【前瞻创想】别再手动SSH了,带你手把手用Kurator搞定分布式云原生那摊子复杂的破事儿
【前瞻创想】别再手动SSH了,带你手把手用Kurator搞定分布式云原生那摊子复杂的破事儿
咱们做运维和架构的,这两年是不是觉得头越来越秃了?单集群玩得好好的,老板非要搞什么多云、混合云、边缘计算。好家伙,几十个集群散落在各地,光是把应用分发下去再配好策略,就能让人从天黑搞到天亮。
今天咱们不聊虚的,就聊聊 Kurator。简单说,这玩意儿就是咱们多云环境下的“大管家”。它不是重新造轮子,而是把Karmada、Istio、Volcano这些顶级的开源神器给“攒”在了一起,搞了一套开箱即用的分布式云原生方案。你不用再去分别折腾这一堆组件,Kurator帮你一键整合。这感觉就像是你以前得自己去菜市场买葱姜蒜肉面条做饭,现在Kurator直接端给你一碗热气腾腾的红烧牛肉面,真香!
废话不多说,咱们直接进入正题,看看这套架构到底怎么玩,怎么帮你省下时间去摸鱼。
一、 揭秘架构:当我们在谈论分布式云原生时,到底在谈什么?
1. 分布式云原生架构的“痛”与“药”
咱们先得哪怕是简单地扯两句分布式云原生架构。现在的业务场景太复杂了,有的服务在阿里云,有的在AWS,还有的在工厂的边缘机房里。传统的K8s是“单机版”思维,你得一个个集群去切Context,累不累啊?分布式云原生就是要打破这个边界,把这些散落在天涯海角的集群看作一个“大资源池”。
