【前瞻创想】Kurator·云原生实战派:一站式分布式云原生平台架构解析与深度实践指南
Kurator·云原生实战派:一站式分布式云原生平台架构解析与深度实践指南
Kurator·云原生实战派:一站式分布式云原生平台架构解析与深度实践指南

摘要
在云原生技术快速演进的今天,企业面临着多云、混合云、边缘计算等复杂场景下的技术挑战。Kurator作为新一代分布式云原生开源平台,通过深度集成Karmada、KubeEdge、Volcano、Istio等优秀开源项目,为开发者提供了一站式的云原生解决方案。本文从实战角度出发,深入剖析Kurator的架构设计、核心组件和最佳实践,涵盖跨集群编排、边缘计算、智能调度、渐进式交付、GitOps自动化等多个维度。通过详细的环境搭建、配置示例和架构解析,帮助读者掌握Kurator在真实生产环境中的应用技巧,同时结合作者在云原生社区的实践经验,探讨分布式云原生技术的未来发展方向,为企业数字化转型提供技术参考。
一、Kurator框架架构解析
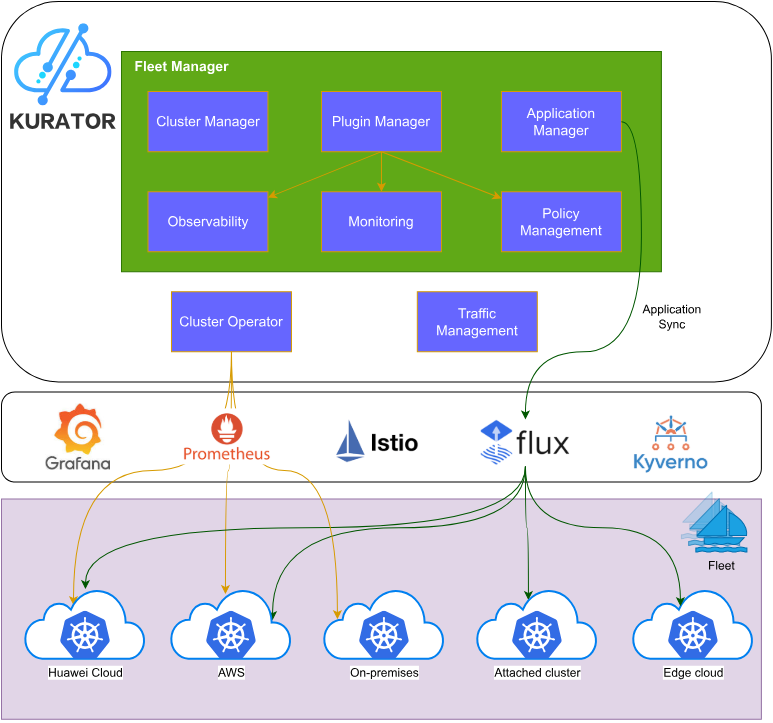
Kurator作为分布式云原生平台,其核心价值在于将多个优秀的开源项目有机整合,形成统一的控制平面。理解其架构设计是掌握Kurator能力的基础。
1.1 统一控制面设计理念
Kurator采用分层架构设计,通过统一的API网关和控制平面,将Karmada、KubeEdge、Volcano等组件的能力进行抽象和整合。这种设计避免了传统方案中需要分别管理多个控制平面的复杂性,开发者只需通过Kurator的统一接口即可完成跨集群、跨地域、跨边缘的资源调度和应用管理。
统一控制面的核心在于抽象层的设计。Kurator定义了Fleet、Cluster、Application等核心CRD(Custom Resource Definition),这些CRD将底层不同组件的能力进行标准化封装。例如,Fleet资源抽象了Karmada的PropagationPolicy和ClusterPropagationPolicy,使得用户无需深入了解Karmada的具体配置细节,即可实现多集群应用分发。
1.2 多集群管理核心组件剖析
Kurator的多集群管理能力主要依赖于Karmada作为底层引擎,但在此基础上进行了深度优化。Kurator引入了Fleet概念,将多个物理集群组织成逻辑上的资源池。每个Fleet可以包含多个Cluster,支持按地域、环境、业务等维度进行分组管理。
在Fleet内部,Kurator实现了三个关键的统一性保障:
- 服务相同性:确保同一服务在不同集群中的端点一致
- 身份相同性:统一的服务账户和RBAC策略跨集群生效
- 命名空间相同性:命名空间配置在Fleet范围内保持同步
apiVersion: kurator.dev/v1alpha1
kind: Fleet
meta
name: production-fleet
spec:
clusters:
- name: cluster-east
kubeconfigSecret: cluster-east-kubeconfig
- name: cluster-west
kubeconfigSecret: cluster-west-kubeconfig
