【前瞻创想】Kurator云原生平台实战:从多集群管理到边缘计算的分布式云原生架构深度解析与实践
【前瞻创想】Kurator云原生平台实战:从多集群管理到边缘计算的分布式云原生架构深度解析与实践
【前瞻创想】Kurator云原生平台实战:从多集群管理到边缘计算的分布式云原生架构深度解析与实践

摘要
本文深入探讨Kurator开源分布式云原生平台的核心架构、关键组件及实践应用。作为站在Kubernetes、Istio、Prometheus、FluxCD、KubeEdge、Volcano、Karmada、Kyverno等众多优秀开源项目肩膀上的集大成者,Kurator为多云、边缘云环境提供了统一的资源编排、调度、流量管理和遥测能力。文章从环境搭建入手,详细剖析Fleet集群管理、Karmada跨集群弹性伸缩、KubeEdge边缘协同、Volcano批处理调度优化等核心功能,并通过GitOps实践和CI/CD流水线构建展示其DevOps能力。最后,基于云原生技术发展趋势,对Kurator的未来发展方向提出前瞻性思考,为构建企业级分布式云原生基础设施提供实战参考。
一、Kurator架构全景与核心组件解析
Kurator作为新一代分布式云原生平台,其架构设计融合了云原生生态中最优秀的开源项目,形成了一个完整的技术栈,为多云、混合云和边缘计算场景提供统一的管理平面。
1.1 基础架构层次划分
kurator架构参考图: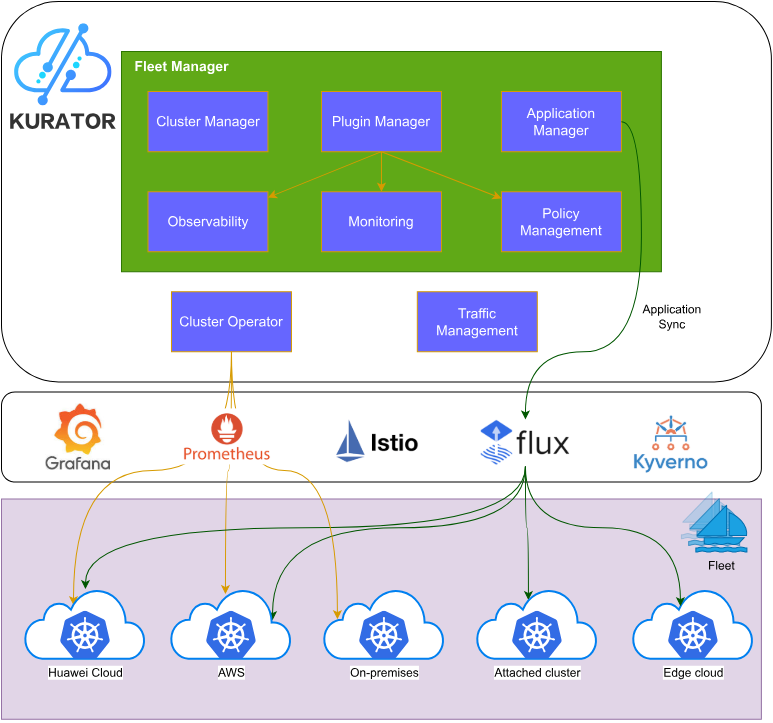
Kurator的架构可以划分为四个主要层次:基础设施层、调度管理层、应用管理层和运维治理层。基础设施层负责对接各种云提供商和边缘节点;调度管理层以Karmada和Volcano为核心,提供跨集群资源调度和批处理任务管理;应用管理层基于GitOps理念,通过FluxCD实现应用的声明式部署;运维治理层则整合了Istio、Prometheus、Kyverno等工具,提供流量管理、监控告警和策略治理能力。
这种分层架构设计使得Kurator能够灵活应对不同规模和复杂度的云原生场景,从单集群到跨地域多云部署,都能提供一致的用户体验和管理能力。
1.2 核心组件功能矩阵
Kurator组成参考图:
Kurator的核心组件形成了一张强大的功能矩阵。Karmada作为跨集群调度的核心,负责多集群资源分发和弹性伸缩;KubeEdge打通云边协同的通道,将Kubernetes的能力延伸到边缘设备;Volcano专注于批处理和AI工作负载的调度优化;Istio提供服务网格能力,实现跨集群的流量管理和安全控制;FluxCD作为GitOps引擎,确保基础设施和应用配置的版本化和自动化;Kyverno则提供策略引擎,保证多集群环境中的策略一致性。
这些组件并非简单堆砌,而是通过精心设计的接口和抽象层实现了深度集成。例如,Kurator的Fleet概念将多个集群抽象为一个逻辑单元,使得Karmada的调度策略、KubeEdge的边缘节点管理、Volcano的队列管理都能在一个统一的上下文中工作。
1.3 统一资源模型设计
Kurator的统一资源模型是其架构的核心创新点。通过自定义资源定义(CRD),Kurator抽象出了Cluster、Fleet、Policy、Workflow等核心概念,将不同组件的能力统一到一个声明式API中。例如,一个Fleet资源可以包含多个集群的引用、命名空间策略、服务账号配置、网络策略等,用户只需声明期望状态,Kurator会自动协调底层组件实现目标状态。
这种设计不仅简化了用户操作,更重要的是实现了基础设施即代码(IaC)的理念。用户可以通过Git仓库管理整个分布式系统的配置,实现版本控制、审计追踪和协作开发,大大提升了多云环境下的运维效率和可靠性。
二、环境搭建与Kurator安装实践
要深入理解Kurator的能力,首先需要搭建一个实验环境。本节将详细介绍从源码构建到完整部署的全流程,帮助读者快速上手这个强大的平台。
2.1 源码获取与依赖准备
首先,我们需要获取Kurator的源代码。使用以下命令克隆官方仓库:
git clone https://github.com/kurator-dev/kurator.git
cd kurator
如果显示下面的问题
表示没用设置git代理,我们可以先设置git代理;先看一下电脑上的代理端口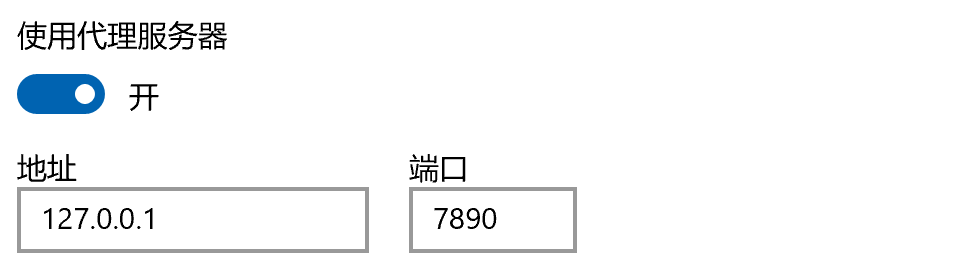
