交叉熵损失&大模型可调节参数&LoRA
一、交叉熵损失
首先,回顾一下什么是交叉熵。当我们在做一个分类任务时,比如输入一个图片,通过神经网络来判断这张图片里是牛还是猴。神经网络最后一层我们一般是通过soft max输出,这张图片是各个类别的概率值,然后标签数据是通过one hot encoding后的label值。如何衡量模型输出与标签之间的差距呢?
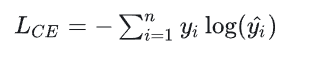
交叉熵损失函数是通过把模型输出 每个类别概率的对数 与 完好的encoding对应类别值(真值为1,假值为0) 的乘积后 累加 取负值。因为进行one hot encoding的缘故,label中只有一个分类值为1,其余都为0。所以在对每个样本进行计算的过程中,只有one hot encoding为1的那个类别会产生损失。这个从log函数的图像也很好理解,只有对样本真实类别预测概率值为1时,log函数值为0。对真实类别预测概率越低,log函数绝对值越大。取负值是因为log函数在0到1之间都为负值,负负得正。
为什么分类会使用交叉熵损失函数呢?一般有两种解释。先从第一种看起,那就是极大似然估计法。我们先来通过一个游戏来回忆一下极大似然估计。假设一个箱子里有白球和黄球,每次你抽取一个观察后放回,再抽取一次,重复十次,你得到10次观测值,一共观测到8次白球,两次黄球,让你估计箱内白球的占比,相信你会给出80%这个答案,为什么呢?
首先我们如果假设白球和黄球都占50%,那么观测得到8次白球两次黄球的概率就为0.5的10次方,也就是9.7乘以10的负4次方。如果白球占比为80%,黄球占比为20%,那么得到这个结果的概率就是0.8的8次方乘以0.2的2次方,也就是6.7乘以10的负3次方。可以看到白球占比80%,得到这个观察结果的概率高了不少。那么我们把出现白球的概率设置为P那么出现黄球的概率就是一减P先后一共出现了八次白球,两个黄球,那么出现这个实验结果的概率就为P的8次方乘以一减P的2次方。我们让出现这个实验结果的概率最高,也就是寻找P在0到1区间里哪个值使得函数值最大化。通过求导我们可以得到P等于0.8,这就是极大似然估计法。
回到我们的分类损失函数问题,我们把神经网络可以看作是一个黑盒,每个类别输出是一个概率label,是实验的观测值。每个样本可以看作是一次独立抽样。在所有的样本上让我们模型输出和label一样值的概率最大,也就得到了我们的最优模型。
首先让我们看如何计算一次抽样模型预测正确的概率,它就等于每个类别预测概率的one hot encoding值的次方的累乘。因为one hot encoding在非真类别上为0,真实类别上为1的原因,而且任何数的0次方为一,1次方为自身的特性,让one hot encoding次方项就帮我们选择了模型在正确类别上的概率。然后因为在N个样本上进行了N次独立试验,所以概率为他们的乘积,让这组实验发生概率最大的模型就是我们要找的模型。因为有很多连乘,我们用log似然函数将连乘变成了连加。最后通过给整个表达式前面加一个负号,让求最大值变成求最小值,这样我们就得到了交叉熵损失函数。
交叉熵损失函数还有另外一种理解方式,那就是从信息论的角度来理解。首先我们要引入一个结论,那就是一个系统的信息熵是对这个系统平均最小的编码长度。比如一个地区有4种天气,分别是阴晴雨雪,这四种天气发生的概率分别为2分之1、4分之1、8分之1、8分之1。则每种天气的信息量或者对它的编码长度分别为1233。这个系统的信息熵为1.75。下边我们通过普通编码和信息熵编码来分别对四种天气进行编码,并通过它们来传递一段时间内这个地区的天气。发现普通编码长度为16,信息熵编码长度为14。
上边这个例子让你直观理解,一个系统的信息熵是对这个系统平均最小的编码长度。如果采用其他的编码格式,那么肯定平均编码长度是要大于信息熵编码的。交叉熵损失函数就是利用这个特性来衡量其他编码格式和信息熵编码格式之间的编码长度的差距。换句话说,就是利用信息熵的最短编码特性来评估一个样本在不同类别上的真实概率分布和预测概率分布之间的差值。
再来看交叉熵损失函数,它和信息熵公式的不同是对预测值y hat取对数。如果预测值y hat的概率和真实值Y的概率一致,那么就退化成了信息熵公式,我们得到的交叉熵损失就为最小值。如果y hat预测的概率值和真实概率值Y不一致,那么交叉熵的值必然大于系统的信息熵,交叉熵损失函数就还有优化的空间。
以上就是两种对交叉熵损失函数的理解。我个人更推荐大家从信息论的角度去理解。因为它是从两个概率分布的相似程度来分析的。假如你知道label smoothing方法的话,标签值不再是非0即1的one hot encoding,这时从概率分布的角度更好理解,而不是极大自然估计的一次抽样。
二、大模型可调节参数
在利用大模型做文本生成时,我们有很多可以调节的参数。这里我们讨论最主要的几个,top k,top p,temperature,number beams, 你知道这几个参数的作用吗?更进一步,如果同时设置这几个参数,它们的作用顺序是什么呢?先应用top k,top p还是temperature呢?