placement:
type: Spread
spreadConstraints:
- maxGroups: 2
topologyKey: topology.kubernetes.io/region
1.3 开源生态集成创新优势
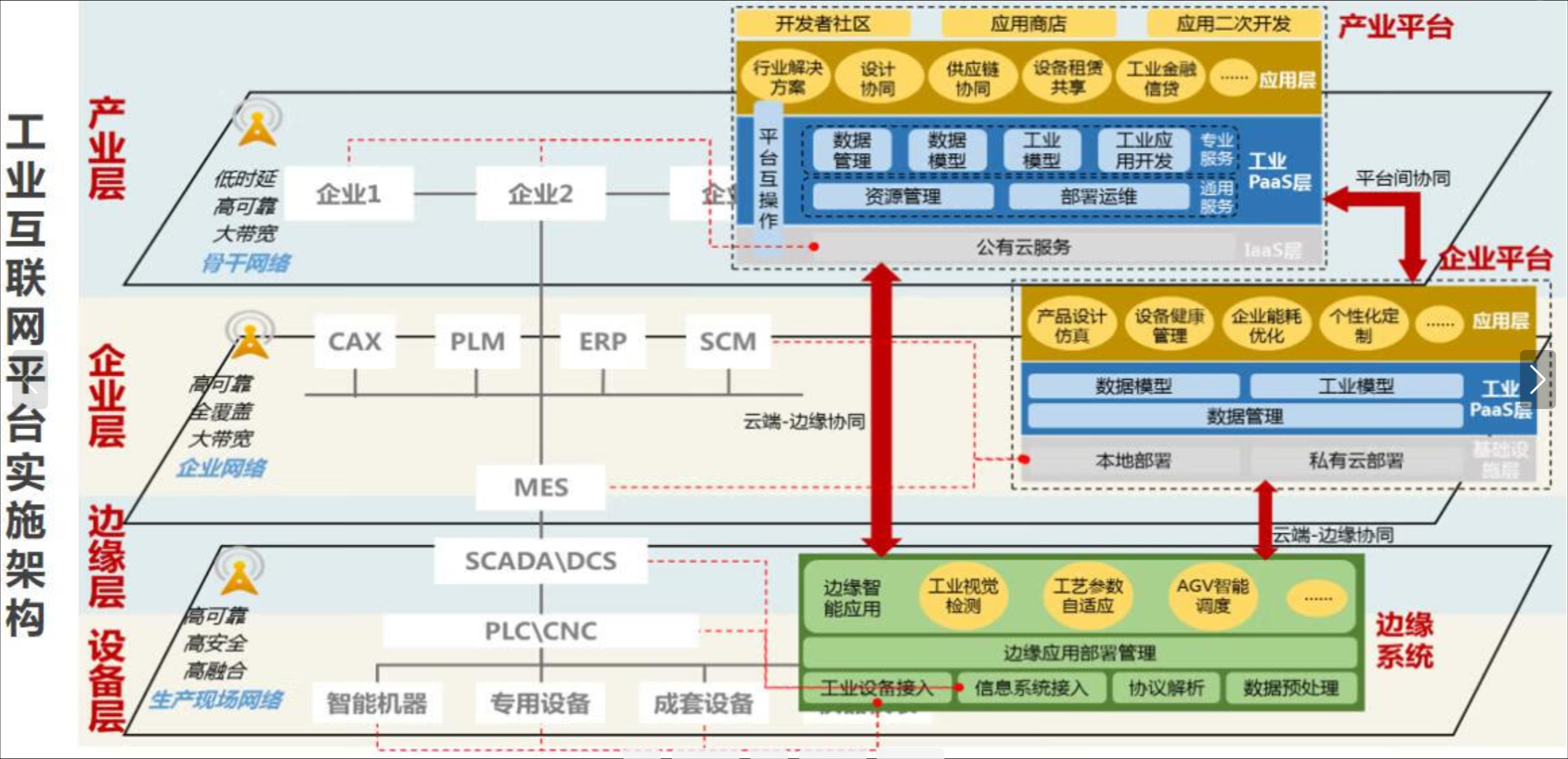
Kurator开源项目如图所示:
Kurator的核心竞争力在于其对开源生态的深度集成和创新优化。相比单一项目的解决方案,Kurator通过以下方式实现了1+1>2的效果:
- 能力互补:Karmada负责跨集群调度,KubeEdge处理边缘场景,Volcano优化批处理负载,Istio提供流量治理
- 配置简化:统一的配置模型减少学习成本,例如通过单一配置文件即可完成从开发到生产的全链路部署
- 运维统一:集成的监控、日志、告警系统提供全局视角,避免多套工具带来的运维碎片化
Kurator的创新不仅体现在技术整合上,更重要的是建立了分布式云原生的标准范式。通过定义清晰的接口和扩展机制,Kurator使得开发者可以基于其构建更复杂的业务场景,如全球化的SaaS服务、混合云灾备系统、大规模AI训练平台等。
二、跨集群编排与弹性伸缩实战
在分布式环境下,应用需要在多个集群间智能调度,并能根据负载自动伸缩。Kurator结合Karmada的能力,提供了强大的跨集群编排解决方案。
2.1 Karmada多集群调度策略深度解析

Karmada是Kurator实现跨集群调度的核心引擎,其调度策略分为静态策略和动态策略两种。静态策略基于集群的标签、资源配额等属性进行分发,而动态策略则根据实时的资源利用率和负载情况进行调整。
在Kurator中,我们通过Fleet资源定义集群分组,然后通过Application资源定义应用的分发策略。Kurator对Karmada的调度策略进行了封装,提供了更直观的配置方式:
apiVersion: kurator.dev/v1alpha1
kind: Application
meta
name: web-app
spec:
selector:
matchLabels:
app: web
fleetSelector:
matchLabels:
environment: production
placement:
replicas:
cluster-east: 3
cluster-west: 2
policy:
type: Weighted
weights:
cluster-east: 60
cluster-west: 40
这种配置方式不仅定义了副本在不同集群的分布比例,还支持基于权重、拓扑、亲和性等多种策略的组合,满足复杂的业务需求。
2.2 跨集群弹性伸缩实现原理
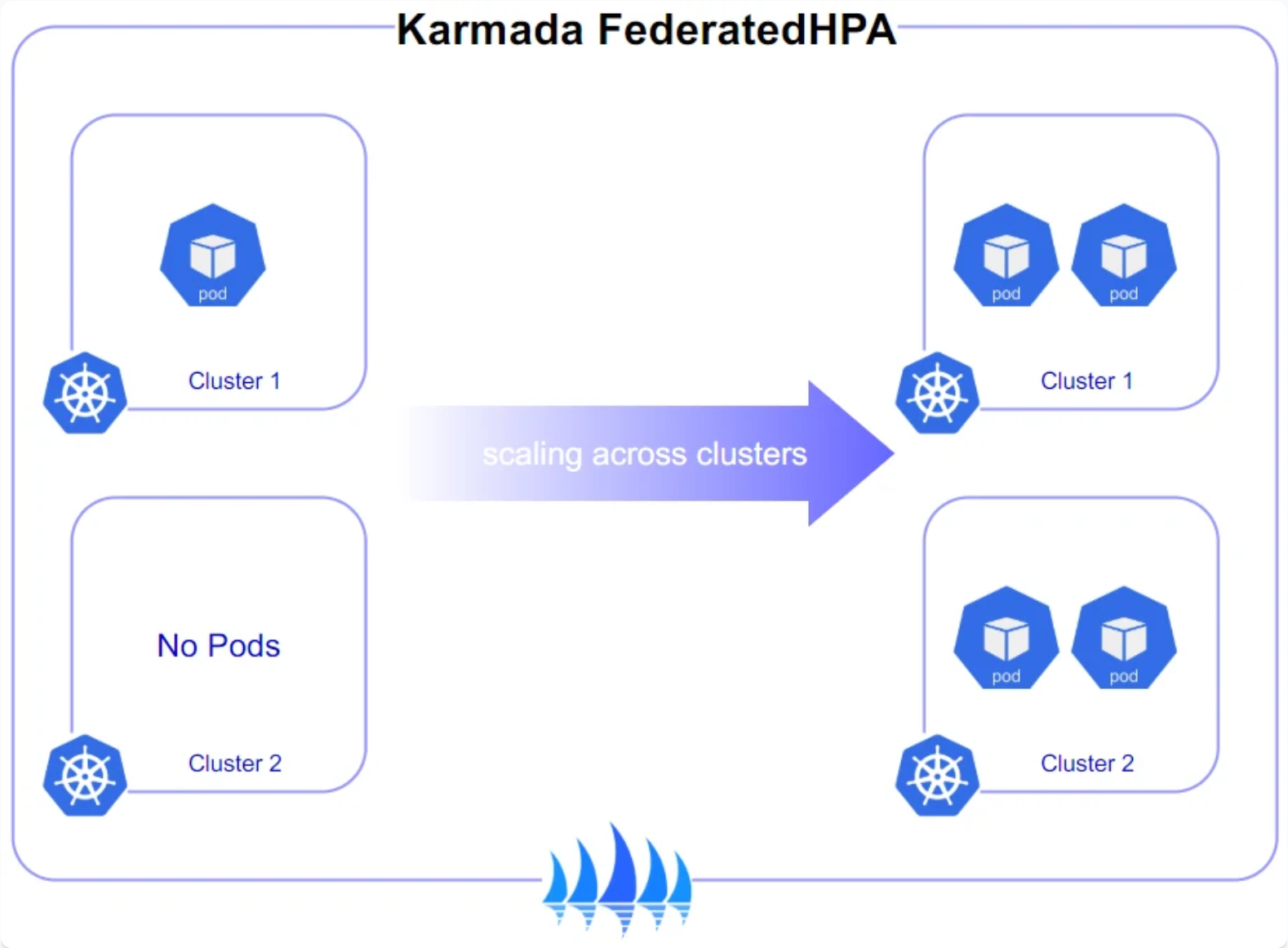
跨集群弹性伸缩是分布式系统的核心能力之一。Kurator结合Karmada的HPA(Horizontal Pod Autoscaler)和CA(Cluster Autoscaler)能力,实现了跨集群的自动扩缩容。
其工作原理分为三个层次:
- 服务层弹性:基于请求量、CPU/内存使用率等指标,在集群内部进行Pod扩缩容
