【前瞻创想】Kurator分布式云原生平台:构建企业级多云与边缘计算统一管理的实战指南
【前瞻创想】Kurator分布式云原生平台:构建企业级多云与边缘计算统一管理的实战指南
【前瞻创想】Kurator分布式云原生平台:构建企业级多云与边缘计算统一管理的实战指南

摘要
本文深度剖析Kurator开源分布式云原生平台,从架构设计到实战部署,全面解读其如何整合Kubernetes、Karmada、KubeEdge、Volcano、Istio等顶级开源项目,打造统一的多云、边缘计算管理平台。文章包含环境搭建、Fleet集群管理、边缘计算GitOps实践、KubeEdge边缘架构、Volcano批处理调度、统一服务治理等核心内容,通过真实代码示例和架构分析,为企业构建分布式云原生基础设施提供专业指导,同时探讨Kurator未来发展方向和企业落地策略,助力企业数字化转型。
1. Kurator云原生平台架构全景解析
分布式云原生架构参考图: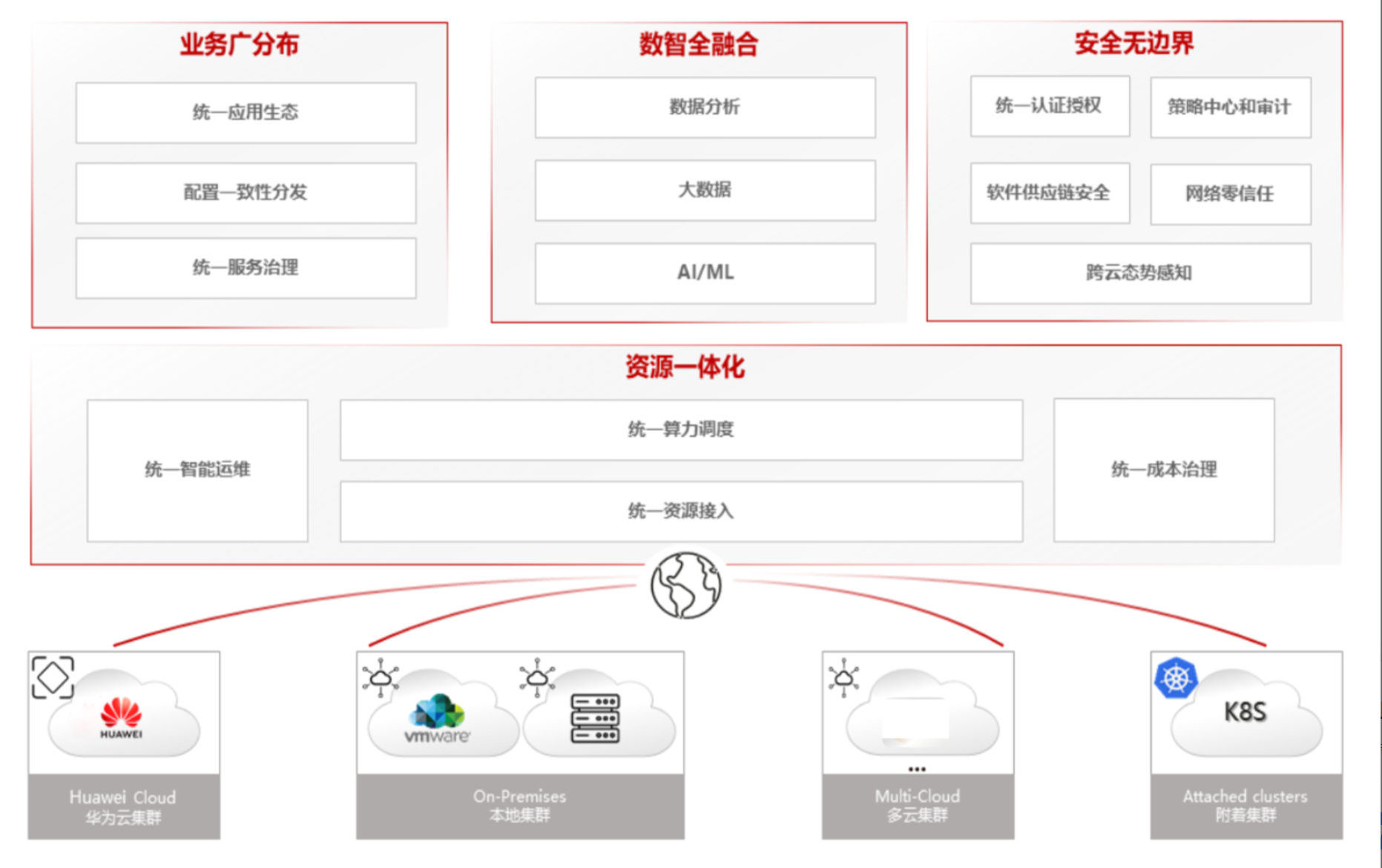
Kurator作为新一代分布式云原生平台,不是简单的技术堆砌,而是通过深度整合多个顶级开源项目,构建了一套完整的分布式基础设施管理解决方案。其架构设计充分考虑了现代企业面临的多云、混合云、边缘计算等复杂场景,提供了统一的抽象层和管理界面。
1.1 核心技术栈与集成生态
Kurator的核心竞争力在于其强大的集成能力。平台原生集成了Kubernetes作为基础编排引擎,Karmada负责多集群管理与调度,KubeEdge支撑边缘计算场景,Volcano处理批处理与AI工作负载,Istio提供服务网格能力,Prometheus构建监控体系,FluxCD实现GitOps持续交付。这种"站在巨人肩膀上"的设计理念,使得Kurator能够快速构建企业级功能,同时保持与社区的紧密同步。
Kurator并非简单地将这些组件打包,而是通过统一的API层、控制平面和插件机制,实现了组件间的深度协同。例如,Karmada的集群调度策略可以与Volcano的作业调度策略联动,KubeEdge的边缘节点可以无缝接入Karmada的多集群管理体系,Istio的服务网格能力可以跨多个物理集群提供统一的服务治理。
1.2 分布式云原生架构设计哲学
Kurator架构设计的核心哲学是"统一但不集中"。在控制平面上,Kurator提供了统一的管理入口和API,但在数据平面上,保持了各集群、各边缘节点的高度自治性。这种设计平衡了集中管理的便利性和分布式系统的弹性与可扩展性。
Kurator采用了分层架构设计:基础设施层负责物理/虚拟资源管理;集群管理层负责Kubernetes集群的生命周期管理;应用管理层负责应用部署、服务治理、监控告警;策略管理层负责安全策略、资源配额、合规控制。每一层都提供了标准化的接口和可插拔的组件,支持不同厂商、不同环境的灵活集成。
2. Kurator环境搭建与初始化配置
要体验Kurator的强大功能,首先需要完成环境搭建。Kurator支持多种部署方式,包括本地开发环境、单集群部署和生产级多集群部署。本节将详细介绍如何从源码开始,构建一个完整的Kurator环境。
2.1 系统要求与前置条件
构建Kurator环境需要满足以下基本要求:
- 一台或多台Linux服务器(推荐Ubuntu 20.04或CentOS 7+)
- 每台服务器至少4核8GB内存
- Docker 20.10+ 或 containerd 1.4+
- Kubernetes 1.21+ 集群(至少一个)
- kubectl 1.21+ 命令行工具
- Git 2.18+ 版本控制工具
- 网络连通性:确保各节点间网络互通,特别是需要访问GitHub等外部仓库
对于边缘计算场景,还需要准备边缘设备(如x86服务器、ARM开发板等),并确保边缘节点能够与中心集群通信。如果是测试环境,可以使用Minikube或Kind在单机上模拟多集群环境。
# 检查系统环境
cat /etc/os-release
docker version
kubectl version --client
git --version
2.2 源码获取与安装流程
Kurator采用源码构建方式,需要先克隆官方仓库。根据要求,使用以下命令获取源码:
# 克隆Kurator源码仓库
git clone https://github.com/kurator-dev/kurator.git
cd kurator
# 或者使用wget方式
# wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
# unzip main.zip
# mv kurator-main kurator
# cd kurator
可以看到这是项目的gitCode源码
我们可以拉取下来
git clone https://github.com/kurator-dev/kurator.git
源码文件如下,接下来就可以使用了
可以注意到,这个命令kurator version可以看到版本号
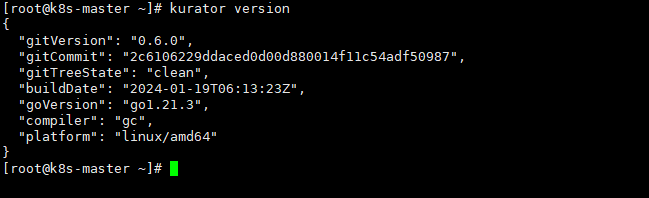
获取源码后,需要安装依赖和构建工具。Kurator使用Go语言开发,需要Go 1.18+环境:
# 安装Go环境(如果尚未安装)
wget https://golang.org/dl/go1.19.4.linux-amd64.tar.gz
sudo tar -C /usr/local -xzf go1.19.4.linux-amd64.tar.gz
export PATH=$PATH:/usr/local/go/bin
# 验证Go版本
go version
# 安装构建依赖
make deps
Kurator提供了便捷的安装脚本,可以一键部署核心组件:
# 构建Kurator CLI工具
make build
# 验证CLI工具
./bin/kurator version
# 安装Kurator到Kubernetes集群
./bin/kurator install --components all
安装过程会部署Kurator的核心组件,包括Fleet Manager、Policy Engine、Scheduler等。可以通过kubectl命令查看安装状态:
# 检查Kurator相关Pod状态
kubectl get pods -n kurator-system
# 预期输出类似:
# NAME READY STATUS RESTARTS AGE
# kurator-controller-manager-0 2/2 Running 0 5m
# kurator-webhook-server-0 1/1 Running 0 5m
# karmada-controller-manager-0 1/1 Running 0 4m
# ...
2.3 验证安装与基础配置
安装完成后,需要验证Kurator核心功能是否正常工作。首先配置kubectl使用Kurator上下文:
# 设置kubeconfig
export KUBECONFIG=$PWD/kubeconfig/kurator-kubeconfig
# 验证集群连通性
kubectl get nodes
# 查看Kurator自定义资源
kubectl get crds | grep kurator
接下来,配置Kurator的基本参数,如集群注册端点、认证信息等:
# 创建kurator-system命名空间配置
apiVersion: v1
kind: Namespace
metadata:
name: kurator-system
---
# 配置Kurator全局参数
apiVersion: config.kurator.dev/v1alpha1
kind: KuratorConfig
meta
name: default
namespace: kurator-system
spec:
clusterRegistration:
enabled: true
endpoint: "https://kurator-controller.kurator-system.svc.cluster.local:443"
policyEngine:
enabled: true
mode: "enforce"
scheduler:
enabled: true
provider: "karmada"
应用配置:
kubectl apply -f kurator-config.yaml
验证Kurator API服务是否正常:
# 测试Kurator API
curl -k https://kurator-api.kurator-system.svc.cluster.local:443/healthz
# 预期返回: ok
至此,Kurator基础环境搭建完成,可以开始注册集群、部署应用等高级操作。在生产环境中,还需要配置高可用、备份恢复、监控告警等企业级功能。
3. Fleet集群管理与统一调度实践
Fleet是Kurator的核心概念,代表一组逻辑上关联的Kubernetes集群。通过Fleet,Kurator实现了跨集群的统一管理、调度、配置同步和策略治理。本节将深入探讨Fleet的工作原理和实际应用场景。
3.1 Fleet架构设计与工作原理
Fleet架构官方参考图: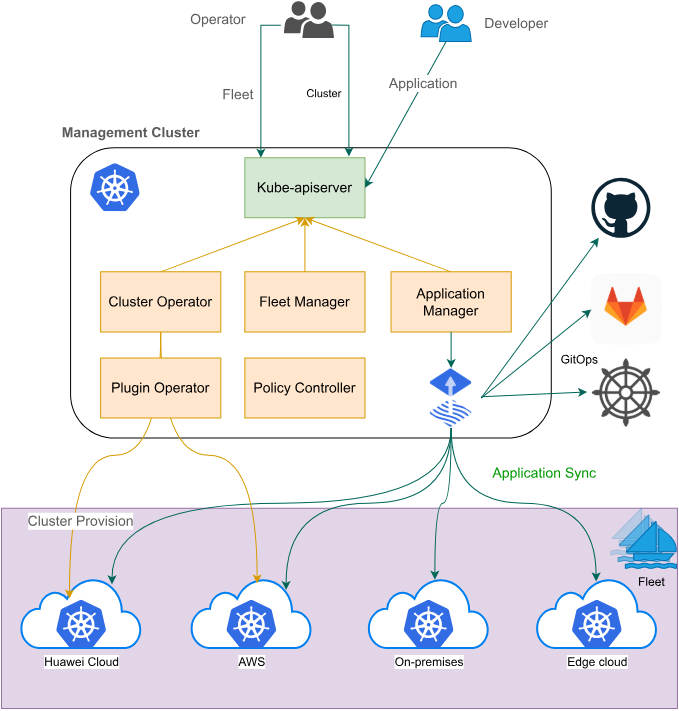
Fleet架构的核心是控制平面与数据平面的分离。控制平面运行在中心集群,负责集群注册、策略分发、状态收集;数据平面分布在各个成员集群,负责执行具体操作、上报状态。这种架构保证了即使在部分集群网络中断的情况下,其他集群仍能正常工作。
Fleet Manager是控制平面的核心组件,它维护着所有注册集群的状态信息,包括集群健康度、资源使用率、标签属性等。当用户创建Fleet资源时,Fleet Manager会根据集群标签选择符合条件的集群,并将Fleet配置分发到这些集群。每个成员集群上运行的Fleet Agent负责接收配置、执行操作,并定期上报状态。
Fleet的设计支持多层次的组织结构。企业可以创建多个Fleet,例如"生产Fleet"、“测试Fleet”、"边缘Fleet"等,每个Fleet可以包含不同地域、不同环境的集群。这种分层设计使得策略管理更加灵活,可以针对不同Fleet应用不同的治理规则。
3.2 多集群注册与资源拓扑管理
集群资源拓扑结构参考图: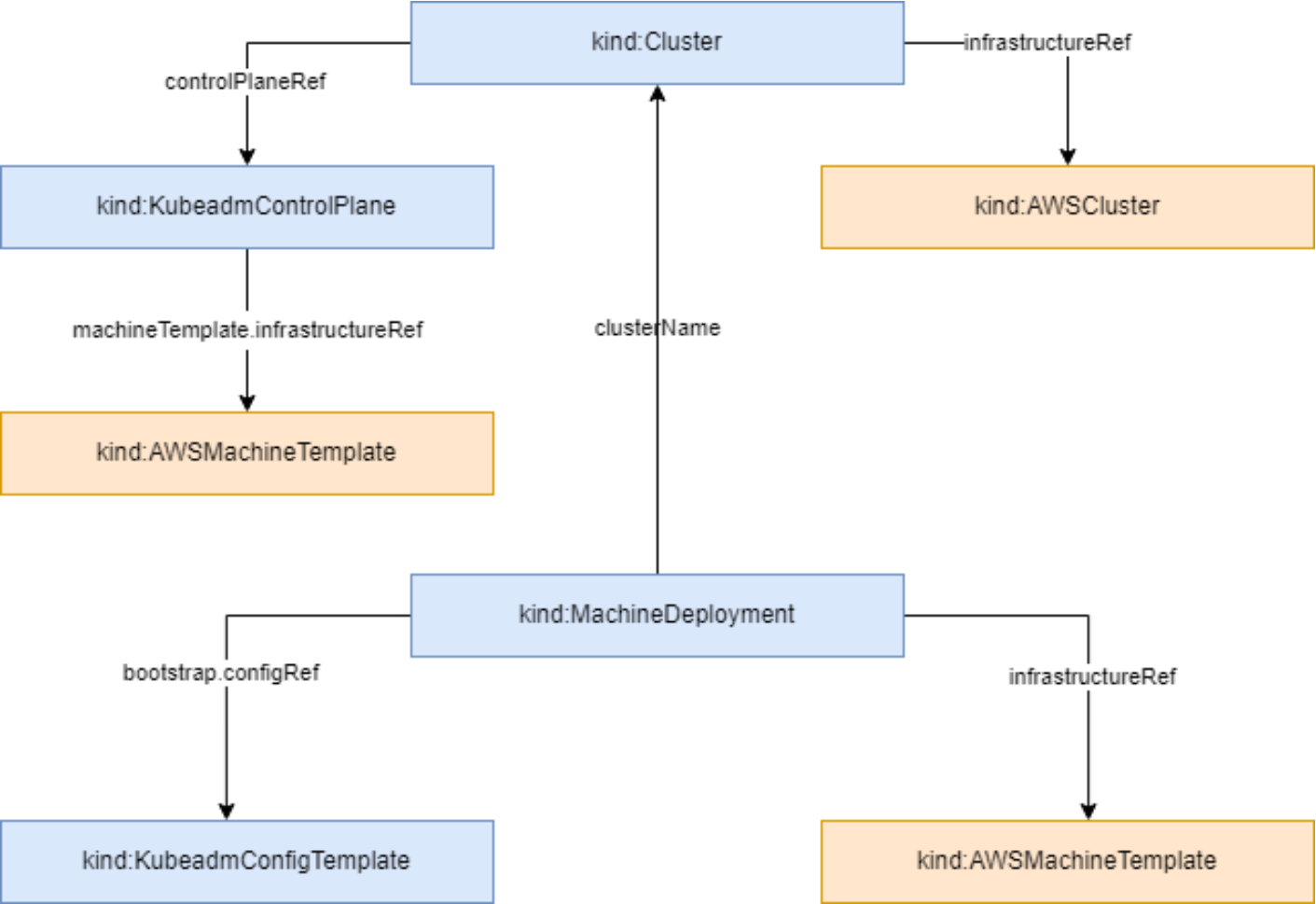
向Fleet注册集群是使用Kurator的第一步。注册过程包括集群发现、认证配置、资源同步等步骤。以下是一个典型的集群注册流程:
# 创建Fleet资源
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: production-fleet
namespace: kurator-system
spec:
clusters:
- name: cluster-east-1
kubeconfigSecret: cluster-east-1-kubeconfig
- name: cluster-west-1
kubeconfigSecret: cluster-west-1-kubeconfig
- name: edge-cluster-1
kubeconfigSecret: edge-cluster-1-kubeconfig
placement:
clusterSelector:
matchLabels:
environment: production
region: [east, west]
在注册集群前,需要先创建kubeconfig的Secret:
# 为每个集群创建kubeconfig Secret
kubectl create secret generic cluster-east-1-kubeconfig \
--from-file=kubeconfig=./clusters/cluster-east-1/kubeconfig \
-n kurator-system
注册完成后,可以通过Kurator CLI查看集群拓扑:
# 查看Fleet状态
./bin/kurator get fleet production-fleet -n kurator-system -o wide
# 预期输出:
# NAME CLUSTERS READY AGE
# production-fleet 3 3/3 10m
#
# CLUSTER NAME STATUS NODES VERSION
# cluster-east-1 Ready 5 v1.24.0
# cluster-west-1 Ready 3 v1.23.8
# edge-cluster-1 Ready 2 v1.22.15
Kurator提供了丰富的集群拓扑视图,包括物理拓扑(地理位置、网络区域)、逻辑拓扑(业务分组、环境分类)、资源拓扑(CPU、内存、存储分布)等。这些信息为后续的调度策略提供了数据基础。
3.3 统一调度策略与跨集群弹性伸缩
Kurator 统一策略管理参考图: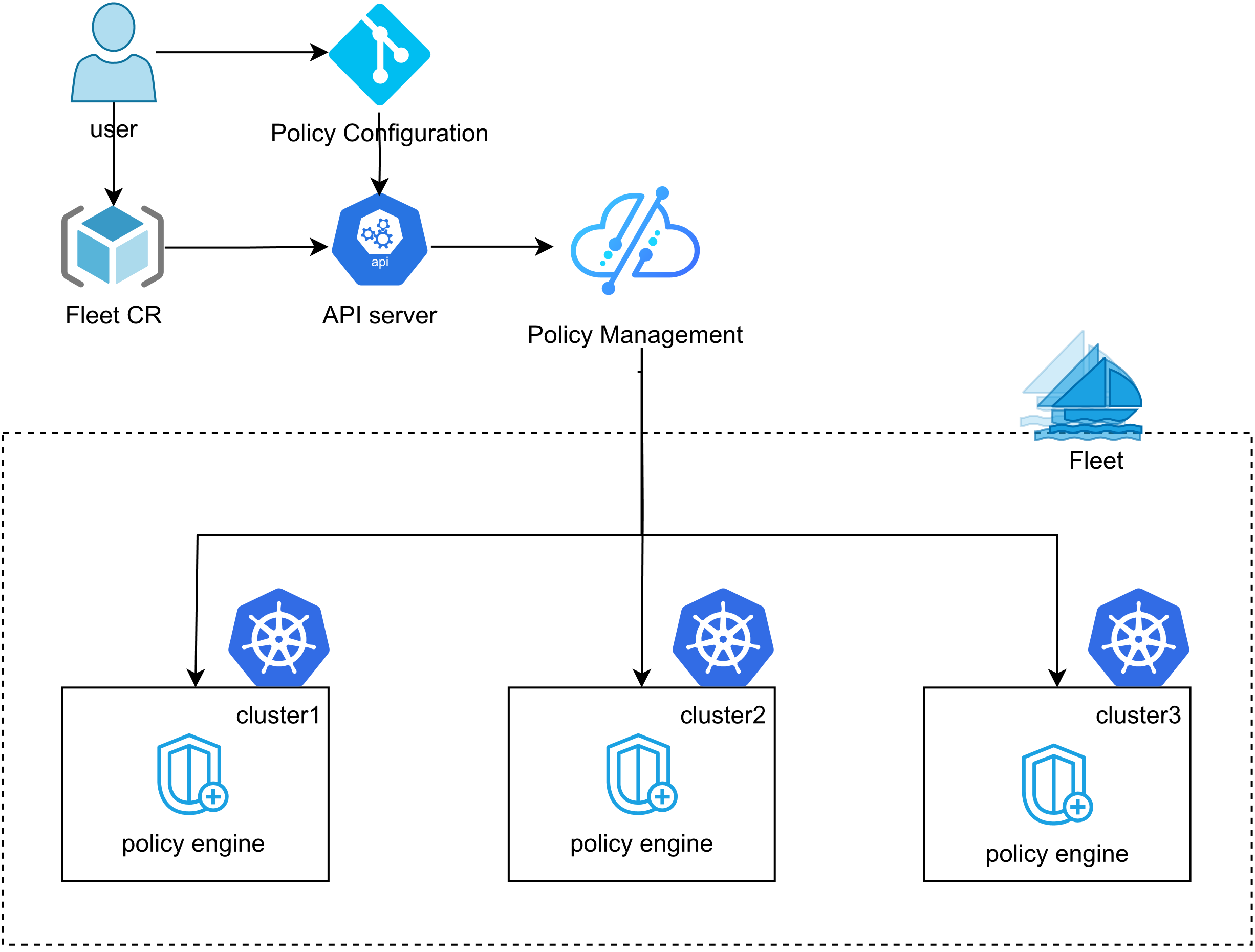
Karmada跨集群弹性伸缩策略参考图: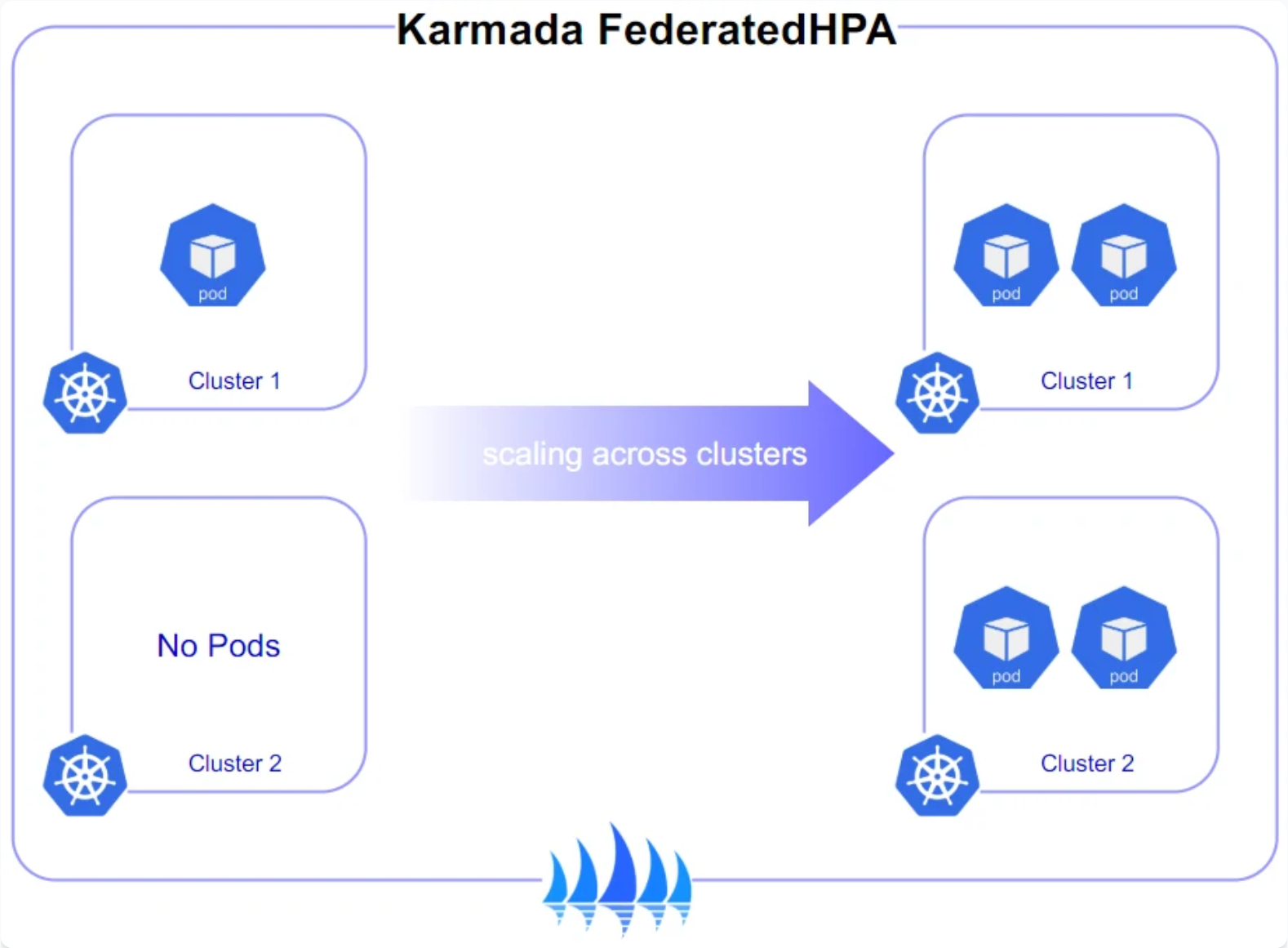
Kurator的统一调度能力基于Karmada实现,但通过Fleet抽象层提供了更易用的接口。调度策略包括静态调度(部署时确定位置)和动态调度(运行时调整位置)。以下是一个跨集群弹性伸缩的示例:
# 创建跨集群Deployment
apiVersion: apps.kurator.dev/v1alpha1
kind: FederatedDeployment
meta
name: nginx-federated
namespace: default