但是,随之而来的问题是:应用怎么分发?流量怎么调度?策略怎么统一?这时候,Kurator架构就派上用场了。Kurator的设计理念非常Hack,它向下屏蔽了底层集群的差异,向上提供了统一的API。它就像是一个超级适配器,左手抓着基础设施管理(比如集群生命周期),右手抓着应用与流量治理。它把多云管理变成了一件像在本地操作minikube一样简单的事儿。
2. 逛逛Kurator开源项目的GitHub主页
这是Kurator开源项目的GitHub主页概览,展示了其统一分布式云管理的核心定位、活跃的开发动态及社区贡献情况: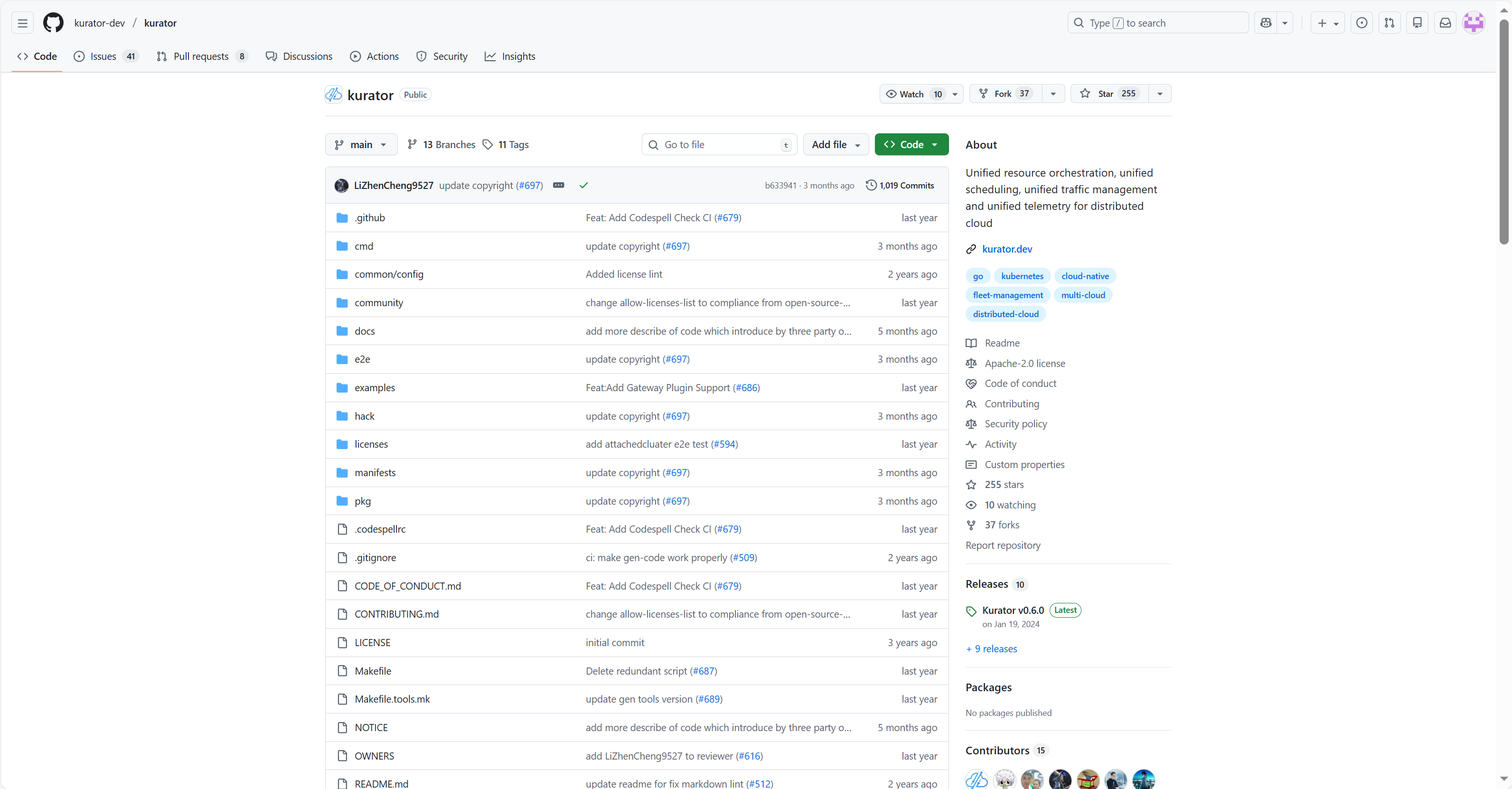
想学技术,第一步肯定是去扒源码。你去Kurator开源项目的GitHub主页溜达一圈,就会发现这帮人是真务实。代码结构非常清晰,Roadmap里写的都是咱们一线痛点,比如统一监控、一键升级啥的。而且Issue区的活跃度很高,很多Feature Request都是社区提出来的,那种“大教堂”式的开发模式在这里不存在,完全是“集市”风格。你看它的Readme,哪怕英文不好也能看懂个大概,它就是想做一个统一的分布式云原生平台,把碎片化的K8s生态给粘合起来。
3. Kurator的统一策略管理架构
这张图展示了Kurator的统一策略管理架构,用户只需要在一处定义策略,就能通过Fleet和FluxCD自动同步到多个集群,配合Kyverno实现跨集群的一致性治理,真正做到“一次配置,全栈生效”: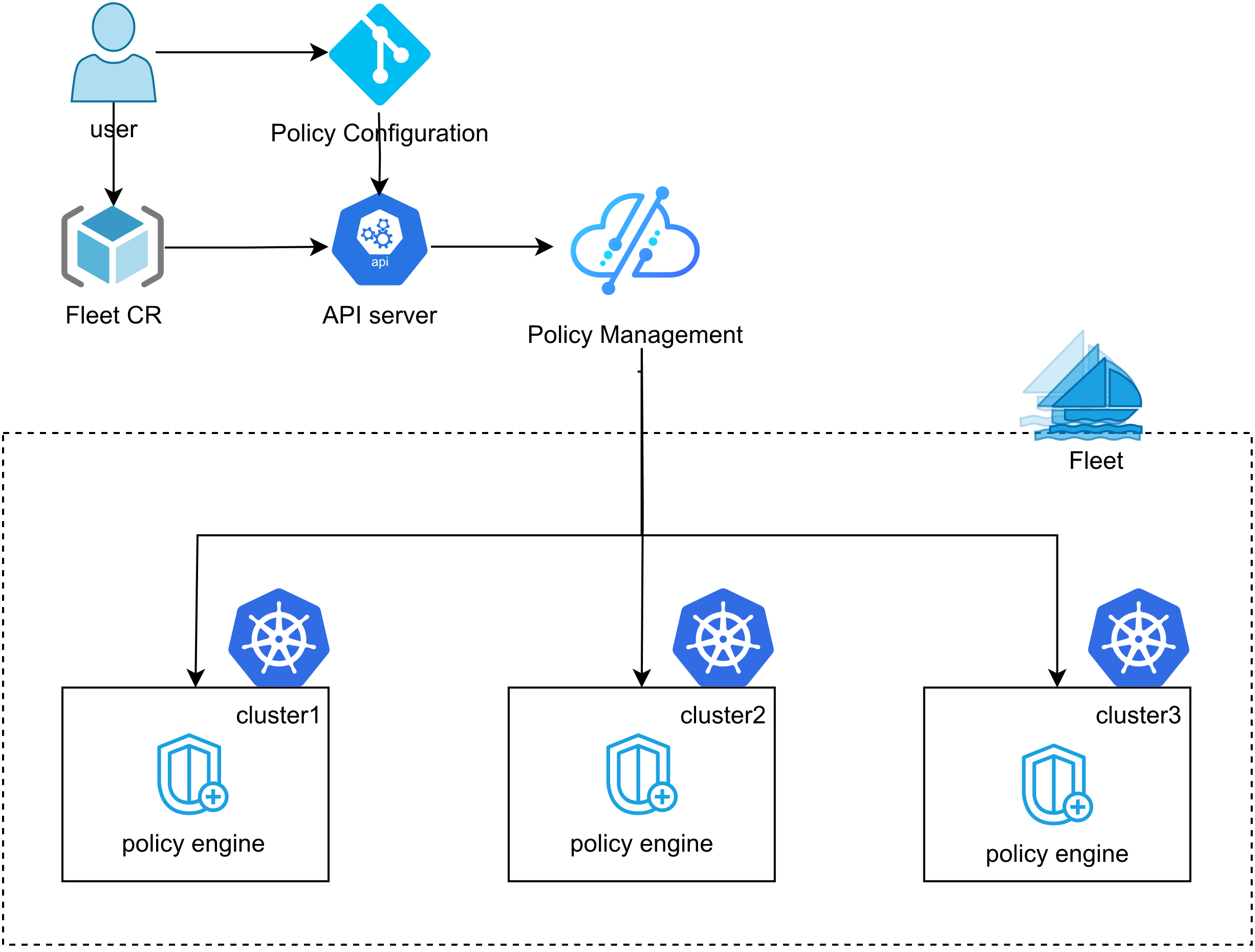
这块是我觉得最牛的地方。在多集群环境下,最怕的就是“配置漂移”。比如你想限制所有Pod的CPU上限,你有10个集群,你就得配10遍。万一漏了一个,生产环境可能就炸了。
