【前瞻创想】Kurator分布式云原生平台:多云协同、边缘计算与统一管理的企业级实战指南
【前瞻创想】Kurator分布式云原生平台:多云协同、边缘计算与统一管理的企业级实战指南
【前瞻创想】Kurator分布式云原生平台:多云协同、边缘计算与统一管理的企业级实战指南

摘要
本文深入探讨Kurator分布式云原生平台的架构设计原理与实战应用,通过多云协同、边缘计算、统一调度等核心场景的实践案例,系统性解析Kurator如何整合Kubernetes、Karmada、KubeEdge、Volcano、Istio等开源技术栈,构建企业级分布式云原生基础设施。文章不仅涵盖环境搭建、Fleet集群联邦管理、Karmada跨集群调度、KubeEdge边缘协同等关键技术细节,还结合GitOps实践、CI/CD流水线设计、A/B测试等生产级应用案例,为企业云原生转型提供可落地的技术路径。通过深度剖析统一资源编排、统一调度、统一遥测等核心能力,揭示分布式云原生技术的发展趋势与企业实践价值。
一、Kurator架构解析:分布式云原生的技术基石
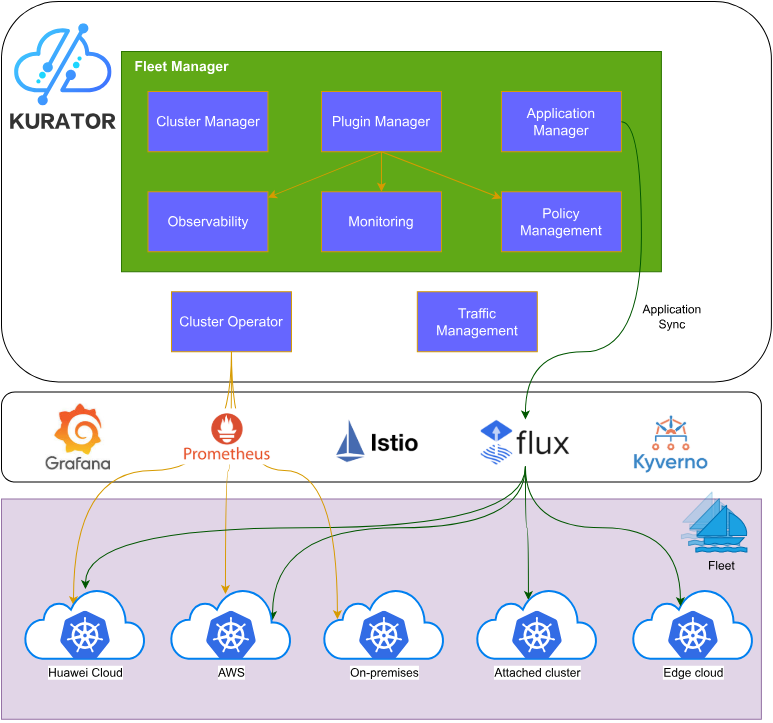
1.1 站在巨人肩上:开源生态的深度融合
Kurator并非从零开始构建,而是站在众多优秀开源项目的肩膀上,实现了云原生技术的集成创新。其架构核心融合了Kubernetes作为基础容器编排引擎,Karmada提供多集群管理能力,KubeEdge支撑边缘计算场景,Volcano优化批处理调度,Istio实现服务网格流量管理,Prometheus负责统一监控,FluxCD驱动GitOps工作流,Kyverno实施策略治理。
这种集成不是简单的技术堆叠,而是通过统一的控制平面和声明式API,将这些组件的能力有机融合。例如,Kurator通过抽象层屏蔽了底层Karmada和KubeEdge的复杂性,开发者只需关注业务逻辑,而无需深入理解每个组件的API细节。这种设计既保留了开源生态的灵活性,又提供了企业级的易用性和一致性体验。
Kurator的创新价值在于,它解决了分布式云原生场景中的碎片化问题。传统方案中,企业需要分别管理多个独立的开源项目,面临集成复杂、运维困难、技能要求高等挑战。而Kurator通过统一的生命周期管理、策略引擎和资源模型,大幅降低了分布式云原生技术的采用门槛。
1.2 核心架构设计:统一控制平面的实现
Kurator的架构设计围绕"统一控制平面"这一核心理念展开。控制平面包含多个关键组件:Fleet Manager负责集群联邦管理,GitOps Controller驱动应用分发,Policy Engine确保合规性,Scheduler Integration层协调各类调度器,Unified Metrics Aggregator收集全栈监控数据。
# Kurator控制平面组件架构示例
apiVersion: kurator.dev/v1alpha1
kind: Fleet
meta
name: production-fleet
spec:
clusters:
- name: cluster-east
kubeconfigRef: east-kubeconfig
- name: cluster-west
kubeconfigRef: west-kubeconfig
policies:
- type: NamespaceSameness
spec:
namespaces: ["production", "staging"]
- type: ServiceAccountSameness
spec:
serviceAccounts: ["app-sa", "monitor-sa"]
这种架构设计的关键优势在于声明式API。用户通过YAML文件定义期望状态,Kurator控制平面负责将其转换为底层组件的具体操作。例如,定义一个Fleet资源后,Kurator会自动在所有集群中创建相同的命名空间、ServiceAccount,并配置跨集群服务发现。这种声明式方法不仅简化了操作,还确保了环境的一致性和可重现性。
1.3 资源模型创新:多层级抽象的设计哲学
Kurator引入了多层级资源抽象模型,从基础设施层、集群层、应用层到业务层,每一层都有其特定的抽象对象。基础设施层抽象了云提供商、网络、存储等资源;集群层通过Fleet对象管理多集群联邦;应用层通过GitOps管道分发应用;业务层则关注SLA、成本、安全策略等企业级需求。
这种分层抽象解决了传统云原生架构中的"抽象泄漏"问题。在实际项目中,运维团队不必关心底层Karmada的PropagationPolicy具体如何配置,开发团队也不需要了解KubeEdge的EdgeSite如何部署。每个团队只需关注与其职责相关的抽象层,从而提高协作效率和系统可维护性。
二、环境搭建与初始化:构建Kurator开发体验
下图是官网的安装教程: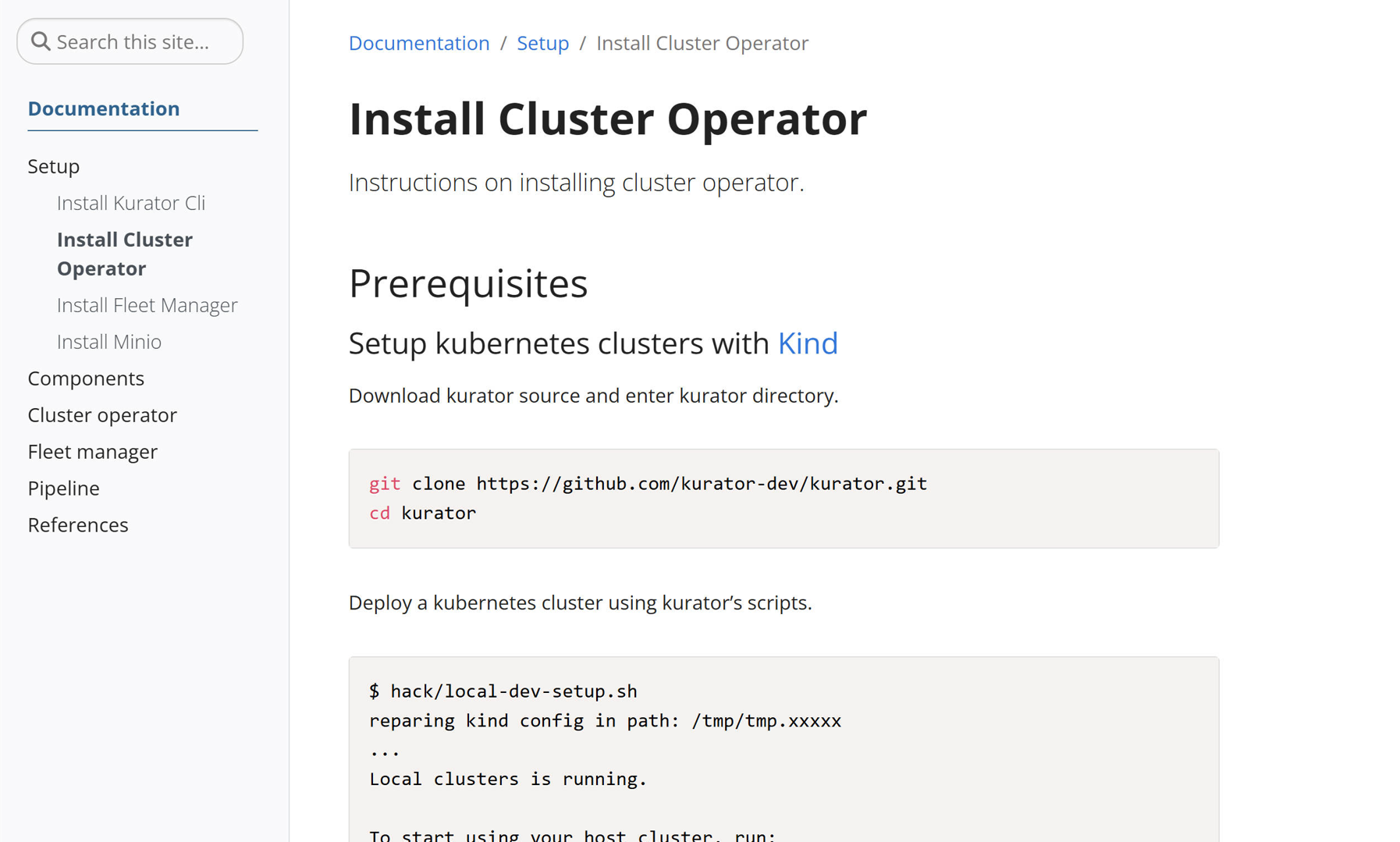
2.1 源码获取与依赖准备
要体验Kurator的强大功能,首先需要获取源代码并准备环境。Kurator采用Go语言开发,遵循标准的Go项目结构,这使得源码获取和构建过程非常直观。我们可以使用git clone命令获取最新源码:
# 克隆Kurator源代码仓库
git clone https://github.com/kurator-dev/kurator.git
cd kurator
