兄弟们坐稳了!手把手带你玩转 Kurator 云原生:从环境搭建到云边协同与调度黑科技大揭秘
兄弟们坐稳了!手把手带你玩转 Kurator 云原生:从环境搭建到云边协同与调度黑科技大揭秘
最近总有兄弟在群里问:“K8s 玩得挺溜了,但一上多集群、搞边缘计算或者跑 AI 任务就头大,Kurator 到底能不能打?” 讲真,Kurator 这玩意儿就像是给原生 K8s 穿了一套“钢铁侠战衣”,不管是管理一堆集群,还是把算力延伸到边缘设备,甚至是用 Volcano 榨干 GPU 性能,它都给你安排得明明白白。
01. 别废话,先把“战场”打扫干净(环境搭建篇)
想玩转 Kurator,第一步肯定得把环境弄好。很多兄弟倒在这一步,其实只要姿势对,分分钟搞定。咱们这次实操主要是在 Linux 环境下,但我建议你准备一个稍微干净点的机器,或者虚拟机,别跟老项目的环境混在一起。
1.1 准备工作做足
你得确认机器上 Docker 或者 Containerd 是跑起来的,Go 环境最好也配一下,毕竟咱们是搞云原生的,随时可能要改点配置。
1.2 拉取 Kurator 源码(关键一步)
这里有个坑,大家平时习惯去 GitHub,但有时候网络不给力是真让人抓狂。为了保证咱们实操的顺滑,这次咱们用这个国内的镜像仓库,速度杠杠的。
打开你的终端,输入下面这行命令,把源码拉下来:
# 兄弟们,这个地址稳,直接干
git clone https://gitcode.com/kurator-dev/kurator.git
cd kurator
# 看一眼咱们拉下来的东西全不全
ls -al
可以看到这是项目的gitCode源码
我们可以拉取下来
源码文件如下,接下来就可以使用了
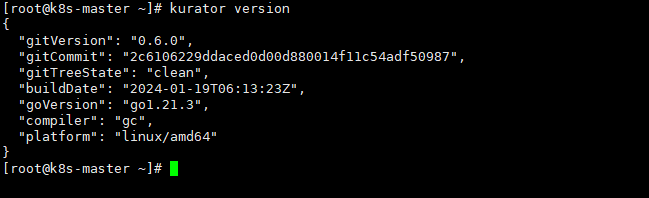
可以注意到,这个命令kurator version可以看到版本号
1.3 快速验证
拉下来之后,咱们可以先别急着从头编译,Kurator 官方提供了一些 Makefile 的快捷指令。你可以试着运行一下 make help,看看它支持哪些操作。只要不报错,咱们的“地基”就算打牢了。接下来,咱们就要在这上面盖楼了。
02. 让 AI 任务跑得飞起:Volcano 的调度艺术
环境搭好了,咱们先来聊聊计算。现在的业务,早就不是简单的 Web 服务了,很多兄弟都在跑 AI 训练、大数据分析。这时候你会发现,K8s 原生的调度器有点“笨”,它是按 Pod 来的,而 AI 任务通常是一组 Pod,缺一个都跑不起来。这时候,Kurator 集成的 Volcano 就派上用场了。