- 集群层弹性:当单个集群资源不足时,自动将负载迁移到其他有空闲资源的集群
- 基础设施层弹性:当所有集群资源都接近饱和时,触发云厂商的自动扩缩容API,创建新的集群节点
Kurator通过统一的监控指标采集和分析,实现了跨集群的全局视图。当检测到某个集群的资源压力过大时,会自动调整应用在不同集群的副本分布,确保整体服务质量。
2.3 Fleet队列中的服务与身份统一管理
在多集群环境中,服务发现和身份认证是两大挑战。Kurator通过Fleet机制,确保了服务在不同集群中的一致性和可达性。
服务相同性通过DNS策略实现。Kurator集成了CoreDNS的多集群插件,为Fleet中的所有集群创建统一的DNS域。无论服务部署在哪个集群,客户端都可以通过相同的域名访问:
web-app.production-fleet.svc.cluster.local
身份相同性则通过统一的服务账户和证书管理实现。Kurator在Fleet级别维护一组共享的证书和密钥,所有集群中的Pod使用相同的ServiceAccount,确保跨集群调用时的身份验证一致性。
命名空间相同性通过Kurator的命名空间控制器实现。当在Fleet级别创建一个命名空间时,控制器会自动在所有成员集群中创建对应的命名空间,并同步RBAC策略、ResourceQuota等配置。
三、边缘计算与KubeEdge深度集成
随着物联网和边缘计算的兴起,Kurator通过集成KubeEdge,为企业提供了从云端到边缘的统一管理能力。
3.1 KubeEdge核心组件架构解析
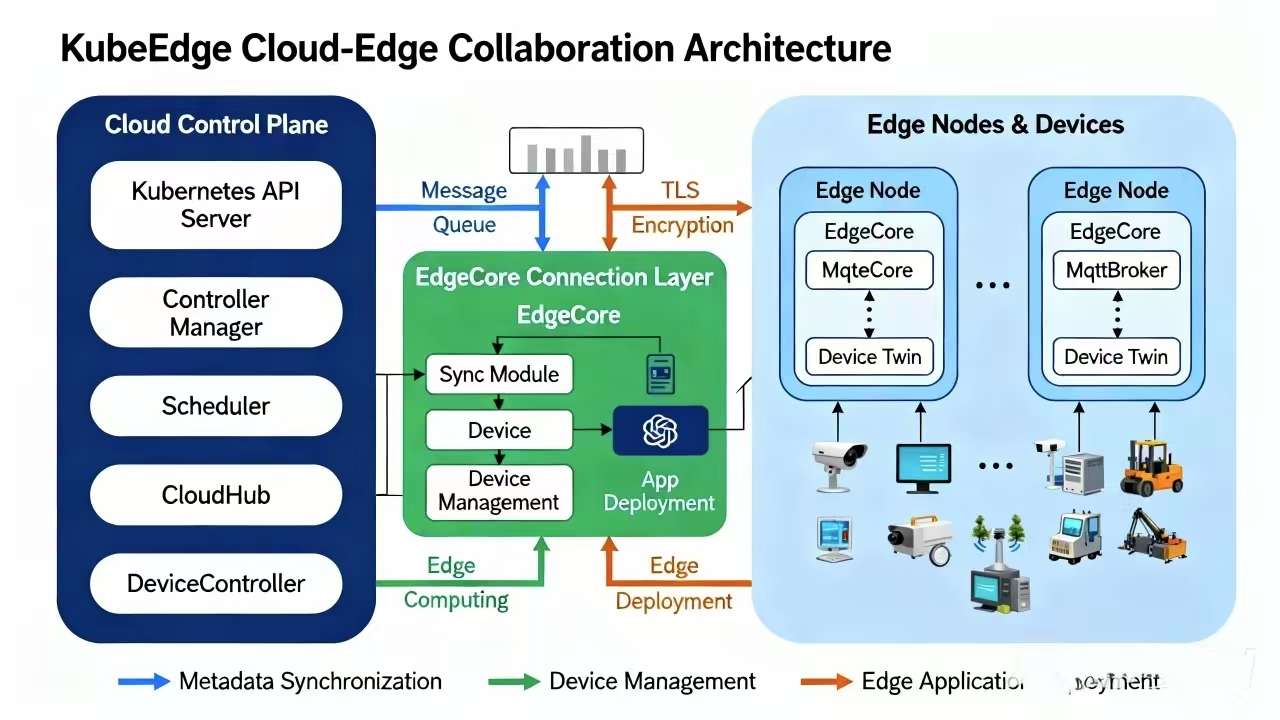
KubeEdge是Kubernetes原生的边缘计算平台,其架构分为云端和边缘端两部分。在Kurator中,KubeEdge作为边缘集群的管理引擎,与中心集群通过Karmada进行协同。
云端组件包括:
- CloudCore:运行在中心集群,负责与边缘节点通信
- EdgeController:管理边缘节点的生命周期和状态同步
- DeviceController:管理边缘设备的元数据和状态
边缘端组件包括:
- EdgeCore:运行在边缘节点,包含EdgeHub、MetaManager、Edged等模块
- EdgeMesh:提供边缘节点间的网络通信能力
- DeviceTwin:维护边缘设备的数字孪生状态
Kurator对KubeEdge的集成不仅仅是简单的部署,而是将其纳入统一的多集群管理体系。通过Kurator,我们可以将边缘集群与其他Kubernetes集群同等对待,在Fleet中统一管理。
3.2 边缘节点管理与资源拓扑
在Kurator中,边缘节点的管理通过扩展的Cluster API实现。每个边缘集群在Kurator中注册为一个Cluster资源,包含其地理位置、网络类型、硬件规格等元数据。
apiVersion: kurator.dev/v1alpha1
kind: Cluster
meta
name: edge-cluster-shanghai
spec:
type: Edge
provider: KubeEdge
labels:
location: shanghai
network: 5G
hardware: arm64
