如何用Kurator搞定云边协同和多集群治理,这波实操必须收藏
如何用Kurator搞定云边协同和多集群治理,这波实操必须收藏
说实话,这两年云原生圈子里“多云”、“边缘计算”喊得震天响,但真落地的没几个。为啥?太复杂了!你想想,光是一个K8s就够喝一壶的,再让你搞多集群编排、边缘设备接入、还要做批量计算,头发都不够掉的。Kurator这项目,我用了有一阵子了,感觉它最大的痛点抓得很准:它不是造新轮子,而是做一个“整合大师”,把业界最强的开源组件集成好,给你一套统一的API去操作。不管你是要管在数据中心的服务器,还是要管几千公里外的高速公路摄像头,用这一套逻辑就够了。
今天咱们就把Kurator拆开了揉碎了,从环境搭建到最复杂的流量治理、算力调度,一次性给它讲透。
第一部分:别光说不练,先把Kurator环境搭起来再说
你要学这东西,光看文档是学不会的,得动手。Kurator的安装其实已经简化了很多,但有些细节还是得注意。
也就是几行命令的事儿,环境跑起来
咱们先搞个测试环境。通常我自己做实验或者给客户做POC(概念验证)的时候,都喜欢直接用源码安装,这样心里有底,想改啥配置也方便。
首先,你的机器上得有Go环境和Docker,这个我就不废话了。重点来了,咱们得把Kurator的代码拉下来。
在项目地址中,可以看到可以clone到本地
https://gitcode.com/kurator-dev/kurator.git
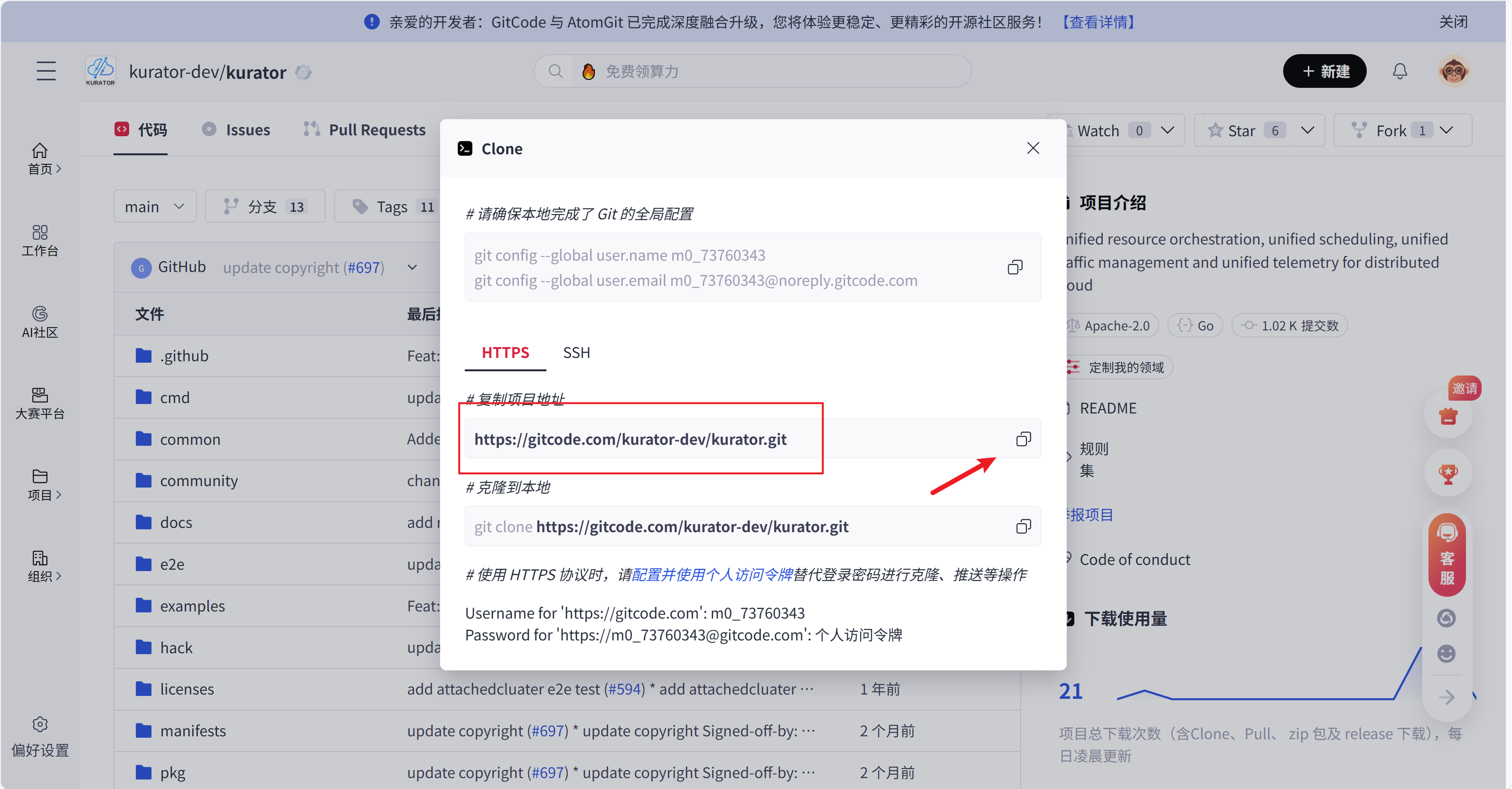
或者我们也可以下载到本地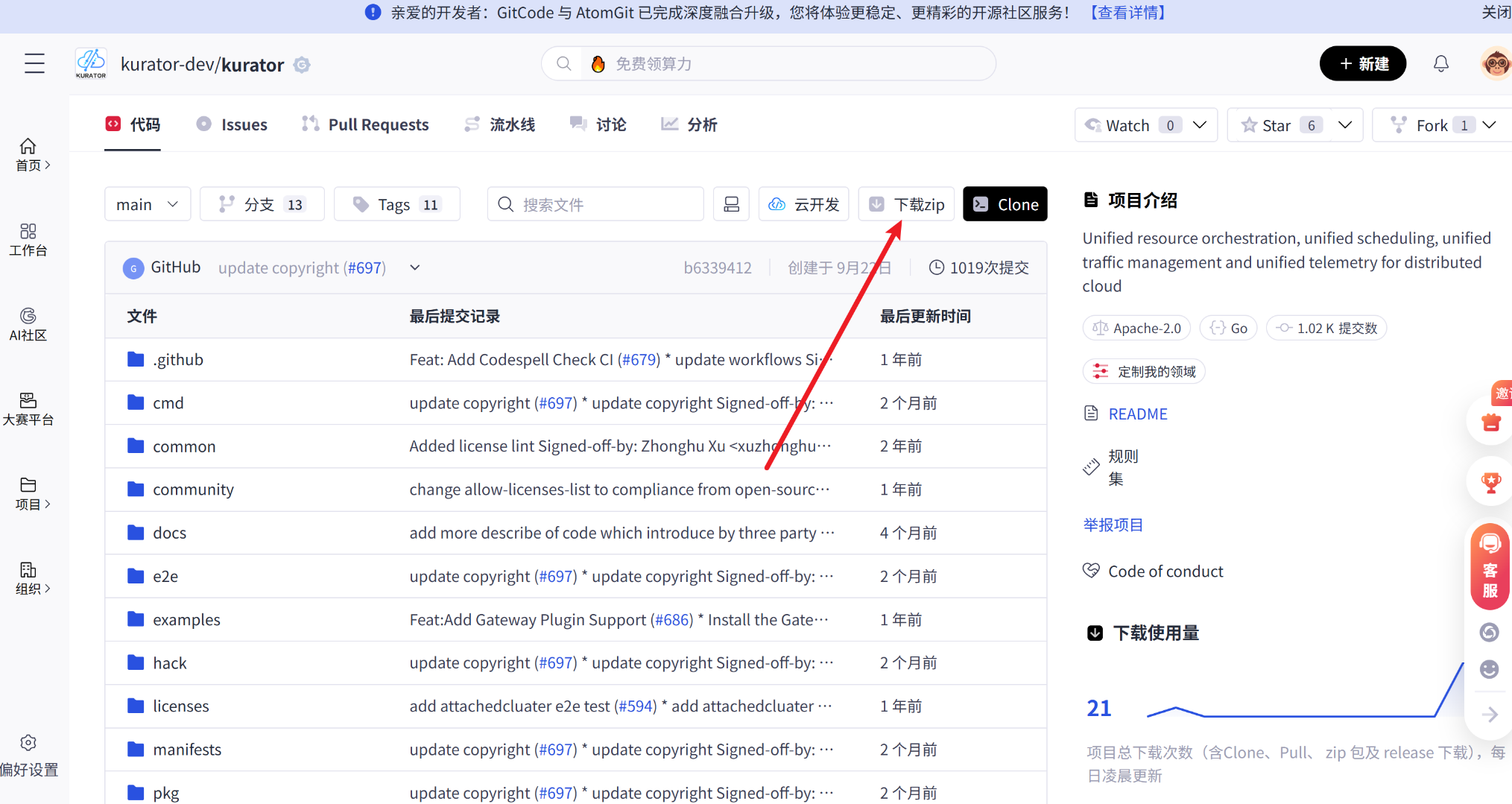
可以看到我们资源文件已经下载下来了
可以看到版本是0.6.0
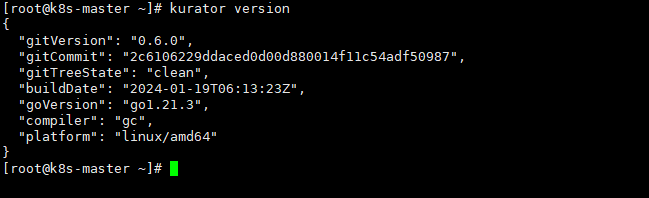
环境拉下来之后,你得准备一个主集群(Host Cluster),通常我们会用Kind或者Minikube先起一个,然后把Kurator的Operator跑上去。这一步搞定后,你就有了一个控制平面。
GitOps这玩意儿怎么在Kurator里落地?