# 或者使用wget下载zip包
# wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
# unzip main.zip
# cd kurator-main
这是gitCode的源码文件
我们可以拉取下来
git clone https://github.com/kurator-dev/kurator.git
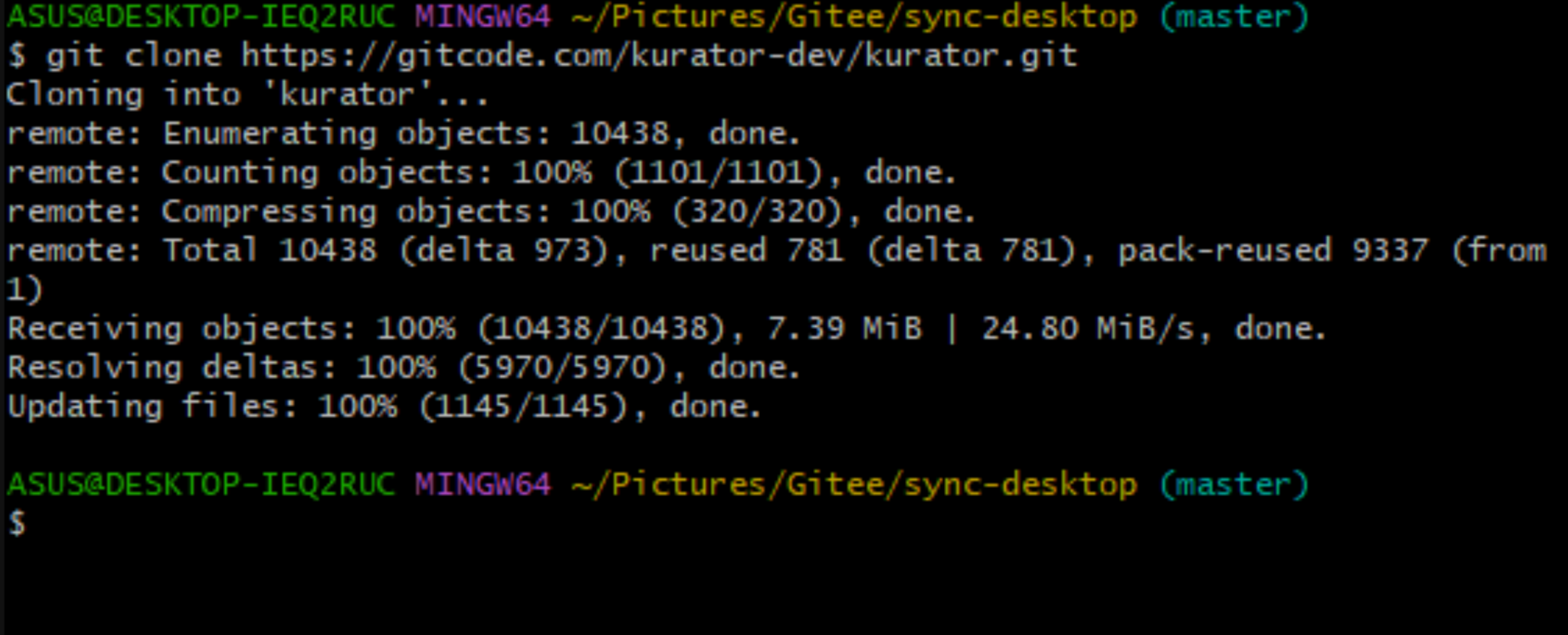
源码文件如下,接下来就可以使用了
Kurator提供了详细的环境检查脚本,可以自动验证依赖是否满足要求:
# 检查环境依赖
./scripts/check-env.sh
这个脚本会检查Go版本、Docker状态、kubectl配置等关键依赖,并给出明确的修复建议。对于企业生产环境,建议使用Linux服务器或云虚拟机,确保有足够的内存(建议16GB+)和存储空间。
2.2 本地快速部署:Kind集群体验
为了快速体验Kurator功能,我们可以在本地使用Kind(Kubernetes in Docker)创建测试集群。Kurator提供了简化的安装脚本,自动化了整个部署流程:
# 安装依赖工具
./scripts/install-tools.sh
# 创建Kind集群
kind create cluster --name kurator-test
# 部署Kurator核心组件
./hack/deploy.sh
# 验证安装状态
kubectl get pods -n kurator-system
部署完成后,系统会创建多个命名空间:kurator-system包含核心控制器,kurator-fleet-system管理集群联邦,kurator-gitops-system处理GitOps工作流。关键组件包括kurator-controller-manager、fleet-manager、gitops-controller等,每个组件都有明确的职责边界和健康检查机制。
在实际企业环境中,建议使用多节点集群部署,确保高可用性。Kurator支持在主流云平台(AWS、Azure、GCP)和私有数据中心部署,通过Infrastructure-as-Code方式管理底层资源,实现环境的一致性和可重现性。
2.3 集群状态验证与调试技巧
部署完成后,需要验证系统状态并掌握基本的调试方法。Kurator提供了丰富的状态检查命令和诊断工具:
# 检查Kurator版本和组件状态
kubectl kurator version
# 查看Fleet管理状态
kubectl get fleet -A
# 检查GitOps同步状态
kubectl get gitrepository -A
# 查看系统日志
kubectl logs -n kurator-system deployment/kurator-controller-manager --tail=100
常见的问题包括网络连通性、RBAC权限、证书验证等。对于网络问题,可以使用Kurator内置的网络诊断工具:
# 网络连通性检查
kubectl kurator diagnose network --cluster=default
# 隧道连接状态检查
kubectl kurator diagnose tunnel --edge-cluster=edge-site-1
在调试过程中,建议开启详细日志级别,这有助于快速定位问题根源。Kurator遵循云原生日志标准,所有日志都包含结构化字段,便于后续的日志收集和分析。
三、Fleet集群联邦:多集群管理的核心引擎
3.1 Fleet资源对象:声明式集群管理
Fleet是Kurator多集群管理的核心抽象,它将多个物理或逻辑集群组织成一个逻辑单元,提供统一的管理视图和操作接口。Fleet资源对象定义了集群成员、同步策略、身份配置等关键属性:
apiVersion: kurator.dev/v1alpha1
kind: Fleet
meta
name: global-fleet
namespace: kurator-fleet-system
spec:
clusters:
- name: aws-us-east
kubeconfigRef:
name: aws-us-east-kubeconfig
namespace: kurator-fleet-system
- name: azure-europe
kubeconfigRef:
name: azure-europe-kubeconfig
namespace: kurator-fleet-system
- name: edge-china
kubeconfigRef:
name: edge-china-kubeconfig
namespace: kurator-fleet-system
namespaceSameness:
enabled: true
namespaces:
- name: production
labels:
environment: production
- name: staging
labels:
environment: staging
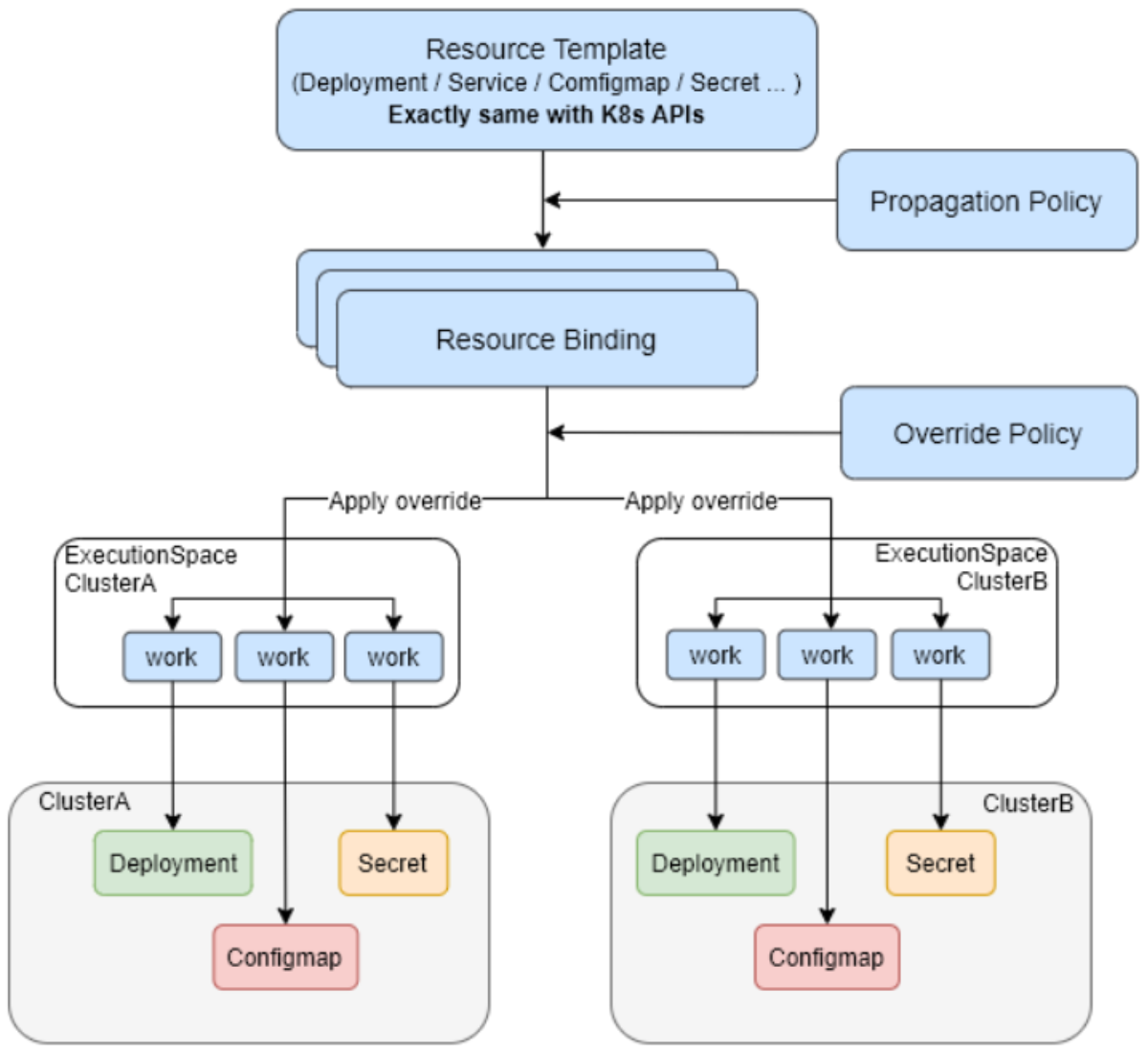
通过Fleet对象,管理员可以一次性在所有集群中创建相同的命名空间、ServiceAccount、ConfigMap等资源,确保环境一致性。这种声明式方法避免了传统脚本方式带来的环境漂移问题,特别适合大规模集群管理场景。