Kurator的统一策略管理架构解决的就是这个问题。它引入了一个全局的Policy控制层。你只需要在主控集群(Host Cluster)上定义一次策略,Kurator就会利用底层的传播机制,把这个策略“复印”到所有的成员集群里。而且它不是死板的复制,它支持差异化配置(Override),比如美国机房的配置和中国机房的配置可以有细微差别,但大原则保持一致。这就叫“书同文,车同轨”,秦始皇看了都得点赞。
二、 别光看不练:手搓环境搭建实战
1. 准备工作与拉取代码
光说不练假把式。咱们现在就来搞个环境。假设你手头有几台Linux机器(虚拟机也行),或者你就在你的Mac上用Kind也行。
首先,咱们得把Kurator的源码搞下来。注意啊,这里咱们用gitcode这个源,速度快,稳得一匹。可以看到这是项目的gitCode源码
我们可以拉取下来
git clone https://github.com/kurator-dev/kurator.git
源码文件如下,接下来就可以使用了
可以注意到,这个命令kurator version可以看到版本号
这一步非常关键,因为后面很多脚本和Example的YAML文件都在这个仓库里。Clone下来之后,建议你先切到一个稳定的Release分支,别直接在main分支上跑,虽然咱们追求刺激,但生产环境还是要稳。
2. 初始化控制面
Kurator的安装其实很大程度上依赖于它提供的CLI工具。你编译好或者下载好kurator这个二进制文件后,初始化其实非常快。它会自动帮你检测环境,安装必要的CRD。