环境有了,咱们紧接着就得聊聊怎么部署应用。现在谁还手动 kubectl apply 啊?那太Low了,而且容易出错。Kurator原生支持GitOps,这东西的核心就是“一切皆代码”。
Kurator里的GitOps实现方式其实挺灵活的,它底层集成了FluxCD的能力,但做了一层封装。你不需要去写复杂的Flux CRD,只需要在Kurator的配置文件里告诉它:“嘿,我的应用配置在这个Git仓库的这个分支上。”
Kurator的Controller会周期性地去扫描你的Git仓库。一旦你往Git里提交了新的代码或配置,它立刻就感知到了,然后自动把变更同步到目标集群里。这在多集群环境下简直是救命稻草——你不用登录到100个集群里去更新镜像版本,改一下Git,100个集群自动同步。
搭建一套丝滑的CI/CD流水线
这张图讲的是怎么用Kurator来搭建CI/CD流水线,从配置Pipeline、设置网关、绑定GitHub Webhook,再到创建各种密钥,一步步教你把自动化构建和部署跑起来,整个流程清晰又实用:
既然说了GitOps,那CI/CD流水线怎么串起来?在Kurator的生态里,我们通常是这么玩的:
Jenkins或者GitLab CI负责前半截——代码构建、单元测试、打Docker镜像,然后把镜像推到仓库,同时更新Git仓库里的Manifest文件(比如修改Deployment的image tag)。
后半截交给Kurator。Kurator监控到Manifest变了,自动触发同步。这中间不需要人工干预。如果你想做得更细致,Kurator还支持Tekton这类的云原生流水线工具。你可以定义一个Pipeline对象,把源码拉取、镜像构建、部署上线全部定义成K8s的资源对象,让Kurator去统一调度这个流水线。
第二部分:云边协同的那些“黑科技”与网络排查
搞定了控制平面,咱们来聊聊边缘计算。这是Kurator的一大卖点,毕竟它整合了KubeEdge。
KubeEdge云边协同架构的核心组件
这是KubeEdge云边协同架构的核心组件图,展示了云端控制平面、消息通道与边缘节点的全链路组件及交互方式: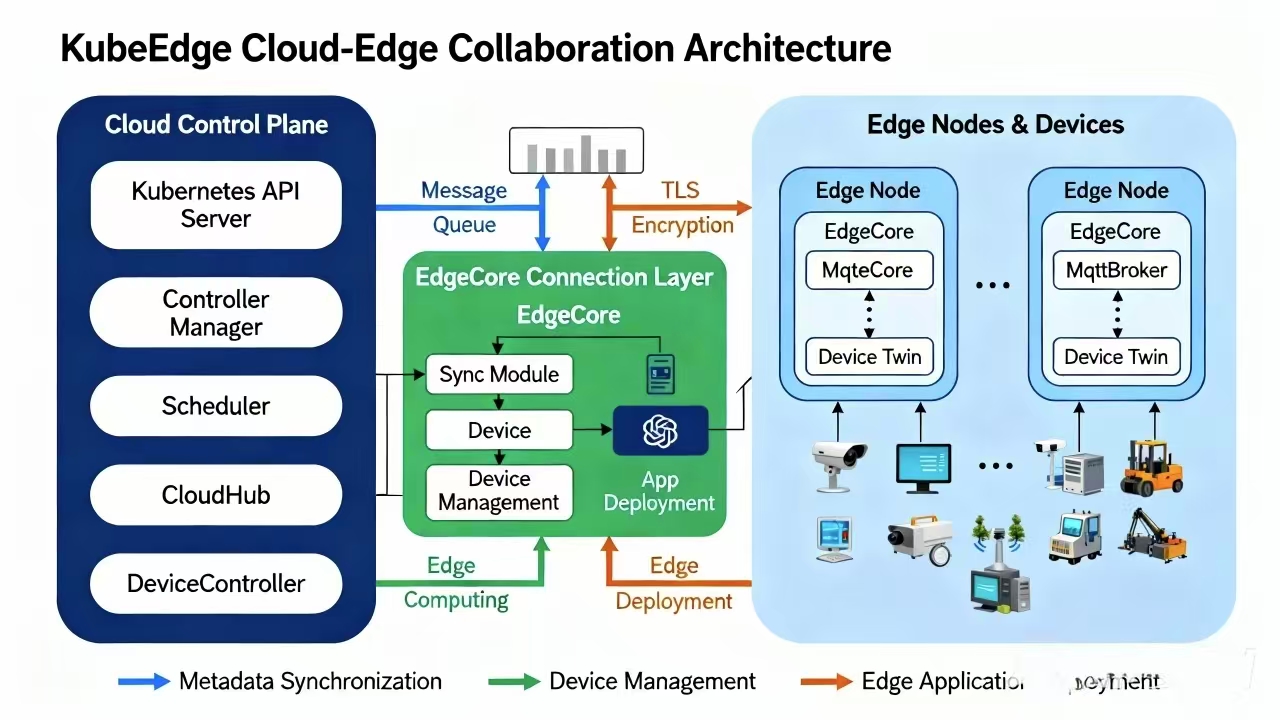