2.1 Volcano 的应用场景到底在哪?
这是Volcano的应用场景参考图,展示了它如何作为统一调度平台,支撑AI训练、大数据及科学计算等多种分布式工作负载: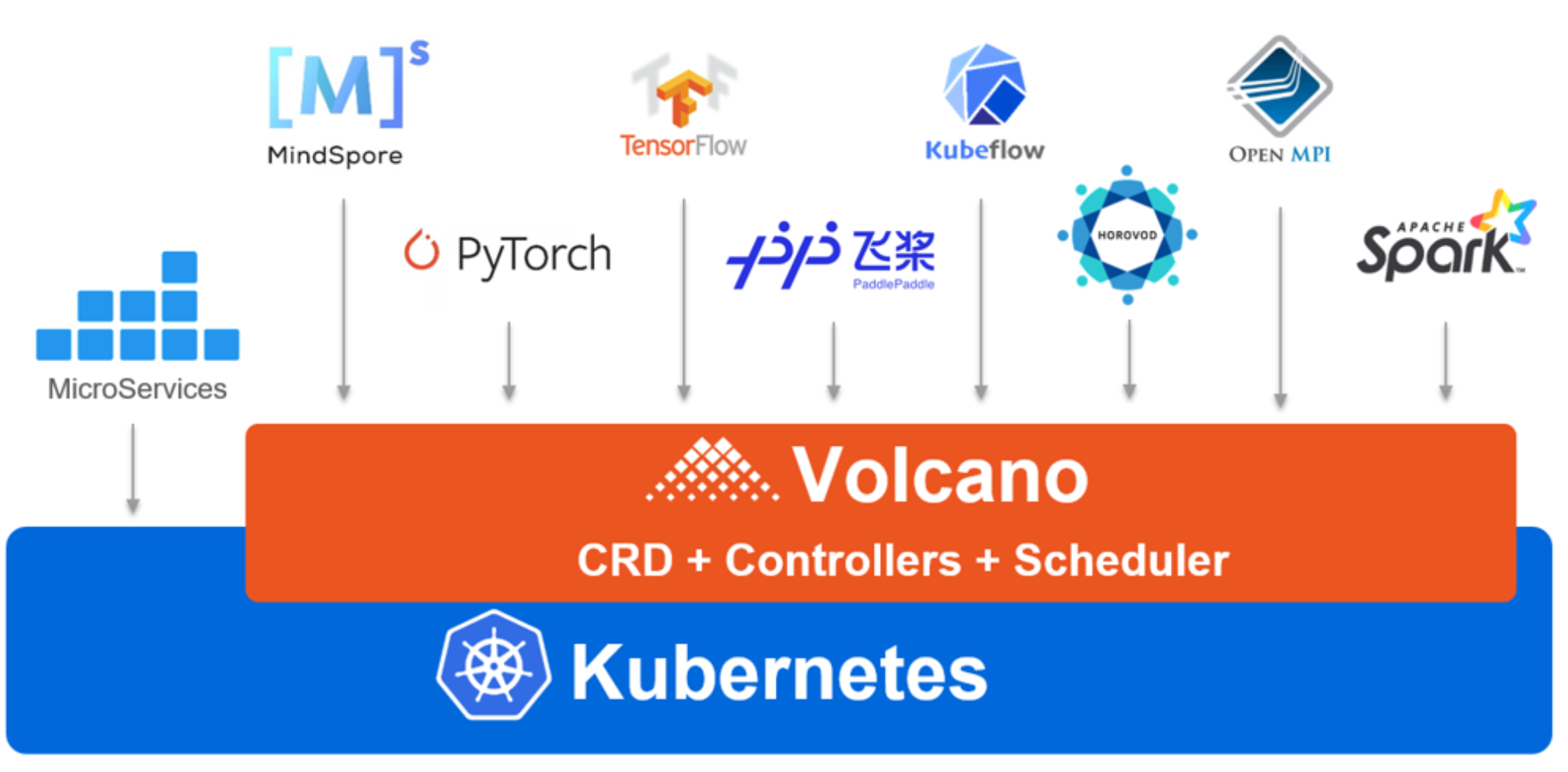
简单说,就是“批量计算”和“高性能计算”。
比如你在搞一个分布式 TensorFlow 训练,需要 10 个 Worker 节点同时就位才能开始。如果用原生调度器,可能凑齐了 5 个,另外 5 个资源不够卡住了,那这 5 个占着茅坑不拉屎,造成了死锁。
Volcano 的场景就是解决这种 Gang Scheduling(帮派调度) 问题。它适用于机器学习(TensorFlow, PyTorch)、大数据(Spark, Flink)以及基因测序等需要高并发、高吞吐的场景。在 Kurator 里,Volcano 被集成进来,就是为了让你的集群能像处理 Web 请求一样丝滑地处理这些“大块头”任务。
2.2 拆解 Volcano 调度架构
这是Volcano调度架构参考图,展示了其核心组件如何通过CRD、控制器和调度器协同工作,实现对批量计算作业的统一管理: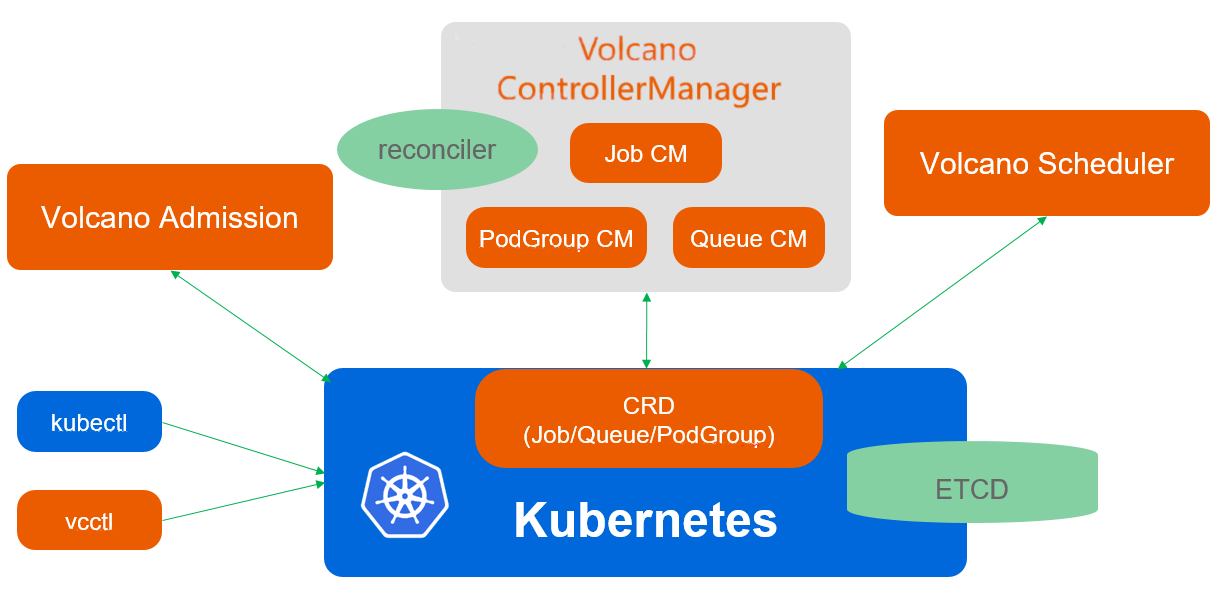
Volcano 的架构其实非常有意思,它在 K8s 原生调度器的基础上做了个“换脑手术”。
它的核心架构包含三个部分:Scheduler(调度器)、Controller(控制器) 和 Admission(准入控制)。
- Scheduler:这是大脑。它不只是看节点 CPU/内存够不够,它看的是