spec:
placement:
clusterSelector:
matchLabels:
environment: production
template:
meta
labels:
app: nginx
spec:
replicas: 10
selector:
matchLabels:
app: nginx
template:
meta
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.21
resources:
requests:
memory: "128Mi"
cpu: "100m"
limits:
memory: "256Mi"
cpu: "500m"
overrides:
- targetCluster:
name: cluster-east-1
replicas: 6 # 60%流量在东部集群
- targetCluster:
name: cluster-west-1
replicas: 4 # 40%流量在西部集群
- targetCluster:
name: edge-cluster-1
replicas: 0 # 边缘集群暂不部署
当业务负载变化时,可以通过策略自动调整各集群的副本数:
# 创建弹性伸缩策略
apiVersion: autoscaling.kurator.dev/v1alpha1
kind: FederatedHPA
meta
name: nginx-federated-hpa
namespace: default
spec:
targetRef:
apiVersion: apps.kurator.dev/v1alpha1
kind: FederatedDeployment
name: nginx-federated
minReplicas: 5
maxReplicas: 50
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
scaleDownStabilizationWindow: 300s
scaleStrategies:
- clusterName: cluster-east-1
weight: 60 # 60%的扩容优先在东部集群
- clusterName: cluster-west-1
weight: 40 # 40%的扩容优先在西部集群
- clusterName: edge-cluster-1
weight: 10 # 10%的扩容在边缘集群(当边缘有需求时)
这种跨集群弹性伸缩能力在应对地域性流量峰值时特别有价值。例如,当东部地区用户活跃度激增时,系统可以自动将更多副本调度到东部集群,减少跨地域网络延迟,提升用户体验。同时,通过权重配置,可以确保核心业务始终有足够的资源保障。
4. 边缘计算场景下的GitOps实践
边缘计算中的 GitOps官方参考图: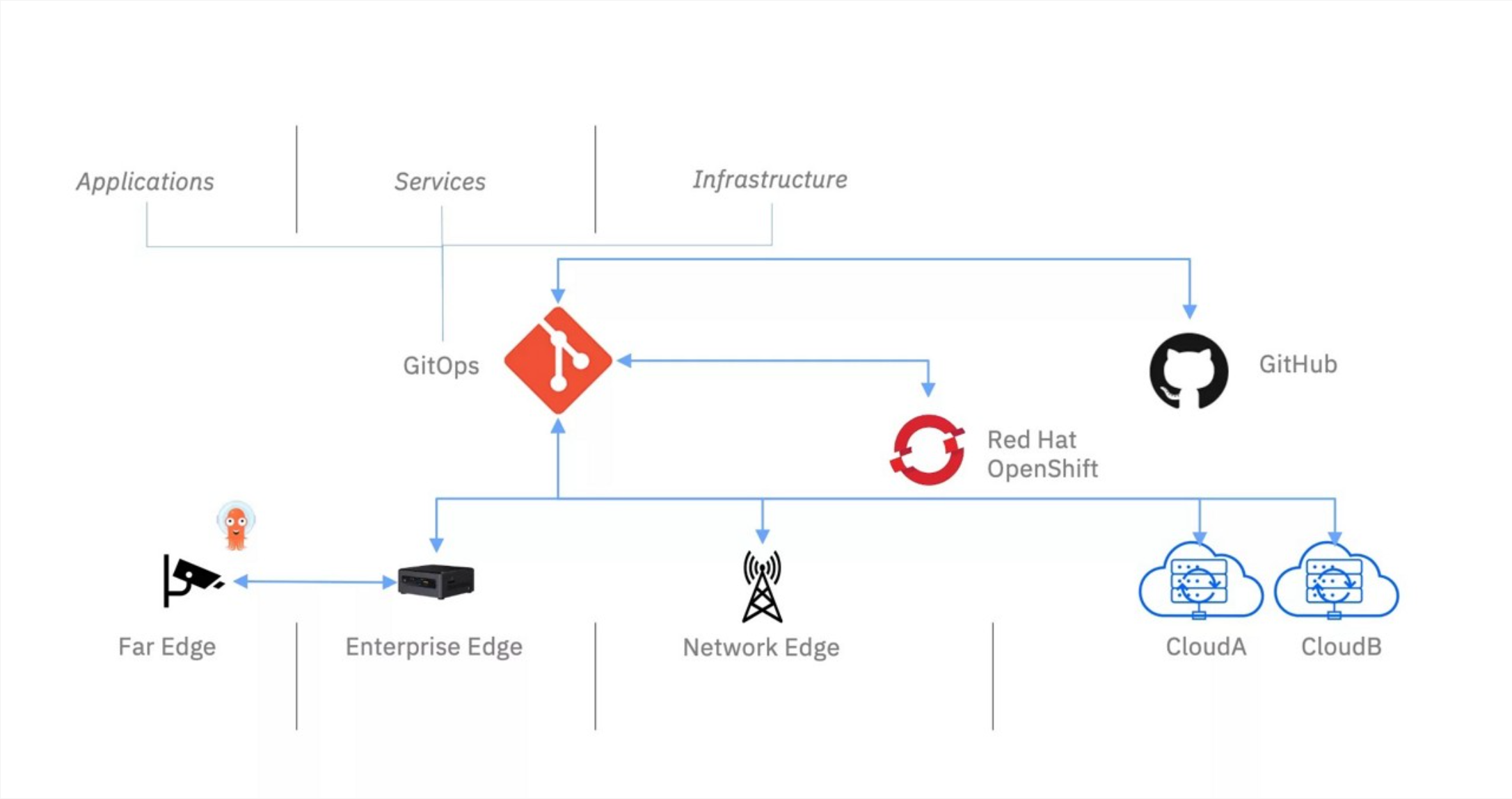
边缘计算场景对部署和管理提出了独特挑战:网络不稳定、设备异构、运维复杂。GitOps作为声明式基础设施管理的最佳实践,与Kurator结合,为边缘计算提供了理想的解决方案。本节将深入探讨如何在边缘场景中实施GitOps。
4.1 GitOps理念与Kurator集成架构
GitOps实现方式官方参考图: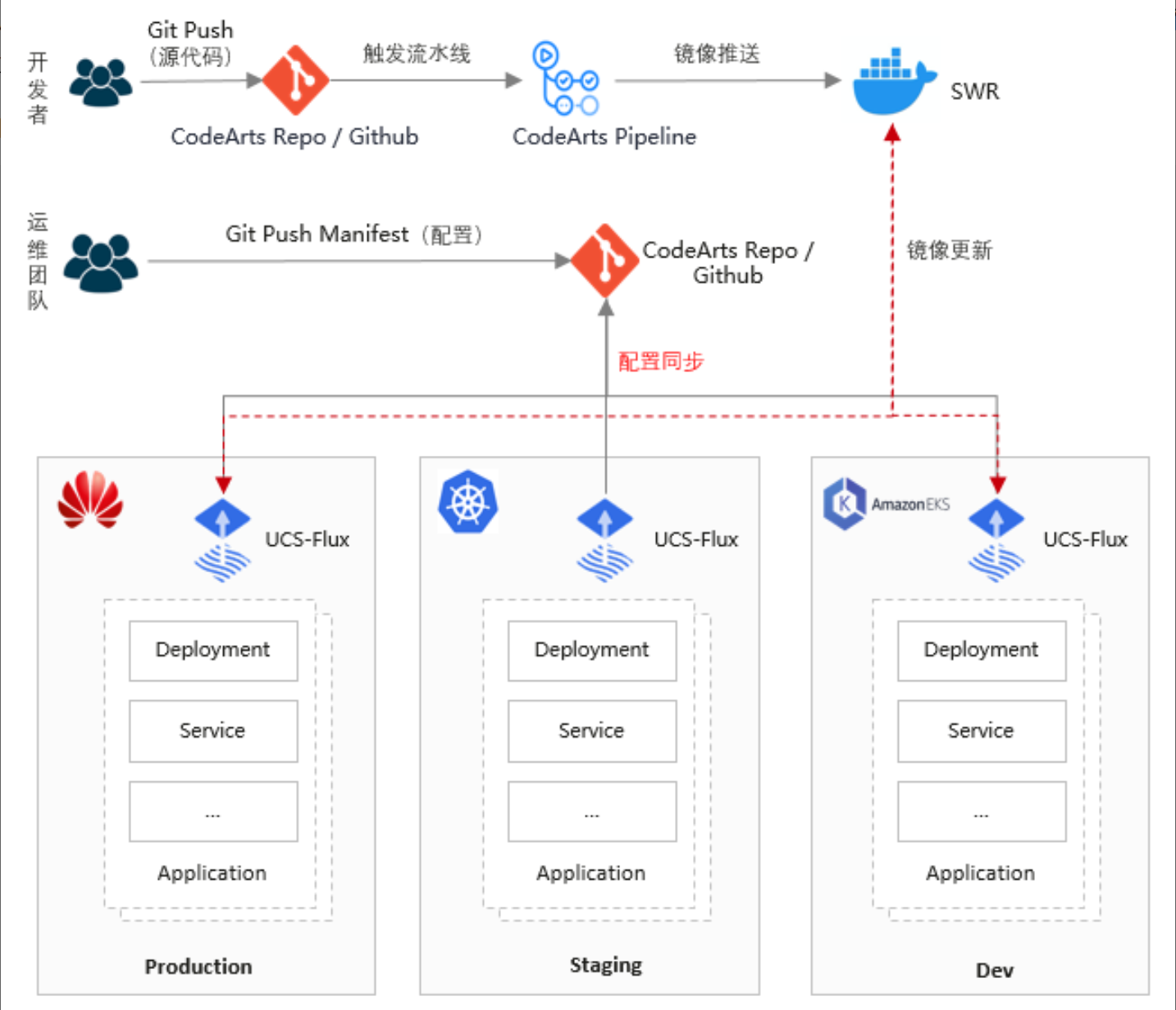
GitOps的核心理念是将系统的期望状态存储在Git仓库中,通过自动化流程确保实际状态与期望状态一致。在边缘计算场景中,这一理念尤为重要,因为边缘环境往往网络不稳定,需要离线自治能力。
Kurator通过深度集成FluxCD,实现了完整的GitOps流程。架构上分为三层:Git仓库层存储期望状态,Kurator控制平面负责策略分发和状态收集,边缘节点执行实际操作。关键创新在于引入了"边缘优先"的设计:当边缘节点与中心断开连接时,仍能基于本地缓存的配置继续工作,并在恢复连接后自动同步状态。
在边缘场景中,GitOps流程需要考虑网络分区、带宽限制、设备资源约束等因素。Kurator通过分层同步策略解决了这些问题:核心配置(如安全策略)强制同步,应用配置按需同步,大文件(如容器镜像)通过边缘缓存优化。
4.2 FluxCD与Helm应用的边缘部署
以下是一个典型的边缘GitOps配置示例,展示如何使用FluxCD和Helm在边缘集群部署应用:
# 创建GitRepository资源,指向包含边缘应用配置的Git仓库
apiVersion: source.toolkit.fluxcd.io/v1beta2
kind: GitRepository
meta
name: edge-apps-repo
namespace: kurator-system
spec:
url: https://github.com/your-org/edge-apps
ref:
branch: main
interval: 1m
timeout: 20s
secretRef:
name: git-repo-secret
---
# 创建HelmRepository,存储边缘应用的Helm chart
apiVersion: source.toolkit.fluxcd.io/v1beta2
kind: HelmRepository
meta
name: edge-charts
namespace: kurator-system
spec:
url: https://charts.your-org.com/edge
interval: 5m
---
# 创建Kustomization,定义如何应用Git仓库中的配置
apiVersion: kustomize.toolkit.fluxcd.io/v1beta2
kind: Kustomization
meta
name: edge-apps
namespace: kurator-system
spec:
targetNamespace: edge-apps
interval: 2m
path: "./clusters/edge-cluster-1"
prune: true
sourceRef:
kind: GitRepository
name: edge-apps-repo
decryption:
provider: sops
secretRef:
name: sops-age-key
在Git仓库中,边缘应用的配置可能包含HelmRelease资源:
# clusters/edge-cluster-1/apps/sensor-collector.yaml
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: sensor-collector
namespace: edge-apps
spec:
chart:
spec:
chart: sensor-collector
version: "1.2.0"
sourceRef:
kind: HelmRepository
name: edge-charts
interval: 5m
targetNamespace: edge-apps
values:
replicaCount: 1
resources:
requests:
memory: "64Mi"
cpu: "50m"
limits:
memory: "128Mi"
cpu: "200m"
edgeSpecific:
offlineMode: true # 启用离线模式
dataRetention: "24h" # 本地数据保留时间