很多兄弟搞不清KubeEdge和原生K8s的区别。其实在Kurator里,KubeEdge主要分两头:云端(CloudCore)和边端(EdgeCore)。
CloudCore 跑在你的中心机房,它负责监听K8s的API Server,看看有没有新的Pod要调度到边缘节点。如果有,它就通过WebSocket通道把指令发出去。
EdgeCore 跑在你的树莓派或者工控机上。它是个轻量级的Kubelet,去掉了Docker里很多不常用的功能,内存占用极低。它负责接收云端的指令,拉起容器,同时还要把边缘设备的状态(比如温度传感器的读数)汇报给云端。
这两者之间配合的关键,在于它们能容忍“弱网”。网断了?没关系,EdgeCore会把数据存在本地数据库里,等网通了再重发。
那个神秘的“隧道机制”与网络连通性排查
在边缘场景下,最头疼的就是网络。边缘节点通常在防火墙后面,或者只有内网IP,云端怎么访问它?这就用到了隧道机制。
Kurator利用KubeEdge的隧道技术(通常是基于WebSocket或者QUIC协议),建立了一条从边缘主动连接云端的长连接。这样,云端的运维人员想要查看边缘容器的日志(kubectl logs)或者进入容器(kubectl exec),数据流其实是走这条反向隧道的。
网络连通性排查是实操中必须掌握的技能。如果你的边缘节点状态变成了 NotReady,或者日志拉不下来,大概率是隧道断了。
- 首先,去边缘节点看
edgecore的日志,搜connection refused之类的报错。 - 检查边缘节点能不能解析云端的域名。
- 最常见的问题:云端的端口(默认10000和10002)是不是被安全组封了?
- 有时候隧道建立起来了但数据不通,可能是MTU的问题,特别是走了VPN或者特殊专线的时候。
云边协同计算场景到底都在跑啥?
这张图展示了云边协同计算场景:终端数据在边缘侧实时处理,再与云端协同分析,实现低时延、高效率的智能应用,适用于工业、交通等对响应速度要求高的领域: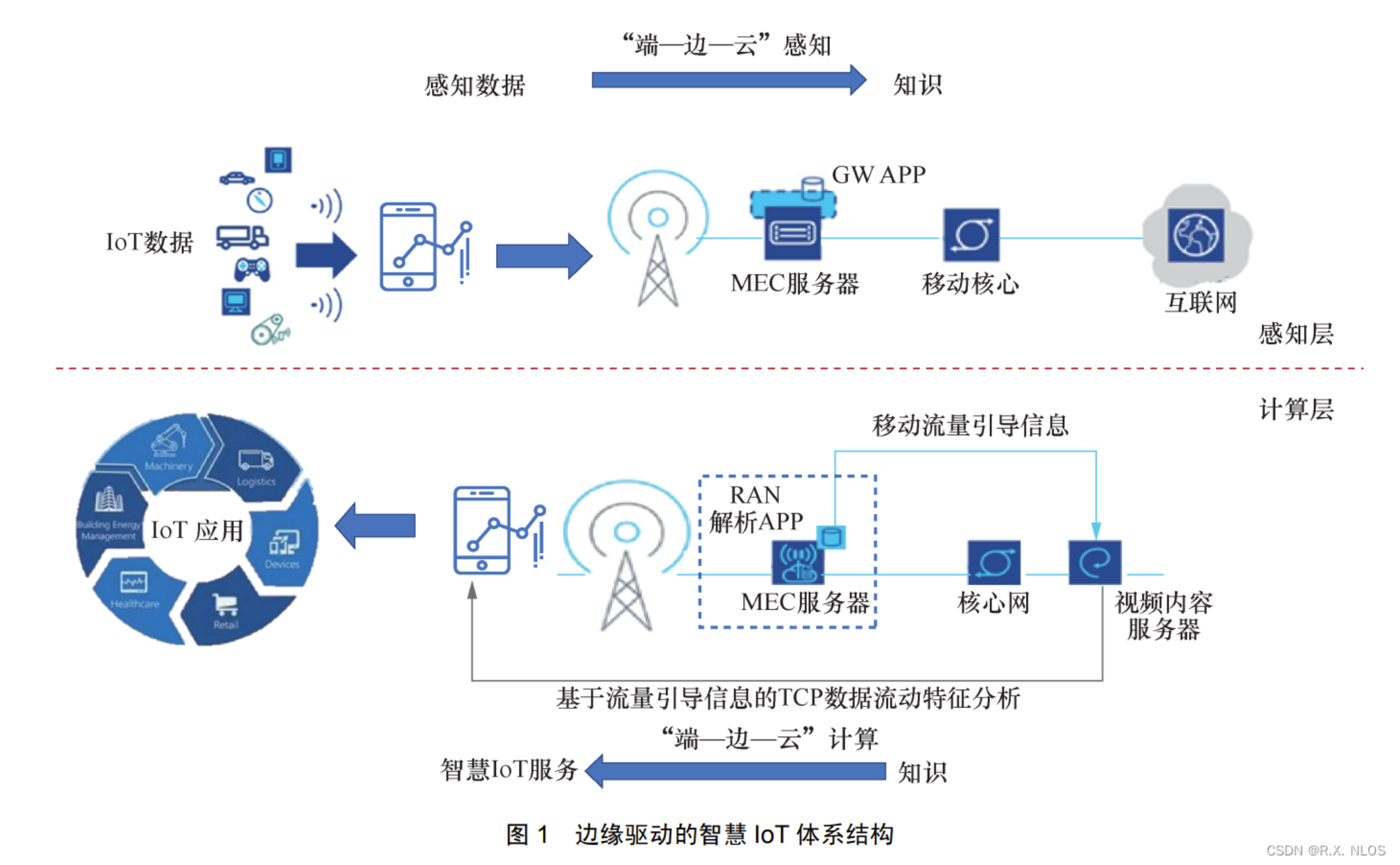
说了半天架构,到底啥场景用得上?我在项目里见得最多的:
- AI推理下沉:模型训练在云端(算力强),训练好了通过Kurator推送到边缘摄像头上做人脸识别(低延迟)。
- 数据预处理:工厂里成千上万个传感器,每秒产生海量数据。直接传上云带宽受不了。用Kurator在边缘部署一个Flink或简单的Python脚本,把数据清洗、聚合一下,只传结果上云。
第三部分:玩转Fleet舰队,多集群管理的艺术
当你手里的集群超过三个,你就需要“舰队”(Fleet)管理了。Kurator在这块引入了很多高级概念。
Fleet访问队列外部资源的身份映射
这是Fleet访问队列外部资源的身份映射示意图,展示了跨集群服务与云平台服务账户的统一身份关联机制: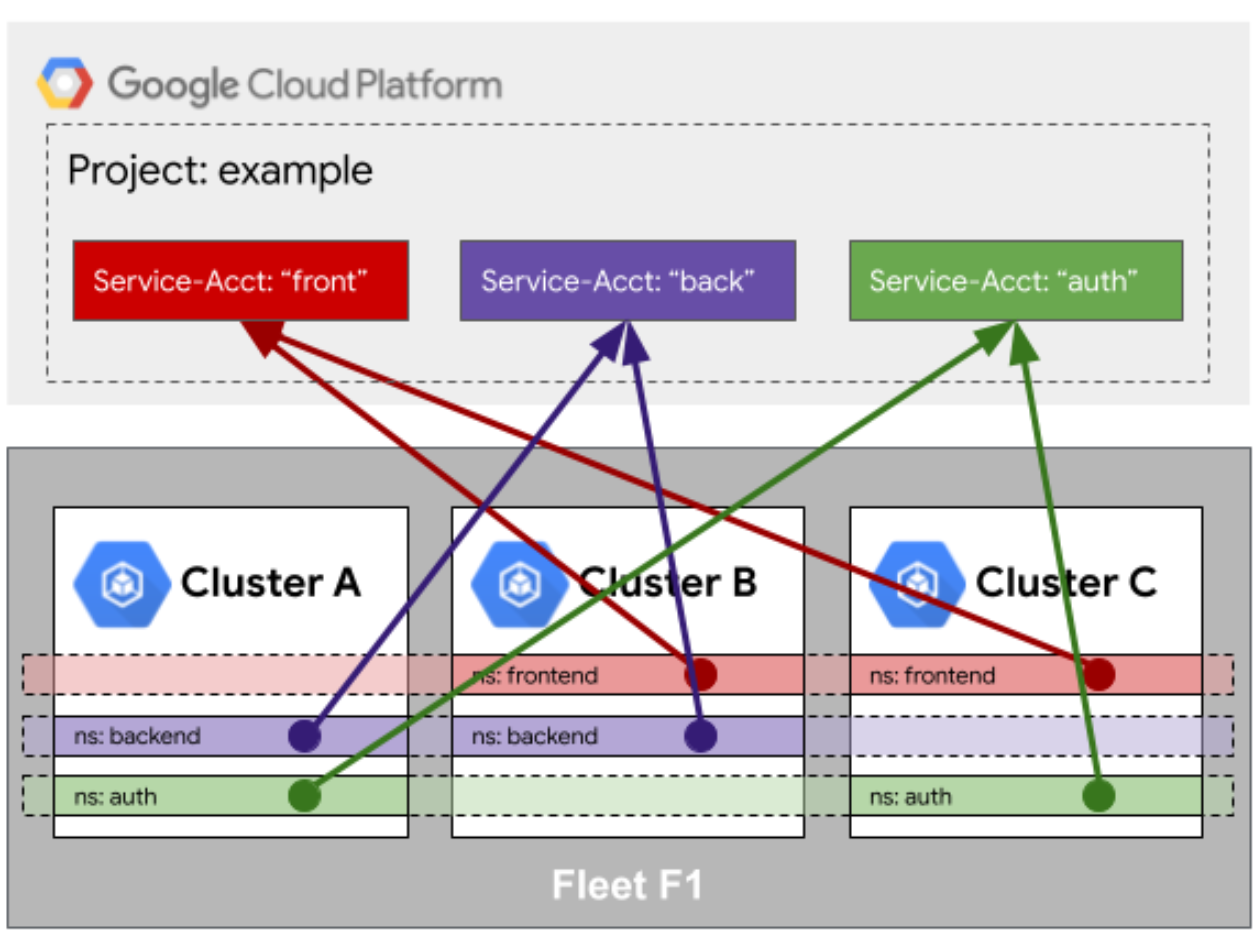
这个问题特别典型。假设你有一百个集群,每个集群里的应用都要去访问同一个AWS S3存储桶或者阿里的OSS。你难道要在一百个集群里埋一百个Access Key吗?那样做既不安全也难以维护。
Kurator提供了一种身份映射机制。它利用了Workload Identity的概念。你可以在管理平面统一配置一个身份策略,说:“所有在这个Fleet里的、属于my-app命名空间的Pod,都自动映射成这个云服务商的IAM角色。”
这样,当Pod启动时,Kurator会自动把临时的Token注入进去。应用拿这个Token就能访问外部资源,完全不需要在代码里写死密钥。这招在企业级安全合规里是非常重要的。
Fleet舰队中命名空间相同性
这是Fleet舰队中命名空间相同性的示意图,展示了多集群间命名空间的对齐逻辑与统一编排映射关系: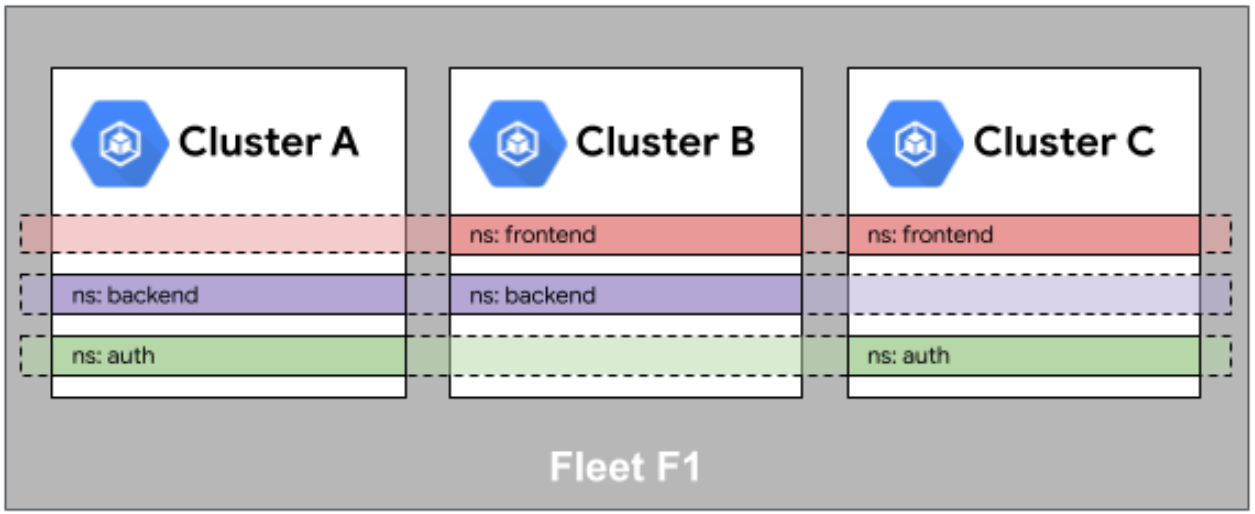
这也是个实操中的大坑。在单集群里,Namespace就是个隔离墙。但在多集群(Fleet)里,我们追求命名空间相同性(Namespace Sameness)。
啥意思呢?就是说,我在集群A里的 prod 命名空间,和集群B里的 prod 命名空间,应该被视为同一个逻辑隔离域。Kurator通过这种抽象,让你在写网络策略(NetworkPolicy)或者服务发现规则时,可以跨集群生效。