Job。它维护了一个Action(动作)和Plugin(插件)的链条。比如Enque(入队)、Allocate(分配)、Preempt(抢占)。它会把整个集群的资源视图缓存起来,然后通过各种算法(比如 DRF 主导资源公平算法)来决定哪个 Job 优先。 - Controller:负责管理 CRD 的生命周期,比如
Queue(队列)、PodGroup(Pod 组)。 - Admission:用来做校验和修改。
咱们来看一段手写的 Volcano Job 配置,感受一下它和普通 Pod 的区别:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: tensorflow-training-job
spec:
minAvailable: 3 # 划重点:必须要凑够3个才能跑,否则一个都别启动
schedulerName: volcano
queue: default
tasks:
- replicas: 1
name: ps
template:
spec:
containers:
- command: ["sh", "-c", "python ps.py"]
image: tensorflow/tensorflow:1.15.2
name: ps
- replicas: 2
name: worker
template:
spec:
containers:
- command: ["sh", "-c", "python worker.py"]
image: tensorflow/tensorflow:1.15.2
name: worker
restartPolicy: OnFailure
看到 minAvailable 了吗?这就是 Volcano 的灵魂。在 Kurator 体系中,这种调度能力被封装得更易用,你只需要关注你的 AI 任务,剩下的资源协调交给 Volcano。