让一个大模型生成输出,给它输入。比如:我喜欢,大模型会输出针对下一个token的一组logic,它的维数就是你字典的维数。比如llama2是32000个,然后经过softmax把logit转化为概率值。
如果是最简单的贪心算法,我们只要选取最大的概率值位置对应的token作为下一个输出,然后把这个输出追加到之前的输入后边,再进行下一个token的预测。这样的贪心算法有个问题,就是我们每次都选取当前概率最大的token作为输出。但实际上我们想要的是找出联合概率最大的输出。选择当前概率最大的token可能会导致后续的token概率都很小。那怎么解决这个问题呢?我们就引入了beam search,它会一直保留多个可能的输出序列,也就是beam最后以整个输出所有token出现的联合概率最大的输出作为最后结果。
看个例子,我们设置beam数量为2,输入是我喜欢大模型输出,对字典里每个token都会有一个概率值,之前贪心算法我们只选择概率最大的那个token,现在我们设置beam数量为2,我们会保留两个可能的输出值,吃和学。下一步我们会以我喜欢吃和我喜欢学这两个序列分别来寻找他们各自的下一个token。同样这两个序列会分别预测字典里每个token作为各自序列下一个token的概率。
接下来我们要选择下一步要保留的两个beam,beam的整体概率是这个beam里所有token概率值的乘积。比如对于我喜欢吃醋,这个闭幕的概率值就为0.32乘以0.35等于0.112。接下来我们为所有可能的BM计算概率值,在实际实现里为了防止多个小值连乘向下溢出,会用log相加的办法来解决。这里为了简单,我们认为beam的概率就是它里面各个token的概率的乘积。最后我们选择这些beam里概率最大的两个beam保留。这里你可以看到,虽然第一个token吃比学的概率大,但是到了第二个token概率不同,两个闭幕整体的概率反而是我喜欢学习比我喜欢吃饭概率更高。接下来以此类推,继续进行beam search。
上面不管是最简单的贪心算法,还是改进的beam search,对于同一个输入,大模型的输出还是固定的,这样有些无聊。我们想让大模型的输出增加一些随机性,也可以说是创造性,有什么办法呢?那就是不以最大的概率选择下一个token,还是对所有的token按照概率进行采样。这样概率越大的token就越有可能被选中,但是概率小的token也有可能被选中。
我们只想保留那些概率大的token进行选择,有什么办法呢?这样就有了top k和top p首先看top k,k为二的时候,我们只保留logit最大的两个logo,其他的设置为负的无穷大。这是因为负无穷大在经过softmax转化为概率值时会变为零。接着我们进行softmax,这样概率就集中在了前两个token上,其余的token概率值都为零。我们再按照概率对前两个token进行选择,这样不论选到哪个都是可以接受的。
Top k固定的K但是token的概率分布有时候可能是平缓的,每个token的概率都差不多大,有时候是尖锐的,也就是说概率集中在少数的几个token上,这时候固定K就不合适了。人们又提出了top p,top p是token的概率从大到小依次累计的值达到多少,然后在这些token里按照概率进行选择。比如这里我们设置的P为0.8,我们累积前三个概率,最大的token累计值概率超过了0.8,然后我们就把剩余token的概率值设置为负的无穷大,然后再经过一次softmax来分配概率,最后再按照概率选择一个token。Top p能很好的处理token不同概率分布的情况,如果token的概率分布平缓,那么最后候选的token就多一些。如果token之间的分布尖锐,最后候选的token就少一些。
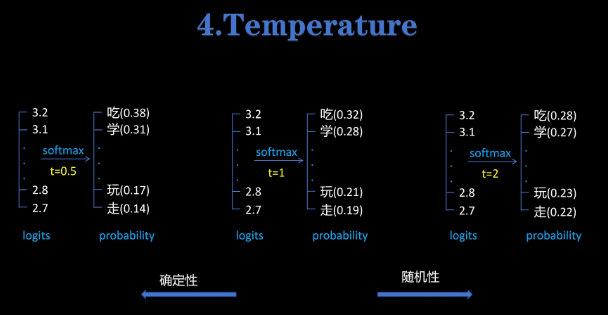
接着我们看一下temperature参数,它是对soft max函数的一个参数调节。我们以标准的soft max作为参照,也就是temperature等于零等于一的情况。如果将temperature调整到0.5,我们可以看到soft max的输出原来概率大的值变得更大了,概率值小的变得更小了。它让后面的token选择更可能选择概率高的那些token,也就是增加了生成的确定性。当我们把temperature调整到2,可以看到soft max的输出各个token之间的概率值变得接近了,这让后边对token的选择增加了随机性。一般在实际应用中,我们选择的temperature值一般是0.5到2之间。