再设置git的代理端口,设置成本地代理
git config --global http.proxy http://127.0.0.1:7890
然后再拉取
git clone https://github.com/kurator-dev/kurator.git

就可以拉取资源了,当然也可以换源,你们可以试试
在安装Kurator之前,需要确保环境满足基本依赖:
- Kubernetes集群(v1.20+)
- Helm(v3.8+)
- kubectl(与集群版本匹配)
- flux(v0.30+)
- kind或k3d(用于本地测试集群)
对于本地开发测试,可以使用kind快速创建多个Kubernetes集群:
# 安装kind
curl -Lo ./kind https://github.com/kubernetes-sigs/kind/releases/download/v0.17.0/kind-linux-amd64
chmod +x ./kind
sudo mv ./kind /usr/local/bin/
# 创建三个测试集群
kind create cluster --name kurator-member1
kind create cluster --name kurator-member2
kind create cluster --name kurator-host
2.2 Kurator安装流程详解
Kurator提供了两种安装方式:使用安装脚本或通过Helm Chart。这里我们使用安装脚本方式:
# 设置环境变量
export KURATOR_HOME=$(pwd)
export PATH=$PATH:$KURATOR_HOME/_output/bin
# 构建Kurator
make build
# 安装Kurator到host集群
./scripts/deploy-kurator.sh --kubeconfig ~/.kube/config
安装过程会执行以下关键步骤:
- 在host集群上部署Kurator控制平面组件
- 创建必要的CRD和RBAC资源
- 配置Fleet控制器和集群注册服务
- 部署GitOps相关的FluxCD组件
- 初始化策略引擎和监控组件
安装完成后,可以通过以下命令验证状态:
kubectl get pods -n kurator-system
# 应该看到所有pod处于Running状态
kubectl get crd | grep kurator
# 应该看到Kurator创建的自定义资源定义
2.3 多集群注册与Fleet初始化
安装完成后,下一步是将member集群注册到Kurator控制平面:
# 获取member集群的kubeconfig
export KUBECONFIG_MEMBER1=$HOME/.kube/kind-kurator-member1.config
kind get kubeconfig --name kurator-member1 > $KUBECONFIG_MEMBER1
# 将member集群注册到Fleet
kurator cluster join member1 --kubeconfig=$KUBECONFIG_MEMBER1 --cluster-type=kind
kurator cluster join member2 --kubeconfig=$HOME/.kube/kind-kurator-member2.config --cluster-type=kind
注册完成后,创建一个Fleet资源来管理这些集群:
# fleet.yaml
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: production-fleet
spec:
clusters:
- member1
- member2
namespaceSame:
enabled: true
namespaces:
- default
- production
serviceAccountSame:
enabled: true
serviceAccounts:
- default
应用这个配置:
kubectl apply -f fleet.yaml
此时,Kurator已经完成了基础环境的搭建,可以开始探索其强大的多集群管理能力了。