03. 掌控全局:Fleet 架构与统一监控
搞定了复杂的计算任务,咱们得把视角拉高。现在的公司,谁还没个两三个集群?开发、测试、生产,甚至多云灾备。Kurator 引入 Fleet 就是为了解决“多集群治理”这个老大难问题。
3.1 Fleet 的核心架构与整体架构
这是Fleet架构的官方示意图,展示了其跨云、混合云和边缘的统一应用分发与管理平台: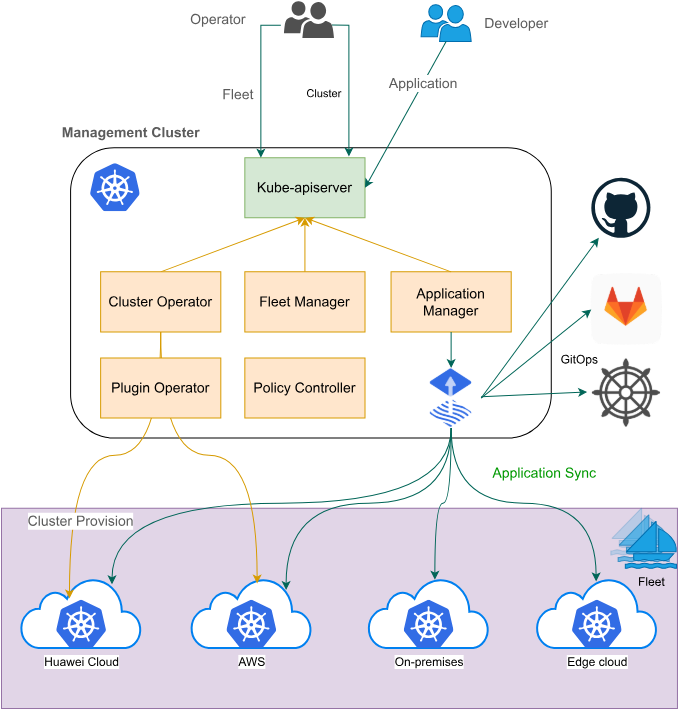
Fleet 这名字起得好,“舰队”。它的目标就是把你散落在 AWS、阿里云、甚至私有机房的 K8s 集群像一支舰队一样统一指挥。
Fleet 架构其实可以分为两层来看:
- 控制平面(Fleet Controller Manager):这是舰队的“司令部”。通常部署在你的 Host Cluster(管理集群)上。它负责存储所有的集群注册信息、资源分发策略(GitOps 配置)。
- 执行平面(Fleet Agent):这是每艘船上的“大副”。在每个 Member Cluster(成员集群)里,都会跑一个 Agent。
Fleet 的核心架构牛就牛在它的 Pull 模式(虽然也支持 Push,但 Pull 更符合边缘和多云场景)。Agent 会主动连回 Manager 问:“长官,今天有啥新任务?”如果有新的 Deployment 或者 ConfigMap 需要下发,Agent 会把它拉取下来并在本地集群应用。
这样做的好处是,如果你的成员集群在一个防火墙后面,或者在一个不稳定的网络环境(比如边缘),Manager 不需要为了连通性去打通复杂的网络隧道,Agent 只要能出网就能工作。