如果你同时配置这些参数,他们是如何协同生效的呢?我们先看没有设置beam设置的情况。首先对大模型的输出的logic应用temperature,比如这里的temperature设置为2,我们直接对logic除以2就可以了。接下来会应用top k这里K为三,我们只保留前三大的logis的值,其余的logis设置为负无穷大。然后进入top p这里P设置为0.6。Top p会先进行一次softmax,把logic的值变化为概率值,然后从大到小对概率进行排列,留下累计值高于0.6的那些token,其他的token的概率值被设置为负无穷大。最后就进入了token的采样环节,这里会重新进行一次softmax,然后按照新的概率对token进行采样。
最后我们再来看设置了beam search的情况,它对每个beam增加token时,每个token的概率计算和上面是一样的。首先应用temperature,然后是top k接着top p,不同的是每一个每一步对beam进行选择时,如果这里beam number设置为3,原来进行选择时是选择概率最大的前三个beam,现在是对beam按照概率进行采样,选择三个,每个beam的概率是整个beam目前所有token的概率乘积。
三、LoRA
我们来学习一下LoRA的原理。在深度神经网络里最主要的计算就是矩阵运算。而大模型里矩阵运算维度都是成千上万的。模型里我们要训练调整的权重也是用矩阵表示的。LoRA就是通过化简权重矩阵来达到参数高效微调的,比如这里这个3乘3的权重矩阵,正常情况下,前向传播时输入乘以权重得到输出,后向传播时调整权重矩阵更新网络。而LoRA的思想是在这个权重矩阵的旁边另辟蹊径,重新构造两个权重矩阵,LoRA A和LoRA B在这个例子里,这两个权重的维度分别为3乘1和1乘3。值得注意的是,这两个lara权重矩阵的乘积的维度和原始权重矩阵的维度是一样的,都是3乘3。

正向传播时输入,通过原始权重得到一个输出,同时输入通过下面这两个LoRA权重得到另一个输出。最后将这两组输出相加,得到这个矩阵计算更新后的输出。可以认为LoRA这个分支在对模型进行微调,改进模型的输出。
而后向传播时,我们锁定原始权重矩阵,只对LoRA权重进行更新。原始的权重个数是3乘3,一共九个,LoRA权重的参数是3乘1加上1乘3,共6个。可以看到LORA可以减少更新权重的个数。
网络训练完成后,原始的矩阵权重没有变化,我们得到一个LoRA A和LoRA B的权重。这时我们把LoRA A和LoRA B相乘,得到一个LoRA权重矩阵。这是这个LoRA权重矩阵的形状,和原始权重矩阵的形状是一样的,我们只需要把lora权重加到原始权重上,就完成了对原始网络的更新。
这个例子里,原始权重的矩阵shape是3乘3,看起来LoRA减少参数训练量也不并不明显。假如原始权重维度是4096乘4096的,而取四的情况,原始矩阵的参数量是4096乘4096,一共16777216个。而LoRA A的参数个数为4096乘以4,LoRA B的参数个数为4乘4096,LoRA训练的参数个数总共为32768个,训练参数是原始参数的512分之1,减少的参数量还是非常可观的。
我们看一下LoRA训练里有两个重要的参数,也就是rank。假设原始权重的维度为M乘以N, LoRA A的权重为M乘以R,LoRA B的权重为R乘以N,R是用来连接LoRA A和LoRA B两个LoRA权重矩阵中的中间维度,一般它远远小于原始权重矩阵中的M和N一般R我们设置为2,4,8,16等。
 input和原始权重相乘后的输出为x,input和LoRA权重相乘后的输出为delta x,上边我们的例子里是直接将x和delt x相加。但在实际实现中前向传播时,我们要对德尔塔的权重进行一个调节,这个调节因子就是阿尔法除以R同样,在更新原始权重时,也记得要对LoRA权重加上这个调节因子,因为delta x是对原始模型输出x进行的调节,调节因子决定了delta x影响的大小,一般我们设置阿尔法为R的2到8倍。
input和原始权重相乘后的输出为x,input和LoRA权重相乘后的输出为delta x,上边我们的例子里是直接将x和delt x相加。但在实际实现中前向传播时,我们要对德尔塔的权重进行一个调节,这个调节因子就是阿尔法除以R同样,在更新原始权重时,也记得要对LoRA权重加上这个调节因子,因为delta x是对原始模型输出x进行的调节,调节因子决定了delta x影响的大小,一般我们设置阿尔法为R的2到8倍。
LoRA训练有很多优点,一、它大大节省了微调大模型的参数量。二、它的训练效果和全量微调差不多。三、微调完的lora模型权重可以默置回原来的权重,不会改变原有的模型结构,推理时也不增加额外的计算量。四、可以通过改变rank r的参数,使得最高的情况下LoRA的训练实际上等同于全量微调。
来源:up主Rethinkfun

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)