三、Fleet集群管理深度解析
Fleet是Kurator的核心抽象,它将多个物理集群抽象为一个逻辑单元,提供统一的资源管理、策略同步和服务发现能力。深入理解Fleet的工作原理,是掌握Kurator多集群管理的关键。
3.1 Fleet资源拓扑结构
Fleet资源拓扑结构参考图: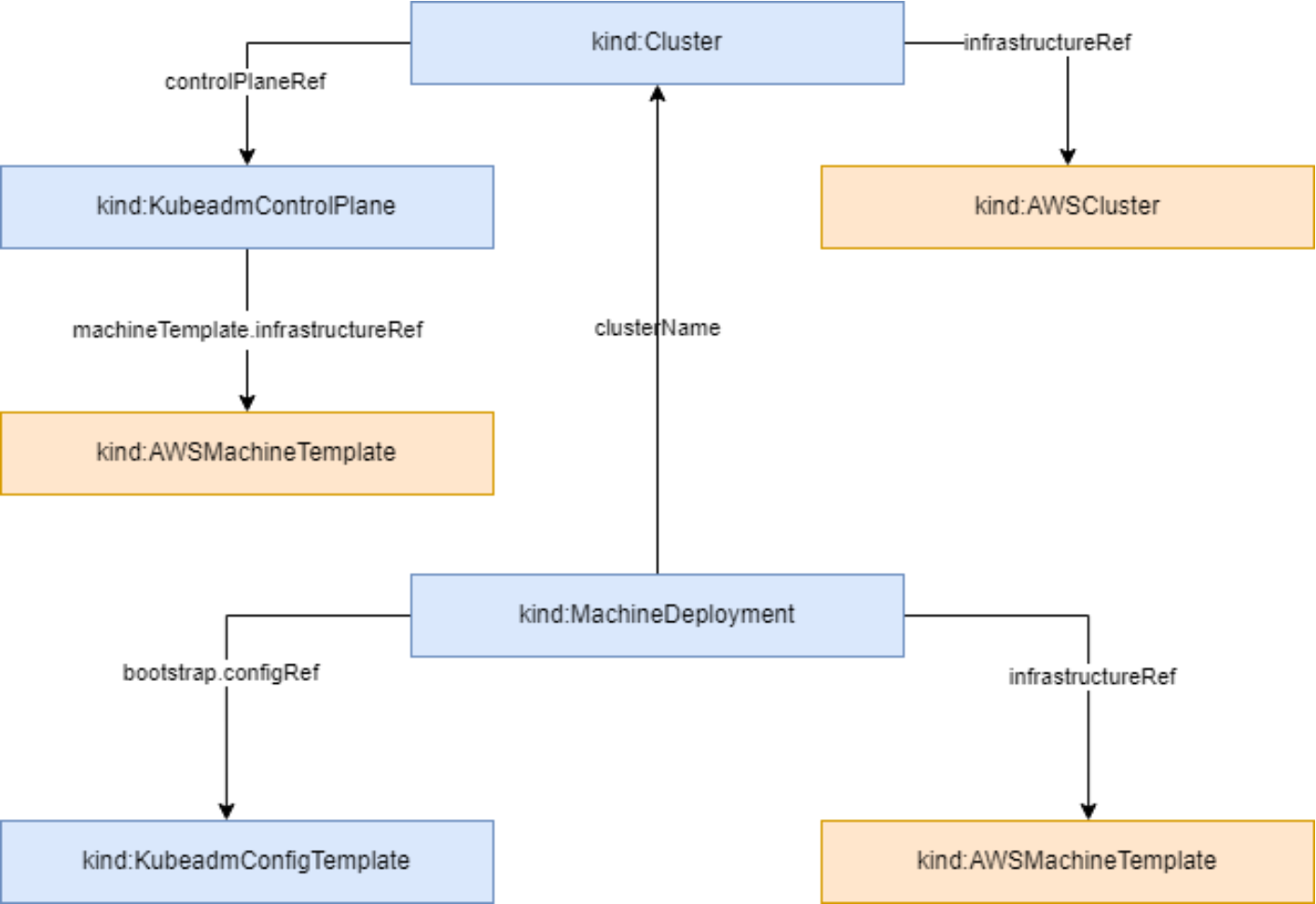
Fleet的资源拓扑结构设计精巧,包含多个层次的抽象。在最外层,Fleet资源定义了集群成员和全局策略;在中间层,通过ClusterSet和ResourceBinding等资源实现跨集群资源分发;在底层,各个成员集群通过agent组件与控制平面保持同步。
这种拓扑结构支持多种集群组织模式:扁平模式下所有集群地位平等;层次模式下可以定义hub-spoke架构,实现区域化管理;混合模式则可以根据业务需求灵活组合。例如,对于全球部署的应用,可以按地理区域创建多个Fleet,每个Fleet内部采用扁平模式,Fleet之间通过全局策略协调。
Fleet的拓扑信息可以通过以下命令查看:
kubectl get fleet production-fleet -o yaml
kubectl get clusterset -A
kubectl get resourcebinding -A
3.2 服务相同性实现机制
Fleet 队列中的服务相同性官方参考图: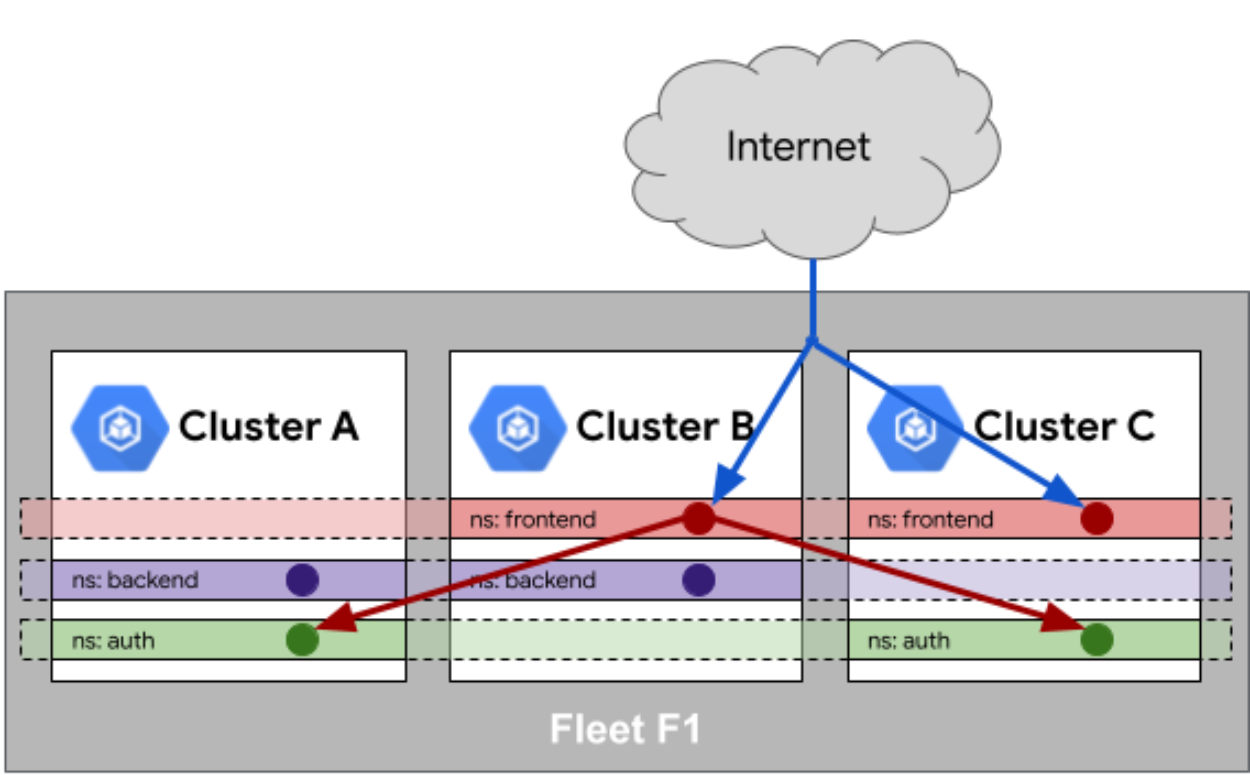
在多集群环境中,服务相同性(Service Sameness)是一个关键挑战。Kurator通过Fleet实现了跨集群的服务发现和通信,使得应用无需关心底层集群分布。
当在Fleet中启用服务相同性后,Kurator会自动在所有成员集群中创建相同的服务定义,并通过服务网格或DNS联邦实现跨集群服务发现。其实现机制包括:
- 服务元数据同步:将服务定义同步到所有成员集群
- 端点聚合:收集各集群中服务的端点信息
- 跨集群路由:基于Istio或CoreDNS实现智能路由
- 健康检查:持续监控跨集群服务的可用性
以下是一个启用服务相同性的Fleet配置示例:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: service-fleet
spec:
clusters:
- member1
- member2
serviceSame:
enabled: true
services:
- name: frontend
namespace: default
- name: backend
namespace: default
3.3 身份与策略统一管理
Kurator 统一策略管理参考图: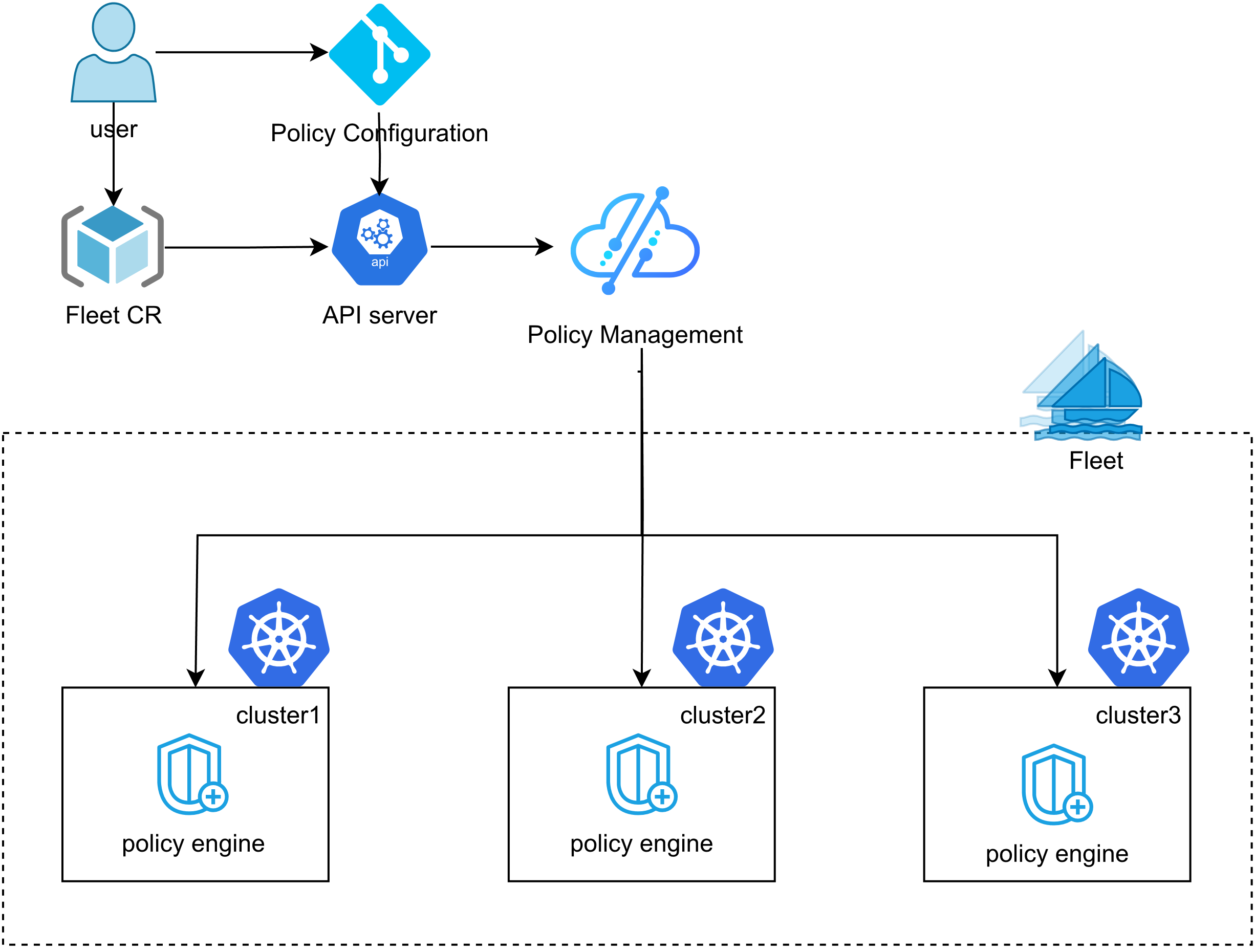
在多集群环境中,身份管理和策略一致性是安全合规的基础。Kurator的Fleet提供了统一的身份相同性(Identity Sameness)和策略管理能力。
身份相同性确保在所有成员集群中,相同的服务账号具有相同的权限和证书。这通过同步ServiceAccount、Role、RoleBinding等资源实现。策略管理则通过集成Kyverno,将安全策略、网络策略、资源配额等统一定义和分发。
以下代码展示了如何在Fleet中配置身份相同性:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: identity-fleet
spec:
clusters:
- member1
- member2
serviceAccountSame:
enabled: true
serviceAccounts:
- name: app-admin
namespace: production
clusterRoleBindings:
- name: cluster-admin
- name: app-reader
namespace: production
roleBindings:
- name: view
namespace: production
这种统一的身份和策略管理,大大简化了多集群环境中的权限控制和合规审计,为企业级应用提供了坚实的安全基础。
四、Karmada跨集群弹性伸缩实践
