【前瞻创想】搞定多云多集群简直是噩梦?来看 Kurator 如何带你飞起!
【前瞻创想】搞定多云多集群简直是噩梦?来看 Kurator 如何带你飞起!
现在的云原生技术发展得太快了,特别是如果你手头有一堆 Kubernetes 集群要管,那酸爽,谁管谁知道。Kurator这玩意儿就像是一个超级管家,专门帮你把那些散落在各地的云资源、边缘节点收拾得服服帖帖的。咱们今天就用最接地气的大白话,把它的里里外外给盘清楚!
🛠️ 先把环境搭起来,动手玩才是真理
咱们既然是搞技术的,光说不练假把式。想玩转 Kurator,第一步肯定是得先把环境搞定。这玩意儿安装其实特简单,不需要你搞什么复杂的配置,咱们直接去它的老家把代码拉下来就行。
打开你的终端,找个顺眼的目录,敲下这行神圣的命令:
# 咱们先把代码拉到本地,这一步最关键
git clone https://github.com/kurator-dev/kurator.git
# 拉完之后直接进目录,准备开始你的表演
cd kurator
# 接下来你就可以照着官方文档那个 quickstart 搞起了
如果显示下面的问题
表示没用设置git代理,我们可以先设置git代理;先看一下电脑上的代理端口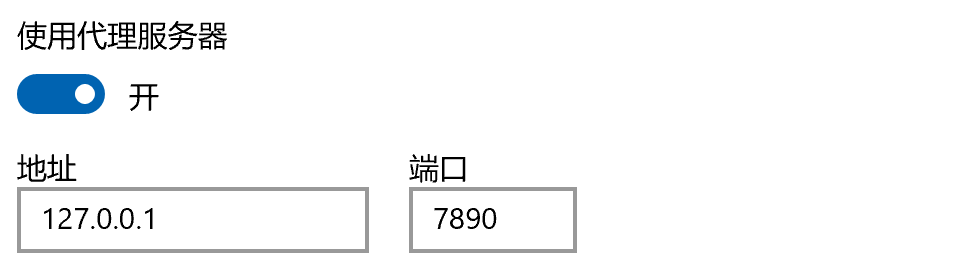
再设置git的代理端口,设置成本地代理
git config --global http.proxy http://127.0.0.1:7890