syncInterval: "5m" # 与中心同步间隔
这种配置方式使得边缘应用可以独立演进,同时保持与中心策略的一致性。当Git仓库中的配置发生变化时,FluxCD会自动检测并应用变更,无需人工干预。
4.3 边缘-云协同的自动化工作流
在实际生产环境中,边缘-云协同需要更复杂的工作流。以下是一个完整的边缘GitOps工作流示例,包括代码提交、镜像构建、配置更新、边缘部署等环节:
# .github/workflows/edge-deployment.yaml
name: Edge Application Deployment
on:
push:
branches: [ main ]
paths:
- 'edge-apps/**'
pull_request:
branches: [ main ]
paths:
- 'edge-apps/**'
jobs:
build-and-deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up QEMU
uses: docker/setup-qemu-action@v2
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v2
- name: Login to Container Registry
uses: docker/login-action@v2
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GHCR_TOKEN }}
- name: Build and push Docker image
uses: docker/build-push-action@v3
with:
context: ./edge-apps/sensor-collector
platforms: linux/amd64,linux/arm64
push: true
tags: |
ghcr.io/${{ github.repository }}/sensor-collector:${{ github.sha }}
ghcr.io/${{ github.repository }}/sensor-collector:latest
- name: Update Helm Chart values
run: |
VERSION=${{ github.sha }}
sed -i "s|imageTag: .*|imageTag: $VERSION|" edge-apps/charts/sensor-collector/values.yaml
- name: Commit and push changes
run: |
git config user.name 'GitHub Actions'
git config user.email 'actions@github.com'
git add edge-apps/charts/sensor-collector/values.yaml
git commit -m "Update sensor-collector image to ${{ github.sha }}" || echo "No changes to commit"
git push
- name: Verify deployment
run: |
kubectl wait --for=condition=ready pod -l app=sensor-collector -n edge-apps --timeout=300s
kubectl logs -l app=sensor-collector -n edge-apps --tail=10
这个工作流实现了完整的CI/CD管道:当开发者提交代码到edge-apps目录时,自动构建多架构Docker镜像,更新Helm chart配置,提交变更到Git仓库,最后验证部署结果。边缘设备上的FluxCD会自动检测Git仓库变化,并部署新版本应用。
Kurator通过这种GitOps方式,实现了边缘计算的"基础设施即代码"理念,使得边缘节点的管理与中心云原生环境保持一致的体验和流程,大大降低了边缘计算的复杂性。
5. KubeEdge边缘计算架构深度剖析
KubeEdge架构参考图: 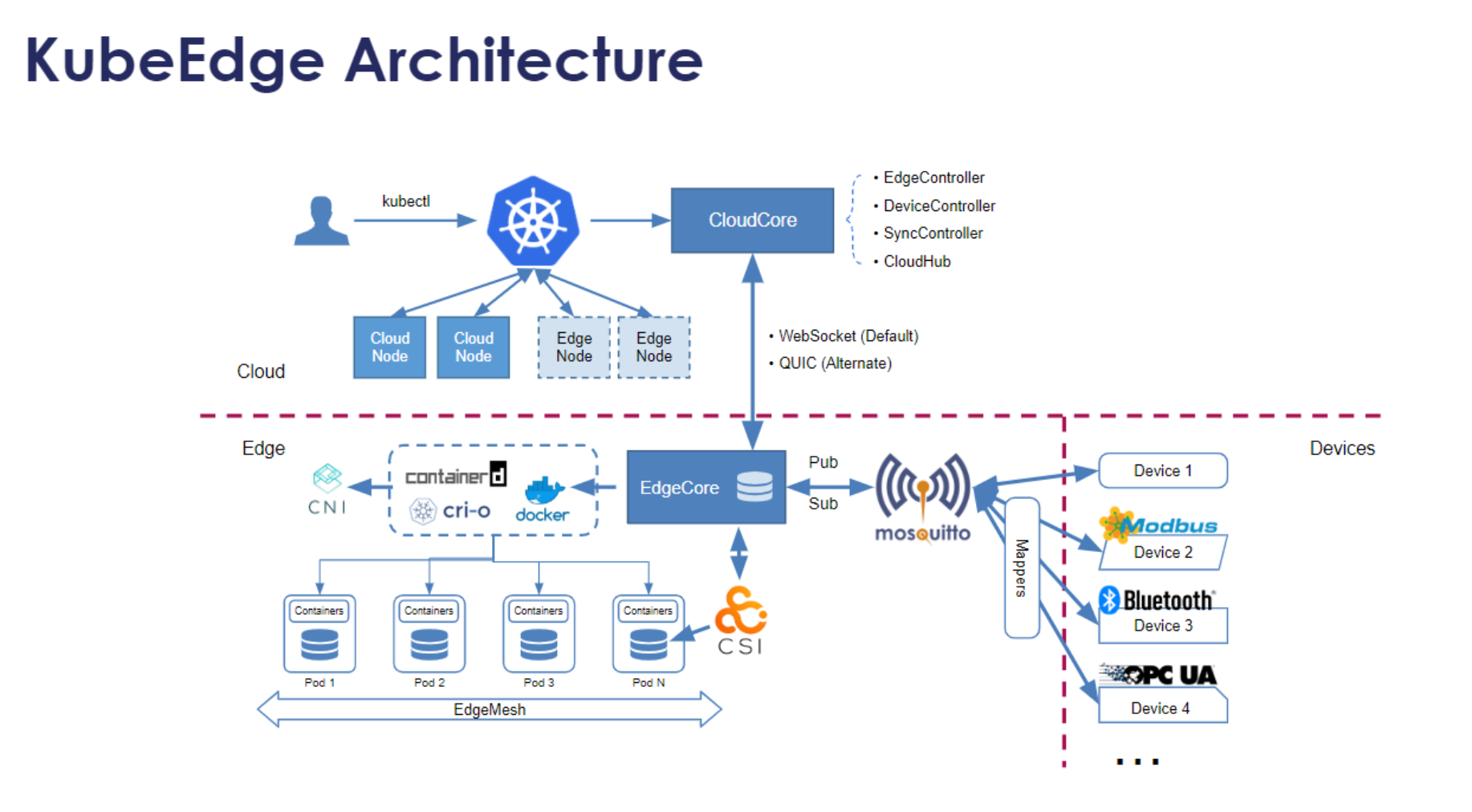
KubeEdge是Kurator集成的核心边缘计算框架,它扩展了Kubernetes原生容器编排能力到边缘,解决了边缘场景下的网络不稳定、设备异构、资源受限等挑战。本节将深入分析KubeEdge架构及其在Kurator中的集成应用。
5.1 KubeEdge核心组件与通信机制
KubeEdge的核心组件参考图: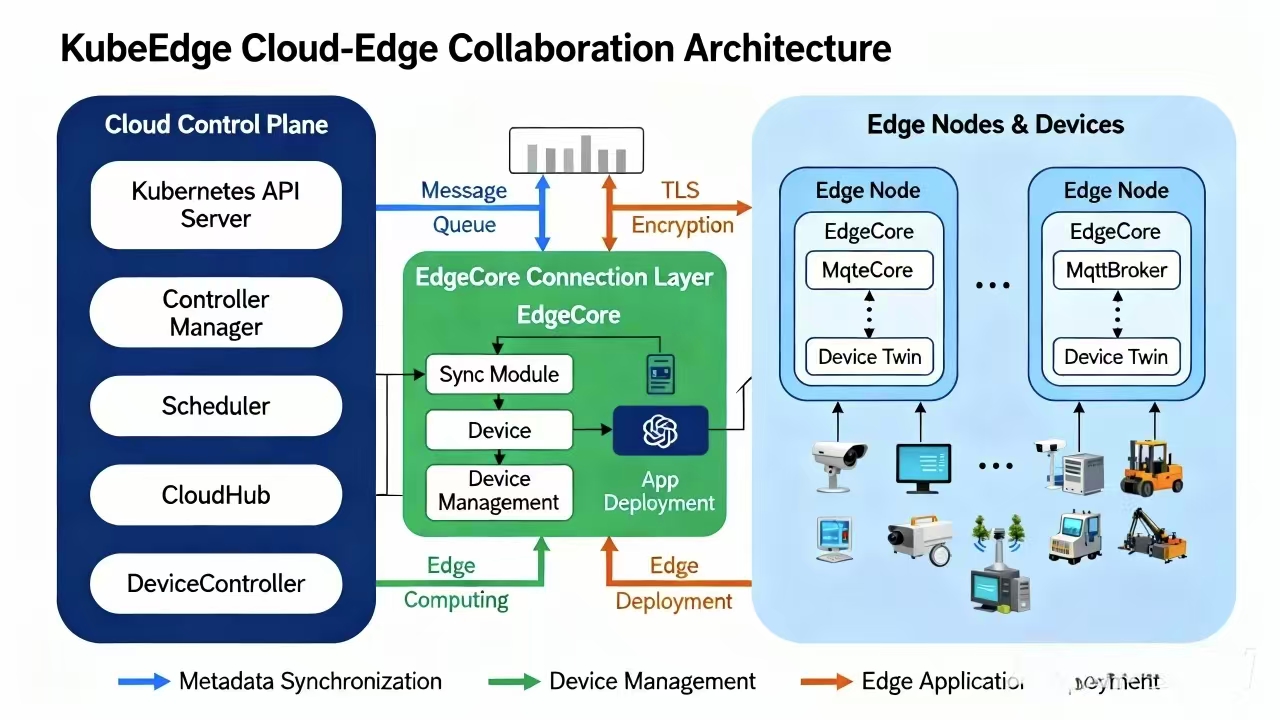
KubeEdge架构由云上组件和边缘组件组成,通过WebSocket和MQTT协议实现云边通信。云上组件包括CloudCore(包含CloudHub、EdgeController、DeviceController等模块),边缘组件包括EdgeCore(包含EdgeHub、MetaManager、Edged、DeviceTwin等模块)。
CloudHub是云上通信中心,负责与所有边缘节点建立WebSocket连接,处理消息路由。EdgeController同步Kubernetes API Server的状态到边缘,确保边缘节点能够获取最新的Pod、ConfigMap等资源。DeviceController管理边缘设备,将设备状态同步到云上。
边缘侧,EdgeHub负责与云上CloudHub建立连接,处理消息收发。MetaManager缓存云上资源,确保在网络中断时边缘节点仍能正常工作。Edged是边缘的轻量级Kubelet,负责Pod生命周期管理。DeviceTwin维护设备状态的数字孪生,支持设备管理API。
在Kurator中,KubeEdge的通信机制进行了优化,增加了消息压缩、断线重连优化、带宽自适应等功能,特别适合边缘网络环境。同时,Kurator通过统一的认证授权体系,确保云边通信的安全性。
5.2 云边协同架构设计
Kurator中的云边协同架构设计充分考虑了边缘场景的特殊性。架构上分为三层:中心控制层、边缘管理层、设备层。
中心控制层运行在云上,包括Kurator的Fleet Manager、策略引擎、调度器等核心组件。这一层负责全局策略制定、集群管理、监控告警等全局性功能。
边缘管理层运行在边缘集群,包括KubeEdge的EdgeCore、Kurator的Fleet Agent、本地策略执行器等。这一层负责执行中心下发的策略,管理本地资源,处理设备接入,并在网络中断时保持自治运行。
设备层包括各种IoT设备、传感器、摄像头等物理设备,通过MQTT、Modbus、Bluetooth等协议接入边缘节点。Kurator通过KubeEdge的设备管理API,将这些设备抽象为Kubernetes的自定义资源,实现统一管理。
这种三层架构实现了良好的解耦:中心控制层不需要关心具体的设备细节,边缘管理层可以独立演进,设备层可以灵活接入不同类型的设备。同时,通过统一的API和数据模型,三层之间可以无缝协同。
5.3 边缘节点管理与应用分发
在Kurator中,边缘节点的管理通过声明式API实现。以下是一个边缘节点注册和应用分发的完整示例:
# 创建边缘集群(使用KubeEdge)
apiVersion: cluster.kurator.dev/v1alpha1
kind: Cluster
meta
name: edge-cluster-beijing