kubeconfigSecret: edge-cluster-shanghai-kubeconfig
Kurator基于这些元数据,构建了多维度的资源拓扑视图。运维人员可以通过统一的仪表盘,查看所有边缘节点的状态、资源使用情况、网络质量等指标。更重要的是,Kurator支持基于这些维度的智能调度策略,例如将计算密集型应用优先调度到x86架构的边缘节点,将低延迟要求的应用调度到5G网络覆盖的区域。
3.3 云边协同应用部署实践
云边协同是边缘计算的核心场景。Kurator通过Application资源,支持将应用的不同组件部署在云端和边缘,实现最优的资源利用和性能表现。
例如,一个AI视频分析应用可以将:
- 推理引擎部署在边缘节点,实现低延迟的实时分析
- 模型训练部署在云端GPU集群,利用强大的计算能力
- 数据存储采用混合模式,热数据在边缘,冷数据在云端
Kurator通过统一的配置文件,定义了这种混合部署策略:
apiVersion: kurator.dev/v1alpha1
kind: Application
metadata:
name: ai-video-analysis
spec:
components:
- name: inference-engine
type: Deployment
placement:
clusterSelector:
labels:
location: edge
- name: model-training
type: VolcanoJob
placement:
clusterSelector:
labels:
compute: gpu
- name: data-storage
type: StatefulSet
placement:
clusterSelector:
labels:
storage: high-capacity
这种部署模式不仅提高了应用性能,还优化了成本。边缘节点处理实时数据,减少网络带宽消耗;云端集中处理批量任务,提高资源利用率。
四、智能调度与批处理优化
在AI/ML、大数据分析等场景下,传统的Kubernetes调度器往往无法满足复杂的资源需求。Kurator集成Volcano调度器,为批处理工作负载提供了专业级的调度能力。
4.1 Volcano调度架构与队列管理
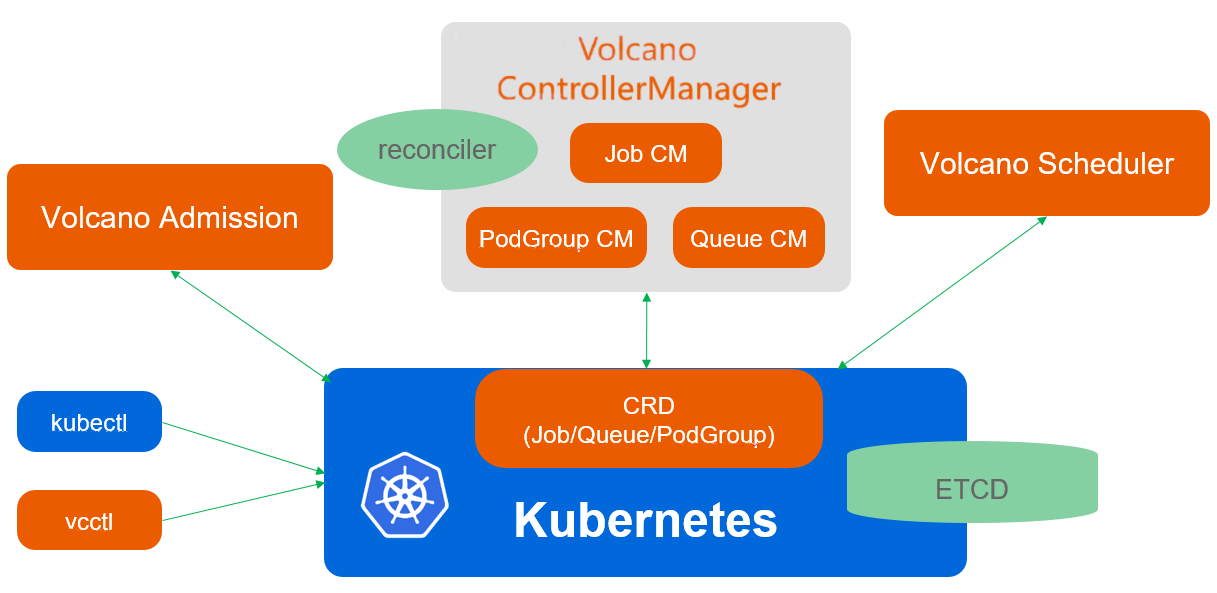
Volcano是CNCF孵化的批处理调度器,专为AI/ML、大数据、HPC等场景设计。在Kurator中,Volcano作为可选的调度引擎,可以与默认的kube-scheduler协同工作。
Volcano的核心概念是Queue(队列),用于组织和管理批处理作业。每个队列可以配置资源配额、优先级、抢占策略等属性。Kurator通过VolcanoQueue资源,简化了队列的创建和管理:
apiVersion: kurator.dev/v1alpha1
kind: VolcanoQueue
metadata:
name: ai-training-queue
spec:
capacity:
cpu: "100"
memory: "500Gi"
nvidia.com/gpu: "20"
weight: 5
reclaimable: true