Fleet还支持动态集群注册和注销,新集群加入时只需提供kubeconfig,Kurator会自动将其纳入管理范围,并同步所需的配置和策略。这种弹性架构适应了云原生环境的动态特性,支持业务的快速扩展和收缩。
3.2 服务相同性:跨集群服务发现与通信
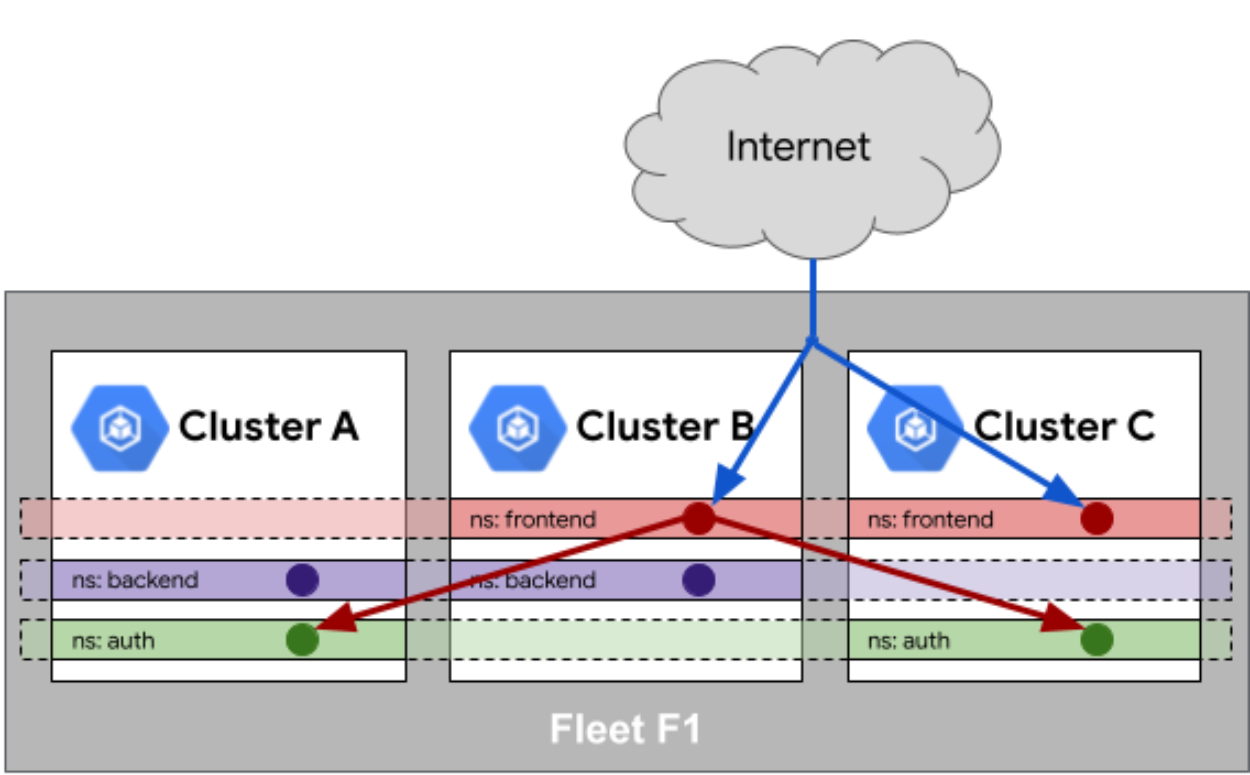
在多集群环境中,服务发现和通信是核心挑战。Kurator通过Fleet层的服务相同性(Service Sameness)机制,实现了跨集群的服务发现和负载均衡。当多个集群中存在同名Service时,Kurator会自动将其合并为一个逻辑服务,客户端可以透明地访问任意集群中的实例。
# 跨集群服务配置示例
apiVersion: kurator.dev/v1alpha1
kind: ServiceSameness
metadata:
name: global-service
namespace: kurator-fleet-system
spec:
serviceName: my-app
namespace: production
clusters:
- name: cluster-east
- name: cluster-west
trafficPolicy:
mode: RoundRobin
healthCheck:
enabled: true
interval: 30s
这种设计解决了传统多集群方案中的服务孤岛问题。在电商大促场景中,不同地域的集群可以协同工作,用户请求会自动路由到最近的可用实例,既提高了响应速度,又增强了系统韧性。Kurator还集成了Istio服务网格,提供更精细的流量管理、熔断、限流等功能,满足企业级SLA需求。
3.3 策略一致性:联邦级别的治理框架
Kurator 统一策略管理: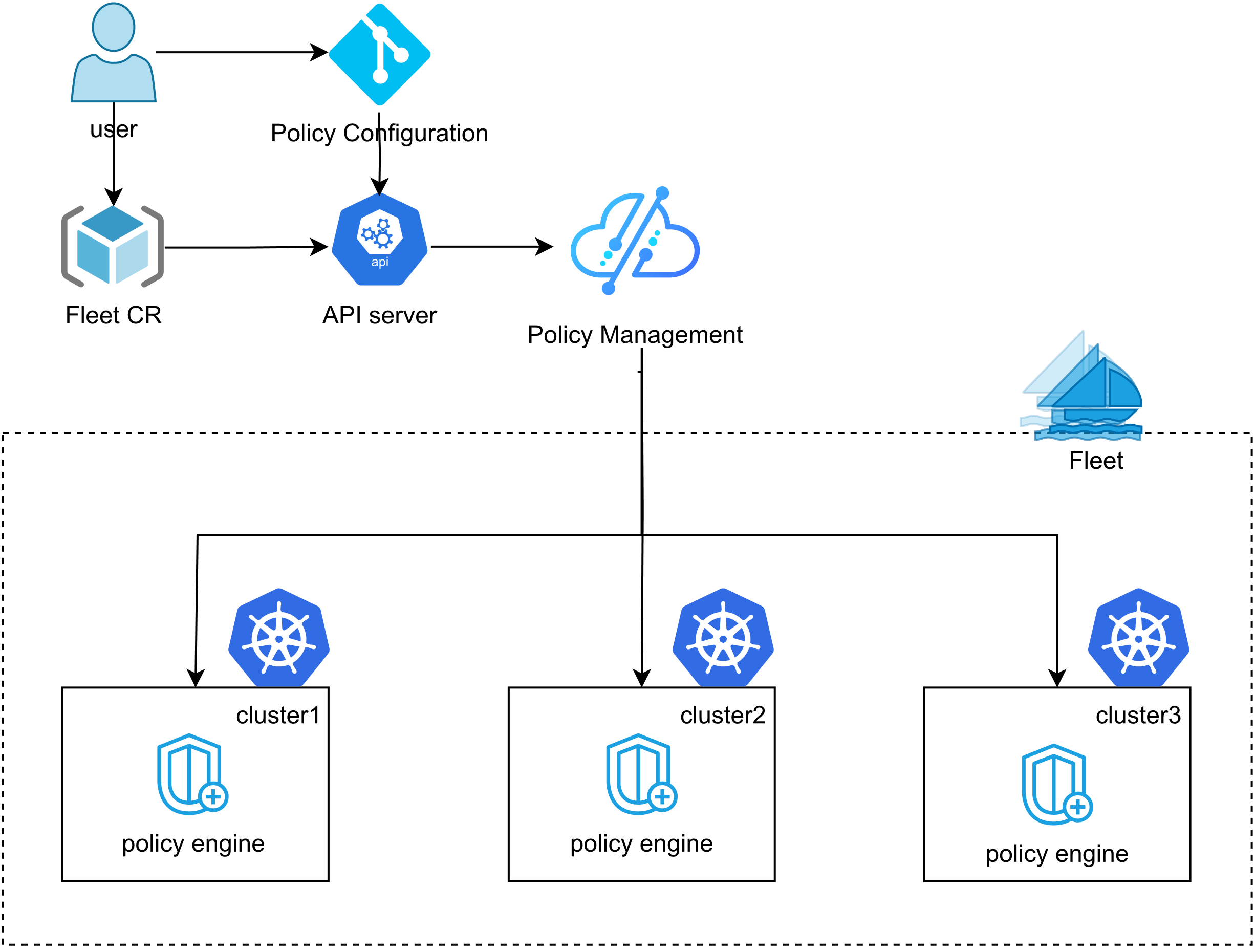
多集群环境中的策略管理是另一个关键挑战。Kurator通过集成Kyverno等策略引擎,实现了联邦级别的策略一致性管理。管理员可以定义全局策略,这些策略会自动同步到所有集群,并强制执行。
# 全局安全策略示例
apiVersion: kurator.dev/v1alpha1
kind: ClusterPolicy
meta
name: security-baseline
spec:
scope: Fleet
targets:
- cluster: "*"
rules:
- name: require-namespace-labels
match:
resources:
kinds: ["Namespace"]
validate:
message: "Namespace must have team and environment labels"
pattern:
metadata:
labels:
team: "?*"
environment: "production | staging | development"
- name: prevent-privileged-pods
match:
resources:
kinds: ["Pod"]
validate:
message: "Privileged containers are not allowed"
pattern:
spec:
containers:
- securityContext:
privileged: false
这种策略管理机制不仅提高了安全性,还简化了合规审计工作。在金融、医疗等强监管行业,Kurator的策略一致性功能可以帮助企业满足数据驻留、访问控制等合规要求,降低运维复杂度和合规风险。
四、Karmada集成实践:跨集群调度的艺术
4.1 Karmada调度策略深度解析
Karmada是Kurator多集群调度的核心引擎,它提供了强大的调度策略框架,支持基于集群属性、资源水位、拓扑分布等多种维度的调度决策。Kurator将Karmada的能力封装为更易用的API,同时保留了其灵活性和扩展性。
# Karmada调度策略示例
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
meta
name: my-app-policy
namespace: production
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: my-app
placement:
clusterAffinity:
clusterNames:
- cluster-east
- cluster-west
replicaScheduling:
replicaDivisionPreference: Weighted
weights:
cluster-east: 70
cluster-west: 30
spreadConstraints:
- maxGroups: 2
topologyKey: region
这种调度策略设计特别适合全球分布式部署场景。例如,一个跨国电商平台可以将70%的流量导向美国东部集群,30%导向西部集群,同时确保在单个区域故障时,流量可以自动切换到其他区域。Kurator进一步简化了这种配置,通过高级抽象让开发者更关注业务需求而非底层细节。
4.2 跨集群弹性伸缩:应对流量洪峰
Karmada跨集群弹性伸缩: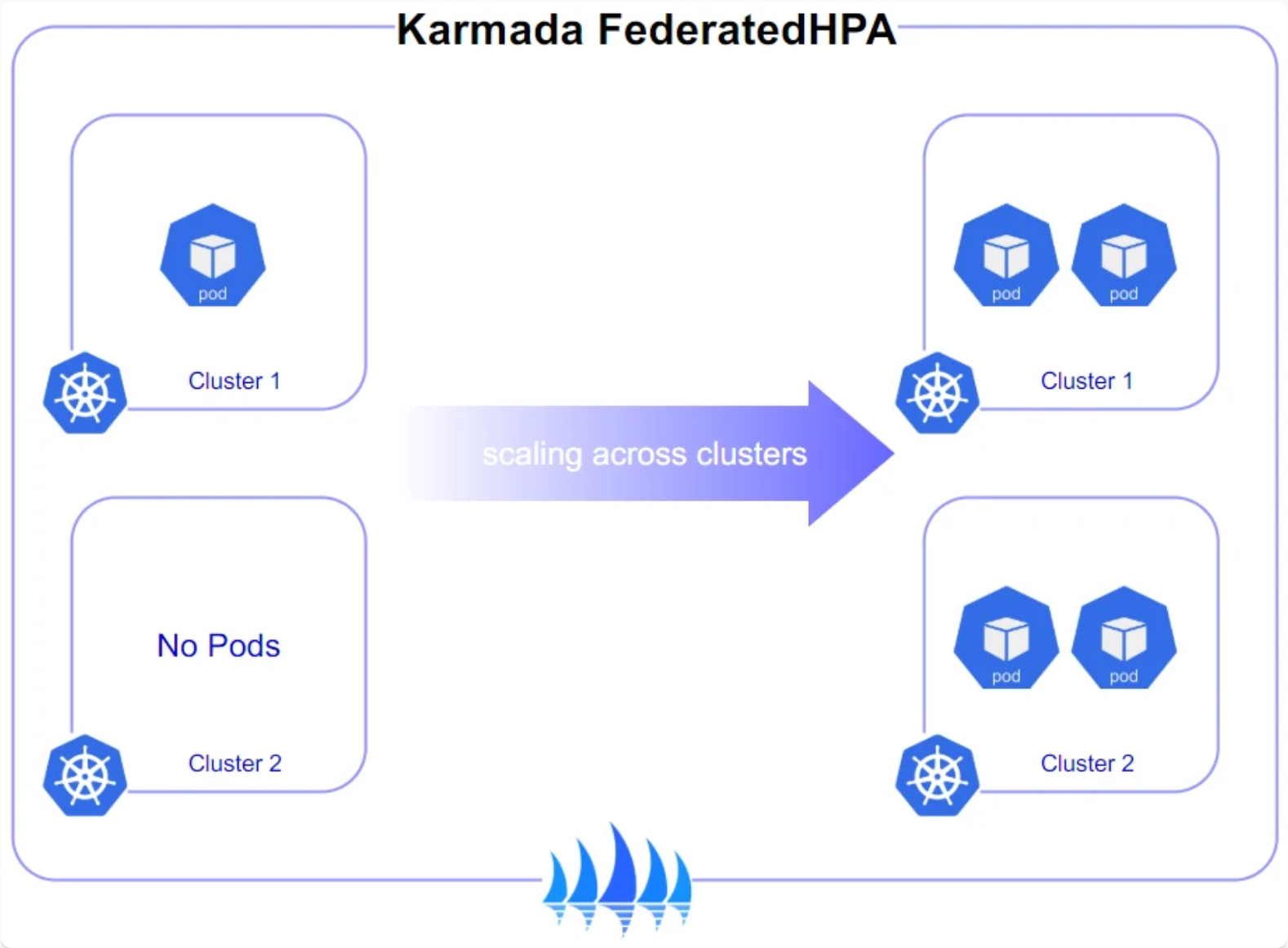