namespace: kurator-system
spec:
type: edge
kubeEdge:
enabled: true
version: "1.12.1"
edgeNodes:
- name: edge-node-1
ip: "192.168.1.101"
labels:
location: "beijing-datacenter"
rack: "rack-3"
environment: "production"
- name: edge-node-2
ip: "192.168.1.102"
labels:
location: "beijing-factory"
workshop: "assembly-line-2"
environment: "production"
network:
tunnelType: "websocket" # 使用WebSocket隧道
bandwidthLimit: "10Mbps" # 限制带宽
offlineCacheDuration: "24h" # 离线缓存时间
---
# 创建边缘应用分发策略
apiVersion: apps.kurator.dev/v1alpha1
kind: FederatedDeployment
meta
name: factory-monitor
namespace: manufacturing
spec:
placement:
clusterSelector:
matchLabels:
type: edge
location: beijing
template:
metadata:
labels:
app: factory-monitor
spec:
replicas: 1
selector:
matchLabels:
app: factory-monitor
template:
meta
labels:
app: factory-monitor
spec:
nodeSelector:
workshop: assembly-line-2 # 指定在装配线2的边缘节点运行
containers:
- name: monitor
image: ghcr.io/your-org/factory-monitor:1.0
resources:
requests:
memory: "128Mi"
cpu: "100m"
limits:
memory: "256Mi"
cpu: "300m"
volumeMounts:
- name: sensor-data
mountPath: /data/sensors
env:
- name: OFFLINE_MODE
value: "true" # 启用离线模式
- name: DATA_RETENTION_HOURS
value: "48"
volumes:
- name: sensor-data
hostPath:
path: /var/lib/factory-monitor/data
type: DirectoryOrCreate
policies:
- type: TopologySpreadConstraints
topologyKey: "workshop" # 在不同车间分散部署
whenUnsatisfiable: DoNotSchedule
- type: ResourceQuota
hard:
cpu: "2"
memory: "1Gi" # 为边缘节点设置资源配额
这个配置实现了精细化的边缘应用管理:边缘节点按地理位置和业务属性打标签,应用根据业务需求调度到特定边缘节点,同时配置了离线模式、资源配额等边缘特有的参数。当网络中断时,边缘应用可以继续运行,数据在本地缓存,网络恢复后自动同步到中心。
Kurator通过这种方式,将边缘计算的复杂性封装在统一的API中,使得开发者可以像管理普通Kubernetes应用一样管理边缘应用,大大降低了边缘计算的使用门槛。
6. Kurator统一服务治理与可观测性体系
在分布式云原生环境中,服务治理和可观测性是保障系统稳定性的核心能力。Kurator通过集成Istio、Prometheus等开源项目,构建了跨集群、跨地域的统一服务治理和可观测性体系。本节将深入探讨这一架构的设计与实践。
6.1 Istio服务网格跨集群集成
lstio服务网格参考图: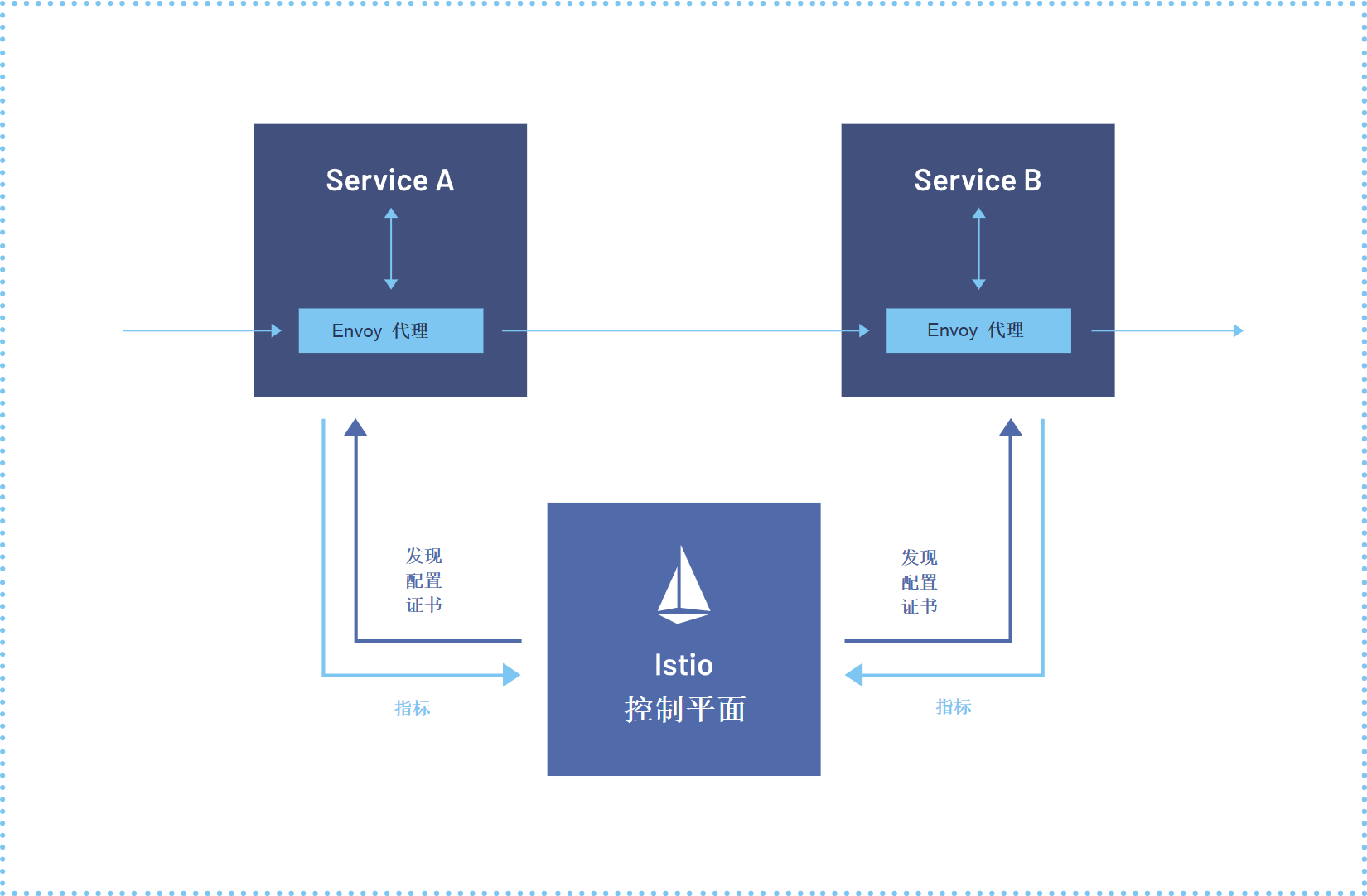
Istio作为服务网格的事实标准,在Kurator中被深度集成,以支持跨集群的服务发现、流量管理、安全策略等功能。Kurator对Istio的集成进行了优化,支持多控制平面架构,适应边缘计算和多云环境。
在Kurator架构中,Istio采用分层部署模式:中心控制平面负责全局策略管理,每个集群(包括边缘集群)部署本地控制平面,负责本地服务治理。中心控制平面与本地控制平面通过安全的API进行通信,同步服务注册信息、策略配置等。
关键创新在于服务相同性(Service Sameness)的实现。Kurator通过扩展Istio的ServiceEntry和DestinationRule,实现了跨集群的服务发现和负载均衡。当服务A需要调用服务B时,无论服务B部署在哪个集群,调用方都可以使用相同的服务名进行访问,Istio会自动选择最优的实例。
# 跨集群服务相同性配置
apiVersion: networking.istio.io/v1alpha3
kind: ServiceEntry
meta
name: user-service-global
namespace: default
spec:
hosts:
- user-service.default.svc.cluster.local
location: MESH_INTERNAL
resolution: DNS
endpoints:
- address: user-service.cluster-east-1.svc.cluster.local
ports:
http: 80
locality: east-1a
- address: user-service.cluster-west-1.svc.cluster.local
ports:
http: 80
locality: west-1a
- address: user-service.edge-cluster-1.svc.cluster.local
ports:
http: 80
locality: edge-beijing
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
meta
name: user-service-dr
namespace: default
spec:
host: user-service.default.svc.cluster.local
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN
outlierDetection:
consecutive5xxErrors: 5
interval: 30s
baseEjectionTime: 30s
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
这种配置实现了跨集群的服务发现和智能路由。调用方只需使用user-service.default.svc.cluster.local这个统一的服务名,Istio会根据实例的健康状态、地理位置、版本标签等因素,自动选择最优的后端实例。
6.2 跨集群流量管理与熔断策略