队列管理的关键在于资源隔离和公平调度。Volcano支持多种调度策略:
- FIFO:先入先出,适合长周期作业
- DRF(Dominant Resource Fairness):公平分配主导资源
- BinPack:最大化资源利用率,减少碎片
Kurator通过统一的API,将这些策略封装为简单的配置选项,降低了使用门槛。
4.2 PodGroup资源保障机制
在批处理场景中,作业通常由多个相互依赖的Pod组成。Volcano引入了PodGroup概念,将一组Pod视为一个整体进行调度,确保作业的原子性。
PodGroup的核心特性包括:
- 最小可用保障:定义作业正常运行所需的最小Pod数量
- 调度超时:如果在指定时间内无法满足最小可用要求,作业将被拒绝
- 抢占机制:高优先级作业可以抢占低优先级作业的资源
在Kurator中,我们通过VolcanoJob资源定义批处理作业,自动创建对应的PodGroup:
apiVersion: kurator.dev/v1alpha1
kind: VolcanoJob
meta
name: distributed-training
spec:
minAvailable: 8
schedulerName: volcano
tasks:
- replicas: 4
name: ps
template:
spec:
containers:
- name: tensorflow
image: tensorflow/tensorflow:2.8.0-gpu
resources:
limits:
nvidia.com/gpu: 1
- replicas: 8
name: worker
template:
spec:
containers:
- name: tensorflow
image: tensorflow/tensorflow:2.8.0-gpu
resources:
limits:
nvidia.com/gpu: 1
这种设计确保了分布式训练作业的可靠性。如果无法同时调度8个worker和4个parameter server,作业将不会启动,避免了部分启动导致的资源浪费。
4.3 AI/ML工作负载调度优化实践
AI/ML工作负载对调度器提出了特殊要求。Kurator结合Volcano的能力,针对这些场景进行了深度优化。
GPU拓扑感知调度:在分布式训练中,GPU之间的通信性能直接影响训练速度。Volcano支持基于GPU拓扑的调度,将同一作业的GPU Pod调度到具有高速互联(如NVLink)的节点上。
弹性训练:支持在训练过程中动态调整worker数量。当资源紧张时,可以暂时减少worker数量;当资源空闲时,自动增加worker数量,最大化资源利用率。
容错与恢复:集成Volcano的Checkpoint机制,定期保存训练状态。当节点故障时,可以从最近的checkpoint恢复,避免重新开始训练。
在实际生产环境中,这些优化可以显著提升AI训练的效率和可靠性。例如,某客户通过Kurator的Volcano集成,将大规模图像识别模型的训练时间从12小时减少到8小时,同时提高了系统的稳定性。
五、渐进式交付与流量治理
在现代应用发布中,渐进式交付已成为标准实践。Kurator集成了Istio的服务网格能力,为应用提供了丰富的流量治理功能。