Karmada跨集群弹性伸缩策略参考图: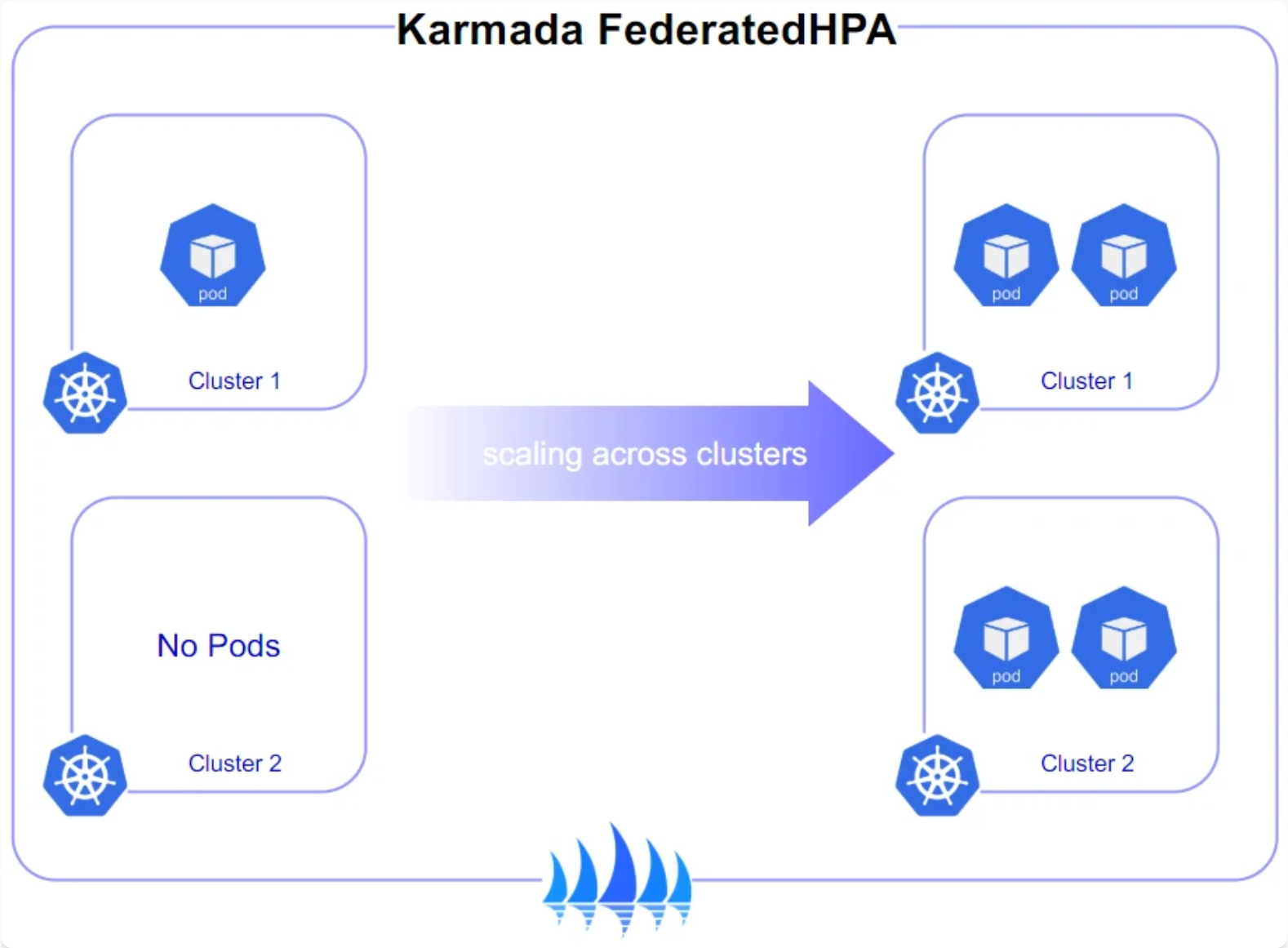
Karmada作为Kurator集成的核心组件之一,提供了强大的跨集群调度和弹性伸缩能力。本节将深入探讨如何利用Karmada实现智能的跨集群资源管理和自动扩缩容。
4.1 Karmada架构与工作原理
Karmada 的总体架构官方参考图: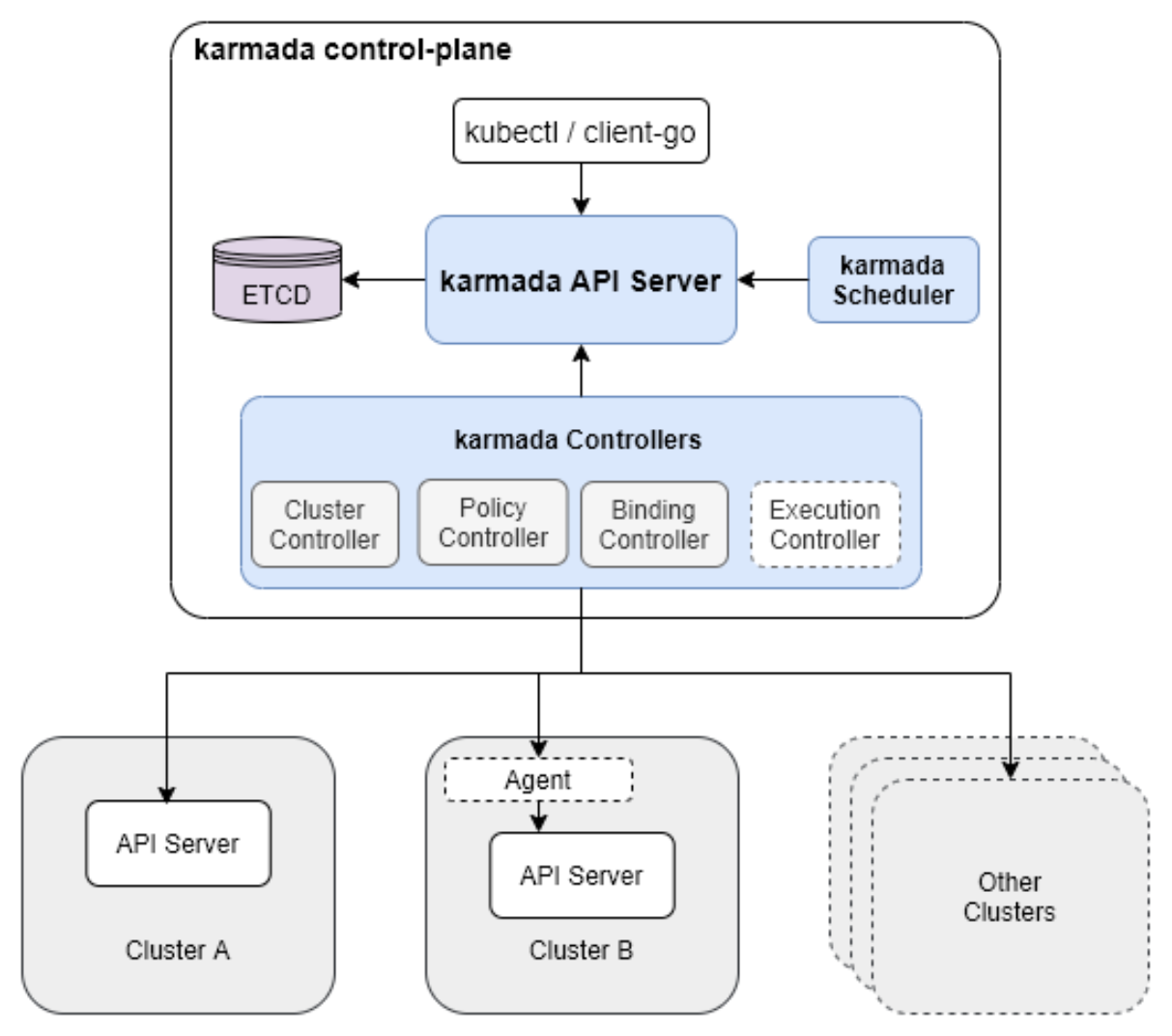
Karmada采用多层调度架构,包含全局调度器(Global Scheduler)和集群调度器(Cluster Scheduler)两个层次。全局调度器负责将工作负载分发到合适的集群,考虑集群容量、地理位置、成本等因素;集群调度器则在单个集群内部进行Pod调度,与Kubernetes原生调度器协同工作。
Karmada的核心资源包括:
- Cluster:表示成员集群的注册信息
- PropagationPolicy:定义资源分发策略
- OverridePolicy:定义集群特定的覆盖配置
- ResourceBinding:表示已绑定的资源分发状态
在Kurator环境中,Karmada与Fleet深度集成,Fleet资源会自动创建相应的PropagationPolicy,实现无缝的跨集群调度。
4.2 跨集群弹性伸缩配置
Karmada提供了多种弹性伸缩策略,包括基于副本数的静态分发、基于集群负载的动态分发、以及基于自定义指标的智能分发。以下是一个基于集群负载的动态分发配置示例:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
meta
name: frontend-dynamic
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: frontend
placement:
clusterAffinity:
clusterNames:
- member1
- member2
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightList:
- targetCluster:
clusterNames:
- member1
weight: 60
- targetCluster:
clusterNames:
- member2
weight: 40
这种配置会根据权重(60%:40%)将frontend部署的副本分配到两个集群,Karmada会监控集群资源使用情况,动态调整权重以优化资源利用率。
4.3 基于指标的智能调度实践
更高级的场景是基于自定义指标的智能调度。例如,根据用户地理位置将流量路由到最近的集群,或根据集群成本动态调整工作负载分布。以下是一个基于延迟指标的调度策略:
apiVersion: policy.karmada.io/v1alpha1
kind: ClusterPropagationPolicy
meta
name: latency-aware-policy
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: latency-sensitive-app
placement:
clusterAffinity:
clusterNames:
- member1
- member2
replicaScheduling:
replicaDivisionPreference: Aggregated
spreadConstraints:
- spreadByField: cluster.region
maxGroups: 2
clusterDecisionStrategy:
strategy: MinimizeLatency
metrics:
- name: latency_ms
type: External
external:
metricSelector:
matchLabels:
app: latency-sensitive-app
targetValue: 100m
这种配置会根据外部指标"latency_ms"的值,自动将工作负载调度到延迟最低的集群,确保用户体验最优。在Kurator环境中,这些指标可以来自Prometheus监控系统,实现端到端的可观测性驱动调度。
五、KubeEdge边缘计算集成与协同