然后再拉取
git clone https://github.com/kurator-dev/kurator.git

就可以拉取资源了,当然也可以换源,你们可以试试
环境搭好了,咱们心里就不慌了。接下来带你钻进它的肚子里看看,这货到底是怎么运转的。
🚢 Fleet 的核心架构:多集群管理的“大脑”
你想象一下,你手底下有几十个集群,分布在阿里云、腾讯云,甚至还有你自己机房的。要是没有一个“大脑”来统筹,那你每天光是切 kubeconfig 就能切到手抽筋。Fleet 就是 Kurator 里负责干这个的。
1. 啥是 Fleet 核心架构?
这是Fleet的核心架构图,展示了其如何基于Bundle定义和集群分组实现多集群应用的分发、同步与状态追踪: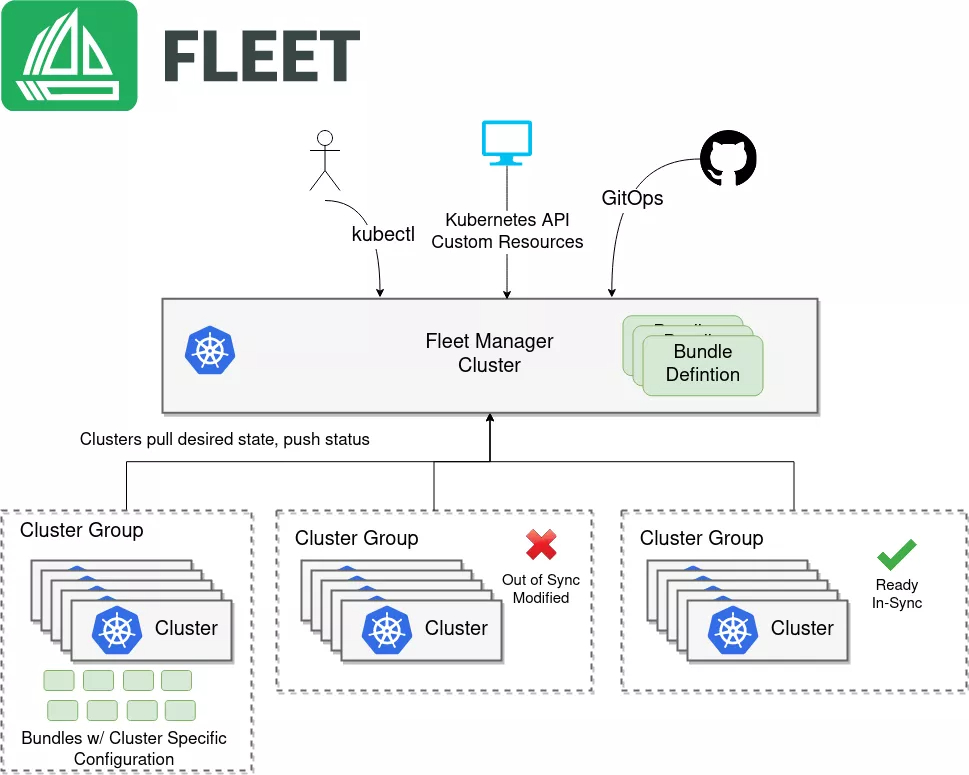
简单来说,Fleet 的核心架构就是一个基于 Kubernetes Operator 模式设计的控制平面。它不直接去干涉你每个集群里的具体业务,而是把一堆集群看成一个整体,我们管它叫“舰队”(Fleet)。在 Fleet Manager 这个组件里,它维护了所有集群的生命周期。你往这个舰队里注册一个集群,Fleet Manager 就给它发个“身份证”,以后这集群就归它管了。
2. Fleet 架构的细节