在安装过程中,你会发现它其实是在帮你拉起一个Karmada的控制面作为底座。你需要准备一个Kubeconfig,指向你的主集群。执行安装命令时,你可以看到日志里在疯狂地创建资源。这时候别急,泡杯咖啡,等它显示“Installation successfully”的时候,属于你的分布式云原生航母就下水了。
三、 核心引擎:Karmada与Volcano的硬核联动
1. Karmada多集群管理平台的核心架构
Kurator之所以能调度多集群,背后的大脑其实是Karmada。Karmada多集群管理平台的核心架构非常有意思,它包含了一个API Server、Controller Manager和一个Scheduler。
简单来说,Karmada把“从哪里来”(用户请求)和“到哪里去”(具体集群)给解耦了。用户把资源提交给Karmada API Server,Karmada把它保存在自己的Etcd里。然后,Karmada的调度器会根据你写的策略,计算出这个Pod到底该去Cluster A还是Cluster B。最后,通过Execution Controller把资源下发下去。这个过程对用户是透明的,你感觉就像是在操作一个巨大的K8s集群。
2. 玩转Karmada跨集群弹性伸缩策略
这是Karmada跨集群弹性伸缩策略参考图,展示了其如何通过FederatedHPA策略在多个成员集群间协调Pod副本数实现统一伸缩: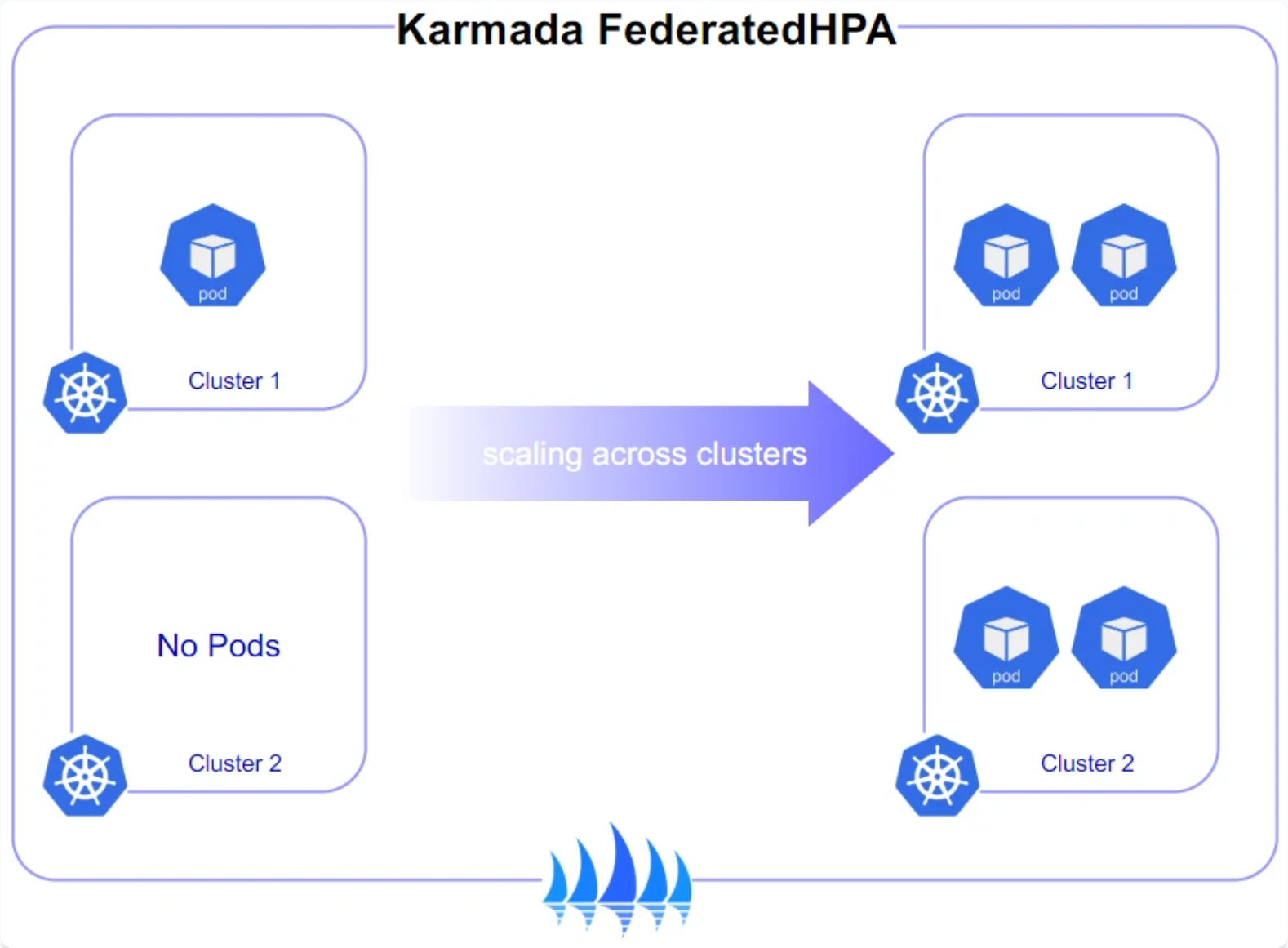