在物联网和边缘计算场景中,Kurator通过集成KubeEdge,将云原生能力延伸到边缘设备,实现云边协同的统一管理。本节将深入探讨KubeEdge的核心架构和在Kurator中的集成实践。
5.1 KubeEdge架构与核心组件
KubeEdge架构参考图: 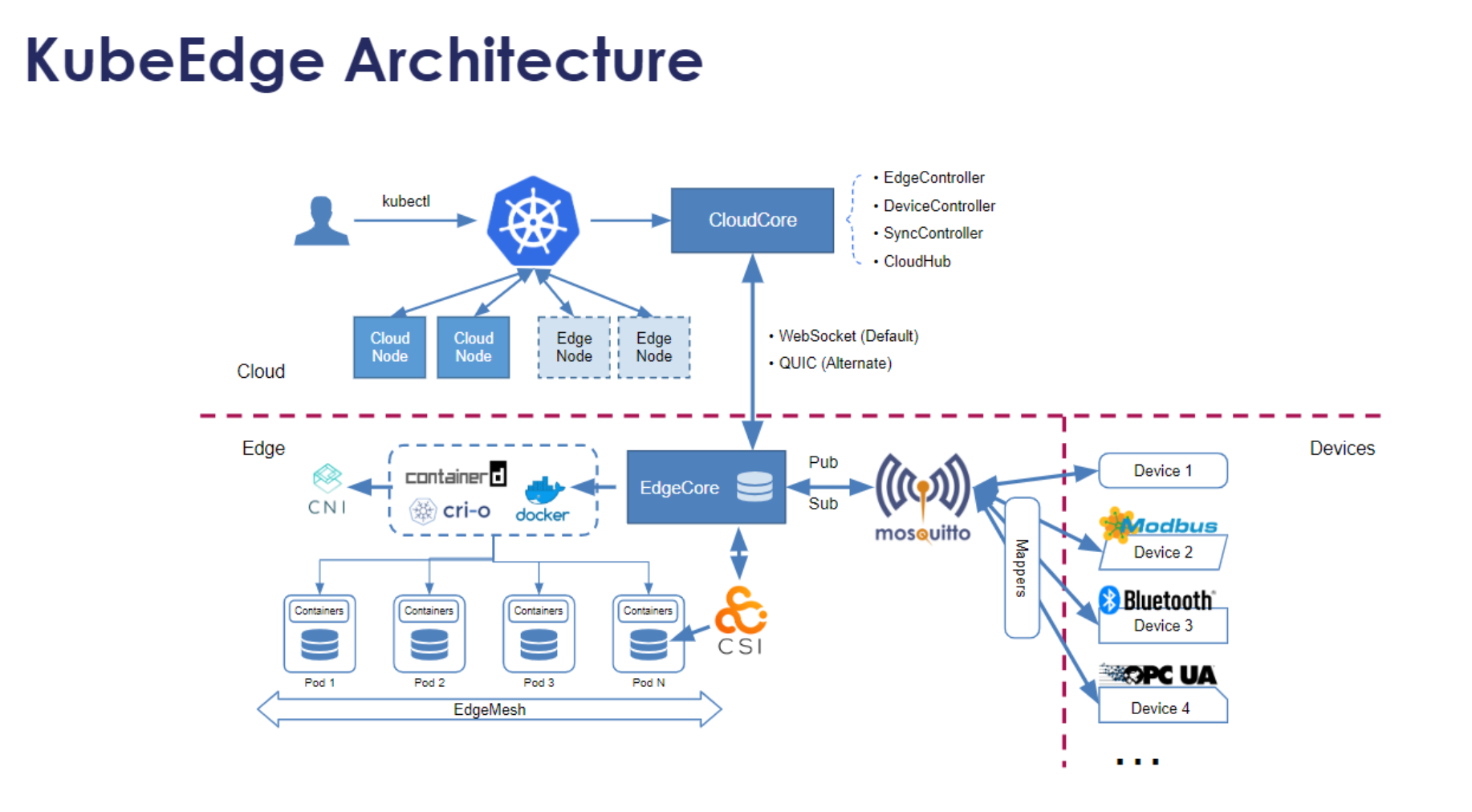
KubeEdge的核心组件参考图: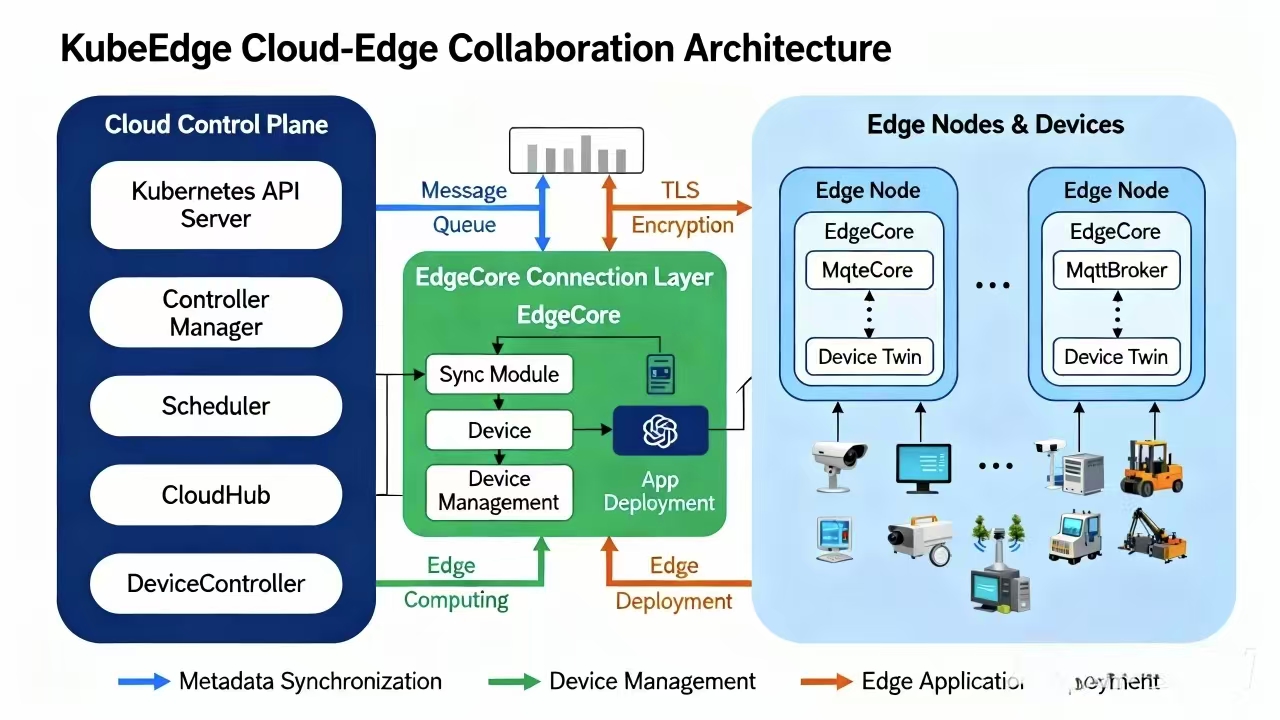
KubeEdge采用分层架构,核心组件包括:
- CloudCore:运行在云端的控制平面组件,负责与Kubernetes API Server通信
- EdgeCore:运行在边缘节点的代理组件,负责在边缘执行Pod、管理设备等
- DeviceTwin:设备孪生服务,实现云边设备状态同步
- EventBus:消息总线,支持MQTT等协议,实现边缘设备通信
在Kurator中,KubeEdge集群可以像普通Kubernetes集群一样注册到Fleet中,使得边缘节点能够参与全局资源调度和服务发现。这种集成使得企业可以在统一的控制平面下管理云、边、端三层架构。
5.2 云边协同GitOps实践
GitOps是Kurator的核心理念之一,在边缘计算场景中尤为重要。通过将边缘应用的期望状态存储在Git仓库中,Kurator可以确保边缘节点在断网恢复后自动同步到最新状态,保证系统的一致性和可靠性。
以下是一个边缘应用的GitOps配置示例:
# edge-app.yaml
apiVersion: apps/v1
kind: Deployment
meta
name: edge-collector
namespace: edge-system
annotations:
kurator.dev/fleet: edge-fleet
spec:
replicas: 3
selector:
matchLabels:
app: edge-collector
template:
metadata:
labels:
app: edge-collector
spec:
tolerations:
- key: node-role.kubernetes.io/edge
operator: Exists
nodeSelector:
node-role.kubernetes.io/edge: "true"
containers:
- name: collector
image: edge-collector:v1.0
resources:
limits:
memory: 256Mi
cpu: 100m
volumeMounts:
- name: edge-data
mountPath: /data
volumes:
- name: edge-data
hostPath:
path: /var/lib/edge-data
这个配置通过annotation kurator.dev/fleet: edge-fleet 指定目标Fleet,Kurator会自动将其同步到边缘集群。同时,通过tolerations和nodeSelector确保Pod调度到边缘节点。
5.3 边缘设备管理与数据同步
在工业物联网场景中,边缘设备的管理和数据同步是关键挑战。Kurator结合KubeEdge提供了完整的设备管理解决方案。
以下是一个温度传感器的设备配置示例:
apiVersion: devices.kubeedge.io/v1alpha2
kind: Device
meta
name: temperature-sensor-001
namespace: edge-system
labels:
kurator.dev/fleet: edge-fleet
spec:
deviceModelRef:
name: temperature-sensor-model
protocol:
modbus:
rtu:
serialPort: /dev/ttyS0
baudRate: 9600
nodeSelector:
node-role.kubernetes.io/edge: "true"
properties:
- name: temperature
dataType: int
readOnly: true
- name: samplingInterval