这是Fleet架构的官方示意图,展示了其跨云、混合云和边缘的统一应用分发与管理平台: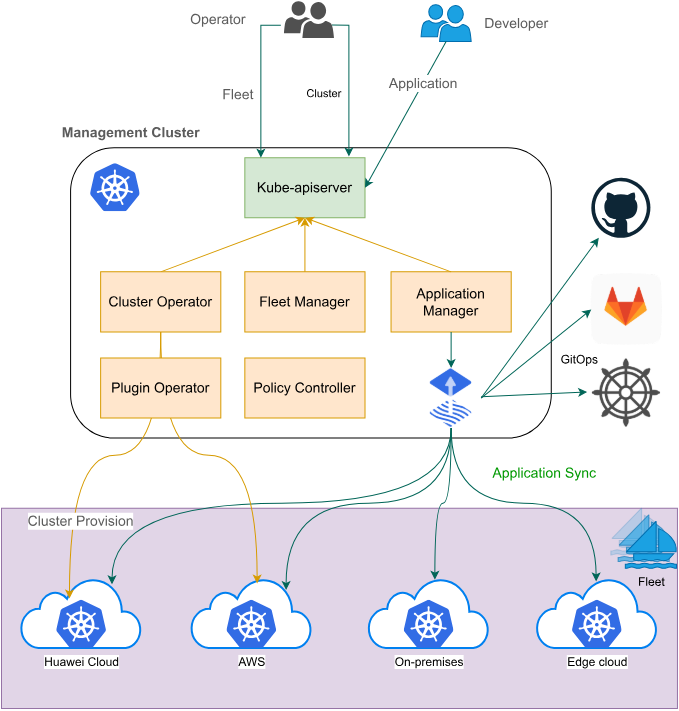
再往细了看,Fleet 架构里头有几个关键点。首先是集群注册与注销,这就像是入职离职手续,全自动化。其次是跨集群的服务发现,这可是个黑科技,比如你在 A 集群有个服务,B 集群想调它,Fleet 能帮你把网络打通,让它们感觉就像在一个局域网里一样。最后是统一的配置同步,你在 Fleet 层面改个配置,哗啦一下,底下所有集群都同步了,根本不用你一个个去 apply。
☁️ KubeEdge:把云的能力延伸到天边
现在边缘计算多火啊,工厂里的机械臂、路边的摄像头,都想连上云。Kurator 这一块集成了 KubeEdge,那叫一个丝滑。
1. KubeEdge 的详细架构
这是KubeEdge的详细架构参考图,展示了云端核心组件、边缘节点及其与设备之间的完整管理、通信与应用部署链路: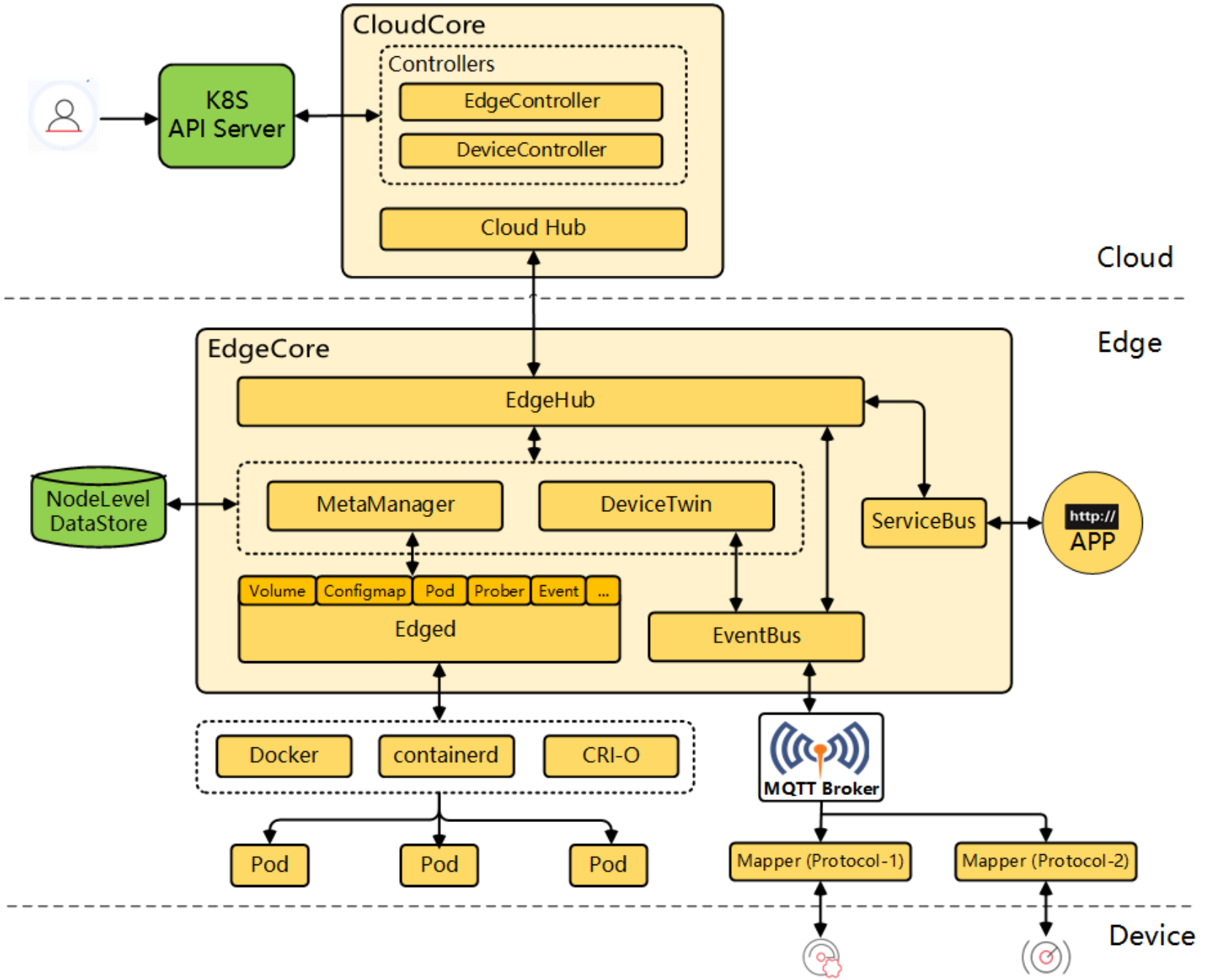
KubeEdge 的架构其实挺有意思,分两头:云端(CloudCore)和边缘端(EdgeCore)。
- 云端(CloudCore):这部分跑在你的 K8s 集群里,它负责监听云上面的变化,比如你发了个指令说“把路灯打开”。它还有个
CloudHub,专门负责跟边缘端吹牛聊天(通信)。 - 边缘端(EdgeCore):这部分跑在边缘设备上,那种树莓派或者工控机。它里面有个
