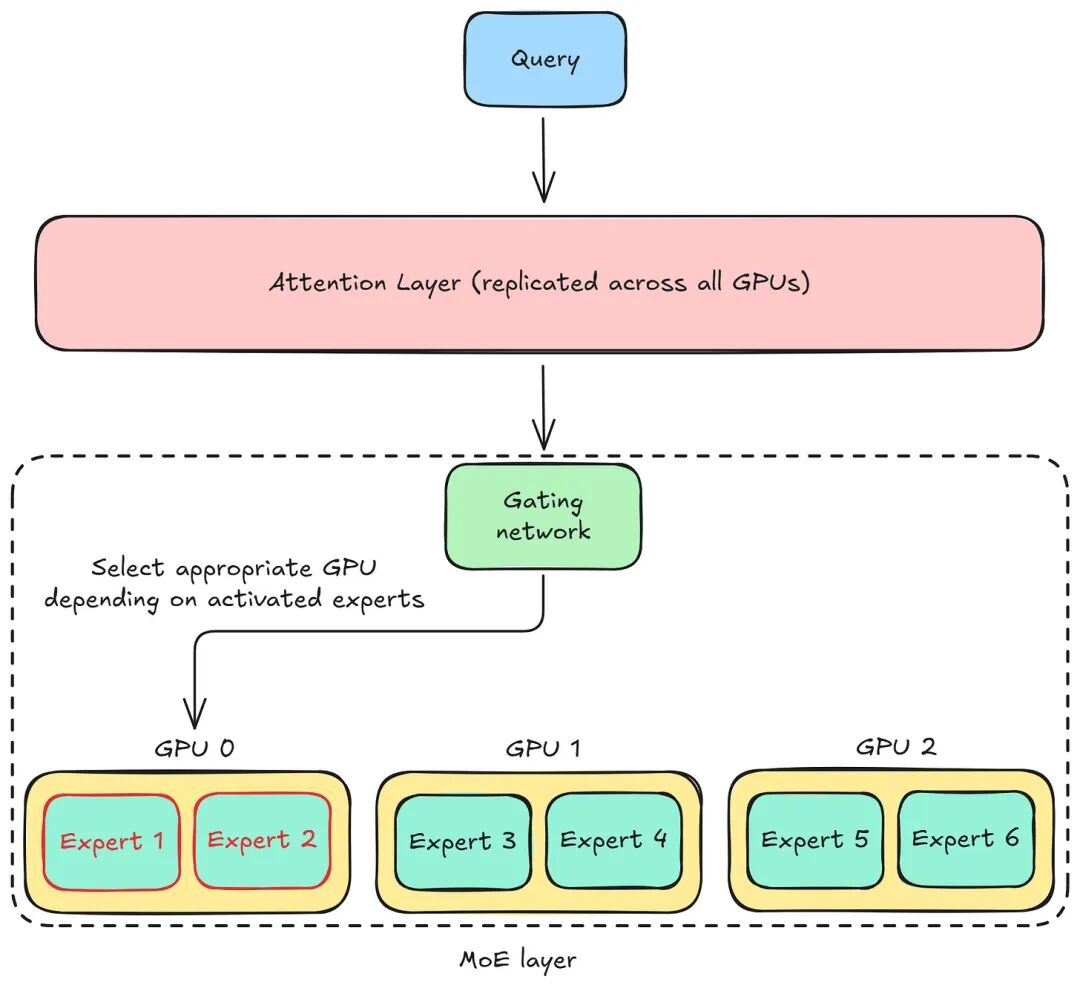
当query请求到达时,混合专家模型中的门控网络会根据当前激活的专家模块,动态决定请求应路由至哪张显卡。
这是一个复杂的内部路由问题,无法像简单的模型副本那样处理,需要借助高性能的专用推理引擎,来管理分片专家池之间的动态计算流程。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献118条内容
已为社区贡献118条内容

所有评论(0)