dataType: int
readOnly: false
defaultValue: 60
通过Kurator的Fleet机制,这个设备配置会被自动同步到指定的边缘集群,CloudCore和EdgeCore会协作实现设备的连接、数据采集和状态同步。同时,结合Prometheus监控,可以对边缘设备的运行状态进行统一监控和告警。
六、Volcano批处理调度优化与AI工作负载支持
在大数据分析和AI训练场景中,传统Kubernetes调度器难以满足复杂的工作负载需求。Kurator集成了Volcano,为批处理任务和AI工作负载提供了专业的调度优化能力。本节将深入探讨Volcano的核心架构和在Kurator中的应用实践。
6.1 Volcano调度架构分析
Volcano调度架构参考图: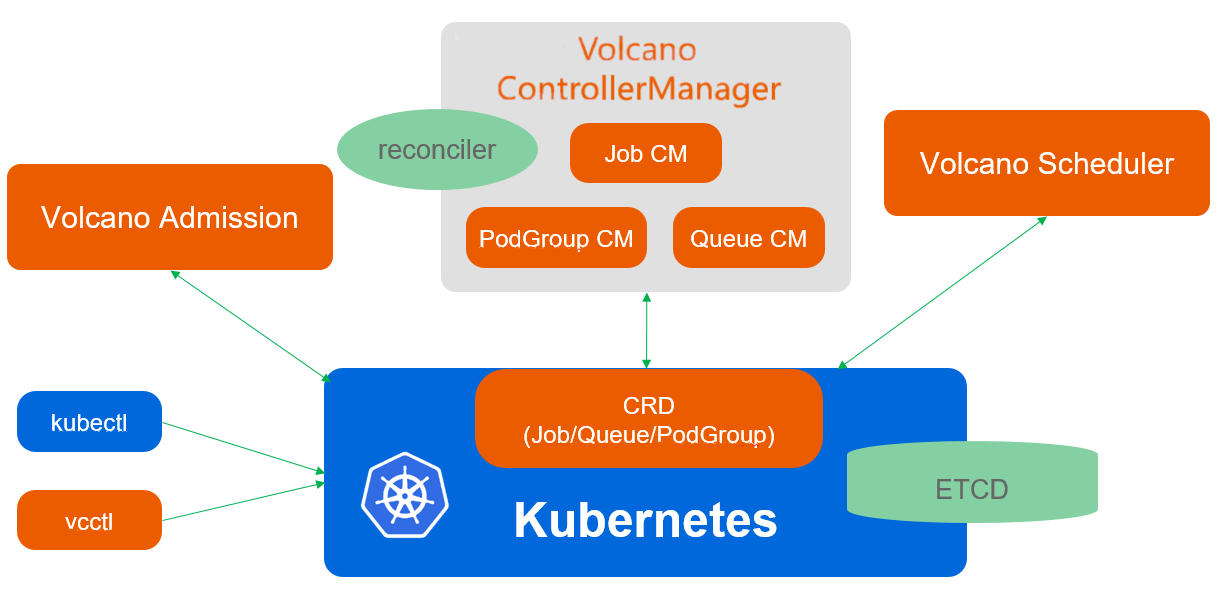
Volcano采用插件化的调度架构,核心组件包括:
- Scheduler:主调度器,协调各调度插件
- Queue:资源队列,支持公平调度和优先级调度
- PodGroup:Pod分组,确保组内Pod同时调度
- Action/Plugin:调度动作和插件,实现具体调度策略
在Kurator环境中,Volcano与Karmada深度集成,可以在跨集群场景下实现批处理任务的智能调度。例如,将AI训练任务分发到GPU资源充足的集群,将数据处理任务分发到存储密集型集群。
6.2 AI训练任务调度优化
AI训练任务通常具有资源密集、运行时间长、需要GPU加速等特点。Volcano通过PodGroup和Queue机制,为AI训练提供了优化的调度策略。
以下是一个AI训练任务的配置示例:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
meta
name: ai-training-job
namespace: ai-workload
spec:
minAvailable: 4
schedulerName: volcano
queue: ai-queue
tasks:
- replicas: 4
name: worker
template:
spec:
containers:
- name: tensorflow
image: tensorflow/tensorflow:latest-gpu
resources:
limits:
nvidia.com/gpu: 1
memory: 16Gi
cpu: 4
volumeMounts:
- name: data-volume
mountPath: /data
volumes:
- name: data-volume
persistentVolumeClaim:
claimName: training-data-pvc
这个配置使用Volcano的Job API,定义了一个需要4个GPU worker的AI训练任务。通过minAvailable: 4确保所有worker同时启动,避免部分启动导致的资源浪费。queue: ai-queue指定使用AI专用队列,可以配置队列级别的资源配额和优先级策略。
6.3 跨集群批处理任务分发
在Kurator环境中,结合Karmada和Volcano,可以实现跨集群的批处理任务分发。例如,将大规模数据处理任务分发到多个集群,每个集群处理数据的一个分片,最后汇总结果。
以下是一个跨集群批处理任务的PropagationPolicy配置:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
meta
name: batch-processing-policy
spec:
resourceSelectors:
- apiVersion: batch.volcano.sh/v1alpha1
kind: Job
name: data-processing-job
placement:
clusterAffinity:
clusterNames:
- member1
- member2
- member3
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightList:
- targetCluster:
clusterNames:
- member1
weight: 33