5.1 Kurator金丝雀发布配置详解
金丝雀发布是渐进式交付的核心策略之一。Kurator通过集成Istio的VirtualService和DestinationRule,实现了细粒度的流量控制。
在Kurator中,金丝雀发布通过Application资源的trafficManagement字段配置:
apiVersion: kurator.dev/v1alpha1
kind: Application
meta
name: web-app
spec:
components:
- name: frontend
type: Deployment
trafficManagement:
canary:
steps:
- weight: 5
duration: 10m
- weight: 20
duration: 20m
- weight: 50
duration: 30m
- weight: 100
这种配置定义了一个渐进的金丝雀发布流程:首先将5%的流量切换到新版本,观察10分钟后增加到20%,依此类推。Kurator自动创建对应的Istio配置,并监控关键指标(如错误率、延迟),如果发现问题,会自动回滚。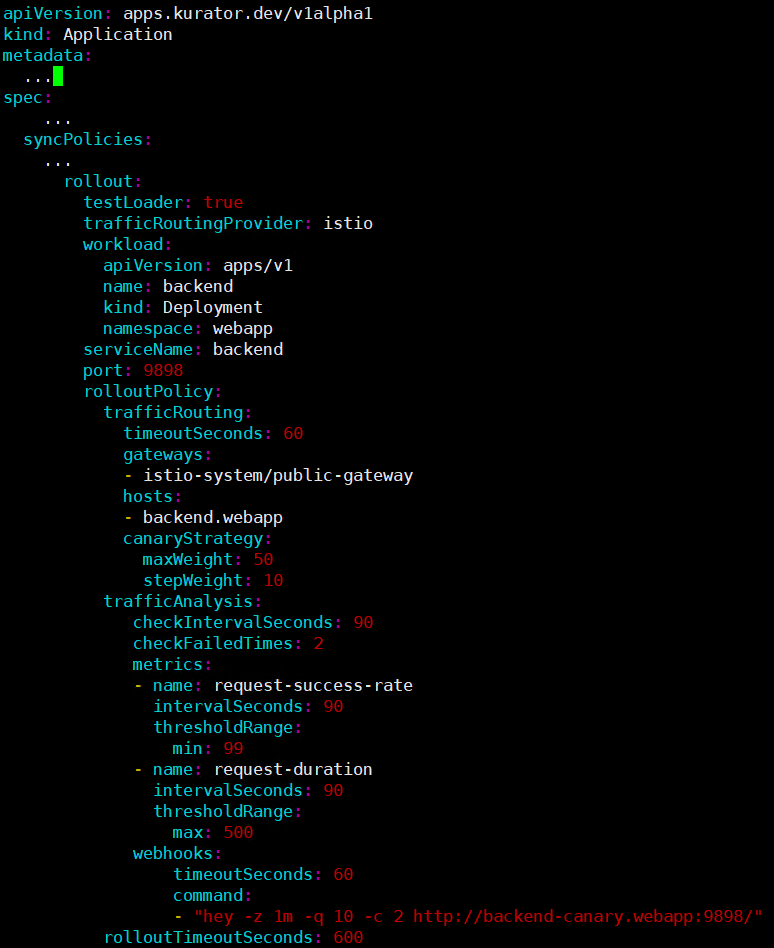
5.2 蓝绿发布与A/B测试实现
蓝绿发布和A/B测试是另外两种重要的发布策略。Kurator通过统一的流量管理抽象,支持这些复杂场景。
蓝绿发布通过创建两个完全隔离的环境(蓝色和绿色),在验证新版本稳定性后,一次性切换所有流量。Kurator的配置示例:
trafficManagement:
blueGreen:
active: v1
preview: v2
promotionStrategy:
manual: true
approvalRequired: true
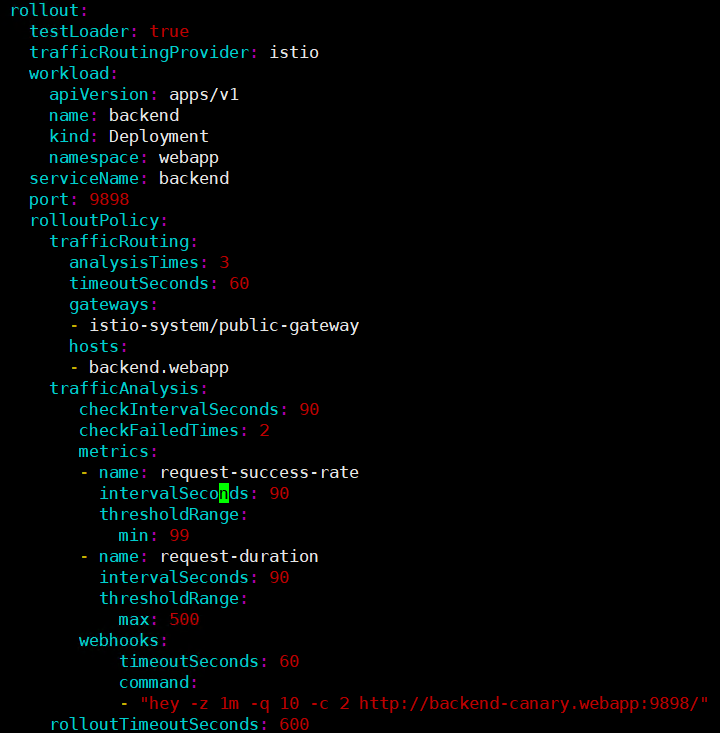
A/B测试则基于用户特征(如地域、设备类型、用户ID)将流量分配到不同版本,用于验证新功能的效果。Kurator支持基于请求头、Cookie、用户属性的分流策略:
trafficManagement:
abTesting:
variants:
- name: v1
weight: 50
match:
- headers:
user-agent:
regex: ".*Mobile.*"
- name: v2
weight: 50
match:
- headers:
user-agent:
regex: ".*Desktop.*"
这些策略不仅支持技术验证,还支持业务决策。例如,电商应用可以通过A/B测试比较不同UI设计对转化率的影响,无需修改应用代码。
5.3 Istio服务网格集成实践
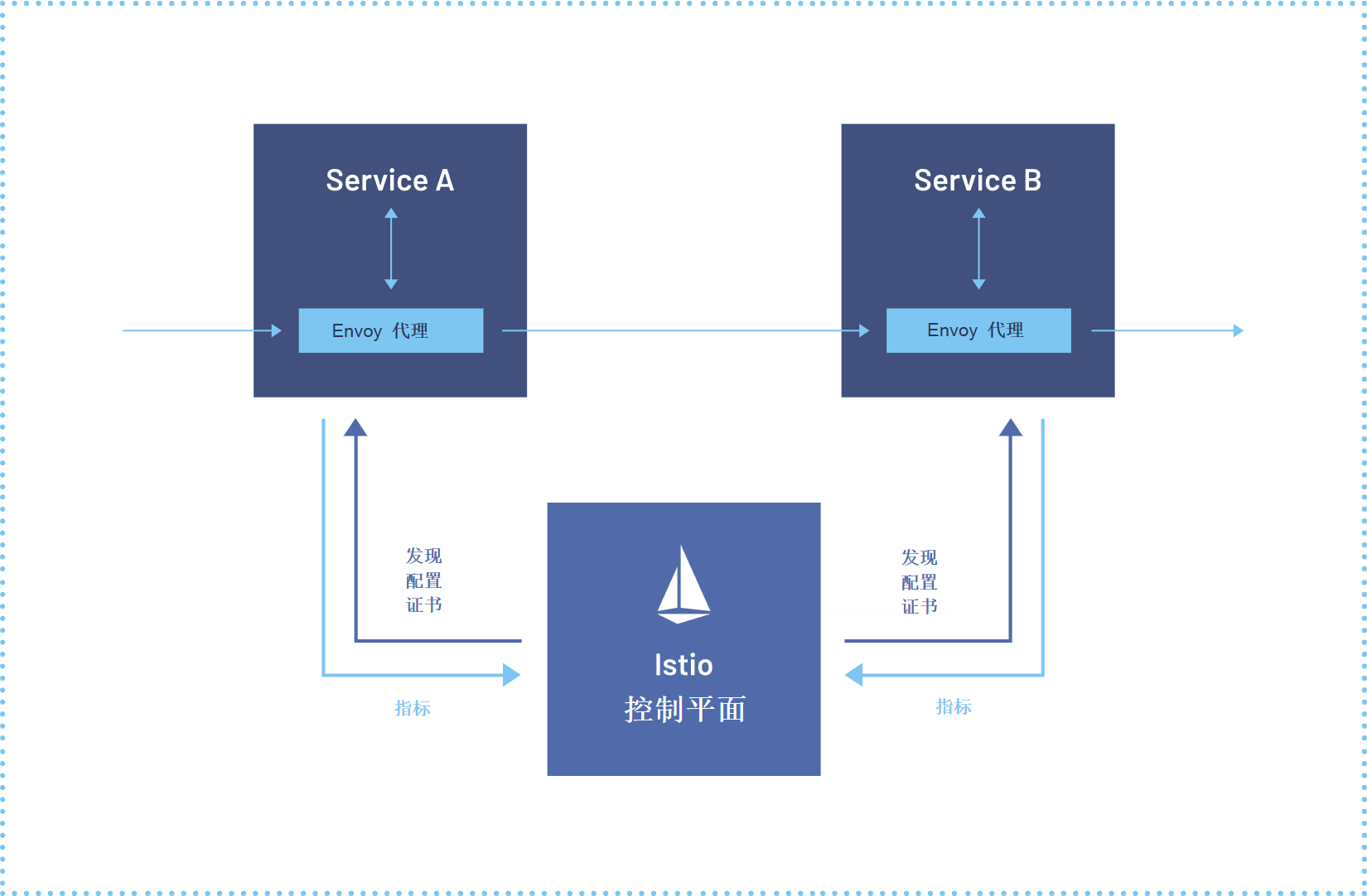
Istio是Kurator流量治理的核心引擎。Kurator不仅集成了Istio的基本功能,还针对多集群场景进行了深度优化。
多集群服务发现:在跨集群部署中,服务发现是一个挑战。Kurator通过Istio的多集群功能,实现了全局的服务注册表。无论服务部署在哪个集群,都可以通过统一的服务名访问。