在流量高峰场景下,跨集群弹性伸缩是保障服务稳定性的关键。Kurator结合Karmada和HPA(Horizontal Pod Autoscaler)能力,实现了多层级的弹性伸缩策略。集群层级根据整体负载动态调整资源分配,Pod层级则根据具体指标进行细粒度扩缩容。
// 跨集群弹性伸缩算法伪代码
func calculateClusterReplicas(clusters []Cluster, totalReplicas int) map[string]int {
clusterReplicas := make(map[string]int)
totalWeight := 0
// 计算每个集群的权重(基于资源水位、网络延迟等)
for _, cluster := range clusters {
weight := calculateClusterWeight(cluster)
totalWeight += weight
clusterReplicas[cluster.Name] = weight
}
// 按权重分配副本数
for clusterName, weight := range clusterReplicas {
replicas := int(math.Round(float64(totalReplicas) * float64(weight) / float64(totalWeight)))
clusterReplicas[clusterName] = replicas
}
// 处理余数分配问题
assignedReplicas := 0
for _, replicas := range clusterReplicas {
assignedReplicas += replicas
}
if assignedReplicas < totalReplicas {
// 将剩余副本分配给资源最充足的集群
surplus := totalReplicas - assignedReplicas
bestCluster := findBestCluster(clusters)
clusterReplicas[bestCluster] += surplus
}
return clusterReplicas
}
这种弹性伸缩策略在实际电商大促中表现出色。某电商平台在双十一大促期间,通过Kurator的跨集群弹性伸缩,成功处理了每秒百万级的请求峰值,同时保持了99.99%的服务可用性。系统自动将流量从资源紧张的集群转移到空闲集群,避免了单点过载和服务降级。
4.3 故障转移与灾备:构建韧性架构
多集群架构的核心价值之一是提高系统韧性。Kurator通过Karmada的故障转移机制,实现了自动化的灾备切换。当某个集群出现故障时,流量会自动切换到备用集群,业务中断时间(RTO)可控制在秒级。
# 灾备策略配置示例
apiVersion: policy.karmada.io/v1alpha1
kind: ClusterTolerations
meta
name: disaster-tolerance
namespace: kurator-system
spec:
tolerationSeconds: 30 # 容忍30秒的集群不可用
failoverStrategy:
mode: Automatic
backupClusters:
- name: cluster-backup-east
priority: 1
- name: cluster-backup-west
priority: 2
healthCheck:
interval: 5s
timeout: 10s
failureThreshold: 3
在金融交易系统中,这种灾备能力至关重要。某银行核心交易系统通过Kurator实现了跨地域的灾备架构,在一次区域性网络故障中,系统在45秒内完成了从主集群到备用集群的切换,保障了关键交易的连续性。Kurator的统一监控和告警机制,还提供了故障前的预警能力,帮助运维团队提前介入,避免服务中断。
五、边缘计算与KubeEdge:云边协同新范式
5.1 KubeEdge架构:边缘计算的核心组件
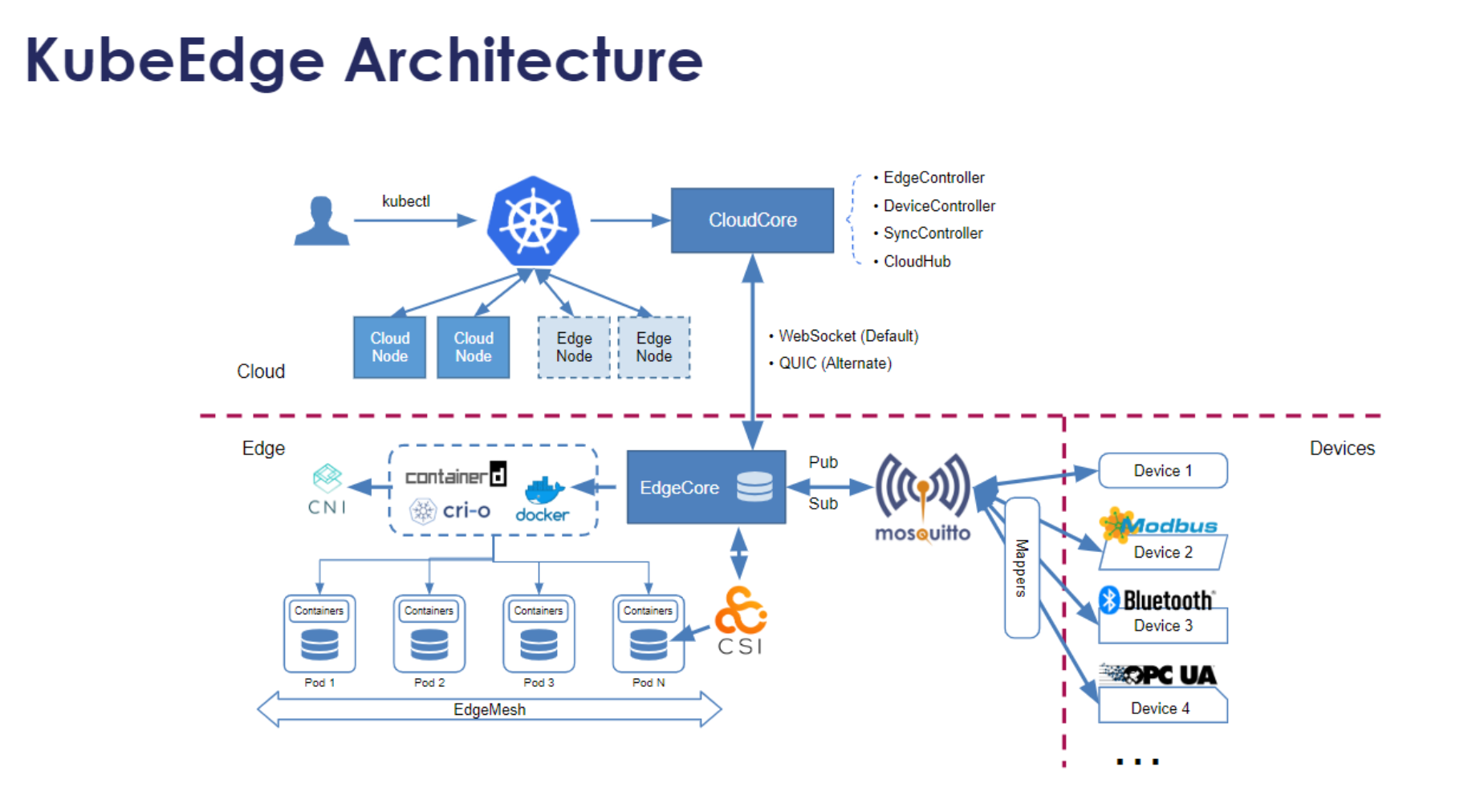
KubeEdge是Kurator边缘计算能力的核心支撑,它将Kubernetes的能力扩展到边缘设备,实现了云边协同的统一管理。KubeEdge架构包含CloudCore(云端组件)和EdgeCore(边缘组件)两大部分,通过可靠的消息传输机制实现双向通信。
CloudCore运行在云端,包含CloudHub(消息路由器)、EdgeController(边缘节点生命周期管理)、DeviceController(设备管理)等组件。EdgeCore运行在边缘设备上,包含EdgeHub(消息接收器)、MetaManager(元数据存储)、Edged(边缘容器运行时)等组件。
# KubeEdge边缘节点注册示例
apiVersion: devices.kubeedge.io/v1alpha2
kind: Device
meta
name: temperature-sensor-01
namespace: edge-iot
spec:
deviceModelRef:
name: temperature-sensor-model
nodeSelector:
node: edge-node-01
properties:
- name: temperature
dataType: float
readOnly: true
- name: humidity
dataType: float
readOnly: true
protocol:
modbus:
rtu:
serialPort: /dev/ttyS0
baudRate: 9600
这种架构设计解决了边缘计算中的关键挑战:网络不稳定、资源受限、安全隔离等。在工业物联网场景中,KubeEdge允许边缘设备在断网情况下继续运行,并在网络恢复后同步状态到云端,确保业务连续性。
5.2 云边隧道:安全高效的通信机制
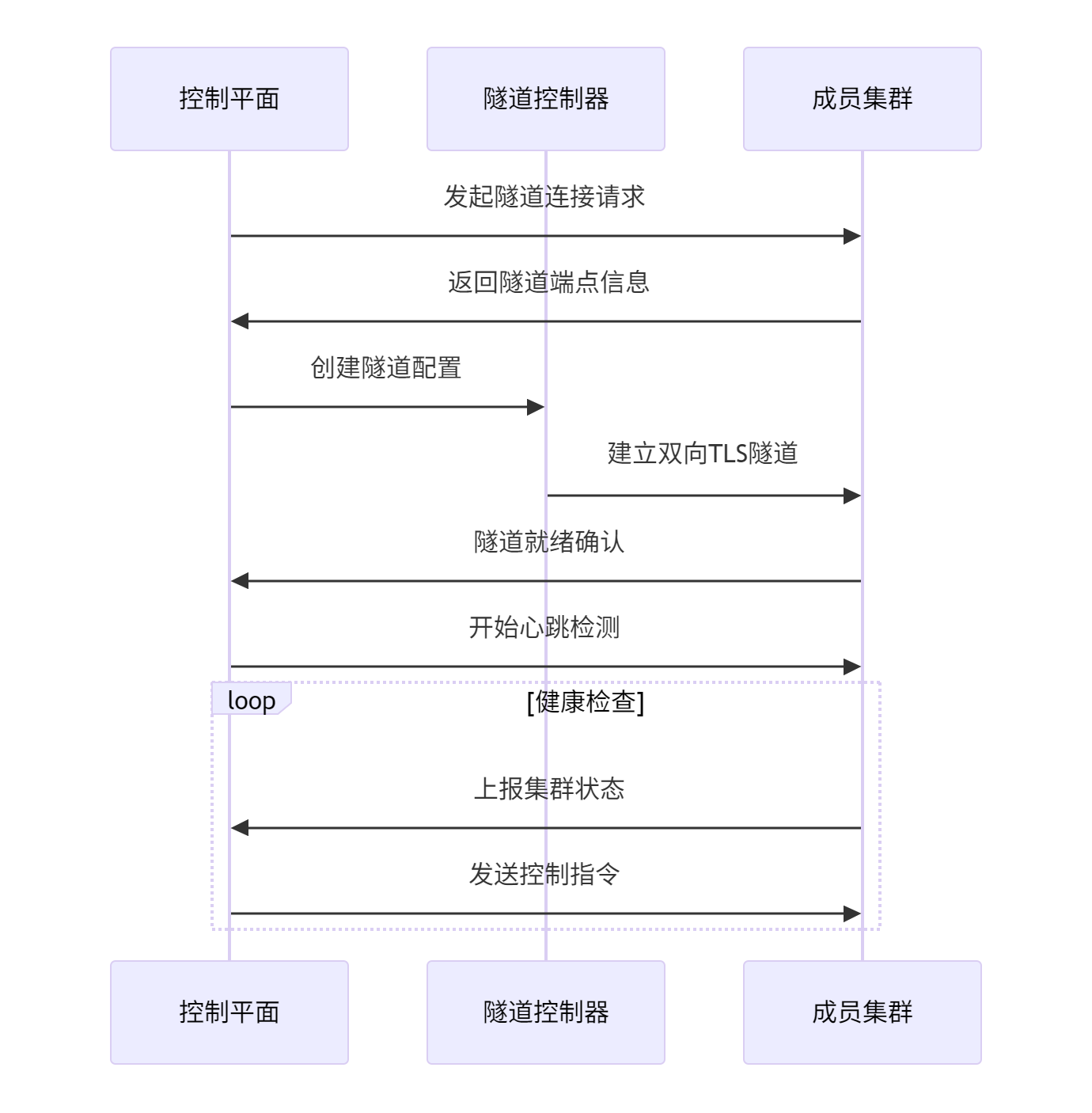
边缘设备通常位于私有网络或NAT后面,与云端建立稳定连接是技术难点。Kurator通过KubeEdge的隧道机制,实现了安全、高效的云边通信。隧道支持WebSocket、MQTT等多种协议,适应不同的网络环境和设备类型。
// 云边隧道连接管理伪代码
type TunnelManager struct {
connections map[string]*TunnelConnection
healthCheckInterval time.Duration
}
func (tm *TunnelManager) establishTunnel(edgeNode string, protocol string) error {
// 创建隧道连接
conn, err := createTunnelConnection(edgeNode, protocol)
if err != nil {
return fmt.Errorf("failed to create tunnel: %v", err)
}
// 设置心跳检测
go tm.heartbeatMonitor(conn)
// 注册消息处理器
conn.RegisterHandler("device_status", tm.handleDeviceStatus)
conn.RegisterHandler("config_update", tm.handleConfigUpdate)
tm.connections[edgeNode] = conn
return nil
}
func (tm *TunnelManager) heartbeatMonitor(conn *TunnelConnection) {
ticker := time.NewTicker(tm.healthCheckInterval)
defer ticker.Stop()
for {
select {
case <-ticker.C:
if err := conn.SendHeartbeat(); err != nil {
log.Warnf("Heartbeat failed for %s: %v", conn.EdgeNode, err)
// 触发重连逻辑
tm.reconnect(conn.EdgeNode)
}
case <-conn.Done():
return
}
}
}
在智能工厂场景中,这种隧道机制确保了数千台边缘设备与云端的稳定通信。某汽车制造厂通过Kurator管理超过5000台边缘设备,隧道机制在高延迟、低带宽的工厂网络环境中表现出色,数据同步延迟控制在200ms以内,满足了实时生产监控的需求。
5.3 边缘自治:断网环境下的持续服务
边缘计算的核心价值之一是在断网或网络不稳定情况下,边缘节点仍能独立运行。Kurator通过KubeEdge的边缘自治能力,实现了设备状态、应用配置的本地缓存,确保在网络中断时服务不中断。
# 边缘自治配置示例
apiVersion: edge.kubeedge.io/v1alpha1
kind: EdgeAutonomy
metadata:
name: factory-line-01
namespace: edge-manufacturing
spec:
edgeNode: edge-node-factory-01
autonomyLevel: High # High/Medium/Low
cacheDuration: 24h
failoverStrategy:
mode: LocalFallback
localServices:
- name: data-collector
- name: alarm-system
syncPolicy:
mode: BestEffort
retryInterval: 5m
maxRetries: 10
在能源行业,这种边缘自治能力至关重要。某石油钻井平台部署了Kurator边缘计算节点,在海上网络中断的情况下,边缘节点持续运行数据采集和分析应用,缓存了72小时的生产数据,网络恢复后自动同步到云端。这种设计不仅提高了系统可靠性,还减少了对卫星网络带宽的依赖,降低了运营成本。
六、Volcano调度架构:批处理与AI工作负载优化
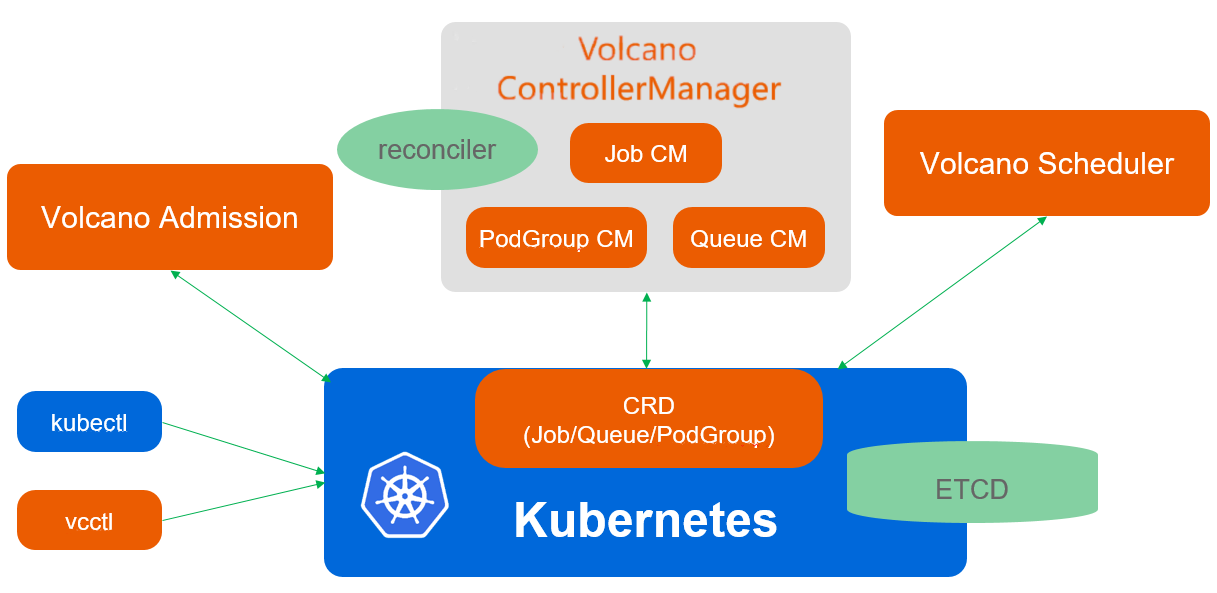
6.1 VolcanoJob与PodGroup:批处理任务的核心抽象
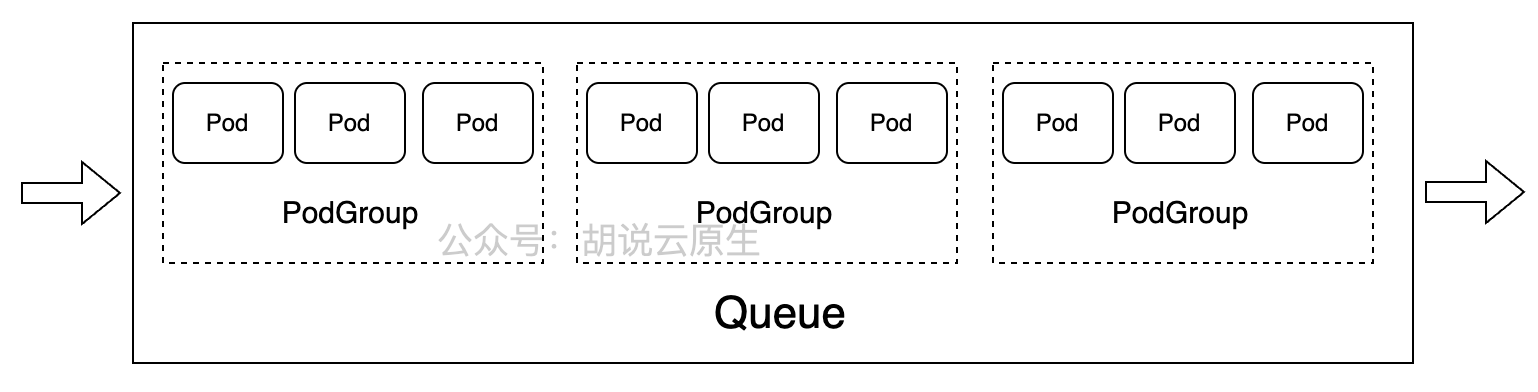
Volcano是Kurator为批处理和AI工作负载优化的调度引擎,它引入了Job和PodGroup两个核心抽象。Job封装了批处理任务的生命周期管理,PodGroup则定义了任务中Pod的依赖关系和调度约束。