- targetCluster:
clusterNames:
- member2
weight: 33
- targetCluster:
clusterNames:
- member3
weight: 34
这种配置将data-processing-job任务按权重分配到三个集群,每个集群处理约1/3的数据量。结合Volcano的队列管理和资源隔离能力,可以确保不同业务的批处理任务不会相互干扰,实现资源的最优利用。
七、GitOps与CI/CD流水线构建实践
GitOps是Kurator的核心设计理念之一,通过将基础设施和应用配置版本化,实现声明式的系统管理和自动化部署。本节将深入探讨Kurator中GitOps的实现方式,并构建完整的CI/CD流水线。
7.1 GitOps实现架构
GitOps实现方式官方参考图: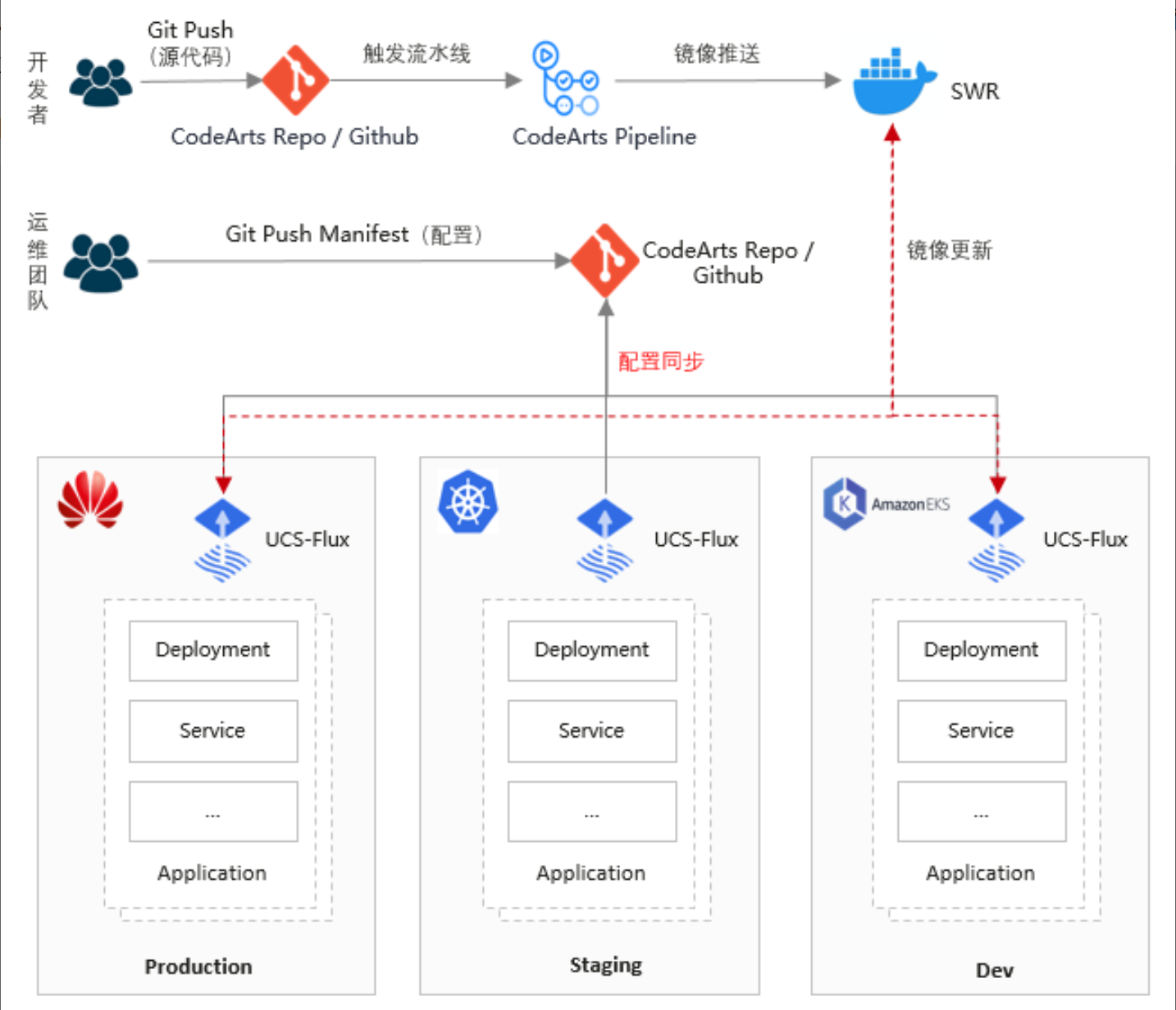
Kurator基于FluxCD实现GitOps能力,核心组件包括:
- Source Controller:监控Git仓库、Helm仓库等源的变化
- Kustomize Controller:处理Kustomize manifests
- Helm Controller:管理Helm releases
- Notification Controller:处理事件通知
在Kurator中,这些组件与Fleet深度集成,实现了跨集群的GitOps同步。用户只需将配置推送到Git仓库,Kurator会自动将变更同步到所有相关的集群,确保系统状态与期望状态一致。
7.2 多环境部署流水线设计
在企业级应用中,通常需要支持多环境(dev/staging/prod)部署。Kurator通过Git仓库的分支策略和目录结构,可以轻松实现这种需求。
以下是一个多环境部署的仓库结构示例:
├── clusters/
│ ├── production/
│ │ ├── fleet.yaml
│ │ ├── kustomization.yaml
│ │ └── namespaces/
│ ├── staging/
│ │ ├── fleet.yaml
│ │ └── kustomization.yaml
│ └── development/
│ ├── fleet.yaml
│ └── kustomization.yaml
├── apps/
│ ├── frontend/
│ │ ├── base/
│ │ ├── production/
│ │ ├── staging/
│ │ └── development/
│ └── backend/
│ ├── base/
│ ├── production/
│ ├── staging/
│ └── development/
└── infrastructure/
├── monitoring/
├── logging/
└── networking/
通过这种结构,可以实现:
- 环境隔离:不同环境使用不同的Fleet和集群
- 配置继承:base目录包含通用配置,环境目录覆盖特定配置
- 权限控制:通过Git分支保护策略控制生产环境变更
7.3 自动化CI/CD流水线实现
结合GitHub Actions或Jenkins,可以构建完整的CI/CD流水线。以下是一个GitHub Actions工作流示例,展示如何在代码变更后自动构建、测试和部署应用:
# .github/workflows/cd.yaml
name: Continuous Deployment
on:
push:
branches:
- main
- staging
- production
pull_request:
branches:
- main
jobs:
build-and-test:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v2
- name: Login to Container Registry
uses: docker/login-action@v2
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Build and push Docker image
uses: docker/build-push-action@v3
with:
context: .