这点是真·省钱利器。咱们业务都有波峰波谷,以前只能每个集群都预留最大资源的机器,浪费钱。Karmada跨集群弹性伸缩策略(FederatedHPA)允许你在流量上来的时候,跨集群扩容。
比如,主集群资源不够了,Karmada能自动把新的Pod调度到备用集群去。下面我手写一段HPA的配置,大家感受一下这种跨集群伸缩的魅力:
apiVersion: autoscaling.karmada.io/v1alpha1
kind: FederatedHPA
metadata:
name: my-app-scaler
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-backend-app
minReplicas: 2
maxReplicas: 100
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
# 这里是关键,定义跨集群的扩容行为
behavior:
scaleUp:
stabilizationWindowSeconds: 60
policies:
- type: Percent
value: 100
periodSeconds: 15
看到没?这和原生的HPA长得很像,但它的作用域是“联邦”级别的。配置好这个,你的应用就能在多个集群间自由呼吸,再也不怕双十一流量突袭了。
3. 搞定算力:Volcano分组调度
这是Volcano分组调度参考图,展示了其如何通过整体资源检查与阈值判断,实现批处理作业的成组调度与资源保障: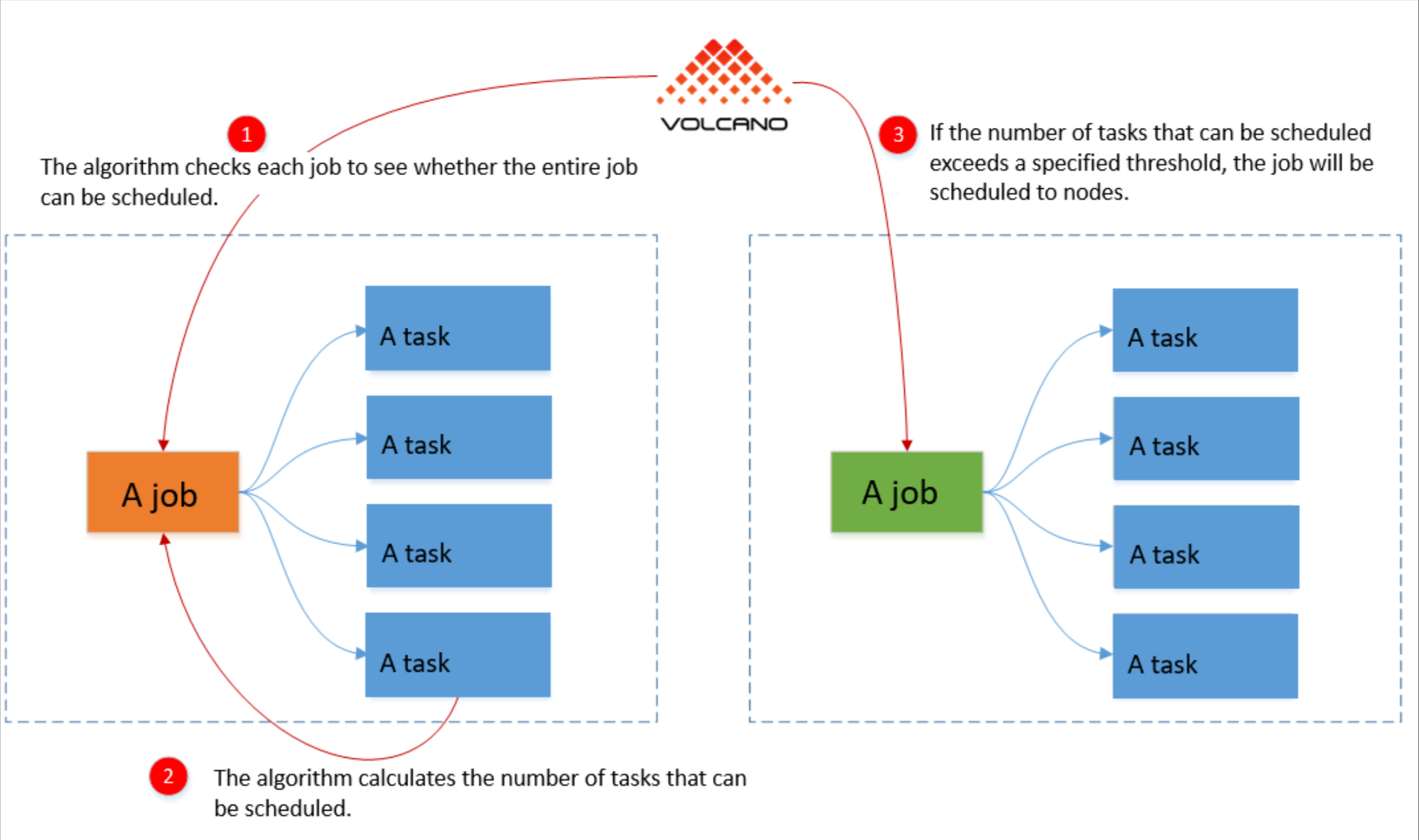
要是你的集群里跑的是AI训练或者大数据任务,那原生的调度器就不够看了。这时候Kurator集成的Volcano分组调度就登场了。
Volcano支持Gang Scheduling(帮派调度)。啥意思呢?就是一个任务需要10个Pod才能跑,如果资源只够启动8个,原生的调度器会先把这8个起起来等着,占着茅坑不拉屎。Volcano不一样,它发现不够10个,就一个都不起,把资源留给能跑起来的小任务。这在昂贵的GPU集群里简直是神技,能极大地提升资源利用率。
四、 策略管家:Fleet与Kyverno的“左右互搏”
1. 啥是Fleet队列中身份相同性?
这是Fleet队列中身份相同性的官方示意图,直观展示了跨集群的命名空间与部署服务间关联映射关系: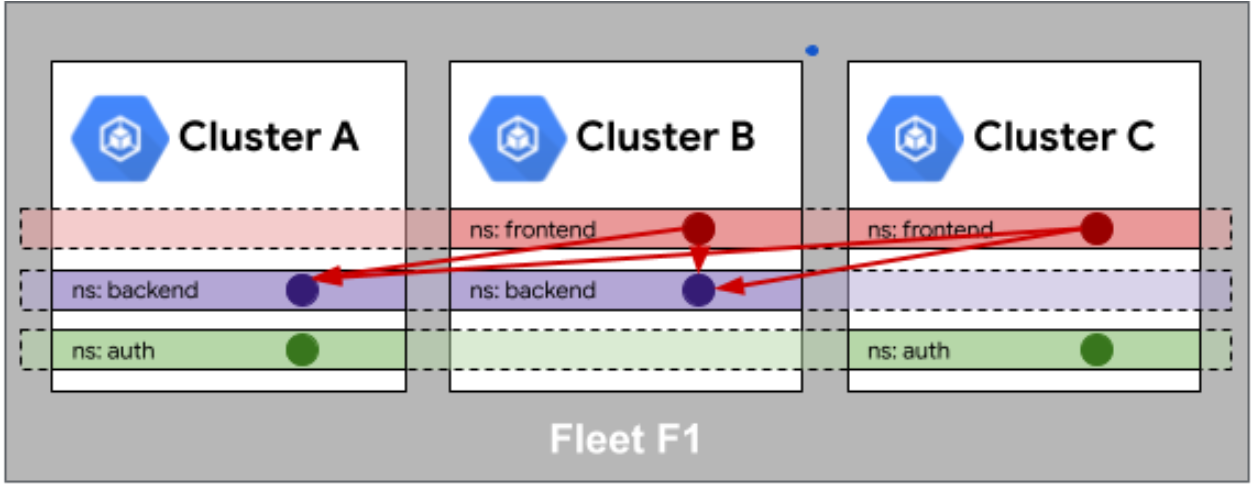
这个概念听起来有点拗口,Fleet队列中身份相同性(Identity Sameness)其实解决的是跨集群认证的问题。
试想一下,你在集群A里的服务“Order”,想去调集群B里的服务“Payment”。在零信任网络下,B怎么知道A真的是A?Fleet通过一种机制,确保在不同集群中,同一个ServiceAccount代表的是同一个“身份”。它通过在集群间共享信任根或者映射Token,让身份在整个Fleet(舰队)里是通行的。这就像你拿着公司的工牌,既能刷开北京总部的门,也能刷开上海分部的门,因为系统认你的身份ID,而不是认你是哪个门禁发出来的卡。