Kurator通过Istio实现了精细化的跨集群流量管理,包括金丝雀发布、故障注入、熔断降级等高级功能。以下是一个跨集群金丝雀发布的示例:
# 跨集群金丝雀发布配置
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
meta
name: payment-service
namespace: finance
spec:
hosts:
- payment-service
gateways:
- finance-gateway
http:
- match:
- headers:
user-agent:
prefix: "mobile-ios"
route:
- destination:
host: payment-service
subset: v2 # iOS用户访问新版本
weight: 100
- destination:
host: payment-service
subset: v1
weight: 0
- route:
- destination:
host: payment-service
subset: v2
weight: 10 # 其他用户10%流量到新版本
- destination:
host: payment-service
subset: v1
weight: 90
---
# 熔断策略配置
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: payment-service-dr
namespace: finance
spec:
host: payment-service
trafficPolicy:
connectionPool:
tcp:
maxConnections: 100
http:
http1MaxPendingRequests: 10
maxRequestsPerConnection: 10
outlierDetection:
consecutive5xxErrors: 3
interval: 30s
baseEjectionTime: 60s
maxEjectionPercent: 50
subsets:
- name: v1
labels:
version: v1
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN
outlierDetection:
consecutive5xxErrors: 2 # v1版本更严格的熔断策略
interval: 15s
baseEjectionTime: 30s
- name: v2
labels:
version: v2
trafficPolicy:
loadBalancer:
localityLbSetting:
enabled: true
failover:
- from: "east-1a"
to: "west-1a" # 东部集群故障时切到西部
- from: "west-1a"
to: "edge-beijing" # 西部也故障时切到边缘
这个配置实现了复杂的流量管理策略:iOS用户全部访问新版本,其他用户10%流量切到新版本;v1版本使用更严格的熔断策略;当东部集群故障时,自动将流量切到西部集群,西部也故障时切到边缘集群。这种多层级的故障转移策略,极大提高了系统的可用性。
Kurator 配置金丝雀参考图: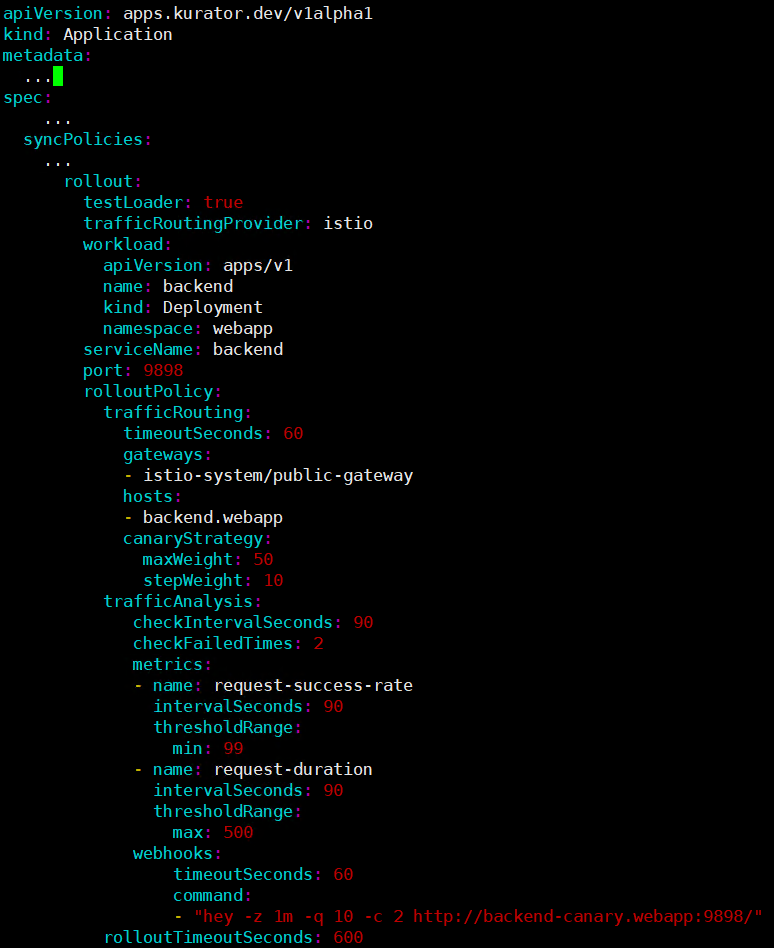
6.3 统一监控与告警体系构建
Kurator集成了Prometheus、Grafana、Alertmanager等开源监控组件,构建了跨集群的统一监控体系。架构上采用分层采集、集中存储、统一查询的设计模式。
边缘节点和各集群部署Prometheus Agent,负责采集本地指标;中心集群部署Prometheus Server,通过Remote Write协议接收各Agent的数据;Thanos或Cortex作为长期存储后端,支持PB级数据存储;Grafana提供统一的可视化界面。
# 创建跨集群监控配置
apiVersion: monitoring.kurator.dev/v1alpha1
kind: FederatedMonitoring
meta
name: global-monitoring
namespace: monitoring
spec:
clusters:
- name: cluster-east-1
prometheus:
endpoint: "http://prometheus.cluster-east-1.svc:9090"
scrapeInterval: "15s"
- name: cluster-west-1
prometheus:
endpoint: "http://prometheus.cluster-west-1.svc:9090"
scrapeInterval: "15s"
- name: edge-cluster-1
prometheus:
endpoint: "http://prometheus.edge-cluster-1.svc:9090"
scrapeInterval: "30s" # 边缘节点降低采集频率
bandwidthLimit: "1Mbps" # 限制带宽使用
recordingRules:
- name: cluster:node_cpu_utilization:ratio
expression: |
sum(rate(node_cpu_seconds_total{mode!="idle"}[5m])) by (cluster, node)
/
sum(rate(node_cpu_seconds_total[5m])) by (cluster, node)
- name: cluster:pods_running:count
expression: |
count(kube_pod_status_phase{phase="Running"}) by (cluster, namespace)
alertingRules:
- name: HighCpuUsage
for: "10m"
expression: |
cluster:node_cpu_utilization:ratio > 0.85
labels:
severity: warning
team: platform
annotations:
summary: "High CPU usage on {{ $labels.cluster }}/{{ $labels.node }}"
description: "CPU utilization has been above 85% for 10 minutes"
- name: ClusterDown
for: "5m"
expression: |
up{job="kubernetes-apiservers"} == 0
labels:
severity: critical
team: sre
annotations:
summary: "Kubernetes API server down in {{ $labels.cluster }}"
description: "Kubernetes API server has been down for 5 minutes"
grafanaDashboards:
- name: cluster-overview
source:
url: "https://grafana.com/api/dashboards/12345"
datasource: "prometheus-global"