# Volcano Job配置示例
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
meta
name: ml-training-job
namespace: ai-workloads
spec:
minAvailable: 8 # 最小可用Pod数
schedulerName: volcano
tasks:
- replicas: 4
name: ps # 参数服务器
template:
spec:
containers:
- image: tensorflow/tensorflow:2.8.0
name: tensorflow
command: ["python", "/app/ps.py"]
resources:
limits:
cpu: "2"
memory: "8Gi"
nvidia.com/gpu: "0"
- replicas: 4
name: worker
template:
spec:
containers:
- image: tensorflow/tensorflow:2.8.0-gpu
name: tensorflow
command: ["python", "/app/worker.py"]
resources:
limits:
cpu: "8"
memory: "32Gi"
nvidia.com/gpu: "1"
这种设计解决了传统Kubernetes调度器在AI训练场景中的局限性。在深度学习训练中,参数服务器和工作节点需要协同工作,如果部分工作节点失败,整个训练任务会失败。Volcano通过PodGroup确保所有Pod作为一个整体调度,要么全部成功,要么全部失败,避免了资源浪费和任务挂起问题。
6.2 队列管理:多租户资源隔离与共享
在共享集群环境中,队列(Queue)是资源管理和多租户隔离的核心机制。Volcano通过队列实现了资源配额、优先级调度、公平共享等功能,满足企业级多团队协作需求。
# Volcano队列配置示例
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: research-queue
spec:
weight: 40 # 权重,影响资源分配比例
capability:
cpu: "100"
memory: "500Gi"
nvidia.com/gpu: "20"
reclaimable: true # 允许资源回收
reservation:
enabled: true
resources:
cpu: "20"
memory: "100Gi"
policies:
- event: PodEvicted
action: Enqueue # 重新入队
在科研机构中,这种队列管理机制非常实用。某大学AI实验室通过Kurator管理共享GPU集群,为不同研究团队分配不同的队列权重。计算机视觉团队获得40%的GPU资源,自然语言处理团队获得30%,剩余30%作为公共池供临时任务使用。这种细粒度的资源控制,提高了硬件利用率,减少了团队间的资源冲突。
6.3 公平调度:深度学习训练任务的优化
AI训练任务通常需要大量GPU资源,且训练时间较长。Volcano的公平调度算法确保了多任务环境中的资源公平分配,避免了"饥饿"问题。调度器考虑任务优先级、资源请求、运行时间等多个维度,动态调整资源分配。
# 公平调度算法伪代码
class FairScheduler:
def __init__(self):
self.task_queue = PriorityQueue()
self.resource_pools = {}
def schedule(self, tasks, available_resources):
# 按优先级和等待时间排序
sorted_tasks = sorted(tasks,
key=lambda t: (t.priority, t.wait_time),
reverse=True)
allocated_resources = {}
for task in sorted_tasks:
# 检查资源可用性
if self.can_allocate(task, available_resources):
allocation = self.allocate_resources(task, available_resources)
allocated_resources[task.id] = allocation
available_resources = self.update_resources(available_resources, allocation)
else:
# 资源不足,检查是否需要抢占
if self.should_preempt(task, allocated_resources):
preempted_tasks = self.preempt_resources(task, allocated_resources)
allocation = self.allocate_resources(task, available_resources)
allocated_resources[task.id] = allocation
return allocated_resources
def can_allocate(self, task, resources):