2. Fleet基于Kyverno的多集群策略管理架构
这是Fleet基于Kyverno的多集群策略管理架构图,展示了策略配置如何通过Fleet分发到各集群执行引擎: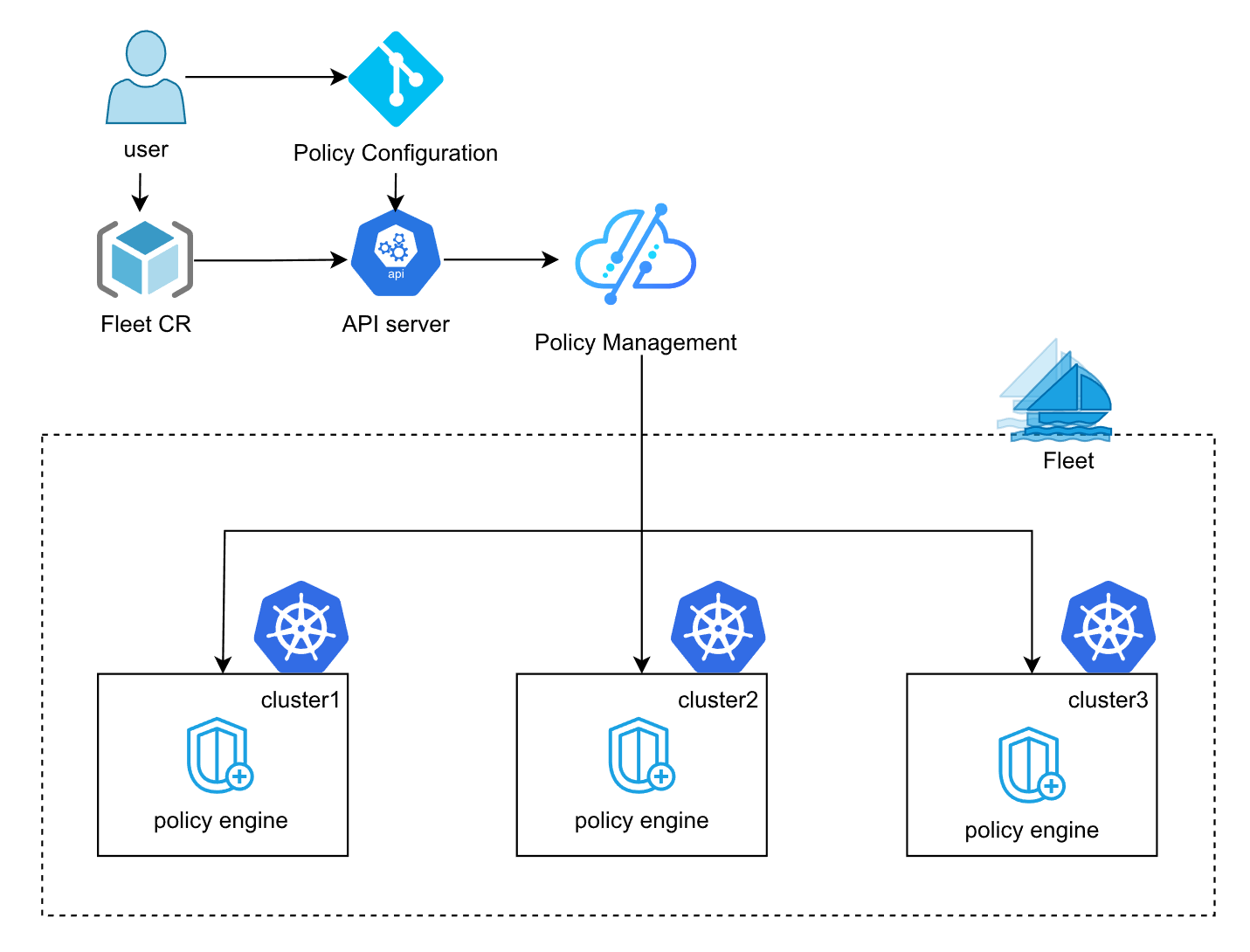
前面说了Kurator有统一策略,具体落地很多时候是靠Kyverno来实现的。Kyverno是K8s原生的策略引擎,不需要学复杂的Rego语言(对,说的就是OPA,那玩意儿太难写了)。
Fleet基于Kyverno的多集群策略管理架构允许你编写YAML格式的策略。比如,你想强制所有Namespace都必须带Label,或者所有Pod都不能用root用户运行。你把这个策略扔给Kurator,Kurator通过Fleet机制分发给所有集群里的Kyverno Agent。
下面是一个真实场景的代码,强制要求镜像必须来自咱们内部的Harbor仓库:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: require-internal-registry
spec:
validationFailureAction: enforce
background: true
rules:
- name: check-image-registry
match:
resources:
kinds:
- Pod
validate:
message: "兄弟,别乱用镜像啊,只能用 internal.harbor.com 的!"