比如,你可以配置一条规则:只允许 prod 命名空间下的服务互相访问,不管它们是跑在哪个物理集群上。Kurator底层会帮你把这些复杂的跨集群防火墙规则下发下去。
FluxCD Helm应用在多集群环境下的工作流程
这是FluxCD Helm应用在多集群环境下的工作流程示意图,展示了控制器如何基于Helm模板与差异化配置,实现跨集群应用的统一编排与同步: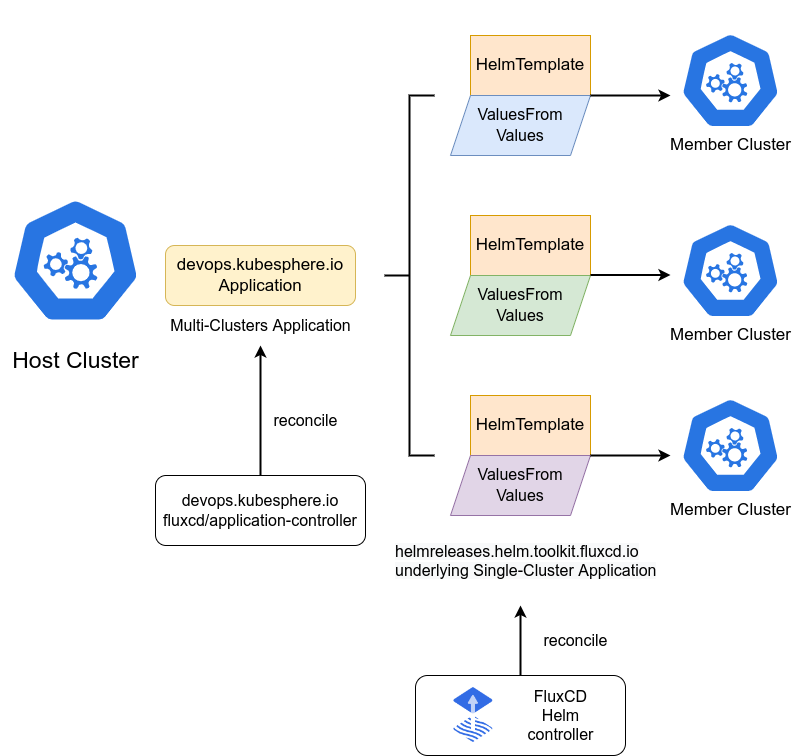
前面提到了GitOps,具体到Helm应用在多集群怎么跑,流程是这样的:
- Source Controller:先去Git仓库拉取Helm Chart的定义。
- Kustomize Controller(可选):如果你需要对Chart做一些Overlay的修改(比如不同区域的集群用不同的values.yaml),这里会进行渲染。
- Helm Controller:这是重头戏。在Kurator的多集群模式下,Helm Controller不是简单地安装Chart,而是会生成一个
HelmRelease对象。 - Kurator会将这个
HelmRelease分发到目标集群。注意,这里有两种模式:一种是推模式,管理面直接推送到子集群;一种是拉模式,子集群上的Agent自己拉取。对于大规模场景,我们通常推荐拉模式,减轻控制面的压力。
第四部分:进阶玩法,流量路由与Volcano算力调度
最后这部分是给高阶玩家准备的,涉及怎么精细化控制流量和算力。
流量路由与通过Kurator配置金丝雀
在多集群或者微服务架构下,流量怎么走是个大学问。Kurator集成了Istio等服务网格的能力,让你可以定义非常复杂的流量路由规则。
比如说,你想搞个金丝雀发布(Canary Release)。新版本上线,只让北京地区、且Header里带着 user-type: beta 的用户访问新版本,其他用户还在旧版本。
在Kurator里,你不用手写复杂的VirtualService,可以定义一个高级的Rollout策略。下面这段代码展示了如何配置一个简单的基于权重的流量切分:
apiVersion: networking.kurator.dev/v1alpha1