3.2 Kurator 的统一监控架构
这张图展示了Kurator的统一监控架构,通过集中式配置和自动同步,把多个集群的监控数据汇聚到一起,实现跨集群的统一观测和管理,让运维更省心、排查问题也更快: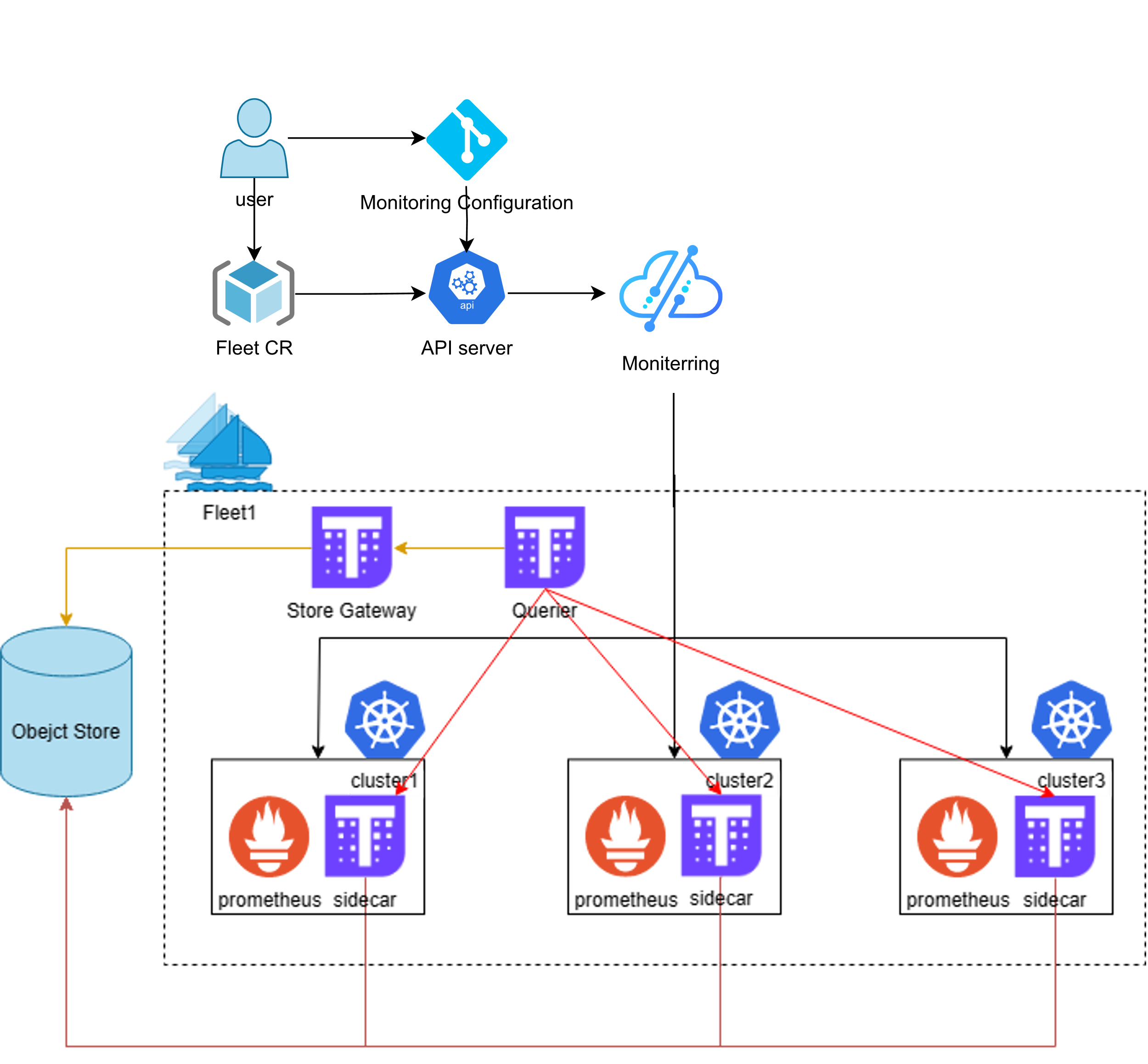
集群多了,监控要是分散的,那运维兄弟得累死。Kurator 的统一监控架构是基于 Prometheus + Thanos 或者 Cortex 这种联邦机制构建的。
在 Kurator 的设计里,它是分层级的:
- 边缘/成员层:每个集群部署一套轻量级的 Prometheus(或者是 Prometheus Agent),负责采集本地的 Metrics。
- 传输层:数据通过 Sidecar 或者 Remote Write 的方式,推送到中心。
- 中心层:部署 Thanos Query 和 Store 组件。它把分散在各个集群的数据聚合起来。
当你打开 Grafana 的时候,你看到的不是一个个孤立的集群,而是一个全局视角。你可以通过 Label 轻松筛选出 cluster="edge-node-01" 的 CPU 使用率。
04. 跨越云端的握手:KubeEdge 与云边协同
讲完多集群,咱们得聊聊更有挑战性的——边缘计算。现在物联网(IoT)这么火,Kurator 整合 KubeEdge 也是必然。
4.1 KubeEdge 的详细架构
这是KubeEdge的详细架构参考图,展示了云端核心组件、边缘节点及其与设备之间的完整管理、通信与应用部署链路: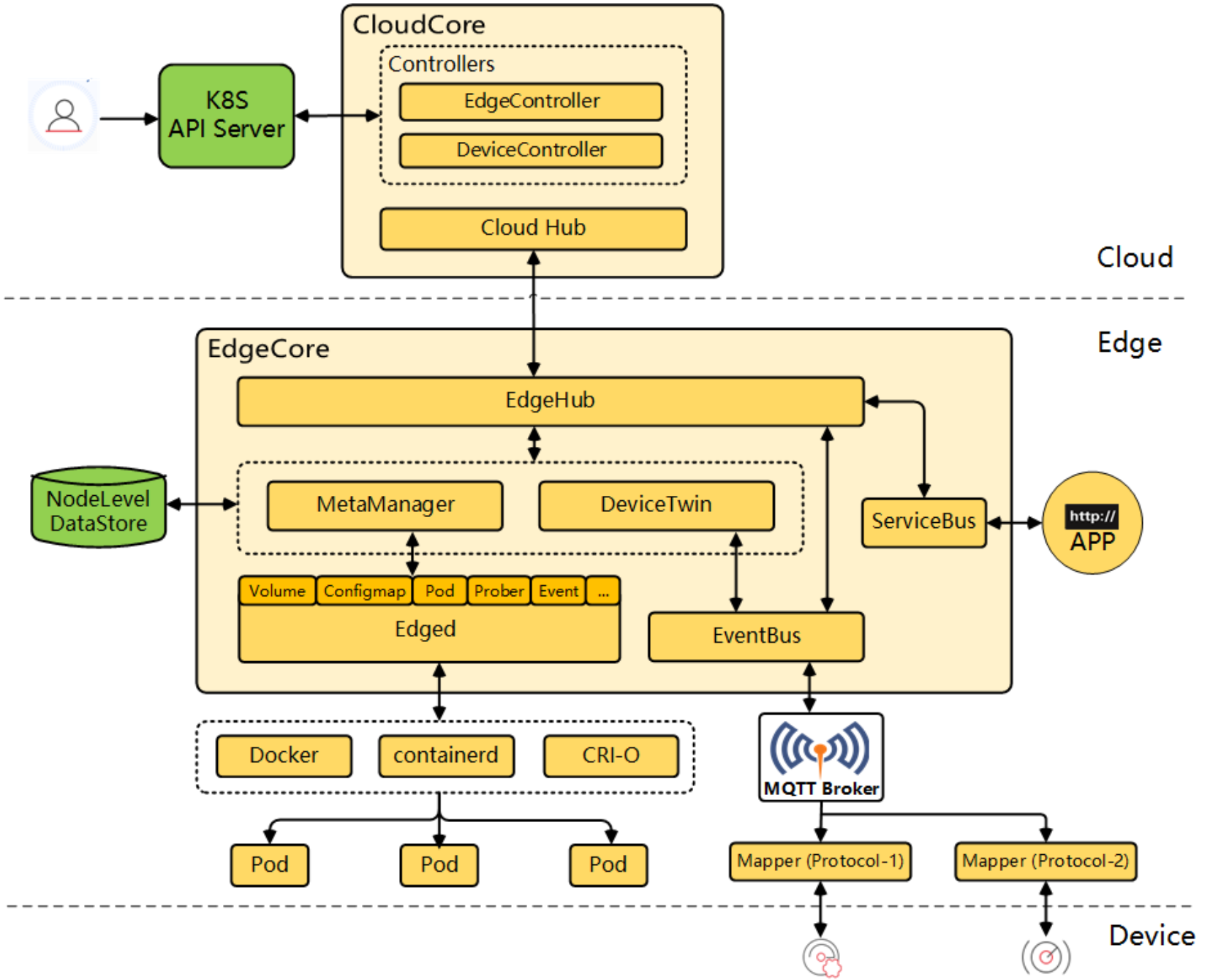