Edged,你可以把它理解成缩小版的 kubelet,专门管容器的生杀大权。还有个EdgeHub,负责跟云端保持联络。最绝的是它有个MetaManager,就算网断了,它也能存点元数据,保证边缘设备不宕机,这就叫离线自治。
2. 云边协同应用的部署架构
这张图展示了云边协同应用的部署架构,从设备层到边缘层、企业层再到产业平台,层层联动,实现工业数据在本地和云端的高效协同处理,支持智能制造和数字化转型: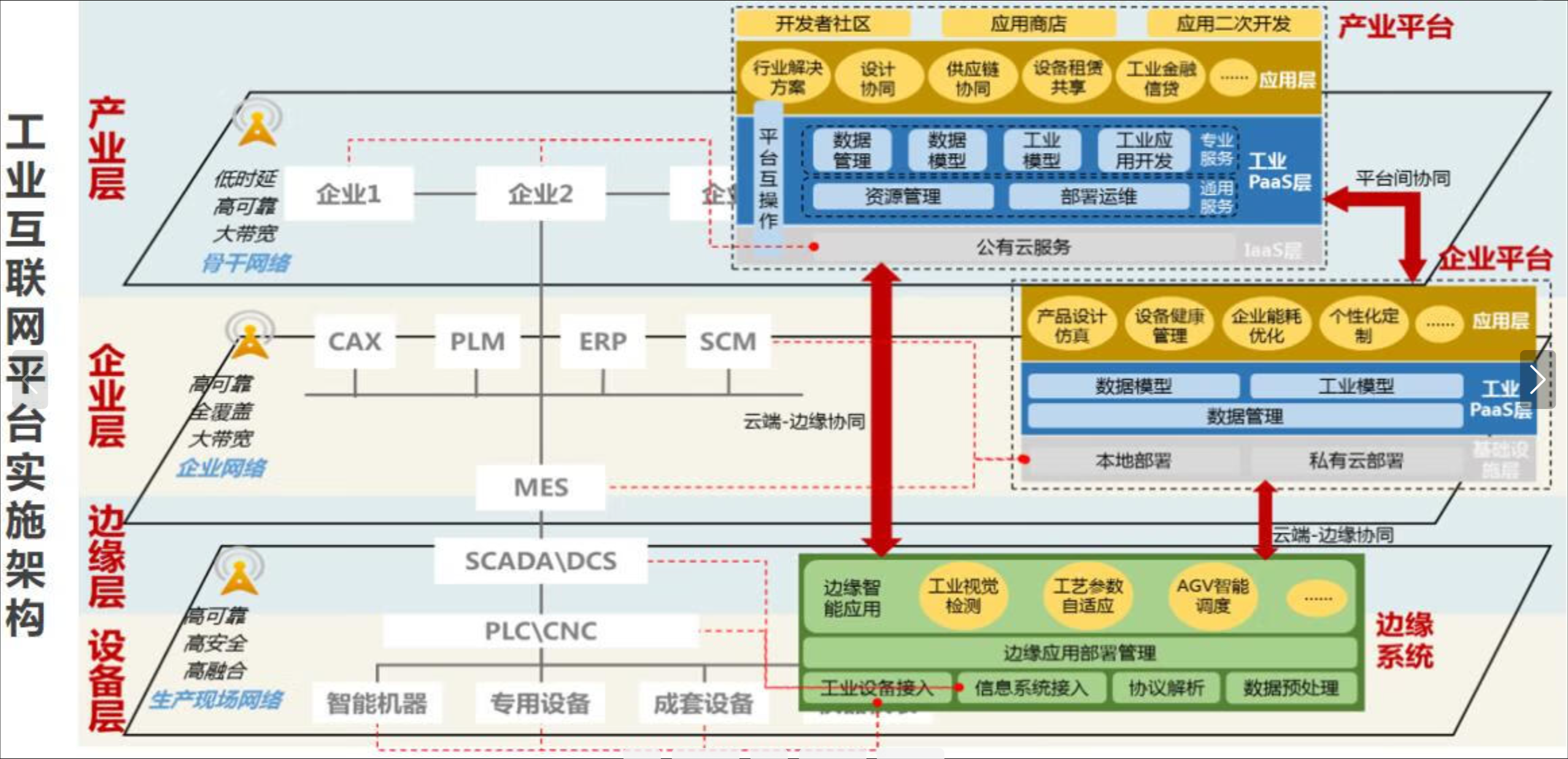
这块儿是真正的实战场景。你在中心云的控制台上,写一个 Deployment,Kurator 就能通过 KubeEdge 的通道,把这个应用精准地投放到千里之外的某个边缘节点上。
咱们手搓一个简单的边缘部署配置看看:
apiVersion: apps/v1
kind: Deployment
metadata:
name: edge-nginx
# namespace 记得选对,别搞乱了
namespace: edge-system
spec:
replicas: 1
selector:
matchLabels:
app: nginx-edge
template:
metadata:
labels:
app: nginx-edge
spec:
# 这个 nodeSelector 是关键,告诉它要去边缘节点
nodeSelector:
node-role.kubernetes.io/edge: ""
containers:
- name: nginx
image: nginx:alpine
# 资源限制还是要给的,边缘设备没那么豪横
resources:
limits:
memory: "128Mi"
cpu: "500m"
这感觉就像在玩红警,鼠标一点,兵就造好了,而且是造在敌后方!😂
🌋 Volcano:算力调度的超级引擎
要是你的业务里有搞 AI 训练、大数据分析这种“吃资源大户”,那普通的 K8s 调度器肯定不够用。这时候 Kurator 里的 Volcano 就派上用场了。
1. Volcano 调度架构
这是Volcano调度架构参考图,展示了其核心组件如何通过CRD、控制器和调度器协同工作,实现对批量计算作业的统一管理: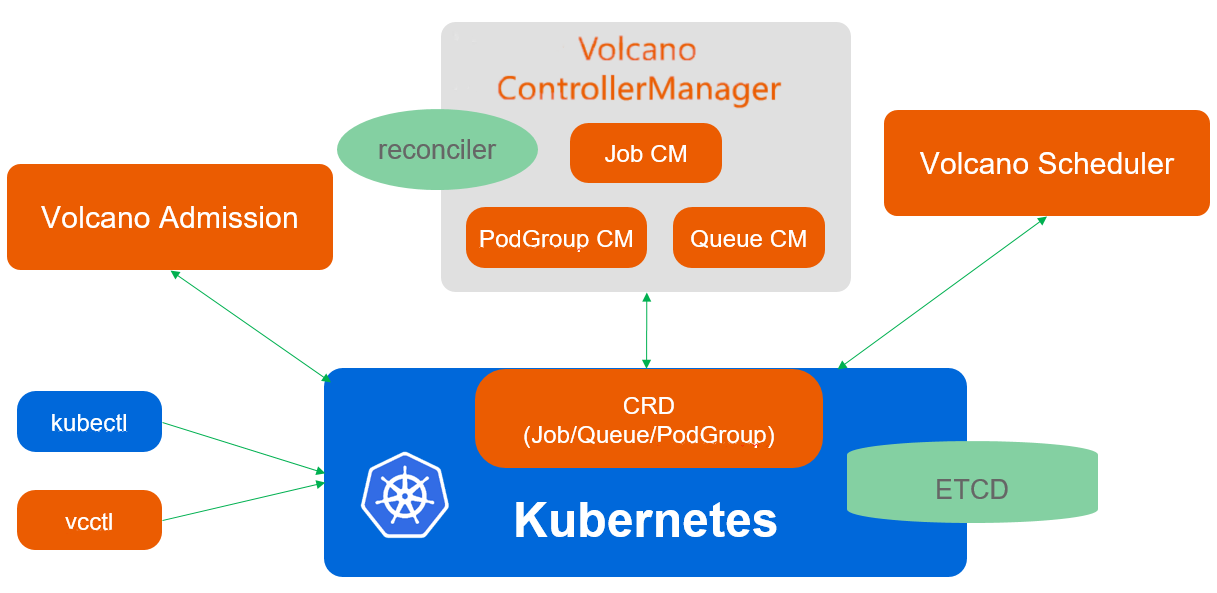
Volcano 的架构是专门为高性能计算(HPC)设计的。它不仅仅看 CPU 和内存够不够,它还看“任务拓扑”。简单说,它有一个 vc-scheduler,这哥们儿比默认调度器聪明多了。它支持 Gang Scheduling(帮派调度),意思是说,如果我有 10 个任务必须一起跑才能干活,资源只够跑 8 个,那这 8 个也不跑,省得占着茅坑不拉屎,等资源够了 10 个一起上。这效率,杠杠的!