kind: TrafficRoute
metadata:
name: canary-demo
namespace: default
spec:
hosts:
- "myapp.example.com"
gateways:
- my-gateway
http:
- route:
- destination:
host: myapp
subset: v1
weight: 90 # 90%的流量走老版本
- destination:
host: myapp
subset: v2
weight: 10 # 10%的流量给金丝雀,用来测试新功能
headers:
request:
set:
x-canary-version: "v2" # 打个标,方便追踪日志
这段配置一下发,Kurator底层的控制器就会自动去调整网关和Sidecar的配置,你立马就能在监控大盘上看到流量分流的效果。
这是通过Kurator配置金丝雀发布的YAML示例,展示了如何基于Istio进行流量路由、指标监控及渐进式权重调整的完整策略定义: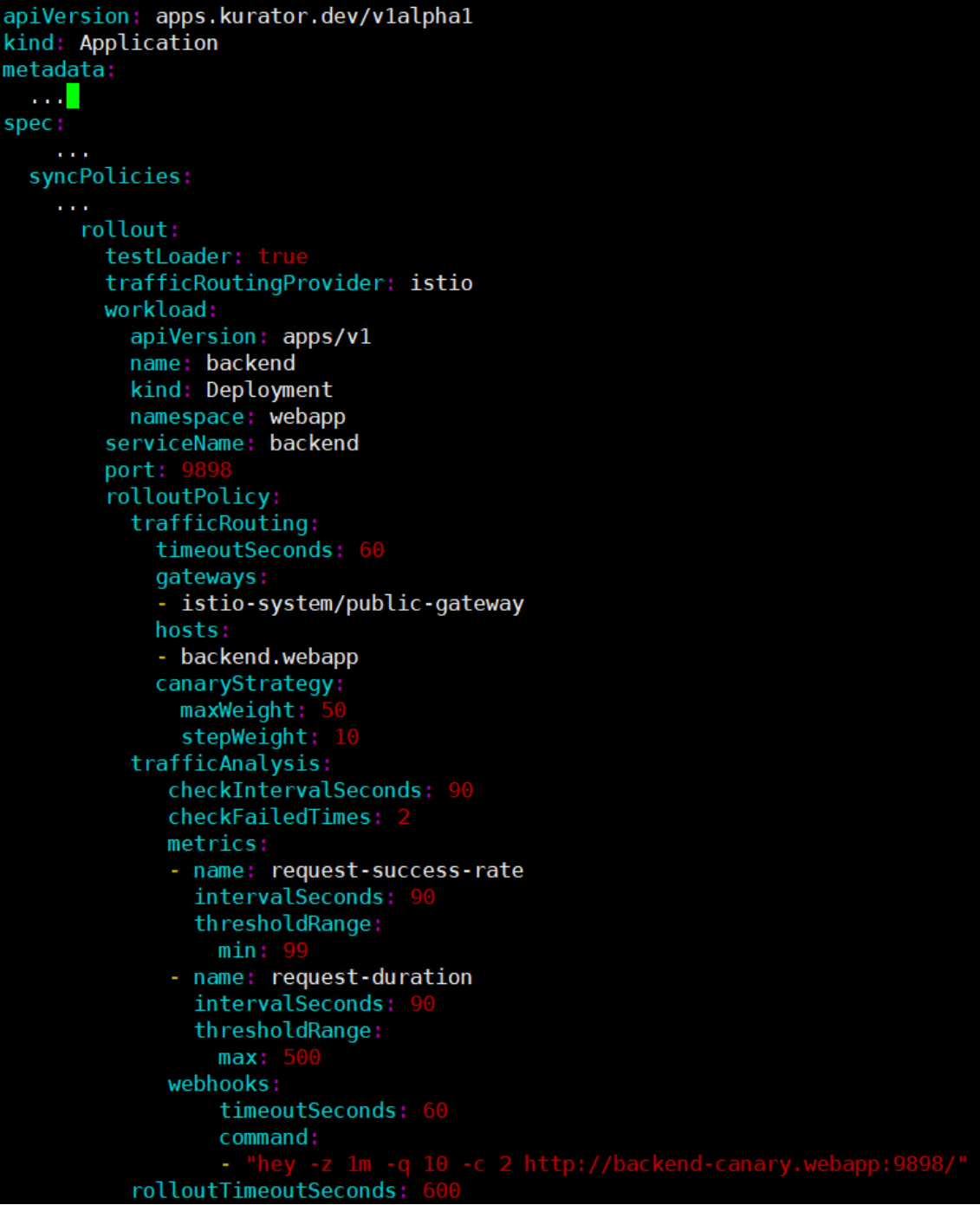
Volcano中Job、Queue与PodGroup关系
如果你的业务涉及大数据处理、基因测序或者AI训练,那你肯定离不开Volcano。K8s原生的调度器对批处理任务支持很烂,Volcano就是为了解决这个的。
在Kurator集成的Volcano里,有三个核心概念必须搞懂,不然你任务跑不起来:
- Job(作业):这是你提交的任务本体,比如一个TensorFlow训练任务。
- PodGroup(Pod组):这是Volcano引入的神概念。一个Job通常包含多个Pod(比如1个PS,4个Worker)。这5个Pod必须同时跑起来,任务才能开始。如果资源只够跑3个,原生的K8s会先把这3个跑起来占着坑,结果大家都卡死(死锁)。PodGroup就是告诉调度器:“这5个Pod是一伙的,要么一起上,要么都别上(All-or-Nothing)”。
- Queue(队列):这是资源分配的桶。你可以把集群资源切分成几个Queue,比如“研发部”占30%,“生产部”占70%。Job是提交到Queue里的。