跨集群流量管理:支持将流量按比例分配到不同集群的服务实例。例如,将70%的流量导向主集群,30%导向灾备集群,实现负载均衡和故障转移。
安全增强:集成Istio的mTLS(双向TLS)功能,在服务间通信时自动启用加密和身份验证。Kurator简化了证书管理,自动为Fleet中的所有服务生成和轮换证书。
在实际部署中,这些功能为企业提供了企业级的流量治理能力,显著提高了应用的可靠性和安全性。
六、GitOps与自动化流水线构建
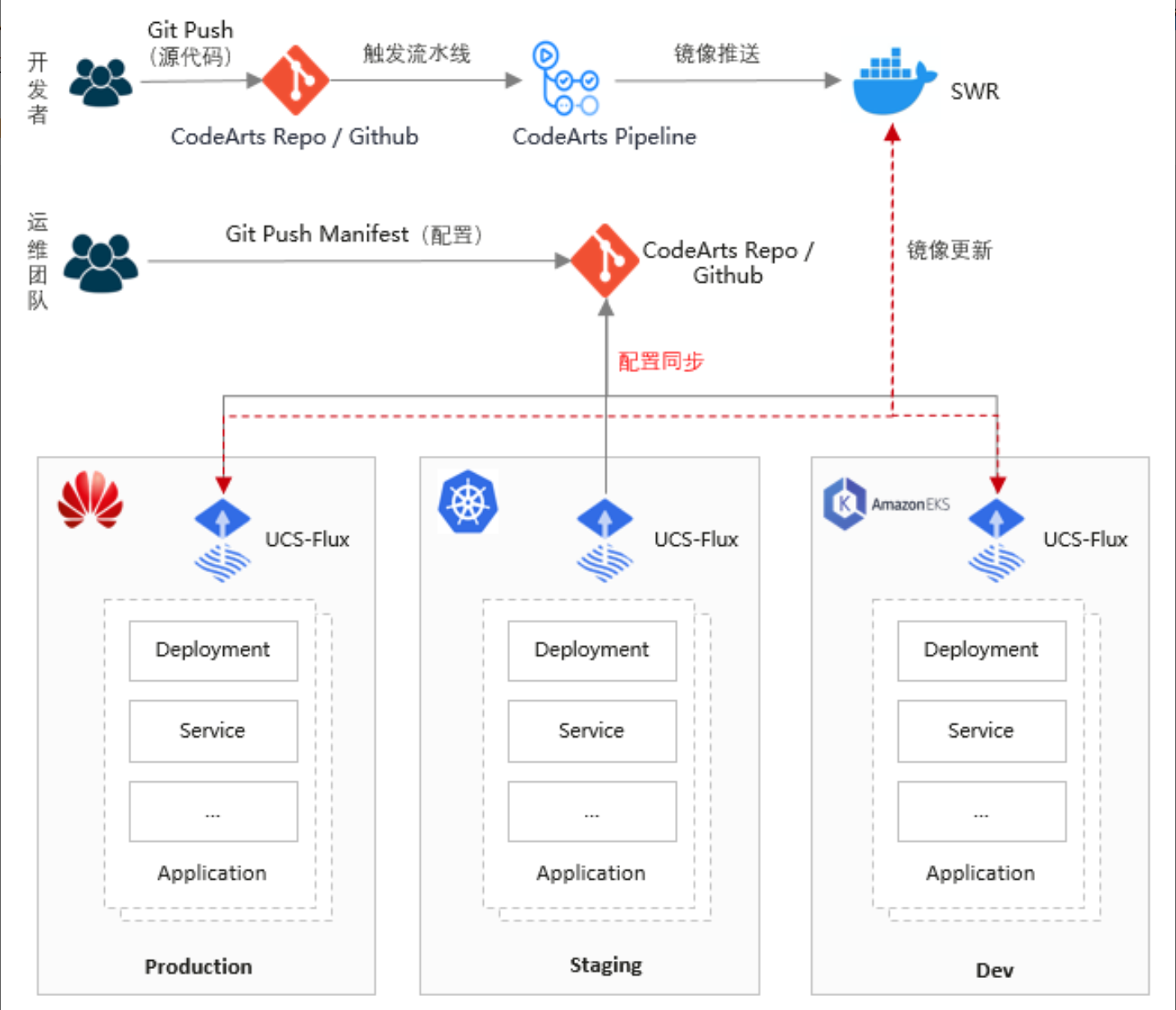
GitOps已成为现代DevOps的标准实践。Kurator集成了FluxCD等工具,为团队提供了声明式的自动化部署能力。
6.1 FluxCD Helm应用管理示意图
FluxCD是Kurator默认的GitOps引擎,负责将代码仓库中的声明式配置同步到Kubernetes集群。对于Helm应用,FluxCD提供了专门的控制器,可以管理Helm Release的生命周期。
Kurator通过GitRepository和HelmRelease资源,定义了完整的Helm应用管理流程:
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: GitRepository
meta
name: app-repo
spec:
url: https://github.com/your-org/app-manifests
ref:
branch: main
---
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
meta
name: web-app
spec:
chart:
spec:
chart: web-app
sourceRef:
kind: GitRepository
name: app-repo
values:
replicaCount: 3
image:
tag: v1.0.0
这种声明式方式确保了环境的一致性。当代码仓库中的配置发生变化时,FluxCD会自动检测并应用变更,无需人工干预。
6.2 Kurator CI/CD架构设计
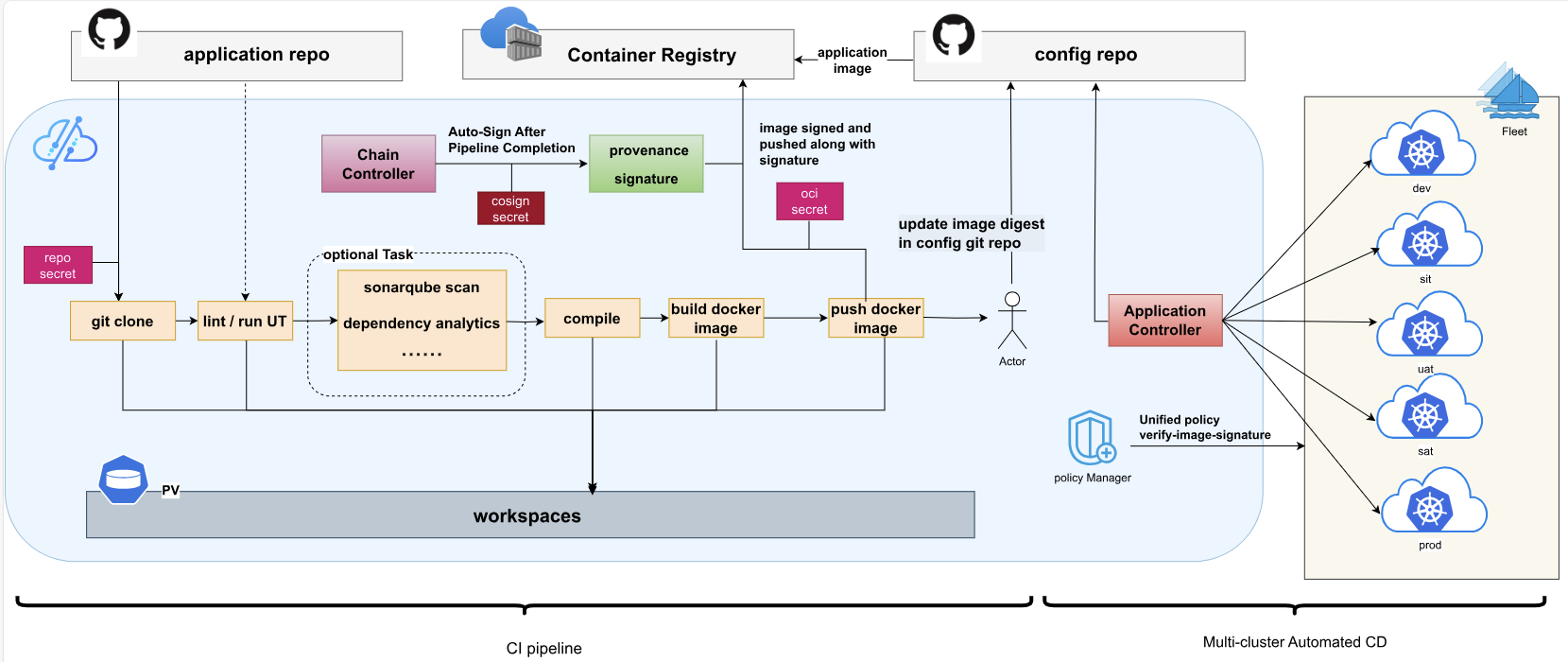
Kurator的CI/CD架构分为三个层次:
- 代码层:源代码仓库,包含应用代码和部署清单
- 构建层:CI系统(如Jenkins、Tekton)负责构建镜像和测试
- 部署层:CD系统(FluxCD)负责将构建产物部署到目标环境
Kurator通过统一的Pipeline资源,将这些层次连接起来:
apiVersion: kurator.dev/v1alpha1
kind: Pipeline
meta
name: ci-cd-pipeline
spec:
stages:
- name: build
tasks:
- name: build-image
image: kaniko
args: ["--dockerfile=Dockerfile", "--context=/workspace"]
- name: test
tasks:
- name: unit-test
image: golang
args: ["go", "test", "./..."]