2. Volcano 的应用场景
这是Volcano的应用场景参考图,展示了它如何作为统一调度平台,支撑AI训练、大数据及科学计算等多种分布式工作负载: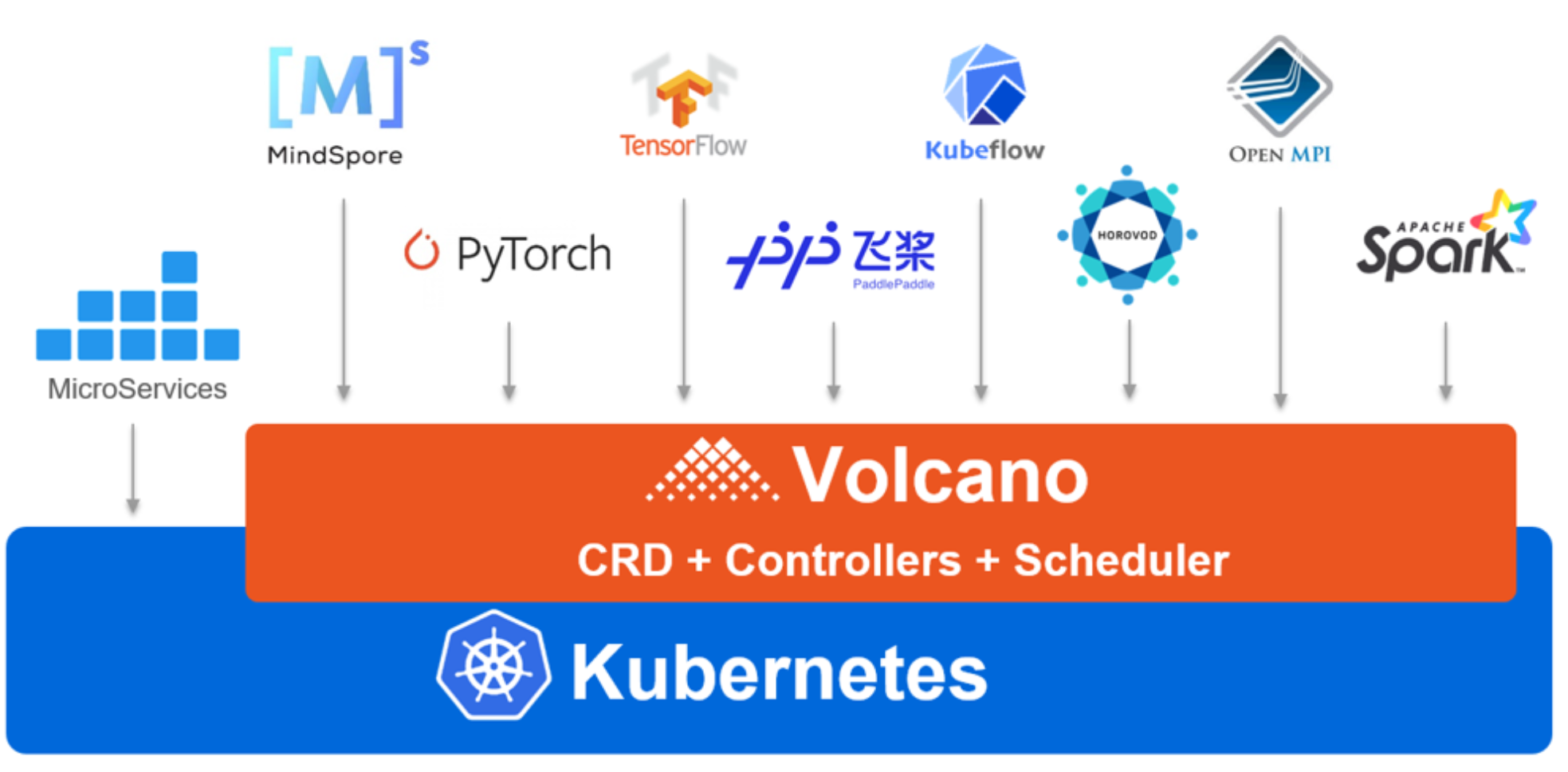
场景可多了去了。比如你跑 TensorFlow 或者 PyTorch 的分布式训练,少一个 worker 都不行,Volcano 就能保证它们同进同退。再比如 Spark 大数据处理,需要大量的批处理任务,Volcano 也能排得井井有条,还能根据优先级插队,保证重要任务先跑完。
🚀 CI/CD 与 Rollout:发布上线一条龙
代码写好了,怎么上生产?Kurator 在这块儿也是操碎了心,给你整了一套丝滑的流程。
1. Kurator CI/CD 的完整流程
这张图展示了Kurator CI/CD的完整流程,从代码拉取、编译、安全扫描、镜像构建和签名,再到多环境自动部署,整个过程高度自动化,既保证了交付效率,又兼顾了安全性和可追溯性: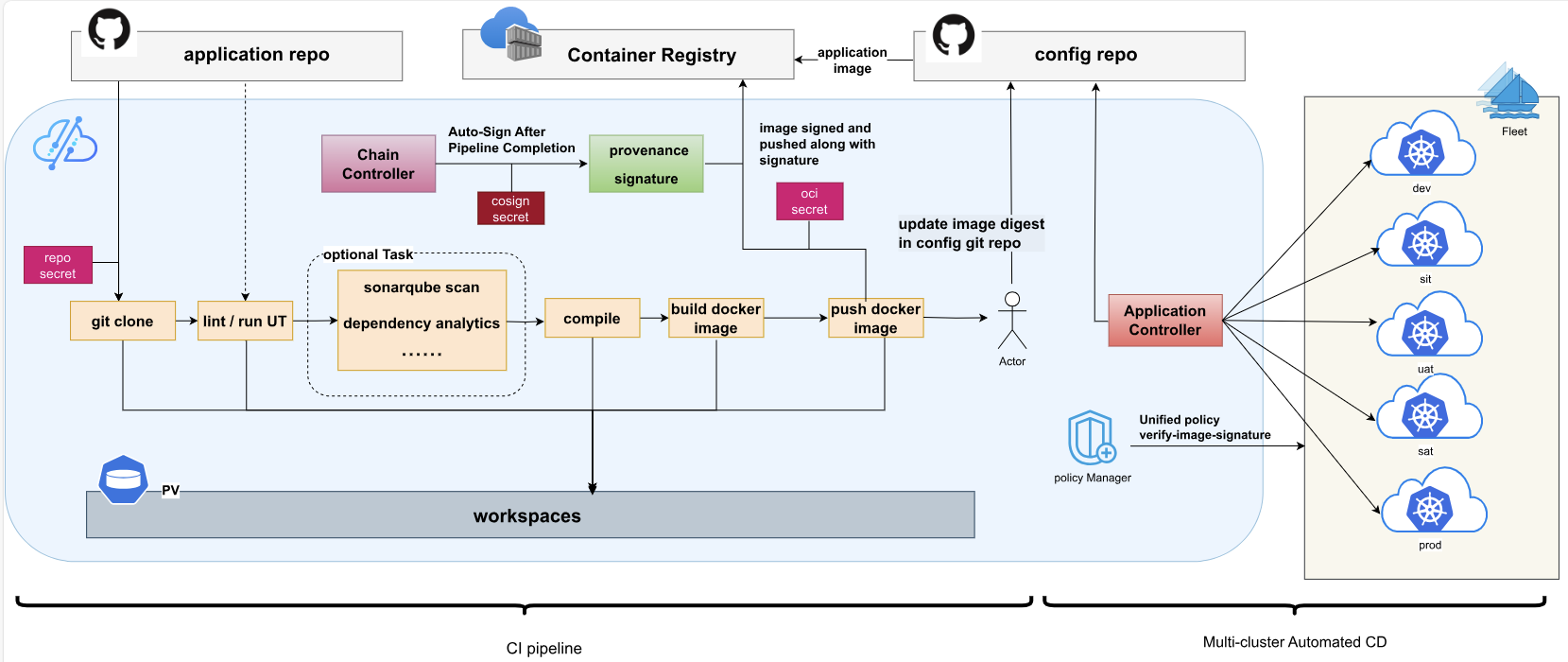
这里的 CI/CD 主打一个“简化”。它底层其实也是用了 Tekton 这种强力工具,但是被封装得很易用。
流程大概是这样的:
- 你提交代码到 Git 仓库。
- Webhook 触发 Kurator 的 Pipeline。
- Pipeline 自动拉代码、编译、打 Docker 镜像。