下面看个Volcano Job的简单例子,感受一下PodGroup是怎么隐式工作的:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: tensorflow-training-job
spec:
minAvailable: 3 # 关键点!只有凑够3个Pod资源,调度器才会动手
schedulerName: volcano
queue: research-queue # 提交到研发队列
tasks:
- replicas: 1
name: ps
template:
spec:
containers:
- command: ["python", "ps.py"]
image: tensorflow/tensorflow:1.15.2
name: ps
- replicas: 2
name: worker
template:
spec:
containers:
- command: ["python", "worker.py"]
image: tensorflow/tensorflow:1.15.2
name: worker
在这个配置里,minAvailable: 3 就隐含了创建一个PodGroup。如果集群现在资源紧张,只够起2个Pod,Volcano会把这个Job挂起,直到凑够资源,避免资源碎片化。
总结
Kurator这东西,说白了就是把咱们云原生运维平时最头疼的几块硬骨头——边缘网络、多集群一致性、批量计算调度——给啃下来了。它不是那种让你看完文档还是一头雾水的项目,而是真的很贴近实操。
咱们今天从 git clone 开始,一路聊到了Volcano的调度原理。希望大家下去之后,真的动手搭一套试试。只有在日志里看到那些报错,再亲手把它修好,这些知识才真正是你自己的。
云原生的路还长,咱们一起折腾!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 21
21 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)