KubeEdge 是那种典型的“看着复杂,其实逻辑特清晰”的架构。它彻底把 K8s 的控制面和数据面撕开了,中间通过 WebSocket 互联。
- CloudCore(云端):部署在 Kurator 的中心管理集群上。
- CloudHub:负责和边缘建立长连接(WebSocket/QUIC)。
- EdgeController:监听 K8s API Server,把针对边缘节点的指令捞出来。
- DeviceController:管理边缘设备的数字孪生(Digital Twin)。
- EdgeCore(边缘端):跑在树莓派或者工控机上。
- EdgeHub:负责跟 CloudHub 通讯,断网了还能把数据存在本地 DB,等网好了再同步。
- Edged:轻量级的 Kubelet,管理本地容器。
- EventBus:用 MQTT 协议跟底层的传感器(温度计、摄像头)说话。
4.2 云边协同应用的部署架构
这张图展示了云边协同应用的部署架构,从设备层到边缘层、企业层再到产业平台,层层联动,实现工业数据在本地和云端的高效协同处理,支持智能制造和数字化转型: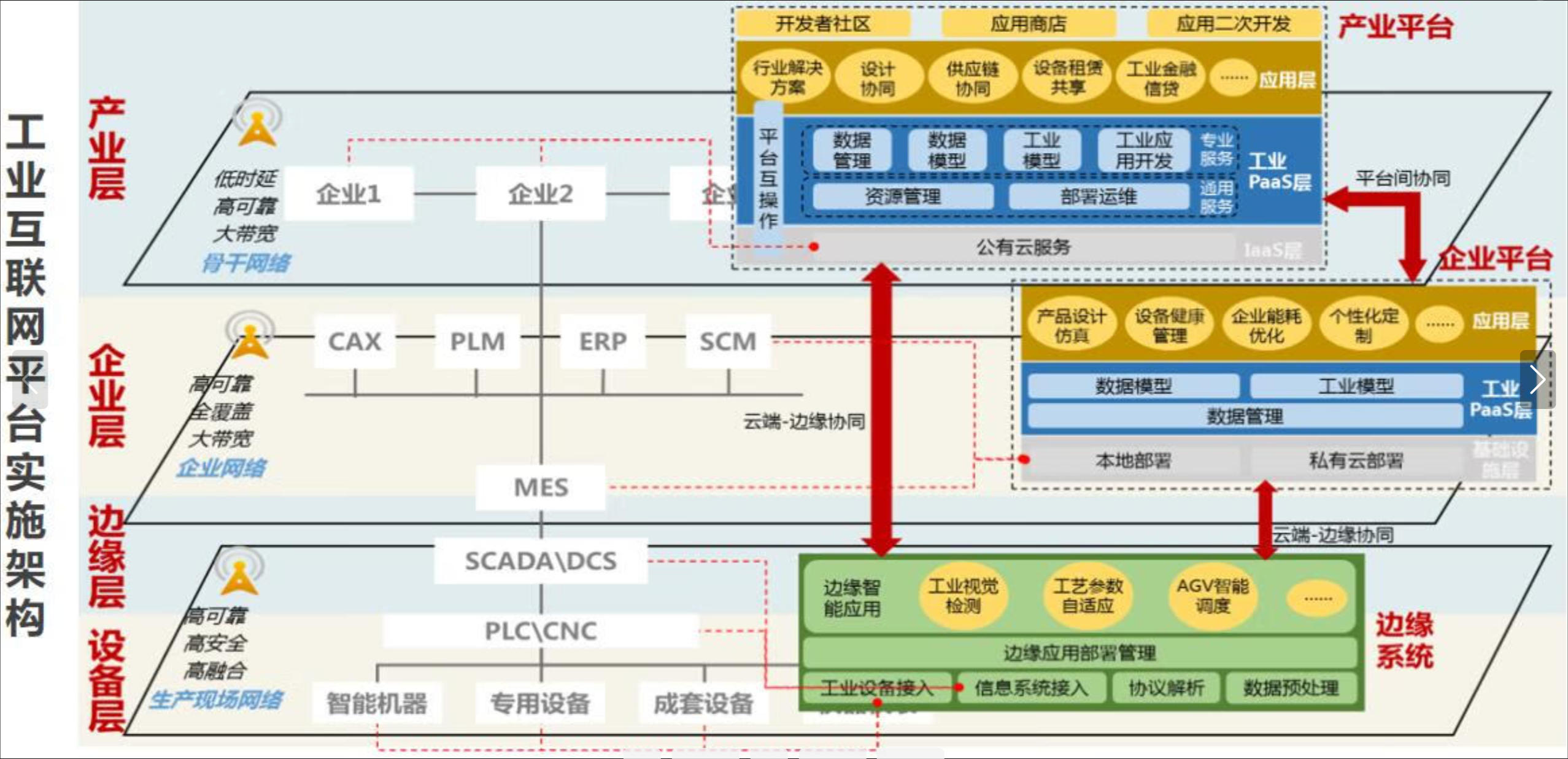
在 Kurator 里,部署一个云边协同应用是非常酷的。通常架构是这样的:
控制端(Cloud) 跑 Web Dashboard 和数据分析服务,边缘端(Edge) 跑数据采集和 AI 推理服务。
应用部署时,你只需要在 Kurator 中心下发一个 YAML,利用 NodeSelector 或者 Affinity,将采集服务调度到边缘节点。Kurator 保证了即使云边网络断开,边缘服务依然能独立运行(自治能力),等网络恢复后,边缘处理好的数据(比如经过清洗的图片特征)再上传到云端做深度分析。