- 镜像推送到仓库后,自动更新 GitOps 的配置仓库。
- 最后自动触发同步,把新版本应用部署到目标集群。
整个过程你只需要喝杯咖啡,看着绿灯一个个亮起来就行。
2. Kurator Rollout 功能的架构
这是Kurator Rollout功能的架构图,展示了如何基于Git仓库和策略控制器,通过Flagger在多个集群中实现灰度发布: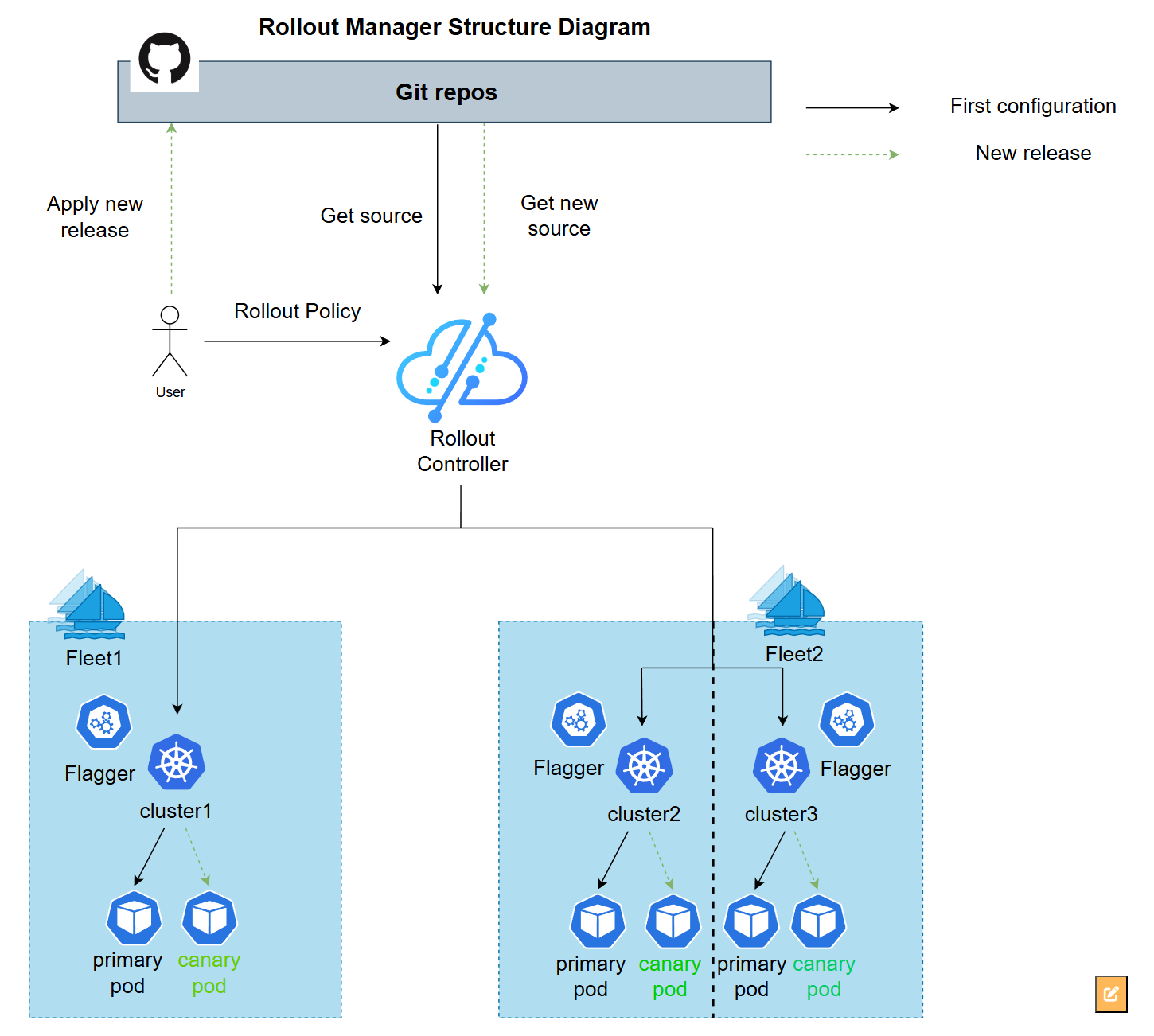
发布的时候,要是直接全量更新,万一有 Bug 就炸了。Kurator 的 Rollout 架构支持金丝雀发布(Canary)和蓝绿部署。它通过引入一个渐进式的流量控制器,配合 Service Mesh(像 Istio),能通过调整流量比例,比如先切 ( 5% ) 的流量给新版本,没报错再切 ( 20% ),最后 ( 100% )。公式表达的话,假设总流量是 ( T ),新版本流量 ( T_{new} ) 是随着时间 ( t ) 递增的函数 ( T_{new}(t) )。
📊 统一监控架构:上帝视角看世界
最后,咱们得知道系统跑得咋样吧?Kurator 搞了个统一监控架构。
1. Kurator 的统一监控架构
这个架构的核心思想是“联邦监控”。它不是让你去每个集群里看 Prometheus,而是通过 Thanos 这种组件,把所有集群的监控数据聚合到一个中心视图里。
每个集群里有个小探针(Sidecar 模式或者 Agent),把数据往上传。中心端有一个全局的 Query 组件,你查一个 Metrics,它能自动去各个集群里捞数据,然后聚合给你看。
来个手搓的监控配置片段感受下:
apiVersion: monitoring.kurator.dev/v1alpha1
kind: UnifiedMonitor
metadata:
name: global-view
spec:
# 告诉它要去哪些集群捞数据
clusters:
- cluster-a
- cluster-b
storage:
# 数据存哪儿,对象存储是个好地方
type: s3
config:
bucket: kurator-metrics
endpoint: s3.amazonaws.com
retention:
# 数据保留多久,看你硬盘够不够大咯
time: "15d"
这样一来,无论你的 Pod 是跑在阿里云的虚拟机上,还是跑在工厂车间的边缘盒子上,你都能在一个大屏上看到它们的 CPU 是不是飙红了。
好啦,Kurator 的这几个核心大件儿咱们算是盘完了。是不是觉得云原生其实也没那么复杂?有了这些神兵利器,咱们这些“云原生牧羊人”也能早点下班回家躺平啦!😎 加油,我看好你哟!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)