- name: edge-node-health
json: |
{
"title": "Edge Node Health",
"panels": [
{
"title": "CPU Usage",
"type": "graph",
"targets": [
{
"expr": "node_cpu_utilization{cluster=~'$cluster',node=~'$node'}",
"legendFormat": "{{node}}"
}
]
}
]
}
这个配置定义了跨集群的监控策略:不同集群的Prometheus端点、统一的记录规则和告警规则、Grafana仪表盘配置。告警规则考虑了集群特性,边缘节点的CPU使用率阈值可能不同于中心集群;网络分区时,系统会智能判断是局部故障还是全局故障,避免告警风暴。
Kurator的统一监控体系不仅收集基础设施指标,还支持应用性能监控(APM)、日志分析、分布式追踪等全栈可观测性能力。通过统一的数据模型和查询接口,运维人员可以快速定位跨集群、跨服务的问题,大大提高了故障排查效率。
7. Volcano批处理调度与AI工作负载优化
在分布式云原生环境中,批处理和AI/ML工作负载对调度提出了特殊要求:需要感知任务依赖、支持队列管理、优化资源利用率。Kurator集成的Volcano调度器专门解决这些问题,为大数据、AI训练、科学计算等场景提供专业支持。本节将深入探讨Volcano在Kurator中的应用。
7.1 Volcano调度架构与核心概念
Volcano调度架构参考图: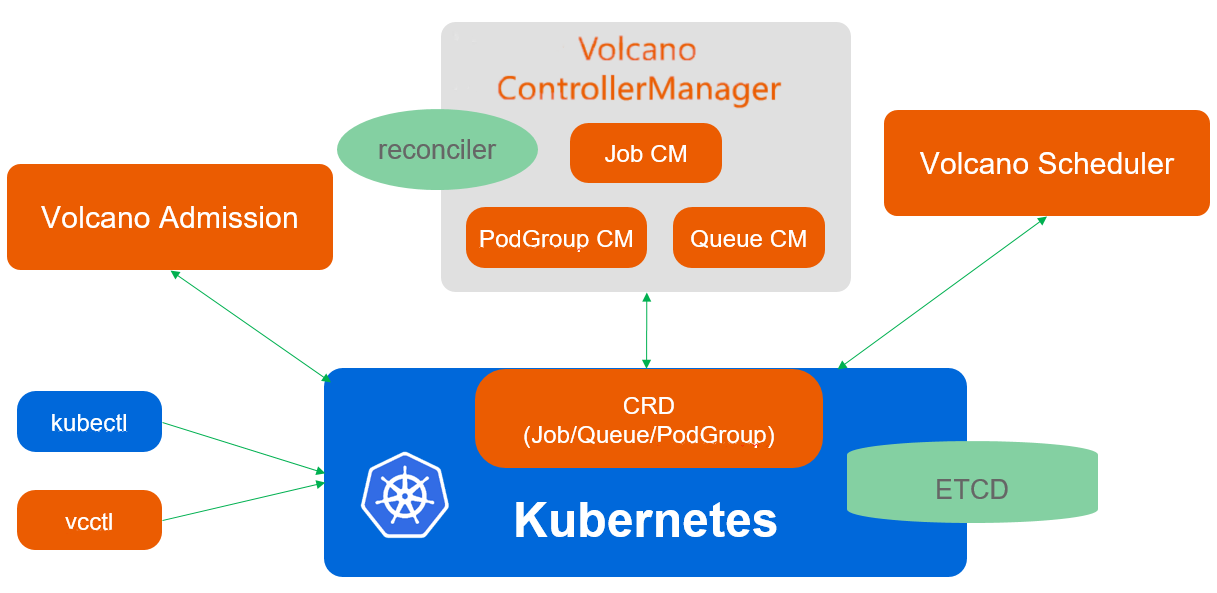
Volcano是CNCF孵化的批处理调度器,专为高性能计算、AI/ML、大数据等场景设计。在Kurator中,Volcano与Karmada深度集成,实现了跨集群的批处理调度能力。
Volcano架构的核心是Scheduler、Controller和Webhook三个组件。Scheduler负责任务调度决策,支持多种调度算法;Controller管理Volcano自定义资源的生命周期;Webhook实现准入控制和默认值注入。
VolcanoJob和Queue、PodGroup 参考图: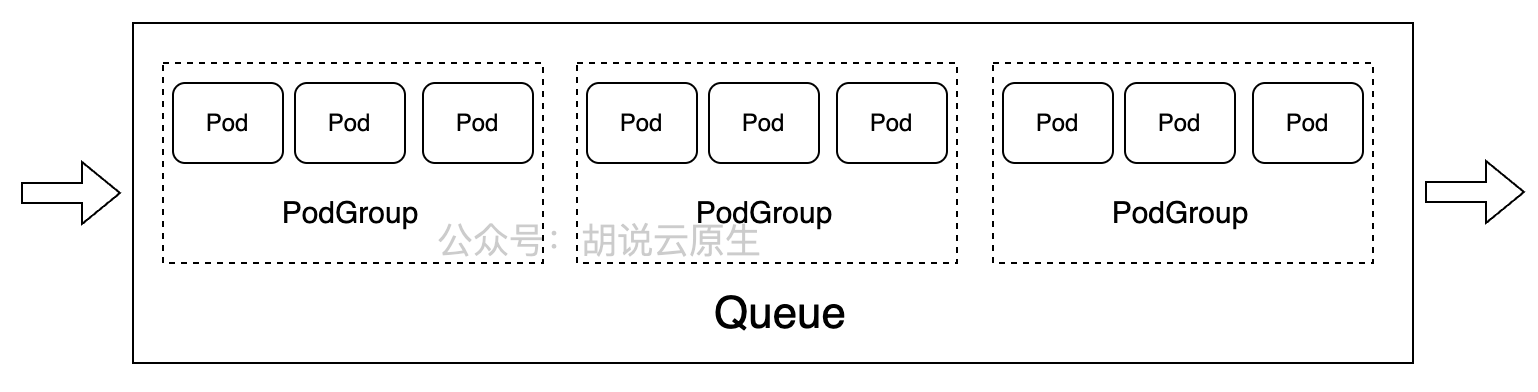
关键概念包括:
- Queue:资源队列,用于资源配额管理和多租户隔离
- PodGroup:任务组,将相关Pod组织在一起,支持All-or-Nothing调度
- Job:批处理作业,支持MPI、TensorFlow、PyTorch等多种框架
- Action/Policy:调度策略,定义任务调度的触发条件和执行动作
在Kurator中,Volcano的调度决策不仅考虑单集群资源,还结合Karmada的集群调度策略,实现跨集群的资源优化。例如,AI训练任务可能需要特定的GPU型号,Volcano会与Karmada协同,选择具有合适GPU资源的集群,并在该集群内进行精细的GPU分配。
7.2 队列管理与作业调度策略
以下是一个典型的Volcano队列和作业配置示例,展示如何在Kurator中管理AI训练任务:
# 创建资源队列
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: ai-training-queue
spec:
weight: 10 # 队列权重
capability:
cpu: 100
memory: 500Gi
nvidia.com/gpu: 20 # GPU资源配额
reclaimable: true # 允许资源回收
---
# 创建PodGroup(任务组)
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
meta
name: image-classification-job
namespace: ai-team
spec:
minMember: 8 # 最小成员数,确保8个Pod同时启动
minTaskMember:
ps: 2 # 至少2个参数服务器
worker: 6 # 至少6个工作节点
queue: ai-training-queue # 关联到队列
---
# 创建Volcano Job(MPI作业)
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
meta
name: image-classification-mpi
namespace: ai-team
spec:
minAvailable: 8 # 最小可用Pod数
schedulerName: volcano # 指定Volcano调度器
queue: ai-training-queue
tasks:
- replicas: 2
name: ps # 参数服务器
template:
meta
labels:
app: image-classification
role: ps
spec:
containers:
- image: tensorflow/tensorflow:2.8.0-gpu
name: tensorflow
command: ["python", "/opt/train.py", "--role=ps"]
resources:
limits:
cpu: "2"
memory: "16Gi"
nvidia.com/gpu: 0 # PS不需要GPU
- replicas: 6
name: worker # 工作节点
template:
metadata:
labels:
app: image-classification
role: worker
spec:
containers:
- image: tensorflow/tensorflow:2.8.0-gpu
name: tensorflow
command: ["python", "/opt/train.py", "--role=worker"]
resources:
limits:
cpu: "8"
memory: "64Gi"
nvidia.com/gpu: 1 # 每个工作节点1个GPU
env:
- name: NCCL_DEBUG
value: INFO
- name: NCCL_IB_DISABLE
value: "1"
这个配置实现了复杂的AI训练任务管理:资源队列限制了团队的总体资源使用;PodGroup确保参数服务器和工作节点同时启动;Volcano Job定义了MPI架构的训练任务,包含2个PS节点和6个Worker节点,每个Worker节点使用1个GPU。
Volcano的调度策略考虑了任务依赖性、数据局部性、GPU拓扑等因素。例如,它会尽量将同一个任务的Pod调度到同一个物理节点或机架,减少网络通信开销;对于GPU任务,会考虑GPU之间的NVLink连接,优化GPU间通信性能。
7.3 AI/大数据场景下的资源优化实践
在AI和大数据场景中,资源优化至关重要。Kurator结合Volcano和Karmada,实现了跨集群的资源优化策略。以下是一个资源优化的高级配置示例:
# 创建跨集群资源优化策略
apiVersion: optimization.kurator.dev/v1alpha1
kind: ResourceOptimizationPolicy
meta
name: ai-training-optimization
namespace: ai-team
spec:
targetRef:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