05. 交付的最后一公里:CI/CD 与 Rollout 架构
最后,咱们聊聊怎么把代码安全地送到生产环境。Kurator 不仅管运行,还管交付。
5.1 Kurator CI/CD 的完整流程
Kurator 的 CI/CD 流程是高度云原生的,通常基于 Tekton 或 Argo workflows。
- 代码提交:开发者 Push 代码到 Git。
- 触发流水线:Webhook 触发 Kurator 里的 Tekton Pipeline。
- 构建与测试:在 K8s Pod 里动态生成构建环境,跑单元测试,打 Docker 镜像。
- 配置更新:新镜像 Tag 自动更新到 Git 仓库的 Manifest 文件里(GitOps 理念)。
- 同步部署:ArgoCD 监测到 Git 变化,开始同步到目标集群。
5.2 Kurator Rollout 功能的架构
光部署还不行,还得保证不挂。这就是 Kurator Rollout 的地盘了。它其实是引入了类似 Argo Rollouts 或 Flagger 的机制,实现了渐进式发布(灰度发布)。
它的架构核心在于流量控制器(Traffic Controller)和分析器(Metric Analyzer)。
- 流量拆分:Kurator Rollout 控制 Ingress 或 Service Mesh(比如 Istio),将 5% 的流量切给新版本。
- 指标分析:同时,它会实时监控 Prometheus 里的指标(比如 HTTP 500 错误率、延迟)。
- 决策反馈:如果错误率低于阈值,自动增加流量到 20%,直到 100%。如果报错多了,立刻回滚。
这部分配置起来其实很有逻辑感,看下面这个手搓的 Rollout 策略片段:
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: rollout-demo
spec:
replicas: 5
strategy:
canary:
# 灰度发布的步骤,一步步来,别步子大了扯着淡
steps:
- setWeight: 10
- pause: {duration: 1m} # 停1分钟,让你观察一下日志
- setWeight: 30
- pause: {duration: 2m} # 这里的pause也可以设为人工确认
- setWeight: 100
template:
metadata:
labels:
app: demo
spec:
containers:
- name: demo-app
image: my-repo/demo:v2.0 # 这里的版本号是CI流程自动换的
总结
兄弟们,Kurator 这套东西,把 Fleet 的多集群管理、Volcano 的高性能调度、KubeEdge 的云边协同以及 CI/CD Rollout 的自动化交付全部串联起来了。它不是一个简单的工具,而是一套完整的云原生方法论。
一路摸爬滚打,把这些核心架构都过了一遍。希望这篇文章能帮你把 Kurator 的这些概念从“天书”变成手边的“工具”。别光看,赶紧去环境里跑起来,只有报错了、修好了,这知识才是你自己的!
下次咱们有机会,再深入拆解一下具体的网络插件配置,回见!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 17
17 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)