push: true
tags: ghcr.io/${{ github.repository }}/app:${{ github.sha }}
cache-from: type=gha
cache-to: type=gha,mode=max
- name: Run tests
run: |
docker run ghcr.io/${{ github.repository }}/app:${{ github.sha }} pytest
deploy-to-environment:
needs: build-and-test
runs-on: ubuntu-latest
environment: ${{ github.ref_name }}
steps:
- name: Checkout infrastructure repo
uses: actions/checkout@v3
with:
repository: ${{ github.repository_owner }}/infrastructure
path: infrastructure
- name: Update image tag
run: |
cd infrastructure/apps/frontend/${{ github.ref_name }}
yq e '.images[0].newTag = "${{ github.sha }}"' -i kustomization.yaml
- name: Commit and push changes
run: |
cd infrastructure
git config user.name "GitHub Actions"
git config user.email "actions@github.com"
git add .
git commit -m "Update frontend image to ${{ github.sha }}"
git push
这个工作流实现了从代码构建、测试到部署的完整流程。当代码推送到不同分支时,会自动部署到对应的环境。通过修改infrastructure仓库中的kustomization.yaml文件,触发Kurator的GitOps同步机制,实现自动化部署。
八、Kurator未来发展方向与前瞻创想
随着云原生技术的不断发展,Kurator作为分布式云原生平台,面临着新的机遇和挑战。本节将基于技术发展趋势,对Kurator的未来发展方向提出前瞻性思考。
8.1 服务网格与多集群流量管理演进
当前,Istio已经成为服务网格的事实标准,但在多集群、多云环境中,服务发现、流量管理、安全策略等仍面临挑战。未来的Kurator应该在以下方面深化服务网格集成:
- 统一服务身份:基于SPIFFE/SPIRE标准,实现跨集群、跨云的服务身份统一管理
- 智能流量调度:结合AI/ML技术,基于实时流量模式和业务指标,动态优化跨集群流量路由
- 边缘服务网格:将服务网格能力延伸到边缘节点,支持边缘服务发现和治理
代码层面,可以预见Kurator会提供更高级的抽象API,简化多集群服务网格配置:
apiVersion: networking.kurator.dev/v1alpha1
kind: MultiClusterService
metadata:
name: global-frontend
spec:
serviceName: frontend
namespace: default
clusters:
- name: member1
weight: 50
failoverPriority: high
- name: member2
weight: 50
failoverPriority: medium
trafficPolicy:
loadBalancer:
mode: ROUND_ROBIN
connectionPool:
tcp:
maxConnections: 100
outlierDetection:
consecutiveErrors: 5
interval: 10s
8.2 可观测性统一平台构建
可观测性是云原生系统的核心支柱之一。当前,Kurator集成了Prometheus、Jaeger等工具,但多集群、多云环境下的统一可观测性仍需加强。未来发展方向包括:
- 统一指标采集:跨集群的指标联邦和聚合,支持全局视图和局部视图
- 智能告警:基于历史数据和机器学习,实现异常检测和智能告警
- 全链路追踪:跨集群、跨服务的分布式追踪,支持边缘设备到云端的完整链路
Kurator可能会提供统一的可观测性API,简化多集群监控配置:
apiVersion: observability.kurator.dev/v1alpha1
kind: MonitoringProfile
meta
name: production-profile
spec:
clusters:
- member1
- member2
- edge-cluster
metrics:
- name: cpu_usage
query: sum(container_cpu_usage_seconds_total) by (cluster, namespace)
- name: request_latency
query: histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le, cluster, service))
alerting:
rules:
- alert: HighErrorRate
expr: sum(rate(http_requests_total{status=~"5.."}[5m])) / sum(rate(http_requests_total[5m])) > 0.1
for: 5m
labels:
severity: critical
annotations:
summary: "High error rate on {{ $labels.service }}"
8.3 AI驱动的自适应云原生基础设施
站在技术发展的前沿,我认为Kurator的终极形态应该是AI驱动的自适应云原生基础设施。这种基础设施能够:
- 自主优化:基于实时负载、成本、性能指标,自动调整资源分配和调度策略
- 预测性运维:通过分析历史数据,预测潜在问题并提前采取措施
- 智能治理:理解业务意图,自动生成和优化安全策略、网络策略等
具体技术路径包括:
- 构建云原生数字孪生:创建物理基础设施的虚拟映射,支持模拟和预测
- 集成强化学习:训练调度策略模型,优化资源利用率和业务SLA
- 实现认知运维:通过NLP理解运维工单,自动生成解决方案
以下是一个概念性的AI调度API设计:
apiVersion: ai.kurator.dev/v1alpha1
kind: AdaptiveScheduler
meta
name: business-critical-scheduler
spec:
objectives:
- type: PERFORMANCE
metric: p99_latency
target: 100ms
weight: 0.6
- type: COST
metric: dollar_per_request
target: 0.001
weight: 0.4
constraints:
- type: AVAILABILITY
minReplicas: 3
maxClusterFailure: 1
learningStrategy:
algorithm: REINFORCEMENT_LEARNING
trainingDataRetention: 7d
explorationRate: 0.1
clusters:
- name: member1
costFactor: 1.0
performanceFactor: 1.2
- name: member2
costFactor: 0.8
performanceFactor: 1.0
- name: edge-cluster
costFactor: 0.5
performanceFactor: 0.7
这种AI驱动的调度器会持续学习集群性能特征、业务负载模式,自动调整调度策略,在满足SLA的前提下最小化成本。这代表了云原生基础设施的未来方向:从自动化到智能化,从被动响应到主动优化。
Kurator作为开源分布式云原生平台,正处于这一技术变革的前沿。通过持续集成创新技术、倾听社区需求、保持架构开放性,Kurator有望成为构建下一代智能云原生基础设施的核心引擎,推动企业数字化转型进入新阶段。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 26
26 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)