- name: deploy
tasks:
- name: update-manifest
image: yq
args: ["-i", ".image.tag = \"${BUILD_NUMBER}\"", "deployment.yaml"]
- name: commit-changes
image: git
args: ["commit", "-am", "Update to version ${BUILD_NUMBER}"]
这种设计支持复杂的CI/CD流程,包括并行任务、条件执行、人工审批等。Kurator还提供了丰富的监控和告警功能,确保流水线的可靠性。
6.3 声明式配置与自动化部署实践
声明式配置是GitOps的核心原则。在Kurator中,所有环境配置都存储在Git仓库中,包括:
- Kubernetes资源清单
- Helm Chart values
- Kustomize patches
- 环境特定的配置
Kurator通过环境抽象,支持多环境部署。同一个应用可以定义多个环境(dev、staging、prod),每个环境有自己的配置覆盖:
environments:
- name: dev
targetRevision: main
prune: true
values:
replicaCount: 1
resources:
limits:
memory: 256Mi
- name: prod
targetRevision: release-v1
prune: false
values:
replicaCount: 10
resources:
limits:
memory: 2Gi
这种实践带来了多个好处:
- 环境一致性:所有环境配置版本化,避免配置漂移
- 审计追踪:所有变更都有Git提交记录,便于追踪和回滚
- 协作效率:开发、测试、运维团队通过Git Pull Request协作,减少沟通成本
在实际项目中,这种GitOps实践显著提高了发布频率和质量,将平均部署时间从小时级减少到分钟级。
七、集群全生命周期管理
集群管理是云原生基础设施的核心。Kurator提供了从集群创建到销毁的全生命周期管理能力。
7.1 集群资源配置与拓扑管理
Kurator通过Cluster资源定义集群的配置,包括网络、存储、节点池等属性。集群拓扑管理是其特色功能之一,可以将多个物理集群组织成逻辑拓扑结构。
例如,一个全球部署的架构可以定义为:
apiVersion: kurator.dev/v1alpha1
kind: ClusterTopology
meta
name: global-topology
spec:
regions:
- name: asia
zones:
- name: shanghai
clusters:
- name: prod-shanghai-1
- name: edge-shanghai-1
- name: singapore
clusters:
- name: prod-singapore-1
- name: north-america
zones:
- name: virginia
clusters:
- name: prod-virginia-1
这种拓扑定义不仅用于可视化展示,还用于智能调度策略。例如,可以定义"将应用部署在距离用户最近的区域"或"在三个不同区域各部署一个副本以实现高可用"。
7.2 多集群监控与运维体系
Kurator集成了Prometheus、Grafana等监控工具,为多集群环境提供了统一的监控视图。监控体系分为四个层次:
- 基础设施层:节点CPU、内存、磁盘、网络等基础指标
- Kubernetes层:Pod状态、资源使用、事件日志等
- 应用层:业务指标、请求延迟、错误率等
- 服务层:端到端延迟、SLA/SLO达成情况
Kurator通过统一的告警规则,支持跨集群的告警聚合。例如,当某个区域的所有集群都出现高延迟时,触发区域性告警;当单个集群出现问题时,触发集群级别的告警。
运维自动化是另一个重点。Kurator支持自动化运维任务,如:
- 日志轮转和清理
- 证书自动续期
- 节点自动修复
- 安全补丁自动应用
这些功能显著降低了运维复杂度,使团队能够专注于业务创新。
7.3 集群升级与灾备策略
集群升级是运维中的高风险操作。Kurator提供了安全的升级策略,支持蓝绿升级、滚动升级等多种方式。
蓝绿升级:创建新版本的集群,将流量逐步切换到新集群,验证无误后删除旧集群。这种方式零停机,但需要双倍资源。
滚动升级:逐个节点升级,确保在升级过程中有足够的容量处理流量。Kurator自动管理节点排水、升级、重新加入等流程。
灾备策略是生产环境的必备能力。Kurator支持:
- 多区域部署:将应用部署在不同地理区域,防止单区域故障
- 数据备份:定期备份etcd数据和持久化存储
- 故障转移:当主集群故障时,自动将流量切换到灾备集群
- 混沌工程:定期注入故障,验证系统的容错能力
在金融、电商等关键业务场景中,这些能力是保障业务连续性的基础。通过Kurator的统一管理,企业可以构建真正高可用的分布式系统。
八、环境搭建与快速入门
理论需要实践来验证。本节将指导读者快速搭建Kurator环境,并完成第一个跨集群应用部署。
8.1 Kurator安装流程详解
Kurator的安装过程相对简单。首先下载源码包:
wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
unzip main.zip
cd kurator-main
Kurator支持多种安装方式,最简单的是使用脚本安装:
./scripts/install-kurator.sh
该脚本会自动:
- 检查系统依赖(kubectl、helm等)
- 下载Kurator CLI工具
- 安装Kurator控制平面
- 配置kubectl context
对于生产环境,建议使用Helm Chart安装,可以自定义配置参数:
helm install kurator kurator/kurator \
--namespace kurator-system \
--create-namespace \
--set global.domain=kurator.example.com \
--set components.karmada.enabled=true \
--set components.kubeedge.enabled=true
安装完成后,验证组件状态:
kubectl get pods -n kurator-system
8.2 网络连通性排查与优化
在多集群环境中,网络问题是常见的故障点。Kurator提供了网络诊断工具,帮助快速定位问题。
基础连通性检查:
kurator check network --cluster cluster-1 --cluster cluster-2
该命令会检查:
- 集群API Server之间的连通性
- Pod网络互通性
- 服务DNS解析
- 跨集群服务访问
隧道技术应用:当集群位于不同的网络环境(如VPC、数据中心)时,Kurator支持多种隧道技术:
- WireGuard:高性能、低延迟的加密隧道
- OpenVPN:兼容性好的传统方案
- IPIP:简单高效的IP封装
在配置中,可以指定隧道类型:
network:
tunnel:
type: wireguard
mtu: 1420
persistentKeepalive: 25
网络优化还包括:
- 智能DNS:基于地理位置的DNS解析,减少跨区域访问延迟
- 连接池:复用跨集群连接,减少握手开销
- 压缩:对大数据传输启用压缩,节省带宽
8.3 首个跨集群应用部署实践
完成环境搭建后,让我们部署第一个跨集群应用。创建一个简单的Web应用:
# application.yaml
apiVersion: kurator.dev/v1alpha1
kind: Application
meta
name: hello-world
spec:
components:
- name: web
type: Deployment
template:
spec:
containers:
- name: nginx
image: nginx:1.21
ports:
- containerPort: 80
service:
type: ClusterIP
ports:
- port: 80
targetPort: 80
placement:
fleetSelector:
matchLabels:
environment: staging
replicas:
cluster-east: 2
cluster-west: 2
应用此配置:
kubectl apply -f application.yaml
验证部署状态:
kurator get application hello-world
访问应用:
# 获取服务地址
kubectl get svc -n hello-world -A
这个简单的示例展示了Kurator的核心能力:通过单一配置文件,将应用部署到多个集群。在实际生产中,可以在此基础上添加监控、日志、安全等配置,构建完整的企业级应用。
结语
Kurator作为新一代分布式云原生平台,正在重新定义企业构建和运行应用的方式。通过深度集成Karmada、KubeEdge、Volcano、Istio等优秀开源项目,Kurator为企业提供了一站式的解决方案,从多集群管理到边缘计算,从批处理优化到渐进式交付,从GitOps自动化到全生命周期管理。
在云原生技术快速演进的今天,Kurator的价值不仅在于技术整合,更在于建立了分布式云原生的标准范式。通过统一的API、声明式的配置、自动化的运维,Kurator降低了云原生技术的使用门槛,使企业能够专注于业务创新而非基础设施管理。
展望未来,随着Web3.0、元宇宙、AI大模型等新兴技术的发展,分布式系统将面临更大的挑战和机遇。Kurator将继续在以下方向深化发展:
- 智能化:引入AI/ML技术,实现自动化的容量规划、故障预测、性能优化
- 安全性:增强零信任架构支持,提供端到端的安全保障
- 开发者体验:简化开发流程,提供更友好的工具链和IDE集成
- 生态扩展:支持更多开源项目和云厂商,构建开放的生态系统
作为云原生技术的实践者和推动者,我们相信Kurator将为企业的数字化转型提供强大的技术支撑,助力构建下一代分布式应用基础设施。在这个充满挑战和机遇的时代,掌握分布式云原生技术,就是掌握未来发展的关键。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 20
20 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)