pattern:
spec:
containers:
- image: "internal.harbor.com/*"
这代码多直观?一旦Apply,任何试图从Docker Hub拉镜像的Pod都会被直接拦截,安全合规立马达标。
五、 边缘与网格:从GitOps到流量治理
1. GitOps边缘计算的新玩法
现在边缘计算很火,什么智慧路灯、智能工厂。这些设备网络环境极差,且经常断网。GitOps边缘计算在Kurator里的实践非常优雅。
我们不直接去操作边缘节点,而是把边缘集群的状态定义在Git仓库里。Kurator配合FluxCD或者ArgoCD,一旦边缘节点连上网,就会自动从Git拉取最新的配置并应用。就算断网了,节点也保持最后一次已知的状态继续运行。这就解决了边缘设备“失联”后的管理焦虑。所有的变更都有Git记录,回滚也方便,简直是运维人员的救命稻草。
2. 深入Kurator分发流程的状态机
大家可能好奇,Kurator把应用推送到那么多集群,万一中间断了咋办?这就得聊聊Kurator分发流程的状态机了。
Kurator内部维护了一个严谨的状态流转图。当你发起一个分发请求时,状态从Pending开始。系统会先检查目标集群的健康状况,如果OK,进入Scheduled。接着开始拉取镜像、渲染模板,进入Processing。如果某个集群网络抖动,状态会变成Retrying,通过指数退避算法重试。只有当所有目标集群的Agent都回报“成功”,总状态才会变成Ready。如果中间任何一步卡死,状态机都能准确地告诉你卡在哪个环节(比如ImagePullBackOff还是资源不足),而不是给你报一个笼统的“Error”。这种确定性在分布式系统中太重要了。
3. 打通经脉:Istio服务网格
最后,应用跑起来了,网络怎么通?Istio服务网格是Kurator网络治理的核心。在多集群模式下,Kurator能帮你配置Istio的ServiceEntry和VirtualService,实现跨集群的服务发现。
比如,你想做一个金丝雀发布,把10%的流量切到新版本的集群去,手写iptables能死人,用Kurator加Istio就极其简单。
看下面这段手搓的路由规则,轻松实现跨集群流量切分:
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: my-global-service
spec:
hosts:
- my-app.prod.svc.cluster.local
http:
- route:
- destination:
host: my-app.prod.svc.cluster.local
subset: v1
weight: 90
- destination:
host: my-app.prod.svc.cluster.local
subset: v2-beta
weight: 10
headers:
response:
set:
x-cluster-id: "cluster-beta-01"
这几行代码下去,流量就乖乖地按比例走了。Kurator帮你屏蔽了底层复杂的Gateway互通配置,你只需要关注业务层的路由规则即可。
好啦,今天的分享就到这儿。说实话,Kurator这套东西,真的是把分布式云原生的门槛降到了地板上。无论你是想搞多地多活,还是想统一管理边缘设备,它都是个极其顺手的工具。
兄弟们,环境搭建的命令我也给了,核心代码也贴了,剩下的就靠你们自己去动手敲一敲了。云原生这条路,光看不行,得练!下次咱们有机会再聊聊怎么用Kurator做全链路监控,回见!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)