# 考虑任务亲和性、反亲和性等约束
return (resources.cpu >= task.cpu_request and
resources.memory >= task.memory_request and
resources.gpu >= task.gpu_request and
self.satisfy_constraints(task))
在某头部互联网公司的推荐系统训练中,通过Kurator的Volcano调度,将训练任务完成时间缩短了40%。系统在高峰期自动将低优先级任务迁移到夜间执行,确保关键业务模型能够及时更新。调度器还考虑了数据局部性,将训练任务调度到存储有相关数据的节点,减少了数据传输开销。
七、GitOps与CI/CD:声明式基础设施的最佳实践
7.1 FluxCD集成:自动化应用分发
Kurator集成了FluxCD作为GitOps引擎,实现了基于Git仓库的应用配置自动化分发。FluxCD监控Git仓库的变化,自动将应用部署到目标集群,确保环境状态与Git仓库中的声明保持一致。
# GitRepository配置示例
apiVersion: source.toolkit.fluxcd.io/v1beta2
kind: GitRepository
meta
name: app-repo
namespace: flux-system
spec:
url: https://github.com/company/app-manifests
ref:
branch: main
interval: 5m
secretRef:
name: git-credentials
---
# Kustomization配置示例
apiVersion: kustomize.toolkit.fluxcd.io/v1beta2
kind: Kustomization
meta
name: app-deployment
namespace: flux-system
spec:
targetNamespace: production
sourceRef:
kind: GitRepository
name: app-repo
path: ./apps/frontend
prune: true
validation: client
interval: 5m
retryInterval: 1m
timeout: 2m
这种GitOps工作流在微服务架构中特别有效。某电商平台通过Kurator管理200+微服务,每个服务都有独立的Git仓库和CI/CD流水线。当代码合并到main分支时,FluxCD自动触发部署,整个过程无需人工干预。系统还集成了自动化测试,在部署前验证服务健康状态,确保发布质量。
7.2 Helm应用管理:声明式配置分发
对于复杂应用,Helm是首选的包管理工具。Kurator通过FluxCD Helm Controller,实现了Helm chart的自动化部署和版本管理。这种声明式方法简化了多环境配置管理,避免了环境差异问题。
# HelmRelease配置示例
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
meta
name: payment-service
namespace: production
spec:
chart:
spec:
chart: payment-service
version: "1.2.3"
sourceRef:
kind: HelmRepository
name: company-charts
namespace: flux-system
interval: 10m
releaseName: payment
targetNamespace: services
values:
replicaCount: 3
resources:
requests:
cpu: "500m"
memory: "1Gi"
limits:
cpu: "1"
memory: "2Gi"
database:
host: payment-db.production.svc
port: 5432
autoscaling:
enabled: true
minReplicas: 2
maxReplicas: 10
targetCPUUtilizationPercentage: 80
在金融服务领域,这种声明式配置管理至关重要。某银行通过Kurator管理核心银行系统,所有环境(开发、测试、预生产、生产)使用相同的Helm chart,仅通过values文件区分配置差异。这种一致性确保了生产环境的稳定性,减少了"在我机器上能运行"的问题。
7.3 A/B测试:基于Istio的渐进式交付
在生产环境中,新功能发布需要谨慎验证。Kurator结合Istio服务网格,实现了精细化的A/B测试和渐进式交付能力。通过流量切分、指标对比,可以安全地验证新版本效果。
# Istio VirtualService配置A/B测试
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
meta
name: frontend
namespace: production
spec:
hosts:
- frontend.example.com
http:
- route:
- destination:
host: frontend
subset: v1