name: image-classification-mpi
strategies:
- name: gpu-consolidation # GPU资源合并策略
enabled: true
parameters:
minGpuUtilization: 0.7 # 最小GPU利用率
consolidationWindow: "10m"
- name: spot-instance-fallback # 竞价实例回退策略
enabled: true
parameters:
spotInstanceClusters: ["cluster-east-1", "cluster-west-1"]
onDemandFallbackClusters: ["cluster-central"]
maxSpotPrice: "0.5" # 最大竞价价格
- name: data-locality # 数据局部性优化
enabled: true
parameters:
datasetName: "imagenet-2012"
preferredClusters: ["cluster-east-1"] # 数据所在集群
maxDataTransferCost: "100GB" # 最大数据传输量
autoScaling:
enabled: true
minReplicas: 4
maxReplicas: 16
metrics:
- type: Resource
resource:
name: gpu-utilization
target:
type: Utilization
averageUtilization: 60
- type: Custom
custom:
name: training-throughput
target:
type: AverageValue
averageValue: "100 images/sec"
costOptimization:
enabled: true
budget: "1000 USD/day"
prioritization:
- job: image-classification-mpi
priority: high
- job: data-preprocessing
priority: medium
这个策略实现了多维度的资源优化:GPU资源合并减少碎片;在竞价实例集群运行任务,成本超标时自动回退到按需实例;优先将任务调度到数据所在的集群,减少数据传输;根据GPU利用率和训练吞吐量自动扩缩容;在预算约束下,优先保障高优先级任务的资源需求。
在实际生产环境中,这种优化策略可以显著降低成本。例如,某AI团队通过Kurator+Volcano的优化,将GPU利用率从平均30%提升到70%,每月节省云成本超过50%。同时,通过数据局部性优化,训练任务完成时间减少了40%,加速了AI模型迭代。
Kurator通过Volcano提供了专业级的批处理调度能力,使得企业可以在分布式云原生环境中高效运行AI、大数据等计算密集型工作负载,充分发挥云原生架构的弹性和成本优势。
8. Kurator未来发展方向与企业落地策略
作为新兴的分布式云原生平台,Kurator正处于快速发展阶段。本节将分析Kurator的技术演进趋势,探讨企业如何在数字化转型中有效采用Kurator,并提出社区共建的策略建议。
8.1 分布式云原生技术演进趋势
分布式云原生技术正朝着几个关键方向演进。首先,边缘计算将从简单的数据采集向边缘智能演进,边缘节点将具备更强的计算能力和自治性。Kurator需要增强边缘AI推理、边缘数据处理等能力,支持更复杂的边缘应用场景。
其次,多云管理将从资源层面向应用层面深化。未来的多云平台不仅管理基础设施,还需要管理应用生命周期、服务治理、安全策略等。Kurator正在向这个方向发展,通过统一的应用抽象层,实现跨云的应用部署和管理。
第三,安全将成为分布式云原生的核心关注点。随着数据在多云、边缘环境流动,数据安全、隐私保护、合规性要求将更加严格。Kurator需要集成零信任架构、机密计算、数据加密等安全技术,提供端到端的安全保障。
最后,可观测性将从监控告警向智能运维演进。AIOps将成为标配,通过机器学习自动检测异常、预测故障、优化性能。Kurator的统一监控体系需要集成这些智能能力,提供预测性运维支持。
Kurator社区正在这些方向上积极投入。例如,边缘AI方面,社区正在探索KubeEdge与TensorFlow Lite、ONNX Runtime的集成;安全方面,正在集成SPIFFE/SPIRE实现零信任身份;AIOps方面,正在与Prometheus生态合作,开发智能告警和根因分析功能。
8.2 企业数字化转型中的Kurator实践
企业在采用Kurator进行数字化转型时,需要制定清晰的演进路线。建议采用分阶段策略:
阶段一:单集群试点(3-6个月)
- 选择非核心业务,在单个Kubernetes集群上部署Kurator
- 重点验证核心功能:集群管理、应用部署、基础监控
- 建立运维团队,积累使用经验
- 目标:验证技术可行性,培养团队能力
阶段二:多集群扩展(6-12个月)
- 将Kurator扩展到多个业务集群
- 实现跨集群的统一管理、服务治理
- 集成CI/CD流水线,实现GitOps工作流
- 目标:提升运维效率,降低管理复杂性
阶段三:边缘计算整合(12-18个月)
- 将边缘节点纳入Kurator管理
- 实现云边协同的应用部署和数据同步
- 优化边缘场景的网络、存储、安全策略
- 目标:支持边缘业务创新,提升用户体验
阶段四:全栈云原生(18-24个月)
- 实现多云、边缘、中心的统一管理
- 深度集成AI/大数据工作负载
- 构建智能运维体系
- 目标:全面数字化转型,构建核心竞争力
在每个阶段,都需要关注组织变革、流程优化、人才培养等软性因素。技术只是手段,真正的价值在于通过技术变革业务模式、提升客户体验、创造新收入来源。
8.3 社区贡献与生态共建策略
Kurator作为开源项目,其成功依赖于活跃的社区和健康的生态。企业参与Kurator社区可以从以下几个层面入手:
代码贡献:
- 从小的Bug修复、文档改进开始,逐步参与核心功能开发
- 重点关注与企业业务相关的领域,如特定边缘设备支持、垂直行业解决方案
- 遵循社区贡献流程,积极参与Code Review
生态建设:
- 开发Kurator插件,扩展平台能力
- 与其他开源项目集成,丰富技术生态
- 构建行业解决方案,推动技术落地
社区运营:
- 参与社区会议,分享实践经验
- 组织本地Meetup,扩大社区影响
- 为社区提供资源支持,如基础设施、资金赞助
标准推动:
- 参与CNCF相关工作组,推动标准制定
- 将企业实践抽象为通用解决方案,回馈社区
- 与学术界合作,探索前沿技术
企业参与开源社区不仅是技术投入,更是战略投资。通过深度参与Kurator社区,企业可以影响技术发展方向,获得先发优势,培养技术人才,建立行业影响力。同时,开源协作模式也加速了技术创新,降低了研发成本,实现了多方共赢。
Kurator的未来充满机遇。随着5G、IoT、AI等技术的普及,分布式云原生将成为数字基础设施的核心。Kurator作为这一领域的创新者,有望成为企业数字化转型的关键支撑。通过社区共建、开放协作,Kurator将不断演进,为构建下一代分布式云原生基础设施贡献力量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 26
26 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)