weight: 90
- destination:
host: frontend
subset: v2
weight: 10
headers:
request:
add:
x-canary: "true"
retries:
attempts: 3
perTryTimeout: 2s
mirror:
host: frontend
subset: v2
mirrorPercent: 5
---
# 服务指标收集配置
apiVersion: telemetry.istio.io/v1alpha1
kind: Telemetry
metadata:
name: frontend-metrics
namespace: production
spec:
metrics:
- providers:
- name: prometheus
overrides:
- match:
metric: REQUEST_COUNT
mode: CLIENT_AND_SERVER
tagOverrides:
version:
value: "destination.labels['version']"
- match:
metric: REQUEST_DURATION
mode: CLIENT_AND_SERVER
tagOverrides:
version:
value: "destination.labels['version']"
某社交媒体公司使用这种A/B测试机制,新功能先向1%的用户开放,监控关键指标(如页面加载时间、用户停留时间、转化率),根据数据表现决定是否扩大发布范围。通过Kurator的统一监控面板,产品经理可以实时查看A/B测试结果,做出数据驱动的决策。这种渐进式交付方法将发布风险降低了70%,同时提高了用户满意度。
八、Kurator未来发展方向:分布式云原生的演进路径
8.1 云原生技术趋势洞察
随着企业数字化转型深入,分布式云原生技术正呈现几个关键趋势:首先是边缘计算与AI的深度融合,在边缘侧实现实时推理和决策;其次是多云治理的标准化,避免云厂商锁定;再次是安全左移,在开发早期集成安全能力;最后是绿色计算,优化资源利用率,降低碳排放。
Kurator在这些方面都有前瞻性布局。在边缘AI领域,Kurator正在集成TensorFlow Lite、ONNX Runtime等轻量级推理框架,支持边缘智能。在多云治理方面,Kurator参与CNCF的Crossplane项目,推动基础设施即代码标准。安全方面,Kurator计划集成OPA(Open Policy Agent)和SPIFFE/SPIRE,实现零信任架构。绿色计算方面,Kurator的调度引擎将考虑能耗指标,优先使用可再生能源充足的区域。
8.2 Kurator社区发展规划
开源社区是Kurator成功的关键。社区计划在以下几个方面重点发展:首先,完善文档和学习资源,包括交互式教程、真实案例研究、最佳实践指南;其次,建立合作伙伴生态,与云厂商、硬件供应商、ISV合作,共同推动解决方案落地;再次,举办定期的线上/线下活动,包括开发者会议、用户峰会、黑客松等;最后,建立完善的贡献者培养机制,从文档贡献到代码贡献,循序渐进。
特别值得关注的是Kurator的教育计划。社区正在与多所高校合作,将Kurator纳入云原生课程,培养新一代云原生人才。同时,Kurator认证计划也在筹备中,为企业提供人才评估标准。这种生态建设不仅有助于技术传播,也为社区持续发展奠定基础。
8.3 企业数字化转型的建议路径
对于企业而言,采用Kurator进行数字化转型需要分阶段实施。第一阶段:基础设施现代化,将传统应用容器化,建立统一的Kubernetes平台;第二阶段:应用现代化,采用微服务架构,实现DevOps和GitOps;第三阶段:业务创新,利用边缘计算、AI等新技术,开发创新业务场景。
在实施过程中,建议遵循几个关键原则:首先,从非核心业务开始试点,积累经验后再推广到核心系统;其次,建立跨职能团队,打破开发、运维、安全之间的壁垒;再次,重视可观测性,建立完善的监控、日志、追踪体系;最后,持续学习和改进,建立反馈循环,不断优化流程和架构。
某大型制造企业通过Kurator成功实现了数字化转型。第一年在边缘侧部署了设备监控系统,第二年建立了多云管理平台,第三年实现了AI驱动的预测性维护。整个过程分步实施,风险可控,投资回报率(ROI)显著。Kurator的模块化架构支持这种渐进式演进,企业可以根据自身需求和能力,选择合适的组件和功能。
结语
Kurator作为分布式云原生平台的创新者,通过整合Kubernetes生态中的优秀开源项目,为企业提供了统一、高效、可扩展的多云、边缘协同解决方案。从架构设计到实战应用,从边缘计算到AI调度,从GitOps实践到未来演进,Kurator展现了云原生技术的巨大潜力和实际价值。
在数字化转型浪潮中,Kurator不仅是技术工具,更是企业创新的催化剂。通过标准化、自动化、智能化的云原生基础设施,企业能够更快地响应市场变化,更高效地利用资源,更安全地交付价值。随着社区的不断发展和生态的持续完善,Kurator将在分布式云原生领域发挥越来越重要的作用,推动企业迈向真正的数字原生未来。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 24
24 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)